本文写于2026年6月。所有性能数据均为基于公开技术参数的工程估算,除非特别标注;所提及系统多为研究原型或早期试点,具身智能(通用操作机器人)的万台级商业成熟仍在验证中。
引言:多线并行的架构演进
具身智能(Embodied AI)正经历一场深刻的架构范式战争。这不是简单的"新淘汰旧"的技术迭代,而是关于智能应如何组织、分布在何处、以何种方式与物理世界交互的根本性分歧。
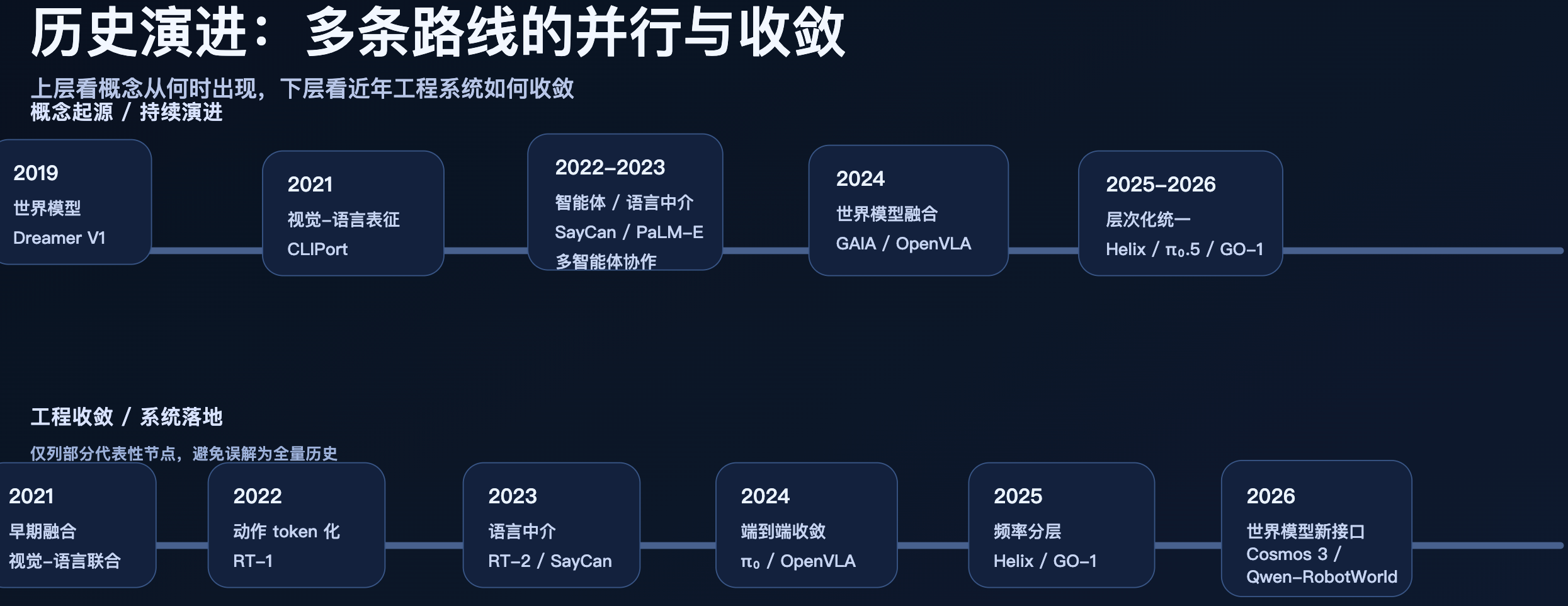
过去十年,具身智能架构在多条路线上并行演进,而非单线替代。端到端融合路线 从CLIPort(2021)的视觉-语言表征起步,经RT-1(2022)的动作token化,到RT-2(2023)和π₀(2024)实现视觉-语言-动作的直连映射;语言中介路线 从SayCan(2022)的LLM规划与价值函数落地,经PaLM-E(2023)的多模态具身推理,探索用自然语言作为感知与动作之间的桥梁。世界模型路线 自DreamerV1(2019)起独立发展,直到2024-2026年才与VLA尝试深度融合。与此同时,云-边-端协同(2019-2021)早于VLA出现,始终作为底层基础设施存在,而非VLA的"后续增强"。
这些路线并非先后替代,而是在2024-2026年 convergent 向层次化统一架构:高层语义理解、中层规划推理、底层物理控制,无论其内部实现是端到端还是显式分层。
然而,与热闹的技术叙事形成鲜明对比的是产业现实的复杂性:截至2026年6月,通用操作机器人的万台级量产能力已获突破------智元于2026年3月实现第10,000台量产下线(第10,000台为远征A3),工信部亦于6月启动万台级规模落地专项行动。但万台级商业成熟(持续盈利、客户复购、ROI可验证的规模化商用)仍是行业待解命题。 量产是商业化的必要条件,而非充分条件。
这意味着,所有架构讨论都必须建立在一种清醒的不确定性之上:我们仍在探索,尚未找到圣杯。
一、历史演进:多条路线的并行与收敛
具身智能架构的演进并非一条直线,而是多条路线在时间上重叠、在空间上交织的网状历史。
1.1 分层架构的统治与局限(2000-2018)
以本田ASIMO、波士顿动力Atlas(液压版)为代表,系统被严格解耦为感知、规划、控制、执行层。ROS成为事实标准,专家知识被编码为无数if-else和有限状态机。这一时代的巅峰成就证明了确定性控制的可能性,但也暴露了其阿喀琉斯之踵:ASIMO耗资数亿美元却只能完成预编程动作,最终于2018年停止开发;传统分层架构在开放域的泛化成本呈指数级上升。ASIMO的终止(2018年)标志着纯规则分层架构在通用操作领域的阶段性终结。
1.2 端到端融合路线(2021-2024)
这条路线的核心信念是:视觉、语言、动作应在统一参数空间内融合,最小化模块间信息损失。
-
CLIPort(2021):将CLIP视觉表征与语言条件策略结合,用于机器人操作,奠定了"视觉-语言联合表征"的基础。
-
RT-1(2022):Google的机器人Transformer,首次将大规模机器人数据与Transformer架构结合,为RT-2奠定基础。
-
RT-2(2023.7):首个大规模VLA,将机器人动作作为文本token处理,实现了视觉-语言到动作的直连映射。
-
π₀ (Physical Intelligence, 2024.10):基于PaliGemma 3B + Flow Matching,在物理硬件上实现50Hz实时控制(官方数据),将端到端VLA推向 dexterous manipulation 的极限。
-
OpenVLA(Berkeley, 2024):开源VLA,基于Llama和DINOv2,降低了研究门槛。
-
Gato(DeepMind, 2022.5):1.2B参数通用ist Agent,跨604个任务(含机器人操作),代表了"单一模型做多任务"的通用ist方向早期探索,与后来的专用VLA形成技术张力。
这条路线带来了强大的语义泛化能力,但也引入了黑盒不可控性 和实时性瓶颈。
1.3 语言中介路线(2022-2023)
与端到端融合路线并行,另一条路线选择用自然语言作为感知与动作之间的显式桥梁,而非直接融合。
-
SayCan(Google, 2022.4):首个将LLM与机器人控制结合的系统,用LLM进行高层规划,通过价值函数将语言指令落地为机器人技能。这是"语言中介"范式的开端。
-
PaLM-E(Google, 2023.3):562B参数的多模态具身模型,将连续传感器数据融入LLM,实现具身推理。
-
VoxPoser(2023):从VLM提取3D affordance,用于零样本操作,展示了"语言→空间约束→动作"的间接路径。
-
Code as Policies(2022):用程序合成进行可解释规划,代表了"语言→代码→动作"的符号化中介路线。
这条路线的优势是可解释性 和模块化,但语言与物理动作之间的"语义鸿沟"始终存在------LLM理解的"轻轻放下"与机械臂需要的精确力矩之间,需要额外的翻译层。
1.4 世界模型路线:独立发展后的融合尝试(2019-2026)
世界模型的探索远早于VLA,但长期独立于机器人控制之外。
-
DreamerV1(DeepMind, 2019):基于潜在动力学的想象与规划,在仿真环境中表现优异,但仿真到现实的域差距(Sim-to-Real Gap)限制了直接应用。
-
GAIA-1(Wayve, 2023):自动驾驶场景的世界模型,主要用于预测,与具身操作机器人的场景差异显著。
-
LingBot-VA (蚂蚁灵波, 2026.1):采用MoT(Mixture-of-Transformers)架构,将视频token和动作token映射到统一潜空间,通过视频预测反推动作生成。这代表了世界模型与VLA的深度融合,与"世界模型作为独立增强模块"的传统思路不同。
-
Cosmos 3(NVIDIA, 2026.5.31):采用MoT架构(Reasoner + Generator),统一处理文本、图像、视频、环境音频和动作序列五种模态。Cosmos 3 Nano(16B)声称可部署于Jetson Thor系列平台(NVIDIA官方宣传),但其实际运行时的推理速度、功耗、散热表现尚无公开实测数据。
-
Qwen-RobotWorld (阿里, 2026.6.16):语言条件视频世界模型,采用60层双流MMDiT扩散Transformer,以自然语言作为跨操作/驾驶/导航/人→机迁移的统一动作接口。在EWMBench、DreamGen Bench等评测中取得领先成绩。这代表了**"世界模型作为规划信号"的新范式** ------不同于LingBot-VA的token级融合或Cosmos 3的多模态统一,Qwen-RobotWorld选择自然语言作为跨场景的统一接口。但需注意,EWMBench等榜单目前主要衡量视频生成的保真度(FVD)和文本对齐度,其在真实机器人上的物理推理(Physical Reasoning)泛化能力尚待物理实测验证;此外,其60层MMDiT的推理延迟、端侧可部署性、以及真实机器人部署表现,亦待社区验证。
1.5 云-边-端协同:被低估的基础设施(2019-至今)
云-边-端协同并非VLA时代的产物。2019年,《机器人4.0白皮书》提出了云-边-端融合的机器人系统愿景。2020-2021年,通用边缘计算框架开始成熟,但专门针对通用操作机器人的云控平台出现较晚。
在通用操作机器人领域,VLA的主流部署方式是端侧推理 (Figure Helix的S2(7B VLM)完全运行在嵌入式GPU上;π₀/π₀.5通过量化实现端侧50Hz实时控制)。云-边-端协同并非VLA的"默认选择",而是针对特定场景的备选方案。需要澄清的是:2022-2023年,端侧NPU确实难以承载7B+参数模型的实时推理,算力不足是云-边-端协同的早期核心驱动力 ;但2024-2026年,通过量化(INT4/INT8)、架构精简(如PaliGemma 3B)和专用NPU(Jetson Thor T5000),端侧VLA已能实现10-50Hz的"可用实时性"。当前云-边-端协同的新驱动力已从"跑不动"演变为成本优化、多机协同调度与知识持续更新------通用LLM/VLM的推理成本(非VLA专属)和世界模型等辅助模块的算力需求,可部署在云端与端侧VLA形成互补,而非替代。
1.6 收敛:层次化统一架构(2024-至今)
2024-2026年,面对纯端到端的实时性瓶颈和纯分层的泛化天花板,行业开始 convergent 向层次化统一架构:
-
π₀.5(2025.4):在端到端内部引入高层自回归语义规划(FAST token)+ 低层流匹配动作生成,是"端到端内层次化"的代表。
-
Figure Helix 02(2026.1):S0(10M, 1kHz)+ S1(80M, 200Hz)+ S2(7B, 7-9Hz)的三层频率分层,替代了109,504行手写C++代码。
-
智元GO-1/ViLLA(2025.3发布,9月开源):VLM + MoE(隐式规划器 + 动作专家),在端到端内部引入显式中间表示层。
-
NVIDIA GR00T(2025-2026):双系统架构(System 1快速反射 + System 2慢速推理)。
这些系统的共同特征是:不再纠结于"端到端还是混合"的二元对立,而是根据时间尺度(kHz/Hz/分钟级)和功能需求(物理反射/技能执行/任务规划)自然分层。
二、单节点架构:按复杂度分层
在讨论分布式协同之前,必须先厘清单节点内部 的组织逻辑。这是所有架构的地基。我们不再用"端到端vs混合"的二元对立分类,而是按架构复杂度分为三层。
2.1 分层架构(显式模块化)
核心哲学:物理世界的约束是刚性的,必须用显式规则保证安全。
技术栈:ROS2/ROS → MoveIt2/OmniPlanner → MPC/PID/阻抗控制 → EtherCAT/CAN总线。
真实状态:
-
✅ 工业自动化(汽车产线、3C装配)仍是绝对主流,年出货量以十万台计。
-
⚠️ 通用操作机器人 中,纯分层架构已边缘化。Figure、1X等AI-first公司的新系统倾向于自研中间件或绕过ROS,采用PyTorch推理后直接通过低级SDK下发指令。
-
⚠️ 宇树等厂商仍维护ROS/ROS2集成(GitHub开源项目可验证),但新一代系统也在探索直接推理+驱动路径。ROS不会消亡,但在前沿具身智能公司中的地位从"核心中间件"降级为"遗留接口"或"仿真工具"。
性能基准(工程估算):
-
控制环延迟:1-10 ms(确定性,基于控制理论)
-
任务级泛化:极低,跨任务需重新编程
适用边界:结构化环境、安全关键场景、预算充足且任务固定的工业部署。
2.2 端到端原生架构(单一网络)
核心哲学:智能是涌现的,只要数据足够,单一神经网络自会学会从感知到动作的映射。
代表系统:
-
RT-2(Google, 2023):首个大规模VLA,将机器人动作作为语言token处理。
-
π₀原始版(Physical Intelligence, 2024.10):基于PaliGemma 3B + Flow Matching,单一网络直接映射像素+语言到力矩,实现50Hz实时控制。
-
OpenVLA(Berkeley, 2024):开源VLA,基于Llama和DINOv2。
关键挑战:
-
实时性瓶颈 :7B-13B参数模型在端侧NPU上的单步推理约为50-200 ms(batch=1,分辨率依赖),相对于底层控制所需的1-10ms存在1-2个数量级差距,限制了控制频率。这也是2022-2023年云-边-端协同讨论兴起的直接物理原因;2024年后通过量化与架构优化,端侧VLA已逐步达到"可用实时性"(见1.5节)。
-
OOD脆弱性:对物理常识的推理(如"虚掩门需要多大力推开")仍显不足。
-
黑盒风险:概率模型的"幻觉"在物理世界意味着安全事故。
性能基准(基于公开参数推断):
-
单步推理延迟:50-500 ms
-
训练成本:数十万至数百万美元
适用边界:非结构化环境、自然语言交互优先、对实时性要求不极端的场景。
2.3 层次化统一架构(多层融合)
核心哲学 :不再纠结"端到端还是混合",而是根据时间尺度和功能需求自然分层。这些系统的共同趋势是**"端到端"与"混合"的边界正在消失**,行业正在向层次化统一架构收敛。

代表系统:
-
π₀.5 (Physical Intelligence, 2025.4):引入FAST(Frequency-space Action Sequence Tokenization) ------将连续动作轨迹转为离散token,高层自回归预测语义动作token,低层可选Flow Matching去噪。这是端到端内部的层次化推理。
-
π₀.7 (Physical Intelligence, 2026.4):研究阶段,聚焦组合泛化(compositional generalization),首次在端到端VLA中展现出组合泛化的初步迹象。其架构已显著偏离传统"端到端"定义,引入了显式的高层策略模块、世界模型模块和8.6亿参数的动作专家,与Figure Helix的三层频率分层在"高层慢速推理+低层快速反射"的时间尺度分层逻辑上呈现趋同,但具体实现机制差异显著:规模上(8.6亿 vs 1000万)、训练目标上(组合泛化 vs 全身控制)、接口设计上(隐式 vs 显式频率分界)均不同。这种趋同表明行业正在探索频率分层作为统一架构原则,但最优分层粒度仍是开放问题。
-
Figure Helix / Helix 02:
-
原始Helix(2025.2):S1(80M, 200Hz)+ S2(7B, 7-9Hz)
-
Helix 02(2026.1) :新增S0(10M, 1kHz),替代109,504行手写C++代码(Figure官方博客数据),基于1000+小时人类运动数据训练。S0以1kHz管理平衡和接触力,使机器人首次实现全身自主控制。
-
-
智元GO-1/ViLLA(2025.3发布,9月开源) :采用VLM + MoE(隐式规划器Latent Planner + 动作专家Action Expert)的三层架构。隐式规划器将VLM输出压缩为latent action token,再由动作专家解码为具体控制信号。这代表了**"端到端内部层次化"的另一种技术路线**------与π₀.5的自回归token预测不同,GO-1使用隐式规划器作为中间表示。
-
NVIDIA Isaac GR00T(2025-2026):双系统架构(System 1快速反射 + System 2慢速推理),基于20,000+小时人类自我中心视频(EgoScale)和Isaac Sim合成数据训练。
性能基准(工程估算):
-
底层控制环:< 10 ms
-
高层规划:100-500 ms(异步,非每步调用)
优势 :在安全性与泛化性之间取得平衡,是目前最务实的工程路径。
劣势:系统集成复杂度极高,不同层次间的接口设计(如如何将VLA的语义输出转化为MPC的可行域约束)仍是开放问题。若采用纯神经底层(如Helix S0以10M参数神经网络替代109,504行手写C++代码),需具备极强的数据闭环与仿真验证能力,当前多数团队尚不具备此条件。
三、智能的分布拓扑:云、边、端的部署形态
当单节点架构确定后,下一个关键问题是:智能应部署在何处? 这不仅是技术问题,更是成本、隐私、可靠性的权衡。
3.1 架构组合的统一分析框架
所有"云-边-端"排列组合,都可以用三个维度解构:
| 维度 | 选项 |
|---|---|
| 计算位置 | 端侧(On-Device) / 边侧(Edge Gateway) / 云端(Cloud) |
| 智能粒度 | 单体模型 / 单智能体 / 多模型协作 / 多智能体 |
| 增强模块 | 无 / 世界模型(World Model) / 工具调用(Tool Use) |

基于此,我们可系统分析主流组合:
组合A:以端侧VLA为主的自治架构
-
定位:VLA(Vision-Language-Action)是当前端侧自治架构的核心------它将视觉感知、语言理解和动作生成统一在单一参数空间内,避免了模块化架构的接口信息损失。端侧部署对NPU算力要求极高,且控制频率与模型规模之间存在根本性张力。
-
代表 :Figure 02(Helix 02的三层VLA架构 :S0全身控制10M/1kHz + S1视觉运动策略80M/200Hz + S2语义推理7B/7-9Hz,全部或主要运行在端侧GPU)。语音等自然语言指令通常经端侧ASR编码为文本token后输入VLM/VLA,与视觉模态统一表征,而非外挂独立ASR模块。
-
成本:硬件要求高(需NPU,如Jetson Orin级),但无网络/云端费用。
-
延迟:控制环<10ms,VLA推理50-200ms。
-
现状:实际任务复杂度有限,多为演示级或特定场景。
组合B:端侧+云端协同
-
定位 :当前最主流的产业实践方向。
-
分工 :端侧负责高频感知与反射控制(含视觉感知与语音等自然语言输入预处理),云端负责低频语义规划与知识检索("大脑")。
-
通信模式:端→云上传关键帧/状态摘要;云→端下发任务指令/策略。
-
成本结构:端侧固定硬件成本 + 云端按调用计费的可变成本,总体TCO通常低于纯端侧大模型。
-
延迟:任务级(秒级)由云端处理,控制级(毫秒级)由端侧保证。
-
代表 :特斯拉FSD是自动驾驶领域 端云协同的先驱(2020年前后)。在通用操作机器人领域,云-边-端协同的讨论在2023-2024年增多,但驱动力并非'VLA模型太大无法端侧部署'------事实上,VLA的核心卖点恰恰是端侧实时性。云-边-端协同的驱动力是成本优化、多机协同、知识更新等场景需求,与VLA本身的部署瓶颈无关。
组合C:感知解耦(端侧CV/ASR等小模型 + 云端LLM/VLM)
-
定位:成本最低方案。
-
技术栈 :YOLO/OpenCV/ASR(端侧感知预处理)→ 结构化数据上传 → 云端LLM(语义理解+任务规划+动作决策)。此方案中端侧通常仅有CV和ASR,无TTS、触觉编码器等多模态输出能力,语义天花板极低。核心特征是决策权完全在云端:端侧仅做感知预处理,所有语义理解、任务规划、动作决策均由云端LLM完成。网络中断即失效,延迟瓶颈在网络往返(100ms-数秒)。
-
成本:端侧无需NPU,普通ARM芯片即可。
-
局限:语义天花板极低,无法理解跨模态(如"那个有点旧的红色杯子")描述。
-
适用:工业流水线(固定场景)、低端IoT。
组合D:端侧模块化协作(VLM语义 + CV定位 + 确定性控制器)
-
定位 :传统分层架构的现代演进,用VLM(或融合语音模态的多模态模型)替代人工规则进行语义理解,用CV模型替代传统视觉算法进行定位。本质上是**"分层架构的AI化升级"**。
-
技术栈:
-
VLM/LLM(或融合语音模态的多模态模型)负责语义理解 :"把那个红色的、有点旧的杯子拿给我";语音指令经端侧ASR预处理后输入VLM。核心特征是语义决策权下沉到端侧:VLM在端侧完成"哪个杯子""放哪里"的语义判断,仅把像素级定位交给CV模型。断网仍可执行已理解的任务,延迟瓶颈在端侧VLM推理(100-500ms)而非网络。
-
YOLO/检测模型负责像素级定位:输出红色杯子的bbox和深度
-
两者通过结构化接口(如JSON/ROS topic)传递信息
-
PID/MPC等确定性控制器 负责底层闭环控制
-
-
与组合A的区别:
-
组合D使用VLM(视觉-语言模型)进行语义理解,但不直接输出动作
-
组合A使用VLA(视觉-语言-动作模型)统一感知与动作生成
-
两者的选择取决于任务复杂度与可解释性需求的权衡
-
-
与组合C的区别:
-
组合D的决策权完全在云端 :语义决策权下沉到端侧,VLM在端侧完成"哪个杯子""放哪里"的语义判断,仅把像素级定位交给CV模型。断网仍可执行已理解的任务,延迟瓶颈在端侧VLM推理(100-500ms)而非网络。
-
组合的决策权完全在云端:端侧仅做感知预处理,所有语义理解、任务规划、动作决策均由云端LLM完成。网络中断即失效,延迟瓶颈在网络往返(100ms-数秒)。
-
两者的选择取决于任务复杂度与可解释性需求的权衡
-
-
优势:
-
VLM无需处理像素级定位,CV模型无需理解语义,各用其长
-
端侧VLM可以是轻量级(3B-7B),CV模型是常规目标检测,硬件成本可控
-
模块化调试,单点故障可隔离
-
-
劣势:
-
接口设计复杂,语义输出到CV输入的翻译层需人工设计
-
误差在模块间传递(VLM理解错→CV检测对也白搭)
-
无法处理需要视觉-语言深度融合的模糊指令(如"把那个看起来不太稳的杯子放到安全位置")
-
-
适用:中等复杂度、语义与定位可分离的场景(如仓储分拣、简单服务)。
组合E:端侧Agent(工具调用)+ 确定性控制器
-
定位:分层架构的Agent化演进。
-
核心机制:端侧LLM通过ReAct/CoT循环调用工具(如调用视觉API、机械臂SDK、计算器)。
-
延迟 :每步ReAct循环需数百毫秒至数秒,不适合高频闭环。
-
现状:研究原型为主,端侧7B以下模型的工具调用能力有限。
组合F:分布式联邦多智能体 + 确定性控制器 + 云端智能体
-
定位:去中心化的自主协作,无中央调度节点,Agent间通过协商达成共识。
-
注意区分:集中式调度的多机协作(如亚马逊Kiva、极智嘉Geek+)已在仓储、工厂场景成熟商用,但那是传统调度算法,非AI多智能体。本组合仅指分布式联邦形态。
-
挑战:CAP定理、一致性、故障恢复等分布式系统难题;Agent间通信引入不可控延迟。
-
现状 :纯研究阶段,无知名大规模商业产品。
四、增强模块:世界模型与智能体------前沿还是泡沫?
4.1 世界模型(World Model):从视频生成到物理推理
核心承诺:在"脑内"维护一个可交互的物理世界表征,支持反事实推理("如果我不这样做会怎样?")和长程规划。
技术现状与路线分化:
-
生成式路线:Sora(OpenAI)、GAIA-1(Wayve, 2023)------主要用于自动驾驶场景预测,与具身操作机器人的世界模型场景差异很大。
-
基于模型RL路线:DreamerV3------在仿真环境中表现优异,但仿真到现实的域差距(Sim-to-Real Gap)仍未解决。
-
融合路线:
-
LingBot-VA(蚂蚁灵波, 2026.1):采用MoT架构将视频token和动作token映射到统一潜空间,通过视频预测反推动作生成。代表"潜空间融合"方向。
-
Cosmos 3(NVIDIA, 2026.5.31):采用MoT架构(Reasoner + Generator),统一处理五种模态。代表"多模态统一"方向。
-
Qwen-RobotWorld (阿里, 2026.6.16):语言条件视频世界模型,以自然语言作为跨操作/驾驶/导航/人→机迁移的统一动作接口。代表**"语言接口统一"方向**------世界模型不直接输出动作,而是输出自然语言规划信号,由下游控制器执行。在EWMBench等评测中领先,但其60层MMDiT的推理延迟、端侧可部署性、以及真实机器人部署表现,尚待社区验证。
-
工程现实:
-
世界模型训练需海量视频与交互数据,成本极高。
-
推理时需额外维护世界状态,延迟通常在数百毫秒至数秒(推测,无公开实测)。
-
落地路径分化 :世界模型的部署形态可分为两种。模块化世界模型 (世界模型作为独立仿真器,为策略提供预演数据,与执行策略解耦)的落地难度显著低于统一世界模型(世界模型与策略融合),因为策略训练可沿用成熟VLA框架,世界模型仅作为数据增强模块。
-
结论 :世界模型是具身智能的"圣杯方向",但目前处于研究早期,距离工程化落地有显著距离。四条技术路线(生成式、RL、潜空间融合、多模态统一、语言接口统一)并行探索,尚未收敛。
4.2 智能体:单智能体的工程现实与多智能体的协作理想
单智能体(Single Agent)是当前具身智能最主流的工程形态------Figure Helix 02、π₀.5、智元GO-1本质上都是一个具备感知-规划-行动闭环的自主决策实体。其核心机制可分为两条路线:VLA-based (端到端感知-行动映射,如π₀.5)与LLM-based(显式ReAct/CoT循环调用工具,如组合E的端侧Agent+PID)。前者泛化性强但黑盒,后者可解释但延迟高(每步ReAct循环数百毫秒至数秒)。端侧7B以下模型的工具调用能力有限,幻觉问题在物理世界意味着安全事故。当单智能体无法胜任复杂任务分解时,才需要多智能体协作------但这正是当前工程的地狱所在。
多智能体(Multi-Agent)
核心承诺:多个专精Agent(导航、抓取、对话)通过协作完成复杂任务,提升模块化与容错性。
工程现实:
-
端侧资源竞争(内存、CPU、NPU)使多模型并行运行困难。
-
Agent间通信引入不可控延迟,且可能产生涌现性不可预测行为。
-
目前无大规模商业落地案例,学术原型为主。
五、产业现实:量产突破与商业成熟之间
在结束技术梳理之前,必须直面核心结论:
审慎判断一:性能数据多为估算,存在不确定性
除控制理论确定的PID延迟(<10ms)外,其余VLA推理延迟、世界模型开销等数字,均为基于模型参数量、硬件规格(NPU TOPS、内存带宽)的工程推断。真实部署中,受量化精度、batch size、散热降频、网络抖动影响,实际数字可能偏离30%-300%。
审慎判断二:ROS生态正在分化
传统机器人公司仍深度依赖ROS2,但AI-first具身智能公司(Figure、1X、Physical Intelligence、宇树新一代系统)正倾向于自研中间件或绕过中间件直接推理+驱动。ROS不会消亡,但其"唯一标准"地位已被打破。
审慎判断三:万台级量产已突破,商业成熟仍待验证
-
量产突破 :智元于2026年3月28日 实现第10,000台通用具身机器人量产下线(第10,000台为远征A3)。此前5000台时的构成约为远征1742台 + 灵犀1846台 + 精灵1412台(彭志辉2025年12月披露),但10000台时的具体细分数据未公开。工信部于2026年6月9日启动"2026年度人形机器人与具身智能实景实训专项行动",明确目标"到2026年底,带动形成万台级规模落地能力"。TrendForce预测2026年全球人形机器人出货量将突破5万台。
-
商业成熟待验证 :智元CTO彭志辉在多次采访中强调,判断机器人是否走出Demo阶段,核心指标是能否在开放场景中稳定完成复杂任务、满足产线成功率要求,以及投资回报率是否算得过账。当前万台级出货覆盖的场景包括文娱表演、导览导购、以及3C产线等结构化工业场景 。这些场景中的机器人执行的是特定任务序列 (如贴标、扫码、装配),而非开放域通用操作 (如"帮我整理这个杂乱的抽屉")。因此,开放域通用操作 的万台级商业成功尚未验证,但结构化工业场景的万台级落地已开始。
-
其他厂商状态:
-
Figure、Optimus、宇树H1:仍为Demo或小批量试点阶段。
-
智元精灵G2 :在龙旗科技南昌工厂已实现常态化产线运行(2026年4月直播验证:4台机器人8小时完成2283次任务)。这是全球首个具身智能3C精密制造产线的规模化落地,计划2026年Q3扩至100台。当前部署规模仍属小批量(<100台),尚未达到万台级大规模商用。
-
优必选Walker系列:2025年实际交付超500台,全年人形机器人订单金额接近14亿元(含已中标项目)。实际收入按交付进度确认。
-
奇瑞墨甲:2025年4月首批220台完成全球交付,2026年4月进入"千台签约百台交付"的规模化部署阶段,主要用于汽车4S店迎宾、销售指导等服务场景,属于特定服务场景而非通用操作。
-
这意味着 :所有架构目前仍处于**"技术路线验证期"** ,没有经历过万台级市场的大规模筛选。我们讨论的"最优架构",实际上是**"当前条件下最合理的工程赌注"**。
六、技术版图:数据策略与架构形态两个维度
具身智能架构的全球竞争已形成多条技术路线。按技术本质(而非地理政治)分类,可从两个独立维度理解:
维度一:数据策略
私有数据驱动:Physical Intelligence(π₀系列)、Figure(Helix)------依赖私有海量数据(数十万小时机器人操作数据),训练成本极高,泛化能力强但技术门槛高、不可复现。
开源数据驱动:蚂蚁灵波(LingBot-VLA)、阿里Qwen-Robot系列------基于完全开源或部分开源数据训练,降低入门门槛,促进技术民主化。LingBot-VLA基于开源数据实现跨本体泛化;Qwen-RobotManip基于>38,100小时开源语料预训练;Qwen-RobotWorld基于860万视频-文本对(30%通用视频+70%具身数据)。但开源数据的质量、多样性和标注精度参差不齐,是这条路线的核心挑战。
维度二:架构形态
端到端原生:RT-2、π₀原始版------单一网络直接映射感知→动作,最大化信息保留,但黑盒、实时性差。
端到端内层次化:π₀.5/π₀.7------在单一端到端框架内引入高层语义规划与低层动作生成的内部分层,试图兼顾端到端的泛化与层次化的可控。
显式频率分层:Figure Helix 02(S0/S1/S2)------不同频率的显式子系统,高层慢速推理、低层快速反射,接口明确。
隐式规划分层:智元GO-1/ViLLA------VLM → 隐式规划器(latent action token) → 动作专家,中间表示是隐式的、学习得到的,而非人工设计的频率分层。
关键说明 :一个系统可同时属于多个维度。如Figure Helix既是私有数据驱动 (数据策略),又是显式频率分层 (架构形态)。π₀.5既是私有数据驱动 ,又是端到端内层次化。分类的目的是理解技术选择的空间,而非贴标签。
技术趋同观察:π₀.7(高层策略+世界模型+8.6亿参数动作专家)与Figure Helix(S2→S1→S0,S0为10M参数全身控制基础模型)在"高层慢速推理+低层快速反射"的时间尺度分层逻辑上呈现趋同,但具体实现机制差异显著:规模上(8.6亿 vs 1000万)、训练目标上(组合泛化 vs 全身控制)、接口设计上(隐式 vs 显式频率分界)均不同。这种趋同表明行业正在探索频率分层作为统一架构原则,但最优分层粒度仍是开放问题。
阿里Qwen-RobotManip(2026.6.16发布,尚待社区验证) :采用80维统一动作表征,不依赖绝对坐标,而是基于摄像头画面的相对位置进行操作,用80维向量定义跨硬件的通用"肢体语言"。这解决了跨硬件适配问题,代表了一种动作表征标准化的思路。
七、架构选型决策树:如何在不确定性中做决策
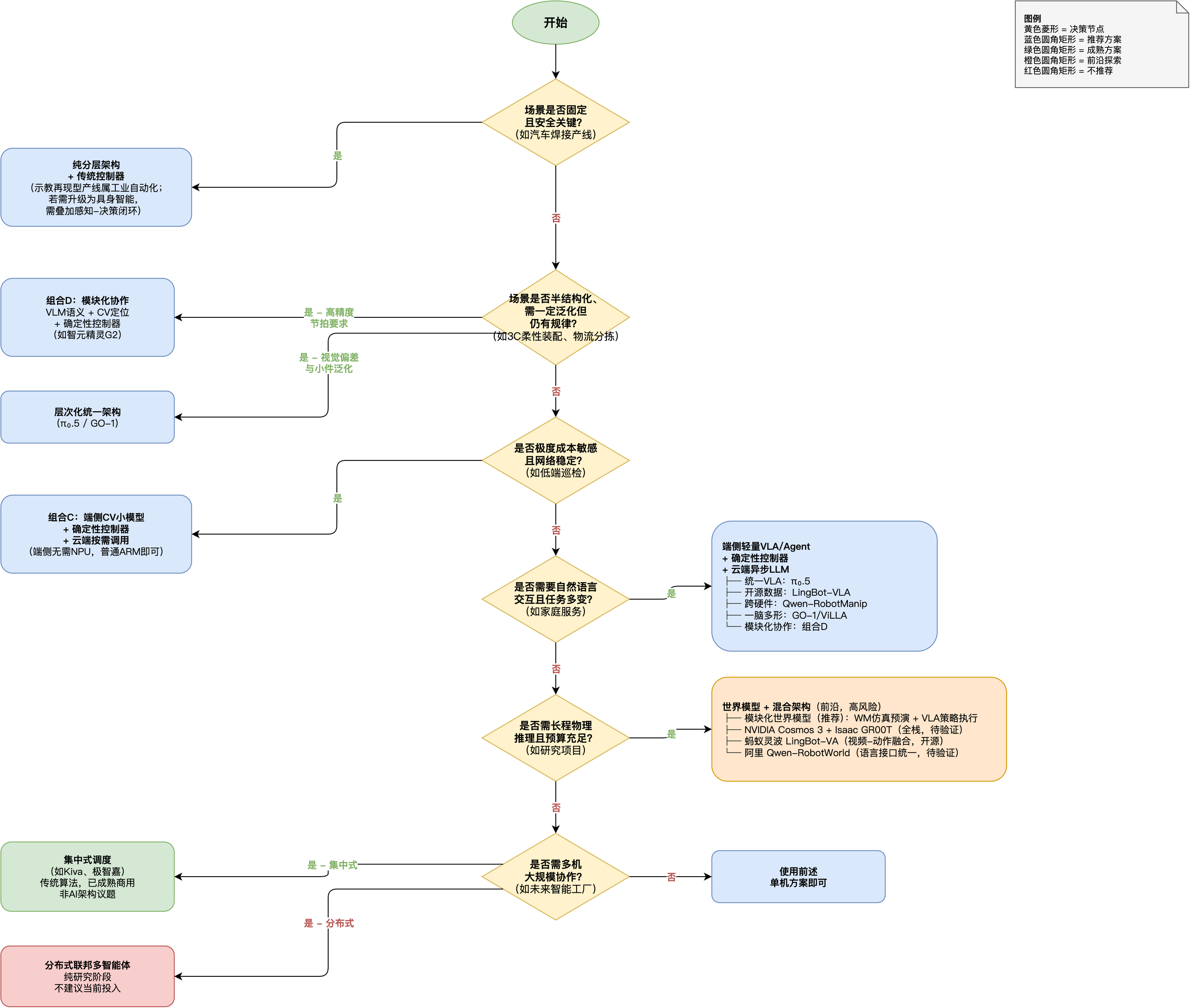
给从业者的建议:
-
从层次化架构起步:不要追求纯端到端的"优雅",工程鲁棒性优先。
-
端侧优先保证控制级实时性 :无论高层用什么模型,强烈建议 底层保留确定性控制器(PID/MPC等)的fallback------这不是因为PID是唯一选项(MPC、WBC甚至纯RL策略在技术上均可替代,如Figure Helix S0已实现10M参数神经网络1kHz全身控制),而是因为确定性控制器的可审计性和安全兜底作用,在当前多数团队的数据与验证能力条件下,仍是工程务实的选择。若采用纯神经底层,需具备极强的数据闭环与仿真验证能力。
-
对"世界模型""多智能体"保持审慎:它们是研究方向,不是2026年的成熟产品方案。
-
自己测延迟:不同硬件(Jetson Orin vs 高通8Gen3 vs 苹果M4 vs Jetson Thor T5000)的推理延迟差异巨大,不存在通用答案。
-
关注开源数据路线:蚂蚁灵波、阿里Qwen-Robot、OpenLoong等开源生态正在降低入门门槛,可能改变产业格局。
-
区分"量产"与"商业成熟":万台级量产能力是里程碑,但不等于万台级商业成功。评估方案时需关注ROI、客户复购、场景通用性等硬指标。
-
考虑组合D(模块化协作):在VLA太贵、纯CV太笨的场景,VLM+CV+确定性控制器的模块化协作可能是性价比最优解。
-
半结构化工业场景优先选层次化或组合D:3C柔性装配、物流分拣等"任务相对固定但需要一定泛化"的场景,是当前工业落地的主力路线。
结语:架构是手段,物理交互是目的
具身智能的架构之争,本质上是**"我们对智能的理解尚不成熟"** 的投射。我们还在争论该用规则还是神经网络、该集中还是分布、该端侧还是云端,是因为没有任何一种方案已经被证明在通用物理交互中足够好。
也许最终的答案不是某一种架构的胜利,而是一种动态的分层:底层是毫秒级的反射弧(模型或控制器),中层是秒级的技能编排,高层是分钟级的任务规划,而贯穿始终的是一个不断学习的、隐式的世界表征。
但在那之前,我们仍需在不确定中前行,保持对技术叙事的警惕,对工程现实的尊重,以及对物理世界复杂性的谦卑。
本文基于公开论文、技术博客与工程经验综合分析,部分性能数据为推断值,具体部署请以实测为准。
创作不易,禁止抄袭,转载请附上原文链接及标题