写在前面
你好,我是 Evan。系统设计面试,是很多后端开发者从"写好代码"迈向"设计好系统"的一道分水岭。它不像算法题有标准答案,考察的是你在面对模糊需求时,如何拆解问题、做出权衡、构建一个可落地的高可用系统。而短链接服务 ,几乎是系统设计面试中最经典的题目之一。原因在于它表面上看似简单------把一个长 URL 转成短字符串------但背后却涉及唯一性、存储、性能、扩展性、高可用 等多个核心设计点。
这篇文章,我会以"设计一个支持百万级 QPS 的短链接服务"为例,从需求分析到数据建模、从缓存策略到限流降级,完整推演一遍系统设计的全过程。希望能帮你建立一套可复用的系统设计思维框架。
一、第一步:需求分析------先搞清楚"要做什么"
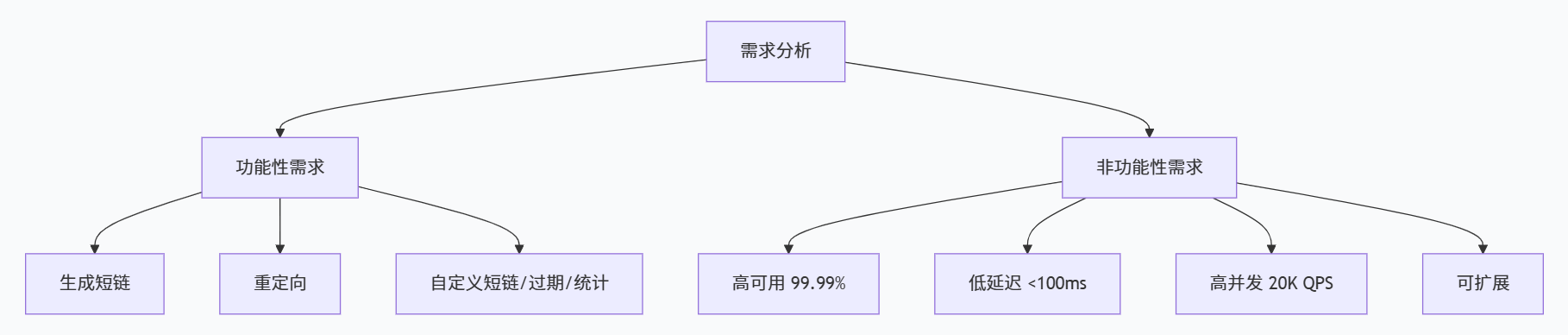
系统设计面试最常见的一个坑,就是拿到题目立刻开始画架构图。正确的做法是:先花 5-10 分钟把需求搞清楚。
面试官问"设计一个短链接服务"时,你需要主动追问以下几个维度:
1.1 功能性需求
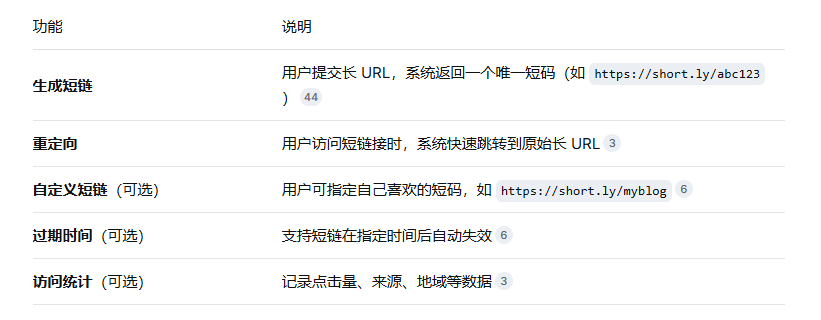
1.2 非功能性需求
这是面试中真正考察设计能力的部分:
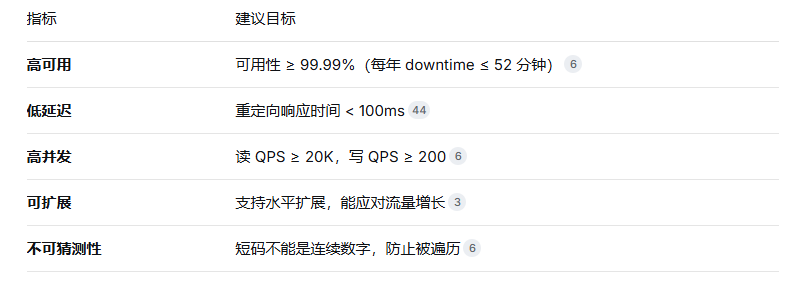
面试技巧:在面试中主动提出这些非功能需求,说明你有系统思维,而不只是"会写代码"。
二、第二步:容量估算------用数字指导设计
需求明确后,下一步是容量估算。很多面试者忽略这一步,直接开始设计,但面试官往往期望你能用数据支撑你的技术选型。
假设系统规模为:每月 5 亿新短链,读写比 100:1。
2.1 存储量估算
-
每月新增短链:5 亿条
-
每条记录(短码 + 长 URL + 元数据):约 500 字节
-
每月新增存储:5 亿 × 500B ≈ 250 GB
-
5 年累计存储:250GB × 12 × 5 ≈ 15 TB
2.2 QPS 估算
-
月活用户 1 亿,每日活跃 10%
-
每天访问量 ≈ 1 亿 × 10% × 10 次 = 10 亿次
-
每秒 QPS ≈ 10 亿 / 86400 ≈ 11,574 QPS
-
峰值可能是平均值的 2-3 倍 → 约 20K-30K QPS
有了这些数字,你就知道:单机 MySQL 扛不住,必须有缓存 + 分库分表。
面试技巧:面试时随口说出"每月 5 亿新链,5 年 15TB 存储,峰值 2 万 QPS",会显得非常专业。
三、第三步:核心设计------短码生成算法
短码生成是短链接系统的核心。面试官一定会追问:"你怎么保证短码是全局唯一的?"
3.1 方案一:自增 ID + Base62 编码(最推荐)
这是最常用、最稳妥的方案。
原理:
-
使用分布式 ID 生成器(如雪花算法 Snowflake)生成一个全局唯一的 64 位整数 ID
-
将该 ID 转换为 Base62 编码(字符集:
0-9a-zA-Z,共 62 个字符) -
转换结果就是短码
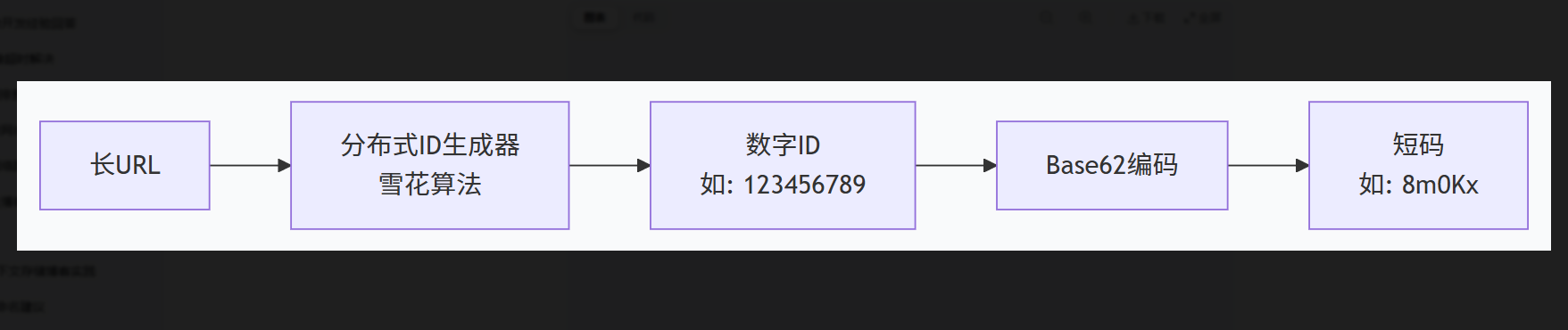
为什么用 Base62 而不是 Base64?
因为 Base64 包含 +、/、= 等字符,在 URL 中不友好。Base62 只用字母和数字,天然适合 URL。
容量分析:
-
6 位 Base62:62⁶ ≈ 568 亿 个组合
-
7 位 Base62:62⁷ ≈ 3.5 万亿 个组合
6 位已经足够大多数场景使用。
优点:无冲突(ID 唯一 → 短码唯一)、实现简单、不可预测。
3.2 方案二:哈希取模
对长 URL 做 MD5/SHA-1 哈希,取前 N 位作为短码。
缺点:存在哈希冲突的可能,需要额外检测和重试。
3.3 方案三:预生成短码池(KGS)
预先批量生成一批短码存入数据库,使用时直接从池中取一个。
优点 :生成速度极快。缺点:需要维护短码池的状态。
面试建议:先提"自增 ID + Base62"作为主方案,再补充"如果并发量极大,可以用预生成池优化"。
四、第四步:存储设计------数据库选型与分库分表
4.1 表结构设计
sql
CREATE TABLE short_url (
id BIGINT PRIMARY KEY, -- 雪花ID
short_code VARCHAR(16) UNIQUE, -- 短码,加唯一索引
long_url TEXT, -- 原始长URL
user_id BIGINT, -- 创建用户(可选)
created_at DATETIME,
expires_at DATETIME, -- 过期时间(可选)
deleted_at DATETIME, -- 软删除
INDEX idx_short_code (short_code)
);4.2 分库分表策略
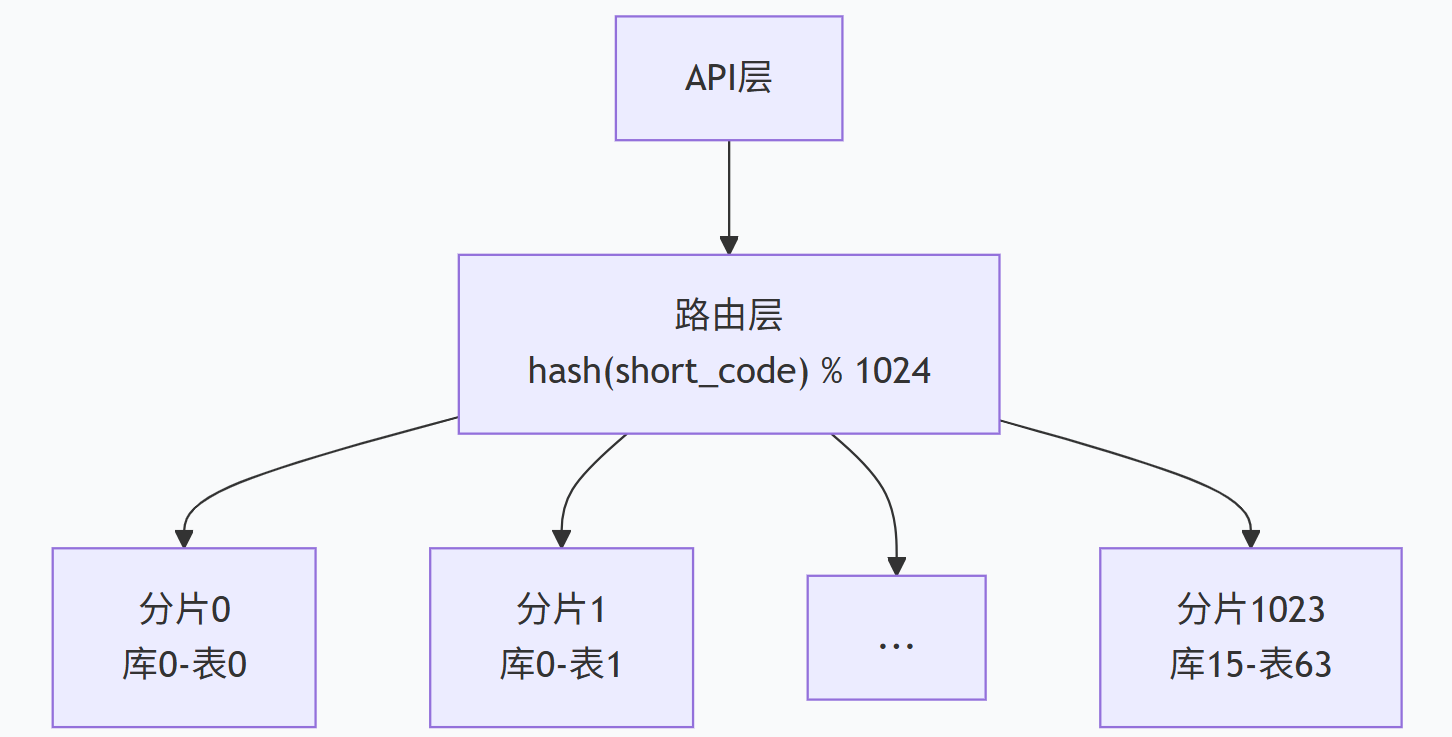
当数据量达到亿级时,单表撑不住,需要分库分表。
分片键选择 :用 short_code 的哈希值取模。
sql
text
shard_id = CRC32(short_code) % 总库数例如分成 16 个库,每个库 64 张表 ,共 1024 张表。每条短链根据 short_code 的哈希值路由到对应的表。
4.3 为什么选 MySQL?
虽然可以用 NoSQL,但短链系统的数据关系非常简单,MySQL + 分库分表 足以支撑海量数据,且事务能力更强。
五、第五步:高并发与缓存策略------让读请求飞起来
短链接系统的读写比通常是 100:1 ,读请求远多于写请求。因此,缓存是性能优化的重中之重。
5.1 多级缓存架构
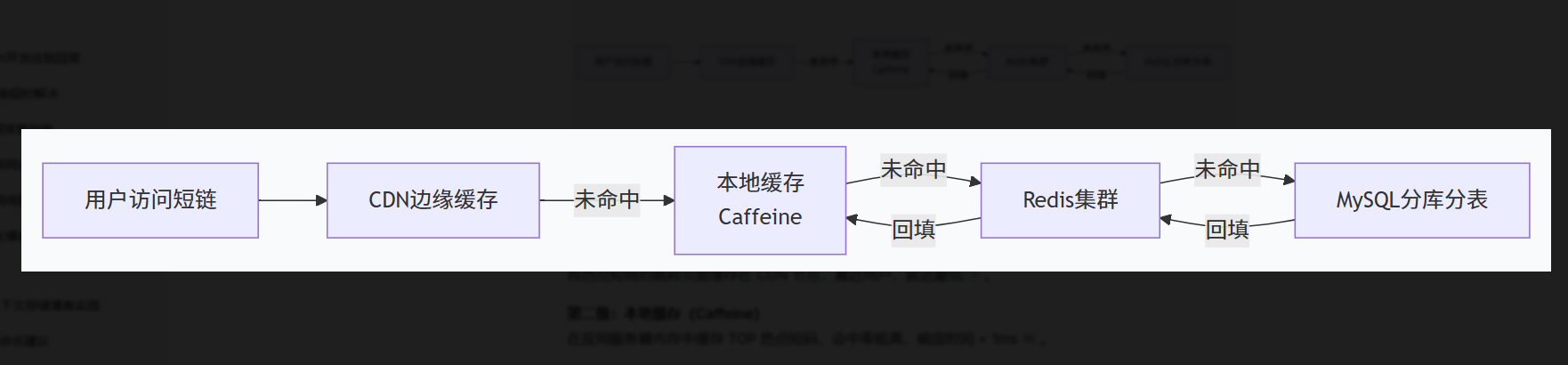
第一级:CDN 边缘缓存
将热点短链的跳转页面缓存在 CDN 节点,靠近用户,延迟最低。
第二级:本地缓存(Caffeine)
在应用服务器内存中缓存 TOP 热点短码,命中率极高,响应时间 < 1ms。
第三级:Redis 集群
存储全量热点短码(如 TOP 100 万条),使用 LFU 淘汰策略。
第四级:MySQL
数据最终持久化存储,缓存未命中时回源查询。
5.2 缓存更新策略(Cache-Aside)
-
读请求:先查缓存 → 命中则直接返回 → 未命中则查 DB → 回填缓存
-
写请求(生成新短链):写入 DB → 删除缓存(或更新缓存)
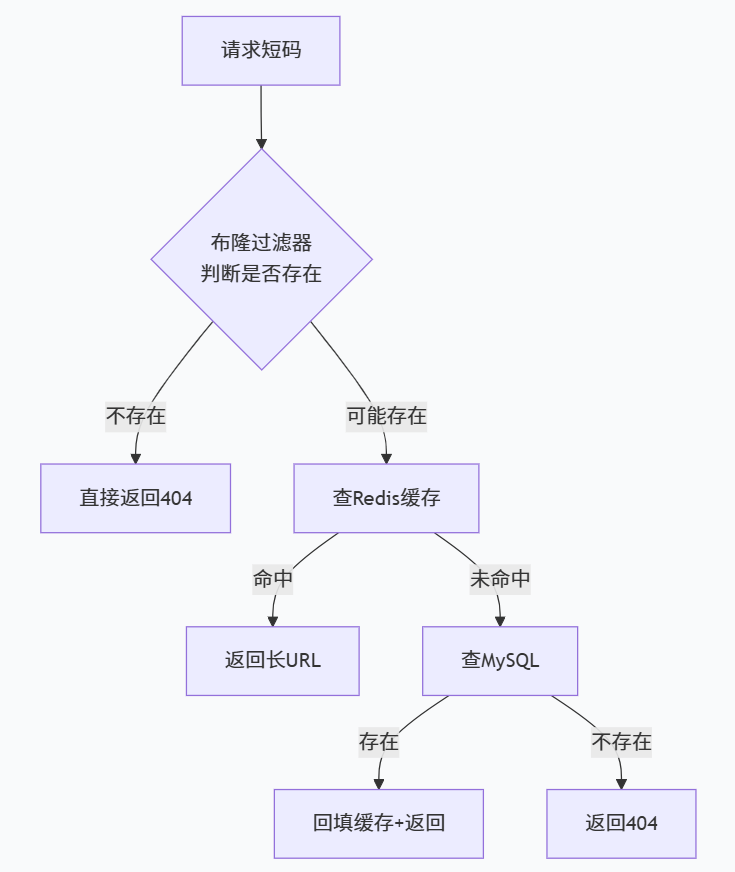
5.3 缓存穿透防护:布隆过滤器
恶意用户可能用不存在的短码大量请求,导致请求穿透缓存直达数据库。
解决方案 :在缓存之前加一层 布隆过滤器(Bloom Filter) 。所有已生成的短码都存入布隆过滤器,查询时先判断短码是否存在,不存在则直接返回 404,不查询数据库。
六、第六步:限流与安全防护------防止系统被冲垮
高并发系统必须有限流 和安全防护机制。
6.1 限流策略
为什么需要限流? 防止短链被恶意刷爆、爬虫攻击、恶意请求。
推荐方案:滑动窗口 + Redis
在时间窗口内统计请求数,超过阈值则拒绝。例如:10 秒窗口内限制 100 次请求
java
// 滑动窗口限流 - Redis ZSet 实现
public boolean allowRequest(String userId) {
String key = "rate_limit:" + userId;
long now = System.currentTimeMillis();
long windowStart = now - 10_000; // 10秒窗口
// 移除窗口外的记录
redis.zremrangeByScore(key, 0, windowStart);
// 统计当前窗口请求数
long count = redis.zcard(key);
if (count >= 100) {
return false; // 限流
}
// 记录本次请求
redis.zadd(key, now, UUID.randomUUID().toString());
redis.expire(key, 10);
return true;
}6.2 其他安全措施
-
IP 黑名单:对异常 IP 进行封禁
-
内容风控:对长 URL 进行安全检测,防止生成恶意短链
-
HTTPS 强制:所有短链接使用 HTTPS,防止中间人劫持
七、第七步:重定向策略------301 还是 302?
这是面试中一个很容易被忽略但非常关键的细节。
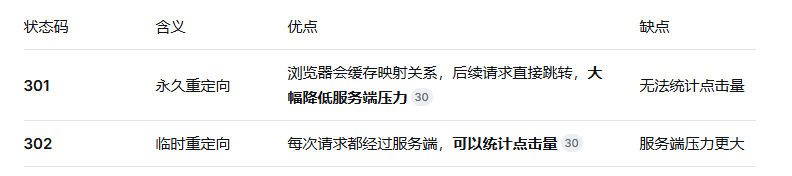
面试回答:
"我会默认使用 302 临时重定向,因为短链接通常用于营销活动,需要统计点击数据。但如果某些链接是永久性的(如官网首页),可以配置使用 301 来降低服务端压力。"
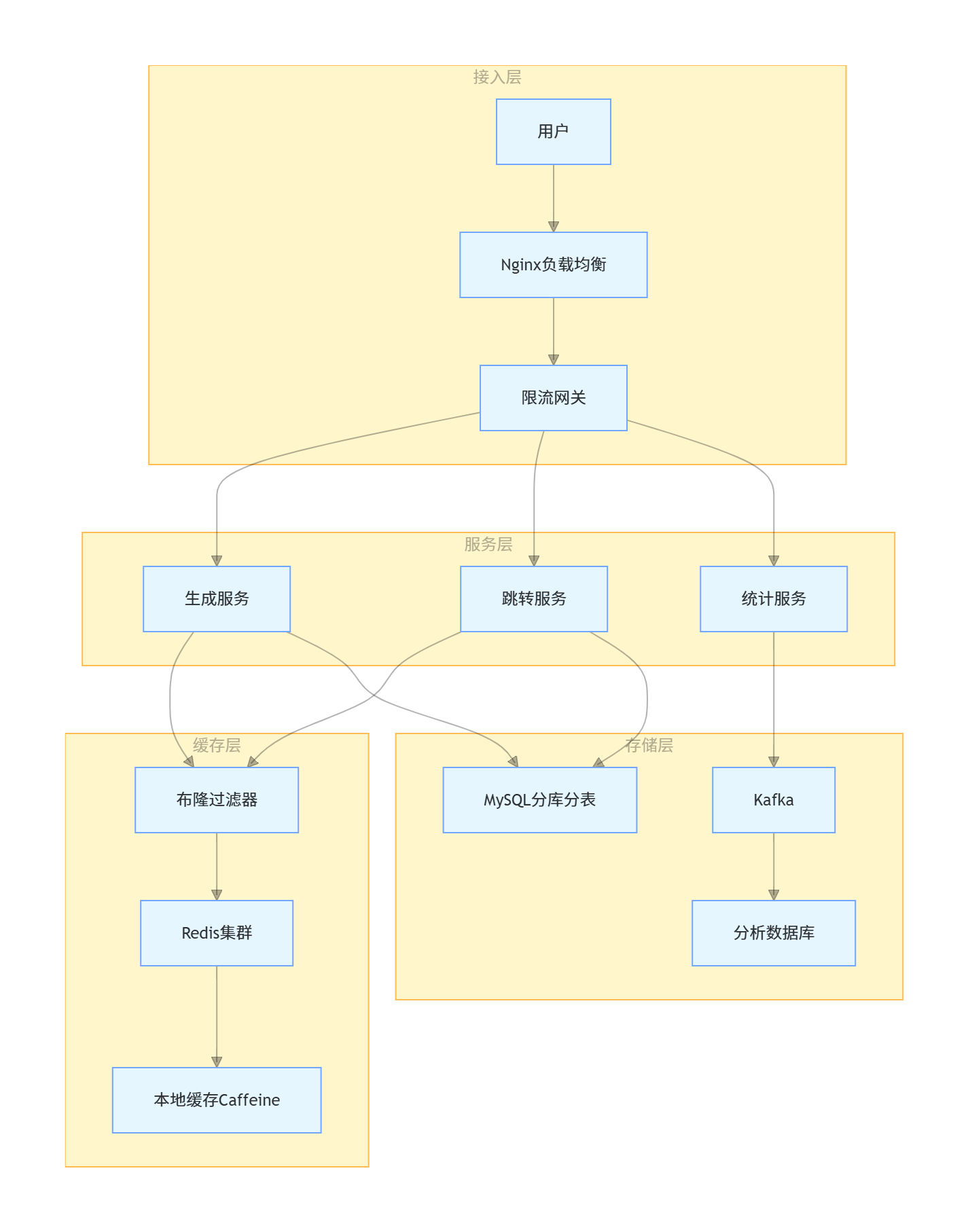
八、完整架构图
把所有模块串起来,一个完整的短链接系统架构如下:
九、总结:系统设计面试的"道"与"术"
短链接系统之所以成为经典面试题,是因为它"麻雀虽小,五脏俱全"。它考察的不仅是你对某个技术的掌握程度,更是你面对复杂问题时的拆解能力和决策逻辑。
面试时的回答框架(建议按此顺序):
-
需求分析(2 分钟):明确功能需求 + 非功能需求
-
容量估算(2 分钟):用数据说话,指导技术选型
-
核心设计(5 分钟):短码生成算法(Base62 + 雪花 ID)
-
存储设计(3 分钟):MySQL + 分库分表
-
性能优化(3 分钟):多级缓存 + 布隆过滤器
-
可用性保障(2 分钟):限流 + 熔断 + 重定向策略
记住:系统设计没有标准答案,只有权衡后的最优解。 面试官想看到的,是你如何在有限资源下做出合理决策。