模式
模式定义DataFrame的列名以及列的数据类型,它可以由数据源来定义模式(称为读时模式,schema-on-read),也可以由我们自己来显式地定义
列
有很多不同的方法来构造和引用列,两个最简单的方法是通过col函数或column函数。使用这两个函数,需要传入列名:
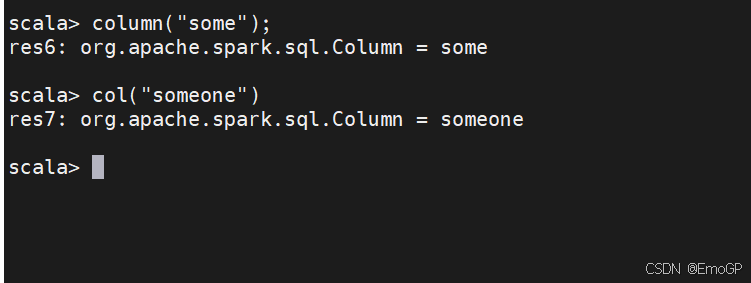
DataFrame可能不包含某列,所以该列要将列名与catalog中维护的列名相比较之后才会确定该列是否会被解析
刚提到了引用列的两种不同方法,而Scala中有一些特有的语言支持,可以使用更多简短的方式来引用列。下面的表达式执行相同的功能,即创建列,但并不能改善性能:
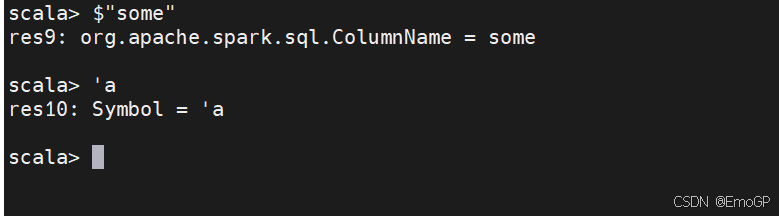
符号$将字符串指定为表达式,而符号(')指定一个symbol,是Scala引用标识符的特殊结构,它们都执行相同的功能,通过列名引用列的简写方式
显式列引用
如果你需要引用某DataFrame的某一列,则可以在这个DataFrame上使用col方法。当执行连接操作时,如果两个连接的DataFrame存在一个同名列,该方法会非常有用,显式引用列的另一个好处就是Spark不用自己解析该列(在分析阶段):df.col("count")
表达式
表达式是对一个DataFrame中某一个记录的一个或多个值的一组转换操作。把他想象成一个函数,它将一个或多个列名作为输入,解析它们,然后针对数据集中的每条记录应用表达式来得到一个单值
列作为表达式
列提供了表达式功能的一个子集,如果你使用col(),并想对该列执行转换操作,则必须对该列的引用执行这些转换操作。当使用表达式时,expr函数实际上可以将字符串解析成转换操作和列引用,也可以在之后将其传递到下一步的转换操作
记录和行
在Spark中,DataFrame的每一行都是一个记录,而记录是Row类型的对象。Spark使用列表达式操纵Row类型对象。Row对象内部其实是字节数组,但是Spark没有提供访问这些数组的接口,因此我们只能使用列表达式去操纵。
当使用DataFrame时,向驱动器请求行的命令总是返回一个或多个Row类型的行数据
行和记录代表同一个意思,多数情况下会使用后者,Row表示Row类型的对象
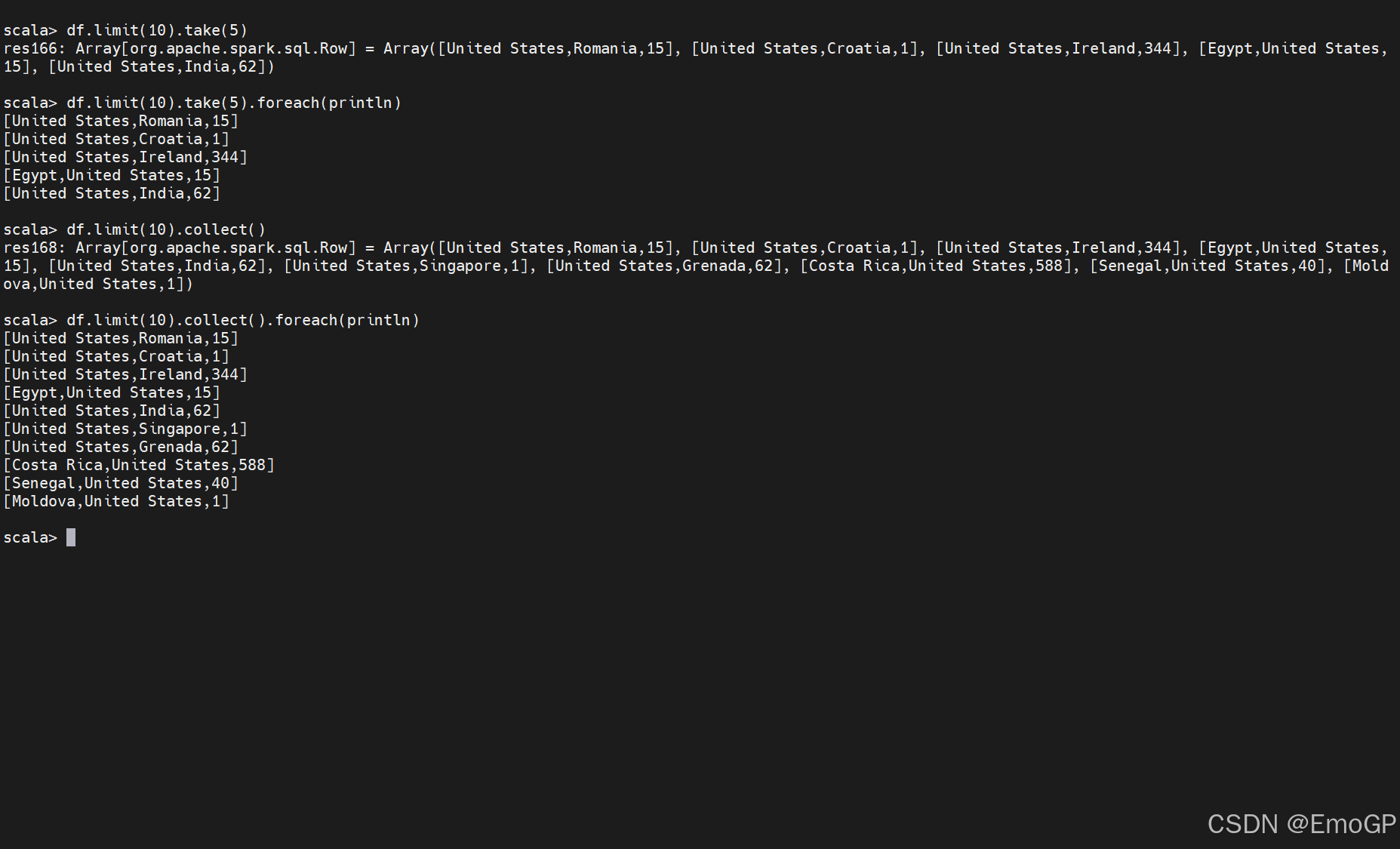
我们可以通过在DataFrame上调用first()来查看一行:df.first()
创建DataFrame
我们可以从原始数据源中创建DataFrame
也可以通过获取一组行并将它们转换操作为一个DataFrame来即时创建DataFrame
bash
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{StructField,StructType,StringType,LongType}
val myManualSchema = new StructType(Array(
new StructField("some",StringType,true),
new StructField("col",StringType,true),
new StructField("names",LongType,false)))
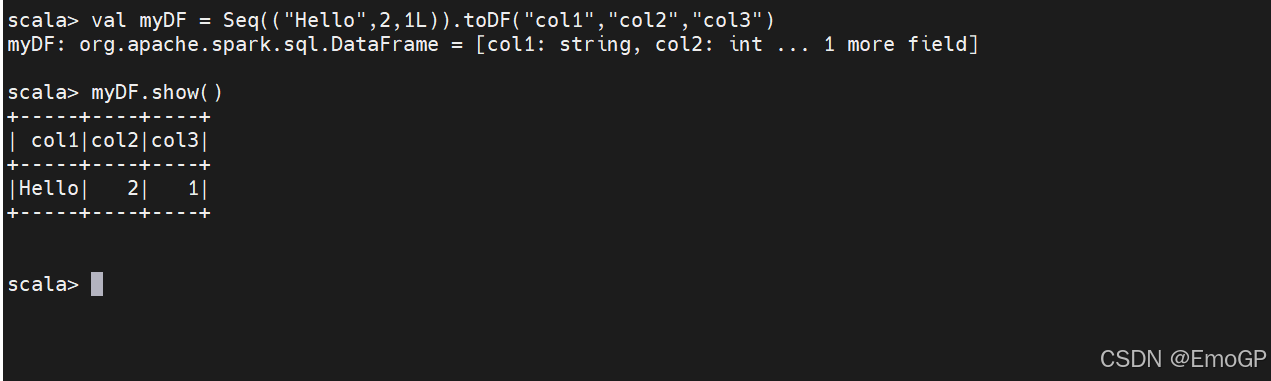
val myRows = Seq(Row("Hello",null,1L))
val myRDD = spark.sparkContext.parallelize(myRows)
val myDf = spark.createDataFrame(myRDD,myManualSchema)
myDf.show()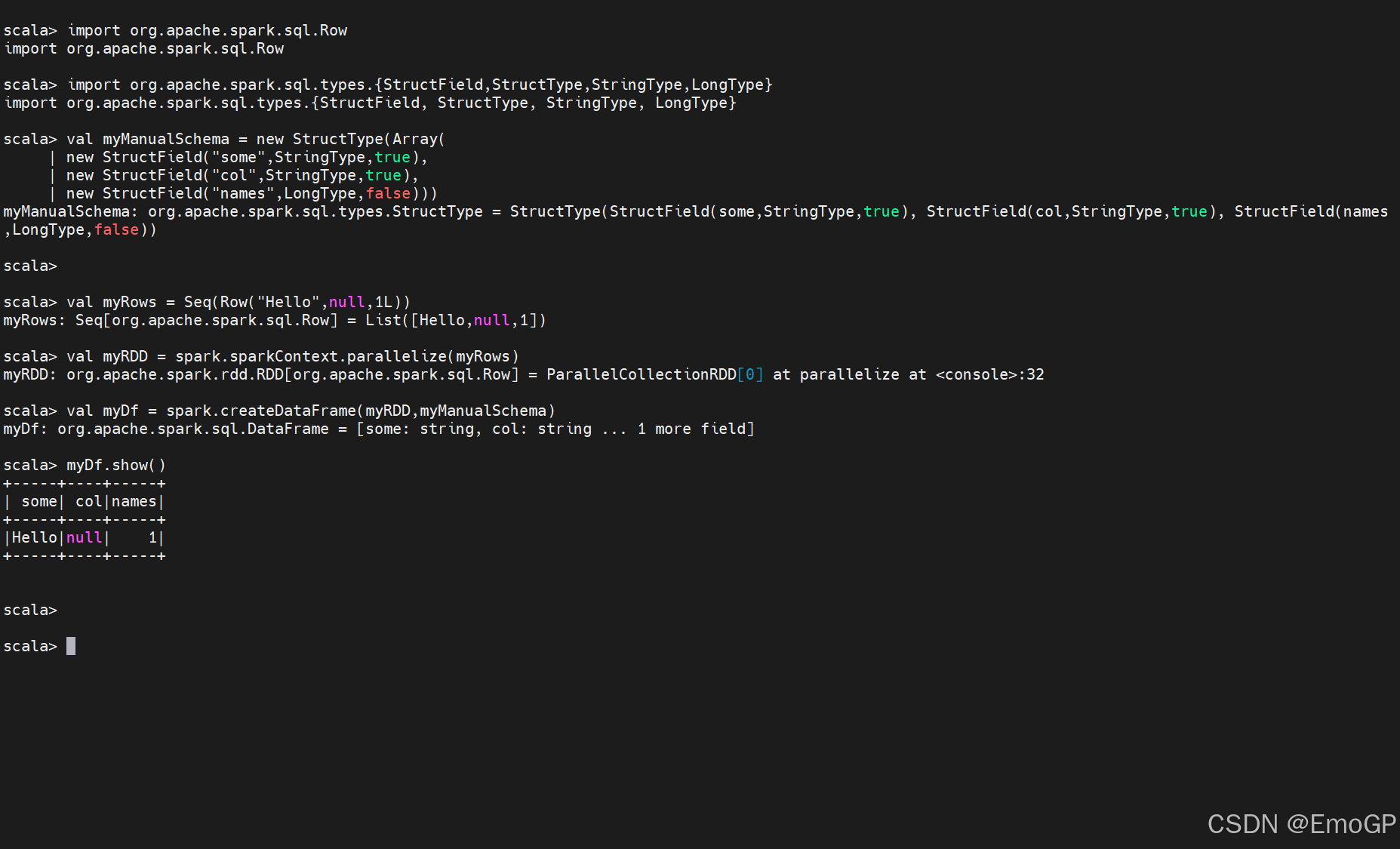
在scala中,还可以通过在seq类型上运行toDF函数来利用控制台中的Spark隐式方法(如果已经将它们导入JAR代码中)。由于对于null类型的支持并不稳定,所以并不推荐在实际生产中使用
接下来看看DataFrame类型支持的最有用的方法:
处理列或表达式时的select方法,以及处理字符串表达式时的selectExpr方法
当然有的转换操作不是针对列的操作方法,因此org.apache.spark.sql.functions包中包含一组函数方法用来提供额外支持
select函数和selectExpr函数
select函数和selectExpr函数支持在DataFrame上执行类似数据表的SQL查询
简单来说,可以使用select和selectExpr来操作DataFrame中的列,我们将通过DataFrame的一些示例来介绍各种不同的写法。最简单的方式就是使用select方法,待处理的列名字符串作为参数传递:
bash
df.select("DEST_COUNTRY_NAME").show(2)
select DEST_COUNTRY_NAME from dfTable limit 2可以使用相同格式的查询来选择多个列,只需在select方法调用中添加更多的列名字符串即可
bash
df.select("DEST_COUNTRY_NAME","ORIGIN_COUNTRY_NAME").show(2);
select DEST_COUNTRY_NAME,ORIGIN_COUNTRY_NAME from dfTable limit 2;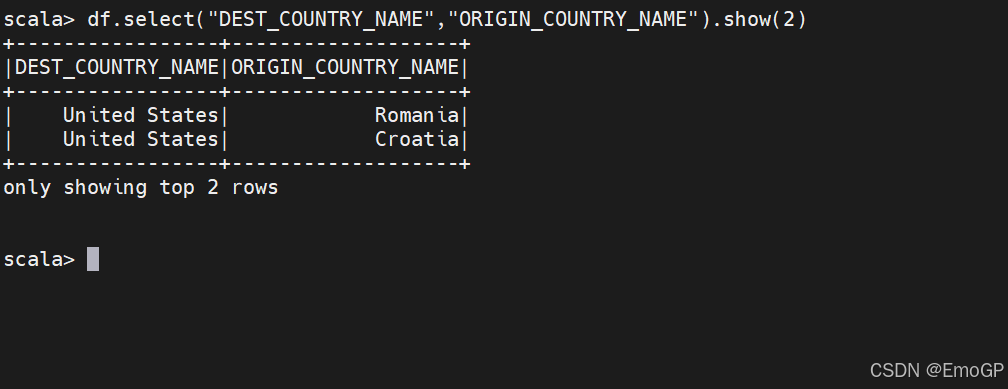
可以通过多种不同的方式引用列,而且这些方式可以等价互换:
bash
df.select(df.col("DEST_COUNTRY_NAME"),col("DEST_COUNTRY_NAME"),column("DEST_COUNTRY_NAME"),'DEST_COUNTRY_NAME,$"DEST_COUNTRY_NAME",expr("DEST_COUNTRY_NAME")).show(2)
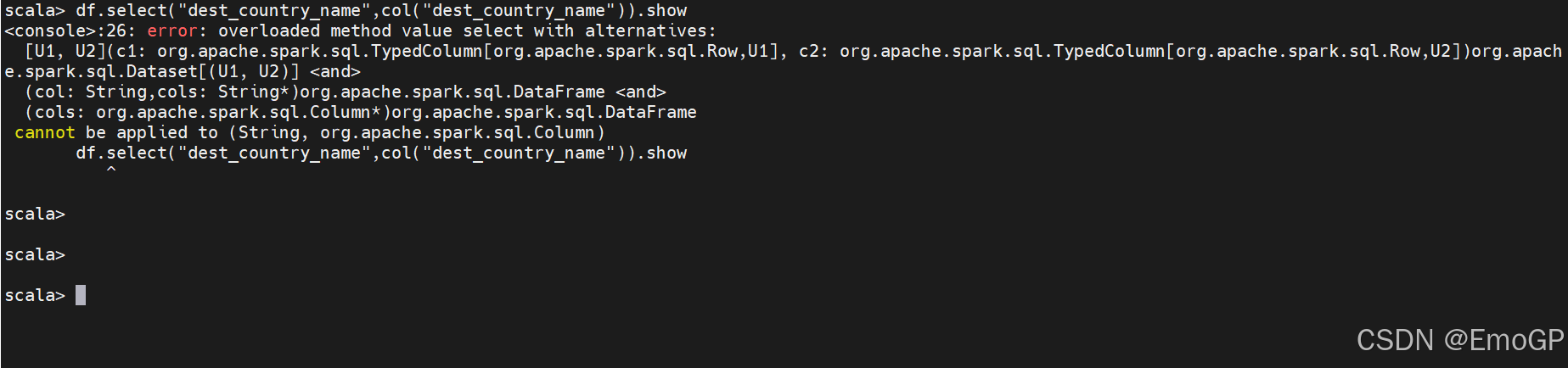
注意在Spark的Scala API中,select方法存在重载限制,Spark的select方法不支持混合传入String和Column类型的参数,它只接受以下两种情况:
- 全部传入String类型
- 全部传入Column类型
以下代码将导致编译错误
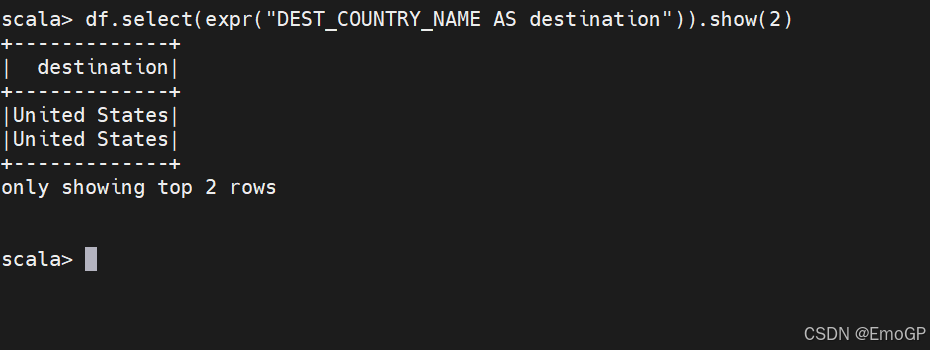
expr是我们目前使用到的最灵活的引用方式。它能够引用一列,也可以引用对列进行操纵的字符串表达式
expr("SQL表达式字符串")返回一个Column对象,和col()同级,区别:
col("字段名"):只能单纯引用列
expr("任意Spark SQL表达式"):支持运算、函数、别名、case when、常量等
注意不能写成如下:
可以进一步操作:
因为select后跟着一系列expr是非常常见的写法,所以Spark有一个有效地描述此操作序列的接口:selectExpr,它可能是最常用的接口:
这是Spark最强大的地方,我们可以利用selectExpr构建复杂表达式来创建DataFrame。实际上,我们可以添加任何不包含聚合操作的有效SQL语句,并且只要列可以解析,它就是有效的
使用select语句,我们还可以利用系统预定义好的聚合函数来指定在整个DataFrame上的聚合操作
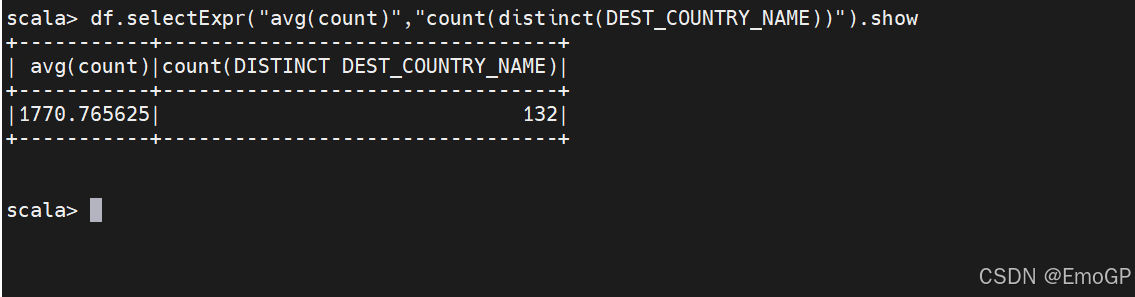
转换操作成Spark类型(字面量)
有时候需要给Spark传递显式的值,它们只是一个值而非新列,这可能是一个常量值,或接下来需要比较的值,我们的方式是通过字面量(literal)传递,简单来说,就是将给定的编程语言的字面上的值转换操作为Spark可以理解的值。字面量就是表达式,你可以用操作表达式的方式来使用它们
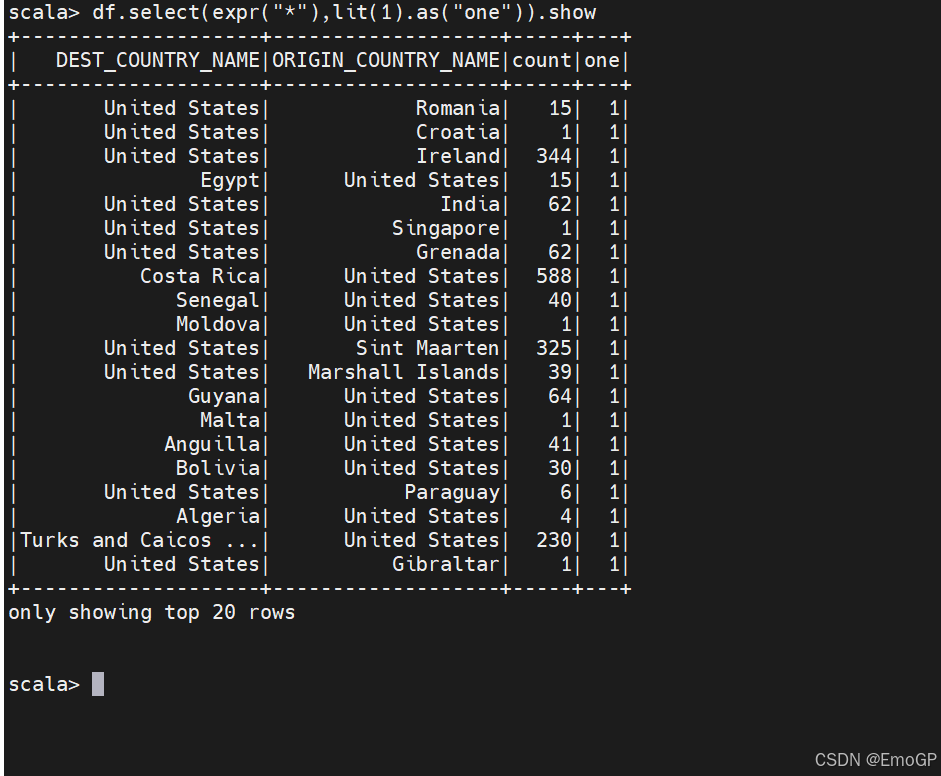
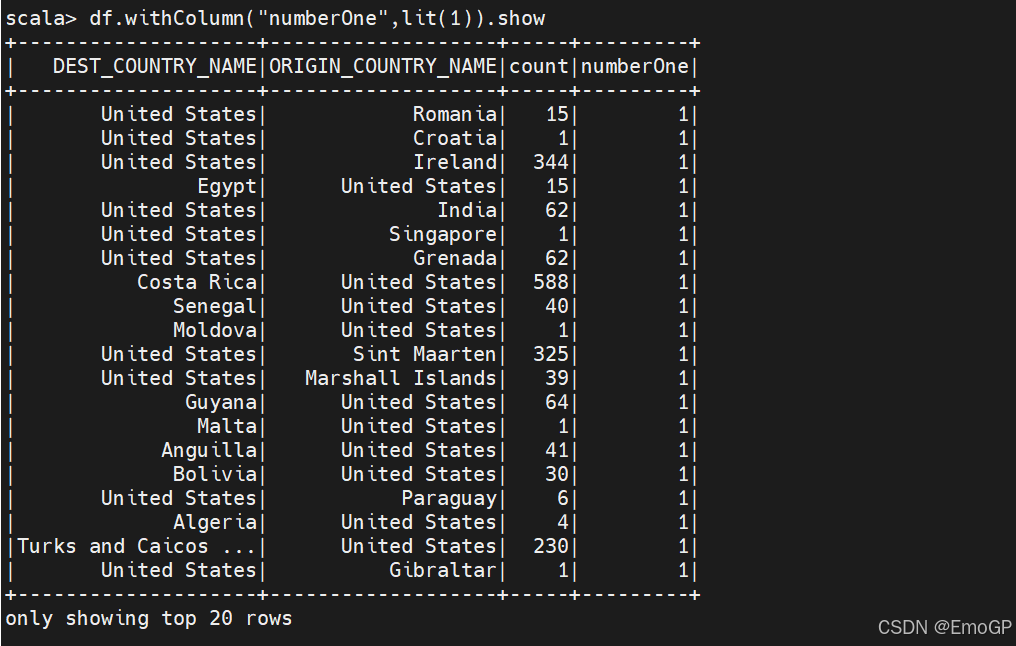
添加列
使用WithColumn可以为DataFrame增加新列,这种方式更为规范一些。例如,添加一个仅包含数字1的列:
让我们做一些有趣的事,来接触一下实际的表达式,在下一个示例中,当count值大于10我们将其设置一个布尔标志
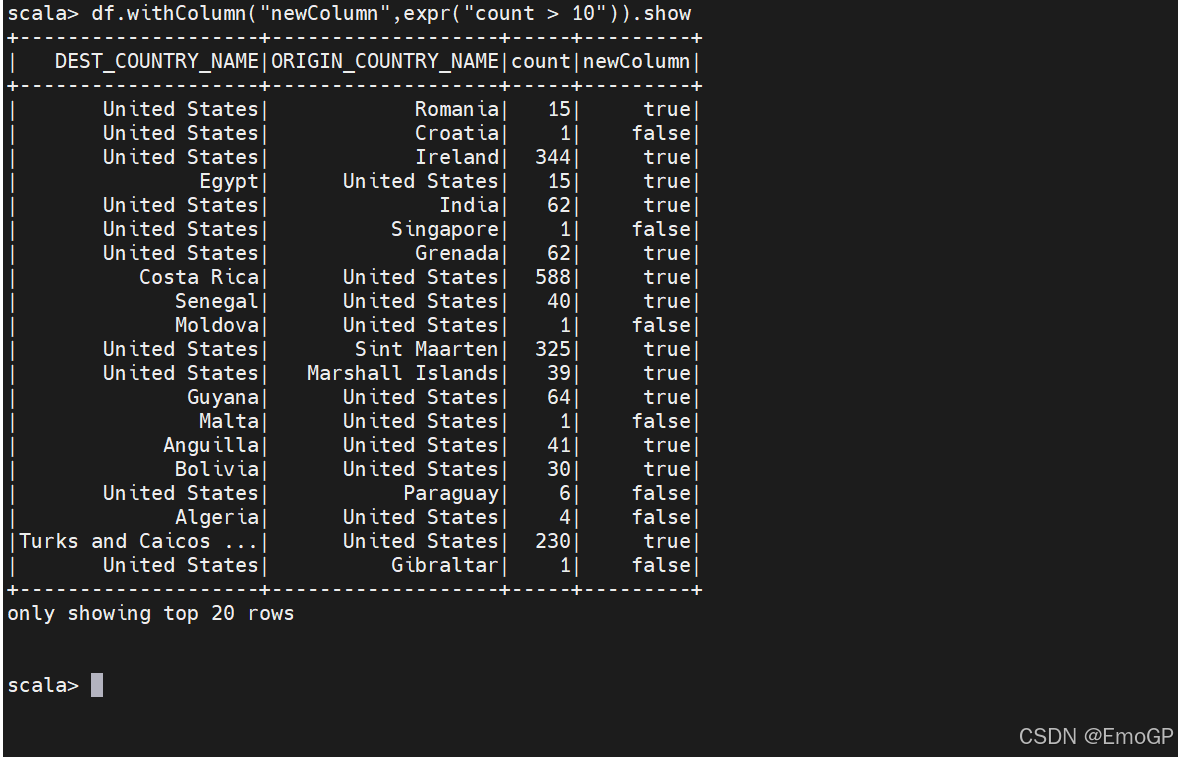
注意:withColumn函数有两个参数:列名和为给定行赋值的表达式。
重命名列
我们可以使用withColumnRenamed方法实现对列重命名
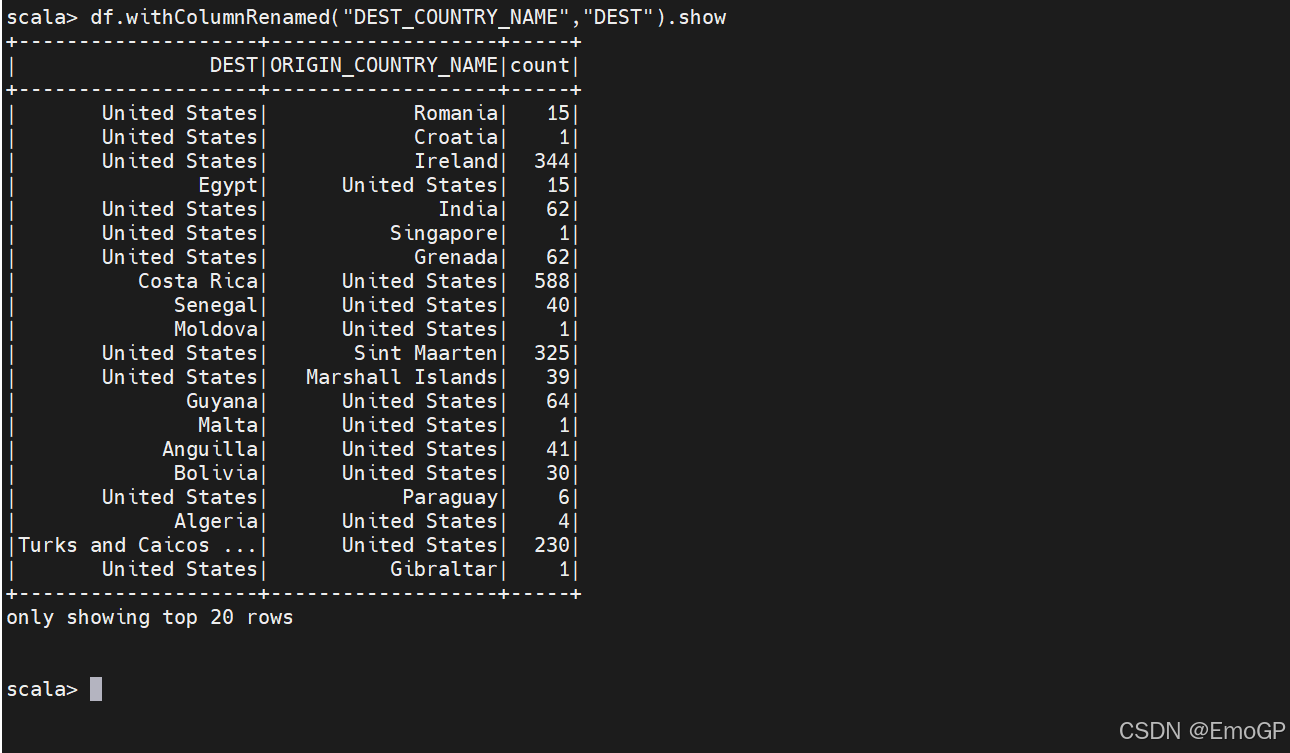
第一个参数是要被修改的列的名,第二个参数是新的列名
保留字与关键字
你可能会遇到列名中包含空格或者连字符等保留字符,要处理这些保留字符意味着要适当地对列名进行转义
在Spark中,我们通过使用反引号(`)字符来实现。withColumn是你刚学会的一个允许使用保留字来创建列的方法。接下来介绍两个示例:在第一个示例中,我们不需要转义字符,但是第二个示例中,我们则会用到
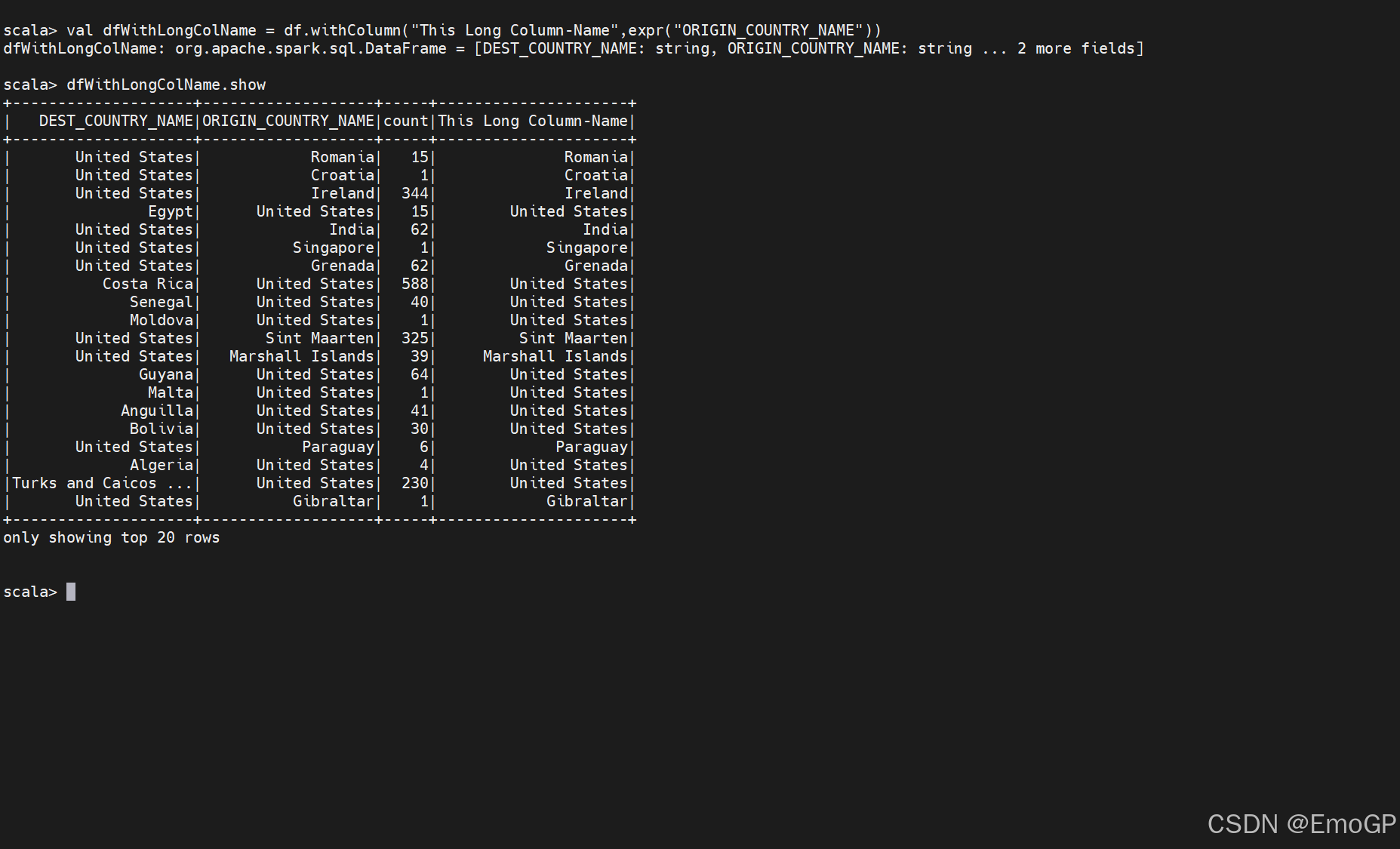
这里不需要转义字符,因为withColumn的第一个参数只是新列名的字符串
但在 下面这个例子中,我们需要使用反引号,因为我们在表达式中引用了一个列
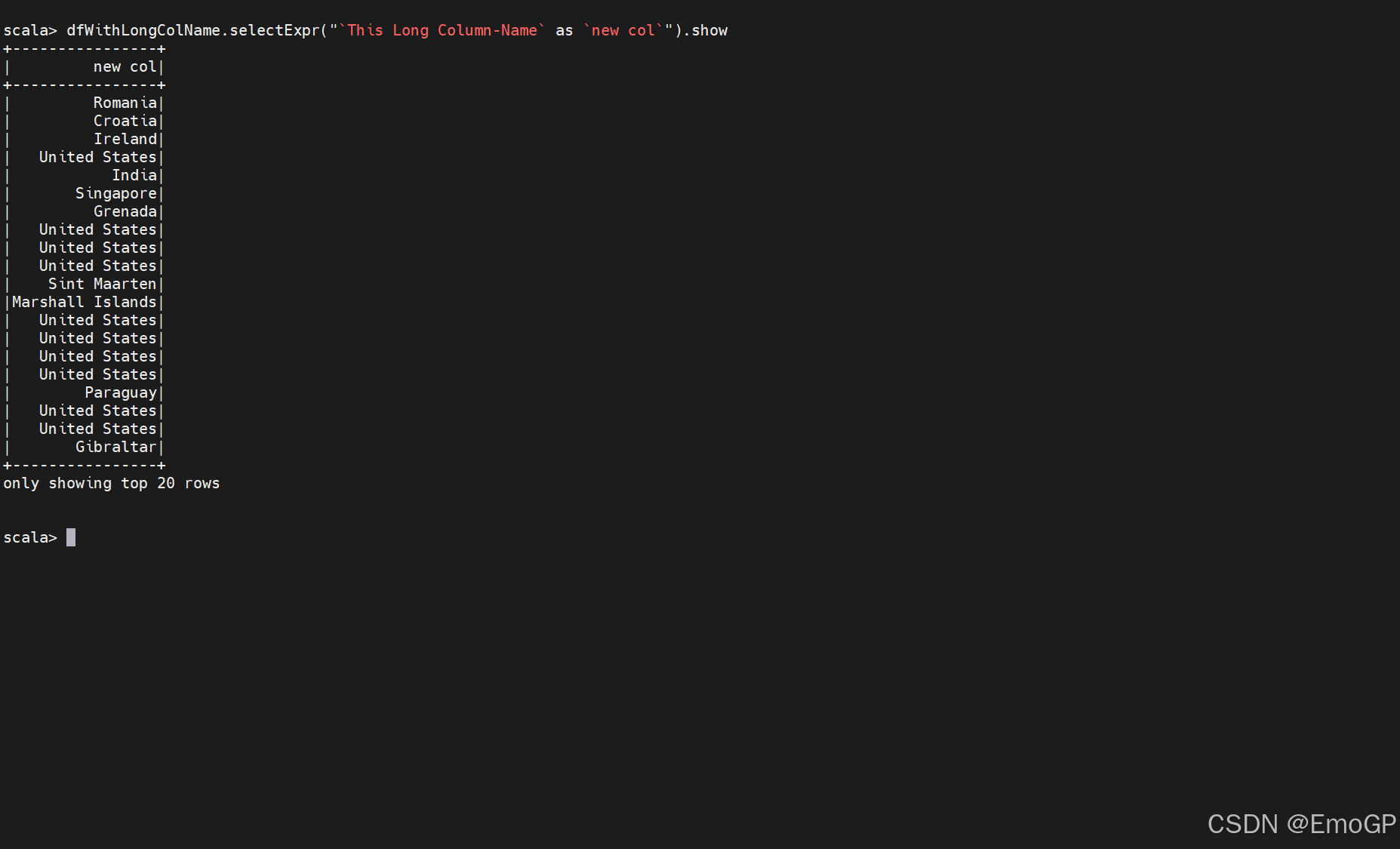
如果我们显式地使用字符串来引用列,则可以引用带有保留字符的列(而不用转义他们),这个字符串会被解释成字面值,而不是表达式。我们只需要转义使用保留字符或者关键字的表达式
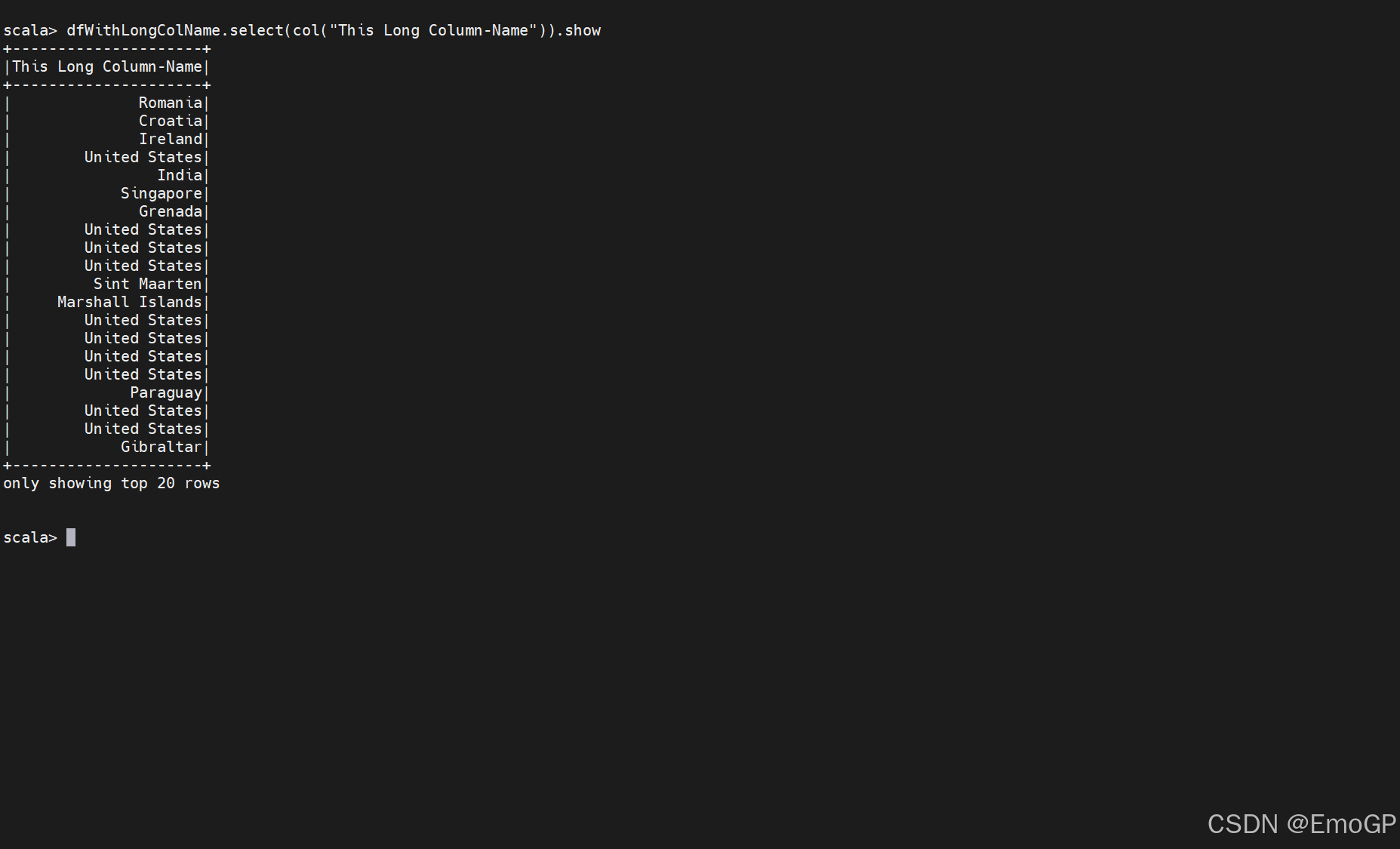
区分大小写
Spark默认是不区分大小写的
删除列
我们可以通过drop方法来删除列
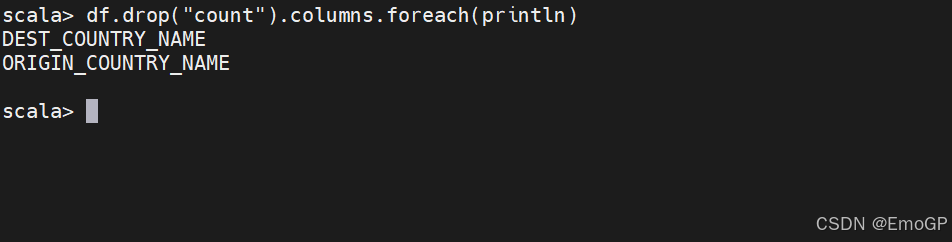

更改列的类型(强制类型转换)
有时,我们可能需要将某一列类型转换操作为另一种类型
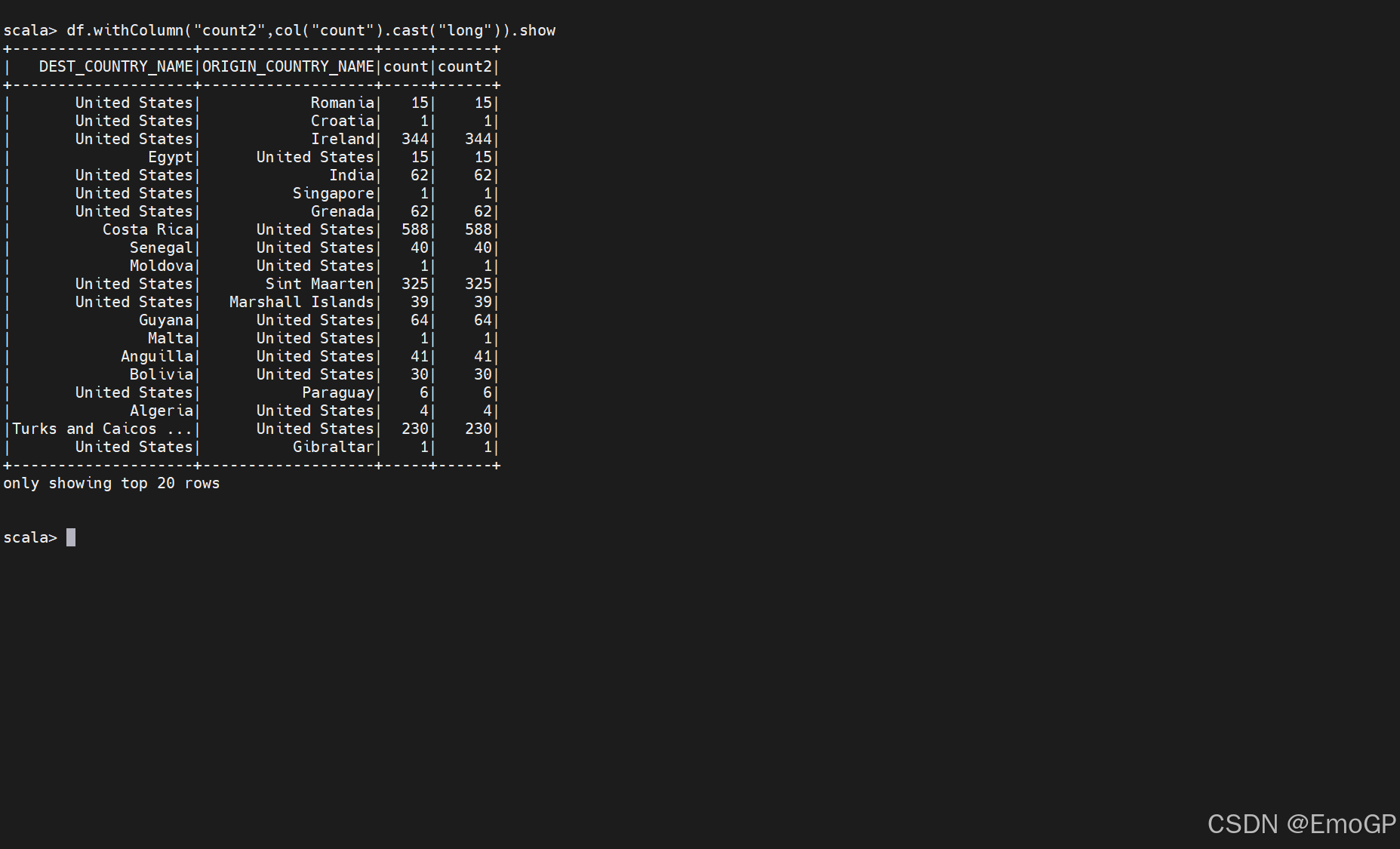
过滤行
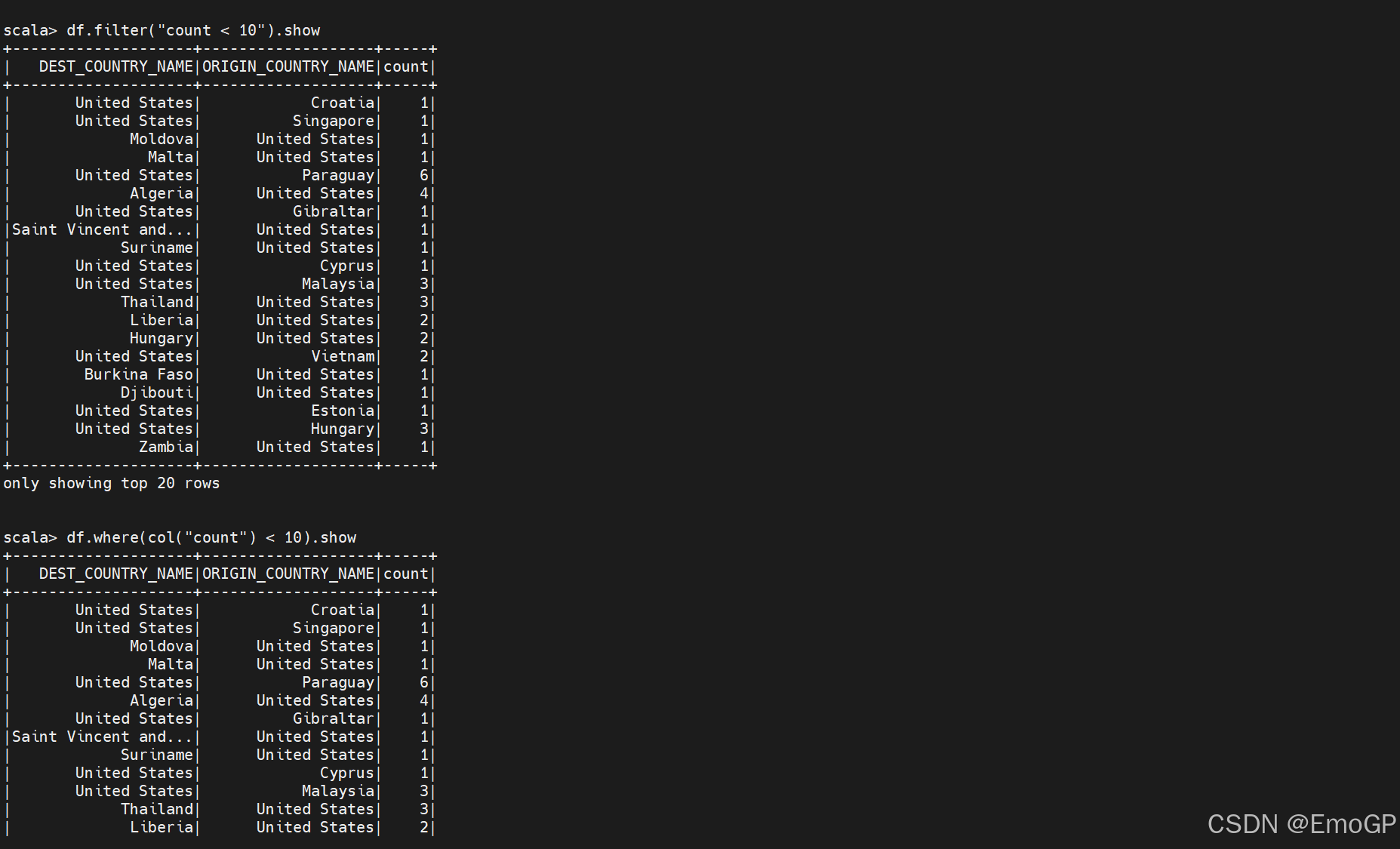
为了过滤行,只要创建一个表达式来判断该表达式是true还是false,然后过滤使表达式为false的行。在DataFrame上实现过滤操作最常见的方法是创建一个字符串表达式,或者通过列操作来构建表达式。有两种实现过滤的方式,分别是where和filter,它们可以执行相同的操作,接受相同参数类型。
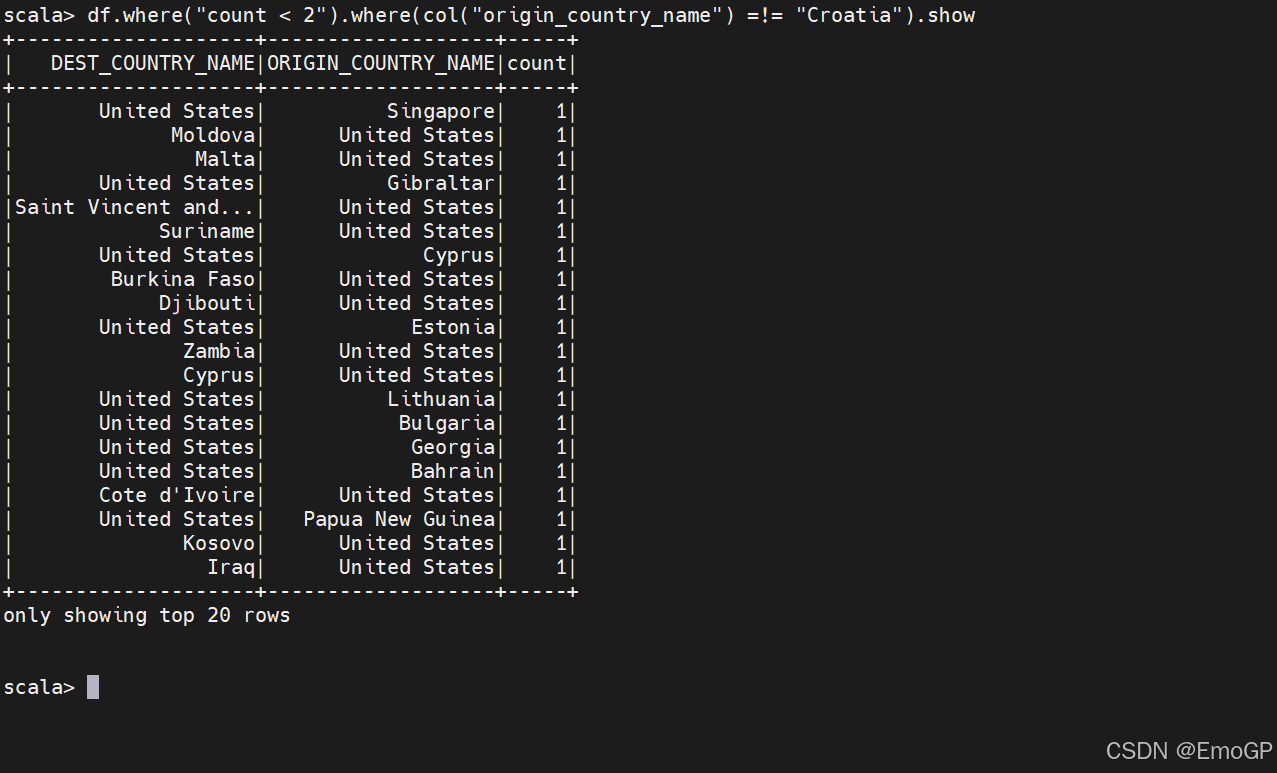
我们可能本能地想把多个过滤条件放到一个表达式中,尽管这种方式可行,但是并不总有效,因为Spark会同时执行所有过滤操作,不管过滤条件的先后顺序,因此当你想指定多个AND过滤操作时,只要按照先后顺序以链式的方式把这些过滤条件串联起来,然后让Spark执行剩下的工作
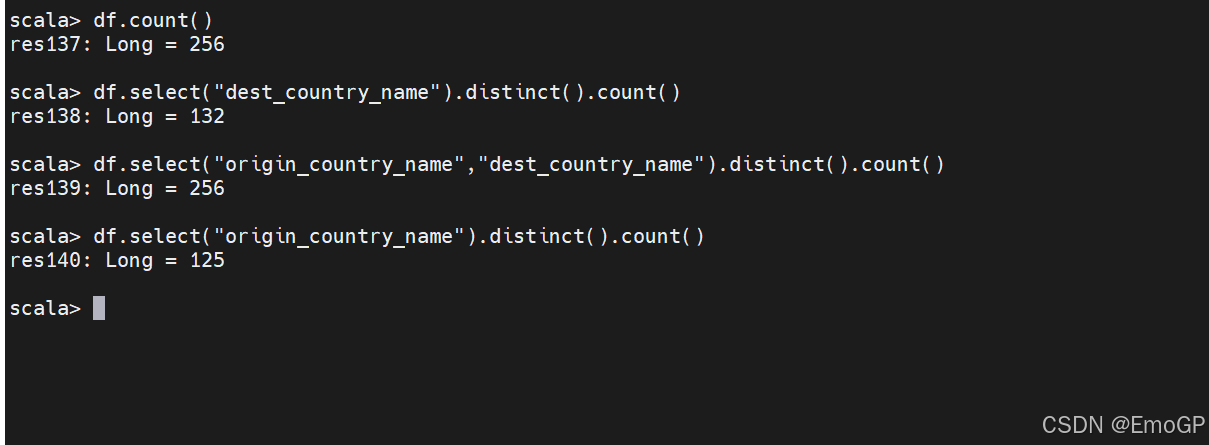
获得去重后的行
使用distinct实现去重
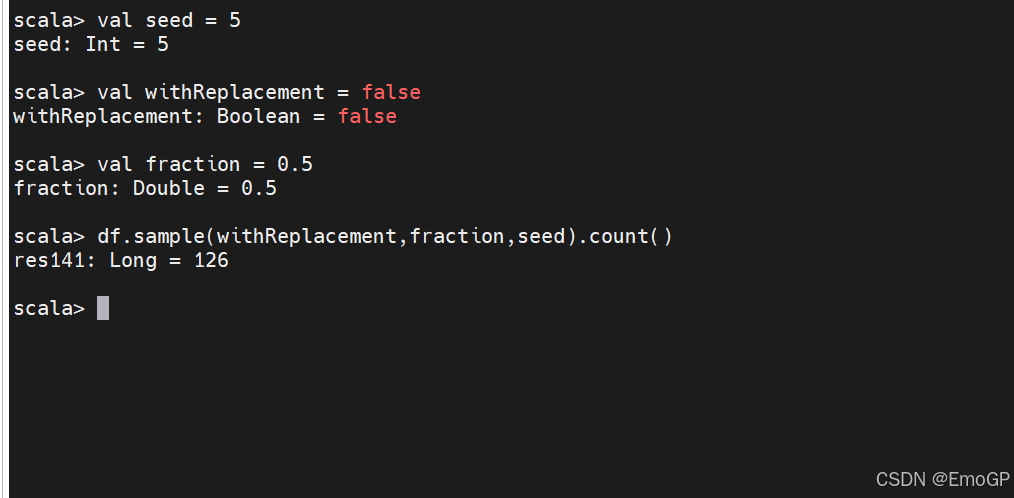
随机抽样
有时可能想从DataFrame中随机抽取一些记录,你可以使用DataFrame的sample方法来实现此操作,它按一定比例从DataFrame中随机抽取一部分行,也可以通过withReplacement参数指定是否放回抽样,true为有放回的抽象(可以有重复样本),false为无放回的抽样(无重复样本)
连接和追加行(联合操作)
DataFrame是不可变的,这意味着用户不能向DataFrame追加行,如果想要向DataFrame追加行,必须将原始的DataFrame与新的DataFrame联合起来,即union操作,也就是拼接两个DataFrame,若想联合两个DataFrame,必须确保它们具有相同的模式和列数,否则联合操作将会失败
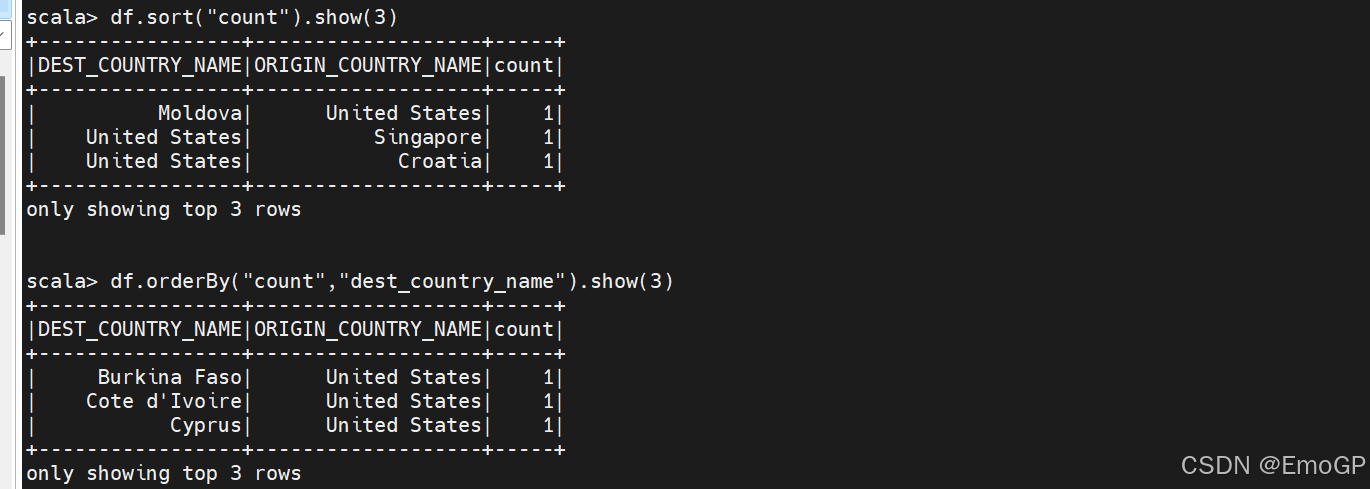
行排序
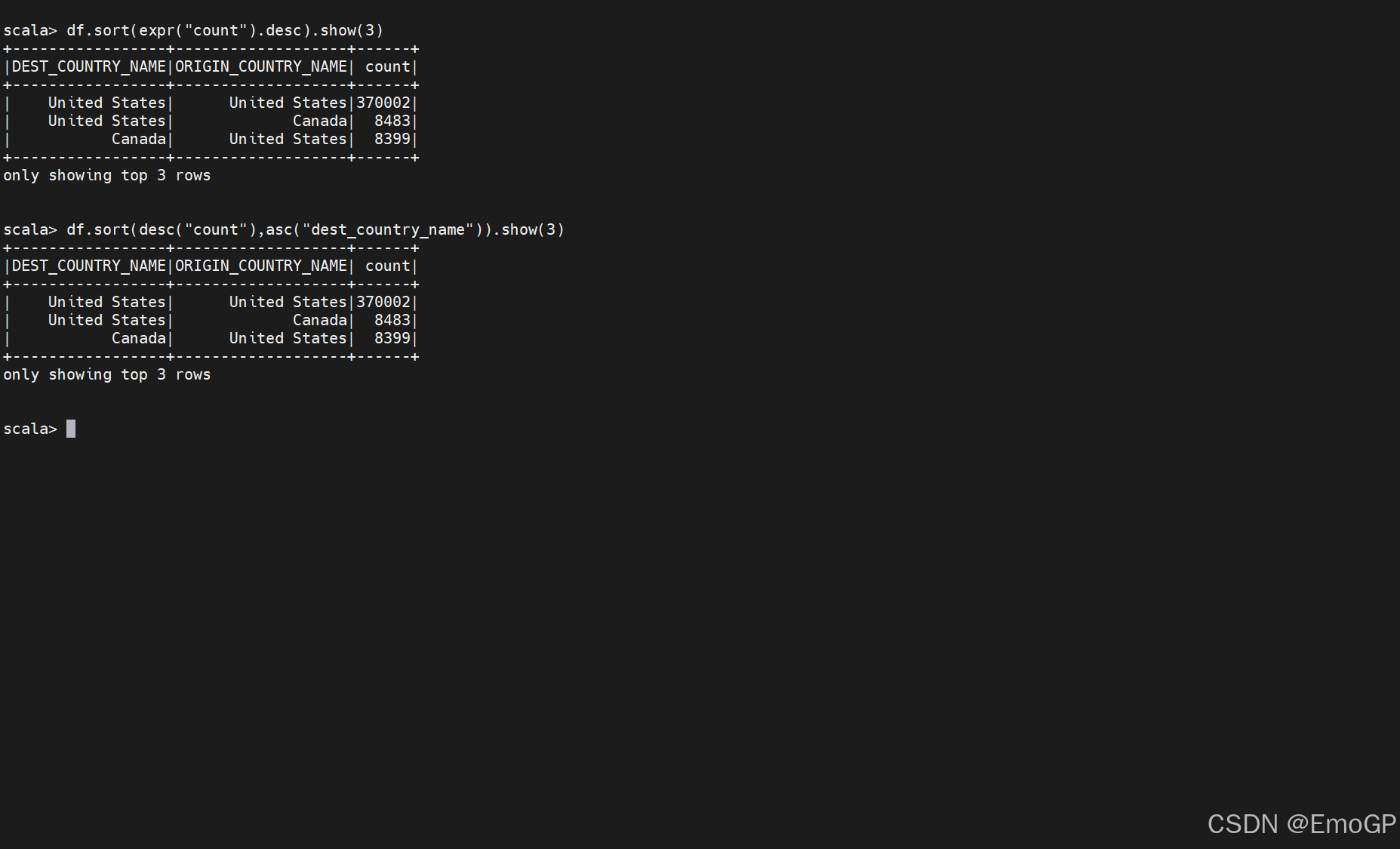
当对DataFrame中的值进行排序时,我们通常是想要获得DataFrame里的一些最大值或者最小值,sort和orderBy方法是相互等价的操作,执行的方式也一样。它们均接收列表达式和字符串,以及多个个列,默认升序。
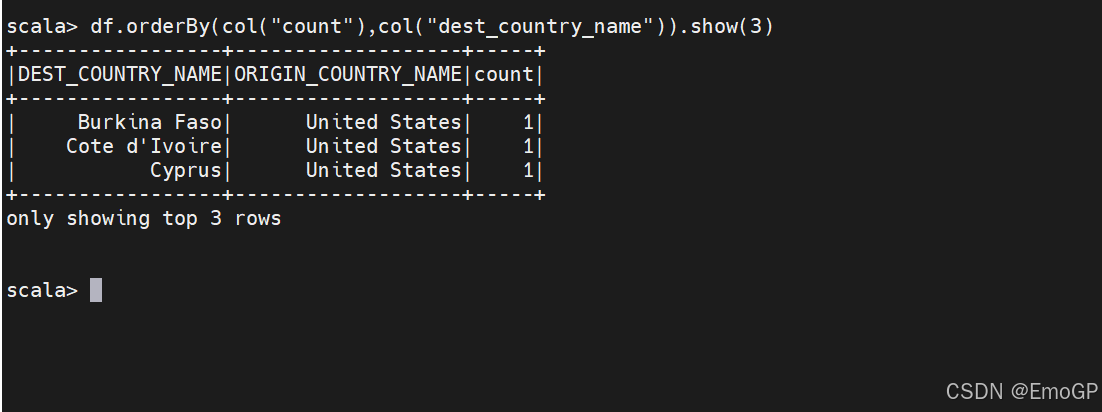
若要明确地指定升序或是降序,则需要使用asc函数和desc函数
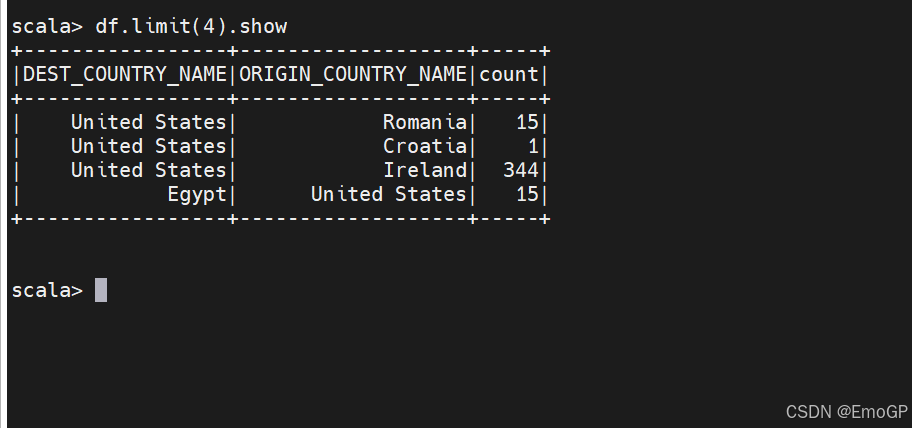
limit
重划分和合并
另一个重要的优化是根据一些经常过滤 的列对数据进行分区
不管是否有必要,重新分区都会导致数据的全面洗牌,如果将来的分区数大于当前的分区数,或者当你想要基于某一组特定列来进行分区时,通常只能重新分区:

如果你知道你经常按照某一列执行过滤操作,则根据该列进行重新分区是很有必要的

你还可以指定你想要的分区数量

而另一方面,合并操作(coalesce)不会导致数据的全面洗牌,但会尝试合并分区
下面代码将基于目的地国家名的列将数据重新划分为5个分区,然后再合并它们(没有导致数据全面洗牌)

驱动器获取行
Spark的驱动器维护者集群状态,有时候需要让驱动器收集一些数据到本地,这样可以在本地机器上处理它们