AI 学习路线 07:Prompt Engineering 入门,如何让大模型更稳定地完成任务?
前言
前面一篇我们学习了 Transformer 与大语言模型:Token、Embedding、上下文窗口、Attention、训练阶段、生成原理、temperature、top_p 和多模态模型。
这一篇进入 AI 应用开发里最常见、也最容易被误解的主题:Prompt Engineering。
很多人第一次写 Prompt,容易把它当成"咒语":
text
请你认真回答。
你是最厉害的专家。
一步一步思考。
给我一个高质量答案。这些话有时有用,但如果只靠这类话,很快会遇到问题:
- 模型回答跑偏。
- 输出格式不稳定。
- 该简洁时太啰嗦。
- 该严谨时开始编造。
- 同一个任务换一条输入就不稳定。
- 想接入程序时,JSON 前后总有多余文字。
Prompt Engineering 的核心不是背固定模板,而是学会把需求写成一份清晰的任务说明书。
这一篇重点解决这些问题:
- Prompt 为什么不是"咒语",而是任务说明书?
- 一个好 Prompt 通常由哪些部分组成?
- 角色、任务、背景、约束、输出格式、示例分别解决什么问题?
- Zero-shot、Few-shot、Chain of Thought 分别适合什么场景?
- 结构化输出为什么是 AI 工程化的关键?
- JSON Schema、兜底规则、程序校验为什么重要?
- Prompt 输出不好时,应该怎么调试?
- 如何把好用 Prompt 版本化、测试化、复用化?
还是老节奏:图、表格、例子、误区、自测题一起上。
一、Prompt 不是咒语,而是任务说明书
Prompt 是什么?
一句话:
text
Prompt 是写给大语言模型的任务说明书。模型并不知道你的真实意图、业务背景、输出标准和边界条件。你输入得越模糊,模型需要自己猜的东西就越多。
比如:
text
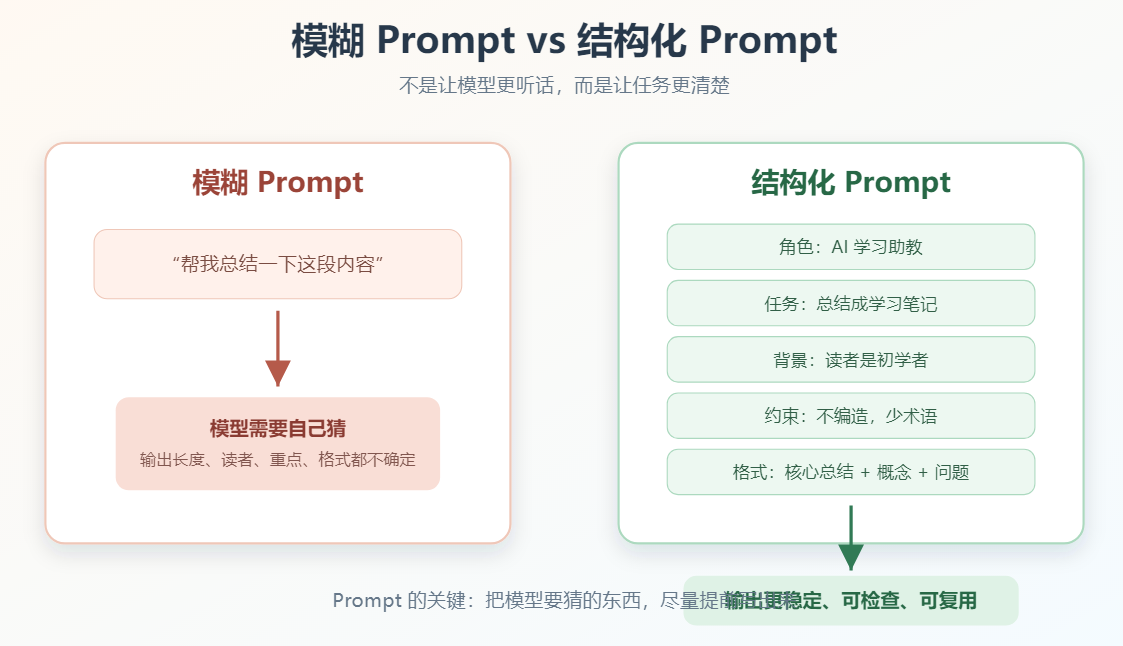
帮我总结一下这段内容。这句话并没有错,但它留下了很多不确定性:
- 总结给谁看?
- 要 50 字还是 500 字?
- 要不要保留专业术语?
- 要不要列重点?
- 要不要给复习题?
- 能不能补充原文没有的信息?
- 输出成段落、列表、表格,还是 JSON?
模型猜得越多,输出就越不稳定。
一个更清楚的 Prompt 可以这样写:
text
你是一名 AI 学习助教。
请把下面这段内容总结成适合初学者理解的学习笔记。
背景:
读者刚学完 Transformer,但还不熟悉 Prompt Engineering。
要求:
1. 不要使用太多专业术语。
2. 保留关键概念。
3. 用类比解释难点。
4. 不要编造原文没有的信息。
输出格式:
- 核心总结
- 关键概念
- 类比解释
- 复习问题
原文:
{这里放原文}这个 Prompt 更长,但不是因为"长"所以好,而是因为它把任务边界说清楚了。
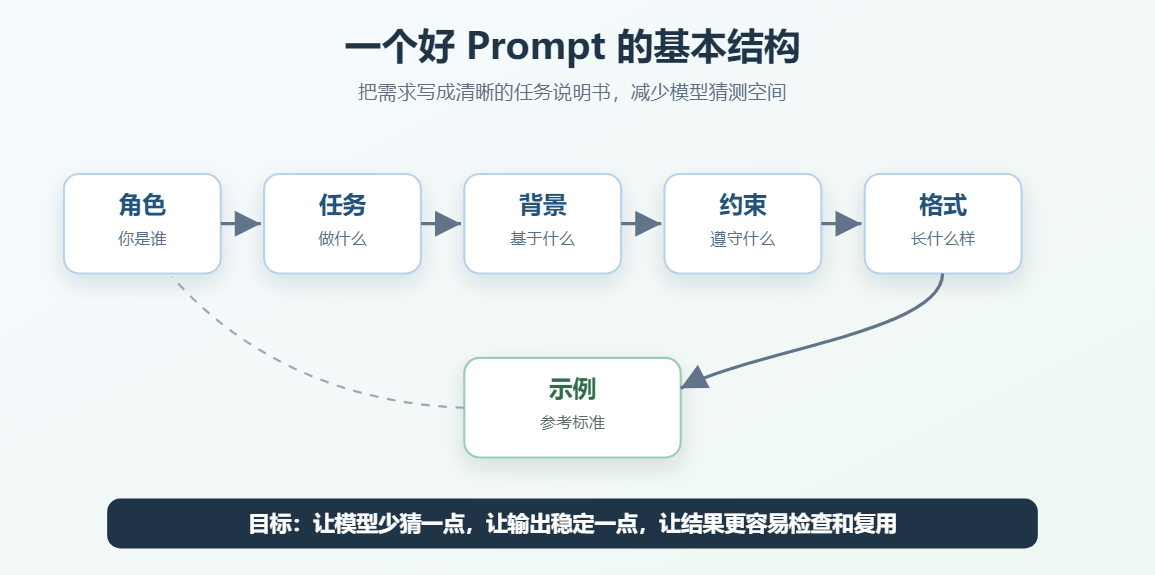
一个常用骨架是:
text
角色 + 任务 + 背景 + 约束 + 输出格式 + 示例可以把它理解成一张任务卡:
| 组成部分 | 解决的问题 | 示例 |
|---|---|---|
| 角色 | 让模型知道用什么身份回答 | 你是一名 AI 学习助教 |
| 任务 | 让模型知道要做什么 | 请总结下面这段内容 |
| 背景 | 让模型知道基于什么场景回答 | 读者是刚入门的程序员 |
| 约束 | 让模型知道必须遵守什么 | 不要编造信息 |
| 输出格式 | 让模型知道答案长什么样 | 用 Markdown 表格输出 |
| 示例 | 让模型知道什么算合格 | 下面是一个合格输出示例 |
模糊 Prompt 和结构化 Prompt 的区别,可以用这张图理解:
二、一个通用 Prompt 模板
以后写 Prompt,可以先套这个模板:
text
你是【角色】。
请完成【任务】。
背景信息:
【上下文、资料、目标用户、业务场景】
要求:
1. 【约束 1】
2. 【约束 2】
3. 【约束 3】
输出格式:
【Markdown / JSON / 表格 / 步骤 / 固定字段】
示例:
【可选。如果任务容易跑偏,建议给示例。】注意,这不是说每个 Prompt 都必须包含全部 6 个部分。
简单任务可以很短:
text
请把下面这句话翻译成英文:
今天天气很好,我想去公园散步。但一旦进入真实业务,比如分类、抽取、审核、生成结构化数据,就应该更清楚地写出任务、约束和输出格式。
三、角色:决定回答视角和表达风格
角色用于规定模型回答时采用的视角、专业程度和表达风格。
例如:
text
你是一名 AI 学习助教。
text
你是一名有 10 年经验的后端架构师。
text
你是一名面向初学者讲课的 Python 老师。角色不是让模型真的变成某个人,而是帮助模型选择更合适的知识范围、表达方式和判断标准。
弱角色:
text
你很专业。更好的角色:
text
你是一名负责企业知识库问答系统的 AI 工程师,请从工程落地角度分析问题。角色要贴近任务,不是越夸张越好。
例如你要写一段给初学者看的解释,与其写:
text
你是世界顶级科学家。不如写:
text
你是一名 AI 课程讲师,请用初学者能听懂的语言解释。四、任务:决定模型到底要做什么
任务是 Prompt 的核心。任务应该包含明确动作。
常见任务动作包括:
- 总结
- 分类
- 提取
- 改写
- 比较
- 生成
- 检查
- 翻译
- 解释
- 评估
模糊任务:
text
看看这个。清晰任务:
text
请阅读下面的客户反馈,并判断它属于"功能建议""Bug 反馈""价格问题"还是"售后咨询"。再比如:
text
请从下面的合同文本中提取甲方、乙方、合同金额、付款时间和违约责任。任务越明确,模型越知道应该围绕什么目标组织输出。
五、背景:让模型回答得贴合场景
背景也叫上下文。它包括任务发生的场景、目标读者、已有资料、业务规则、限制条件和输入数据。
比如只问:
text
请解释 embedding。模型可能从数学、NLP、数据库、RAG、推荐系统等不同角度回答。
如果补充背景:
text
背景:
读者正在学习 RAG 知识库问答,请从"文本如何被检索"这个角度解释 embedding。答案就会更贴近真实目标。
背景的价值是:让模型知道"这道题应该站在哪个场景里回答"。
六、约束:让模型知道边界
约束用于说明模型必须遵守什么、不能做什么。
常见约束包括:
| 约束类型 | 示例 |
|---|---|
| 字数限制 | 控制在 300 字以内 |
| 风格限制 | 用通俗语言,不要堆术语 |
| 信息边界 | 只根据给定材料回答,不要编造 |
| 安全边界 | 不要输出隐私、违法或危险操作 |
| 业务规则 | 只能从给定选项中选择 |
比如:
text
要求:
1. 只根据原文总结,不要补充原文没有的信息。
2. 如果原文没有答案,请输出"资料中未提到"。
3. 每条结论都要标注对应依据。真实 AI 应用里,约束非常重要。
它能减少跑题、幻觉、格式失控和违反业务规则的风险。

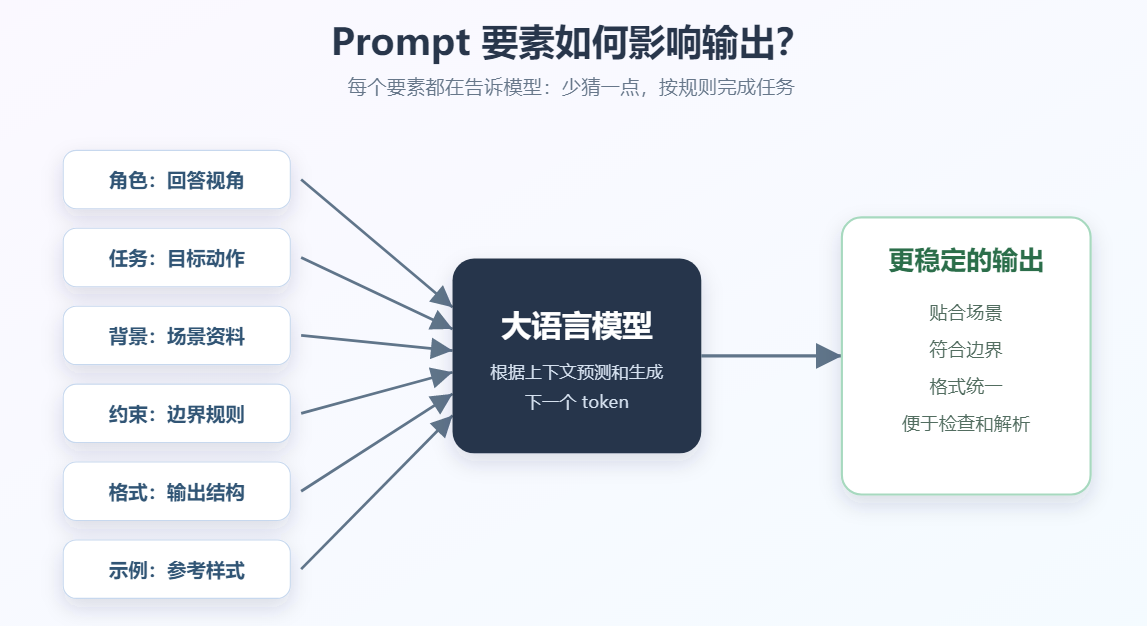
七、输出格式:让结果更稳定、更可解析
输出格式是把模型回答变得稳定、可检查、可接入程序的关键。
常见输出格式:
- Markdown 段落
- Markdown 表格
- JSON
- YAML
- 固定字段模板
- 编号步骤
如果只是给人看,Markdown 很方便:
text
请用 Markdown 输出,包含:
1. 核心结论
2. 关键概念
3. 示例
4. 易错点如果要给程序解析,JSON 更合适:
text
请只输出 JSON,不要输出额外解释:
{
"category": "功能建议 | Bug反馈 | 价格问题 | 售后咨询",
"reason": "判断原因",
"priority": "高 | 中 | 低"
}如果没有输出格式,模型可能这次用段落,下次用列表,再下次用表格。
对人阅读问题不大,但对程序解析就很麻烦。
八、示例:告诉模型什么算合格
示例是 Few-shot 的基础。它能告诉模型:输入长什么样,输出应该怎么写。
例如:
text
示例:
输入:这个功能很好,但希望能增加批量导出。
输出:
{
"category": "功能建议",
"reason": "用户表达了新增批量导出能力的需求",
"priority": "中"
}当任务规则比较抽象、输出风格比较特殊、分类边界容易混淆时,示例尤其有用。
比如客户反馈分类里,"功能建议"和"Bug 反馈"就容易混淆:
text
希望可以支持批量导出订单。这是功能建议。
text
导出订单时系统报错。这是 Bug 反馈。
如果不给示例,模型可能会把"导出相关"的内容都归成同一类。
给几个典型示例后,模型更容易理解分类边界。
九、综合例子:客户反馈分类
较弱 Prompt:
text
帮我看看这个客户反馈。问题很明显:
- 没说要看什么。
- 没说可选类别。
- 没说输出格式。
- 没说是否允许多选。
- 没说信息不足怎么办。
更好的 Prompt:
text
你是一名 SaaS 产品运营分析师。
任务:
请判断下面的客户反馈属于哪一种类型。
背景:
我们正在整理客户反馈,用于产品迭代和客服分流。
可选类型:
- 功能建议
- Bug 反馈
- 价格问题
- 售后咨询
要求:
1. 只能从可选类型中选择一个。
2. 如果同时包含多个问题,选择最主要的问题。
3. 不要编造客户没有表达的内容。
输出格式:
请只输出 JSON:
{
"type": "类型",
"reason": "一句话说明原因"
}
客户反馈:
这个系统挺好用的,但是导出数据时经常失败,希望尽快修复。可能输出:
json
{
"type": "Bug 反馈",
"reason": "客户明确提到导出数据时经常失败,希望修复。"
}这就是一个相对完整的业务 Prompt。
十、Zero-shot:不给示例,直接完成任务
Zero-shot 指的是:不提供样例,直接告诉模型任务,让它根据已有能力完成。
例子:
text
请把下面这句话翻译成英文:
今天天气很好,我想去公园散步。再比如:
text
请判断下面这段客户反馈属于"功能建议""Bug 反馈""价格问题"还是"售后咨询":
导出数据时经常失败,希望尽快修复。Zero-shot 适合:
- 任务很常见。
- 判断标准比较清楚。
- 输出格式不复杂。
- 对稳定性要求没有特别高。
优点是简单、成本低、token 少。
缺点是任务边界模糊时,模型可能按自己的理解发挥。
十一、Few-shot:给几个示例,让模型模仿
Few-shot 指的是:在 Prompt 中提供几个输入和输出示例,让模型学习任务模式。
例子:
text
请判断客户反馈类型。
可选类型:
- 功能建议
- Bug 反馈
- 价格问题
- 售后咨询
示例 1:
输入:希望可以支持批量导出订单。
输出:功能建议
示例 2:
输入:登录后页面一直空白。
输出:Bug 反馈
示例 3:
输入:套餐价格能不能便宜一点?
输出:价格问题
现在请判断:
输入:导出数据时经常失败,希望尽快修复。
输出:Few-shot 的价值在于:它不只是告诉模型"做什么",还告诉模型"什么样的输出算符合要求"。
Few-shot 适合:
- 分类边界容易混淆。
- 输出风格有固定要求。
- 任务不是特别常见。
- 你希望模型模仿某种格式。
注意:示例不是越多越好。
示例要典型、清晰、一致,并且和最终期望输出格式接近。
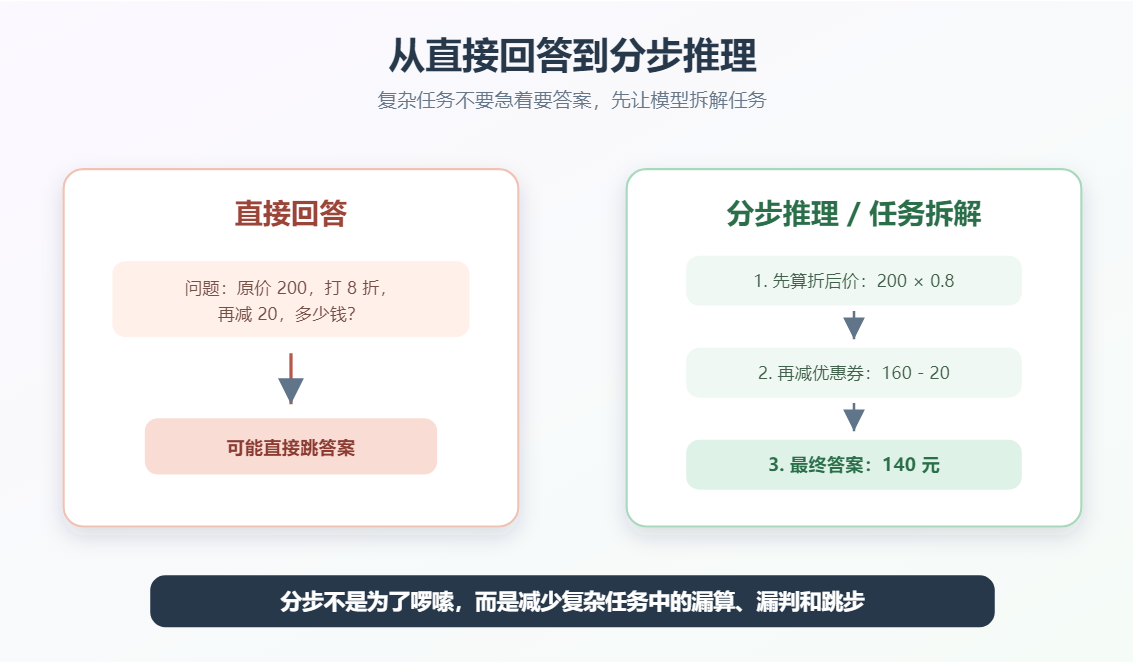
十二、Chain of Thought:让模型先拆解问题
Chain of Thought 常简称 CoT,意思是"思维链"。直觉上,它是让模型不要直接跳答案,而是先拆解问题、分析条件,再给出结论。
简单例子:
text
请先分析问题,再给出最终答案。
问题:
一个商品原价 200 元,先打 8 折,再使用 20 元优惠券,最终价格是多少?计算过程:
text
200 × 0.8 = 160
160 - 20 = 140
最终价格是 140 元。CoT 适合:
- 多步骤推理。
- 数学计算。
- 复杂判断。
- 需要比较多个条件的任务。
- 需要先分析再决策的场景。
不过真实应用里,不一定要把完整思考过程全部展示给用户。更推荐:
text
请先在内部完成分析,然后只输出:
1. 最终结论
2. 关键理由
3. 不确定点这样既鼓励模型认真拆解问题,又不会让最终答案过于冗长。

十三、任务拆解:复杂任务不要一口气全塞进去
任务拆解和 CoT 很接近,但更偏工程实践。
如果一个 Prompt 同时要求模型:
text
阅读、提取、判断、改写、生成 JSON、检查风险模型就容易漏步骤。
更稳的做法是拆开:
text
请按下面步骤完成:
1. 提取客户反馈中的关键信息。
2. 判断反馈类型。
3. 判断紧急程度。
4. 输出 JSON。对于复杂工作流,还可以拆成多轮:
text
第一步:先提取信息。
第二步:再根据提取结果分类。
第三步:最后生成结构化输出。拆解不是为了让 Prompt 看起来复杂,而是降低每一步的出错概率。
十四、三种技巧怎么选?
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 简单翻译、简单总结 | Zero-shot | 任务常见,直接做即可 |
| 分类标准细、格式固定 | Few-shot | 示例能帮助模型模仿边界和格式 |
| 数学题、复杂推理 | Chain of Thought | 分步骤更不容易跳错 |
| 复杂业务流程 | 任务拆解 + 结构化输出 | 降低漏步骤和格式失控 |
| 面向程序解析 | Few-shot + JSON 格式 | 示例和格式能提升稳定性 |
可以记一句:
text
简单任务直接做,
边界复杂给示例,
推理复杂拆步骤。十五、结构化输出:AI 工程化的关键
前面的内容主要解决"如何让模型理解任务"。
接下来解决另一个关键问题:如何让模型的输出稳定进入系统流程。
在真实 AI 应用里,模型回答不只是给人看,很多时候还要:
- 被程序解析字段。
- 根据分类结果分流。
- 写入数据库。
- 触发工作流下一步。
- 被评估系统判断是否合格。
这时就不能只说"帮我回答一下",而要明确输出结构。
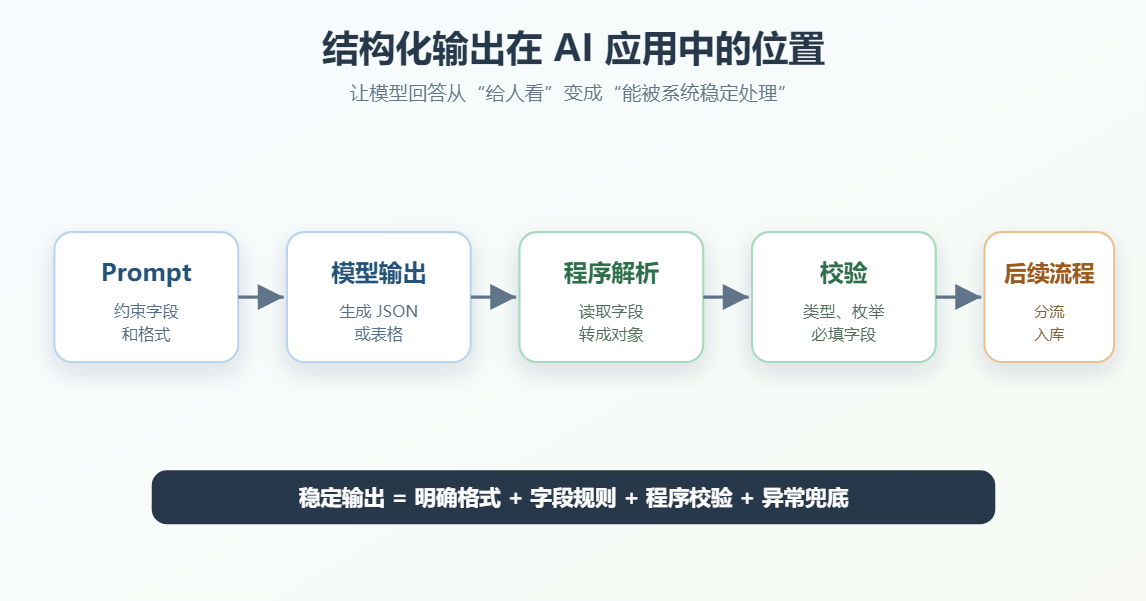
自由输出:
text
这个用户应该是在反馈一个 Bug,因为他说导出数据经常失败。结构化输出:
json
{
"type": "Bug 反馈",
"reason": "用户提到导出数据经常失败,说明已有功能出现异常。",
"priority": "高"
}后者更适合程序解析、校验和自动化处理。
十六、Markdown、表格、JSON 分别适合什么?
| 输出格式 | 适合场景 | 优点 | 注意点 |
|---|---|---|---|
| Markdown | 学习笔记、报告、总结 | 适合人阅读 | 程序解析不够稳定 |
| 表格 | 对比、清单、分类汇总 | 信息整齐 | 复杂嵌套不方便 |
| JSON | 程序解析、接口传递 | 字段清楚,可校验 | 需要防止多余文字和格式错误 |
| YAML | 配置、层级结构 | 可读性较好 | 缩进敏感 |
| 固定字段模板 | 审核、抽取、报告 | 易读、易检查 | 不如 JSON 标准化 |
如果面向人,Markdown 很好。
如果面向程序,JSON 通常更合适。
十七、不要只写"输出 JSON"
很多人会写:
text
请输出 JSON。这还不够。
问题是:
- 没有字段名。
- 没有字段类型。
- 没有可选值。
- 没有说明是否允许额外文字。
- 没有说明信息不足怎么办。
更好的写法:
text
请只输出 JSON,不要输出额外解释。
字段要求:
{
"category": "只能是:功能建议、Bug反馈、价格问题、售后咨询、无法判断",
"reason": "一句话说明原因",
"confidence": "0 到 1 之间的小数",
"need_human_review": "boolean"
}
规则:
1. 如果客户反馈信息不足,category 输出"无法判断"。
2. 如果 confidence 低于 0.6,need_human_review 输出 true。
3. 不要编造客户没有表达的内容。这就接近一个简单的 Schema。
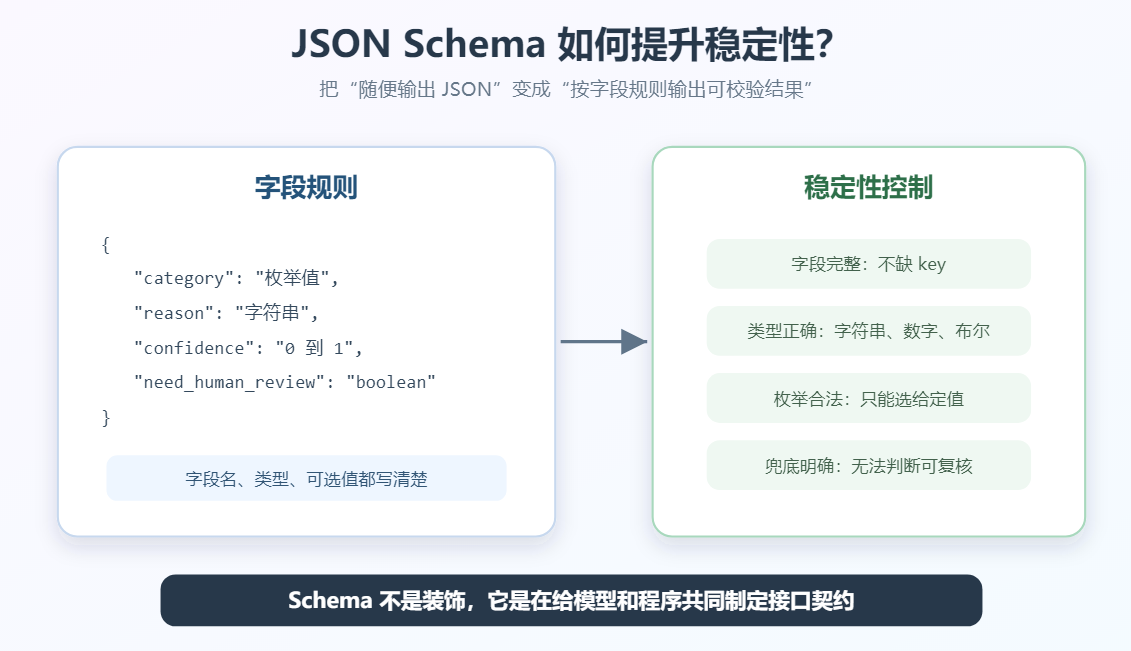
十八、稳定性控制:字段、枚举、兜底和校验
结构化输出不只是格式问题,它本质上是在控制模型输出空间。
常用方法:
- 明确字段名。
- 明确字段类型。
- 明确可选值。
- 明确禁止额外内容。
- 明确信息不足时怎么输出。
- 给出一两个合格示例。
- 对输出做程序校验,不合格时重试或要求修正。
特别重要的是兜底规则:
text
如果无法判断类型,请输出:
{
"type": "无法判断",
"reason": "说明缺少什么信息",
"need_human_review": true
}如果没有兜底,模型可能为了"必须回答"而猜一个看似合理但不可靠的结果。
真实系统里应该这样做:
text
Prompt 约束输出格式
↓
模型生成 JSON
↓
程序解析 JSON
↓
校验字段是否存在、类型是否正确、枚举值是否合法
↓
不合格则重试、修正或转人工记住一句话:
text
Prompt 是第一道约束,程序校验是第二道保险。十九、Prompt 调试:先定位问题,再修改
Prompt 很少一次就写到完美。真实工作中,Prompt Engineering 更像一个调试过程:
text
观察输出问题 -> 判断问题类型 -> 修改 Prompt -> 测试多组样例 -> 固化版本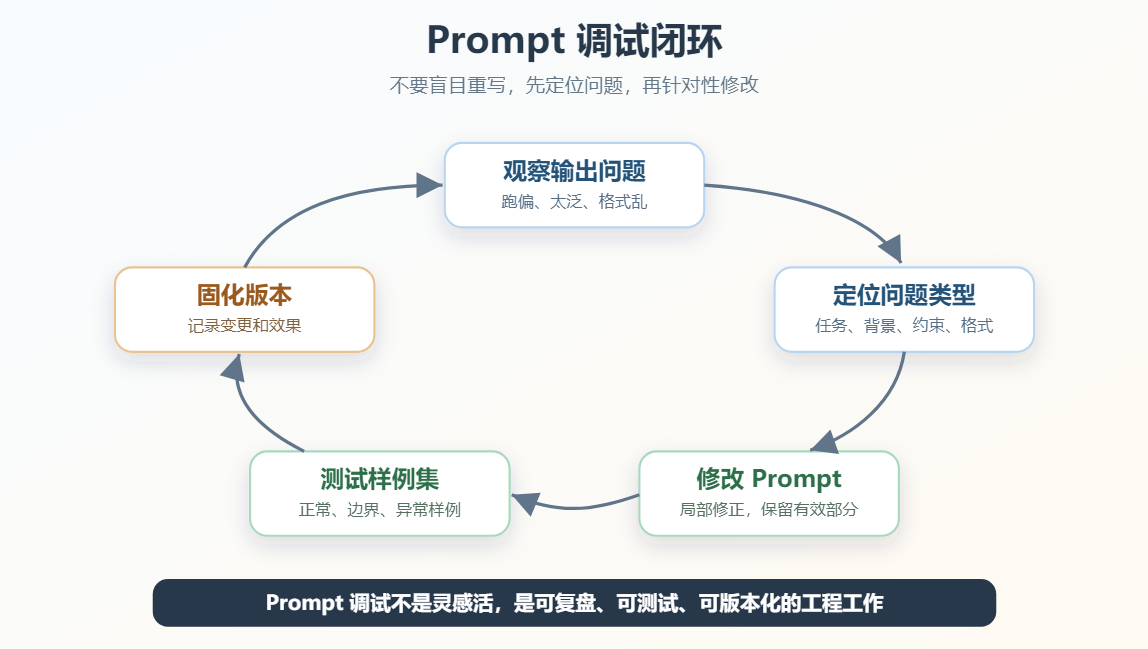
当模型输出不好时,不要第一反应就是"模型不行"。先判断是哪类问题。
| 输出问题 | 常见原因 | 优先修改方向 |
|---|---|---|
| 答非所问 | 任务不清楚 | 明确任务目标 |
| 内容太泛 | 背景不足 | 补充场景、读者、材料 |
| 格式混乱 | 输出格式不明确 | 固定字段、表格或 JSON |
| 编造信息 | 约束不足 | 限定只基于材料回答 |
| 分类不稳定 | 边界不清 | 增加规则和 Few-shot 示例 |
| 漏步骤 | 任务太复杂 | 拆分步骤或多轮完成 |
| 答案太长 | 长度和重点不清 | 限制字数和结构 |
调试 Prompt 的第一步,是把"输出不好"拆成具体症状。
二十、几个常见调试场景
1. 答非所问:改任务描述
模糊写法:
text
帮我处理一下这段内容。改进写法:
text
请阅读下面的客户反馈,并完成两件事:
1. 判断反馈类型。
2. 用一句话说明判断原因。2. 答案太泛:补背景
模糊写法:
text
请解释 RAG。改进写法:
text
请面向已经了解大语言模型、但还没有做过知识库问答项目的开发者解释 RAG。
重点说明:为什么需要检索、Embedding 的作用、向量数据库的作用。3. 格式混乱:固定结构
text
请只输出 JSON,不要输出额外解释:
{
"type": "功能建议 | Bug反馈 | 价格问题 | 售后咨询 | 无法判断",
"reason": "一句话说明原因",
"need_human_review": true
}4. 编造信息:加边界和兜底
text
要求:
1. 只根据给定材料回答。
2. 不要补充材料中没有的信息。
3. 如果材料中没有答案,请输出"资料中未提到"。5. 分类不稳定:加规则、反例和 Few-shot
text
分类规则:
- 如果用户希望新增当前不存在的能力,归为"功能建议"。
- 如果用户反馈已有功能无法正常使用,归为"Bug反馈"。
注意:
"希望修复导出失败"不是功能建议,而是 Bug反馈。二十一、用测试集验证 Prompt
很多 Prompt 在一个例子上效果很好,但换几个输入就不稳定。
真实应用中应该准备一组测试样例:
- 正常样例
- 边界样例
- 信息不足样例
- 多类别混合样例
- 异常格式样例
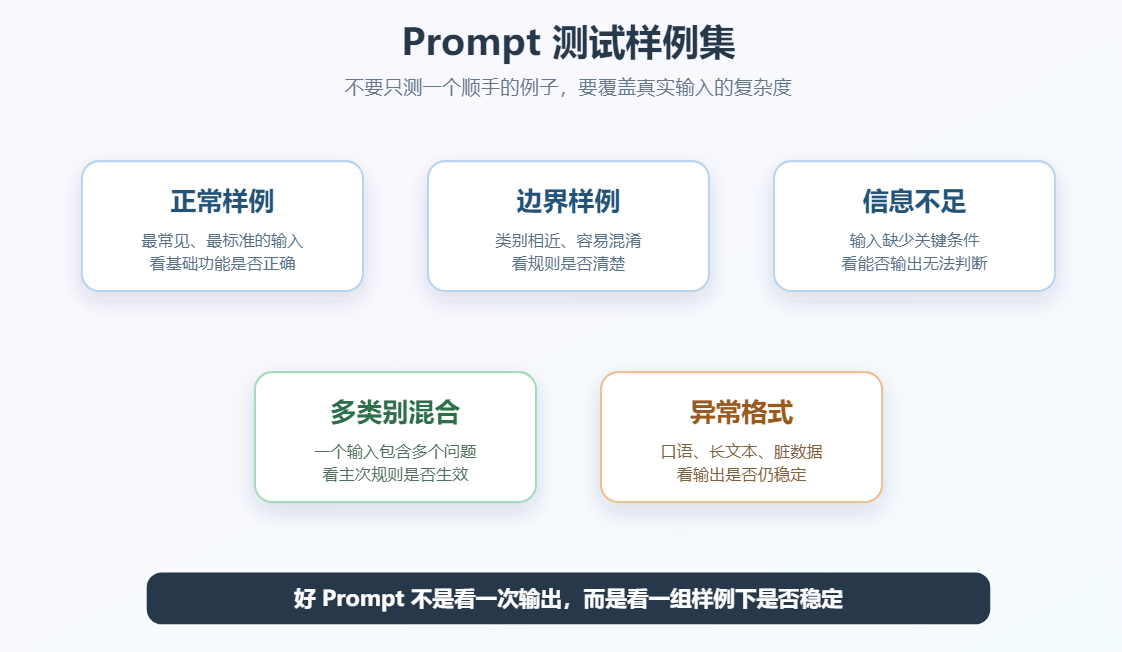
例如客户反馈分类,可以准备:
| 样例类型 | 输入示例 | 观察点 |
|---|---|---|
| 正常样例 | 导出数据失败 | 是否归为 Bug |
| 边界样例 | 希望导出更快 | 是否区分建议和 Bug |
| 信息不足 | 不太好用 | 是否输出无法判断 |
| 多类别混合 | 太贵,而且登录失败 | 是否按规则选主问题 |
| 异常格式 | 一大段口语化吐槽 | 是否仍能稳定输出 JSON |
好 Prompt 不是看一次输出,而是看一组样例下是否稳定。
二十二、Prompt 也要做版本管理
Prompt 也应该像代码一样管理版本。
至少记录:
- Prompt 版本号
- 修改了什么
- 为什么修改
- 测试了哪些样例
- 输出效果如何
- 当前已知问题
例如:
text
v1:基础分类 Prompt,只要求输出类型。
v2:增加 JSON 输出格式。
v3:增加"无法判断"和 need_human_review。
v4:增加功能建议 / Bug反馈 的边界示例。这样以后输出变差时,你能知道是哪次修改引入了问题。
二十三、一个实用调试口诀
text
跑偏看任务,
太泛补背景,
乱格式定结构,
会编造加边界,
分不清给示例,
漏步骤就拆解,
上线前做测试。这个口诀基本覆盖了 Prompt 调试的主要思路。
二十四、常见误区
| 误区 | 正确理解 |
|---|---|
| Prompt 是咒语 | Prompt 是任务说明书 |
| Prompt 越长越好 | 必要信息要清楚,无关内容不要堆 |
| 角色越夸张越好 | 角色要贴近任务 |
| Few-shot 示例越多越好 | 示例要典型、清晰、一致 |
| CoT 就是展示完整思考过程 | 可以让模型先分析,但最终只输出必要结论 |
| 输出 JSON 就一定稳定 | 还要字段、类型、枚举、兜底和程序校验 |
| 一个样例通过就够了 | 要用测试样例集验证 |
| 输出不好就全部重写 | 先定位问题,再局部修改 |
二十五、面试回答:Prompt Engineering 的核心是什么?
如果面试问:
text
你怎么理解 Prompt Engineering?可以这样回答:
text
Prompt Engineering 的核心不是写固定咒语,而是把任务、上下文、约束和输出格式清楚地表达给大模型,让模型减少猜测空间,从而得到更稳定、可检查、可复用的输出。
在实际工程里,我会先明确角色、任务、背景、约束、输出格式和示例;对于边界复杂的任务会使用 Few-shot,对于多步骤推理会做任务拆解;如果输出要接入程序,会要求结构化输出,例如 JSON,并配合字段校验、异常兜底和版本管理。如果问:
text
为什么结构化输出重要?可以回答:
text
因为真实 AI 应用里,模型输出往往要进入后续系统流程。结构化输出能让程序更容易解析、校验和处理结果。比如分类、抽取、审核任务中,JSON 字段、枚举值、置信度和人工复核标记都能提升系统稳定性。但 Prompt 不能替代程序校验,工程上还需要解析失败重试、字段校验和异常兜底。二十六、自测题
Q1. Prompt 为什么不是咒语?
因为 Prompt 的本质是任务说明书,目标是清楚表达任务、背景、约束和输出格式。
Q2. 一个完整 Prompt 通常包含哪些部分?
角色、任务、背景、约束、输出格式、示例。
Q3. Zero-shot 和 Few-shot 的区别是什么?
Zero-shot 不给示例,直接让模型完成任务;Few-shot 给几个输入输出示例,让模型模仿任务模式。
Q4. Chain of Thought 适合什么场景?
多步骤推理、复杂判断、数学计算、需要先分析再决策的场景。
Q5. 为什么 JSON 比 Markdown 更适合程序解析?
JSON 字段明确、结构标准、便于程序读取、校验和传递。
Q6. 为什么只写"输出 JSON"还不够?
还需要明确字段名、字段类型、可选值、是否允许额外内容、信息不足时如何兜底。
Q7. Prompt 调试为什么要先定位问题类型?
因为不同问题对应不同修改方向。跑偏看任务,太泛补背景,格式乱定结构,编造信息加边界。
Q8. 为什么不能只用一个样例验证 Prompt?
一个样例通过不代表在边界样例、异常样例、信息不足样例上也稳定。
二十七、总结
这一篇我们系统学习了 Prompt Engineering。
最重要的结论可以压缩成几句话:
- Prompt 不是咒语,而是任务说明书。
- 好 Prompt 的目标是减少模型猜测空间。
- 常用结构是:角色、任务、背景、约束、输出格式、示例。
- 简单任务可以 Zero-shot,边界复杂用 Few-shot,推理复杂用 CoT 或任务拆解。
- 真实 AI 应用里,结构化输出非常关键,尤其是 JSON、字段规则、枚举值、兜底规则和程序校验。
- Prompt 调试不是玄学,而是观察问题、定位原因、局部修改、测试验证、版本管理的工程过程。
学完这一章,你就已经具备了把大模型"从聊天工具变成可控组件"的基础能力。
下一篇我们进入一个更工程化、也更常见的应用方向:
text
RAG 知识库问答也就是:
text
如何让大模型基于企业文档、知识库和私有资料回答问题?这会把前面学过的 Embedding、Prompt、结构化输出真正串到一个完整系统里。