工业时序数据的长期运行挑战:写入、索引、冷热、扩展四道关
在工业、电力、交通、城市物联等场景,时序数据的压力往往不是第一天就显现。系统刚上线时,接入点位少、留存短、查询简单,多数系统都能平稳运行。但随着设备持续接入、采样频率提升、历史数据沉淀,原本可控的数据流会逐渐演变为难以收拾的工程问题。
这正是时序场景与普通业务系统的根本差异:普通业务数据来自单次明确动作(交易、订单、审批),而时序数据是设备状态的持续上报,规模随采集点位线性乃至指数级增长。电表遥测、风机参数、产线振动、车辆轨迹......只要设备运转,数据就不会停。因此,时序数据库真正面对的不是某一次峰值写入,而是高频采集、长期留存、持续查询三者同时存在的复合压力。
四个会随时间叠加的问题
系统运行一段时间后,以下四个问题会逐步浮现,最终压垮很多看似"高性能"的时序方案:
写入压力 设备数量和采样频率同时增长后,系统要持续承接高并发写入。写入链路不只是插入数据,还涉及内存管理、WAL 日志、磁盘 I/O、索引维护等一整套动作。点位规模上来后,单节点能力很容易被持续压住,吞吐量曲线开始下滑。
索引膨胀 时序数据看似只是"时间戳 + 数值",但真实查询通常带设备 ID、指标类型、区域、业务标签等过滤条件。随着历史数据增长,B-Tree 索引规模会急剧膨胀。一旦索引无法驻留内存,系统就不得不依赖磁盘随机 I/O,写入和查询都受影响。
冷热混杂 工业现场既要看最新状态,也要查历史趋势------最近几分钟的数据用于告警,过去几天的用于波动分析,过去几年的用于故障追溯和模型训练。如果所有数据以同一方式存储和管理,实时业务和历史分析会互相抢资源。
扩展与运维 工业系统往往要长期运行。后续继续加设备、提采样频率、延长留存周期是常态。如果每次扩容都要停机迁移,或者只能靠不断升级单机硬件来撑,系统越往后越被动。
针对这四个问题的工程解法
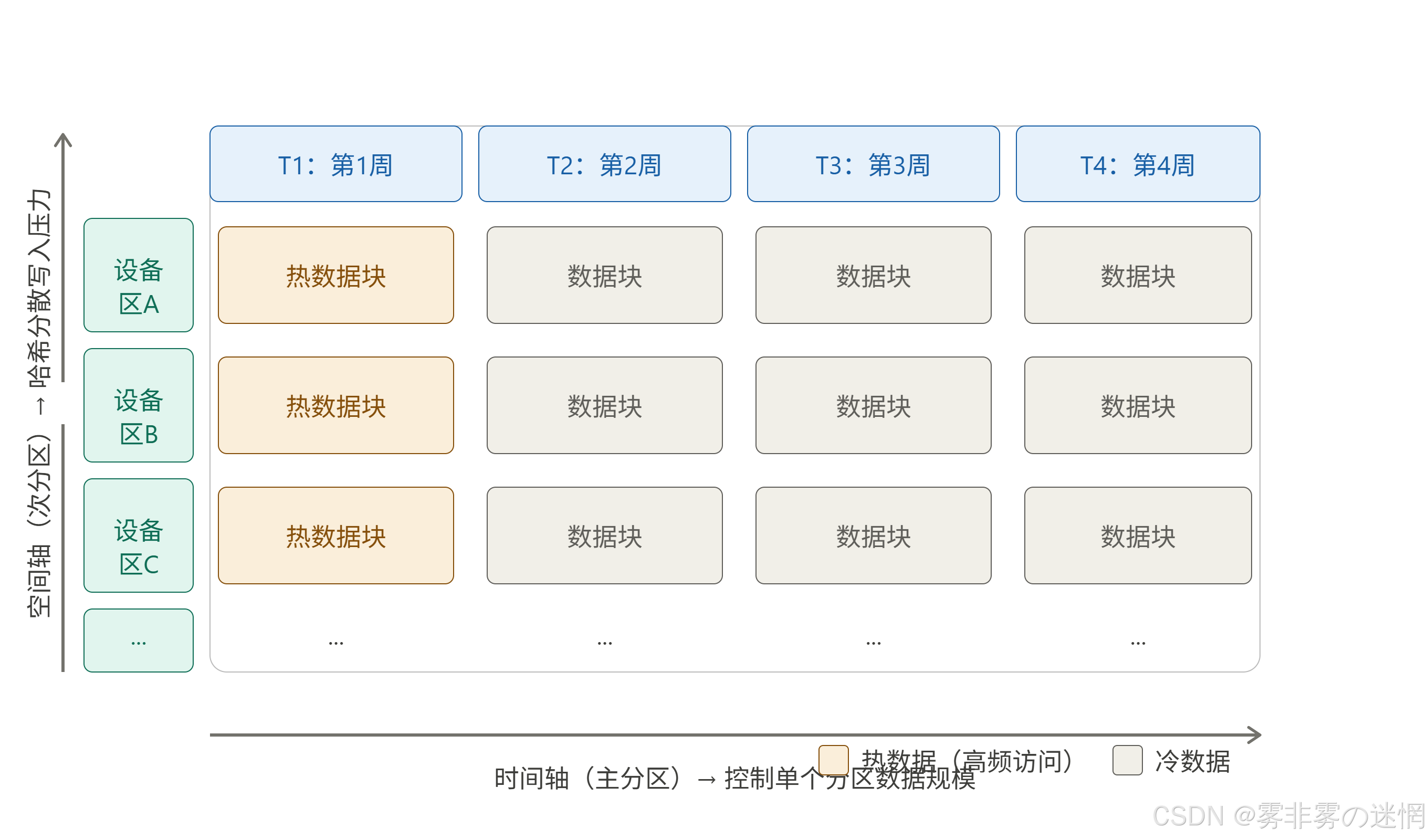
数据组织:二维分区
针对写入压力和索引膨胀,一种思路是在数据块的组织方式上做文章------时间和空间两个维度同时分区。
时间轴作为主分区,控制单个分区内的数据块规模,避免热数据范围无限扩张;空间轴(通常是设备 ID 或标签的哈希值)作为次分区,将高并发写入均匀分散到各个数据节点,减少单节点集中承压的风险。
两个维度叠加后,数据在逻辑上形成一个矩阵:
查询时,基于时间范围可以精确定位到少数几个分区块,不需要全表扫描;基于设备 ID 可以直接路由到对应节点,跳过无关数据。这两种剪枝同时生效,索引需要覆盖的范围就大幅收窄了。
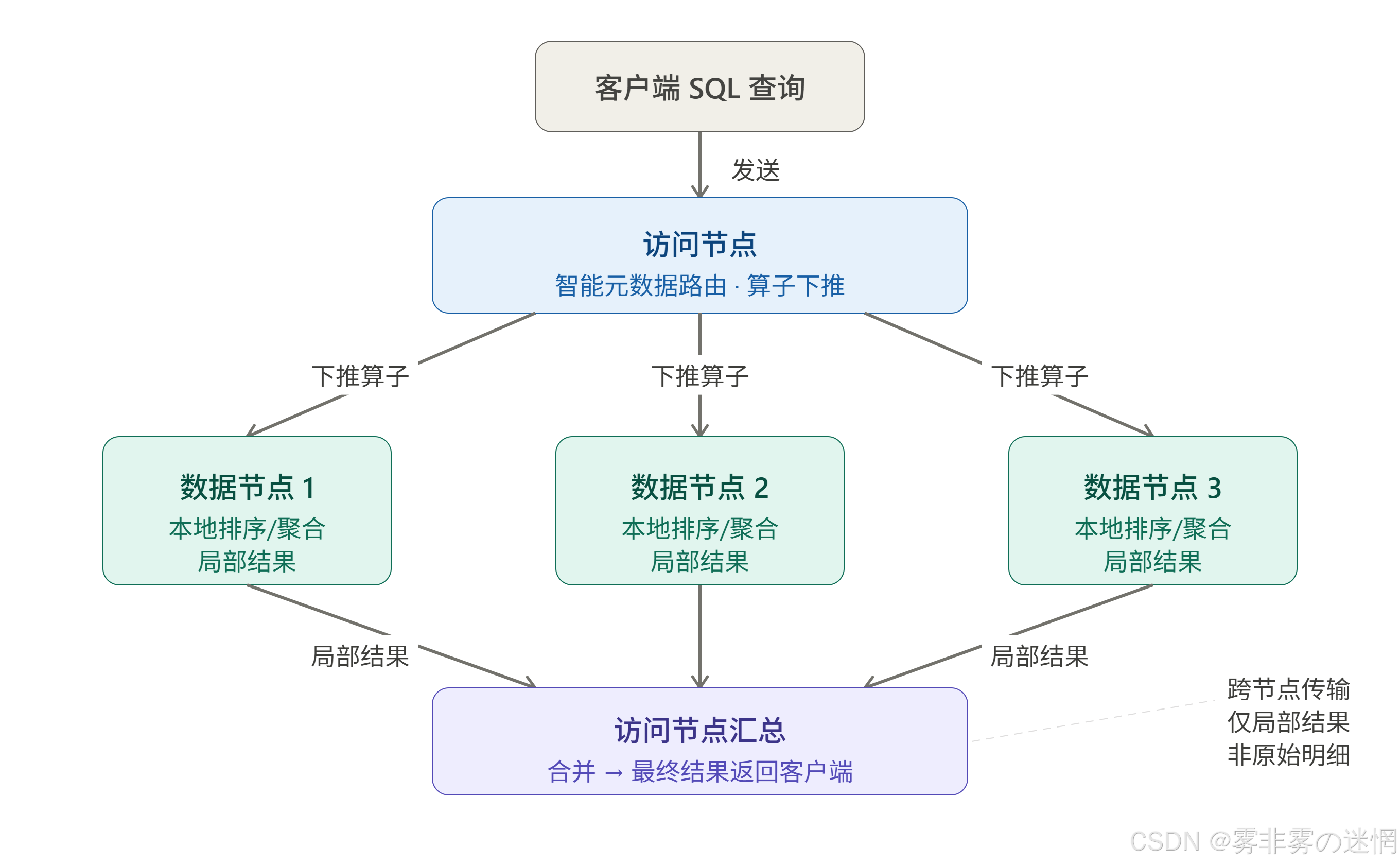
查询计算:算子下推
对于聚合分析类查询,数据在哪里计算比数据怎么传输更关键。
很多时序查询不需要回传全量明细------比如按分钟统计平均温度、按小时计算最大电流、按天汇总能耗。如果把这些聚合计算放到数据所在节点先做,只把局部结果汇总到访问节点,就能大幅减少跨节点的数据搬运量,中心节点的压力也随之降低。
结合插值填补(处理采集缺失的时间点)和时间桶聚合(time_bucket 类函数)两类内置能力,原本需要分钟级响应的跨节点复杂分析,可以压缩到亚秒级。
长期留存:自适应冷热分层
历史数据不能全部放在高成本存储上,但也不能随意丢弃。合理的做法是根据访问频率分层管理:
- 热层:最近一段时间的数据,服务实时告警和高频查询,存在高速介质上,保持索引完整
- 冷层:超过保留窗口的历史数据,服务趋势分析、故障追溯和模型训练,压缩后存到低成本介质
自适应压缩会根据数据的时间戳和访问模式自动决定是否压缩、压缩比多少,不需要人工干预冷热切换的时机。全生命周期管理体系则确保数据在不同层之间的流转是自动的,不影响上层查询接口。
可靠性:事务一致性与多副本
工业场景对可靠性的要求不亚于对性能的要求。生产调度、电力监测、交通运行等系统,一旦出现数据不一致或服务中断,影响面很大。
纯粹追求写入吞吐的时序引擎往往会在一致性上做妥协(最终一致、部分节点可接受数据丢失)。如果业务对数据一致性和业务连续性有明确要求,需要在选型时仔细确认目标系统的事务保证等级和故障切换策略,而不是只看 benchmark 上的写入峰值。
选型时更值得关注的几个问题
时序数据库的 benchmark 很容易被"每秒能写多少行"这个指标主导,但这个数字在实际运行中的参考价值有限。以下几个问题可能更能反映一个系统的实际工程能力:
- 数据规模持续增长后,写入吞吐是否能保持稳定,还是会随历史数据积累而衰减?
- 查询模式从简单点查变为复杂聚合后,延迟如何变化?
- 设备数量从百台扩展到万台,是否支持在线扩容而不需要停机迁移?
- 时序数据能否直接与设备档案、空间信息、运维工单等关系数据做联合查询,还是必须依赖外部 ETL 同步?
最后一点在工业场景尤为重要。时序数据本身只是设备状态的一部分,要形成业务判断,通常还需要关联设备档案、地理位置、工单记录等信息。如果时序库和业务库是两套孤立的系统,这类跨类型分析就需要额外的数据同步链路,而这条链路本身就是一个维护负担和潜在故障点。