
论文题目:DeNovoSWE: Scaling Long-Horizon Environments for Generating Entire Repositories from Scratch
仓库链接:github.com/AweAI-Team/...
huggingface 链接:huggingface.co/collections...
当下,LLM Code Agent 能力正在加速迭代。一个明显的趋势是:单文件或单函数代码补全不再是研究者的重点,更接近真实研发场景的长程任务才是未来的关键,例如:仓库级的代码生成、跨文件协调、从零到一的架构搭建等任务。
顺应这一趋势,长程任务相关的评测基准也相继发布,如 NL2RepoBench、BeyondSWE 等。在这些标准内,Code Agent 也从原有的"仓库维护者",逐渐升级为"架构师"。它既需要理解现有代码,又需要做规划、拆解任务,并完成整个仓库级别的代码生成与优化。
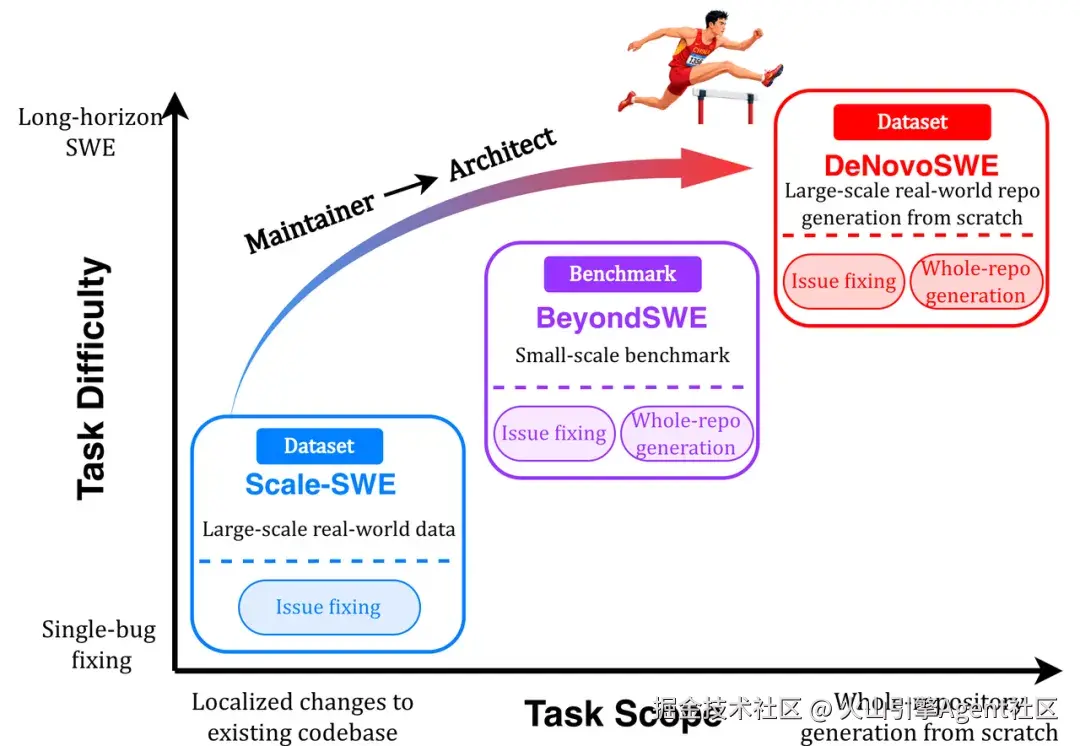
然而,长程任务的规模化数据构建并非一蹴而就。传统本地环境规模有限,难以支撑大规模并发,且资源隔离不足,安全风险非常大。而现有云上沙箱的能力参差不齐,在整个规模化数据构建流程中问题更多。需要解决的现实难题就是:如何搭建一个安全、可控、高并发的环境,稳定地运行 Agent 轨迹采集、编译验证和自动化评测?
火山引擎云沙箱的出现,就是希望能解决这一问题。
作为面向 AI Agent 研发全流程的沙箱基础设施,火山引擎云沙箱具备三大核心能力:高并发调度(实际可支持 10 万级并发)、强安全隔离(虚拟机级别运行时隔离)、灵活可控的执行环境(毫秒级拉起,按需配置)。 这些能力提供了稳定可靠的技术底座,助力 Code Agent 的数据构建、RL 训练、模型蒸馏和自动化评测顺利进行。
来自学术界的最新合作成果,对火山引擎云沙箱能力进行了验证。
近日,中国人民大学高瓴人工智能学院团队发布了 DeNovoSWE 数据集。该研究聚焦于长程软件工程任务,尤其是仓库级别代码从零生成这一极具挑战性的任务方向。依托火山引擎云沙箱,团队采用 Divide & Conquer 与 Critic & Repair 机制,高质量地构建了长程 SWE 任务数据集,这是目前开源社区中规模最大的数据集,包含 4,818 个真实数据样本,有效支撑了 Code Agent 长程能力的训练。
更重要的是,研究团队通过给数据集的题目难度打分与过滤手段,有效缓解了"困难题目比例"与"轨迹质量"之间难以权衡的问题,保障了训练数据的难度,又不牺牲可用性。
在多个评测基准上,基于 DeNovoSWE 数据集训练的某 30B 参数规模开源模型取得了显著提升:
- BeyondSWE-Doc2Repo:从 5.8% 提升至 47.2%
- NL2RepoBench:从 4.3% 提升至 23%
这一成果的高效落地,得益于火山引擎云沙箱强有力支撑。在构建过程中,研究团队仅启用了 5,000 并发的 Sandbox 资源,便实现了数据流水线的稳定运行、安全防护与快速迭代,轻松支撑起 4.8k 量级数据的全流程处理。
对于正在推进 Code Agent 长程能力研发的团队而言,这或许是一个值得关注的参考案例。以下是关于本次研究成果的一些关键解读:
DeNovoSWE:让代码智能体从一份文档开始,重建整个仓库
过去一年,代码智能体在 SWE-bench 这类真实软件工程任务上快速进步。但当模型越来越擅长"修一个 issue""改几行 bug"之后,一个更关键的问题开始浮现:智能体真的具备长程软件工程能力了吗?
真实世界的软件开发,往往不是改一个函数、补一个条件判断,而是理解需求、规划架构、创建文件、设计 API、处理依赖、联通模块,并最终让整个仓库在测试中跑通。
换句话说,真正困难的是 long-horizon repository-level generation:从一份任务文档出发,生成一个完整、可执行、可验证的软件仓库。
这正是 DeNovoSWE 想要解决的问题。
高质量的"从头生成仓库"任务文档,应该是什么样的?
在 document-to-repository generation 中,文档不只是 README,也不是简单的 API 列表。它本质上是智能体重建整个仓库的唯一任务入口。
一份高质量的任务文档,至少需要满足两个核心标准。
第一:它必须是 well-organized 的
仓库级任务天然复杂,包含多个模块、接口、配置、数据结构和交互流程。如果文档只是把函数说明堆在一起,智能体很容易迷失在碎片信息中。因此,文档应该先给出清晰的仓库总览,再按照能力或工作流拆分章节,让每一部分都对应明确的功能边界。
第二:从可靠 evaluation 的角度
文档既不能太少,否则任务变成欠定义问题;也不能太多,否则直接泄漏实现细节,让任务失去挑战。真正高质量的文档应该描述 evaluation 所依赖的关键行为:包括 import path、公开 API、输入输出、默认参数、异常行为、配置项、模式字符串、返回字段等。也就是说,文档要足以让智能体复现可测试行为,但不能变成实现代码的拷贝。
因此适合训练的文档应该是:既可读、可实现,又可验证。
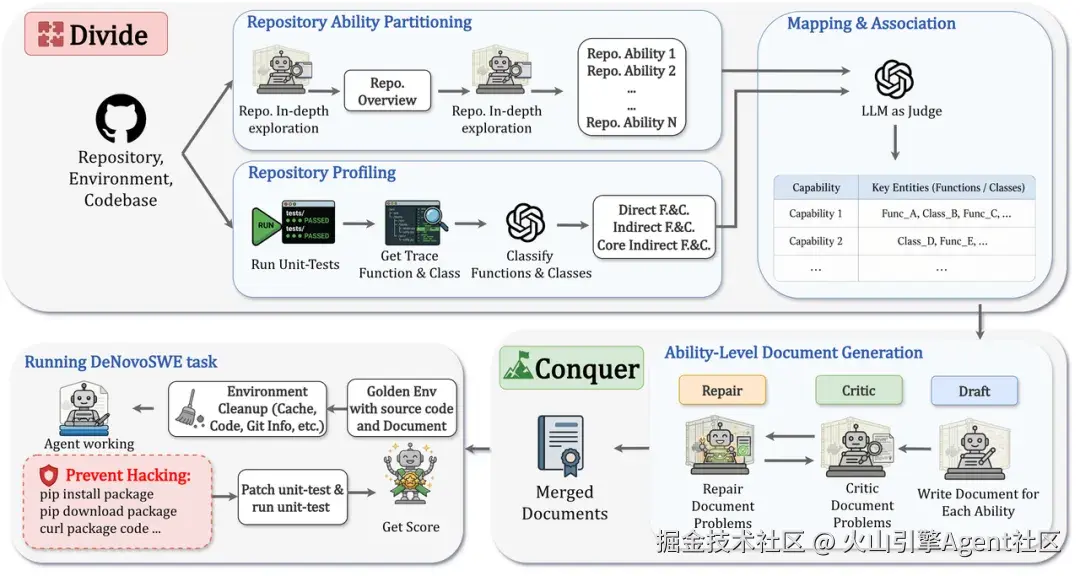
DeNovoSWE 方法:Divide and Conquer + Critic-Repair
DeNovoSWE 将"从文档生成完整仓库"构造成一个大规模、可验证的长程软件工程任务。它不是人工手写文档,而是通过一个 sandboxed multi-agent workflow 自动构建高质量实例。
整个方法可以概括为两步:Divide 和 Conquer。
在 Divide 阶段:系统首先分析目标仓库,将其拆解为多个 repository capabilities。每个 capability 对应仓库中的一个核心能力或工作流,例如认证与连接、数据读写、批处理、导出流程等。这样,原本庞大的仓库生成问题被拆成若干结构清晰的文档章节。
同时,DeNovoSWE 会运行原始单元测试并收集执行 trace,识别哪些函数、类和接口真正影响 evaluation。它进一步区分三类组件:
- direct components:直接被测试调用的接口,必须详细记录;
- core indirect components:会影响可观察行为的核心间接组件,需要覆盖;
- non-core indirect components:非核心内部实现,留给智能体自由发挥。
在 Conquer 阶段:使用 Draft-Critic-Repair 机制逐能力生成文档。Draft agent 先写出初稿;Critic agent 检查文档质量是否足够好------是否遗漏关键功能、API、行为契约或结构信息;Repair agent 再根据反馈修复文档。这个循环不断迭代,直到每个能力章节足够清晰、完整、与 evaluation 对齐。
最终,不同能力文档会被合并成一份完整的任务文档,作为智能体从零生成仓库的唯一依据。
难度:为什么这是长程任务?
DeNovoSWE 的任务难度来自一个根本变化:它不再是 issue-level fixing,而是 whole-repository generation。
在传统 SWE 任务中,智能体通常面对的是一个已有仓库,只需要定位 bug、修改局部代码、通过测试即可。而在 DeNovoSWE 中,智能体面对的是一个被清理后的环境:原始源码和测试被移除,git 历史被重置,缓存、site-packages 残留、pip wheel、临时编译产物等潜在泄漏渠道也会被清除。
这意味着智能体必须真正依赖文档来完成整个仓库的重建。
它需要规划项目结构,创建模块文件,定义公开接口,实现跨文件交互,处理依赖和配置,并在多轮编辑与测试反馈中不断修复错误。任何一个 API 签名、返回字段、异常类型或默认行为的偏差,都可能导致测试失败。错误还会在长程过程中累积:一个早期设计不合理的模块,可能影响后续多个文件和调用链。
因此,DeNovoSWE 不只是"代码生成"数据集,而是面向长程软件工程能力的数据集。
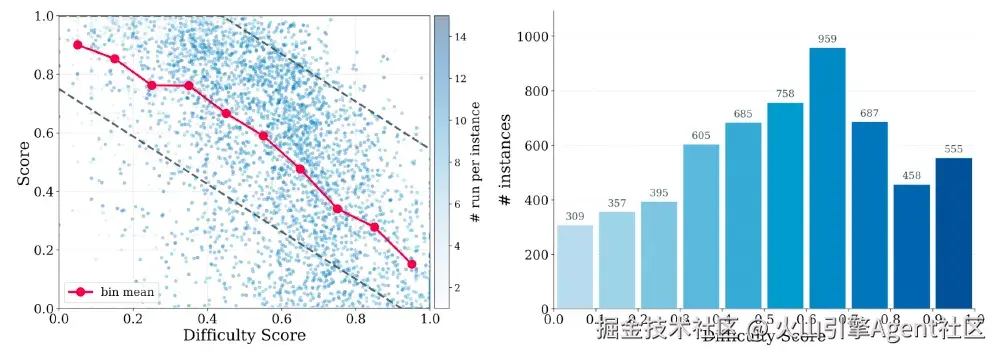
为了进一步处理不同仓库难度差异,DeNovoSWE 还提出了 difficulty-aware trajectory filtering。简单地说,容易任务应该要求更高通过率,困难任务则不能因为没有达到完美分数就被全部丢弃。DeNovoSWE 根据结构复杂度和 LLM 难度判断,为不同难度区间设置不同过滤阈值,从而在质量和多样性之间取得平衡。
这对于长程任务尤其重要:越复杂的仓库,越难一次性完全通过所有测试,但其中的高质量部分成功轨迹仍然包含宝贵的长程规划与实现能力。
结果:高质量长程数据带来能力跃迁
DeNovoSWE 最终构建了 4,818 个高质量 document-to-repository 任务实例,规模显著超过此前的仓库生成数据集。更重要的是,这些实例不是静态文本任务,而是可执行、可评估、可训练的长程软件工程环境。
实验结果显示,DeNovoSWE 对模型的长程仓库生成能力带来了显著提升。
在某 30B 参数开源模型上:
- 原始模型在 BeyondSWE-Doc2Repo 上只有 5.8% ,在 NL2RepoBench 上只有 4.3% ;
- 使用常规 issue-level SWE 数据训练的 Scale-SWE-Agent 可以提升到 29.2% 和 18.3% ------ 说明普通 SWE 数据确实有迁移效果;
- 使用 DeNovoSWE 训练后,性能进一步提升到 47.2% 和 23.0% 。
这说明,面向"修 bug"的数据,并不能完全替代面向"生成完整仓库"的长程数据。 想让智能体真正学会 repository-level engineering,就需要专门面向长程任务构建训练环境。
在更强的某 35B 参数开源模型上,DeNovoSWE 同样带来稳定收益:BeyondSWE-Doc2Repo 从 43.8% 提升到 50.0% ,NL2RepoBench 从 23.5% 提升到 27.1% 。
结语:从"会修代码"的维护者到"会造软件"的架构师
未来的代码智能体,不仅要更快地修复单个 issue,而且要能够理解文档、规划架构、组织模块、实现接口,最终生成一个完整可运行的软件仓库。
从一份文档开始,重建整个 repository,这是长程代码智能体真正需要跨越的门槛。
DeNooSWE 将这个目标高效落地,系统化地构造成了可训练、可验证、可扩展的数据集,并回答了一个关键问题:什么样的数据,才能真正训练出具备长程软件工程能力的智能体?
答案不是更多碎片化的代码片段,也不是更简单的题目,而是高质量、结构化、与 evaluation 对齐,且做好防泄漏设计(anti-leakage)的全仓库生成任务。
在 DeNovoSWE 的实践中,火山引擎云沙箱提供了稳定、可扩展的基础设施支撑,仅用 5,000 并发便完成了全部流程。这远非其能力上限,它的底层调度系统实际可支持 10 万量级的并发沙箱调度,能为更大规模的 Agent 研发任务预留充足空间。从数据构建、RL 训练,到模型蒸馏、自动化评测,火山引擎云沙箱以高并发、高安全、高稳定为核心优势,将复杂研发流程化繁为简,为每一步工作提供可量化、可复现的基础设施保障。
跨过这道门槛后,长程代码智能体不再只是一个"修 bug 的快手",而是成长为一个有能力参与真实软件架构设计的"协作者"。