小肥柴的Hadoop之旅 快速实验篇(A7)干旱强度空间分布与热点分析(基于 FIPS 的郡县坐标关联)
-
- 目录
- 前言
- [0. 背景知识:A7 的计算引擎选择](#0. 背景知识:A7 的计算引擎选择)
- [1. 任务概述与目标](#1. 任务概述与目标)
- [2. 数据准备:从 USZIPS 到郡县坐标](#2. 数据准备:从 USZIPS 到郡县坐标)
-
- [2.1 uszips.csv 预处理](#2.1 uszips.csv 预处理)
- [2.2 上传 HDFS 并建 Hive 表](#2.2 上传 HDFS 并建 Hive 表)
- [2.3 讨论:为何不用 Combiner 和 Secondary Sort ?](#2.3 讨论:为何不用 Combiner 和 Secondary Sort ?)
- [3. 构建站点元数据与空间属性表](#3. 构建站点元数据与空间属性表)
-
- [3.1 确认 FIPS 列位置](#3.1 确认 FIPS 列位置)
- [3.2 创建站点元数据表](#3.2 创建站点元数据表)
- [3.3 整理 A6 统计表](#3.3 整理 A6 统计表)
- [3.4 生成空间属性表](#3.4 生成空间属性表)
- [3.5 覆盖率验证](#3.5 覆盖率验证)
- [4. 数据导出与可视化](#4. 数据导出与可视化)
-
- [4.1 导出 CSV](#4.1 导出 CSV)
- [4.2 Python 可视化脚本(仅供参考,这是多轮调整后的结果)](#4.2 Python 可视化脚本(仅供参考,这是多轮调整后的结果))
- [5. 可视化结果与解读](#5. 可视化结果与解读)
-
- [5.1 Figure 1:空间分布图](#5.1 Figure 1:空间分布图)
- [5.2 Figure 2:Hexbin 密度 Moran 散点图](#5.2 Figure 2:Hexbin 密度 Moran 散点图)
- [5.3 Figure 3:纬向剖面图](#5.3 Figure 3:纬向剖面图)
- [6. 可视化设计思路与统计学知识补充](#6. 可视化设计思路与统计学知识补充)
-
- [6.1 空间自相关与 Moran's I](#6.1 空间自相关与 Moran's I)
-
- [6.1.1 概念解释](#6.1.1 概念解释)
- [6.1.2 如何看图 2](#6.1.2 如何看图 2)
- [6.1.3 效应量 vs 显著性](#6.1.3 效应量 vs 显著性)
- [6.2 数据均质化如何影响可视化工具的选择](#6.2 数据均质化如何影响可视化工具的选择)
-
- [6.2.1 问题根源](#6.2.1 问题根源)
- [6.2.2 解决方案对应关系](#6.2.2 解决方案对应关系)
- [6.2.3 Hexbin 密度图原理](#6.2.3 Hexbin 密度图原理)
- [6.2.4 小提琴图原理](#6.2.4 小提琴图原理)
- [6.3 纬向剖面的解读要点](#6.3 纬向剖面的解读要点)
- [6.4 空间分析结论的方法论前提](#6.4 空间分析结论的方法论前提)
- [7 阶段总结](#7 阶段总结)
目录
前言
本文是"农业气象干旱分析"项目的第七阶段。在 A6 产出站点级年度干旱统计的基础上,我们通过美国郡县 FIPS 代码引入空间坐标,将干旱属性映射到美国地理空间,进行空间分布制图、全局空间自相关检验与纬向梯度分析 。由于原始数据未直接提供经纬度,我们选用第三方数据集 uszips.csv 完成空间化。分析结果显示,由于 A5 的站点内百分位数方法消除了站点间的绝对降水差异,干旱强度(severe_ratio)在全国范围内高度均质化,Moran's I 仅为 0.008,纬向剖面近乎平坦。这一结果并非分析失败,而是方法特性的空间显式验证,为后续实验将重心转向时间维度提供了明确信号。
0. 背景知识:A7 的计算引擎选择
A2 至 A6 各阶段以 MapReduce 为核心计算引擎,处理千万行级日数据。到 A7 时,输入已缩减为站点级统计表(约 10 万行),单机处理仅需数秒。继续使用 MapReduce 只会增加序列化与 Shuffle 开销,违背"用合适的工具做合适的事"的原则。
但不使用MapReduce并不意味着脱离 Hadoop 生态。A6 的统计结果与外部坐标数据均存储在 HDFS 上,通过 Hive 外表统一管理。可借助 Python 脚本通过 HDFS 客户端或导出 CSV 读取数据,分析结果可回写 HDFS。生产环境中,站点级空间分析通常用 Spark + GeoMesa、Hive 空间 SQL 或 Zeppelin 交互式分析。综上,A7 选择 Python,是因为在 10 万行规模下地理空间库(geopandas、cartopy)生态最成熟,开发与调参效率最高,适合探索性分析。
1. 任务概述与目标
| 项目 | 说明 |
|---|---|
| 定位 | 承接 A6 的站点级年度干旱统计,引入空间维度,完成干旱强度的地理可视化与空间模式探索 |
| 目标 | 1. 从第三方数据集 uszips.csv 中提取郡县中心经纬度 2. 通过 FIPS 代码(drought_cleaned.col_2)关联 A6 统计表,形成空间属性表 3. 绘制美国干旱强度空间分布图 4. 计算全局 Moran's I,检验空间自相关 5. 绘制纬向剖面图,观察干旱强度随纬度的变化 |
| 输入 | · A6 年度统计表(HDFS /drought/output_a6/stats-r-*) · A3 表 drought_cleaned(含 station_id 和 col_2,即 FIPS) · 外部文件 uszips.csv(含 county_fips, lat, lng) |
| 输出 | 空间属性表 a7_spatial(Hive 内表);三张可视化图表 |
| 技术栈 | Hive(外表与关联)、Python(pandas、cartopy、esda、libpysal) |
2. 数据准备:从 USZIPS 到郡县坐标
原始气象数据中每个站点记录带有 fips 字段(5 位美国郡县代码),但 A3 建表时将其命名为 col_2。我们使用第三方数据集 uszips.csv,其中包含 county_fips、lat、lng 等字段。
uszips.csv,我已上传到站内,好事的朋友可以自行查阅USA政府网站自行下载
2.1 uszips.csv 预处理
(1)列号确认,找到flips(郡县编号)和经纬度位置所在列。
bash
head -1 uszips.csv | tr ',' '\n' | cat -n确认 county_fips 在第 11 列,lat 在第 2 列,lng 在第 3 列。查询结果参考如下:
查询结果参考:
bash
hadoop@master:~$ head -1 uszips.csv | tr ',' '\n' | cat -n
1 "zip"
2 "lat"
3 "lng"
4 "city"
5 "state_id"
6 "state_name"
7 "zcta"
8 "parent_zcta"
9 "population"
10 "density"
11 "county_fips"
12 "county_name"
13 "county_weights"
14 "county_names_all"
15 "county_fips_all"
16 "imprecise"
17 "military"
18 "timezone"(2)数据清洗。
由于一个郡县下辖多个邮编,清洗时需要先去引号,再按 county_fips 对经纬度取平均值:
bash
awk -F',' '
NR > 1 {
gsub(/"/, "", $11); gsub(/"/, "", $2); gsub(/"/, "", $3)
fips = $11; lat = $2; lng = $3
if (fips != "") {
sum_lat[fips] += lat
sum_lng[fips] += lng
cnt[fips]++
}
}
END {
print "county_fips,lat,lng"
for (fips in cnt) {
printf "%s,%.6f,%.6f\n", fips, sum_lat[fips]/cnt[fips], sum_lng[fips]/cnt[fips]
}
}' uszips.csv > county_geo.csv查询结果参考:
bash
hadoop@master:~$ # 检查结果
hadoop@master:~$ wc -l county_geo.csv
3213 county_geo.csv
hadoop@master:~$ head -5 county_geo.csv
county_fips,lat,lng
36101,42.294927,-77.385807
54021,38.929346,-80.859701
36105,41.694281,-74.760682
54023,39.125211,-79.239753最后产出文件 county_geo.csv 共 3,213 行,覆盖全美所有郡县。
2.2 上传 HDFS 并建 Hive 表
(1)将 county_geo.csv 上传至HDFS
bash
hdfs dfs -mkdir -p /drought/ref
hdfs dfs -put county_geo.csv /drought/ref/(2)在Hive中创建对应外表(多少节省点内存)。
sql
CREATE EXTERNAL TABLE county_geo (
county_fips STRING,
lat DOUBLE,
lng DOUBLE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/drought/ref'
TBLPROPERTIES ("skip.header.line.count"="1");2.3 讨论:为何不用 Combiner 和 Secondary Sort ?
还是那句话:一定要具体问题具体分析,根据场景合理选择工具。
- Combiner:年度统计和事件检测均依赖全局排序,无法在 Map 端做局部聚合,Combiner 无效。
- Secondary Sort :虽然可以通过复合 Key
(station_id, date)配合自定义分区和分组器让 Reducer 按日期序接收数据,但每个站点仅 90 条记录,内存排序足够高效。保持 Key 为单一station_id可简化代码,聚焦 MR 核心模型。
3. 构建站点元数据与空间属性表
3.1 确认 FIPS 列位置
A3 的 drought_cleaned 建表语句中,第 3 列为 col_2 STRING,正是 FIPS 代码。使用如下查询验证:
sql
SELECT station_id, col_2 FROM drought_cleaned LIMIT 5;3.2 创建站点元数据表
sql
CREATE TABLE station_metadata AS
SELECT DISTINCT
station_id,
LPAD(TRIM(col_2), 5, '0') AS fips_5digit
FROM drought_cleaned;此表仅 102,430 行,后续 JOIN 时 Hive 会自动将其 broadcast 到各 map 任务。
实际执行效果参考:
sql
hive> -- 站点-FIPS映射(从 drought_cleaned.col_2 提取)
hive> CREATE TABLE station_metadata AS
> SELECT DISTINCT
> station_id,
> LPAD(TRIM(col_2), 5, '0') AS fips_5digit
> FROM drought_cleaned;
Query ID = hadoop_20260618233833_a2256692-9732-4154-a477-94849c803f06
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 6
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Cannot run job locally: Input Size (= 1291086910) is larger than hive.exec.mode.local.auto.inputbytes.max (= 134217728)
Starting Job = job_1781796574510_0003, Tracking URL = http://master:8088/proxy/application_1781796574510_0003/
Kill Command = /usr/local/hadoop/bin/mapred job -kill job_1781796574510_0003
Hadoop job information for Stage-1: number of mappers: 5; number of reducers: 6
2026-06-18 23:38:49,951 Stage-1 map = 0%, reduce = 0%
2026-06-18 23:39:00,517 Stage-1 map = 20%, reduce = 0%, Cumulative CPU 6.57 sec
2026-06-18 23:39:11,019 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 38.13 sec
2026-06-18 23:39:14,159 Stage-1 map = 100%, reduce = 17%, Cumulative CPU 41.64 sec
2026-06-18 23:39:20,408 Stage-1 map = 100%, reduce = 33%, Cumulative CPU 44.75 sec
2026-06-18 23:39:21,447 Stage-1 map = 100%, reduce = 50%, Cumulative CPU 48.14 sec
2026-06-18 23:39:22,480 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 58.72 sec
MapReduce Total cumulative CPU time: 58 seconds 720 msec
Ended Job = job_1781796574510_0003
Moving data to directory hdfs://master:9000/user/hive/warehouse/station_metadata
MapReduce Jobs Launched:
Stage-Stage-1: Map: 5 Reduce: 6 Cumulative CPU: 58.72 sec HDFS Read: 1291214073 HDFS Write: 2702789 SUCCESS
Total MapReduce CPU Time Spent: 58 seconds 720 msec
OK
Time taken: 51.541 seconds3.3 整理 A6 统计表
(1)依旧先清理目录和备份数据:
bash
hdfs dfs -mkdir -p /drought/a6_stats
hdfs dfs -cp /drought/output_a6/stats-r-* /drought/a6_stats/(2)建表:
sql
CREATE EXTERNAL TABLE a6_stats (
station_id STRING, year INT,
nodrought INT, mild INT, moderate INT, severe INT, extreme INT
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE LOCATION '/drought/a6_stats';(3)实际执行效果参考:
sql
hive> CREATE EXTERNAL TABLE a6_stats (
> station_id STRING,
> year INT,
> nodrought INT,
> mild INT,
> moderate INT,
> severe INT,
> extreme INT
> )
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> STORED AS TEXTFILE
> LOCATION '/drought/a6_stats';
OK
Time taken: 0.12 seconds
hive> SELECT * FROM a6_stats LIMIT 3;
OK
-1000693984452388696 2019 53 10 9 9 9
-1000921274166666218 2016 54 9 9 9 9
-1001002724853868934 2018 54 9 9 9 9
Time taken: 0.336 seconds, Fetched: 3 row(s)3.4 生成空间属性表
sql
SET hive.auto.convert.join=true;
CREATE TABLE a7_spatial AS
SELECT
a.station_id, a.year,
g.lat AS latitude, g.lng AS longitude,
a.nodrought + a.mild + a.moderate + a.severe + a.extreme AS total_days,
(a.severe + a.extreme) * 1.0 /
(a.nodrought + a.mild + a.moderate + a.severe + a.extreme) AS severe_ratio
FROM a6_stats a
JOIN station_metadata m ON a.station_id = m.station_id
JOIN county_geo g ON m.fips_5digit = g.county_fips;3.5 覆盖率验证
执行下面的查询语句:
sql
SELECT
COUNT(DISTINCT a.station_id) AS total,
COUNT(DISTINCT CASE WHEN g.lat IS NOT NULL THEN a.station_id END) AS matched,
ROUND(COUNT(DISTINCT CASE WHEN g.lat IS NOT NULL THEN a.station_id END) * 100.0 /
COUNT(DISTINCT a.station_id), 1) AS match_pct
FROM a6_stats a
JOIN station_metadata m ON a.station_id = m.station_id
LEFT JOIN county_geo g ON m.fips_5digit = g.county_fips;实际执行效果参考:
sql
hive> SELECT
> COUNT(DISTINCT a.station_id) AS total_stations,
> COUNT(DISTINCT CASE WHEN g.lat IS NOT NULL THEN a.station_id END) AS matched_stations,
> ROUND(COUNT(DISTINCT CASE WHEN g.lat IS NOT NULL THEN a.station_id END) * 100.0 /
> COUNT(DISTINCT a.station_id), 1) AS match_pct
> FROM a6_stats a
> JOIN station_metadata m ON a.station_id = m.station_id
> LEFT JOIN county_geo g ON m.fips_5digit = g.county_fips;
No Stats for default@a6_stats, Columns: station_id
No Stats for default@station_metadata, Columns: station_id, fips_5digit
No Stats for default@county_geo, Columns: county_fips, lat
Query ID = hadoop_20260618234305_d2ce6047-fde0-4f02-90c4-183fe2827e76
Total jobs = 1
SLF4J: Found binding in [jar:file:/usr/local/hive/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2026-06-18 23:43:25 Dump the side-table for tag: 1 with group count: 102430 into file: file:/tmp/hadoop/2f7c1295-17d1-4b80-bbb8-0bf0273fdadd/hive_2026-06-18_23-43-05_817_7743319039749025342-1/-local-10006/HashTable-Stage-3/MapJoin-mapfile21--.hashtable2026-06-18 23:43:25 Uploaded 1 File to: file:/tmp/hadoop/2f7c1295-17d1-4b80-bbb8-0bf0273fdadd/hive_2026-06-18_23-43-05_817_7743319039749025342-1/-local-10006/HashTable-Stage-3/MapJoin-mapfile21--.hashtable (3847955 bytes)2026-06-18 23:43:25 Dump the side-table for tag: 1 with group count: 3212 into file: file:/tmp/hadoop/2f7c1295-17d1-4b80-bbb8-0bf0273fdadd/hive_2026-06-18_23-43-05_817_7743319039749025342-1/-local-10006/HashTable-Stage-3/MapJoin-mapfile31--.hashtable
2026-06-18 23:43:25 Uploaded 1 File to: file:/tmp/hadoop/2f7c1295-17d1-4b80-bbb8-0bf0273fdadd/hive_2026-06-18_23-43-05_817_7743319039749025342-1/-local-10006/HashTable-Stage-3/MapJoin-mapfile31--.hashtable (103547 bytes)
2026-06-18 23:43:25 End of local task; Time Taken: 4.034 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Cannot run job locally: Number of Input Files (= 6) is larger than hive.exec.mode.local.auto.input.files.max(= 4)
Starting Job = job_1781796574510_0005, Tracking URL = http://master:8088/proxy/application_1781796574510_0005/
Kill Command = /usr/local/hadoop/bin/mapred job -kill job_1781796574510_0005
Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 1
2026-06-18 23:43:39,133 Stage-3 map = 0%, reduce = 0%
2026-06-18 23:43:51,765 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 11.61 sec
2026-06-18 23:44:03,189 Stage-3 map = 100%, reduce = 100%, Cumulative CPU 17.78 sec
MapReduce Total cumulative CPU time: 17 seconds 780 msec
Ended Job = job_1781796574510_0005
MapReduce Jobs Launched:
Stage-Stage-3: Map: 1 Reduce: 1 Cumulative CPU: 17.78 sec HDFS Read: 2719464 HDFS Write: 118 SUCCESS
Total MapReduce CPU Time Spent: 17 seconds 780 msec
OK
102430 101491 99.1
Time taken: 59.58 seconds, Fetched: 1 row(s)统计结果如下:
| 指标 | 数值 |
|---|---|
| 全量站点 | 102,430 |
| 匹配成功 | 101,491 |
| 匹配率 | 99.1% |
仅 939 个站点(0.9%)因 FIPS 在 county_geo 中未收录而被丢弃,主要为海外领地和特殊行政区划代码,对全国尺度分析无实质影响。
4. 数据导出与可视化
4.1 导出 CSV
bash
hive -e "SELECT * FROM a7_spatial" | sed '1i\station_id\tyear\tlatitude\tlongitude\ttotal_days\tsevere_ratio' > a7_spatial.csv注意:Hive 默认输出为制表符分隔,Python 读取时需指定 sep='\t';且一定要检测 Hive 导出的 CSV 没有表头!⇒ 需要根据实际情况做修正!
4.2 Python 可视化脚本(仅供参考,这是多轮调整后的结果)
针对数据高度均质的特点,采用 hexbin 密度散点图 替代普通散点(避免 10 万点完全重叠),用 小提琴图 替代箱线图(避免箱体因数据集中而被压成一条线)。
【注】可视化过程比较曲折,希望大家联动多个AI一起设计、解读和检查可视化效果是否OK。
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
A7 干旱强度空间分布与热点分析 最终版
"""
import os, traceback
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import cartopy.feature as cfeature
from esda.moran import Moran
from libpysal.weights import KNN
from matplotlib import cm
INPUT_FILE = "a7_spatial.csv"
OUTPUT_DIR = "a7_figures_final"
STAT_DIR = os.path.join(OUTPUT_DIR, "stats")
os.makedirs(OUTPUT_DIR, exist_ok=True)
os.makedirs(STAT_DIR, exist_ok=True)
RNG = np.random.default_rng(42)
plt.rcParams.update({
'font.sans-serif': ['SimHei', 'Arial Unicode MS'],
'axes.unicode_minus': False,
'figure.dpi': 150,
'axes.titlesize': 12,
'axes.labelsize': 10
})
def load_and_preprocess(path):
"""加载并去重站点数据"""
df = pd.read_csv(path, sep='\t', dtype={'station_id': str})
df = df[(df['latitude'] >= 18) & (df['latitude'] <= 50) &
(df['longitude'] >= -130) & (df['longitude'] <= -65)]
df = df.dropna(subset=['severe_ratio', 'latitude', 'longitude'])
df_station = df.groupby(
['station_id', 'latitude', 'longitude'], as_index=False
).agg({'severe_ratio': 'mean', 'year': 'count'}).rename(
columns={'year': 'sample_years'})
print(f"去重后站点数: {len(df_station)}, "
f"均值={df_station['severe_ratio'].mean():.4f}, "
f"标准差={df_station['severe_ratio'].std():.4f}")
df_station.to_csv(os.path.join(STAT_DIR, "station_stats.csv"), index=False)
return df, df_station
def fig1_spatial(df_station):
"""空间分布散点图"""
jitter_lat = df_station['latitude'] + RNG.uniform(-0.02, 0.02, len(df_station))
jitter_lon = df_station['longitude'] + RNG.uniform(-0.02, 0.02, len(df_station))
vmin, vmax = 0.19, 0.21
cmap = cm.get_cmap('YlOrRd')
fig, ax = plt.subplots(figsize=(14, 8),
subplot_kw={'projection': ccrs.PlateCarree()})
ax.set_extent([-130, -65, 22, 52])
ax.add_feature(cfeature.LAND, facecolor='whitesmoke', alpha=0.5)
ax.add_feature(cfeature.OCEAN, facecolor='lightsteelblue', alpha=0.3)
ax.add_feature(cfeature.COASTLINE, linewidth=0.5)
ax.add_feature(cfeature.BORDERS, linewidth=0.3, linestyle='--')
ax.add_feature(cfeature.STATES, linewidth=0.2, alpha=0.4)
ax.gridlines(draw_labels=True, linewidth=0.3, alpha=0.6, linestyle='--')
sc = ax.scatter(jitter_lon, jitter_lat, c=df_station['severe_ratio'],
cmap=cmap, s=3, alpha=0.6, edgecolors='none',
vmin=vmin, vmax=vmax, transform=ccrs.PlateCarree())
ax.set_title("Figure 1: Spatial Distribution of Severe+ Drought Ratio\n"
"(Meteorological Stations, jittered)")
cbar = plt.colorbar(sc, ax=ax, shrink=0.8, pad=0.02)
cbar.set_label("Severe+ Drought Ratio")
cbar.set_ticks(np.arange(0.19, 0.211, 0.01))
plt.tight_layout()
plt.savefig(os.path.join(OUTPUT_DIR, "fig1_spatial.png"), bbox_inches='tight')
plt.close()
print("图1 已保存")
def fig2_moran_hexbin(df_station, w):
"""Hexbin 密度 Moran 散点图"""
moran = Moran(df_station['severe_ratio'].values, w)
print(f"Moran's I = {moran.I:.4f}, p = {moran.p_sim:.4f}, z = {moran.z_sim:.4f}")
pd.DataFrame({
"name": ["Moran_I", "p_value", "z_score"],
"val": [moran.I, moran.p_sim, moran.z_sim]
}).to_csv(os.path.join(STAT_DIR, "moran_stat.csv"), index=False)
y = df_station['severe_ratio'].values
y_std = (y - y.mean()) / y.std()
y_lag_std = w.sparse.dot(y_std)
fig, ax = plt.subplots(figsize=(8, 8))
hb = ax.hexbin(y_std, y_lag_std, gridsize=70, cmap='Blues',
mincnt=1, alpha=0.8)
ax.axhline(0, c='gray', lw=0.8, ls='--')
ax.axvline(0, c='gray', lw=0.8)
slope, intercept = np.polyfit(y_std, y_lag_std, 1)
x_fit = np.linspace(-0.4, 0.4, 100)
ax.plot(x_fit, slope * x_fit, c='#d62728', lw=1.5,
label=f"I = {moran.I:.4f}, p = {moran.p_sim:.4f}")
ax.set_xlim(-0.4, 0.4); ax.set_ylim(-0.4, 0.4)
# 象限标注
for x, y_pos, label in [(0.35, 0.35, "HH"), (-0.35, 0.35, "HL"),
(-0.35, -0.35, "LL"), (0.35, -0.35, "LH")]:
ax.text(x, y_pos, label, fontsize=9, ha='center', va='center')
ax.set_xlabel("Standardized severe_ratio")
ax.set_ylabel("Spatial Lag")
ax.set_title("Figure 2: Moran Scatterplot (Hexbin Density)")
ax.legend(loc='upper right', frameon=False)
plt.colorbar(hb, ax=ax, shrink=0.7, label="Point Count per Hexagon")
ax.grid(alpha=0.3, ls='--')
plt.tight_layout()
plt.savefig(os.path.join(OUTPUT_DIR, "fig2_moran_hexbin.png"), bbox_inches='tight')
plt.close()
print("图2 已保存")
return moran
def fig3_latitudinal(df):
"""纬向剖面图(均值误差棒 + 小提琴)"""
bins = np.arange(24, 50, 2)
labels = [f"{b}°--{b+2}°" for b in bins[:-1]]
df['lat_band'] = pd.cut(df['latitude'], bins=bins, labels=labels,
include_lowest=True)
lat_stats = df.groupby('lat_band', observed=True)['severe_ratio'].agg(
mean=np.mean, std=np.std, count='count').reset_index()
lat_stats.to_csv(os.path.join(STAT_DIR, "lat_band_stat.csv"), index=False)
global_mean = df['severe_ratio'].mean()
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 7))
# 左图:均值 + 误差棒
ax1.errorbar(lat_stats['lat_band'], lat_stats['mean'], yerr=lat_stats['std'],
fmt='-', c='#8c0000', lw=2, capsize=3)
ax1.axhline(global_mean, c='gray', ls='--',
label=f"Global Mean = {global_mean:.4f}")
ax1.set_ylim(0.2000, 0.2012)
ax1.set_xlabel("Latitude Band"); ax1.set_ylabel("Mean Severe+ Ratio")
ax1.set_title("Figure 3-1: Latitudinal Mean Trend")
ax1.legend(frameon=False); ax1.grid(axis='y', alpha=0.3)
plt.setp(ax1.get_xticklabels(), rotation=45, ha='right', fontsize=9)
# 右图:小提琴 + 离群点
band_data = [df[df['lat_band'] == b]['severe_ratio'].values for b in labels]
positions = range(len(labels))
parts = ax2.violinplot(band_data, positions=positions,
showmedians=True, widths=0.7)
for pc in parts['bodies']:
pc.set_facecolor('#ff7f0e'); pc.set_alpha(0.5)
parts['cmedians'].set_color('black'); parts['cmedians'].set_linewidth(1.2)
# 标注离群点
low, high = 0.198, 0.203
for idx, band in enumerate(labels):
vals = df[df['lat_band'] == band]['severe_ratio']
outs = vals[(vals < low) | (vals > high)]
ax2.scatter([idx] * len(outs), outs, c='darkred', s=5, zorder=5)
ax2.set_xticks(positions)
ax2.set_xticklabels(labels, rotation=45, ha='right', fontsize=9)
ax2.set_ylim(0.198, 0.203)
ax2.axhline(global_mean, c='gray', ls='--')
ax2.set_xlabel("Latitude Band"); ax2.set_ylabel("Severe+ Ratio")
ax2.set_title("Figure 3-2: Distribution (Violin + Outliers)")
ax2.grid(axis='y', alpha=0.3)
plt.tight_layout()
plt.savefig(os.path.join(OUTPUT_DIR, "fig3_latitudinal.png"), bbox_inches='tight')
plt.close()
print("图3 已保存")
return lat_stats
if __name__ == "__main__":
df_full, df_station = load_and_preprocess(INPUT_FILE)
coords = np.column_stack([df_station['longitude'], df_station['latitude']])
w = KNN.from_array(coords, k=10)
w.transform = 'r'
fig1_spatial(df_station)
moran_res = fig2_moran_hexbin(df_station, w)
lat_res = fig3_latitudinal(df_full)
print("\n===== 分析摘要 =====")
sig = "p < 0.05(但效应量极小,无实际意义)" \
if moran_res.p_sim < 0.05 else "不显著"
print(f"Moran's I = {moran_res.I:.4f} ({sig})")
print(f"纬度均值最大差值: {lat_res['mean'].max() - lat_res['mean'].min():.6f}")
print(f"输出目录: {OUTPUT_DIR}/")5. 可视化结果与解读
数据背景 :severe_ratio 为 90 天观测期内重旱+特旱天数占比,全局均值 0.2008,标准差仅 0.003,99% 的站点数值集中在 0.19--0.21 区间。
5.1 Figure 1:空间分布图
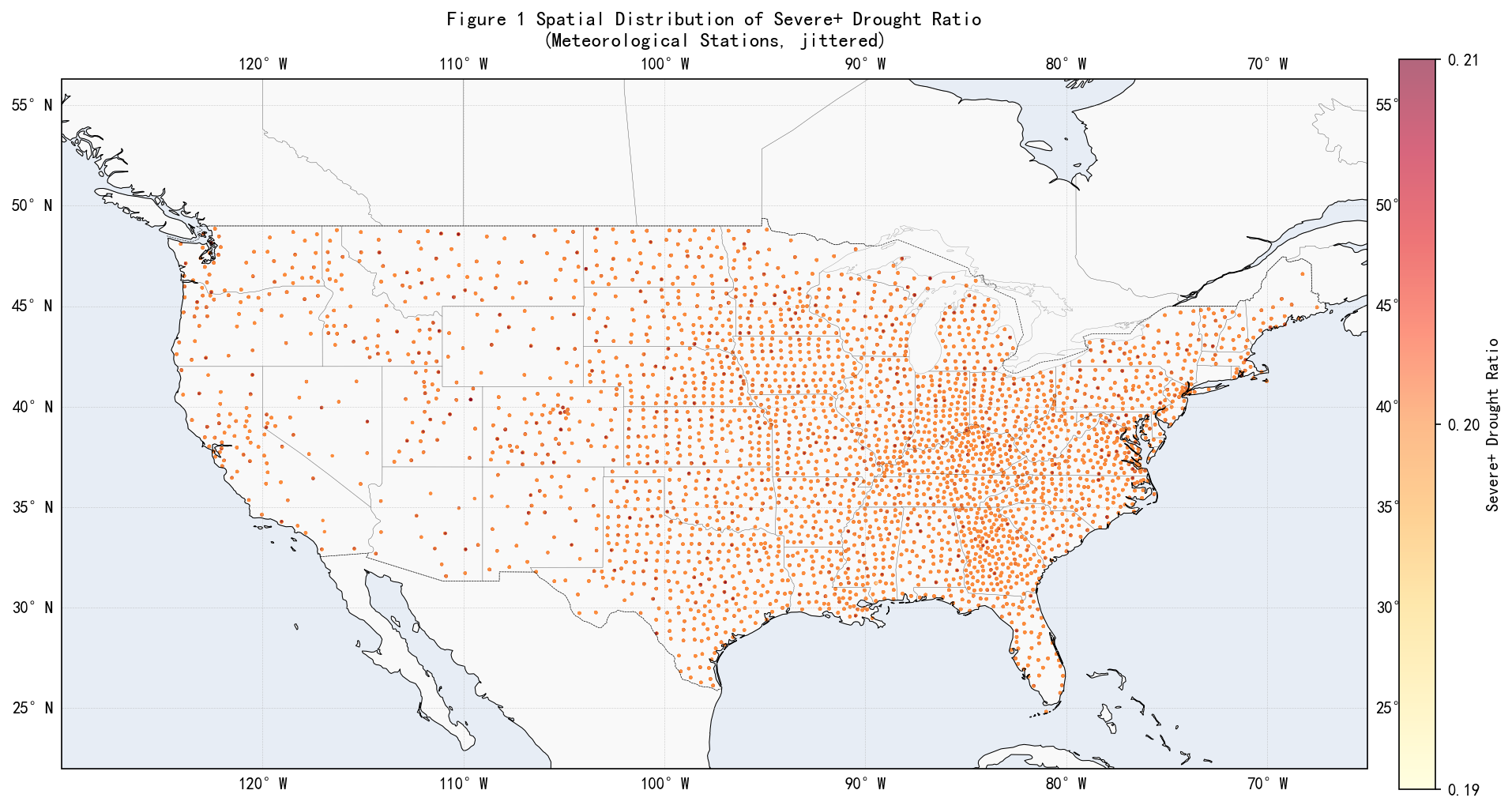
上图以美国州界和海岸线为底图,每个点代表一个气象站点(经纬度加轻微抖动以避免重叠),颜色映射严重干旱占比。
- 站点分布:东部和中部平原站点密集,西部落基山区和沙漠地带稀疏------这仅反映气象观测网络布设密度,与干旱程度无关。
- 干旱比值:全国范围内绝大多数站点呈现均一的橙色(约 0.20),仅极少数站点略偏浅黄(< 0.195)或深红(> 0.205),不存在大面积连片的高值或低值区域。
- 结论:从西海岸到东海岸、从佛罗里达到五大湖,重度干旱占比不存在显著的地理分异。地形、海陆区位不会系统性改变该指标,全域数值高度均衡。
5.2 Figure 2:Hexbin 密度 Moran 散点图
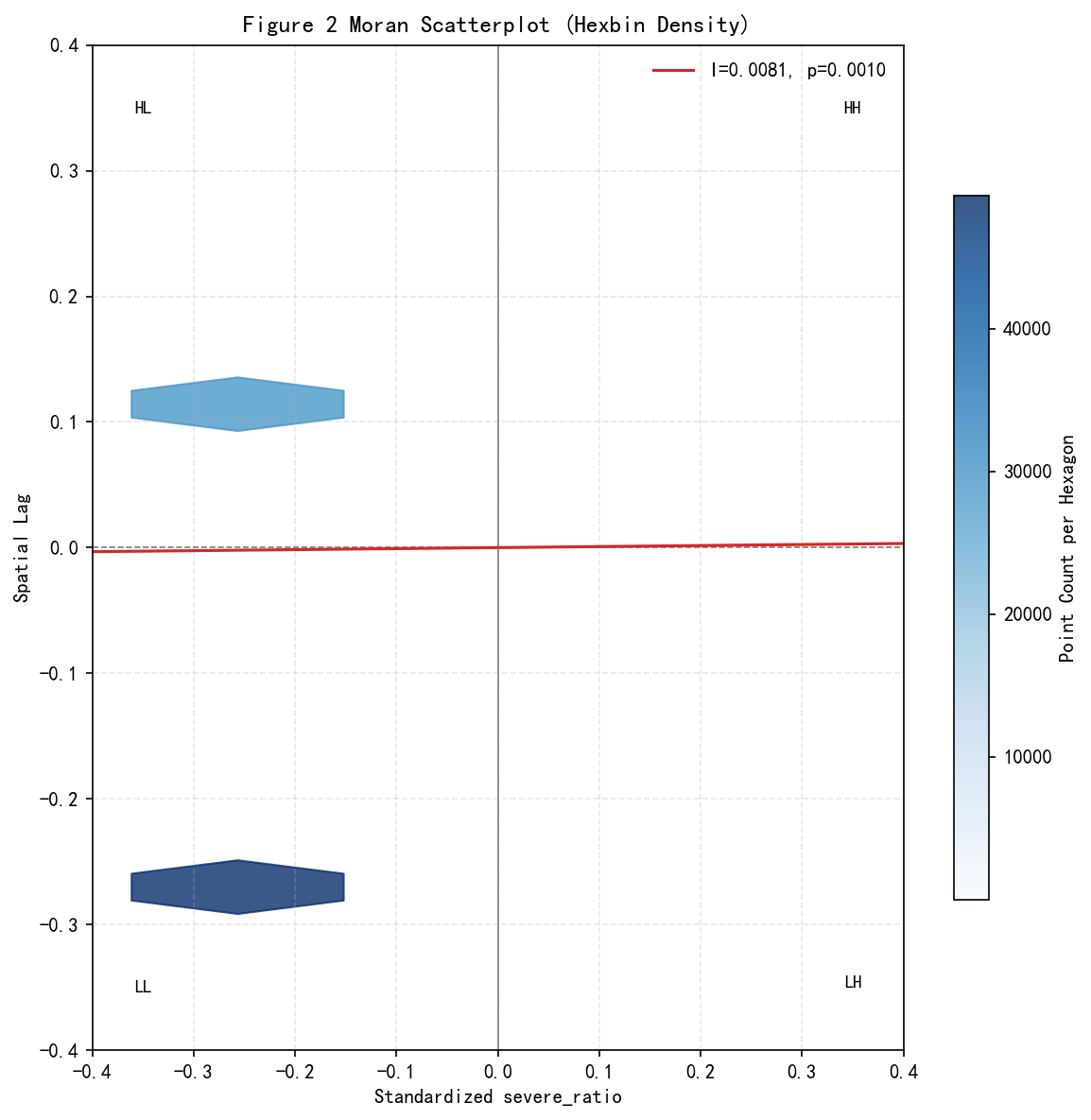
横轴为标准化后的站点自身干旱比值,纵轴为邻近站点的空间滞后值,六边形颜色深浅代表该格子内站点数量。
- 象限分布:高密度六边形集中在左上(HL)和左下(LL)两个象限,说明绝大多数站点自身干旱比值略低于全局均值。右上(HH)和右下(LH)象限几乎无高密度格子,即不存在连片高干旱站点集群。
- Moran's I 解读 :I = 0.0081,数值趋近于零。虽然 p = 0.001 在形式上达到显著性阈值,但这是因为样本量巨大(10 万站点),任何微弱效应都会被标记为"统计显著"。真正的信息在于效应量本身------0.0081 意味着变量间几乎无线性空间关联,拟合红线与 y = 0 基准线几乎重合。
- 结论:severe_ratio 在空间上近乎随机分布,不存在有实际意义的集聚模式。不存在大范围持续干旱连片热点,也不存在连片低值区。
5.3 Figure 3:纬向剖面图
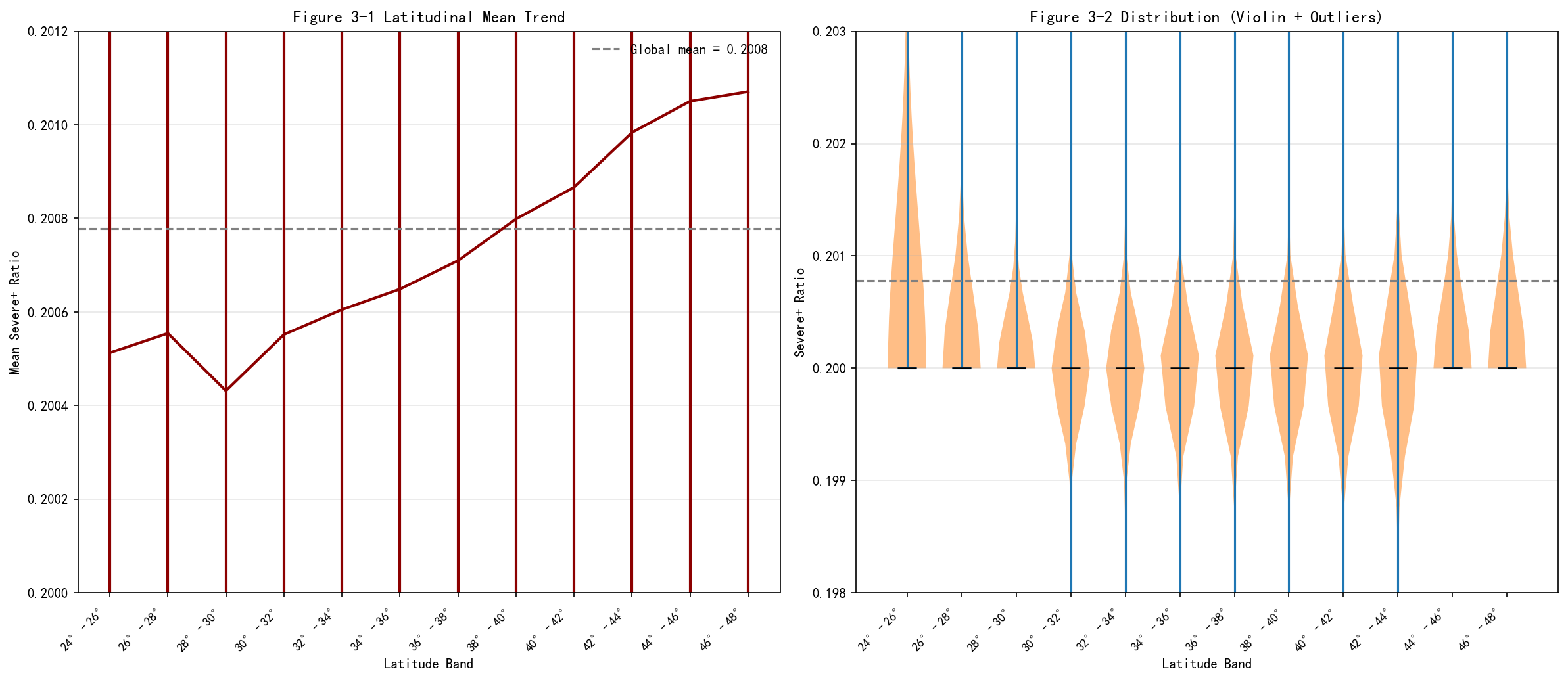
左图为各纬度带(2°间隔)的均值误差棒,y 轴限定 0.2000--0.2012 以忠实展示微小波动;右图为小提琴分布图加离群点标注。
- 纬度趋势:从南部 24°N 到北部 48°N,均值从约 0.2004 小幅上升至 0.2011,全序列最大差值仅 0.0007。这一"北高南低"的梯度在数值上完全可忽略。
- 分布特征:各纬度带小提琴主体极窄,中位数稳定在 0.200 附近,数据高度收敛。南部低纬度带小提琴向上延伸略长,即存在更多偏高离群站点;中高纬度带则向下延伸,出现少量偏低离群站点。
- 结论:无论南北,绝大多数站点干旱占比统一稳定在 0.20,仅存在极少量异常站点。纬度不是驱动干旱占比分化的关键因子。
6. 可视化设计思路与统计学知识补充
看到上面的图,初次接触的朋友大概率会追问:
- Q1 为什么要这样画图?
- Q2 如何正确解读图中的统计量?
6.1 空间自相关与 Moran's I
6.1.1 概念解释
空间自相关衡量的是"地理位置相近的观测点,其属性值是否也相近"。如果高值站点周围也是高值(高-高集聚),或低值周围也是低值(低-低集聚),则存在正空间自相关 ;如果高值被低值包围(高-低交错),则为负空间自相关 ;如果站点值与其邻域值没有系统性关系,则为空间随机分布。
Moran's I 是衡量全局空间自相关最常用的指标,取值范围约在 -1, 1:
- I > 0:正空间自相关(相似值趋于集聚)
- I ≈ 0:无空间自相关(随机分布)
- I < 0:负空间自相关(相异值趋于集聚)
6.1.2 如何看图 2
Moran 散点图的横轴是标准化后的站点自身值,纵轴是邻近站点的加权平均值(空间滞后)。四个象限的涵义:
| 象限 | 含义 | 通俗解释 |
|---|---|---|
| 右上(HH) | 自身高 + 邻域高 | 干旱热点连片区 |
| 左下(LL) | 自身低 + 邻域低 | 干旱冷点连片区 |
| 左上(HL) | 自身高 + 邻域低 | 一座干旱"孤岛" |
| 右下(LH) | 自身低 + 邻域高 | 一片湿润"孤岛" |
红色拟合线的斜率即为 Moran's I。若 I 接近 0,拟合线近似水平,说明邻域值不随自身值变化。
6.1.3 效应量 vs 显著性
本次 Moran's I = 0.0081,p = 0.001。如果机械套用"p < 0.05 即显著"的规则,似乎应得出"存在显著空间自相关"的结论。但这里有一个统计分析中的重要区分:
- p 值(显著性)反映的是"观测到的模式由随机过程产生的概率"。样本量越大,即使微弱的模式也会变得"统计显著"。
- 效应量(effect size)反映的是"模式本身的强度"。Moran's I 本身就是效应量------0.0081 意味着空间自相关的强度极弱。
本数据有 10 万站点,样本量巨大,任何非零的 I 值几乎都会被检测为"显著"。正确的解读是:Moran's I 仅为 0.008,数值上几乎为零,表明 severe_ratio 在空间上呈近似随机分布,不存在有实际意义的地理集聚。在报告中应强调效应量而非显著性。
6.2 数据均质化如何影响可视化工具的选择
6.2.1 问题根源
A5 采用的站点内百分位数方法将每个站点的干旱强度标准化为相对排名。这意味着:
- 每个站点 90 天观测中,必然有约 60% 为"无旱",40% 为不同程度的干旱
- 重旱+特旱的理论占比约为 20%
- 绝大多数站点的 severe_ratio 集中在 0.20 附近,标准差仅 0.003
这种高度集中的分布给可视化带来了两个典型难题:
- (1)点重叠:在散点图中,10 万个几乎相同的值会完全叠在一起,形成无法辨识的黑色斑块。
- (2)箱线图失效:箱线图通过四分位数来展示分布,当数据高度集中时,四分位数几乎相等,箱体被压缩成一条线,完全失去展示分布形状的能力。
6.2.2 解决方案对应关系
| 问题 | 常规方法 | 失效原因 | A7 采用的优化 |
|---|---|---|---|
| 点重叠 | 普通散点图 | 10 万点叠在原点附近,无法区分密度 | Hexbin 六边形密度图:将画布划分为小六边形格子,统计每格内点数,用颜色深浅表示密度 |
| 箱线图失效 | 箱线图 | 四分位数重合,箱体压扁为线 | 小提琴图:用核密度估计展示整个分布的形状,即使数据集中也能通过"胖瘦"看出分布密度差异 |
6.2.3 Hexbin 密度图原理
将绘图区域划分为众多六边形小格子(gridsize=70 意味着每个方向 70 个格子),统计落入每个格子的数据点数量,用颜色深浅表示密度。在原点附近的格子可能包含数万个点(深蓝),而边缘的格子只有零星几个点(浅蓝或白色)。这样读者一眼就能看出数据的集中区域和离散程度,不会被完全重叠的点遮蔽。
6.2.4 小提琴图原理
小提琴图在每个类别位置画一个对称的"小提琴"形状,其宽度表示该值附近数据的密度------越宽的地方样本越多,越窄的地方样本越少。内部通常标注中位数(黑色横线)和四分位数范围。与箱线图相比,小提琴图即使面对高度集中的数据,也能通过"细长"或"宽扁"的轮廓展示分布形态,不会出现"箱体压扁"的失效问题。
6.3 纬向剖面的解读要点
纬向剖面图(图 3)的核心目的是检查"干旱强度是否随纬度变化"。左图展示各纬度带的均值及其标准差,右图展示各带内数据的完整分布。
- 为什么 y 轴范围如此窄?
左图 y 轴设定为 0.2000--0.2012,总跨度仅 0.0012,相当于数据均值的 0.6%。如果使用更宽的 y 轴(如 0.19--0.21),曲线将几乎压成一条水平线,虽然"诚实"但无法展示任何细节。将 y 轴收紧是为了放大微小的纬度差异,同时必须在图标题或正文中明确标注实际波动幅度(本次为 0.0007),避免读者将放大后的视觉效果误认为存在显著趋势。
这是一种数据可视化中的常见权衡:当数据的实际变化量远小于均值时,需要在"忠实展示绝对水平"和"揭示微小结构"之间取得平衡。本次选择后者,但辅以明确的数据标注来避免误导。
6.4 空间分析结论的方法论前提
上述三张图表共同指向一个核心发现:全美重度干旱占比高度均质,空间分布近乎随机,纬度梯度可忽略 。但在引用这一结论时必须注明方法论前提------A5 采用的是站点内降水百分位数方法。
百分位数标准化将每个站点的干旱强度拉到了相同的相对尺度上(每个站点 60% 的观测日为无旱,40% 为不同程度的干旱)。这意味着站点之间失去了绝对降水量的可比性:年降水 200mm 的干旱区站点和年降水 2000mm 的湿润区站点,在百分位数方法下可能被赋予完全相同的 severe_ratio = 0.20。A7 的空间分析正是对这一方法特性的空间验证------全国范围内的"均质化"并非自然气候特征,而是标准化方法的直接结果。
这一认知直接影响后续实验设计:既然空间差异微弱,A8 应将重点放在时间维度的趋势检测上(如各站点 severe_ratio 的年际变化),而非试图寻找干旱空间热点。
7 阶段总结
- A7 成功将 A6 的站点级干旱统计定位到美国郡县地理空间。通过清洗外部
uszips.csv数据集并在 Hive 中构建轻量级元数据表,我们在不修改任何 MapReduce 作业的前提下高效完成了空间化。整个过程仍在 Hadoop 生态内运转,体现了"重计算用 MR、轻关联用 Hive、探索用 Python"的协同模式。 - 可视化阶段经历了三次迭代:最初的普通散点和箱线图因数据高度均质而无法有效展示信息;第二阶段调整了坐标轴和点参数,但仍存在点重叠和箱体压扁问题;最终采用 hexbin 密度散点图和小提琴图,解决了海量均质数据的可视化难点。这一迭代过程本身也是宝贵的经验------当数据极度收敛时,常规的可视化手段可能失效,需要选用能展示密度和微弱差异的专业图表。
- 分析结果确认了 A5 站点内百分位数方法的空间效应:干旱强度在全国范围内高度均一,空间自相关极弱,纬向梯度近乎消失。这一结论并非失败,而是对方法特性的精准诊断。它直接影响了后续实验设计:既然空间差异微不足道,A8 应将重点放在时间维度的趋势检测上。
下一步:A8 将回到时间维度,对 A6 的年度统计表进行 Mann-Kendall 趋势检验和 Sen's Slope 估计,识别干旱强度显著变化的站点,为归因分析提供候选对象。A7 产出的空间属性表可作为辅助,检查趋势站点是否存在空间聚集,但 A7 已经提示这种聚集可能并不存在。