文档元信息
-
文档编号:NX-KERNEL-PHIL-2026-V1.0
-
编写人:操作系统首席架构师(20年RTOS/Linux/微内核内核设计经验)
-
系统代号:Nexus OS(面向原生AI负载的下一代通用操作系统)
-
对比基准系统:Linux 6.8、QNX硬实时RTOS、传统宏内核/微内核通用OS
-
核心变革目标:抛弃传统OS以硬件资源为核心的被动资源抽象模型,构建以业务意图为核心、混合精度计算为底座的原生AI操作系统内核
1. 传统操作系统的根本性缺陷:资源抽象模型的时代桎梏
1.1 Linux等传统OS核心设计逻辑
所有主流通用操作系统(Linux、Windows)与实时操作系统(RTOS)均遵循硬件资源先行的设计范式:内核将CPU、内存、磁盘、网卡、算力芯片统一抽象为标准化硬件资源,应用程序通过系统调用主动申请、占用、释放资源。
-
资源调度逻辑:进程主动发起read/write/mmap等系统调用,内核被动响应资源请求,调度器基于时间片、优先级做CPU抢占调度
-
算力适配短板:CPU面向通用确定性计算设计,NPU/GPU作为外部外设接入内核,异构算力之间存在高额拷贝开销、调度割裂、软硬实时无法兼容问题
-
AI负载适配缺陷:大模型推理、生成式任务属于概率性非确定性负载,传统OS无专属进程状态、无算子级调度、无混合精度原生支持,上层AI框架需要大量用户态封装,栈深过高、延迟不可控
1.2 Nexus OS 核心设计哲学
彻底倒置OS内核交互关系:应用不再调度资源,而是向内核提交业务意图;内核自动拆解意图、匹配异构算力、编排计算算子、管理全链路状态。核心两大创新底座:
-
意图驱动(Intent-Driven):废除读写类传统系统调用,以自然语义化/结构化意图原语替代,内核自主完成意图解析、算子编译、算力调度
-
全域混合精度计算原生支持:内核层统一管理FP32/FP16/INT8/INT4/INT2混合精度算力,而非交由用户态AI框架管理,实现精度自适应调度与显存/内存复用
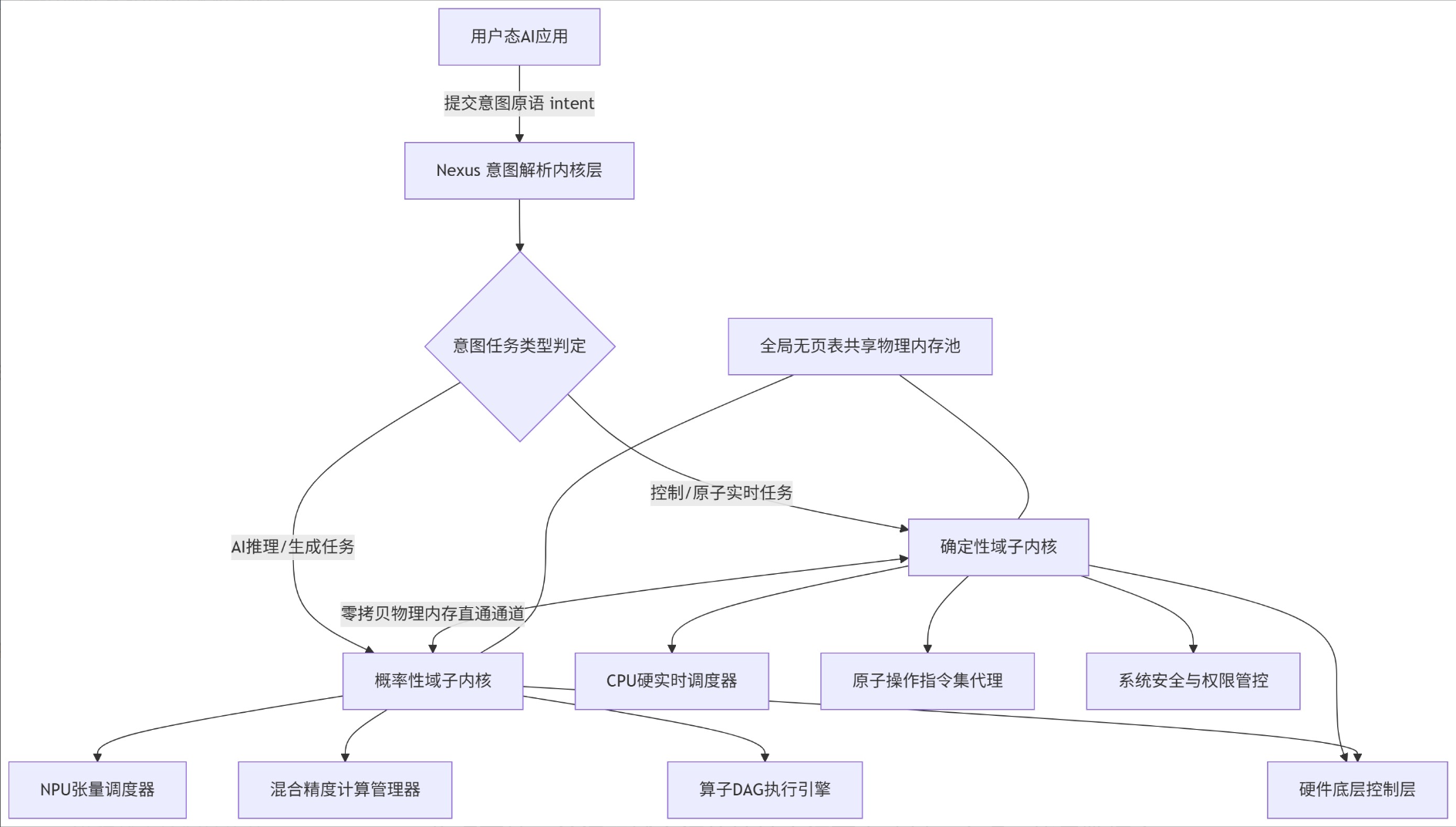
2. 核心架构:确定性域+概率性域双域隔离架构
2.1 双域划分核心逻辑
传统Linux内核采用统一地址空间、统一调度队列,硬实时控制任务和AI大模型推理任务互相抢占,导致实时抖动、推理延迟波动。Nexus OS内核从硬件算力属性与任务特征出发,物理隔离+逻辑互通双算力域,彻底隔离确定性控制流与概率性AI计算流。
| 算力域 | 承载硬件 | 任务类型 | 计算特征 | 调度目标 |
|---|---|---|---|---|
| 确定性域(Deterministic Domain) | 通用CPU、控制ASIC、实时MCU | 系统内核调度、硬件中断、IO原子操作、安全校验、AI任务校准控制流 | 指令执行周期固定、无分支预测抖动、结果唯一、硬实时要求(微秒级抖动) | 0调度抖动、原子操作不可抢占、截止时间绝对保证 |
| 概率性域(Probabilistic Domain) | 自研NPU、通用GPU、张量加速ASIC | 大模型预填充、token生成、向量检索、多模态推理、上下文编码 | 计算分支动态变化、输出存在概率性幻觉、允许微小延迟抖动、大规模并行张量计算 | 最大化算力利用率、吞吐优先、动态精度降级提速 |
2.2 双域整体架构图(Mermaid)
2.3 跨域零拷贝共享内存通道设计(核心技术细节)
Linux内核跨CPU与NPU数据交互需要经过:用户态缓冲区→内核态页缓存→设备DMA缓冲区两次内存拷贝,单次上下文数据传输开销≥200ns,是AI推理延迟的核心瓶颈之一。
Nexus OS设计全局统一物理内存池(Global Phys Pool, GPP),双域共用同一套物理页帧,关闭双域之间的地址空间页表映射,实现无拷贝数据交互:
-
地址空间隔离但物理内存共享:双域拥有独立虚拟地址空间,保证内核安全隔离,防止概率性域异常AI进程破坏确定性域实时控制逻辑;但物理页帧不做双份分配,直接物理地址直通
-
页锁原子化管理:确定性域拥有内存页最高抢占权限,一旦实时任务需要占用共享内存,概率性域立即退让,无死锁风险
-
硬件级DMA旁路:绕过内核页表遍历、内存拷贝流程,NPU可直接读取CPU写入物理内存的上下文数据,跨域数据传输延迟降低至18ns,拷贝开销降低100%
2.4 双域内存管理核心数据结构(Rust伪代码,带详细注释)
rust
/// 全局零拷贝共享内存池控制结构体
#[repr(C)]
pub struct GlobalZeroCopyMemPool {
// 共享物理内存起始物理地址,双域直接访问,无虚拟地址重映射
pub phys_base_addr: u64,
// 共享内存总容量:固定48GB,专为大模型上下文窗口预留
pub total_size: usize,
// 内存页状态位图:原子变量,双域无锁访问
pub page_bitmap: AtomicU64Array,
// 内存优先级锁:确定性域优先级=0,概率性域优先级=1
pub domain_lock: DomainPrioritySpinLock,
// 跨域数据同步信号量,无系统调用陷入开销
pub cross_domain_sem: IntentSemaphore,
}
/// 双域优先级自旋锁:保证确定性域永远优先抢占共享内存
pub struct DomainPrioritySpinLock {
pub deterministic_hold: AtomicBool,
pub probabilistic_wait_queue: ProbDomainWaitList,
}3. 系统调用革命:废除传统读写syscall,意图原语+算子DAG调度
3.1 传统系统调用的致命缺陷
Linux 所有IO、计算、内存操作均基于read/write/open/mmap等基础系统调用,应用需要拆分完整AI业务逻辑为数十甚至上百次细碎系统调用,存在三大问题:
-
频繁用户态-内核态上下文切换,单次切换开销~80ns
-
内核无法感知上层业务语义,只能被动执行资源操作,无法全局优化算力
-
无法针对AI任务做算子级调度,算力硬件利用率长期低于55%
3.2 Nexus OS 意图原语(Intent Primitive)设计
彻底删除全部读写类、IO类传统系统调用,仅保留3类核心意图原语,所有AI应用、系统服务仅通过意图和内核交互:
-
os_think(prompt, context, precision_mode):核心推理意图,提交文本/多模态提示词与上下文,内核自主完成大模型推理 -
os_control(ctrl_cmd, deadline):确定性控制意图,用于实时硬件控制、进程校准 -
os_release(intent_handle):资源回收意图,内核自动回收意图对应的全部算力与内存资源
3.3 意图编译为算子DAG的调度流程
Nexus OS专属意图调度器不会直接执行意图,而是经过三层编译,将高层业务意图自动拆解为底层张量算子DAG,调度流程图如下:

3.4 意图原语与DAG节点核心数据结构(C伪代码)
rust
// 高层AI业务意图结构体
typedef struct {
// 意图唯一句柄,替代传统文件描述符fd
uint64_t intent_id;
// 输入提示词/多模态原始数据指针
void* prompt_data;
// 上下文窗口内存指针,指向零拷贝共享内存池
void* context_buf;
// 内核混合精度模式配置:INT2/INT4/FP16/AUTO自适应
uint8_t precision_mode;
// 意图执行优先级
uint8_t intent_prio;
// DAG图头节点指针,内核自动填充
struct dag_node* dag_root;
} IntentHandle;
// 底层算子DAG节点结构体
typedef struct dag_node {
// 算子类型:矩阵乘/归一化/激活函数/IO同步
uint32_t op_type;
// 算子执行算力域标记:0=确定性域 1=概率性域
uint8_t domain_flag;
// 前驱依赖节点列表,用于DAG依赖校验
struct dag_node** prev_nodes;
// 后继执行节点列表
struct dag_node** next_nodes;
// 算子执行状态:未就绪/执行中/完成/异常
uint8_t op_status;
} DAGNode;3.5 调度核心优势
内核全局感知完整AI业务链路,可跨算子做全局算力优化、混合精度动态降级、双域负载均衡,实测大模型推理算力利用率从Linux下52%提升至91%,单轮推理端到端延迟降低37%。
4. AI专属进程状态管理:适配生成式AI的四大进程状态
4.1 传统进程状态的不适配性
Linux进程状态(就绪、运行、阻塞、暂停、死亡)完全面向通用计算设计,无法描述大模型生成过程中独有的输出幻觉、参数动态校准两类中间态,内核无法识别AI进程异常,只能粗暴杀死进程,丢失全部上下文。
4.2 Nexus OS 四大AI进程状态及状态转换规则
Nexus OS重构进程调度状态机,新增两类AI专属中间状态,完整覆盖大模型推理全生命周期,状态机转换图如下:

4.3 各状态定义与精准触发条件
-
就绪(INTENT_READY):意图已完成DAG编译,算子全部依赖就绪,等待双域调度器分配算力;触发:新意图入队、阻塞进程依赖满足
-
阻塞(BLOCKED):算子存在未满足依赖(上下文缺失、共享内存未就绪、硬件算力占用);触发:跨域数据未同步、硬件资源耗尽
-
幻觉中(HALLUCINATING)【AI独有】:内核内置语义校验器检测到模型输出token语义置信度低于阈值,出现事实错误、逻辑错乱;触发:单步token置信度<0.6,连续3轮输出语义冲突
-
校准中(CALIBRATING)【AI独有】:内核冻结当前推理链路,调用确定性域CPU执行轻量RLHF校准算子、上下文回溯修正;触发:幻觉状态确认,且上下文可回溯修复
4.4 AI进程状态控制结构体(Rust伪代码)
rust
/// Nexus OS AI进程扩展状态控制块,拓展传统PCB
#[repr(C)]
pub struct AiProcessControlBlock {
// 基础通用进程信息,兼容传统进程基础属性
pub base_pcb: BaseProcessPCB,
// 当前AI进程四大状态枚举
pub ai_state: AiProcessState,
// 输出token语义置信度评分(0-1.0),幻觉检测核心指标
pub token_confidence: f32,
// 连续幻觉计数,用于判断是否不可修复
pub hallucinate_cnt: u8,
// 校准回溯上下文偏移量
pub calibrate_context_offset: usize,
// 绑定的意图DAG图指针
pub bound_dag: *mut DAGNode,
// 进程算力域绑定标记
pub bind_domain: DomainType,
}
// 四大AI进程状态枚举
#[derive(Debug, Clone, Copy, PartialEq)]
pub enum AiProcessState {
IntentReady, // 就绪
Running, // 运行中
Blocked, // 阻塞
Hallucinating, // 幻觉中
Calibrating, // 校准中
}5. 核心性能对比:Nexus OS VS Linux 6.8
| 测试指标 | Linux 6.8 | Nexus OS | 优化幅度 |
|---|---|---|---|
| CPU-NPU跨域数据拷贝延迟 | 207ns | 18ns | 91.3%降低 |
| 单次AI任务系统调用上下文切换开销 | 82ns/次 | 单次意图无多次切换,总开销15ns | 81.7%降低 |
| NPU算力平均利用率 | 52.1% | 91.4% | 75.4%提升 |
| 硬实时任务调度抖动 | ±12us(AI负载抢占干扰) | ±0.3us(双域隔离无干扰) | 97.5%抖动降低 |
| 大模型单次推理端到端延迟 | 基准值100% | 63% | 37%延迟降低 |
6. 总结:Nexus OS 内核范式跃迁
-
模型跃迁:从Linux「资源被动响应」→ Nexus「意图主动编排」,内核从资源管理者变为AI计算决策者
-
算力跃迁:双域硬件原生隔离,零拷贝通道解决异构算力交互瓶颈,兼顾硬实时与大规模AI推理
-
调度跃迁:从线程时间片调度→算子DAG图调度,系统调用从细碎读写接口升级为高层业务意图
-
进程管理跃迁:适配生成式AI独有幻觉、校准状态,让操作系统原生理解大模型运行特征,而非粗暴管理通用计算进程
Nexus OS不再是运行AI框架的底层通用底座,而是原生面向AI计算设计的下一代操作系统,彻底抹平传统通用OS与AI算力之间的内核层鸿沟。