一、引言
1.1 核心概念定义
并发控制是数据库管理系统为保证多事务并发访问时数据一致性、完整性而实现的核心机制,事务是并发控制的基本逻辑单位,指对数据库进行读写操作的一组不可分割的执行序列。封锁协议是当前关系型数据库实现并发控制的主流技术手段,通过对数据对象施加不同类型的锁、控制锁的申请与释放时机,实现事务间的访问隔离。
1.2 软考考点定位
本知识点属于软考高级系统架构设计师考试大纲中 "数据库架构设计" 模块的核心内容,历年考试中选择题、案例分析题均有涉及,平均占比约 5-8 分,考点集中在 ACID 特性的场景判断、并发问题的识别、封锁协议的适用场景、两段锁协议的原理分析四个方向。
1.3 技术发展脉络
数据库并发控制技术经历了三个核心发展阶段:1970 年代关系型数据库诞生初期,基于 E.F.Codd 提出的事务理论,IBM 研究院首次提出封锁机制作为并发控制的基础方案;1976 年 Gray 正式提出两段锁协议,明确了可串行化调度的实现标准;1980 年代后 ANSI/ISO SQL 标准将隔离级别与封锁协议对应,形成了当前通用的并发控制技术体系。
1.4 本文知识点覆盖
本文将系统讲解事务 ACID 特性的核心内涵、并发访问的三类典型问题、X/S 锁的工作机制、三级封锁协议的设计逻辑、两段锁协议的可串行化原理,同时给出考点分析与实践应用建议。
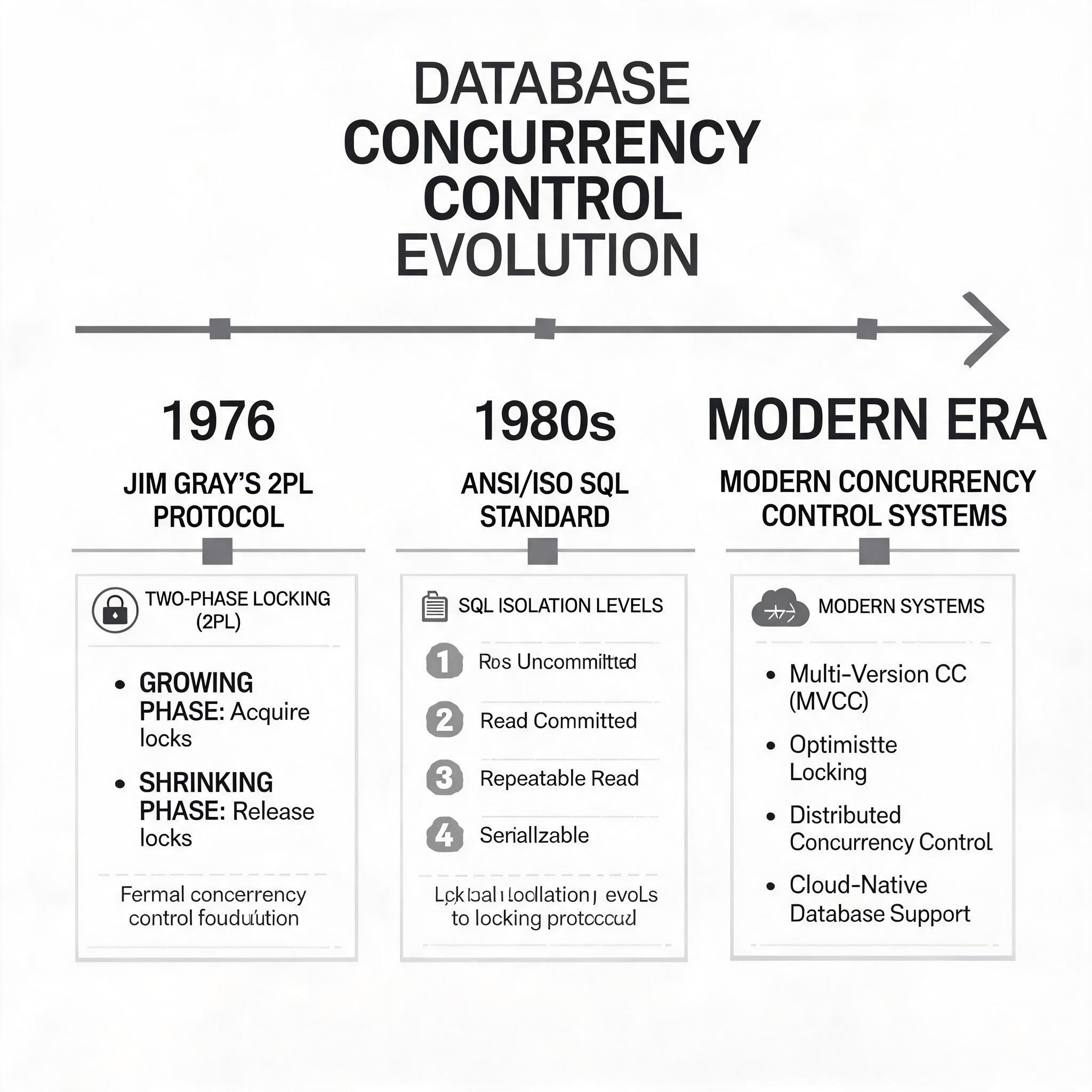 数据库并发控制技术演进路线图
数据库并发控制技术演进路线图
二、事务 ACID 特性核心原理
2.1 原子性(Atomicity)
原子性指事务包含的所有操作是不可分割的执行单元,执行结果只有两种状态:全部操作成功提交,或任意操作失败时所有已执行操作全部回滚,数据库恢复到事务执行前的状态。其底层实现依赖数据库的 Undo 日志(回滚日志),事务执行过程中所有修改操作的反向操作会被记录到 Undo 日志,一旦事务执行异常,系统通过 Undo 日志反向撤销所有已完成的修改。例如电商下单事务包含扣减库存、生成订单、扣减用户余额三个操作,若扣减余额时出现异常,系统会自动恢复库存、删除生成的中间订单数据,保证无部分操作生效。
2.2 一致性(Consistency)
一致性指事务执行前后,数据库的所有完整性约束(包括实体约束、参照约束、用户自定义约束)始终保持合法状态。一致性是事务执行的最终目标,原子性、隔离性、持久性都是为了保证一致性而设计的手段。例如银行转账事务中,A 账户向 B 账户转账 1000 元,转账前后两个账户的总余额必须保持不变,若出现总余额增加或减少的情况,即违反了一致性要求。
2.3 隔离性(Isolation)
隔离性指多个事务并发执行时,事务内部的操作与数据对其他事务是隔离的,事务之间不会互相干扰。隔离性的核心是控制事务之间的可见性,不同的隔离级别对应不同的隔离强度,隔离性越高并发性能越低,两者呈反向 trade-off 关系。例如多个用户同时抢购同一商品时,隔离性保证每个用户的扣减库存操作不会互相干扰,不会出现超卖的情况。
2.4 持久性(Durability)
持久性指事务一旦提交成功,其对数据库的修改会永久保存,即使系统发生宕机、断电等故障,提交后的修改数据也不会丢失。其底层实现依赖数据库的 Redo 日志(重做日志),事务提交前所有修改操作的记录会先持久化写入 Redo 日志,再更新内存中的数据页,系统重启时可通过 Redo 日志恢复未写入磁盘的已提交修改。例如用户支付成功提交事务后,即使服务器立刻宕机,重启后支付记录仍然存在,不会出现支付成功但订单显示未支付的问题。
 事务 ACID 特性关系与实现依赖示意图
事务 ACID 特性关系与实现依赖示意图
三、并发访问的典型问题分析
多事务并发访问同一数据对象时,若未加控制会产生三类数据一致性问题,三类问题的严重程度依次降低:
3.1 丢失更新
丢失更新指两个事务同时读取同一数据并进行修改,后提交的事务的修改结果覆盖了先提交的事务的修改结果,导致先提交事务的更新丢失。例如事务 T1 和 T2 同时读取商品库存为 100,T1 扣减 10 后将库存更新为 90 并提交,T2 扣减 20 后将库存更新为 80 并提交,最终库存为 80,丢失了 T1 扣减的 10 件库存。该问题属于最严重的并发问题,会直接导致业务数据错误。
3.2 读 "脏" 数据
读 "脏" 数据指一个事务读取了另一个事务尚未提交的修改数据,若后续该修改被回滚,会导致当前事务读取到的数据是无效的。例如事务 T1 修改商品库存为 90 但尚未提交,事务 T2 读取库存为 90,随后 T1 因异常回滚,库存恢复为 100,此时 T2 读取到的 90 就是脏数据,基于该数据的后续操作会出现错误。
3.3 不可重复读
不可重复读指一个事务内多次读取同一数据对象,在两次读取之间有其他事务对该数据进行了修改并提交,导致同一事务内两次读取的结果不一致。例如事务 T1 第一次读取商品库存为 100,此时事务 T2 扣减 10 并提交,T1 第二次读取库存为 90,同一个事务内两次读取结果不同,违反了事务的隔离性要求。部分场景下还会衍生幻读问题:同一事务内两次执行相同的范围查询,第二次查询返回了第一次没有的新数据,属于不可重复读的特殊场景。
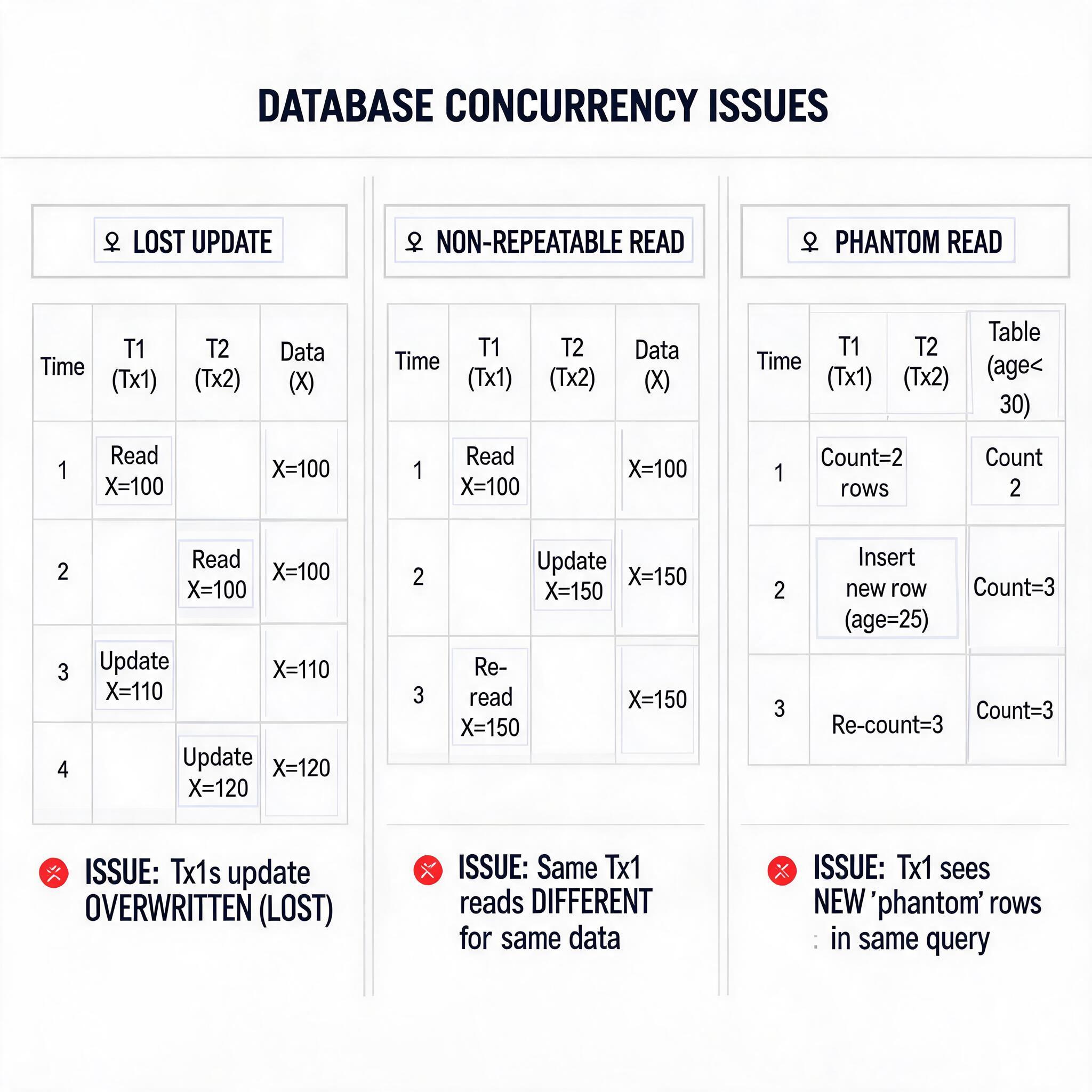 三类并发问题执行时序对比示意图
三类并发问题执行时序对比示意图
四、封锁机制核心设计
封锁是实现并发控制的核心技术,通过对数据对象施加不同类型的锁,限制其他事务对该数据的访问权限,从根源上避免并发问题的产生。
4.1 锁的类型与工作机制
当前主流关系型数据库均实现两类基础锁:
(1)X 锁(排他锁 / 写锁):事务 T 对数据对象 R 加 X 锁后,仅允许 T 读取和修改 R,其他任何事务都不能再对 R 施加任何类型的锁,直到 T 释放 X 锁。X 锁采用独占访问模式,保证同一时间只有一个事务可以修改数据,适用于写操作场景。
(2)S 锁(共享锁 / 读锁):事务 T 对数据对象 R 加 S 锁后,仅允许 T 读取 R,其他事务可以同时对 R 施加 S 锁进行读取,但不能施加 X 锁进行修改,直到 T 释放 S 锁。S 锁采用共享访问模式,保证同一时间可以有多个事务并行读取数据,但读取过程中数据不会被修改,适用于读操作场景。
4.2 三级封锁协议
三级封锁协议通过定义不同的加锁要求和锁释放时机,实现不同强度的隔离级别,对应解决不同的并发问题:
(1)一级封锁协议:核心规则为事务修改数据前必须先加 X 锁,直到事务结束(提交或回滚)才释放 X 锁,读数据时不需要加锁。该协议可以完全防止丢失更新问题,但因为读操作不加锁,无法避免读脏数据和不可重复读问题,对应 SQL 标准中的读未提交隔离级别。
(2)二级封锁协议:在一级封锁协议的基础上,新增规则为事务读取数据前必须先加 S 锁,读取完成后立即释放 S 锁。该协议在防止丢失更新的基础上,由于读数据时加 S 锁,其他事务无法对数据加 X 锁修改,因此可以防止读脏数据问题,但因为读取完成就释放 S 锁,事务后续再次读取时可能出现数据被修改的情况,无法避免不可重复读问题,对应 SQL 标准中的读已提交隔离级别。
(3)三级封锁协议:在一级封锁协议的基础上,新增规则为事务读取数据前必须先加 S 锁,直到事务结束才释放 S 锁。该协议可以同时防止丢失更新、读脏数据、不可重复读三类问题,因为事务全程持有读取数据的 S 锁,其他事务无法修改数据,对应 SQL 标准中的可重复读隔离级别。若需要进一步防止幻读,需要在此基础上增加范围锁机制。
| 封锁协议等级 | 加锁要求 | 锁释放时机 | 可防止的并发问题 | 对应 SQL 隔离级别 |
|---|---|---|---|---|
| 一级封锁协议 | 修改前加 X 锁 | 事务结束释放 X 锁 | 丢失更新 | 读未提交 |
| 二级封锁协议 | 一级基础上,读取前加 S 锁 | 事务结束释放 X 锁,读取完成释放 S 锁 | 丢失更新、读脏数据 | 读已提交 |
| 三级封锁协议 | 一级基础上,读取前加 S 锁 | 事务结束释放 X 锁和 S 锁 | 丢失更新、读脏数据、不可重复读 | 可重复读 |
 三级封锁协议规则与能力对比表
三级封锁协议规则与能力对比表
五、两段锁协议与可串行化调度
5.1 两段锁协议核心规则
两段锁协议(Two-Phase Locking, 2PL)是保证事务调度可串行化的充分条件,要求所有事务的锁操作必须分为两个阶段:
(1)扩展阶段(加锁阶段):事务在对任何数据进行读写操作之前,首先要申请并获得对应数据的锁,该阶段只能申请加锁,不能释放任何锁。
(2)收缩阶段(解锁阶段):事务一旦释放任何一个锁之后,就进入收缩阶段,该阶段只能释放已经持有的锁,不能再申请任何新的锁。
例如事务 T 的锁操作序列为:加 S 锁 (A)→加 X 锁 (B)→读 (A)→写 (B)→释放 S 锁 (A)→释放 X 锁 (B),符合两段锁协议;若锁操作序列为:加 S 锁 (A)→读 (A)→释放 S 锁 (A)→加 X 锁 (B)→写 (B)→释放 X 锁 (B),则不符合两段锁协议,因为释放 S 锁 (A) 后又申请了 X 锁 (B)。
5.2 可串行化保证原理
可串行化调度指多个并发事务的调度执行结果,与这些事务按某一顺序串行执行的结果完全一致,是并发调度正确性的最高标准。两段锁协议保证可串行化的核心逻辑是:所有事务的加锁操作都在解锁操作之前,因此不会出现两个事务交叉持有对方需要的锁并进行修改的情况,调度执行的结果等价于按事务加锁完成的顺序串行执行的结果。
需要注意的是,两段锁协议是可串行化的充分条件而非必要条件,即存在不遵守两段锁协议但仍然是可串行化的调度;同时两段锁协议无法避免死锁问题,因为多个事务可能在扩展阶段互相等待对方持有的锁,形成循环等待。
5.3 两段锁协议的工业实现
当前主流关系型数据库如 MySQL InnoDB、PostgreSQL 等均基于两段锁协议实现并发控制,同时对基础 2PL 进行了优化:
(1)严格两段锁协议(Strict 2PL):要求事务持有的所有 X 锁必须在事务提交后才能释放,避免其他事务读取到未提交的修改数据,是工业界的主流实现方案。
(2)强两段锁协议(Rigorous 2PL):要求事务持有的所有 X 锁和 S 锁都必须在事务提交后才能释放,实现了最高级别的隔离性,对应 SQL 标准中的可串行化隔离级别。
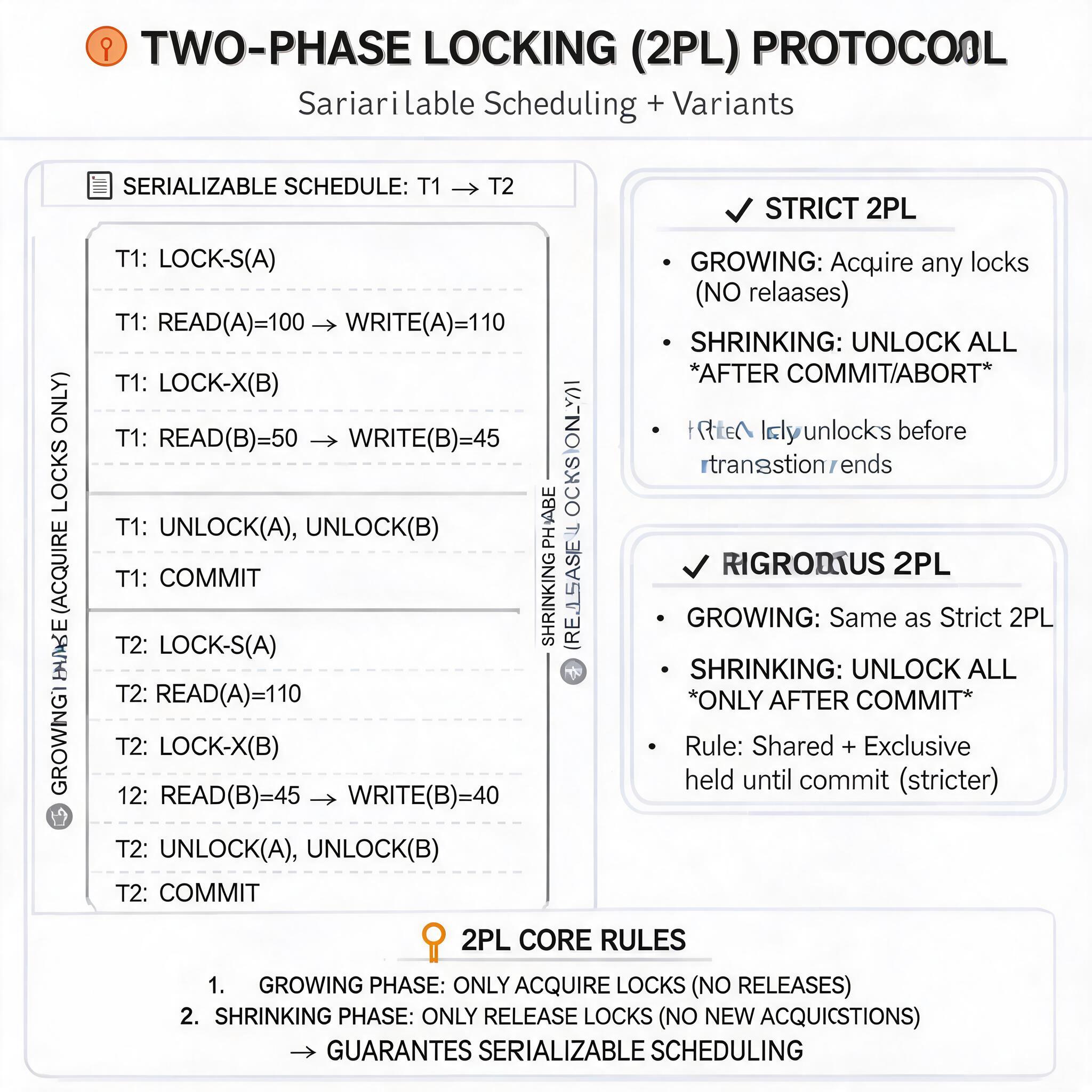 两段锁协议执行流程与可串行化调度示例图
两段锁协议执行流程与可串行化调度示例图
六、前沿发展与趋势
6.1 现有封锁机制的局限性
传统封锁机制的核心局限性在于锁开销大、并发性能受限,高并发写场景下大量锁竞争会导致系统吞吐量急剧下降,同时死锁问题需要额外的检测与恢复机制,增加了系统复杂度。
6.2 新兴并发控制技术
当前主流的替代技术方向包括:
(1)多版本并发控制(MVCC):通过为每个修改保留多个数据版本,读操作不需要加锁,写操作也不阻塞读操作,大幅提升读密集场景的并发性能,当前 MySQL、PostgreSQL 等主流数据库均已实现 MVCC 与封锁机制结合的混合并发控制方案。
(2)乐观并发控制(OCC):基于数据版本校验机制,事务执行过程中不加锁,提交时检查是否有其他事务修改了相关数据,若无冲突则提交,有冲突则回滚,适用于冲突概率低的高并发场景,广泛应用于分布式数据库系统。
6.3 软考考点趋势
近年来软考考试中该知识点的考察逐渐向应用场景倾斜,案例分析题常出现结合电商、金融等业务场景,要求选择合适的封锁协议、设计并发控制方案的题型,同时 MVCC 与封锁机制的对比分析也成为高频考点。
七、总结与备考建议
7.1 核心知识点提炼
(1)事务 ACID 特性中,原子性是执行基础,一致性是最终目标,隔离性是并发控制的核心,持久性是故障安全保证,四个特性缺一不可。
(2)三类并发问题的严重程度依次为丢失更新 > 读脏数据 > 不可重复读,三级封锁协议分别对应解决不同级别的问题,隔离强度与并发性能呈反向关系。
(3)两段锁协议是可串行化调度的充分条件,分为扩展和收缩两个阶段,工业界普遍采用严格两段锁协议实现,无法避免死锁问题。
7.2 软考考试重点提示
(1)高频考点:三级封锁协议的规则与可解决的并发问题对应关系、两段锁协议的判断、并发问题的场景识别。
(2)易错点:二级封锁协议仅释放读锁的时机、两段锁协议与可串行化的关系、X 锁与 S 锁的兼容性判断。
7.3 实践应用建议
(1)业务场景选型:金融核心交易系统要求强一致性,采用三级封锁协议或可重复读隔离级别;内容管理等读多写少系统,采用二级封锁协议或读已提交隔离级别,平衡一致性与性能。
(2)性能优化:高并发场景下尽量缩小事务粒度,减少锁持有时间,避免长事务导致的锁竞争,必要时结合 MVCC、乐观锁等技术提升并发性能。
(3)死锁规避:事务按统一顺序申请锁,设置锁超时时间,定期检测死锁并终止权重低的事务恢复系统可用性。