激活函数用于对每层的输出数据进行变换, 进而为整个网络结构结构注入了非线性因素,以解决线性模型表达能力不足的问题。
如果不用激活函数,无论网络多深多复杂,本质上还是一个线性回归。是激活函数让网络有了处理复杂非线性问题的能力。
神经网络参数在更新时,使用的反向传播算法(BP),要求我们的激活函数必须可微。
今天先介绍sigmoid 激活函数,毕竟干货要慢慢消化。
sigmoid 激活函数
Sigmoid 函数是一个将任意实数映射到 (0, 1) 区间的 S 形曲线函数。由于其输出值可以解释为概率,它也被称为 Logistic 函数。
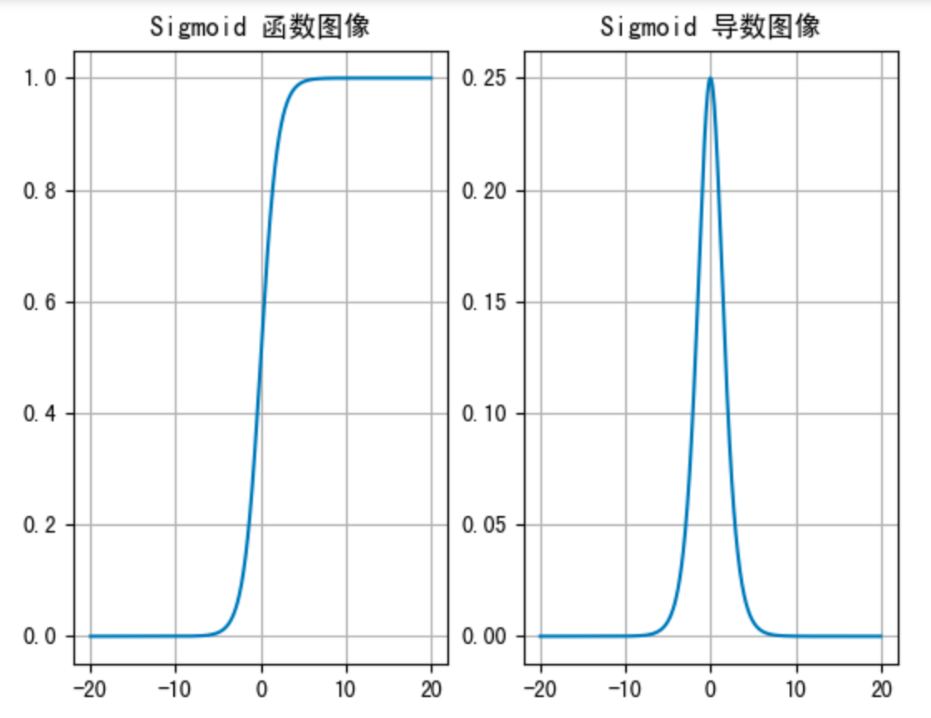
从 sigmoid 函数图像可以得到,sigmoid 函数可以将任意的输入映射到 (0, 1) 之间,可以把它想象成一个 "概率转换器" ,它把任何数值都变成了一个概率值。
- 输入极大的正数 → 输出无限接近于 1
- 输入 0 → 输出正好是 0.5
- 输入极小的负数 → 输出无限接近于 0
当输入的值大致在 <-6 或者 >6 时,输入任何值得到的激活值都是差不多的,这样会丢失部分的信息。比如:输入 100 和输出 10000 经过 sigmoid 的激活值几乎都是等于 1 的,但是输入的数据之间相差 100 倍的信息就丢失了。
对于 sigmoid 函数而言,输入值在 -6, 6 之间输出值才会有明显差异,输入值在 -3, 3 之间才会有比较好的效果。
通过上述导数图像,我们发现导数数值范围是 (0, 0.25),当输入 <-6 或者 >6 时,sigmoid 激活函数图像的导数接近为 0,此时网络参数将更新极其缓慢,或者无法更新。
一般来说, sigmoid 网络在 5 层之内就会产生梯度消失现象。而且,该激活函数并不是以 0 为中心的,所以在实践中这种激活函数使用的很少。sigmoid函数一般只用于二分类的输出层。
1. 它的数学公式
数学公式 :
σ(x)=11+e−x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
(注:σ\sigmaσ 读作 sigma,eee 是自然常数约等于 2.718,xxx 是输入值)
图像形状 :
它画出来是一个平滑的 "S"型曲线:
- 两端是平坦的(称为"饱和区")
- 中间(x=0x=0x=0 附近)是最陡峭的
2. 它曾经为什么那么火?(优点)
在深度学习早期(20世纪八九十年代到2010年左右),Sigmoid 几乎是唯一的标配,因为它有两个极其讨喜的优点:
- 平滑可导:它的曲线没有棱角,这意味着它在每一个点都有明确的斜率(导数),完美适配反向传播中的链式法则。
- 输出就是概率 :因为输出严格在 (0,1)(0, 1)(0,1) 之间,在做"这是猫还是狗"的二分类任务时,输出 0.8 就可以直接理解为"有 80% 的概率是猫",解释性极强。
4. 它为什么被踢出隐藏层?(致命缺点)
随着网络越来越深,Sigmoid 的三个致命缺陷暴露无遗,其中最核心的就是我们之前讨论过的:
缺点一:导致梯度消失(最致命)
Sigmoid 函数的导数公式有一个非常优雅的变形:
σ′(x)=σ(x)⋅(1−σ(x)) \sigma'(x) = \sigma(x) \cdot (1 - \sigma(x)) σ′(x)=σ(x)⋅(1−σ(x))
因为 σ(x)\sigma(x)σ(x) 的值永远在 0 和 1 之间,你可以想象一下,两个小于 1 的数相乘,结果只会更小。
通过数学计算可以证明,Sigmoid 导数的最大值只有 0.25 (发生在输入 x=0x=0x=0 的时候,此时 0.5×0.5=0.250.5 \times 0.5 = 0.250.5×0.5=0.25)。
当输入稍微大一点或小一点(进入两端的平坦区),导数就会迅速逼近于 0。
后果 :在反向传播时,这个小于等于 0.25 的数字会被一层一层地连乘(正如我们之前算过的 0.25×0.25×0.25...0.25 \times 0.25 \times 0.25 \dots0.25×0.25×0.25...),传到前面几层时,梯度基本没了,前面的权重根本不更新。
缺点二:输出不是"零中心化"
因为 Sigmoid 的输出范围:全都是正数(0 到 1 之间),不是以 0 为中心,这意味着所有神经元的输出都是正的,在反向传播时,权重更新的梯度方向会一致(全正或全负),可能出现 "zig-zag"(锯齿状)的优化路径,减慢收敛速度。
缺点三:计算成本较高(涉及指数运算)
公式里有个 e−xe^{-x}e−x(指数运算)。对于计算机来说,算加减乘除很快,但算指数、算对数是很耗算力的。当网络里有几百万个神经元时,每次前向传播算几百万次指数,太慢了。
Sigmoid 现在的"归宿"
既然 Sigmoid 这么差,那它被淘汰了吗?
没有!它只是退居二线了。
- 在隐藏层中:它已经被彻底淘汰。 现在大家统一使用 ReLU 函数(正数直接输出,负数输出0,计算极快,且正数区域导数恒为1,完美解决梯度消失)。
- 在输出层中:它依然是王者。 当我们做二分类任务 (比如判断邮件是不是垃圾邮件、判断图片里是不是猫),我们依然会在网络的最后一层放上 Sigmoid 函数,因为我们最终就需要一个 0 到 1 之间的概率值。