
🎯 博主简介
CSDN 「新星创作者」 ,人工智能技术领域博主,码龄 5 年 ,累计发布
190+ 篇原创文章,博客总访问量30万+浏览。
🚀 持续更新 AI 前沿实战知识,专注于 AI 技术实战、RAG 系统、Agent 应用开发与大模型工程化落地。目前主要更新方向包括:
- 🦞 最新 OpenClaw 教程 ---从入门到精通|AI 智能助手/自动化/Skills 实战(原 Clawdbot/Moltbot)
- ✨ Agent 记忆系统 --- 长期记忆、上下文管理与个性化智能体设计
🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥以下系列正在火热更新中🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥- 📘 图解机器学习合集 --- 用图解方式系统梳理机器学习核心概念,持续更新中
同时也会持续分享 AI 编程、Java 后端、Spring 生态、Transformer、大模型基础、计算机视觉 等方向内容,内容会尽量结合自己的学习记录、项目实践和踩坑经验来整理。
📱GZH:安逸Ai(科技前沿新闻,Github热门项目,最新免费资料...)- 网页观看完整系列合集:🌐 Anyi AI 学习资源站
聚类和降维:没有标签时机器学习怎么工作?
你用决策树预测了一堆数据,效果还不错。但你有没有想过:那些预测结果其实都依赖一个前提------你得先告诉机器"正确答案是什么"。
问题来了。
现实里,大部分数据根本没有答案。电商平台有几亿用户的浏览记录,但没人给这些记录标注"这是冲动型消费者"或"这是理性比价党"。医院有大量CT影像,但医生根本没时间一张张标注有没有肿瘤。
没有标签,机器怎么学习?
这就是无监督学习要回答的问题。今天聊两个最核心的技术:聚类和降维。
聚类是什么------自己发现规律的分类
先把"聚类"和"分类"区分清楚。
分类是有老师的:你告诉机器,这张图是猫、那张图是狗,机器学着区分。聚类没老师:一堆数据扔进去,机器自己看哪些长得像,把它们归成一组。
像不像你小时候玩彩色珠子?
一盘五颜六色的珠子混在一起,没人告诉你"这是红色、这是蓝色"。但你自然会发现:这几颗看起来都是一个色系的,那几颗又是另一个色系。
聚类就是这个道理。算法按相似度把数据分组,组内相似,组间不同。它自己摸索出了数据的内在结构。
K-Means------最经典的聚类算法
说到聚类,必须提K-Means。它几乎是入门必学的算法,简单又好用。
原理是这样的:
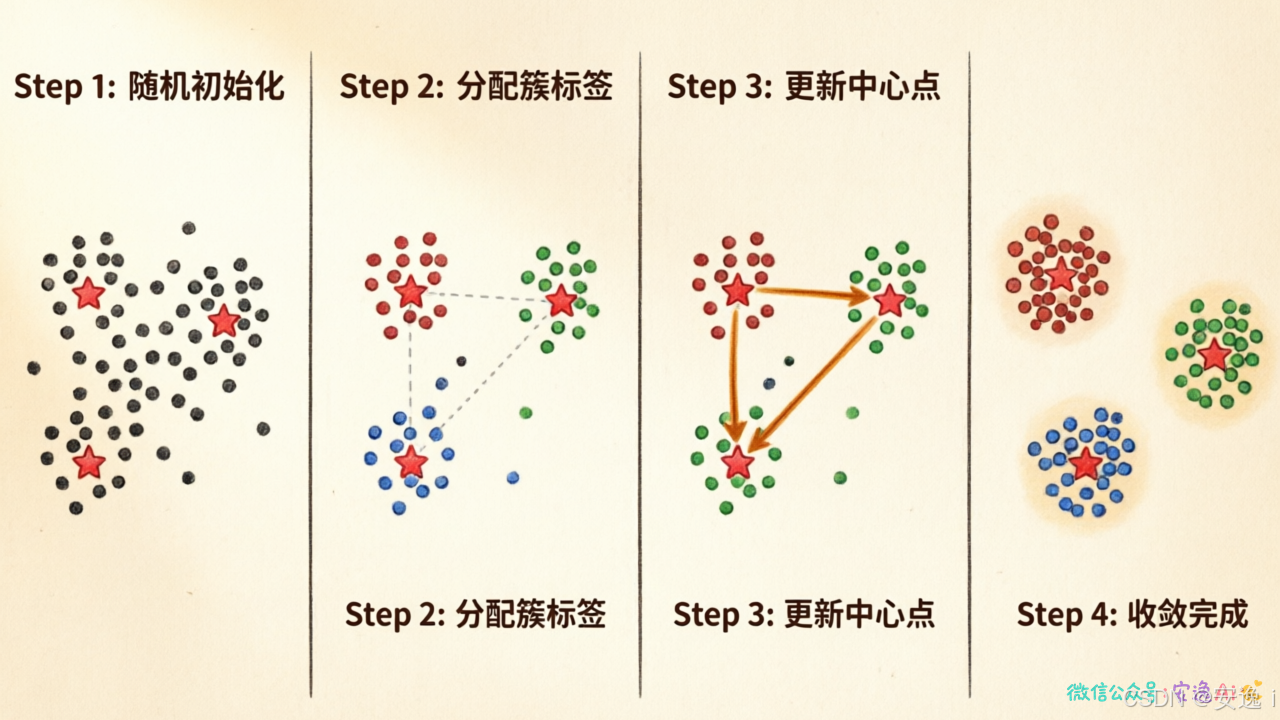
第一步,随机选K个点作为"中心"。
第二步,每个数据点找到离自己最近的中心,划归到那个中心代表的组。
第三步,每组重新计算自己的中心------就是组内所有点的平均值。
第四步,重复第二步和第三步,直到中心不再动为止。
听起来有点绕?换个场景理解。
想象幼儿园老师要分座位。先随便指定几个小朋友当"小队长",其他小朋友分别站到最近的小队长旁边。然后,每个小队长看看自己队里都站了谁,调整一下自己的站位(走到大家的正中间)。其他小朋友再看看现在哪个队长最近,重新排队。这个"排队---调位置"的过程一直重复,直到没人再换队为止。
这就是K-Means在做的事。
但这里有个问题:K是多少?
你得提前告诉算法"我想把这堆数据分成几组"。选多了,每个组太细碎;选少了,组内混进了不该混的东西。
这个K值怎么定?没有标准答案。通常要跑多次、比较效果,结合业务理解来选。比如你要给客户分群,先想清楚"我需要几个有意义的客户类型"。
其他聚类方法------不是所有数据都长得像球
K-Means有个局限:它擅长发现"球状"的簇。就是那种差不多圆溜溜的数据群体。
但现实数据不都是圆的。
比如社交网络里,用户之间的联系可能形成各种奇怪的形状。K-Means硬套上去,效果就差。
这时候可以看看其他算法。
层次聚类像整理书架。它先把每本书当成一类,然后每次把最像的两类合并,层层往上,最后形成一棵树。
这个树叫"族谱图"。你想分多细就切到哪一层。要不要分大类、中类、小类,切的位置不同,结果就不同。这种灵活性是K-Means没有的。
DBSCAN是另一种思路。它基于密度------哪块儿数据点扎堆,就算一个簇;零星几个点落单的,算异常点。
想象在一锅粥里找米粒聚集的区域。密度高的地方就是一团米粒,密度低的缝隙把它们分开。
DBSCAN厉害的地方在于:它能找到任意形状的簇,还能自动发现"噪音"。

选哪个算法?看你数据的形状。没有万能钥匙。
降维------给高维数据瘦身
说完了聚类,再聊另一个无监督学习的核心能力:降维。
什么是维?就是你描述一个东西需要几个数字。
一件衣服,用"价格"一个维度描述,是1维。用"价格、尺码、颜色"三个维度描述,是3维。
现在数据动不动就几百维、上千维。一个28×28像素的灰度图,有784个像素,每个像素一个数值。你要处理一万张这种图,就是78400个维度。
人脑根本没法直观理解78400维空间。降维干的事,就是把这些高维数据压缩到2维、3维------人能看懂的维度。
但不是随便压缩。
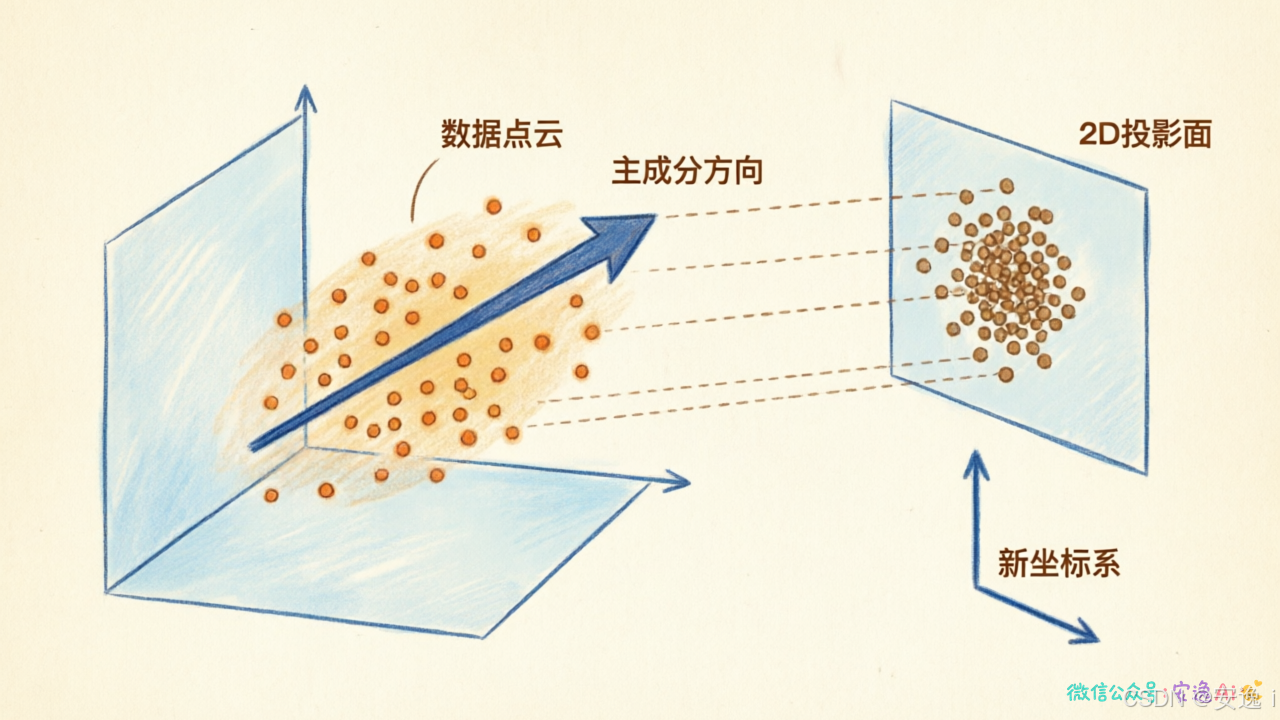
想象你给一个3D物体拍照,变成2D照片。会丢失信息对吧?但你肯定能认出拍的是什么。说明照片保留了最关键的特征。
降维就是这个思路:扔掉不重要的信息,保留最能区分数据特点的那些方向。
PCA------主成分分析------是最常用的降维方法。
它的核心思想是:找到数据变化最大的那个方向,作为第一主成分。然后在垂直于它的方向上,找变化第二大的,作为第二主成分。以此类推。
你可以理解为:先抓住最明显的变化趋势,再处理次要的变化。
把数据投影到这些主成分上,维度就降下来了。原来100维的数据,保留前10个主成分,可能保留了95%的信息。
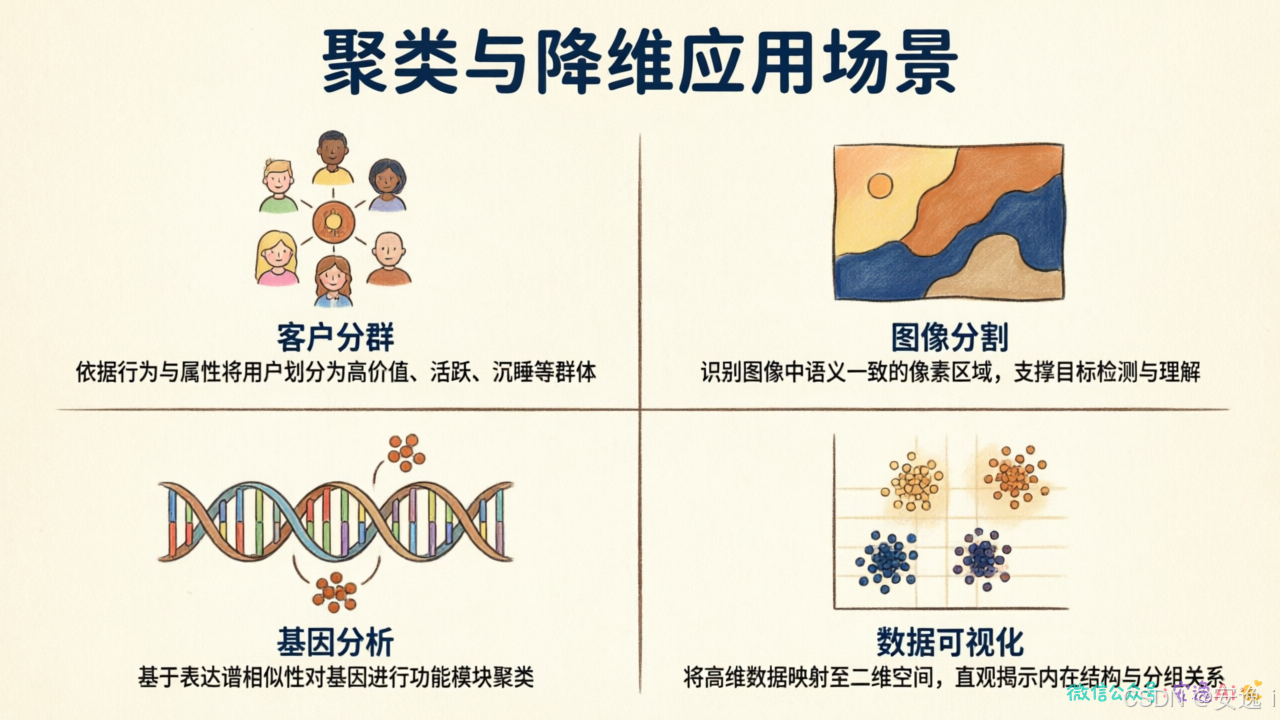
聚类和降维怎么用
说了这么多,它们在真实场景里有什么用?
客户分群是最常见的应用。淘宝根据用户的浏览、购买、收藏记录,把用户自动分成"省钱党""品质控""跟风族"等群体。没人提前标注这些标签,是算法自己发现的。我之前做用户分析的时候,用K-Means跑了三天,调了十几轮参数,最后分出6个用户群,其中有个"深夜剁手党"群体特别有意思------凌晨下单率是其他群体的3倍。
图像处理也离不开这两个技术。一张图片有几十万个像素,每个像素一个数值,高维得可怕。降维可以压缩图像,聚类可以分割图像------把相似区域归成一组。OCR识别、图像搜索背后都有它们的身影。
生物信息学里,基因表达数据动不动就几万个基因。降维帮助找到主要的基因表达模式,聚类把功能相似的基因归在一起。这能帮科学家发现哪些基因可能协同工作。2020年新冠研究里,就有团队用聚类分析发现了不同症状患者的基因表达特征差异。
数据可视化是降维最直接的价值。把几百维的数据降到2维或3维,画成散点图,人就能直观看出数据分布、发现异常点、识别聚类结构。做探索性数据分析必备这一步。
写在最后
整个系列到这里就结束了。从最基础的概念到前沿的应用,我们走过了机器学习最核心的知识地图。
有标签的数据永远是少数。大部分数据是沉默的、没有答案的。聚类和降维教机器在沉默中发现结构,在没有指引的情况下摸索规律。
这其实很像人类的学习方式。没人手把手教你怎么做人,但你通过观察、比较、归纳,慢慢理解了这个社会的规则。无监督学习,就是让机器也具备这种能力。
剩下的,就交给实践了。去跑几个模型、做几个项目,你会发现:懂了原理,踩坑都会踩得更明白。