今天看的项目是 Panniantong/Agent-Reach。
它主要解决的是:让 AI Agent 不只会读本地文件和网页,还能连接更多真实互联网信息源,比如 Twitter、Reddit、YouTube、GitHub、B站、小红书等。
先说我的建议:值得关注,可以试用,但不要把它当成稳定生产级信息采集基础设施。
如果你经常用 AI Agent 做调研、内容分析、竞品观察、开源项目筛选,可以重点看看;如果你对账号安全、Cookie、隐私和平台风控非常敏感,暂时不要急着上车。
说明:本文基于项目公开信息进行观察,不是完整实测评测,重点是帮你判断这个项目是否值得关注。
先用一张图看懂它
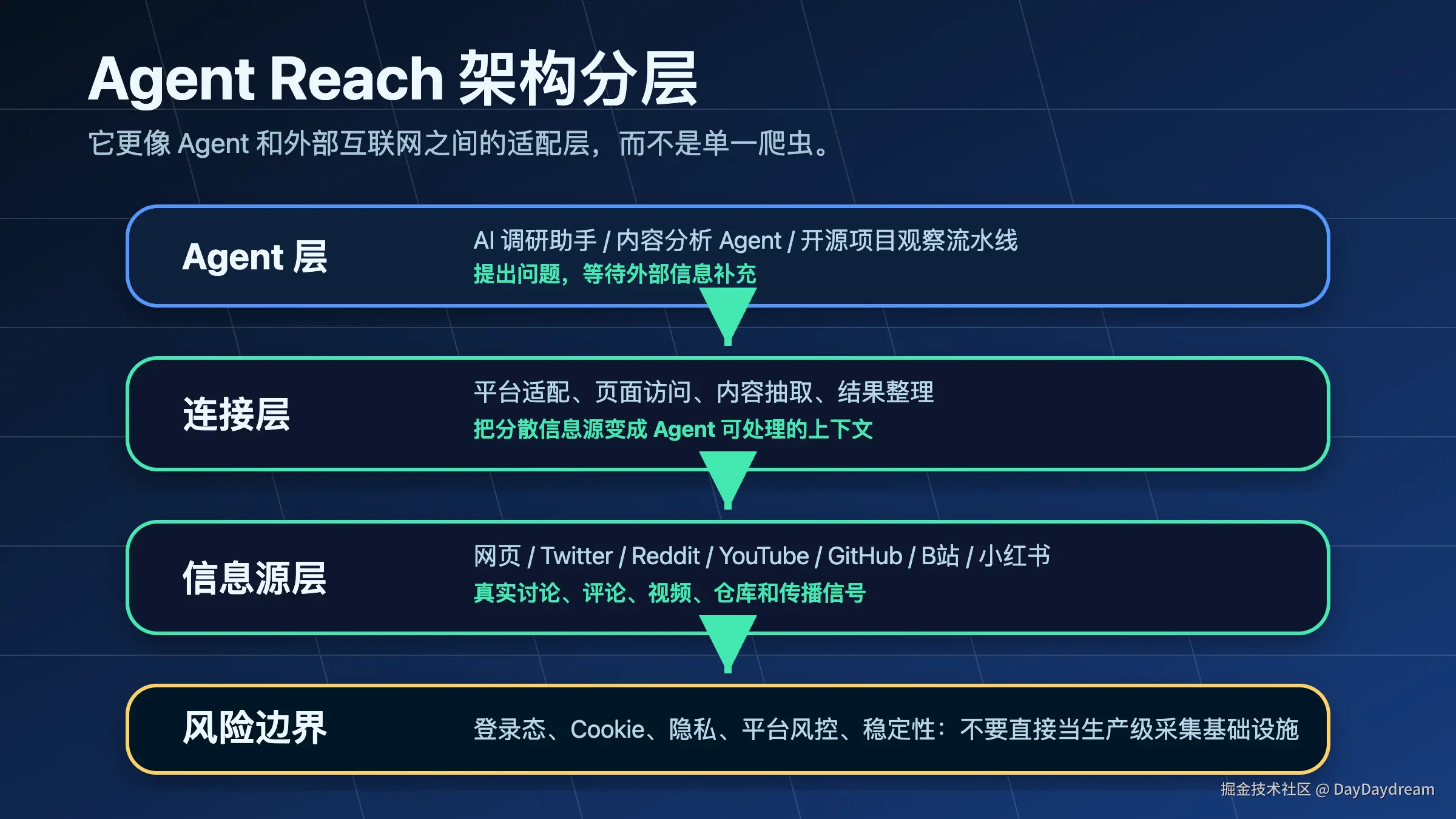
这张图可以把 Agent Reach 理解成 AI Agent 的"互联网触手":Agent 提出问题,Agent Reach 去连接网页、社媒、视频站点、代码平台等信息源,再把结果整理回上下文里。
一、这个项目是做什么的?
Agent Reach 可以理解成:给 AI Agent 用的多平台信息获取层。
它不是一个单纯的网页爬虫,也不是只针对某个平台的下载工具。更准确地说,它想解决的是:
AI Agent 想做真实世界调研时,怎么稳定拿到外部信息。
它大概提供这些能力:
- 连接多个公开互联网平台;
- 让 Agent 读取网页、社媒、视频、代码平台等内容;
- 把外部信息变成 Agent 可以继续处理的上下文;
- 降低每个项目单独写平台适配器的成本。
一句话总结:它想给 AI Agent 装上"看外部世界的眼睛"。
二、它为什么最近会火?
我觉得主要有三个原因。
1. AI Agent 正在从"写代码"走向"做调研"
很多人最开始用 Agent,是让它改代码、跑命令、读本地文件。
但真正复杂的任务往往不只发生在本地项目里。比如:
- 调研一个开源项目为什么火;
- 分析某个产品在社区里的反馈;
- 看 YouTube 或 B站视频里的信息;
- 找小红书、Reddit、Twitter 上的真实用户讨论;
- 比较多个工具在不同平台上的传播情况。
这些任务都要求 Agent 能访问外部信息,而不是只在本地文件里打转。
2. 多平台信息源越来越重要
以前做技术调研,看 GitHub、文档、搜索引擎可能就够了。
现在很多信息分散在不同平台:
- 技术讨论在 GitHub、Reddit、Twitter;
- 产品反馈在小红书、B站、YouTube;
- 用户真实吐槽可能在评论区;
- 新工具传播经常先出现在社媒。
如果 Agent 只能读网页搜索结果,它看到的是压缩过的一层信息。
如果它能进入更多信息源,就可能更接近真实语境。
3. 它击中了"Agent 信息获取能力不足"的痛点
现在很多 Agent 工具很会执行任务,但获取外部信息的能力参差不齐。
常见问题是:
- 搜索结果太浅;
- 网页内容抓取不稳定;
- 视频、社媒、评论区难处理;
- 平台登录态和反爬机制复杂;
- 每个平台都要单独适配。
Agent Reach 之所以容易被关注,是因为它把这些问题包装成一个更直观的方向:
让 Agent reach the internet。
三、它解决的是谁的痛点?
我觉得它最适合这几类人。
1. 重度使用 AI Agent 做调研的人
如果你经常让 AI 帮你找资料、分析趋势、整理竞品,它会很有吸引力。
因为你的问题通常不是"AI 会不会总结",而是:
AI 能不能拿到足够真实、足够新的信息。
2. 做内容分析和开源项目观察的人
这类场景和我们这个栏目本身也很贴近。
比如每天找高增长开源项目时,除了看仓库本身,还可能想看:
- Twitter 有没有讨论;
- Reddit 有没有真实使用反馈;
- YouTube 有没有测评;
- 小红书或 B站有没有中文传播;
- GitHub issue 里有没有明显问题。
如果 Agent 能自动聚合这些信号,内容判断效率会提高很多。
3. 做内部知识助手或研究助手的人
企业内部如果想做"研究型 Agent",也会遇到类似问题。
Agent 不只要读内部文档,还要读外部公开资料、行业动态、竞品信息和社区反馈。
Agent Reach 代表的方向,就是把"信息源接入"变成 Agent 基础设施的一部分。
再看一张结构图
从结构上看,它更像 Agent 和外部互联网之间的适配层:上层是各种 AI Agent 或自动化任务,中间是 Agent Reach 负责平台连接和内容抽取,底层是不同网站、社媒、视频站点和代码平台。
四、普通开发者怎么看它的价值?
对普通应用开发者 / 全栈开发者来说,不要只把它看成"又一个爬虫工具"。
更实用的理解是:
它在补 AI Agent 的信息获取短板。
我会重点看三件事。
-
它解决的问题是不是高频?
对做调研、内容分析、竞品研究的人很高频;对只写业务代码的人不一定高频。
-
它是不是能接入现有工作流?
如果它能被 Agent 工具稳定调用,就有机会成为调研流水线的一环;如果只能手动跑,价值会下降。
-
它是不是值得现在投入时间?
可以试,但不要一开始就把关键业务流程押上去。多平台接入通常会受到登录态、平台规则、页面变化和风控影响。
我更愿意把它看成:
AI Agent 的"外部信息连接器"。
五、适合谁?不适合谁?
适合
- 经常用 AI Agent 做资料调研的人;
- 做内容分析、竞品分析、开源项目观察的人;
- 想让 Agent 读取社媒、视频、评论区信息的人;
- 做研究助手、信息聚合工具、自动化内容流水线的人。
不适合
- 对 Cookie、账号登录态、隐私和安全非常敏感的人;
- 想要企业级稳定数据采集基础设施的人;
- 不想处理平台风控、反爬、页面变化的人;
- 只是偶尔用 AI 写代码的人。
六、我的建议
我的建议是:值得关注,可以试用,但不要把它当成稳定生产级信息采集基础设施。
原因有三个。
第一,它切中的问题真实存在。AI Agent 想真正做调研,必须能看到本地文件之外的信息。
第二,多平台信息源会越来越重要。尤其是内容分析、产品调研、开源项目观察这类任务,信息往往分散在社媒、视频、评论和社区里。
第三,它代表了一个重要趋势:Agent 不只是执行器,也需要信息获取基础设施。
但我不会建议所有人马上重度依赖。主要原因是:
- 多平台抓取稳定性天然不容易保证;
- 登录态、Cookie、账号安全需要谨慎处理;
- 不同平台规则变化会影响可用性;
- 外部信息源越多,噪声和误判也越多。
所以我的最终判断是:
如果你正在做 AI 调研助手、内容分析工具、开源项目观察流水线,可以试用;如果你只是普通开发者,先收藏,等它生态和稳定性进一步验证。