词嵌入(Word Embedding)
核心概念
嵌入(Embedding):将每个 token(单词或词片段)映射到一个高维向量。
高维空间中的方向 = 语义含义
嵌入空间的特性
|------|---------------------------------|
| 示例 | 含义 |
| 性别方向 | 从 "king" 的嵌入沿某方向移动 → 得到 "queen" |
| 数量方向 | 单复数变化 |
| 其他方向 | 词性、时态、主题等无数语义维度 |
-
原始嵌入仅编码单词本身,不含上下文信息
-
Transformer 的目标是逐步调整这些嵌入,使其包含丰富的上下文含义
注意力机制要解决什么问题?
核心目标
让模型能够根据上下文语境,动态更新每个词的嵌入表示。
典型案例
案例 1:Mole 的多义性
-
1 mole of carbon dioxide → mole(摩尔,计量单位)
-
take a biopsy of the mole → mole(痣,医学术语)
-
初始嵌入阶段:两个 "mole" 的向量完全相同
-
注意力机制:根据周围词语,动态调整嵌入方向,使其指向正确的语义区域
案例 2:Tower 的具体化
-
tower → 泛化的"高大建筑"方向
-
Eiffel tower → 更具体:与巴黎、法国、钢铁等向量相关联
-
miniature tower → 进一步调整:不再与"大"相关联
案例 3:整句上下文
输入:there the murderer was ???
期望输出:精准预测下一个词
最终向量必须编码:整本推理小说的上下文信息、凶手身份、场景氛围等,否则只根据这句话无法得知凶手是谁。
单头注意力(Single Head of Attention)的计算流程
以形容词修饰名词为例(一种注意类别:名词注意形容词)
"a fluffy blue creature roamed the verdant forest"
目标:fluffy 和 blue 的含义被传递给 creature
第一步:生成查询向量(Query)
Query = W_Q × Embedding
|------------|--------------|
| **参数** | **值** |
| 嵌入维度 | 12,288 |
| Query 空间维度 | 128 |
| W_Q 矩阵大小 | 128 × 12,288 |
| 参数数量 | ≈ 150 万 |直觉理解:
-
每个名词(如 creature)"提问":"我前面有哪些形容词?"
-
Query 矩阵将名词嵌入映射到 Query 空间,编码"寻找形容词"的意图
第二步:生成键向量(Key)
Key = W_K × Embedding
|------------|--------------|
| **参数** | **值** |
| W_K 矩阵大小 | 128 × 12,288 |
| 参数数量 | ≈ 150 万 |直觉理解:
-
每个词(包括形容词)"回答":"我是形容词,我在那个位置"
-
Key 向量与 Query 向量在同一低维空间(128维)
第三步:计算注意力分数(Attention Scores)
Score = Query · Key
-
对每对 (Query, Key) 计算点积
-
结果可正可负,从负无穷到正无穷
|----------|----------|--------|-----|---------|--------|
| | creature | roamed | the | verdant | forest |
| fluffy | ●● | ○ | ○ | ○ | ○ |
| blue | ●● | ○ | ○ | ○ | ○ |
| creature | ○ | ○ | ○ | ○ | ○ |
| ... | ... | ... | ... | ... | ... |第四步:Softmax 归一化
Attention Pattern = softmax(Score / √d_k)
其中 d_k = 128(Query/Key 空间维度)
为什么要除以 √d_k?
防止点积值过大,导致 softmax 输出趋近于 one-hot 分布(梯度消失)
梯度消失:模型不知道该往哪个方向发展。
第五步:掩码机制(Masking)
训练时的额外要求:同时预测每个位置之后的词,但训练时传入的一般是整句话,在训练某个词的时候将后面词都掩盖住。
掩码矩阵:
|----------|----------|--------|-----|---------|--------|
| | creature | roamed | the | verdant | forest |
| fluffy | 0.4 | -∞ | -∞ | -∞ | -∞ |
| blue | ● | 0.5 | -∞ | -∞ | -∞ |
| creature | ● | ● | 0.1 | -∞ | -∞ |
| ... | ... | ... | ... | ... | ... | -
将"禁止看到"的区域设为 -∞
-
Softmax 后变为 0,保持列和为 1
掩码机制:训练 vs 推理
掩码在训练和推理阶段都存在,但作用场景不同:
|----|-------------------------------------------------------------------------------------------------|-------------------------------------------------|
| 阶段 | 掩码作用 | 为什么 |
| 训练 | Teacher Forcing:输入整句 "fluffy blue creature",同时预测每个位置的下一个词。预测 "fluffy" 时禁止看到 "blue" 和 "creature" | 防止作弊 --- 如果 "fluffy" 预测时偷看了 "blue",模型学不到真正的预测能力 |
| 推理 | 自回归生成:已生成 "今天天气",预测下一个 token 时,禁止看到还没生成的内容 | 还没生成的内容不存在,自然不能看 |实现方式:将禁止看到的位置的注意力分数设为 -∞,softmax 后变为 0。
第六步:生成值向量(Value)
Value = W_V × Embedding
关键洞察:
Value 向量 = "如果要修改另一个词的嵌入,应该加什么?"
|------------|-------------------------------|
| **组件** | **说明** |
| W_V_down | 将高维嵌入投影到低维(128维) |
| W_V_up | 从低维映射回高维(12,288维) |
| 组合效果 | 低秩变换(Low-rank transformation) |为什么用低秩分解?
-
全 12,288 × 12,288 矩阵 → 1.5 亿参数
-
分解为两个小矩阵 → 参数数量与其他矩阵相当
-
多头注意力时效率更高
K 和 V 的关系:同一词的两个侧面
K 和 V 是同一个词的两个不同投影 --- K 负责"被找到",V 负责"传递内容"。
|------|-------------|-----------------|
| | fluffy 的 K | fluffy 的 V |
| 角色 | 「注意我!我是形容词」 | 「我是『毛茸茸』这个具体意思」 |
| 决定什么 | 被谁关注、被关注多少 | 关注到之后,传递什么内容 |
| 优化目标 | 学到词性/语法角色 | 保留完整语义信息 |K 回答"我是什么角色",V 回答"我这个角色具体是什么内容"。
就像简历:K = 「我是前端工程师」(让 HR 找到你),V = 「我会 React、性能优化」(找到后你能贡献什么)。
为什么 K 和 V 必须分开?
如果只用 V 既当 Key 又当 Value:
-
fluffy 的"毛茸茸语义"和 creature 的"名词语义"直接点积 → 语义不同,分数反而低
-
明明该关注,结果没关注到
拆成 K 和 V 后:
-
K 专门优化"怎么被人找到" → 学到的是词性、语法角色
-
V 专门优化"传什么内容" → 保留的是语义信息
-
两个矩阵各司其职,互补不冲突
第七步:加权求和与更新
ΔE_creature = Σ (Attention_weight × Value)
new_embedding = old_embedding + ΔE_creature
Q、K、V 与 Wq、Wk、Wv 的关系
Wq、Wk、Wv 是可学习的投影矩阵,Q、K、V 是投影后的结果。
|----|-----------------|--------------------|
| 符号 | 含义 | 形状 |
| Wq | 把嵌入投影成「我要找什么」 | 128 × 12,288 |
| Wk | 把嵌入投影成「我能提供什么」 | 128 × 12,288 |
| Wv | 把嵌入投影成「实际传递的内容」 | 低秩分解(128 ↔ 12,288) |
| Q | 投影后的查询向量 | 128 维 |
| K | 投影后的键向量 | 128 维 |
| V | 投影后的值向量 | 12,288 维 |为什么要投影到低维(128)再做 QK 点积?
-
不投影时,每个词的嵌入在高维空间里和自己永远点积最大 → 注意力永远只看自己,失去意义
-
投影到不同的低维空间后,Q 和 K 各自编码不同信息,才有区分度
-
「朴素的理解是直接算相似度,但其实是计算 QK 空间投影后的相似度」
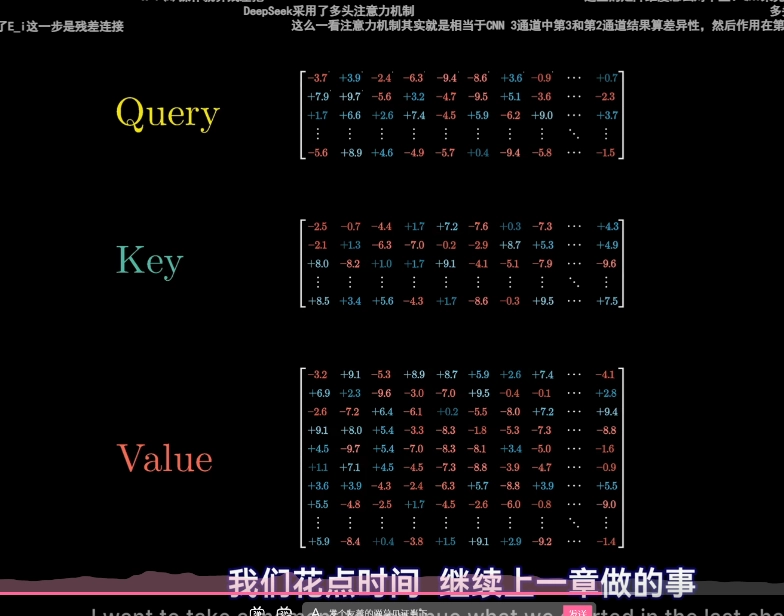
注意力公式逐步拆解(三步走)
以 "a fluffy blue creature roamed the verdant forest" 中更新 creature 的嵌入为例:
第一步: 计算相关度(该关注谁?)
creature 的 Q 与所有词的 K 做点积,得到一行原始分数:
结果:
creature 在问"谁是形容词?",fluffy 和 blue 的 K 回答"我是!",分数自然高。
第二步: 归一化为概率(关注多少?)
除以 √d_k(√128 ≈ 11.3)压缩分数范围,防止 softmax 推向 one-hot:
softmax 后变成概率(加起来 = 1):
高维点积天然偏大,不除 √d_k 会让 softmax 趋近 one-hot(只有一个接近 1,其他都是 0),导致梯度消失。
第三步: 加权提取信息(拿什么过来?)
每个词的 V 是它"愿意传递的内容",按权重加权求和:
最后:新嵌入 = 旧嵌入 + ΔE_creature
creature 从泛化的"生物"变成了"毛茸茸的、蓝色的、在森林里的生物"。
三步总结
|------|-----------------|--------|
| 步骤 | 公式 | 回答的问题 |
| 算相关度 | QK^T | 该关注谁? |
| 变概率 | ÷√d_k → softmax | 关注多少? |
| 取信息 | ×V | 拿什么过来? |一句话:查相关度 → 变概率 → 取信息。公式看着唬人,拆开就三步。
参数统计
单个注意力头
|----------|--------------|-----------|
| 矩阵 | 形状 | 参数量 |
| W_Q | 128 × 12,288 | 1,572,864 |
| W_K | 128 × 12,288 | 1,572,864 |
| W_V_down | 128 × 12,288 | 1,572,864 |
| W_V_up | 12,288 × 128 | 1,572,864 |
| 总计 | | ≈ 630 万 |GPT-3 配置
|------------|-----------------|
| **参数** | **值** |
| 注意力头数 | 96 |
| 每块参数量 | 96 × 630万 ≈ 6 亿 |
| 层数(Blocks) | 96 |
| 注意力相关总参数 | 96 × 6亿 ≈ 58 亿 |
| 网络总参数 | 1750 亿 |注意力参数仅占总参数的约 1/3,其余来自 MLP 等组件。
交叉注意力(Cross Attention)
与自注意力的区别
|--------|-----------------------|-------------------------------------|
| 特性 | 自注意力 (Self-Attention) | 交叉注意力 (Cross-Attention) |
| Q 来源 | 同一个序列 | 目标序列(如英语) |
| K、V 来源 | 同一个序列 | 源序列(如法语) |
| 在干嘛 | 「这句话里,词和词之间什么关系?」 | 「翻译时,这个英文词对应哪个法语词?」 |
| 掩码 | 需要(防止看到未来) | 通常不需要(源序列是完整的) |
| 使用模型 | GPT 等纯 Decoder 模型 | 原始 Transformer 的 Encoder-Decoder 结构 |自注意力 = 同一句话内部互相看;交叉注意力 = 一句话去「查」另一句话。
翻译示例
Keys 来源: 法语文本
Queries 来源: 英文文本
Attention Pattern: 英文单词 ↔ 对应的法文单词
Transformer 的原始用途与 GPT 的区别
-
原始 Transformer(2017 "Attention Is All You Need"):为机器翻译设计,有完整 Encoder-Decoder 结构
-
Encoder 读源语言 → Decoder 生成目标语言
-
Decoder 中同时有自注意力(看已生成的目标语言)和交叉注意力(查源语言)
-
-
GPT:只保留 Decoder 部分,去掉了 Encoder 和交叉注意力
-
纯自注意力 + 掩码,专攻「预测下一个词」一个任务
-
结果这个简单的目标竟能涌现翻译、推理、编程等各种能力
-
所以 GPT 里只有自注意力,没有交叉注意力
多头注意力(Multi-Head Attention)
为什么需要多头?
现实中的上下文关系远不止"形容词修饰名词"一种:
|--------------|----------------------------------|
| **关系类型** | **示例** |
| 语法结构 | "crashed the car" → 影响 car 的形状含义 |
| 实体关联 | wizard + Harry → 哈利波特 |
| 指代消解 | Queen/Sussex/William → 哈里王子 |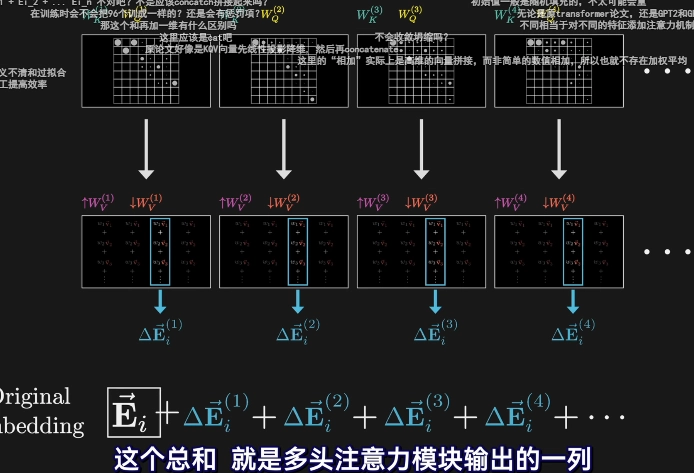
-
单头注意力 → 多头注意力(对比)
单头注意力:一套 Wq、Wk、Wv,只能捕获一种关系(如"形容词修饰名词")。
多头注意力:N 套独立的 Wq、Wk、Wv,并行计算,各自可能学到不同类型的关系:
|------|--------------|-----------------------|
| | 单头 | 多头 |
| 参数套数 | 1 套 Wq/Wk/Wv | N 套独立的 Wq/Wk/Wv |
| 捕获关系 | 仅一种 | 并行捕获多种 |
| 输出 | ΔE | ΔE₁ + ΔE₂ + ... + ΔEₙ |
| 类比 | 一个人看问题 | 96 个专家各看各的,综合意见 |
「综合分析 96 个人的意见,每个人关注的角度不同。
并行计算结构
数学本质:多个独立的头从不同角度分析上下文,最终合并意见
输出矩阵(Output Matrix)的实际实现
数学上完全等价,但计算效率更高。
深层网络:堆叠多个注意力块
处理流程
信息传播特点
-
早期层:捕获基本语义关系(形容词→名词、语法结构)
-
中期层:抽象概念(实体识别、指代关系)
-
深层:高级语义(情感倾向、主题判断、隐含科学事实)
为什么需要多层?
-
每个词的嵌入经过多层注意力,每层都吸收新的上下文
-
周围词的嵌入本身也在逐层精炼
-
迭代过程中信息逐步整合,编码越来越抽象的概念
注意力机制的深层优势
可并行化(Parallelizable)
注意力机制的核心优势不仅是"能做什么",更是运行效率
-
大量矩阵乘法 → GPU 高度并行优化
-
支持大规模分布式训练
规模效应(Scaling)
深度学习数十年的经验教训:
更大的模型 + 更多数据 = 质的飞跃
注意力架构的并行特性,使得扩展到千亿参数级别成为可能。
关键概念速查
|-------------------|------------|-----------------|
| **术语** | **维度** | **作用** |
| Embedding | 12,288 | 词的高维向量表示 |
| Query (Q) | 128 | "我需要什么信息" |
| Key (K) | 128 | "我能提供什么信息" |
| Value (V) | 12,288 | "具体要传递的内容" |
| Attention Pattern | N×N | Q-K 点积归一化后的权重矩阵 |
| Mask | N×N | 遮蔽未来信息(训练时) |
注意力分数计算公式

一句话总结
Q 问路,K 指路,V 带路。QK^T 决定「让谁说、说多少」,×V 决定「说了什么」。权重决定跟谁走,×V 决定走到哪。