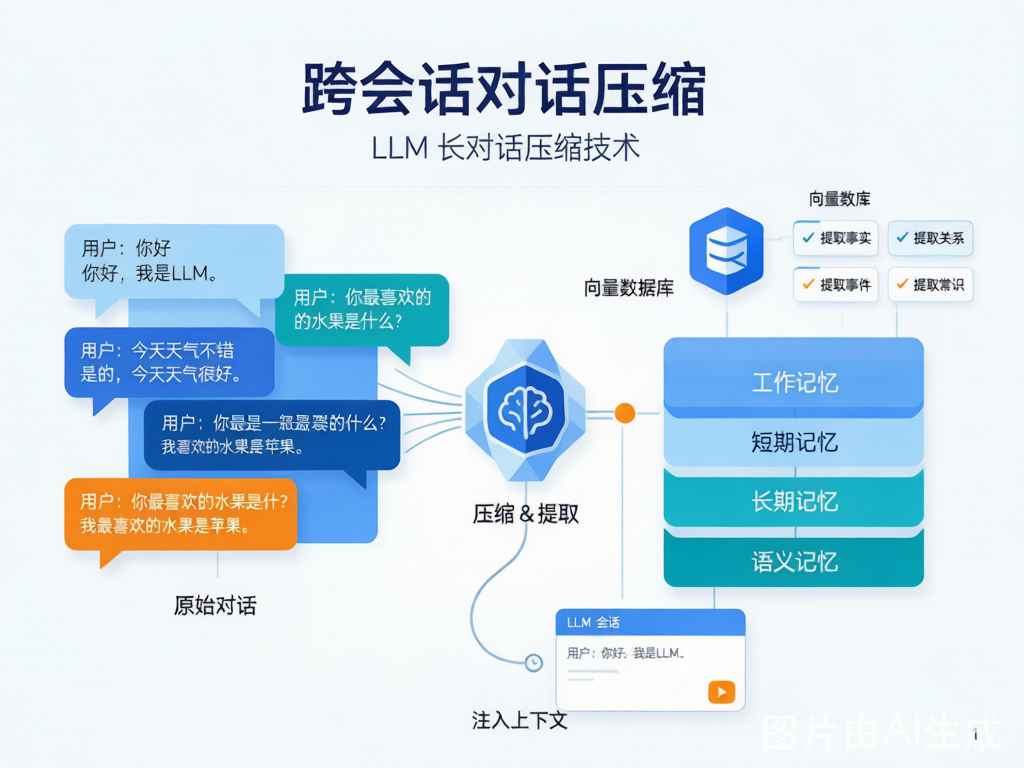
一、问题背景
LLM的上下文窗口有限(即使长窗口模型也存在注意力衰减问题),且长上下文会带来高昂的API成本。跨会话压缩对话的核心目标是:在有限的token预算内,保留足够的历史信息,使得模型在新的会话中仍能理解用户意图和对话背景。
二、核心策略
1. 摘要式压缩(Summarization)
最经典的方案:用LLM对历史对话生成结构化摘要。
原始对话(N 轮)
│
▼
LLM 摘要生成
│
▼
结构化摘要(用户目标、关键事实、决策、待办)摘要维度建议:
- 用户画像:身份、偏好、使用场景
- 当前目标:本次对话的核心任务
- 关键事实:用户提供的重要信息(如姓名、数据、配置)
- 决策记录:用户做出的选择和确认
- 待办事项:未完成的任务
- 约束条件:用户明确提出的限制
实现要点:
- 使用独立的总结 prompt,而非复用对话模型
- 摘要要有"增量更新"能力:新对话发生后,merge 到已有摘要中
- 控制摘要长度,通常 500-2000 tokens 即可
2. 关键信息提取 + 结构化存储
不是生成自然语言摘要,而是提取结构化的事实单元。
┌──────────────────────────────────────┐
│ Memory Store │
├──────────────────────────────────────┤
│ entity: user │
│ - name: "张三" │
│ - role: "后端开发" │
│ - preference: "用TypeScript" │
│ │
│ session: 2024-06-15 │
│ - task: "搭建CI/CD流水线" │
│ - decision: "选择GitHub Actions" │
│ - status: "进行中" │
│ │
│ constraint: │
│ - "不使用Docker" │
│ - "部署到腾讯云" │
└──────────────────────────────────────┘优势:
- 精确检索,不会像自由文本摘要那样丢失细节
- 方便跨会话的精确查询
- 可配合向量数据库做语义检索
3. 滑动窗口 + 摘要混合
结合多种粒度,形成多层记忆:
Layer 1: 最近 N 轮对话(完整保留)
Layer 2: 中期对话 → 轮次级摘要
Layer 3: 远期对话 → 会话级摘要
Layer 4: 全局用户记忆 → 跨会话的长期画像典型配置:
| 层级 | 内容 | 保留策略 |
|---|---|---|
| 工作记忆 | 最近 10-20 轮 | 完整保留 |
| 短期记忆 | 当前会话早期 | 逐段摘要,每 20 轮压缩一次 |
| 长期记忆 | 历史会话 | 会话级摘要 + 关键事实提取 |
| 语义记忆 | 用户画像/全局知识 | 结构化存储,跨会话持久化 |
4. 记忆分级(MemGPT 思路)
MemGPT 将记忆分为主上下文(main context)和外部记忆(external memory):
┌──────────────┐ 检索/写入 ┌──────────────────┐
│ Main Context │ ◄──────────────► │ External Memory │
│ (LLM 窗口) │ │ (向量DB/知识库) │
│ │ │ │
│ 当前对话 │ │ 历史会话摘要 │
│ 最近记忆 │ │ 用户画像 │
│ 检索到的 │ │ 领域知识 │
│ 相关内容 │ │ 事实库 │
└──────────────┘ └──────────────────┘核心机制:
- LLM 自身可以决定何时把当前上下文中的内容"写入"外部记忆
- 需要时,LLM 发起检索从外部记忆中"召回"相关内容
- 类似操作系统的虚拟内存管理
5. 基于 Embedding 的语义检索
将每轮对话或摘要编码为向量,检索时用语义相似度找到相关历史。
新用户消息
│
├──→ 向量化
│ │
│ ▼
│ 在历史对话向量库中检索 Top-K
│ │
│ ▼
│ 返回最相关的历史片段
│
▼
组装 prompt = 系统提示 + 检索到的历史 + 当前对话 + 用户消息关键设计点:
- 检索粒度:整段对话 vs 单轮对话 vs 事实单元
- 检索触发时机:每次对话都检索 vs 按需检索
- 去重和排序:同一信息可能被多次存储,需要去重
三、压缩效果评估
好的压缩方案应该:
| 指标 | 含义 |
|---|---|
| 压缩率 | 压缩后 token 数 / 原始 token 数,通常目标 1:10 ~ 1:20 |
| 信息保真度 | 压缩后能否正确回答关于历史的问题 |
| 检索准确率 | 需要历史信息时,能否准确 recall |
| 更新及时性 | 新信息多久能被纳入压缩后的记忆 |
四、推荐的工程实现方案
用户消息
│
┌────────────┼────────────┐
▼ ▼ ▼
最新N轮 语义检索 结构化
完整对话 (向量DB) 用户记忆
│ │ │
└────────────┼────────────┘
│
▼
Prompt 组装
│
▼
LLM
│
┌─────────┼─────────┐
▼ ▼
生成回复 记忆更新
│
┌────────────┼────────────┐
▼ ▼ ▼
增量更新 更新向量 更新结构化
对话摘要 索引 记忆库关键组件的实现
1. 增量摘要更新
def update_summary(existing_summary, new_turns):
prompt = f"""
现有摘要:{existing_summary}
新增对话:{new_turns}
请将新增信息合并到摘要中,保持结构化格式。
如果新信息与旧信息冲突,以新信息为准。
"""
return llm(prompt)2. 关键事实提取 + 冲突解决
def extract_and_merge_facts(existing_facts, new_dialogue):
# 1. 从新对话中提取事实
new_facts = llm_extract_facts(new_dialogue)
# 2. 与现有事实对比
for fact in new_facts:
conflict = find_conflict(existing_facts, fact)
if conflict:
existing_facts = resolve_conflict(conflict, fact) # 新覆盖旧
else:
existing_facts.append(fact)
return existing_facts3. 向量检索增强
- 每次对话后,将压缩后的摘要和关键事实向量化并存入向量库
- 新会话开始时,用用户的首条消息作为 query 检索相关历史
- 检索结果注入 system prompt 或作为上下文前缀
五、常见陷阱
| 陷阱 | 解决方案 |
|---|---|
| 摘要漂移:多次增量摘要后偏离原意 | 定期做全量重新摘要,或保留原始对话快照做校验 |
| 关键信息被摘要吞没 | 对关键信息(数字、配置、决策)单独提取并强保留 |
| 检索不准确导致上下文混乱 | 结合关键词匹配 + 语义检索,设置相似度阈值 |
| 记忆无限膨胀 | 设置记忆容量上限,用 LRU 或重要性评分做淘汰 |
| 隐私信息泄露 | 压缩前脱敏,敏感信息加密存储 |
六、业界参考:Claude Code 的实现方案
Claude Code 采用了一套工程化的跨会话压缩方案,核心思路如下:
- 两路径互补:AI 生成的会话摘要 + 后台 Session Memory 持续提取,互为备份
- 固定结构化模板:摘要采用 9-10 个固定字段(用户目标、关键决策、约束条件、文件状态等),而非自由文本
- 保留窗口算法:最近消息不压缩,采用三重约束(10K token 下限 / 5 条消息下限 / 40K token 上限)动态决定压缩边界
- 工具对完整性保护 :
tool_use和tool_result必须成对保留,防止压缩后上下文断裂 - 重新注入机制:压缩后主动恢复关键上下文(已打开的文件、技能、Plan、MCP 状态等),预算约 50K token
- 状态跨压缩保留 :
invokedSkills、sentSkillNames等运行时状态在压缩中不丢失 - Hook 可扩展:允许用户自定义压缩和上下文后处理逻辑
详细见往期文章。Claude code源码精读之 跨会话关键信息保留机制
七、总结
跨会话压缩的核心公式:
压缩质量 = 摘要结构化程度 × 检索精度 × 更新策略的合理性
推荐的最小可行方案:
- 当前会话:保留最近 N 轮完整对话
- 会话结束:生成结构化摘要(含用户画像、关键决策、待办)
- 新会话启动:注入上一会话摘要 + 从向量库检索最相关的历史片段
- 长期维护:定期合并多个会话摘要,形成用户级别的长期记忆