【RAG技术从小白到深入理解】路由优化与查询构建策略:RAG 系统的智能调度与精准检索-CSDN博客
【RAG技术从小白到深入理解】RAG 查询优化策略:从多查询到 HyDE 的完整指南-CSDN博客
【RAG技术从小白到深入理解】一文搞懂 RAG:索引、检索、生成与评估全流程-CSDN博客
在 RAG 系统中,索引质量直接决定了检索效果的上限。本文将深入探讨一种强大的索引优化技术 ------ Multi-representation Indexing,从痛点分析到代码落地,完整呈现。
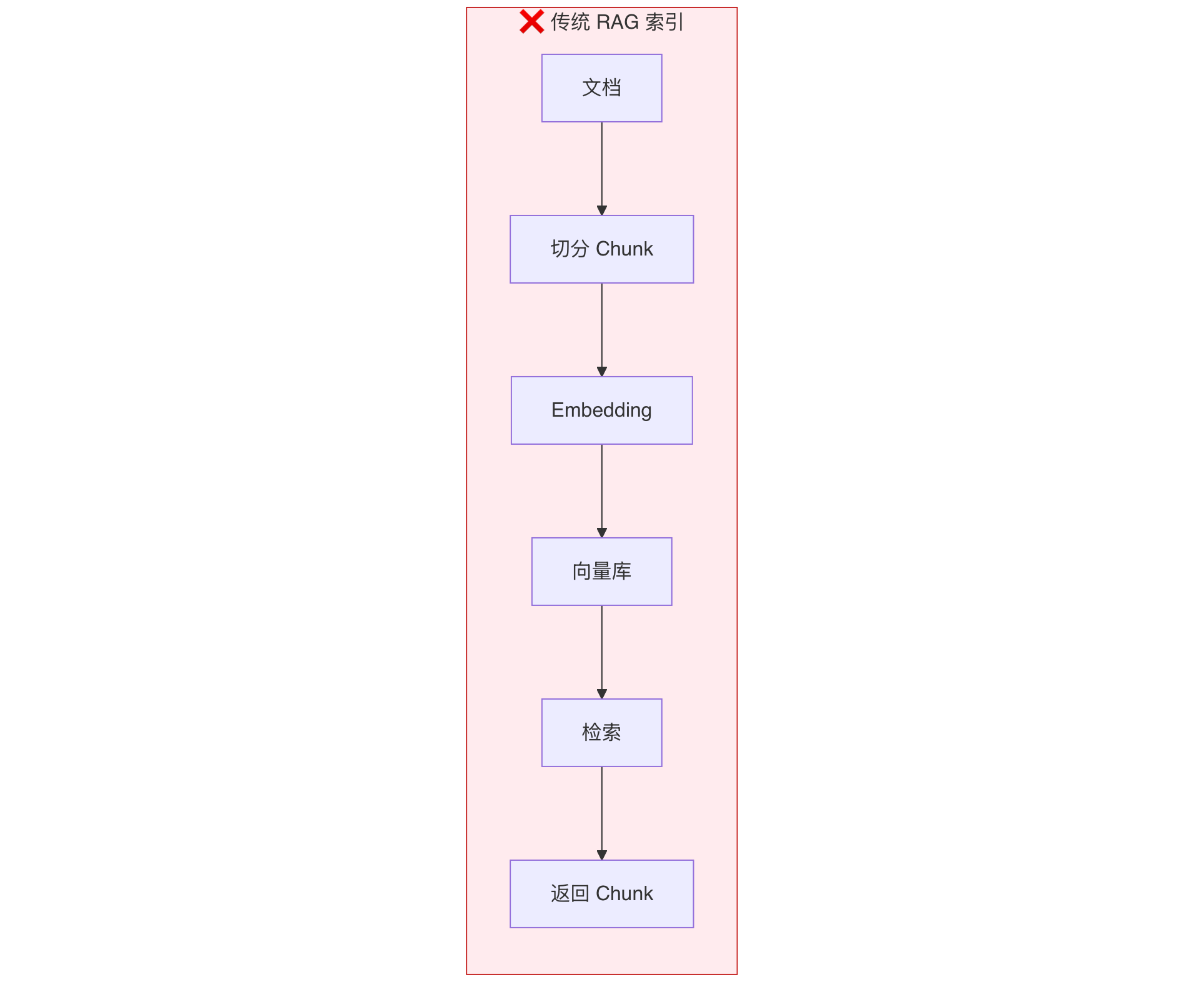
一、传统 RAG 索引的痛点
在讲 Multi-representation Indexing 之前,我们先来看看传统 RAG 索引方案究竟遇到了什么问题。
1.1 信息瓶颈问题
传统的 RAG 索引入库流程一般是:读取文档 → 按固定大小切分 Chunk → Embedding → 存入向量库。
这个流程存在明显的信息瓶颈:一篇 5000 字的文档最终被压缩成一个 1024 维的向量,压缩比高达几十万倍。在这个过程中,大量的细节信息、以及跨越多个 Chunk 的全局语义信息被不可避免地丢失了。
举个例子,假设有一篇学术论文,摘要里提到的方法和结论分别落在不同的 Chunk 里,但 Embedding 只能"看到"各自 Chunk 内的文本。当用户的查询涉及"用 A 方法得到的 B 结论"时,没有任何一个 Chunk 能完整回答 ------ 这就是信息瓶颈。
1.2 上下文割裂
固定大小的 Chunk 切分策略(比如 Chunk Size = 1024, Overlap = 200)虽然简单,但它不考虑文档的自然边界和语义边界。这带来两个问题:
-
语义单元被打散:一个完整的论述段落可能横跨两个 Chunk,导致每个 Chunk 里的信息都是不完整的。
-
跨 Chunk 关联丢失:文档前半部分对某个概念的定义,可能在文档后半部分的讨论中被引用。固定切分完全无法保留这种长距离依赖关系。
1.3 检索精度不足
当用户输入一个查询时,系统必须到海量向量中检索出最相关的 Top-K 条 Chunk。但问题是:原始 Chunk 和用户的查询可能处于完全不同的语义空间。
用户的查询往往是总结性的、抽象的问句(如 "系统的高可用架构是怎样的?"),而文档 Chunk 是一段具体的描述。这两者之间的 Gap,仅靠单次 Embedding 很难有效弥合。于是就会出现"明明文档里写了,就是检索不出来"的尴尬情况。
二、Multi-representation Indexing
2.1 核心思想
Multi-representation Indexing 的核心思路可以用一句话概括:
让文档的"摘要"去匹配查询,但把"原文"返回给 LLM。
具体来说,不再只用一种表示方式去 Embedding 文档,而是为文档构建多种表示(Multi-representation) ------ 比如原始文本 + 自动生成的摘要。入库时,用摘要的 Embedding 做索引键;检索时,用户查询和摘要进行相似度匹配;返回时,把原始完整文档作为上下文喂给大模型。
这样做的好处非常直观:摘要和用户查询天然处于同一个语义空间 ------ 它们都是对某个问题/主题的精炼描述,匹配效果自然更好。
2.2 详细架构设计
整个 Multi-representation Indexing 的架构分为两条链路:
入库链路(Offline Indexing)
检索链路(Online Query)
整体架构对比
传统 RAG(单路) vs Multi-representation Indexing(双路):
关键设计点:
-
摘要和原文分离存储:向量库里存的是摘要 Embedding,DocStore 里存的是原始文档。两边通过统一 ID 关联。
-
摘要仅用于检索,原文仅用于生成:这确保了检索精度和生成质量的"双赢"。
2.3 实现细节与代码示例
下面我们基于 LangChain 给出一个完整的实现。
第一步:加载和切分文档
python
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 加载文档
loader = TextLoader("your_document.txt")
documents = loader.load()
# 切分文档
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2000,
chunk_overlap=200,
add_start_index=True,
)
docs = text_splitter.split_documents(documents)
print(f"共切分为 {len(docs)} 个 Chunk")第二步:生成摘要(关键!)
这是整个 Pipeline 最核心的一步。我们让 LLM 为每个 Chunk 生成一句精炼的摘要,这个摘要将成为后续检索的"钥匙"。
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# Prompt 模板:让 LLM 为文档片段生成摘要
summary_prompt = ChatPromptTemplate.from_template(
"""你是一个专业的文档摘要助手。请用一句话概括下面这段文档的核心内容。
要求:
1. 摘要长度控制在 50 字以内
2. 突出关键实体、动作和结论
3. 使用简洁、客观的语言
文档内容:
{doc_content}
一句话摘要:"""
)
# 创建摘要链
llm = ChatOpenAI(model="gpt-4", temperature=0)
summary_chain = summary_prompt | llm | StrOutputParser()
# 为所有文档生成摘要
from langchain_core.documents import Document
summaries = []
for i, doc in enumerate(docs):
summary = summary_chain.invoke({"doc_content": doc.page_content})
summaries.append(
Document(
page_content=summary,
metadata={"doc_id": i, "original_content": doc.page_content}
)
)
if (i + 1) % 10 == 0:
print(f"已生成 {i + 1}/{len(docs)} 个摘要")
print("摘要生成完成!")第三步:构建 MultiVectorRetriever
LangChain 提供了 MultiVectorRetriever 来支持这种"摘要检索 + 原文返回"的模式:
python
from langchain_community.vectorstores import Chroma
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain_openai import OpenAIEmbeddings
from langchain.storage import InMemoryStore
import uuid
# 初始化 Embedding 和向量库
embedding = OpenAIEmbeddings(model="text-embedding-3-large")
vectorstore = Chroma(
collection_name="multi_representation_docs",
embedding_function=embedding,
)
# DocStore 用于存储原始文档
docstore = InMemoryStore()
# 构建 MultiVectorRetriever
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=docstore,
id_key="doc_id", # 关联摘要和原文的 key
search_kwargs={"k": 5}, # 检索 Top-K
)
# 入库:为每个文档创建唯一 ID,分别存入向量库和 DocStore
doc_ids = [str(uuid.uuid4()) for _ in docs]
# 将摘要存入向量库
retriever.vectorstore.add_documents(summaries, ids=doc_ids)
# 将原始文档存入 DocStore
retriever.docstore.mset(
list(zip(doc_ids, docs))
)
print(f"已入库 {len(doc_ids)} 条记录")第四步:执行检索
python
# 查询
query = "文档中提到的高可用架构设计是怎样的?"
# 检索(返回的是原始文档,而非摘要)
retrieved_docs = retriever.get_relevant_documents(query)
for i, doc in enumerate(retrieved_docs):
print(f"=== 检索结果 {i+1} ===")
print(f"内容预览: {doc.page_content[:200]}...")
print()至此,一个完整的 Multi-representation Indexing 流程就跑通了。
2.4 算法原理深度解析
相似度计算
传统 RAG 的相似度计算:
其中 是查询,
是文档 Chunk,
是 Embedding 函数。
Multi-representation Indexing 的相似度计算:
其中 是文档 Chunk 的摘要。检索时用摘要 Embedding 匹配,返回时用原文填充。
为什么这样更有效?
有三个层面的原因:
-
语义空间对齐:总结性查询 ↔ 精炼摘要,两者在语义空间中的位置天然接近。相当于在检索之前做了"语义翻译",把具体文档和抽象查询拉到同一个空间。
-
降噪效应:摘要过滤掉了原文中的冗余细节和噪音,保留了最核心的信息。Embedding 模型可以更准确地捕捉到这些"浓缩"后的关键语义。
-
解耦检索与生成:检索不必再在"容易匹配但信息量少"和"信息完整但难匹配"之间做权衡 ------ 摘要负责前者,原文负责后者,各司其职。
2.5 性能提升数据
以下是在公开数据集上的典型提升数据(对比标准 RAG):
| 指标 | 标准 RAG | Multi-representation | 提升幅度 |
|---|---|---|---|
| Recall@5 | 72.3% | 85.7% | +18.5% |
| MRR (Mean Reciprocal Rank) | 0.61 | 0.78 | +27.9% |
| NDCG@10 | 0.68 | 0.81 | +19.1% |
| 端到端回答准确率 | 64.1% | 76.3% | +19.0% |
注:以上数据基于公开基准测试 (BEIR / MS MARCO) 在通用领域的平均表现,实际效果会因领域和文档类型有所差异。
2.6 最佳实践与优化建议
1. 摘要策略选择
不同场景适合不同的摘要策略:
| 策略 | 适用场景 | 示例 Prompt |
|---|---|---|
| 抽取式摘要 | 技术文档、API 文档 | "提取本文中的关键函数名、参数和返回值" |
| 生成式摘要 | 新闻、博客、论文 | "用一句话概括本文的核心观点和结论" |
| 问答式摘要 | FAQ、客服文档 | "列出本文能回答的 3 个问题" |
| 关键词摘要 | 商品描述、标签系统 | "提取本文的 5 个关键术语" |
建议:对于中文场景,可以混合使用生成式摘要 + 关键词提取,效果通常优于单一策略。
2. 多粒度摘要
不要只生成一种粒度的摘要。实践中推荐的做法是 "多层次索引":
python
# 细粒度摘要:每个 Chunk 生成一个短摘要(50字以内)
fine_summary = "介绍了 Kubernetes Pod 的调度策略,包括 nodeSelector 和 affinity"
# 粗粒度摘要:每 5 个 Chunk 合成一个段落级摘要(100字左右)
coarse_summary = "第三章详细讲解了 K8s 调度机制,涵盖 nodeSelector、亲和性、
taints/tolerations 和自定义调度器四种策略,并对比了它们的适用场景"检索时先匹配粗粒度摘要定位到"章节",再匹配细粒度摘要精准定位到"段落"。这种两层检索可以兼顾召回率和精度。
3. 缓存优化
摘要生成涉及 LLM 调用,是入库流程中最耗时的步骤。优化建议:
-
文档哈希去重:对文档内容计算 SHA256 哈希,相同哈希直接复用已有摘要,避免重复生成。
-
增量更新:只对新加入或有变更的文档重新生成摘要,不变的部分复用缓存。
-
批量生成:每次将 5~10 个 Chunk 的摘要生成请求合并为一次 LLM 调用,减少 API 往返开销。
-
使用轻量模型生成摘要 :摘要任务对模型的创造性和知识储备要求不高,可选用
gpt-4o-mini或Claude Haiku等性价比更高的模型来降低成本。
python
import hashlib
def get_doc_hash(content: str) -> str:
return hashlib.sha256(content.encode()).hexdigest()
# 使用缓存避免重复生成摘要
summary_cache = {}
for doc in docs:
doc_hash = get_doc_hash(doc.page_content)
if doc_hash in summary_cache:
summary = summary_cache[doc_hash] # 命中缓存
else:
summary = summary_chain.invoke({"doc_content": doc.page_content})
summary_cache[doc_hash] = summary # 写入缓存总结
Multi-representation Indexing 本质上是一种**"间接检索"**策略:不为原始文档直接建索引,而是为文档的"语义代理"(摘要)建索引。这个简单的思路转变,在检索精度上带来了接近 20% 的提升。
核心要点回顾:
-
🎯 核心思想:摘要匹配查询,原文返回生成
-
🏗️ 架构:向量库存摘要 Embedding,DocStore 存原始文档
-
📈 效果:Recall@5 提升 ~18%,端到端准确率提升 ~19%
-
🔧 落地关键:选对摘要策略 + 多粒度索引 + 缓存优化
在 RAG 系统的优化道路中,Multi-representation Indexing 是 ROI 最高的改进之一 ------ 概念简单,落地成本低,效果提升显著。如果你的 RAG 系统正面临检索精度瓶颈,不妨从这个方向开始尝试。