本文是对 UCSD 团队发表在 ICLR 2025 论文的解读,该论文正是 AIBrix 中
prefix_cache_preble算法的学术原型。
一、论文解决的核心问题
现代 LLM 推理有两个明显趋势:
- Prompt 越来越长:五种被研究的工作负载中,prompt 长度是生成序列的 37 倍到 2494 倍。Video QA 场景尤为夸张,prompt 几乎全是视频 token。
- Prompt 大量重复共享:这五种工作负载中,85% 到 97% 的 prompt token 都与其他请求共享,单个共享序列平均被 8.6 到 126 个请求复用。
现有系统的矛盾在于:
- 单 GPU 层面的 KV cache 复用(SGLang、vLLM)已经做得不错。
- 但到了多 GPU 分布式场景,目前的分布式 LLM 服务系统不感知 prompt 缓存;它们试图把计算负载均匀分布到各 GPU 上,但这样会把共享相同前缀的请求发到不同 GPU,导致大量本可避免的 KV 重计算。
- 反过来,如果朴素地把所有相同前缀请求发到同一个 GPU,又会导致负载失衡。
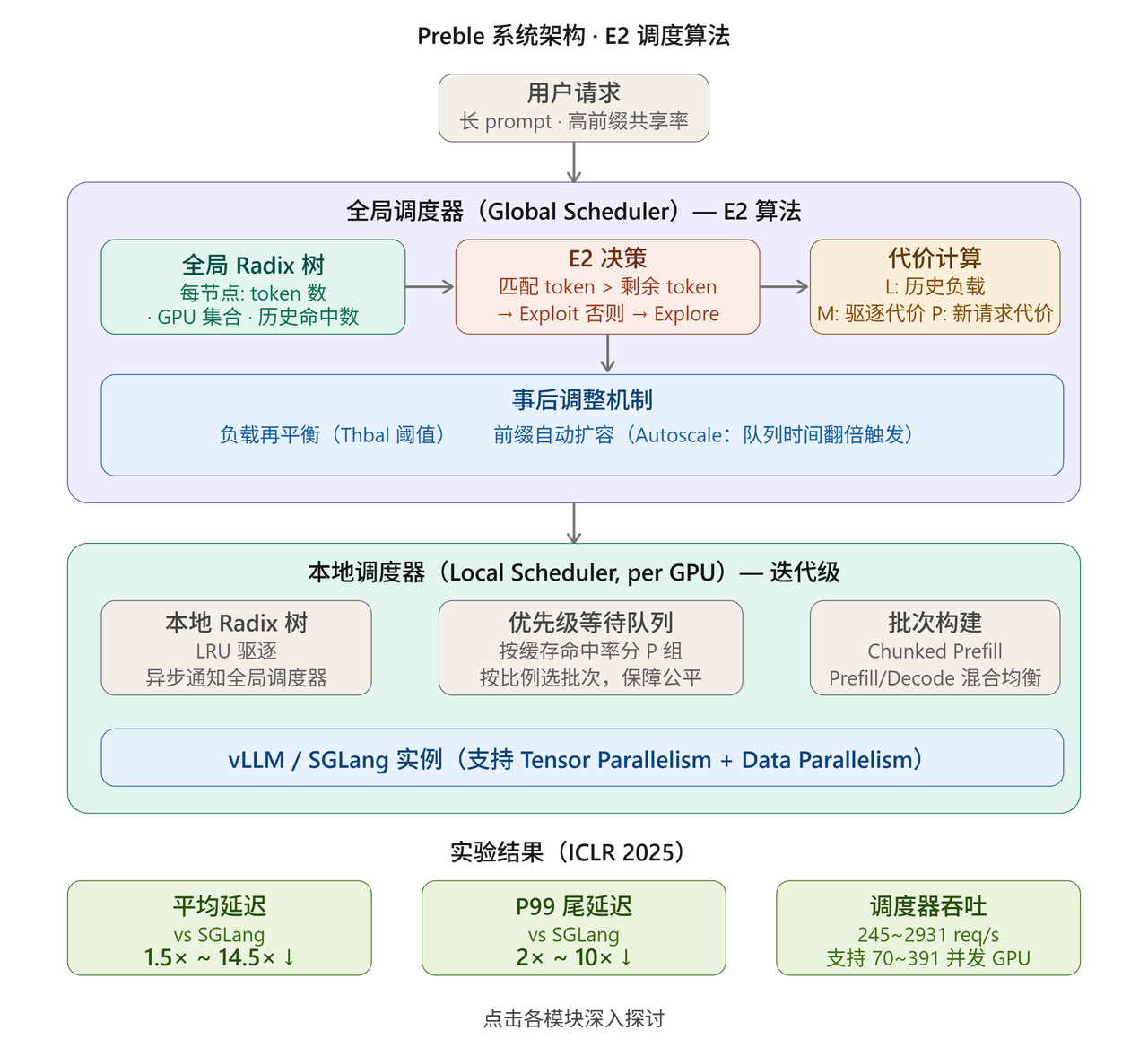
二、E2 调度算法------论文最核心的创新
"E2"代表 Exploitation + Exploration,这个命名来自强化学习的经典 trade-off。
决策门槛
当匹配到的前缀 token 数量大于 剩余未匹配 token 数量时,选择 Exploit (复用缓存);否则选择 Explore(寻找最优 GPU)。
这个边界成立是因为:前缀越长,节省的 GPU 计算越多,值得优先保证缓存命中。
Exploit 路径
直接把请求路由到持有最长前缀 KV cache 的 GPU,若并列则取负载最轻者。
Explore 路径
用一个三部分加总的代价函数选最优 GPU:
- L(历史负载):用一个时间窗口 H(默认 3 分钟)内所有请求的 prefill + decode 时间估算。prefill 时间用回归函数由未命中 token 数估算;decode 时间用窗口内平均输出长度估算。
- M(驱逐代价):为了给新请求腾出 GPU 内存需要驱逐的 KV 节点,其代价 = 被驱逐节点的 prefill 重计算时间 × 该节点历史命中率。命中率越高的节点越贵,驱逐它损失越大。
- P(新请求代价):当次请求在该 GPU 上需要 prefill 的未命中 token 的计算时间。
最终选择 L+M+P 最小的 GPU 发送请求。
三、三个工程配套机制
1. 事后再平衡与自动扩容
- 若最重负载 GPU 的负载超过最轻 GPU 的 Thbal 倍,则将原本要路由到重载 GPU 的请求改发到轻载 GPU。
- 若某前缀的平均排队时间在窗口 H 内翻倍,则触发自动扩容------把该前缀的 KV 复制到多个 GPU 上。
2. Prefill/Decode 均衡
这是 Preble 一个很聪明的洞察:
- 一个请求如果整个 prompt 都命中缓存,它实际上只需要执行 decode;
- 而一个 prompt 完全没命中缓存且输出很短的请求,本质上是纯 prefill 计算。
因此可以把这两类请求混合调度,在集群层面平衡 prefill 和 decode 的计算压力,而不需要物理上分离 prefill/decode GPU。
3. 优先级等待队列
本地调度器按请求的缓存命中率把等待队列分成 P 组:
- 命中率越高优先级越高;
- 但各优先级按比例分配批次名额,以此在最大化缓存复用的同时保证公平性、避免低命中率请求饿死。
四、评测结果
论文在两套环境(4×A6000、8×H100)、两个模型(Mistral-7B、Llama-3-70B)、五种工作负载上做了对比:
- 与 SGLang 相比,Preble 在平均延迟上提升 1.5× 到 14.5× ,P99 尾延迟上提升 2× 到 10×。
- 改进幅度最大的是 Tool Use、Embodied Agent、Video QA 这类 decode 比例低、共享率高的场景;
- 改进最小的是 Programming 场景,因为那个 workload 的 decode 长度最长,decode 时间本身成为瓶颈,Preble 优化不了 decode 阶段。
消融实验结论
- E2 基础算法贡献了大部分平均延迟收益;
- 再平衡 和Prefill/Decode 均衡主要贡献 P99 收益;
- 优先级队列只改善 P99,不影响均值(符合预期,它针对的是公平性)。
五、与 AIBrix 实现的对照
AIBrix 中 prefix_cache_preble.go 正是对这篇论文的工程落地,但有几处重要差异值得注意:
| 维度 | 论文 Preble | AIBrix 实现 |
|---|---|---|
| 状态范围 | 全局调度器维护集群级 Radix 树 | 单 gateway 内存,多 gateway 不共享 |
| 代价函数 | L + M + P 三项 | prefillCost + decodeCost,M(驱逐代价)未实现 |
| Exploit 门槛 | matched > remaining(50% 可动态变化) | 硬编码 0.5 阈值 |
| 负载均衡后调整 | 负载再平衡 + 自动扩容 | 无,退化为最小代价选取 |
| Prefill/Decode 均衡 | 显式混合调度 | 未实现 |
最关键的缺失是驱逐代价 M:
- 论文里这一项让 E2 在决定把请求发到一个缓存丰富但已满的 GPU 时能准确评估"我需要踢掉哪些高价值缓存";
- AIBrix 现在跳过了这项,代价估算因此偏乐观。