大模型是如何自主调用工具的?纯 Python 实现 ReAct 引擎与函数自省注册
适用读者:了解 Python 基础,想弄清楚 Agent 工具调用闭环的读者。
配套代码:
../v1_react/代码地址:v1_react 示例代码
本文目标:用一个可运行、可观察、无 API Key 依赖的 ReAct 小引擎,说明模型如何在 Thought、Action、Observation、Final 之间流转。
1. 这篇文章要解决什么问题
"大模型自主调用工具"听起来像一个复杂能力,但拆开之后,它通常由三件事组成:
- 把可用工具告诉模型;
- 约束模型按固定格式输出下一步动作;
- 程序解析动作、调用工具、把结果写回上下文。
真正容易误解的地方是:模型并不会直接执行 Python 函数 。模型只输出下一步意图,真正执行工具的是 Agent Runtime。本文用 v1_react/ 做一个白盒版本,把这件事从代码、运行结果和 trace 三个层面摊开。
这篇文章的验收标准很具体:
| 验收点 | 判断方式 |
|---|---|
能看到模型输出 Thought / Action / Final |
控制台输出包含 3 轮模型返回 |
| 能看到工具真的由程序执行 | 控制台和 trace 中出现 tool_call 与 observation |
| 能复现完整状态流转 | 运行后生成 v1_react/trace.json |
| 能可视化检查执行过程 | 通过本地 HTTP 服务打开 visualization.html |
| 能说明 demo 与生产系统的边界 | 第 8 节列出当前做法和生产级替代 |
2. 环境与前置条件
本文示例在本地验证环境如下:
| 项目 | 说明 |
|---|---|
| 操作系统 | Windows + PowerShell |
| Python | 本机验证为 Python 3.12.5;建议 Python 3.10+ |
| 第三方依赖 | 无,示例只使用 Python 标准库 |
| API Key | 不需要。默认使用 ScriptedModel 固定返回模型输出 |
| 网络 | 运行 demo 不需要网络;查看官方文档需要网络 |
为什么默认不接真实大模型?因为本文要观察的是 Agent Runtime 的状态流转。如果一开始就接真实模型,读者会把问题混在一起:
- 是 Prompt 没写好?
- 是模型温度太高?
- 是网络请求失败?
- 是工具 Schema 不清楚?
- 是 Action 解析器太脆弱?
教学阶段先用 ScriptedModel 固定模型输出,才能把变量控制住。等闭环机制看清楚,再替换真实模型才有意义。
3. 先运行:得到一个可复现闭环
在专栏根目录执行:
powershell
cd 撕开黑盒学大模型-从白盒状态机演进到工业级Agent框架
python v1_react\main.py本机实测输出如下:
text
[step 1] model
Thought: 先计算预算。
Action: calculator[128 / 4 + 16]
[step 1] observation
48.0
[step 2] model
Thought: 数值已得到,再查询目的地天气。
Action: weather[杭州]
[step 2] observation
小雨,气温 23 度,建议带伞。
[step 3] model
Thought: 工具信息足够。
Final: 预算结果是 48.0,杭州小雨,出门建议带伞。
final answer: 预算结果是 48.0,杭州小雨,出门建议带伞。
trace written: trace.json这个输出证明了两件事:
- 模型输出的是文本协议:
Thought、Action、Final。 - 工具调用和结果回灌发生在程序侧:
calculator返回48.0,weather返回杭州天气,再被写回下一轮上下文。
运行后会生成:
v1_react/trace.json:结构化执行轨迹;v1_react/visualization.html:读取 trace 后展示状态流转。
4. ReAct 的最小状态机
ReAct 的核心不是某个库,而是一套状态约定:
text
Thought: 模型先说明当前判断
Action: 需要调用哪个工具,以及传什么参数
Observation: 程序把工具返回结果写回上下文
Final: 模型给出最终答案在 agent.py 中,ReactAgent.run() 的主循环负责三件事:
python
for step in range(1, self.max_steps + 1):
output = self.model.complete(transcript)
final_line = next(
(line for line in output.splitlines() if line.startswith("Final:")),
"",
)
if final_line:
return final_line.removeprefix("Final:").strip()
action_line = next(
(line for line in output.splitlines() if line.startswith("Action:")),
"",
)第一步是让模型基于当前 transcript 生成下一步文本。第二步先判断是否已经出现 Final。如果没有,程序继续寻找 Action。
Action 被解析后,程序调用对应工具,并把 Observation 追加到 transcript:
python
observation = self.tools.call(tool_name, tool_arg)
transcript += f"\n{output}\nObservation: {observation}"这里有一个关键结论:模型没有真的直接调用函数 。它只是写出 Action: calculator[128 / 4 + 16]。真正执行 calculator() 的,是外部 Python Runtime。
这也是 Agent 框架的基本分工:
| 角色 | 负责什么 |
|---|---|
| 模型 | 根据上下文选择下一步意图 |
| Runtime | 解析意图、调用工具、处理异常 |
| 工具 | 执行确定性动作并返回结果 |
| Trace | 记录每一步,方便复盘和定位问题 |
5. 工具是如何注册给模型的
工具注册在 tools.py 中完成。示例里提供了两个工具:
calculator(expression: str):计算一个受限数学表达式;weather(city: str):返回确定性的天气文本。
注册器使用 inspect.signature 读取函数入参,用 docstring 读取工具说明:
python
signature = inspect.signature(func)
parameters = {
param_name: str(param.annotation)
for param_name, param in signature.parameters.items()
}这样做的价值是:普通 Python 函数可以被自动转成模型可理解的工具 Schema。最终进入 Prompt 的工具说明大致长这样:
text
Available tools:
- calculator({'expression': 'str'}): Evaluate a small arithmetic expression.
- weather({'city': 'str'}): Return a deterministic weather report for a city.LangChain 官方文档对 tools 的解释也是类似方向:tools 本质上是具有明确输入输出、传给模型选择调用的 callable functions;类型提示和说明会影响工具 Schema 的生成与模型选择。本文的 ToolRegistry 是一个教学版最小实现,不等于生产级工具系统。
当前 demo 为了保持机制清楚,只支持单参数工具:
python
if len(signature.parameters) != 1:
raise ValueError("This demo runtime only supports one-argument tools.")这不是生产限制,而是教学取舍。生产系统通常会用 JSON Schema、Pydantic、模型原生 function calling 或框架工具抽象来处理复杂参数。
6. 为什么 Action 解析是风险点
当前 Action 解析使用的是正则:
python
ACTION_RE = re.compile(r"^Action:\s*(?P<name>\w+)\[(?P<arg>.*)\]\s*$")它能解析:
text
Action: calculator[128 / 4 + 16]但它并不健壮。下面这些情况都可能出问题:
- 参数里包含复杂括号;
- 模型多输出了空格或解释;
- Action 跨多行;
- 工具参数需要 JSON 对象;
- 工具名或参数格式被模型写错。
这就是为什么生产系统更倾向于 Tool Calling、JSON Mode、Pydantic 或框架内置工具 Schema。正则适合教学,因为它把机制暴露得很清楚;但正则不应该成为生产级 Agent 的最终边界。
当前代码至少做了一件必要的事情:如果解析失败,会把 parse_error 写入 trace:
python
if not match:
if self.trace:
self.trace.add(step, "parse_error", action_line=action_line, output=output)
raise ValueError(f"Cannot parse action line: {action_line!r}")这比静默失败要好。工程系统里,失败必须可见,否则线上问题只能靠猜。
7. trace.json:把状态流转变成证据
只看控制台输出还不够。控制台适合人看,trace 更适合复盘、测试和可视化。
本次运行生成的 trace.json 关键片段如下:
json
[
{
"step": 1,
"phase": "model_output",
"payload": {
"text": "Thought: 先计算预算。\\nAction: calculator[128 / 4 + 16]"
}
},
{
"step": 1,
"phase": "tool_call",
"payload": {
"name": "calculator",
"argument": "128 / 4 + 16"
}
},
{
"step": 1,
"phase": "observation",
"payload": {
"text": "48.0"
}
}
]这个结构说明了每一步的职责:
| phase | 含义 | 用途 |
|---|---|---|
prompt |
初始任务和工具说明 | 复盘模型到底看到了什么 |
model_output |
模型输出 Thought、Action 或 Final | 判断模型是否按协议输出 |
tool_call |
Runtime 准备调用的工具和参数 | 判断是否选错工具或传错参数 |
observation |
工具返回结果 | 判断工具是否成功执行 |
final |
最终答案 | 判断循环是否正确退出 |
parse_error |
解析失败记录 | 定位格式漂移和协议破坏 |
这比"模型好像调用了工具"更可靠。trace 能回答清楚:哪一步由模型决定,哪一步由程序执行,哪一步出了问题。
8. 可视化验证:用本地 HTTP 服务打开
visualization.html 会读取同目录下的 trace.json。直接双击 HTML 时,有些浏览器会因为本地文件读取限制导致 fetch("./trace.json") 失败。因此推荐用本地 HTTP 服务打开:
powershell
cd v1_react
python -m http.server 8871 --bind 127.0.0.1然后访问:
text
http://127.0.0.1:8871/visualization.html实际截图如下:
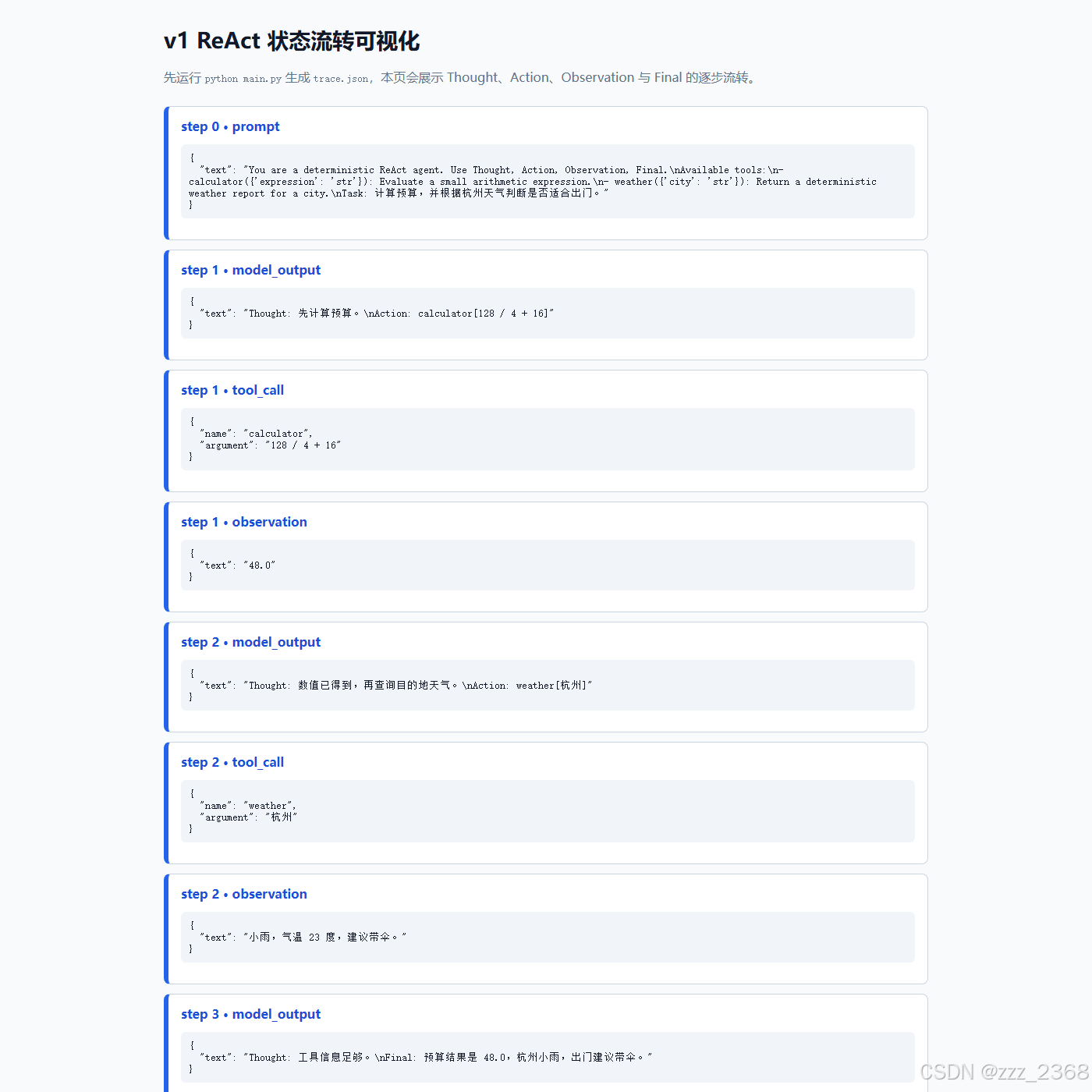
可视化不是为了美化,而是为了让读者直接看到:
- 初始 Prompt;
- 每轮模型输出;
- 工具调用名称与参数;
- Observation;
- Final 答案。
后续接真实模型后,trace 也能帮助定位:到底是模型输出异常、Action 解析异常,还是工具调用异常。
9. 工程取舍与生产边界
这个 demo 有意保留几个"不完美点",因为它们正是学习 Agent 工程边界的入口:
| 设计 | 当前做法 | 生产级替代 |
|---|---|---|
| 模型输出 | 文本 ReAct | Tool Calling / JSON Mode |
| Action 解析 | 正则 | 强类型 Schema + 参数校验 |
| 工具参数 | 单字符串 | Pydantic / JSON Schema |
| 模型客户端 | ScriptedModel 默认 | OpenAI-compatible adapter / 框架模型抽象 |
| 状态保存 | 进程内 transcript + trace 文件 | checkpointer / 数据库 / trace 系统 |
| 可视化 | 本地 HTML 读取 trace | 统一日志、链路追踪和评估平台 |
注意,这些不是"当前 demo 的缺陷",而是刻意保留的学习阶梯。先看清楚最小机制,再逐步替换薄弱环节。
如果把这个 demo 推向生产,至少还要补齐:
- 工具参数的结构化校验;
- 工具异常的分类处理和重试策略;
- 长任务状态持久化;
- 敏感工具的权限控制;
- Prompt 注入和越权调用防护;
- trace 的集中存储、检索和告警。
10. 总结
大模型并不会真正"自主执行 Python 函数"。它输出下一步意图,Agent Runtime 解析意图、调用工具、把结果写回上下文。ReAct 的价值就在于把这个过程拆成可观察的 Thought、Action、Observation 和 Final。
本文的最小实现证明了一个闭环:
text
工具说明进入 Prompt
-> 模型输出 Action
-> Runtime 解析 Action
-> Python 工具执行
-> Observation 写回上下文
-> 模型继续推理或输出 Final理解这件事之后,再看 LangChain tools 或模型原生 function calling,就能明白它们本质上是在解决同一类工程问题:让模型输出的工具调用从脆弱文本变成结构化、可验证、可追踪的工程事件。
发布前自检清单
- 本地运行
python v1_react\main.py通过; - 控制台输出包含 3 轮模型输出和最终答案;
- 生成
v1_react/trace.json; - 通过
python -m http.server打开可视化页面; - 文中说明了 demo 与生产系统边界;
- 文中没有真实 API Key、私有端点或破坏性命令。
下一篇:小z疯狂码字ing...
感谢阅读,记得点赞、关注、收藏,欢迎各位评论区交流!!!
