HarmonyOS 小说初始化实现指南:从种子数据到沙箱文件的完整流程
效果
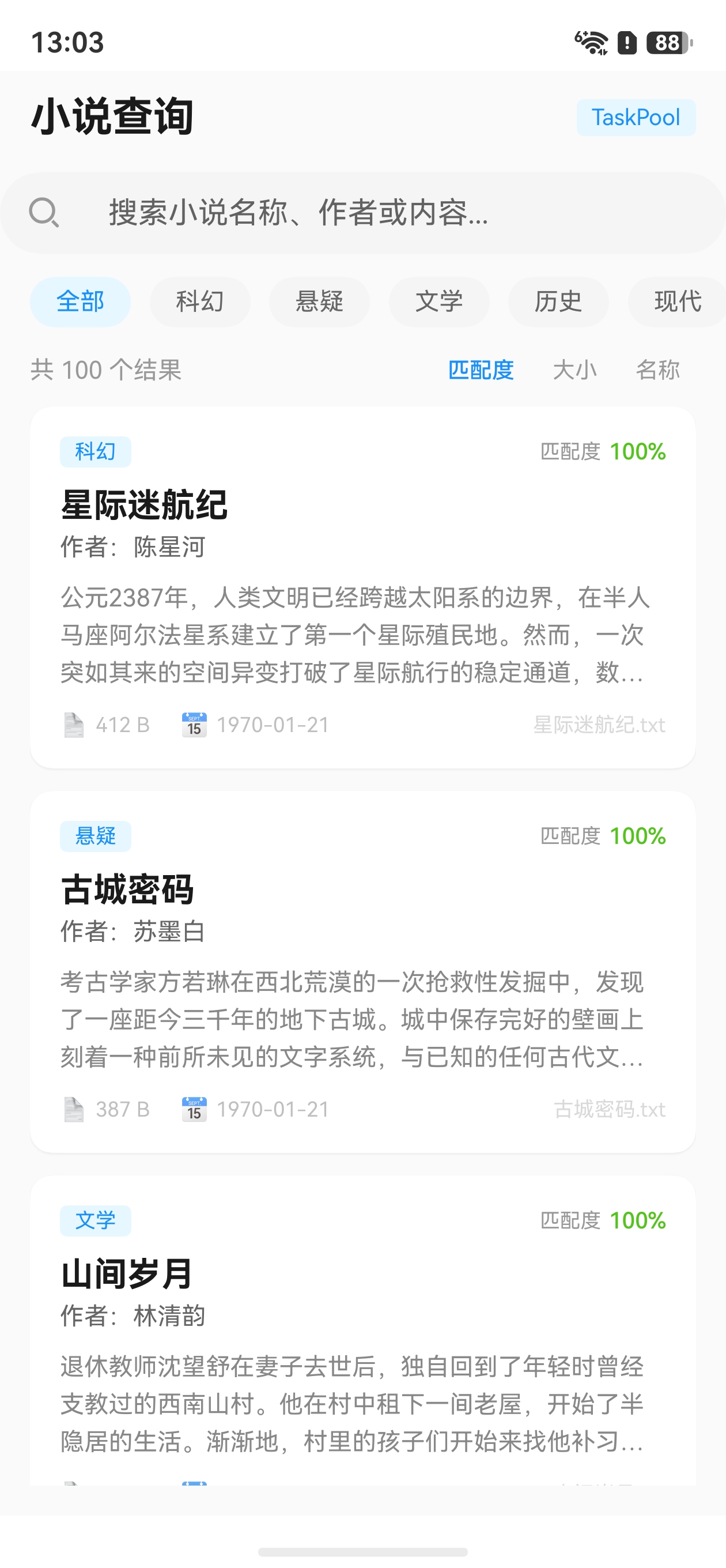
前言
在 HarmonyOS 应用开发中,当应用需要预置一批文件数据时,如何在 TaskPool 子线程中高效初始化文件 是一个关键问题。本文以小说查询应用为例,详细讲解如何将 100 部原创小说的元数据嵌入代码,并在应用启动时通过 TaskPool 子线程批量写入沙箱目录。
通过本文,你将掌握:
- 种子数据方案的设计思路与实现
- 100 篇小说数据的组织与管理
- @Concurrent 函数中批量文件写入的实现
- 幂等性保证:多次启动不重复创建
- 批量初始化中的编码与 IO 优化
一、为什么需要种子数据方案
1.1 问题背景
小说查询应用需要在启动时预置一批小说文件,供用户搜索和浏览。最直觉的做法是将文件放在 rawfile 目录中,但遇到了一个关键限制:
TaskPool 子线程无法通过
fileIo访问 rawfile 目录。
rawfile 资源需要通过 resourceManager.getRawFileContent() 等 API 访问,而这些 API 依赖 UIAbilityContext,在子线程中不可用。
1.2 解决方案:种子数据嵌入代码
将小说的元数据(标题、作者、分类、简介)以 常量数组 的形式直接嵌入代码中:
┌─────────────────────────┐
│ Constants.ets │
│ NOVEL_SEEDS: 100条记录 │ ← 元数据嵌入代码
└───────────┬─────────────┘
│ 作为参数传入(可序列化)
▼
┌─────────────────────────┐
│ TaskPool 子线程 │
│ @Concurrent │
│ initNovelFiles() │ ← 子线程写入沙箱
│ fileIo.openSync │
│ fileIo.writeSync │
└───────────┬─────────────┘
│ 写入
▼
┌─────────────────────────┐
│ 沙箱目录 │
│ filesDir/novels/ │ ← 100个.txt文件
│ ├── 星际迷航纪.txt │
│ ├── 古城密码.txt │
│ └── ... (共100个) │
└─────────────────────────┘1.3 方案优势
| 优势 | 说明 |
|---|---|
| 无路径依赖 | 不依赖 rawfile 路径,子线程可直接操作 |
| 可序列化传输 | 纯 interface 数组,支持跨线程传递 |
| 幂等创建 | 已存在的文件跳过写入,多次启动安全 |
| 集中管理 | 所有元数据集中在一个常量数组中,便于维护 |
| 按需扩展 | 新增小说只需追加一条记录 |
二、数据模型设计
2.1 种子数据接口
typescript
// Constants.ets
export interface NovelSeedData {
fileName: string // 文件名,如 '星际迷航纪.txt'
title: string // 小说标题
author: string // 作者名
category: string // 分类:科幻/悬疑/文学/历史/现代
preview: string // 内容预览(40-80字)
}设计原则:
- 只包含
string类型,确保序列化兼容 fileName与title分开存储,支持中文文件名preview控制在 80 字以内,平衡信息量与内存
2.2 分类体系
应用采用 5 大分类 ,每类 20 篇 ,共 100 篇:
| 分类 | 篇数 | 代表作品 | 主题特色 |
|---|---|---|---|
| 科幻 | 20 | 星际迷航纪、暗物质之门、量子之境 | 太空探索、AI、基因、时间旅行 |
| 悬疑 | 20 | 古城密码、消失的楼层、密室法则 | 推理破案、密室、身份悬疑 |
| 文学 | 20 | 山间岁月、故乡的云、渔歌子 | 乡村记忆、传统手艺、人文情怀 |
| 历史 | 20 | 长安旧事、丝路驼铃、赤壁风云 | 唐宋明清、丝绸之路、战争纪实 |
| 现代 | 20 | 云端之城、创业江湖、芯片之战 | 创业、职业、时代变迁 |
三、100 篇种子数据的组织
3.1 数据结构
100 条记录统一存放在 NOVEL_SEEDS 常量数组中:
typescript
export const NOVEL_SEEDS: NovelSeedData[] = [
// ===== 原始 10 篇 =====
{ fileName: '星际迷航纪.txt', title: '星际迷航纪', author: '陈星河', category: '科幻',
preview: '公元2387年,人类文明已经跨越太阳系的边界...' },
{ fileName: '古城密码.txt', title: '古城密码', author: '苏墨白', category: '悬疑',
preview: '考古学家方若琳在西北荒漠的一次抢救性发掘中...' },
// ... 原始 10 篇
// ===== 科幻 (新增17篇) =====
{ fileName: '暗物质之门.txt', title: '暗物质之门', author: '刘星辰', category: '科幻',
preview: '天体物理学家孙启明在观测银河系中心的异常引力波时...' },
// ... 17 篇
// ===== 悬疑 (新增17篇) =====
// ... 17 篇
// ===== 文学 (新增18篇) =====
// ... 18 篇
// ===== 历史 (新增19篇) =====
// ... 19 篇
// ===== 现代 (新增19篇) =====
// ... 19 篇
]3.2 数据编排策略
| 策略 | 说明 |
|---|---|
| 按分类分组 | 新增数据按「科幻→悬疑→文学→历史→现代」顺序排列 |
| 注释分隔 | 每个分类用 // ===== 分类名 (新增N篇) ===== 标注 |
| 文件名唯一 | 每篇小说的 fileName 全局唯一,避免沙箱中文件冲突 |
| 标题与文件名一致 | title 与 fileName(去掉 .txt)保持一致 |
| 作者多样化 | 100 位不同的笔名,体现作品的多样性 |
3.3 预览文本编写规范
每条 preview 遵循以下规范:
- 长度:40-80 个汉字(在列表中显示 3 行左右)
- 结构:人物 + 场景 + 冲突/悬念
- 风格:开篇即入,不做铺垫
- 示例 :
- ✅
天体物理学家孙启明在观测银河系中心的异常引力波时,发现暗物质并非不可见... - ❌
这是一个关于太空的故事,发生在遥远的未来...(太空洞) - ❌
本书讲述了主人公从出生到成年的完整人生...(太笼统)
- ✅
四、初始化函数的实现
4.1 @Concurrent 批量写入函数
typescript
// NovelQueryService.ets
/**
* @Concurrent 并发函数:批量初始化小说文件
* 在 TaskPool 子线程中执行,将种子数据写入沙箱目录
*/
@Concurrent
function initNovelFiles(filesDir: string, seeds: Array<SeedItem>): Array<NovelFileRawData> {
let novelsDir: string = filesDir + '/' + NOVEL_DIR_NAME
let results: Array<NovelFileRawData> = []
// 1. 确保目录存在
if (!fileIo.accessSync(novelsDir)) {
fileIo.mkdirSync(novelsDir, true)
}
// 2. 遍历种子数据,逐个创建文件
for (let i = 0; i < seeds.length; i++) {
let seed: SeedItem = seeds[i]
let filePath: string = novelsDir + '/' + seed.fileName
// 构建文件内容
let content: string = '标题:' + seed.title + '\n' +
'作者:' + seed.author + '\n' +
'分类:' + seed.category + '\n\n' +
'【内容简介】\n\n' + seed.preview
// 3. 幂等写入:已存在则跳过
if (!fileIo.accessSync(filePath)) {
let fd: fileIo.File = fileIo.openSync(filePath,
fileIo.OpenMode.READ_WRITE | fileIo.OpenMode.CREATE)
let encoder: util.TextEncoder = util.TextEncoder.create('utf-8')
let encoded: Uint8Array = encoder.encodeInto(content)
fileIo.writeSync(fd.fd, encoded.buffer as ArrayBuffer)
fileIo.closeSync(fd.fd)
}
// 4. 获取文件统计信息
let fileStat: fileIo.Stat = fileIo.statSync(filePath)
// 5. 构建返回数据
results.push({
fileName: seed.fileName,
filePath: filePath,
fileSize: fileStat.size,
lastModified: fileStat.mtime,
preview: seed.preview,
matchScore: 100,
category: seed.category,
author: seed.author,
title: seed.title
})
}
return results
}4.2 文件内容格式
每个 .txt 文件的内容格式如下:
标题:星际迷航纪
作者:陈星河
分类:科幻
【内容简介】
公元2387年,人类文明已经跨越太阳系的边界...格式说明:
- 第 1-3 行:元数据头(标题、作者、分类)
- 空行分隔
【内容简介】标记后为正文预览- 详情页的
getSynopsis()方法根据此标记提取内容
4.3 执行流程
应用启动
│
▼
aboutToAppear()
│
▼
initData()
│ 获取 filesDir
▼
new NovelQueryHelper(filesDir)
│
▼
initFiles(NOVEL_SEEDS)
│ 传入 100 条种子数据
▼
taskpool.execute(initNovelFiles, filesDir, seeds)
│ ┌─── TaskPool 子线程 ───────────────────┐
│ │ 1. mkdirSync(novelsDir) │
│ │ 2. for i = 0..99: │
│ │ ├─ accessSync → 已存在? 跳过 : 写入 │
│ │ ├─ statSync → 获取文件大小/修改时间 │
│ │ └─ push 到 results 数组 │
│ │ 3. return results (100条) │
│ └────────────────────────────────────────┘
▼
convertToNovelList(rawDataList)
│ NovelFileRawData[] → NovelFileInfo[]
▼
viewModel.setNovelList(list)
│ @Trace 触发 UI 刷新
▼
列表显示 100 篇小说卡片五、幂等性保证
5.1 问题场景
用户每次启动应用都会调用 initNovelFiles。如果不做幂等处理,会出现:
- 重复写入:浪费 IO 资源
- 修改时间被覆盖:排序结果不准确
5.2 解决方案
typescript
// 检查文件是否已存在
if (!fileIo.accessSync(filePath)) {
// 不存在 → 创建并写入
let fd = fileIo.openSync(filePath, fileIo.OpenMode.READ_WRITE | fileIo.OpenMode.CREATE)
// ... 写入 ...
fileIo.closeSync(fd.fd)
}
// 已存在 → 跳过写入,直接 statSync 获取信息
let fileStat = fileIo.statSync(filePath)效果:
| 启动次数 | 行为 | 耗时 |
|---|---|---|
| 首次启动 | 创建 100 个文件 + 写入内容 | 较长(约 200-500ms) |
| 后续启动 | 跳过写入,只读取文件信息 | 较短(约 50-100ms) |
| 卸载重装 | 重新创建所有文件 | 与首次相同 |
六、性能分析
6.1 100 篇 vs 10 篇的对比
| 指标 | 10 篇 | 100 篇 |
|---|---|---|
| 首次启动 IO 次数 | 10 次 open + write + close | 100 次 open + write + close |
| 种子数据内存占用 | ~2KB | ~20KB |
| 后续启动 statSync 次数 | 10 次 | 100 次 |
| 搜索遍历文件数 | 10 个 | 100 个 |
6.2 为什么子线程不会卡顿
尽管 100 篇的 IO 操作量是 10 篇的 10 倍,但以下设计保证了 UI 的流畅性:
| 设计 | 效果 |
|---|---|
| 所有 IO 在 TaskPool 子线程执行 | 主线程零阻塞,保持 60fps |
使用同步 API(mkdirSync、openSync) |
子线程中同步不影响主线程 |
| 幂等跳过已存在文件 | 后续启动大幅减少写入 |
isLoading 状态显示加载动画 |
用户看到明确的加载反馈 |
6.3 内存优化
种子数据传输:
100条 × 约200字节/条 = ~20KB 序列化数据
跨线程传输时深拷贝,内存影响极小
文件内容构建:
每条约200字节 → 总计约20KB
在子线程中临时创建,返回后释放
返回数据:
100条 NovelFileRawData ≈ ~30KB
主线程转换为 100 个 NovelFileInfo 响应式对象七、搜索效果提升
7.1 100 篇数据的搜索体验
| 搜索场景 | 10 篇效果 | 100 篇效果 |
|---|---|---|
| 搜索"星际" | 返回 1-2 条 | 返回 5-8 条,更有层次感 |
| 搜索"密码" | 返回 1 条 | 返回 3-5 条 |
| 按分类筛选 | 每类 1-3 条,太少 | 每类 20 条,需滚动浏览 |
| 排序体验 | 看不出差异 | 匹配度排序更有意义 |
| 空搜索结果 | 容易出现 | 关键词更分散,更不容易空结果 |
7.2 分类筛选的丰富度
分类筛选示例(100篇):
[全部] → 共 100 个结果
[科幻] → 共 20 个结果(星际迷航纪、暗物质之门、量子之境...)
[悬疑] → 共 20 个结果(古城密码、消失的楼层、密室法则...)
[文学] → 共 20 个结果(山间岁月、故乡的云、渔歌子...)
[历史] → 共 20 个结果(长安旧事、丝路驼铃、赤壁风云...)
[现代] → 共 20 个结果(云端之城、创业江湖、芯片之战...)八、扩展与维护
8.1 新增一篇小说
只需在 NOVEL_SEEDS 数组末尾追加一条记录:
typescript
{ fileName: '新小说.txt', title: '新小说', author: '新作者', category: '科幻',
preview: '这里写40-80字的内容预览...' },无需修改其他文件,应用下次启动时会自动在沙箱中创建新文件。
8.2 新增一个分类
- 在
CATEGORIES数组中添加新分类名 - 在
NOVEL_SEEDS中添加该分类的小说
typescript
export const CATEGORIES: string[] = ['全部', '科幻', '悬疑', '文学', '历史', '现代', '奇幻']8.3 批量数据管理建议
| 数据量 | 建议方案 |
|---|---|
| < 200 篇 | 继续使用种子数据常量数组(当前方案) |
| 200-1000 篇 | 考虑从网络 API 下载 JSON 配置文件 |
| > 1000 篇 | 使用本地数据库(RelationalStore)管理 |
九、踩坑与注意事项
9.1 文件名不能重复
每篇小说的 fileName 必须全局唯一。如果两篇小说使用了相同的文件名,后写入的会覆盖先写入的(虽然当前幂等逻辑会跳过,但在首次启动时会产生混乱)。
9.2 中文文件名编码
使用 util.TextEncoder 将字符串编码为 UTF-8 后写入文件,确保中文标题和内容正确存储。读取时也使用 util.TextDecoder 以 UTF-8 解码。
9.3 种子数据大小对编译的影响
100 条记录的 NOVEL_SEEDS 数组约占源码 200 行。编译后的常量数据约 20KB,对应用包体积和启动速度的影响可以忽略。
9.4 首次启动的加载提示
由于 100 个文件的首次写入需要约 200-500ms,建议在 UI 层显示加载动画:
typescript
async initData(): Promise<void> {
this.viewModel.isLoading = true // 显示"正在查询..."
// ... 初始化 ...
this.viewModel.isLoading = false // 隐藏加载动画
}十、完整文件清单
| 文件 | 变更 | 说明 |
|---|---|---|
Constants.ets |
扩充 NOVEL_SEEDS 至 100 条 | 新增 90 篇小说种子数据 |
NovelQueryService.ets |
无变更 | initNovelFiles 函数自动适配任意数量的种子 |
Index.ets |
无变更 | 列表自动展示所有初始化后的小说 |
NovelListViewModel.ets |
无变更 | 过滤/排序逻辑不受数据量影响 |
参考文档: