
🎯 博主简介
CSDN 「新星创作者」 ,人工智能技术领域博主,码龄 5 年 ,累计发布
190+ 篇原创文章,博客总访问量30万+浏览。
🚀 持续更新 AI 前沿实战知识,专注于 AI 技术实战、RAG 系统、Agent 应用开发与大模型工程化落地。目前主要更新方向包括:
- 🦞 最新 OpenClaw 教程 ---从入门到精通|AI 智能助手/自动化/Skills 实战(原 Clawdbot/Moltbot)
- ✨ Agent 记忆系统 --- 长期记忆、上下文管理与个性化智能体设计
🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥以下系列正在火热更新中🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥- 📘 图解机器学习合集 --- 用图解方式系统梳理机器学习核心概念,持续更新中
同时也会持续分享 AI 编程、Java 后端、Spring 生态、Transformer、大模型基础、计算机视觉 等方向内容,内容会尽量结合自己的学习记录、项目实践和踩坑经验来整理。
📱GZH:安逸Ai(科技前沿新闻,Github热门项目,最新免费资料...)- 网页观看完整系列合集:🌐 Anyi AI 学习资源站
分类模型怎么评估?准确率、精确率、召回率和 F1
上回聊完过拟合和欠拟合,你应该已经知道了模型太复杂或太简单会出什么问题。
但这里有个更根本的问题还没解决:模型训练完了,你怎么知道它到底好不好?
很多人会说"看准确率啊"。但准确率这东西,有时候会骗人。
为什么准确率会骗人?
准确率的计算很简单:正确预测的样本数 ÷ 总样本数。
比如100个样本,预测对了95个,准确率就是95%。听起来很直观对吧?
问题出在哪?出在数据可能本身就不平衡。
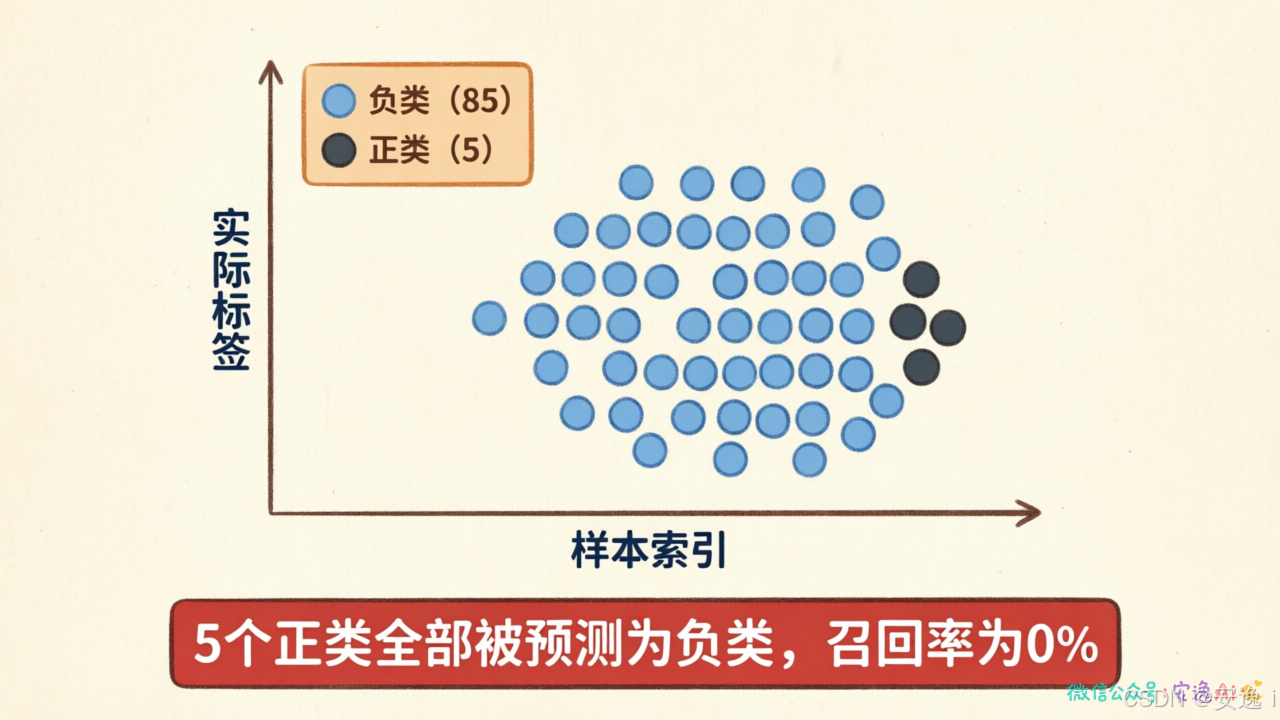
假设你做了一个垃圾邮件分类模型,测试数据里有99封正常邮件、1封垃圾邮件。模型偷了个懒------全部预测为正常邮件。
你猜准确率是多少?
99%。
吓人不?准确率99%的模型,实际上把唯一的垃圾邮件漏掉了。
医生诊断癌症也是同样道理。如果100个病人里只有5个真正患病,医生全部诊断为"没病",准确率还是95%,但这意味着他漏掉了所有真正的病人。
所以准确率高,不代表模型真的好。你还得知道它"错在哪里"。
混淆矩阵------模型预测的"体检报告"
想全面了解模型表现,你需要一张"体检报告"。
这就是混淆矩阵。
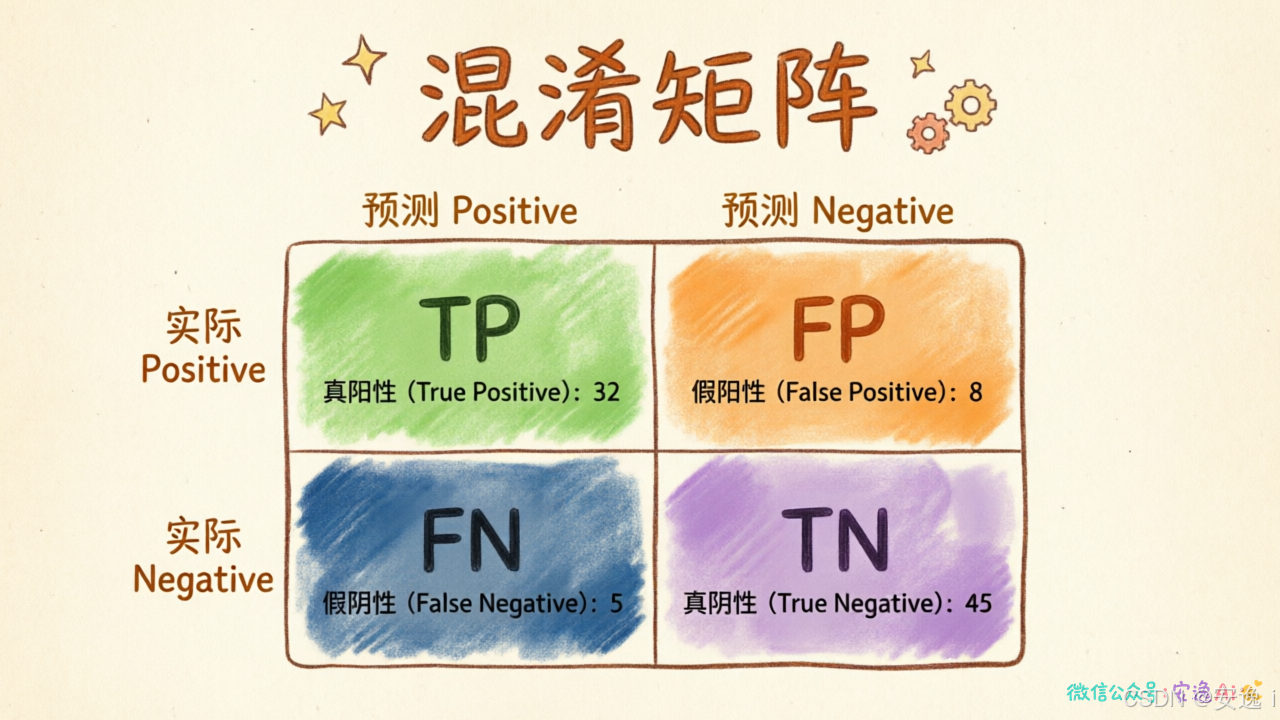
它把预测结果分成四个格子,每个格子代表一种情况:
- TP(True Positive):实际是正类,预测也是正类。命中。
- FP(False Positive):实际是负类,预测却是正类。误报。
- FN(False Negative):实际是正类,预测却是负类。漏检。
- TN(True Negative):实际是负类,预测也是负类。正确排除。
知道这四个数字之后,你就能算出一堆更有用的指标了。
我第一次看混淆矩阵的时候,觉得这东西挺反直觉的------为什么要把预测结果这么拆开来?但用多了就发现,这种拆法确实管用,能把模型的"性格"看得清清楚楚。
精确率------"宁缺毋滥"的谨慎派
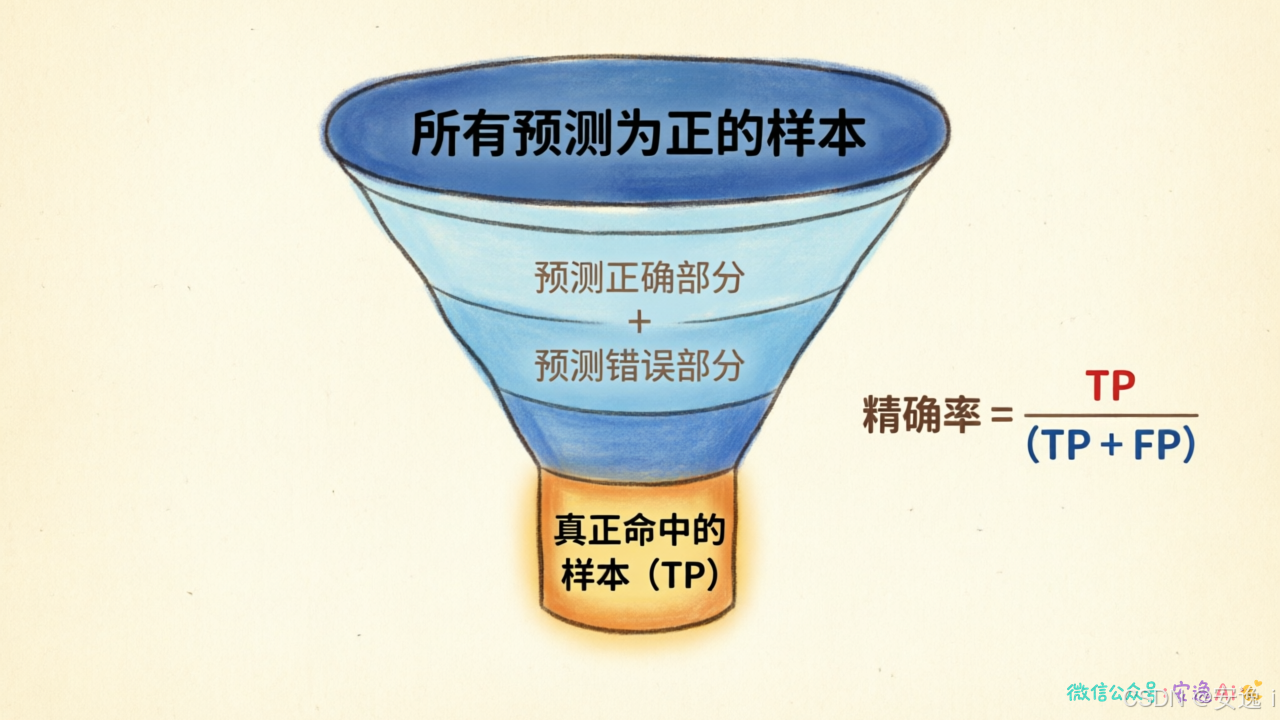
第一个指标叫精确率,英文叫 Precision。
公式是:TP ÷ (TP + FP)
翻译成人话就是:预测为正的样本里,有多少是真的正类?
这个指标回答的是"我预测的这些positive,有多少是靠谱的?"
典型的应用场景是垃圾邮件检测。
你肯定不想把重要邮件误删对吧?所以宁可少标记一些垃圾邮件,也不能冤枉好邮件。
这时候就要看重精确率。
你可以把它想象成一个严格的面试官。宁可是少招几个人,也不愿招错一个------毕竟招进来容易,想开除可就难了。
精确率越高,误报越少。
我自己做垃圾邮件分类项目的时候,初期模型精确率只有60%多,一堆正常邮件被误标为垃圾邮件,用户投诉不断。后来花了不少功夫调优,才把精确率提到90%以上,这下才稳住了。
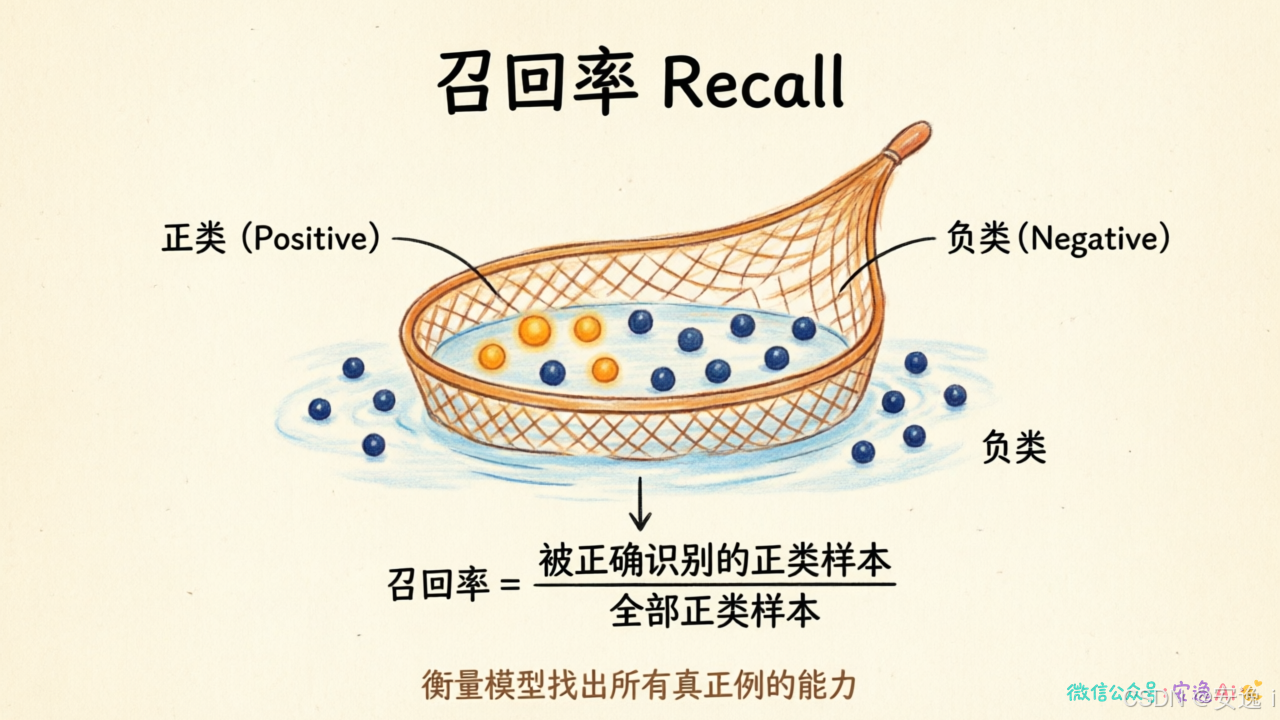
召回率------"宁错不漏"的全面派
第二个指标叫召回率,英文叫 Recall。
公式是:TP ÷ (TP + FN)
翻译成人话就是:所有实际为正的样本里,有多少被我正确预测出来了?
这个指标回答的是"所有真正的positive,我找到了多少?"
典型的应用场景是医学诊断。
你想啊,癌症早期筛查,宁可多查出来几个疑似,也不能漏掉一个真的癌症患者。漏掉一个,可能就是一条命。
安全监控、地震预警这些场景也是一个道理------你可以接受一些误报,但绝对不能漏掉真正的危险。
召回率越高,漏检越少。
你可以把它想象成一个尽职的搜查官。宁可误伤,也不能放过------保证所有嫌疑人都被排查一遍。
F1------精确率和召回率的调和大师
问题来了:精确率和召回率,有时候是矛盾的。
你想抓更多坏人,召回率就高了,但误报也会增多,精确率就下降。
你想减少误报,精确率就高了,但可能漏掉一些坏人,召回率又下去了。
鱼和熊掌怎么兼得?
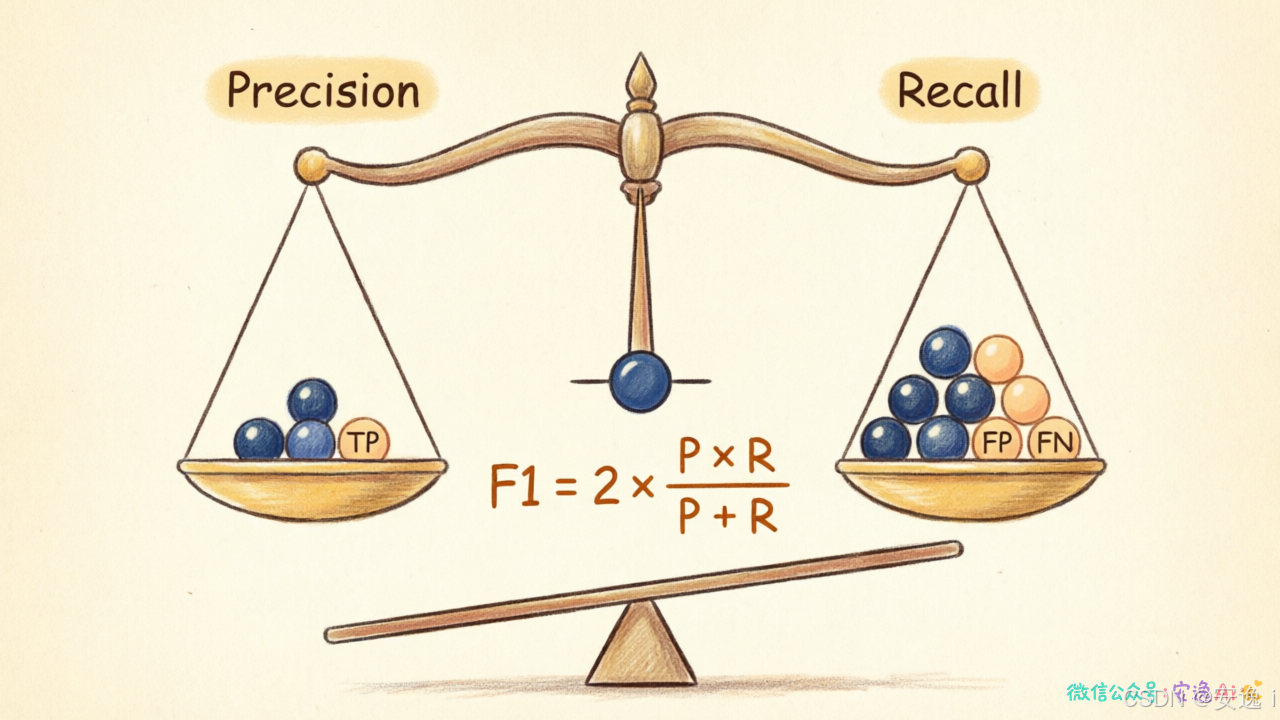
F1 score 就登场了。
公式是:2 × (精确率 × 召回率) ÷ (精确率 + 召回率)
你发现没有,这其实是调和平均,不是简单的算术平均。
为什么用调和平均?
因为调和平均对极端值特别敏感。如果精确率是100%但召回率只有10%,算术平均还能凑个55分,调和平均就只有18分------直接拉低总分。
这样就能逼着你不能瘸腿走路,必须两项都兼顾。
你可以把F1想象成一个追求平衡的裁判。他既不能太严格导致误判(精确率低),也不能太宽松放过问题(召回率低)。
当业务需要在"查得准"和"查得全"之间找平衡时,F1就是首选。
我之前做过一个内容审核的项目,就是用的F1来评估------既要拦住违规内容,又不能误杀太多正常内容。单独看精确率或召回率都不够用,F1才是关键。
实战------用sklearn一键计算
学完理论,当然要上手试试。
sklearn 给提供了四个函数,一行代码就能算出来:
python
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 假设y_true是真实标签,y_pred是模型预测
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"准确率: {accuracy:.2f}")
print(f"精确率: {precision:.2f}")
print(f"召回率: {recall:.2f}")
print(f"F1分数: {f1:.2f}")你可能还看到过这些函数有个叫 average 的参数,可以选 macro、micro、weighted:
macro:分别计算每个类别的指标,然后取平均micro:把所有样本放在一起算weighted:按每个类别的样本数加权平均
多分类问题一般用 macro,二分类用 binary 就够了。
选哪个指标,不是拍脑袋决定的,是看你的业务场景。
垃圾邮件检测看重精确率。医学诊断看重召回率。两个都重要但又不能偏废,就用F1。
没有最好的指标,只有最适合你的指标。

说到底,评估指标本质上是在问一个问题:你更不能接受哪种错误?
漏掉一个癌症患者,还是误诊一个健康人?
这个问题没有标准答案。你做的业务不一样,答案就不一样。