面向新人:本文从零拆解 Hermes Agent 的闭环自学习机制,覆盖每一步的触发条件、执行流程、关键代码位置和设计哲学。配合 Mermaid 流程图理解更佳。
一句话概述
Hermes 在每次对话轮次结束后,自动 fork 一个独立 agent 线程,复盘刚刚完成的任务,主动判断:这段对话中是否出现了值得记住的"用户特性"(记忆系统)和"可复用的工作模式"(技能系统),然后将它们持久化。几轮之后,一个定期运行的"管家"会审查所有 agent 自创的技能,合并碎片、归档过期内容,保持技能库始终处于"类级别"的高质量结构。
这不是传统的"用户手动存备忘"或"被动日志",而是 agent 主动判断、主动沉淀、主动维护 的完整闭环。
为什么需要闭环自学习?
系统全景图
三大子系统逐一拆解
4.1 每轮后背景审查 (Background Review)
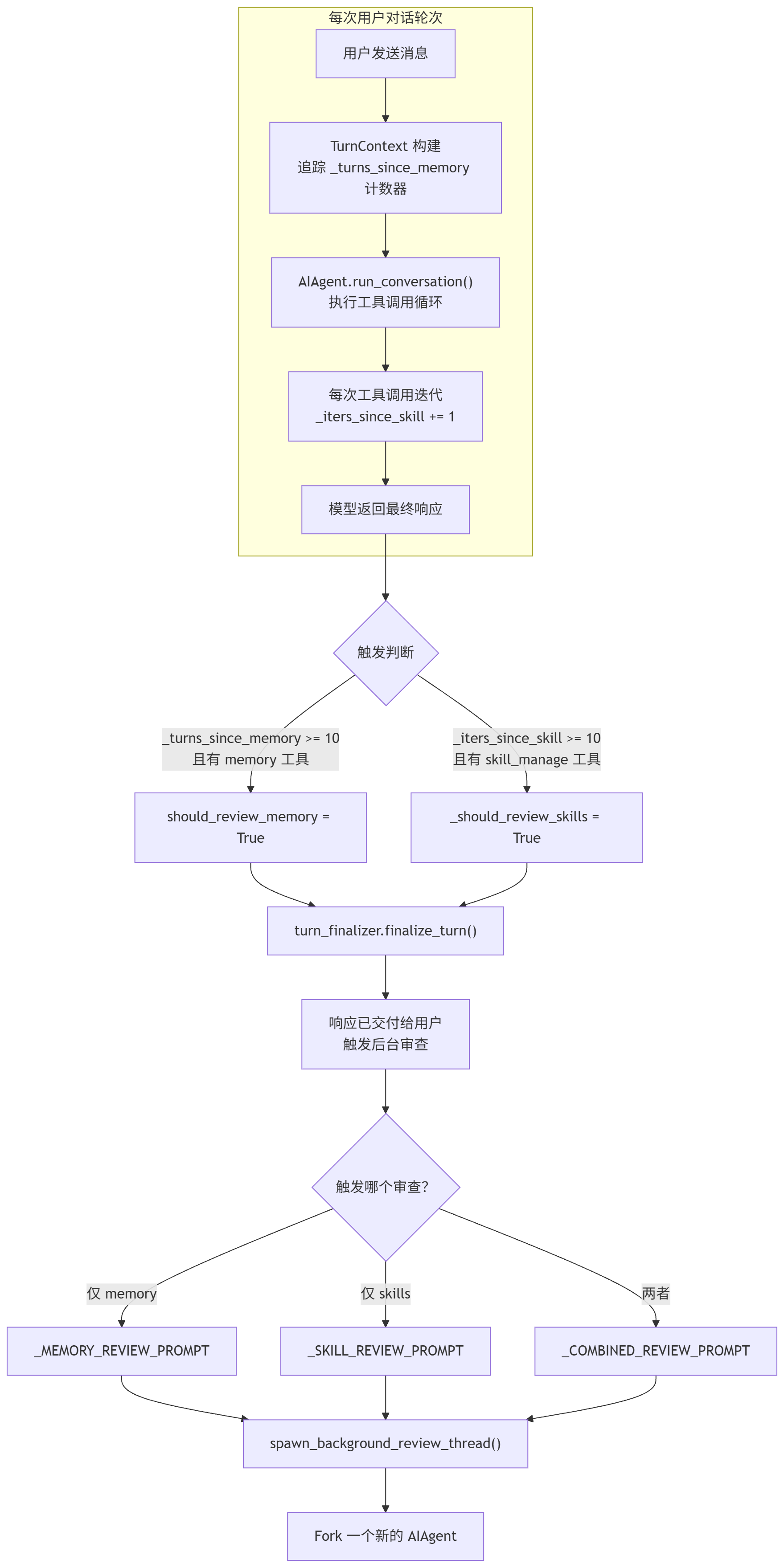
触发时机
不是每轮都触发,而是基于计数器的"nudge"机制:
两个计数器独立运作------可能同一轮同时触发 memory 和 skill 审查。
执行流程(逐步骤)
Step 1: 计数器累加
# agent/turn_context.py:210-215
agent._turns_since_memory += 1
if agent._turns_since_memory >= agent._memory_nudge_interval:
should_review_memory = True
agent._turns_since_memory = 0
# agent/conversation_loop.py:518-520
if (agent._skill_nudge_interval > 0
and "skill_manage" in agent.valid_tool_names):
agent._iters_since_skill += 1Step 2: 响应交付后才触发
# agent/turn_finalizer.py:374-397
# 先判断 skill nudge 是否达到阈值
if (agent._skill_nudge_interval > 0
and agent._iters_since_skill >= agent._skill_nudge_interval
and "skill_manage" in agent.valid_tool_names):
_should_review_skills = True
agent._iters_since_skill = 0
# 响应已经交付,再后台审查------不与用户任务争抢模型注意力
if final_response and not interrupted and (_should_review_memory or _should_review_skills):
agent._spawn_background_review(
messages_snapshot=list(messages),
review_memory=_should_review_memory,
review_skills=_should_review_skills,
)Step 3: 选择审查 Prompt
# agent/background_review.py:580-587
# 根据触发条件选择对应 prompt
if review_memory and review_skills:
prompt = _COMBINED_REVIEW_PROMPT # 同时审查记忆和技能
elif review_memory:
prompt = _MEMORY_REVIEW_PROMPT # 仅审查记忆
else:
prompt = _SKILL_REVIEW_PROMPT # 仅审查技能Step 4: Fork 独立 AIAgent
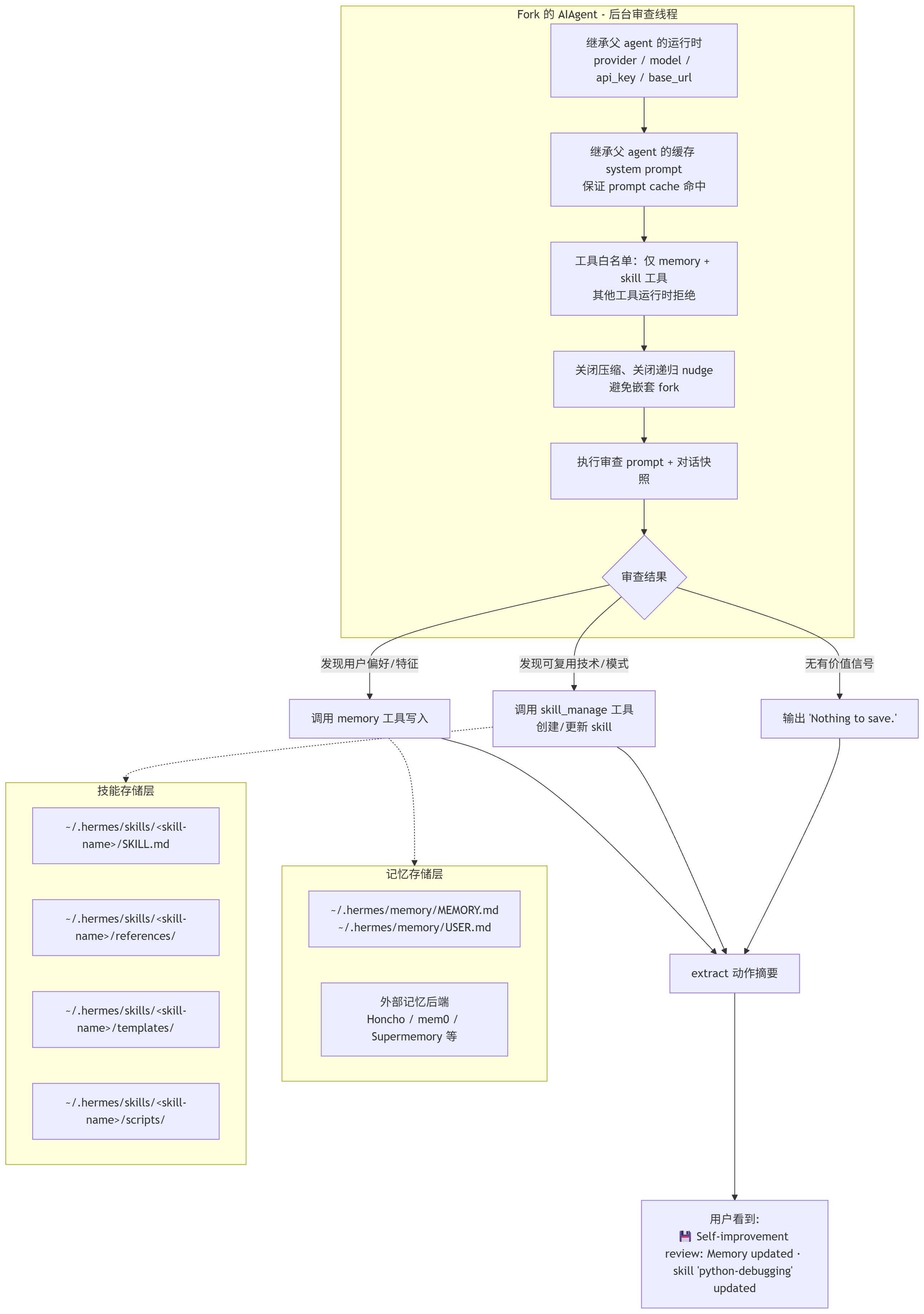
这是设计最精巧的环节:
# agent/background_review.py:400-425
review_agent = AIAgent(
model=agent.model, # 继承父 agent 的模型
provider=agent.provider, # 继承 provider
base_url=parent_runtime["base_url"], # 继承 base_url
api_key=parent_runtime["api_key"], # 继承 api_key
max_iterations=16, # 最多 16 次迭代
quiet_mode=True, # 静默模式
skip_memory=True, # 不访问外部记忆后端
)
# 关键:继承缓存 promptsystem prompt,保证 Anthropic cache 命中
review_agent._cached_system_prompt = agent._cached_system_prompt
# 关键:关闭压缩------审查需要完整上下文
review_agent.compression_enabled = False
# 关键:关闭递归 nudge------fork 不再触发内层 fork
review_agent._memory_nudge_interval = 0
review_agent._skill_nudge_interval = 0Step 5: 工具白名单限制
# agent/background_review.py:460-474
# 只允许 memory 和 skill 相关工具
review_whitelist = {
t["function"]["name"]
for t in get_tool_definitions(
enabled_toolsets=["memory", "skills"],
quiet_mode=True,
)
}
set_thread_tool_whitelist(review_whitelist)
# 其他工具运行时拒绝,例如终端、浏览器等Step 6: 运行审查
# agent/background_review.py:475-481
review_agent.run_conversation(
user_message=prompt + "\n\n" + "只能使用 memory 和 skill 管理工具",
conversation_history=messages_snapshot, # 完整对话快照作为上下文
)Step 7: 提取动作摘要
# agent/background_review.py:505-510
actions = summarize_background_review_actions(
review_messages,
messages_snapshot, # 排除对话中已有的旧工具结果
)
# 例如: actions = ["Memory updated", "skill 'python-debugging' updated"]Step 8: 通知用户
💾 Self-improvement review: Memory updated · skill 'python-debugging' updated记忆审查 Prompt 的核心意图
审查对话并考虑保存到记忆中。
关注点:
1. 用户是否透露了关于自身的信息------个性、愿望、偏好、个人细节?
2. 用户是否表达了对你行为的期望、工作风格、操作方式?
如果有值得记住的,使用 memory 工具保存。
如果没什么值得保存,说 'Nothing to save.' 然后停止。技能审查 Prompt 的核心意图(更复杂)
审查对话并更新技能库。要主动------大多数会话至少产生一个技能更新。
信号(任何一个就值得操作):
• 用户纠正了你的风格、语调、格式、详细程度
• 用户纠正了你的工作流、方法或步骤顺序
• 出现了非平凡的技术、修复、变通方案、调试路径或工具使用模式
• 本会话中加载/查阅的技能被证明是错误的、缺少步骤或过时的
操作优先级:
1. 更新"当前加载的"技能(通过 /skill-name 或 skill_view 加载的)
2. 更新一个已有的 umbrella skill
3. 在已有 umbrella 下添加 references/templates/scripts 支持文件
4. 创建一个新的类级别 umbrella skill
绝不要捕捉为 skill 的:
✗ 环境相关的失败(缺少二进制、未配置凭据等)
✗ 关于工具的负面断言("浏览器工具坏了"------修好后 agent 会自我设限数月)
✗ 已解决的瞬态错误
✗ 一次性任务叙述("总结今天的市场"不是一类工作)4.2 记忆管理器 (Memory Manager)
agent/memory_manager.py 是整个记忆系统的统一入口,替代了早期分散在各处的记忆代码。
架构
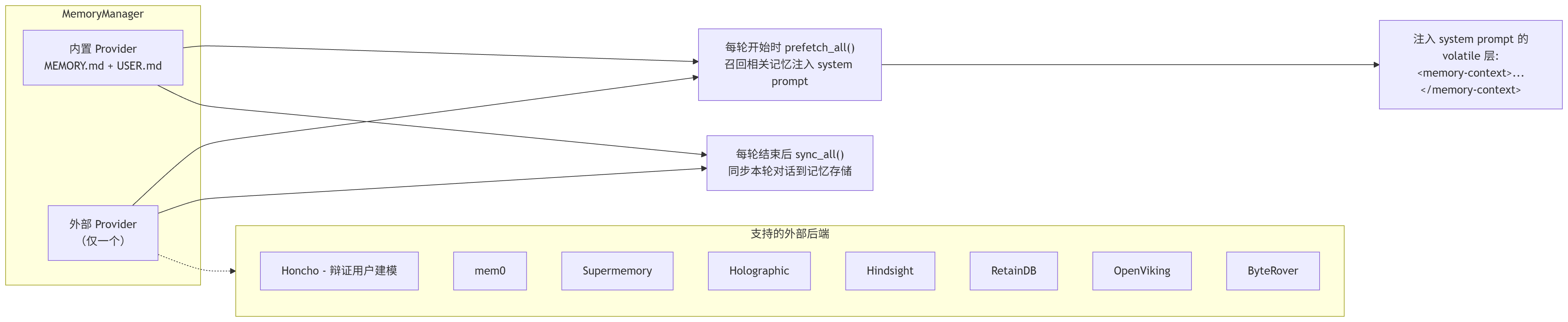
记忆上下文隔离
记忆内容通过 <memory-context> 标签注入 system prompt,并用 [System note] 标记:
<memory-context>
[System note: The following is recalled memory context,
NOT new user input. Treat as authoritative reference data ---
this is the agent's persistent memory and should inform all responses.]
用户偏好简洁的代码输出,不喜欢冗长的解释...
用户的工作环境是 Windows + PowerShell...
</memory-context>StreamingContextScrubber 确保即使流式输出被分割,这些标记也不会泄露到 UI 中。
核心约束
-
只有一个外部 provider:注册第二个会被拒绝并警告,防止工具 schema 膨胀和记忆后端冲突。
-
内置 provider 永远存在 :
~/.hermes/memory/MEMORY.md和USER.md不可移除。 -
核心工具名保护:memory provider 注册的工具如果与核心工具重名,会被拒绝(核心工具永远获胜)。
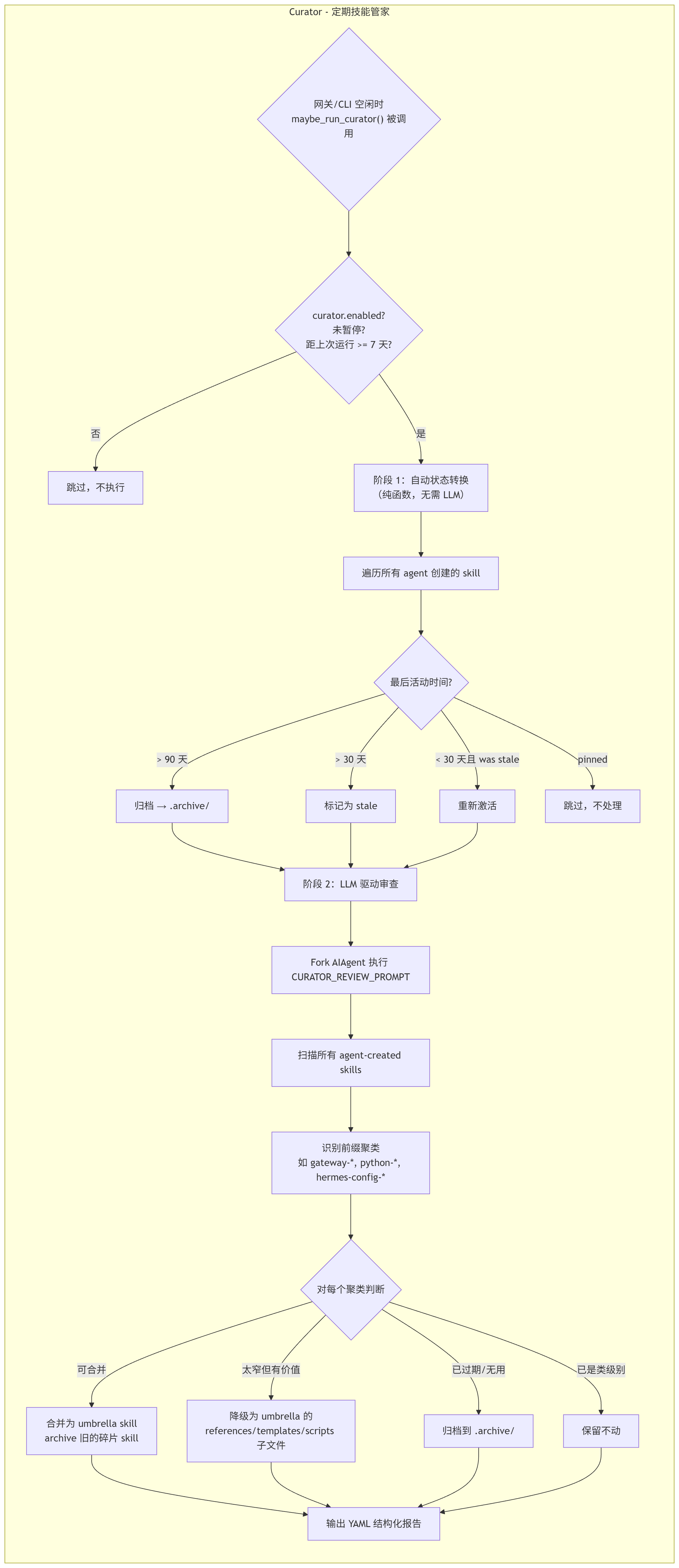
4.3 技能管家 (Curator)
agent/curator.py 不是 cron daemon,而是 空闲触发 的后台任务:
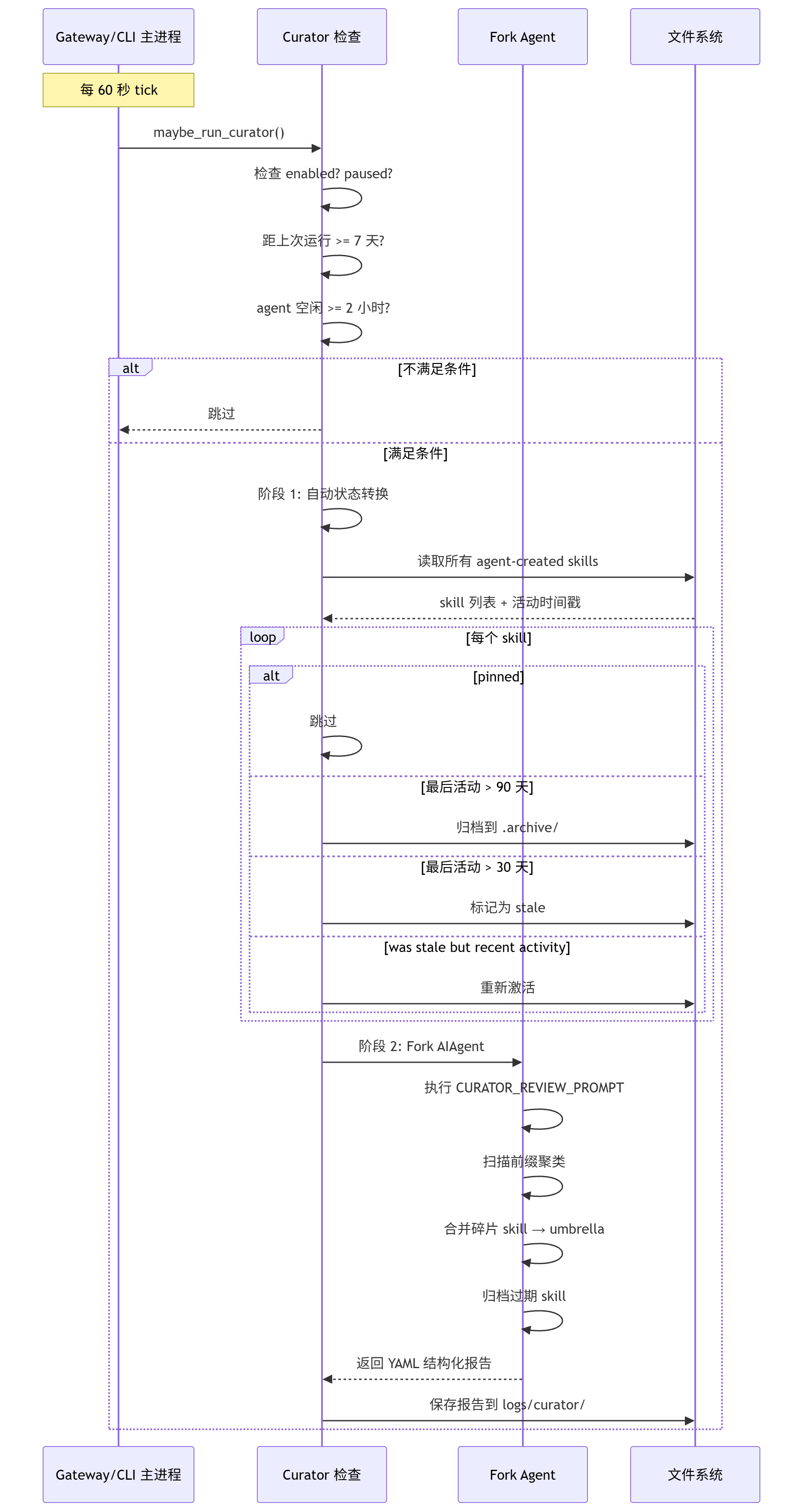
两阶段设计
阶段 1:自动状态转换(纯函数,无 LLM 开销)
# agent/curator.py:250-300
for row in agent_created_report():
if row.get("pinned"):
continue # pinned 技能永不自动转换
anchor = last_activity or created_at
if anchor <= archive_cutoff: # > 90 天无活动
archive_skill(name) # 移到 .archive/,可恢复
elif anchor <= stale_cutoff: # > 30 天无活动
set_state(name, STATE_STALE) # 标记为陈旧
elif anchor > stale_cutoff and current == STATE_STALE:
set_state(name, STATE_ACTIVE) # 重新激活阶段 2:LLM 驱动审查
Curator 的审查 prompt 非常强调"类级别"和"umbrella 合并":
-
扫描所有 agent 自创 skill
-
识别前缀聚类 (如
gateway-*、python-*) -
对每个聚类:合并为 umbrella skill 或降级为子文件
-
目标:把数百个碎片 skill 变成几十个高质量类级别 skill
Curator 的铁律
1. 绝不触碰 bundled / hub-installed 技能
2. 绝不删除------最大破坏性操作是归档(可恢复)
3. 绝不触碰 pinned=yes 的技能
4. 不以 use_count 低为理由拒绝合并------计数器是新功能,大多是 0
5. "每个 skill 有不同的触发器"不是拒绝合并的理由数据流全链路
将以上所有子系统串联起来,一图看清完整数据流:
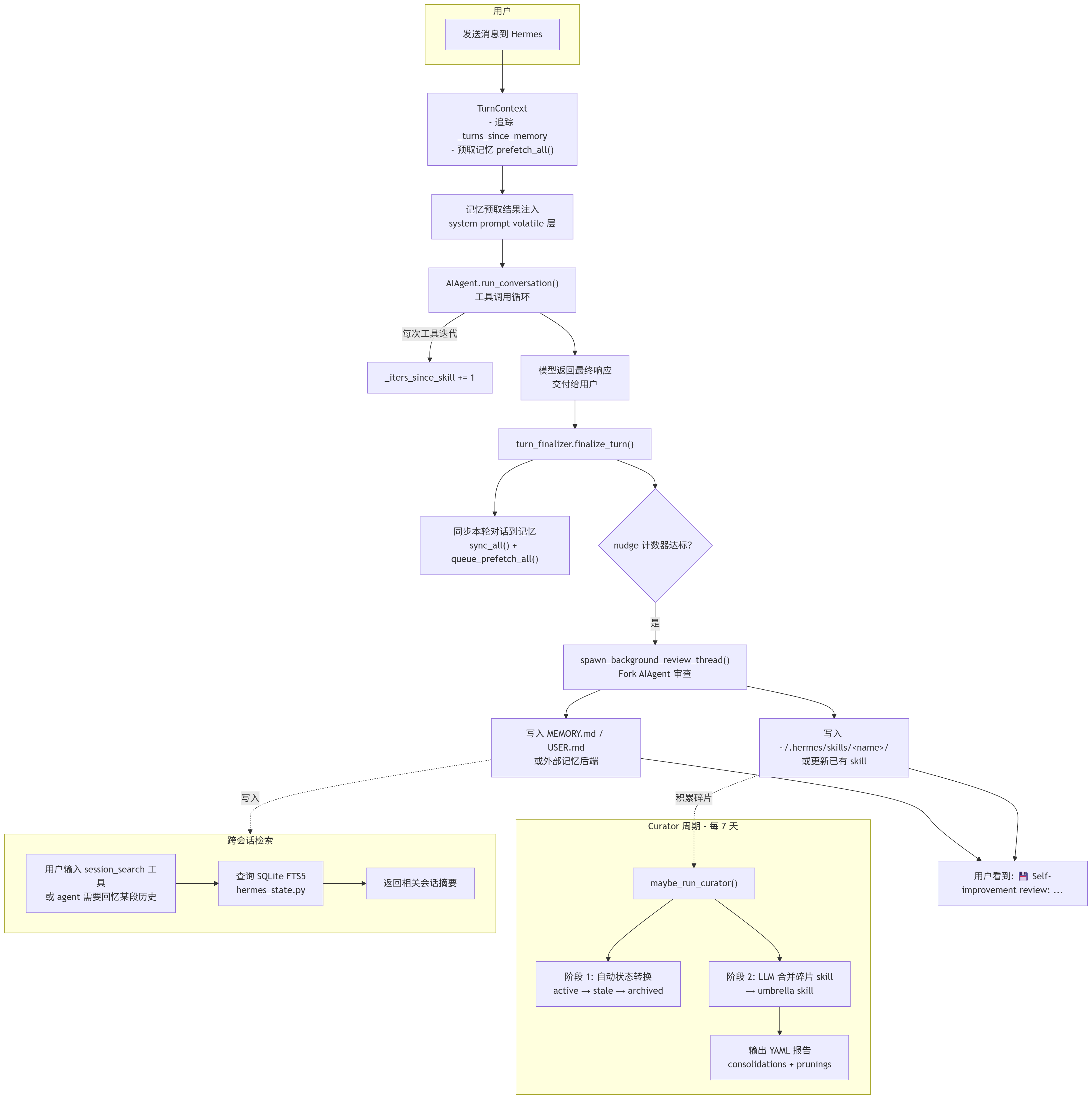
设计哲学
1. 主动而非被动 (Proactive, not Passive)
传统的记忆系统是"用户说存我才存"。Hermes 的核心理念是agent 应该自己判断什么值得沉淀。
每轮对话结束后,不是简单地记录日志,而是让一个独立的 agent 以"第三视角"复盘:
-
有没有出现新的用户偏好?
-
有没有出现值得复用的技术模式?
-
用户是否纠正了我?
如果没有,坦然说 Nothing to save.;如果有,主动写入。
2. 非阻塞、零感知 (Non-blocking, Zero-perception)
后台审查在 daemon 线程中运行,响应先交付给用户,审查后发生:
# agent/turn_finalizer.py:391
# Background memory/skill review --- runs AFTER the response is delivered
# so it never competes with the user's task for model attention.用户不会感知到审查的发生------只有在完成后看到一行简洁的 💾 Self-improvement review: ...。
3. 低成本复用 (Cost-Efficient Reuse)
Fork 的子 agent 通过以下手段最大化 API 调用的性价比:
4. 分层职责 (Layered Responsibility)
三个子系统各司其职,互不越界:
Background Review → 微观、高频 → 每 10 轮触发 → 从单轮对话中提取信号
Memory Manager → 基础设施 → 每轮必调用 → 管理记忆的存储/召回
Curator → 宏观、低频 → 每 7 天触发 → 从技能库整体视角做合并/归5. 安全不可妥协 (Safety Non-negotiable)
# 后台审查 fork 的审批回调
def _bg_review_auto_deny(command, description, **kwargs):
return "deny" # 危险命令一律拒绝,不会向用户弹窗审查 agent 只被允许使用 memory 和 skill 工具------即使模型幻觉要执行 rm -rf /,运行时也会被拒绝。
6. 渐进式、可逆 (Gradual & Reversible)
7. 类级别知识结构 (Class-Level Knowledge Structure)
Curator 的核心哲学是:"一个包含 100 个碎片技能的库是失败的"。目标是一个图书馆式的类级别结构:
❌ 错误的技能结构(碎片化):
- debug-python-importerror-20240501
- debug-python-modulenotfound-20240503
- fix-python-path-issue
- python-venv-setup-workaround
✅ 正确的技能结构(类级别 umbrella):
- python-debugging/
├── SKILL.md # 类级别:Python 调试方法论
├── references/
│ ├── import-errors.md # 会话特有的错误排查记录
│ └── venv-issues.md # 虚拟环境问题与修复
├── templates/
│ └── debug-script.py # 可复用的调试模板
└── scripts/
└── check-pyenv.sh # 环境检查脚本8. 隔离而非耦合 (Isolation over Coupling)
背景审查 fork 与主 agent 之间的隔离边界非常清晰:
-
独立 AIAgent 实例:不共享 conversation loop 状态
-
独立的 stdout/stderr:重定向到 /dev/null
-
不触碰外部记忆后端 :
skip_memory=True -
不参与上下文压缩 :
compression_enabled=False -
不触发递归 nudge :
_memory_nudge_interval=0, _skill_nudge_interval=0
唯一共享的是凭据 和缓存 system prompt------前者是必需品,后者是为了省钱。
关键源码索引
本文基于 Hermes Agent 源码分析生成。