note
- 路线对比:
- CLIP路线:图片 + 文本→ 学语义
- DINO路线:只有图片→ 学视觉世界本身
- 模型越大,分类能力越强,但容易出现Dense Feature Collapse(稠密特征退化)问题,局部patch特征开始混。比如CLIP、SigLIP等模型擅长图片xx是什么,但可能不擅长它长什么样、和旁边的像不像等;再比如五官边界模糊等,后者更靠dense feature
- DINOv3是目前最强的一批纯视觉 Foundation Model,它试图证明:不用文本监督(CLIP),光靠图片自监督学习,也能学出世界知识
- DINOv3通过扩展数据集和模型规模,引入Gram锚定方法(Gram Anchoring),并应用高分辨率适应和模型蒸馏技术,实现了大规模视觉表示的学习。
- DINOv3在各种视觉任务上表现出色,无需微调即可达到最先进的性能。DINOv3系列模型为不同的资源约束和部署场景提供了可扩展的解决方案,推动了自监督学习在计算机视觉领域的进一步发展。
- DINOv3冻结主干网络,只加一层简单线性头,就能超越很多专门有监督训练的专用模型。分类、检测、分割、深度估计、图像检索、3D 重建、目标追踪共用同一个主干,不用维护多个模型。
- 启发:未来最强的视觉编码器未必来自 Image-Text 对齐(CLIP),也可能来自超大规模自监督视觉学习(DINOv3)。 这也是近两年 GPT-4o、Gemini、Qwen-VL 等系统越来越重视高质量视觉表征而不仅仅是图文对齐的原因
文章目录
- note
- 一、研究背景
- 二、DINOv3
-
- [1、Gram Anchoring](#1、Gram Anchoring)
- 2、架构全面升级,适配超高分辨率图像
- 三、实验设计
- 四、结果与分析
- 五、论文评价
- 六、关键问题
- Reference
一、研究背景
- 研究问题:这篇文章要解决的问题是如何通过自监督学习(SSL)实现大规模视觉表示的学习,从而消除对手动数据标注的依赖。自监督学习通过从原始像素数据中学习,利用图像中模式的自然共现性,能够训练出强大的视觉编码器。
- 研究难点:该问题的研究难点包括:如何有效地扩展数据集和模型规模,如何解决密集特征图在长时间训练过程中出现的退化问题,以及如何在不进行微调的情况下提高模型在各种视觉任务上的性能。
- 相关工作:该问题的研究相关工作有:DINOv2(Oquab等人,2024),它在图像理解任务中取得了显著成果,并在病理学等复杂领域进行了预训练;其他自监督学习方法如CLIP(Radford等人,2021)和DINOv2(Oquab等人,2024)等,这些方法在图像分类和目标检测等任务上表现出色,但在处理密集特征图退化问题上仍有改进空间。
三代简单演进对比
DINOv1(2021):证明 ViT 能无监督自学,只能抓整张图全局特征,分割、轮廓识别很差;
DINOv2(2023):1.42 亿图训练,加掩码 iBOT 损失,局部细节变强,但模型放大、训练轮次拉长后,会丢失边缘、纹理、物体几何结构;
DINOv3(2025):17 亿精选图片、70 亿参数超大教师模型,新增Gram Anchoring 锚定损失,根治 "细节退化",全局语义 + 像素级局部特征双拉满,高分辨率图表现暴涨。
二、DINOv3
提出了DINOv3,用于解决自监督学习在大规模视觉表示学习中的挑战。
1、数据准备和模型扩展:首先,通过仔细的数据准备、设计和优化,扩展数据集和模型规模。使用层次k均值聚类和检索系统创建大规模预训练数据集,并将模型大小扩展到7B参数。
1、Gram Anchoring
2、Gram锚定方法:引入了一种新的方法叫做Gram锚定,用于有效解决密集特征图在长时间训练过程中出现的退化问题。Gram锚定通过在训练过程中保持特征图的局部一致性,避免了特征图的退化。具体公式如下:
L Gram = ∥ X S ⋅ X S T − X G ⋅ X G T ∥ F 2 \mathcal{L}_{\text{Gram}} = \| X_S \cdot X_S^T - X_G \cdot X_G^T \|_F^2 LGram=∥XS⋅XST−XG⋅XGT∥F2
其中, X S X_S XS 和 X G X_G XG 分别表示学生模型和Gram教师的局部特征矩阵。
Gram 矩阵本质是统计图片所有小块特征之间的关联关系,比如 "黄色皮毛 + 尖耳朵" 永远同时出现、"车轮 + 车身" 绑定在一起。
DINOv3 强制约束:原图和裁剪视图的 Gram 矩阵必须高度相似。
2、架构全面升级,适配超高分辨率图像
高分辨率适应和模型蒸馏:最后,应用高分辨率后训练阶段和蒸馏技术,生成一系列高性能的模型变体,包括Vision Transformer (ViT) Small、Base和Large,以及基于ConvNeXt的架构。
- RoPE 旋转位置编码:DINOv2 用可学习位置编码,放大图片尺寸后会失效;RoPE 靠三角函数给像素加位置信息,输入 512/1024 超大分辨率图不会崩,卫星图、医疗大图、航拍图友好。
- Patch 统一 16,超大 7B 教师模型:基座 Teacher ViT-7B(4096 维特征),再一次性蒸馏出 S/B/L/H 多种小尺寸模型,兼顾精度与部署速度;同时支持 ConvNeXt 卷积版本,低算力设备可用。
- 训练配方简化稳定:放弃复杂多段学习率,全程固定常数调度,17 亿图片稳定训练不崩溃,大规模自监督训练门槛大幅降低。
模型架构:
python
DINOv3ViTModel(
(embeddings): DINOv3ViTEmbeddings(
(patch_embeddings): Conv2d(3, 1024, kernel_size=(16, 16), stride=(16, 16))
)
(rope_embeddings): DINOv3ViTRopePositionEmbedding()
(layer): ModuleList(
(0-23): 24 x DINOv3ViTLayer(
(norm1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(attention): DINOv3ViTAttention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=False)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(o_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(layer_scale1): DINOv3ViTLayerScale()
(drop_path): Identity()
(norm2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp): DINOv3ViTMLP(
(up_proj): Linear(in_features=1024, out_features=4096, bias=True)
(down_proj): Linear(in_features=4096, out_features=1024, bias=True)
(act_fn): GELUActivation()
)
(layer_scale2): DINOv3ViTLayerScale()
)
)
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)DINOv3 ViT-L 实际结构:
- patch_embeddings: Conv2d,kernel=16×16,将 224×224 图切成 14×14 = 196 个 patch
- rope_embeddings: 用 RoPE(旋转位置编码)替代了传统的可学习位置编码,这是 DINOv3 相比 DINOv2 的重要改变
- 24层 Transformer block,hidden dim=1024,FFN dim=4096
模型推理:
python
def load_model():
processor = AutoImageProcessor.from_pretrained(MODEL_DIR)
model = AutoModel.from_pretrained(MODEL_DIR, dtype=torch.float32)
model.eval()
device = "cuda" if torch.cuda.is_available() else "cpu"
return processor, model.to(device), device
def extract_features(processor, model, device, image: Image.Image):
inputs = processor(images=image, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
cls_token = outputs.last_hidden_state[:, 0, :] # (1, 1024)
patch_feats = outputs.last_hidden_state[:, 1:, :] # (1, N, 1024)
return cls_token, patch_feats
cls1, patch1 = extract_features(processor, model, device, img1)
# CLS token 维度: torch.Size([1, 1024])
# Patch features 维度: torch.Size([1, 200, 1024])其中200的构成:
- 1 CLS token
- 196 patch token(14×14),Conv2d kernel=16×16,将 224×224 图切成 14×14 = 196 个 patch
- 4 register token(num_register_tokens=4,来自 DINOv2 的 registers 改进,DINOv3 继承了)
三、实验设计
- 数据收集和预处理:构建了一个大规模预训练数据集,包括从Instagram收集的约170亿张图像,并通过层次k均值聚类和检索系统进行预处理。数据集分为三个部分:自动聚类、检索系统和原始计算机视觉数据集(如ImageNet1k)。
- 模型训练:使用自定义的ViT架构,包含现代的位置嵌入(axial RoPE)和正则化技术以避免位置伪影。训练过程中使用恒定的超参数调度,训练1M次迭代。
- Gram锚定训练:在训练过程中引入Gram锚定损失,每10k次迭代更新一次Gram教师模型。
- 高分辨率适应:在训练结束后,进行高分辨率适应步骤,采样不同大小的全局/局部/Gram教师裁剪分辨率对,训练10k次迭代。
- 模型蒸馏:将7B教师模型的知识蒸馏到一系列更小的ViT模型中,包括ViT-S、ViT-B和ViT-L。
四、结果与分析
密集特征图质量:DINOv3生成的密集特征图在视觉质量上更为清晰,噪声更少,语义一致性更好。通过PCA降维后的三维可视化展示了这一点。
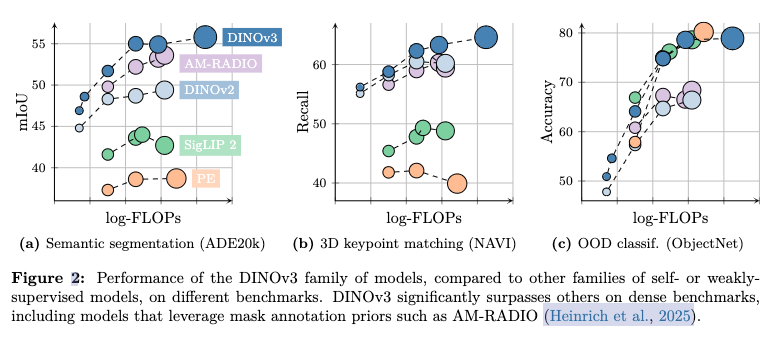
线性探测任务:在语义分割和单目深度估计任务上,DINOv3表现出色。在ADE20k数据集上,DINOv3的mIoU达到了55.9%,显著优于其他自监督基线。
3D对应关系估计:在NAVI和SPair数据集上,DINOv3在几何和语义对应关系估计任务上表现优异,几何对应关系的召回率分别提高了4.3%和2.6%。
无监督对象发现:在VOC 2007数据集上,DINOv3的CorLoc评分提高了5.9%,显著优于其他自监督基线。
视频分割跟踪:在DAVIS 2017数据集上,DINOv3的J&F-mean评分为83.3%,显著优于其他竞争者。
视频分类:在UCF101数据集上,DINOv3的top-1准确率为93.5%,与最先进的弱监督模型相当。
五、论文评价
1、优点与创新
1、数据准备和优化:通过仔细的数据准备、设计和优化,实现了数据集和模型规模的扩展。
2、Gram锚定方法:引入了一种新的方法Gram锚定,有效解决了密集特征图在长时间训练过程中退化的问题。
3、后处理策略:应用了高分辨率后训练和蒸馏等后处理策略,进一步增强了模型的灵活性,使其在分辨率、模型大小和对齐文本方面表现更好。
4、多功能视觉基础模型:提出了一个多功能的视觉基础模型,无需微调即可在各种视觉任务上超越现有的专门状态。
5、高质量密集特征:生成了高质量的密集特征,在视觉任务的各个方面都取得了杰出的性能,显著超越了之前自监督和监督的基础模型。
6、模型家族:分享了设计用于在不同资源约束和部署场景下推进最先进水平的DINOv3系列模型。
7、自监督学习的通用性:展示了自监督学习在不同领域(如卫星图像)的通用性,超越了所有先前的自监督学习方法。
8、环境影响评估:对预训练的碳排放进行了评估,提供了详细的计算和数据。
2、不足与反思
1、高范数补丁异常值:在大规模训练中观察到的高范数补丁异常值问题仍然存在,尽管通过引入寄存器标记和注意力机制中的偏差策略来缓解这一问题。
2、特征维度异常值:尽管引入了寄存器标记,但在训练7B模型时仍然观察到特征维度异常值问题,这些异常值在训练过程中逐渐增加并在输出层达到最大值。建议在推理时使用最终层归一化或批量归一化来处理这些异常值。
3、OCR密集型任务的挑战:在OCR密集型任务中,DINOv3与最先进的弱监督模型相比仍有较大差距,表明在这些任务中学习字形关联具有挑战性。未来的工作可以集中在缩小这一差距。
4、地理公平性和多样性:尽管DINOv3在不同收入类别和地区表现出相对一致的绩效,但在低收入类别中存在显著的绩效下降,欧洲和非洲之间的相对差异也超过了14%。未来的工作可以进一步探讨如何提高模型在不同地理区域和收入类别上的公平性和多样性。
六、关键问题
问题1:DINOv3在解决密集特征图退化问题上引入了什么新方法?其具体原理是什么?
DINOv3引入了Gram锚定方法来解决密集特征图在长时间训练过程中出现的退化问题。具体原理是通过在训练过程中保持特征图的局部一致性来避免特征图的退化。Gram锚定的核心思想是利用Gram矩阵来度量学生模型和Gram教师模型之间的特征相似性。Gram矩阵是所有局部特征对的点积矩阵。具体公式如下:
L Gram = ∥ X S ⋅ X S T − X G ⋅ X G T ∥ F 2 \mathcal{L}_{\text{Gram}} = \| X_S \cdot X_S^T - X_G \cdot X_G^T \|_F^2 LGram=∥XS⋅XST−XG⋅XGT∥F2
其中, X S X_S XS 和 X G X_G XG 分别表示学生模型和Gram教师的局部特征矩阵。通过最小化这个损失函数,DINOv3能够在训练过程中保持特征图的局部一致性,从而避免特征图的退化。
问题2:DINOv3在数据准备和模型扩展方面采取了哪些具体措施?这些措施对模型性能有何影响?
- 数据收集和预处理:构建了一个大规模预训练数据集,包括从Instagram收集的约170亿张图像,并通过层次k均值聚类和检索系统进行预处理。数据集分为三个部分:自动聚类、检索系统和原始计算机视觉数据集(如ImageNet1k)。
- 模型扩展:将模型大小扩展到7B参数,并使用自定义的ViT架构,包含现代的位置嵌入(axial RoPE)和正则化技术以避免位置伪影。训练过程中使用恒定的超参数调度,训练1M次迭代。
- 这些措施对模型性能的影响显著。通过扩展数据集和模型规模,DINOv3能够学习到更丰富的特征表示。引入Gram锚定方法有效地解决了密集特征图在长时间训练过程中出现的退化问题,进一步提升了模型的稳定性和性能。高分辨率适应和模型蒸馏技术则使得DINOv3能够在各种视觉任务上表现出色,无需微调即可达到最先进的性能。
问题3:DINOv3在视频分割跟踪任务上表现如何?与其他竞争者相比有何优势?
- DINOv3在视频分割跟踪任务上表现优异。在DAVIS 2017数据集上,DINOv3的J&F-mean评分为83.3%,显著优于其他竞争者。具体优势包括:
- 特征质量:DINOv3生成的密集特征图在视觉质量上更为清晰,噪声更少,语义一致性更好,这使得其在视频分割任务中能够更准确地捕捉对象的边界和细节。
- 训练策略:DINOv3采用了高分辨率适应和模型蒸馏技术,生成了一系列高性能的模型变体,这些模型在视频分割任务中表现出色。
- 鲁棒性:DINOv3在处理视频帧时能够保持特征的稳定性和一致性,即使在复杂的光照和运动条件下也能表现良好。
Reference
1 DINOv3