SoftPatch: Unsupervised Anomaly Detection with Noisy Data 论文阅读笔记
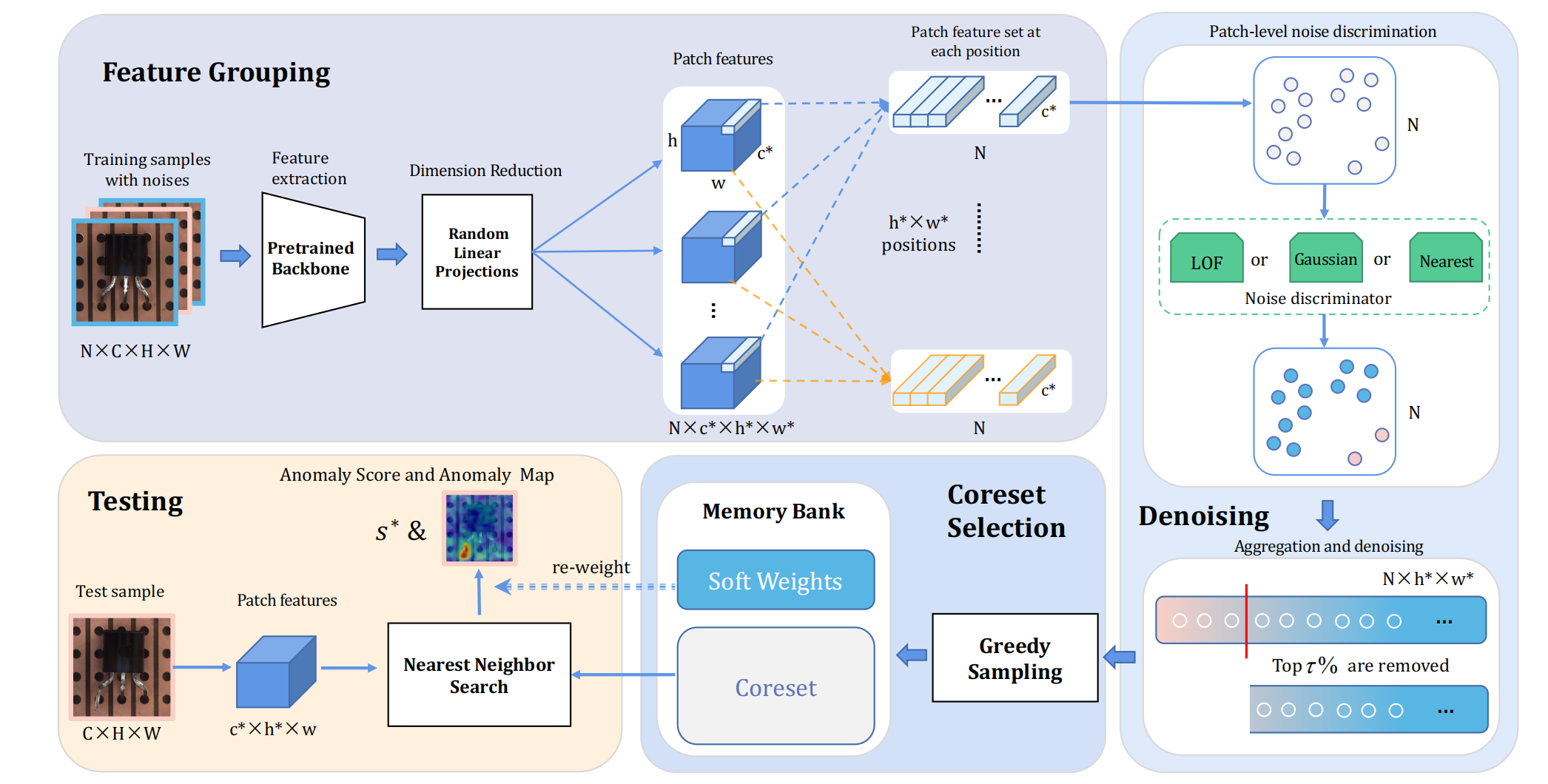
1. 论文基本信息
-
论文标题:SoftPatch: Unsupervised Anomaly Detection with Noisy Data
-
任务方向:无监督异常检测,工业视觉异常检测,异常定位
-
核心关键词:
- Unsupervised Anomaly Detection
- Noisy Training Data
- Patch-level Denoising
- Memory Bank
- Coreset Selection
- Local Outlier Factor
- Soft Re-weighting
2. 一句话总结
这篇论文关注一个更真实的工业异常检测场景:训练集中可能混入异常样本 。为了解决传统方法过度相信训练集干净的问题,作者提出 SoftPatch,在构建 memory bank 之前先进行 patch 级别去噪 ,并在推理阶段使用 soft weight 降低可疑训练 patch 对异常分数的影响。
3. 研究背景
无监督工业异常检测通常假设训练集只包含正常样本。很多经典方法,例如 PatchCore,会提取训练图像的 patch 特征,并将这些特征构造成 coreset / memory bank。测试时,如果某个测试 patch 和 memory bank 中的正常 patch 很接近,就认为它是正常的;如果距离很远,则认为它可能异常。
但是在真实工业场景中,训练集并不一定完全干净。由于人工误判、数据漂移、生产缺陷难以彻底过滤等原因,一些异常图像可能会混入正常训练集。如果异常 patch 被存入 memory bank,模型在测试阶段遇到相似异常时,就可能把它误判为正常。
因此,这篇论文想解决的问题是:
在训练集存在噪声,也就是混入异常样本的情况下,如何提升无监督异常检测模型的鲁棒性?
4. 论文核心问题
传统无监督异常检测方法存在一个隐含假设:
训练集中的样本全部是正常样本。
但这个假设在真实工业场景中经常不成立。
如果训练集中混入异常样本,会产生两个问题:
-
异常 patch 污染 memory bank
PatchCore 等方法会把训练 patch 特征存入 memory bank。如果异常 patch 被存进去,模型就会把某些异常模式也当成正常模式。
-
模型对训练集过度自信
传统 memory-based 方法默认训练特征都是正常的,因此在推理时只要测试 patch 找到相似训练 patch,就容易被判为正常。这样会导致类似异常在测试阶段被漏检。
5. 方法总览:SoftPatch
SoftPatch 的整体思想可以概括为:
不要完全相信训练集中的每个 patch,而是先判断每个 patch 是否可疑,再决定它是否进入 memory bank,以及它在推理时应该有多大影响。
SoftPatch 主要包含两个关键模块:
-
Patch-level Denoising
- 在训练阶段对 patch 级特征进行离群检测;
- 删除最可疑的异常 patch;
- 保留同一张噪声图像中仍然正常的 patch。
-
Soft Re-weighting
- 对保留下来的 patch 保存一个 soft weight;
- 推理阶段使用该权重重新加权 anomaly score;
- 降低可疑训练 patch 对最终判断的影响。
6. 为什么是 patch-level,而不是 image-level?
工业异常通常只占据图像中的一小块区域。例如划痕、污点、裂纹等缺陷往往是局部的。
如果使用 image-level denoising,也就是直接删除整张疑似异常图像,会有两个问题:
- 一张异常图像中大部分区域可能仍然是正常的;
- 删除整张图会浪费大量正常 patch 信息。
因此,SoftPatch 采用 patch-level denoising:
- 异常 patch 被删除;
- 正常 patch 仍然可以被利用;
- 数据利用率更高;
- 对局部缺陷更友好。
7. SoftPatch 的具体流程
SoftPatch 的整体流程如下:
-
输入训练图像
- 训练集中可能包含正常图像,也可能混入异常图像。
-
使用预训练 backbone 提取特征
- 对每张图像提取 feature map;
- 每个空间位置对应一个 patch feature。
-
按空间位置进行特征分组
- 将不同图像中同一位置的 patch 放在一起比较;
- 这样可以缩小比较范围,使离群检测更准确。
-
计算每个 patch 的 outlier score
-
使用 noise discriminator 判断 patch 是否可疑;
-
论文中使用了三种方法:
- Nearest Neighbor distance
- Multi-variate Gaussian / Mahalanobis distance
- LOF
-
-
删除 top τ% 最可疑 patch
- outlier score 越高,越可能是异常 patch;
- 删除分数最高的一部分 patch。
-
构建 coreset / memory bank
- 对剩余 patch 进行 coreset sampling;
- 构造更加干净的 memory bank。
-
保存 soft weight
- 对保留 patch 的 outlier score 进行保存;
- 推理时用来重新加权 anomaly score。
-
推理阶段进行最近邻搜索
- 测试 patch 在 memory bank 中寻找最近邻;
- 根据距离和 soft weight 计算最终异常分数。
8. 三种 Noise Discriminator 的思想
8.1 Nearest Neighbor Distance
Nearest Neighbor 的思想最直观:
如果一个 patch 连最近的邻居都离它很远,那么它可能是异常 patch。
对于某个 patch feature:
\\phi_i(h,w)
它的最近邻离群分数定义为:
W_i\^{nn}(h,w)=\\min_{n\\neq i}\|\\phi_i(h,w)-\\phi_n(h,w)\|_2
其中:
- (\phi_i(h,w)):第 (i) 张图像在位置 ((h,w)) 的 patch 特征;
- (\phi_n(h,w)):其他图像在同一位置的 patch 特征;
- 距离越大,说明该 patch 越孤立,越可能是异常。
优点:
- 简单直接;
- 能识别明显离群 patch。
缺点:
- 只看最近邻,缺少对整体分布的建模;
- 如果正常数据本身分布不均匀,可能误判稀疏正常点。
8.2 Multi-variate Gaussian / Mahalanobis Distance
Multi-variate Gaussian 的思想是:
同一位置的正常 patch 特征应该服从某种高维高斯分布,偏离该分布越远,越可能异常。
首先计算每个空间位置上的均值和协方差:
μh,w,Σh,w \mu_{h,w}, \Sigma_{h,w} μh,w,Σh,w
然后用 Mahalanobis distance 衡量 patch 偏离正常分布的程度:
Wimvg(h,w)=(ϕi(h,w)−μh,w)TΣh,w−1(ϕi(h,w)−μh,w) W_i^{mvg}(h,w)= \sqrt{ (\phi_i(h,w)-\mu_{h,w})^T \Sigma_{h,w}^{-1} (\phi_i(h,w)-\mu_{h,w}) } Wimvg(h,w)=(ϕi(h,w)−μh,w)TΣh,w−1(ϕi(h,w)−μh,w)
相比普通欧氏距离,Mahalanobis distance 会考虑不同方向上的方差。
直觉是:
- 如果某个方向本身变化很大,那么偏离一点不一定异常;
- 如果某个方向本身很稳定,那么轻微偏离也可能很可疑。
优点:
- 能利用整体统计分布;
- 比简单最近邻更有分布建模能力。
缺点:
- 默认数据近似服从单个高斯分布;
- 对多簇分布、错位图像、小簇正常模式不够友好。
8.3 LOF:Local Outlier Factor
LOF 的思想是:
不看一个点离全局中心多远,而是看它所在区域的局部密度是否明显低于邻居区域的局部密度。
LOF 的计算步骤如下:
第一步:找到 k 个最近邻
对某个 patch (\phi_i(h,w)),找到它的 (k) 个最近邻:
Nk(ϕi(h,w)) N_k(\phi_i(h,w)) Nk(ϕi(h,w))
第二步:计算 reachability distance
distkreach(ϕi,ϕb) dist_k^{reach}(\phi_i,\phi_b) distkreach(ϕi,ϕb)
max(distk(ϕb),d(ϕi,ϕb)) \max(dist_k(\phi_b), d(\phi_i,\phi_b)) max(distk(ϕb),d(ϕi,ϕb))
其中:
- (d(ϕi,ϕb)d(\phi_i,\phi_b)d(ϕi,ϕb)):两个 patch 之间的 L2 距离;
- (distk(ϕb)dist_k(\phi_b)distk(ϕb)):邻居 (\phi_b) 到其第 (k) 个最近邻的距离。
第三步:计算局部可达密度 LRD
lrdi(h,w)=1∑b∈Nk(ϕi(h,w))distkreach(ϕi(h,w),ϕb(h,w))∣Nk(ϕi(h,w))∣ lrd_i(h,w)= \frac{1}{ \frac{ \sum_{b\in N_k(\phi_i(h,w))} dist_k^{reach}(\phi_i(h,w),\phi_b(h,w)) }{ |N_k(\phi_i(h,w))| } } lrdi(h,w)=∣Nk(ϕi(h,w))∣∑b∈Nk(ϕi(h,w))distkreach(ϕi(h,w),ϕb(h,w))1
LRD 可以理解为局部密度:
- 平均距离越小,局部密度越大;
- 平均距离越大,局部密度越小。
第四步:计算 LOF 分数
WiLOF(h,w)=∑b∈Nk(ϕi(h,w))lrdb(h,w)∣Nk(ϕi(h,w))∣⋅lrdi(h,w) W_i^{LOF}(h,w)= \frac{ \sum_{b\in N_k(\phi_i(h,w))} lrd_b(h,w) }{ |N_k(\phi_i(h,w))|\cdot lrd_i(h,w) } WiLOF(h,w)=∣Nk(ϕi(h,w))∣⋅lrdi(h,w)∑b∈Nk(ϕi(h,w))lrdb(h,w)
直观理解:
LOFi=邻居的平均局部密度自己的局部密度 LOF_i = \frac{\text{邻居的平均局部密度}}{\text{自己的局部密度}} LOFi=自己的局部密度邻居的平均局部密度
如果:
- (LOF \approx 1):说明该 patch 和邻居密度差不多,通常是正常的;
- (LOF > 1):说明该 patch 比邻居更稀疏,更可能是异常;
- (LOF) 越大,离群程度越强。
LOF 的优点是它关注局部密度,因此更适合处理多簇、不均匀、高维的 patch 特征分布。
9. Soft Weight 的作用
即使做了 patch-level denoising,也不可能完全删除所有异常 patch。有些异常 patch 和正常 patch 很像,属于 hard noisy samples,可能仍然留在 memory bank 中。
因此,SoftPatch 进一步引入 soft weight。
对于测试 patch §,先在 memory bank (M) 中找到最近邻:
m∗=argminm∈M∣p−m∣2 m^*=\arg\min_{m\in M}|p-m|_2 m∗=argm∈Mmin∣p−m∣2
然后计算 patch-level anomaly score:
sh,w=Wm∗∣ph,w−m∗∣2 s_{h,w}=W_{m^*}|p_{h,w}-m^*|_2 sh,w=Wm∗∣ph,w−m∗∣2
其中:
- (m∗m^*m∗):测试 patch 在 memory bank 中的最近邻;
- (Wm∗W_{m^*}Wm∗):该 memory patch 对应的 soft weight;
- (∣ph,w−m∗∣2|p_{h,w}-m^*|_2∣ph,w−m∗∣2):测试 patch 与最近邻之间的距离。
Soft weight 的作用是:
如果某个 memory patch 本身比较可疑,那么它在推理时对测试 patch 的"正常性证明"就应该被削弱。
换句话说,SoftPatch 不再把 memory bank 中的所有 patch 都当成完全可信的正常样本,而是给它们不同的置信度。
10. 与 PatchCore 的关系
SoftPatch 可以看作是对 PatchCore 的鲁棒性增强。
PatchCore 的流程是:
text
训练图像 → 特征提取 → coreset sampling → memory bank → 最近邻异常检测SoftPatch 的流程是:
text
训练图像 → 特征提取 → patch-level noise discrimination → 删除异常 patch → coreset sampling → memory bank + soft weights → 加权最近邻异常检测两者的核心区别在于:
| 方法 | 是否考虑训练集噪声 | memory bank 是否完全可信 | 是否使用 soft weight |
|---|---|---|---|
| PatchCore | 否 | 是 | 否 |
| SoftPatch | 是 | 否 | 是 |
PatchCore 的问题是对训练集过度自信;SoftPatch 的改进点是先过滤异常 patch,并对保留 patch 赋予软置信度。
11. 实验设计
论文主要在两个数据集上进行实验:
-
MVTecAD
- 工业异常检测常用数据集;
- 论文人为向训练集中加入一定比例的异常样本,构造 noisy training set;
- 分为 No overlap 和 Overlap 两种设置。
-
BTAD
- 另一个工业异常检测数据集;
- 作者发现 BTAD 原始训练集中本身就存在一些噪声样本,因此更接近真实场景。
评价指标包括:
- Image-level AUROC
- Pixel-level AUROC
其中:
- Image-level AUROC 衡量整张图是否异常;
- Pixel-level AUROC 衡量异常区域定位效果。
12. 主要实验结论
论文实验表明:
- 当训练集混入异常样本时,传统方法性能会下降;
- PatchCore 在 Overlap 设置下下降尤其明显,因为它容易把异常 patch 存进 memory bank;
- SoftPatch 在 noisy training data 下更加稳定;
- 三种 noise discriminator 中,LOF 整体表现最好;
- 在 BTAD 数据集上,SoftPatch 也取得了较好的结果,说明它对真实噪声训练集有实际意义。
13. 论文创新点
13.1 提出更真实的问题设定
以往无监督异常检测默认训练集是干净的,但真实工业场景中训练集可能混入异常样本。论文将 noisy training data 引入无监督工业异常检测,是一个更贴近实际应用的问题设定。
13.2 Patch-level denoising
相比 image-level denoising,patch-level denoising 更适合工业缺陷检测,因为工业异常往往只占据局部区域。该策略可以删除异常区域,同时保留同一张图中的正常区域。
13.3 Soft re-weighting
作者没有简单地认为去噪后剩余 patch 都是完全正常的,而是保留 outlier score 作为 soft weight,在推理阶段重新加权 anomaly score。这缓解了 memory bank 过度自信的问题。
13.4 与现有 memory-based 方法兼容
SoftPatch 的主体框架仍然基于 PatchCore 思路,因此方法简单、直观,并且容易和 memory bank 类异常检测方法结合。
14. 方法优点
-
更符合真实工业场景
- 考虑训练集中存在噪声的问题。
-
数据利用率高
- 不直接删除整张异常图,而是删除局部异常 patch。
-
对 PatchCore 改动较小
- 在原有 memory bank 框架上加入去噪和加权模块。
-
LOF 适合复杂分布
- LOF 通过局部密度判断离群点,能更好处理多簇和不均匀分布。
-
鲁棒性更强
- 在 noisy training data 下相比传统方法更加稳定。
15. 方法局限性
-
依赖预训练特征质量
- 如果 backbone 提取的 patch 特征不能很好区分正常和异常,离群检测效果会受影响。
-
超参数仍然存在
- 例如删除比例 (\tau)、LOF 的邻居数 (k) 等,虽然论文中使用固定值,但不同数据集上可能仍需调整。
-
极难异常可能仍然无法完全去除
- 如果异常 patch 与正常 patch 非常相似,它可能不会被离群检测识别出来。
-
按空间位置分组依赖图像对齐
- 如果图像存在较大位置偏移、旋转或形变,按固定空间位置比较可能不够准确。
-
主要适用于工业视觉异常检测
- 对语义异常检测或自然图像异常检测是否同样有效,还需要进一步验证。
16. 我的理解
这篇论文的关键价值不在于提出一个完全新的异常检测框架,而是在于指出了一个很重要但容易被忽视的问题:
无监督异常检测虽然叫"无监督",但它其实隐含地依赖一个强监督假设:训练集全是正常样本。
SoftPatch 的贡献是削弱了这个假设。它不再完全相信训练集,而是先对训练 patch 进行可信度判断。这样做非常符合工业场景,因为真实生产线上的数据很难保证完全干净。
从方法上看,SoftPatch 的思想非常清晰:
- PatchCore 负责建模正常 patch 分布;
- LOF / Gaussian / Nearest Neighbor 负责找出训练集中的可疑 patch;
- soft weight 负责缓解残留噪声带来的过度自信问题。
其中我认为最关键的是 patch-level denoising。因为工业异常往往是局部的,所以直接删除整张图并不合理。SoftPatch 只删除可疑 patch,保留正常 patch,这一点既提高了鲁棒性,也提高了数据利用率。
17. 可进一步思考的问题
- 如果训练集中异常比例非常高,LOF 是否仍然有效?
- 如果图像没有严格对齐,按空间位置分组是否会带来误判?
- Soft weight 是否可以学习得到,而不是由离群分数手工计算?
- 是否可以将 SoftPatch 与 transformer-based feature extractor 结合?
- 对于非工业图像,例如医学图像、遥感图像,patch-level denoising 是否同样适用?
- 能否在训练阶段自动估计最佳删除比例 (\tau)?
- SoftPatch 是否可以扩展到视频异常检测或时序异常检测?
18. 总结
SoftPatch 针对无监督异常检测中的 noisy training data 问题,提出了一种简单有效的增强方法。它通过 patch-level noise discrimination 删除训练集中可疑的异常 patch,并通过 soft weight 在推理阶段降低残留噪声的影响。
这篇论文的核心启发是:
在真实工业异常检测中,训练集不应被默认视为完全干净。相比"完全信任训练集",更合理的做法是对训练 patch 建立可信度,并在 memory bank 构建和推理过程中使用这种可信度。
因此,SoftPatch 可以被理解为一种对 PatchCore 的鲁棒性改进:它保留了 memory-based anomaly detection 的高性能,同时增强了模型在噪声训练集下的稳定性。