目录
[1. 什么是内置函数](#1. 什么是内置函数)
[2. 函数调用语法](#2. 函数调用语法)
[1. 日期时间函数分类详解](#1. 日期时间函数分类详解)
[1.1 获取当前系统时间](#1.1 获取当前系统时间)
[1.2 日期提取函数](#1.2 日期提取函数)
[1.3 日期计算函数](#1.3 日期计算函数)
[1.4 日期格式化函数](#1.4 日期格式化函数)
[2. 日期函数实战案例](#2. 日期函数实战案例)
[2.1 筛选近 30 天内录入的学生](#2.1 筛选近 30 天内录入的学生)
[2.2 报表脱敏与格式美化](#2.2 报表脱敏与格式美化)
[3. 使用注意](#3. 使用注意)
[1. 核心字符串函数分类详解](#1. 核心字符串函数分类详解)
[1.1 长度与大小写转换](#1.1 长度与大小写转换)
[1.2 字符串拼接与截取](#1.2 字符串拼接与截取)
[1.3 字符串查找、替换与修剪](#1.3 字符串查找、替换与修剪)
[2. 字符串函数案例](#2. 字符串函数案例)
[2.1 生成标准化的业务通知文案](#2.1 生成标准化的业务通知文案)
[2.2 隐私数据脱敏](#2.2 隐私数据脱敏)
[1. 核心数学函数分类详解](#1. 核心数学函数分类详解)
[1.1 绝对值与求余运算](#1.1 绝对值与求余运算)
[1.2 取整与四舍五入](#1.2 取整与四舍五入)
[1.3 随机数函数](#1.3 随机数函数)
[2. 数学函数实战案例](#2. 数学函数实战案例)
[2.1 期末平均成绩的规整化展示](#2.1 期末平均成绩的规整化展示)
[2.2 课堂随机点名](#2.2 课堂随机点名)
[1. 流程控制函数](#1. 流程控制函数)
[2. 系统与环境信息函数](#2. 系统与环境信息函数)
[3. 流程控制函数生产级实战案例](#3. 流程控制函数生产级实战案例)
[3.1 解决缺考造成的连锁影响](#3.1 解决缺考造成的连锁影响)
[3.2 生成多维度的学生成绩考核报告](#3.2 生成多维度的学生成绩考核报告)
[实战 OJ:统计字符串中逗号出现次数](#实战 OJ:统计字符串中逗号出现次数)
一、为什么需要内置函数
在攻克了数据操作与聚合查询的关卡后,我们已经能够自如地指挥 MySQL 筛选、修改和归类大批量的数据。但在实际的项目开发中,业务的需求往往更加刁钻和精细
例如:前端页面要求用户的手机号必须脱敏显示(如 138****1234);Excel 报表要求日期格式必须是2026年06月21日;或者需要根据用户的生日自动计算出其当前年龄
面对这些涉及字符串剪裁、日期加减、数学计算以及条件判断 的处理需求,如果单纯依靠基础的 SQL 语法,往往显得无能为力。为了让我们在数据库一线就能优雅地解决这些问题,MySQL 提供了强大的内置函数
1. 什么是内置函数
内置函数是 MySQL 数据库引擎预先编写、封装好并内置在系统内部的特定功能代码块。我们只需要传入对应的参数,函数就会在底层执行复杂的逻辑,并返回处理后的结果
内置函数的核心作用
在现代企业级开发中,关于 "数据清洗和转换应该放在后端(如 Java/Python)还是放在数据库" 一直存在探讨。而合理利用内置函数,具备以下不可替代的优势:
-
减少网络带宽: 举个例子,如果需要判断一封邮件的长度是否合规,利用内置函数直接在 WHERE 子句中过滤,数据库最终只返回符合条件的数据。如果放在后端处理,则必须把整表的所有大文本数据全部读取到应用层内存中,会造成巨大的网络和内存浪费
-
简化后端业务: 诸如生成当前系统时间戳、字符串大小写转换、四舍五入等操作,直接在 SQL 层面通过一行函数搞定,能够让后端的业务代码变得更加干净
-
统一业务: 当多个不同的微服务(例如一个 Java 后台管理系统和一个 Python 数据分析脚本)同时访问同一个数据库时,直接在数据库层利用内置函数进行时间或数值计算,能够避免因各开发语言底层精度不同而导致的 "计算结果不一致" 问题
2. 函数调用语法
MySQL 的内置函数调用方式非常灵活,它们几乎可以嵌入到 SQL 语句的任何角落(如 SELECT 子句、WHERE 子句、ORDER BY 子句等)
基础调用语法
标准的函数调用结构如下:
sql
函数名(参数1, 参数2, ...)两种常见的调用形态
独立验证(不依赖具体数据表)
如果我们只是想临时测试某个函数的功能,或者获取系统的全局信息,可以省略 FROM 子句,直接使用 SELECT 调用函数:
sql
-- 获取当前 MySQL 数据库的版本号
SELECT VERSION();
-- 计算 -50 的绝对值
SELECT ABS(-50);字段驱动(结合数据表按行处理)
当函数作用于数据表中的某个字段时,它会对检索出来的每一行记录的该列数值进行逐一处理:
sql
-- 将表中所有学生的姓名转换为大写(假设名字包含英文)
SELECT UPPER(name) FROM student_score;二、日期时间函数
在商业系统的开发中,时间是一个至关重要的维度。无论是订单的生成时间、用户的最后登录时间等,都高度依赖对日期和时间的精准操作
MySQL 提供了丰富的日期时间处理函数。为了方便掌握,我们获取、提取、计算与格式化内容合并归类,并结合实战进行拆解
1. 日期时间函数分类详解
1.1 获取当前系统时间
用于在插入数据或生成报表时获取当前的最新时间
-
NOW / CURRENT_TIMESTAMP: 返回当前系统的完整日期和时间,格式为 YYYY-MM-DD HH:MM:SS
-
CURDATE(): 仅返回当前日期,格式为 YYYY-MM-DD
-
CURTIME(): 仅返回当前时间,格式为 HH:MM:SS
sql
-- 验证获取当前时间的函数
SELECT NOW() AS 完整时间, CURDATE() AS 仅日期, CURTIME() AS 仅时间;1.2 日期提取函数
当数据库存储了一个完整的日期时间(如 2026-06-21 09:30:00),而业务只需要知道它属于哪一年、哪个月或周几时,可以使用提取函数:
-
YEAR(date) / MONTH(date) / DAY(date): 分别提取年、月、日
-
**HOUR(time) / MINUTE(time) / SECOND(time):**分别提取时、分、秒
sql
-- 从指定的日期时间中提取年份和月份
SELECT YEAR('2026-06-21 09:30:00') AS 年, MONTH('2026-06-21 09:30:00') AS 月;1.3 日期计算函数
这是日期处理中最核心的业务武器。比如 "计算会员 30 天后的到期时间"、"计算两个日期之间相差了多少天"
-
**DATE_ADD(date, INTERVAL expr unit):**向后累加时间
-
**DATE_SUB(date, INTERVAL expr unit):**向前推算时间
- 常见的单位包括:YEAR(年)、MONTH(月)、DAY(天)、HOUR(小时)
-
**DATEDIFF(date1, date2):**计算两个日期之间的差值(date1 - date2),返回相差的天数
sql
-- 计算今天往后推 7 天的日期,以及两个日期的天数差
SELECT
DATE_ADD(CURDATE(), INTERVAL 7 DAY) AS 七天后,
DATEDIFF('2026-06-30', '2026-06-21') AS 距离月底天数;1.4 日期格式化函数
前后端交互时,前端页面或 Excel 报表往往需要特定格式的日期字符串。
DATE_FORMAT(date, format) 可以将日期类型完美转化为任意指定的格式
常用占位符对照表
-
%Y:4 位的年份(如 2026)
-
%m:2 位的月份(01-12)
-
%d:2 位的月内天数(01-31)
-
%H:24 小时制的小时(00-23)
-
%i:2 位的分钟(00-59)
-
%s:2 位的秒数(00-59)
sql
-- 将当前时间转换为习惯的格式
SELECT DATE_FORMAT(NOW(), '%Y年%m月%d日 %H时%i分%s秒') AS 格式化输出;
-- 输出结果:2026年06月21日 21时24分00秒(基于当前系统时间)2. 日期函数实战案例
下面我们沿用之前的 student_score(学生成绩表),通过两个贴近真实业务的需求,演练日期函数的综合应用
2.1 筛选近 30 天内录入的学生
业务场景: 随着时间推移,表内的历史数据越来越多。运营团队需要搭建一个动态看板,只查看 "最近 30 天内" 新录入的学生成绩,以便追踪近期的教学反馈
sql
-- 利用 DATE_SUB 动态构建 30 天前的时间边界
SELECT id, student_no, name, created_at
FROM student_score
WHERE created_at >= DATE_SUB(NOW(), INTERVAL 30 DAY);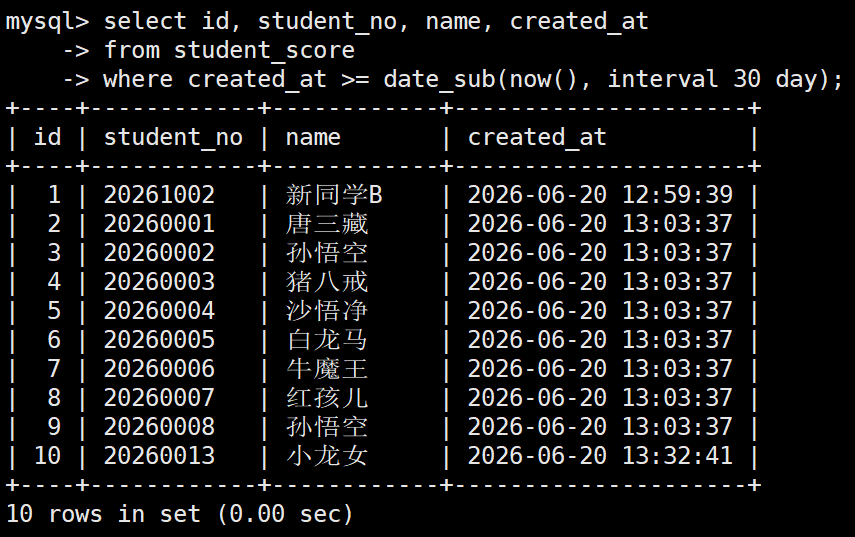
2.2 报表脱敏与格式美化
业务场景: 后台管理系统需要导出一份 "学生档案录入报告"。要求:
-
录入时间必须精确到分钟,且以 年-月-日 时:分 的格式展现
-
增加一列统计指标,算出该记录已经录入了多少天(留存时长)
sql
SELECT
student_no AS 学号,
name AS 姓名,
DATE_FORMAT(created_at, '%Y-%m-%d %H:%i') AS 录入时间,
DATEDIFF(NOW(), created_at) AS 已录入天数
FROM student_score
ORDER BY 已录入天数 DESC;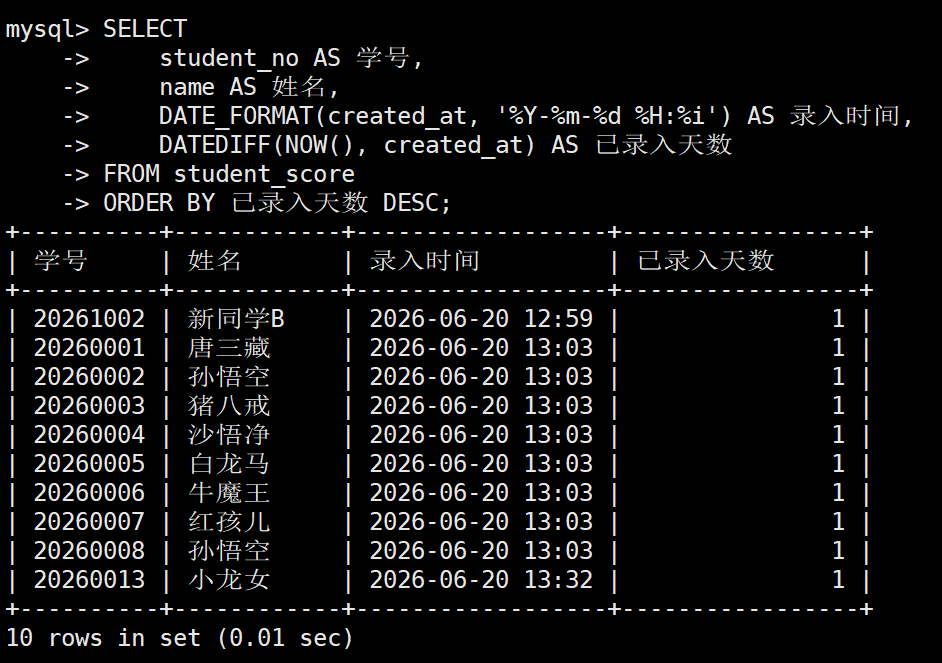
3. 使用注意
日期计算函数虽然便利,但在 WHERE 子句中使用时隐藏着一个巨大的性能陷阱
错误写法
假设我们要查询 2026 年录入的学生,很多人会写出如下 SQL:
sql
-- 不推荐:会导致全表扫描
SELECT * FROM student_score WHERE YEAR(created_at) = 2026;底层原理解析: 哪怕我们在 created_at 字段上建立了高效的 B+ 树索引,一旦将该字段包裹在函数内部(如 YEAR(created_at)),MySQL 引擎将无法直接利用索引进行快速定位。因为引擎必须把表里的每一行记录都读取出来,在 CPU 中执行一次 YEAR() 计算,最后才能进行对比。这会导致索引彻底失效,在千万级大表中会直接引发全表扫描,拖垮整台数据库
最佳实践
应当始终保持字段的干净与独立,将计算过程移至等号的右侧(常量端):
sql
SELECT * FROM student_score
WHERE created_at >= '2026-01-01 00:00:00'
AND created_at <= '2026-12-31 23:59:59';三、字符串函数
在系统研发中,文本数据的清洗与格式化占据了数据处理的很大一部分比例。例如:生成用户友好的通知文案、对手机号或身份证进行脱敏处理、过滤输入框前后的空格等
MySQL 提供了强大的字符串内置函数。我们将这些函数归纳为 "长度与大小写"、"拼接与截取" 以及 **"查找、替换与修剪"**三个类别
1. 核心字符串函数分类详解
1.1 长度与大小写转换
用于文本长度校验以及标准化处理。
-
CHAR_LENGTH(str): 返回字符串的字符个数。无论汉字、英文字母还是数字,一个符号均算作一个字符
-
LENGTH(str) : 返回字符串的字节长度。该函数的返回值高度依赖数据库的字符集编码
-
UPPER(str) / LOWER(str): 将字符串中的英文字母分别强制转换为全大写或全小写
注意
在目前的生产环境中,绝大多数数据库都统一采用了 utf8mb4 编码
-
执行 CHAR_LENGTH('中文'),结果为 2(代表 2 个字)
-
执行 LENGTH('中文'),结果为 6(在 UTF-8 编码下,一个常用汉字通常占用 3 个字节)
在做输入框字数限制校验时,强烈建议统一使用 CHAR_LENGTH,避免因中英文混合输入导致字数算错
1.2 字符串拼接与截取
用于对文本进行组装或碎片化提取
-
CONCAT(s1, s2, ...): 将多个字符串或字段值首尾拼接成一个完整的长字符串。
-
CONCAT_WS(separator, s1, s2, ...): 带有分隔符的拼接。第一个参数为分隔符,后续拼接时系统会自动在各段之间插入该分隔符
-
SUBSTRING(str, pos, len) : 从位置 pos 开始,截取长度为 len 的子字符串。MySQL 的文本索引是从 1 开始计算的,而不是 0
-
LEFT(str, len) / RIGHT(str, len): 分别从字符串的最左侧或最右侧快速截取指定长度的字符
sql
SELECT
CONCAT('MySQL', '-', '8.0') AS 基础拼接,
CONCAT_WS('/', '2026', '06', '21') AS 带分隔符拼接,
SUBSTRING('专注于数据库技术', 4, 3) AS 中间截取; -- 结果:数据库1.3 字符串查找、替换与修剪
用于文本数据的清洗与修正
-
REPLACE(str, from_str, to_str): 文本替换。将原字符串中所有的 from_str 批量替换为 to_str
-
TRIM(str): 自动去除字符串首尾两端的空格(中间的空格不会被去掉)。常用于清洗由于用户误操作输入的隐形空格
2. 字符串函数案例
下面我们基于现有的学生成绩表,来演练两个极其贴近企业真实开发场景的字符串实战
2.1 生成标准化的业务通知文案
业务场景: 班主任需要导出一份话术,用于在家长群里通报。要求输出的格式形如:
【天字一班】唐三藏同学,学号:20260001
sql
SELECT
CONCAT('【', class_name, '】', name, '同学,学号:', student_no) AS 班级通知
FROM student_score;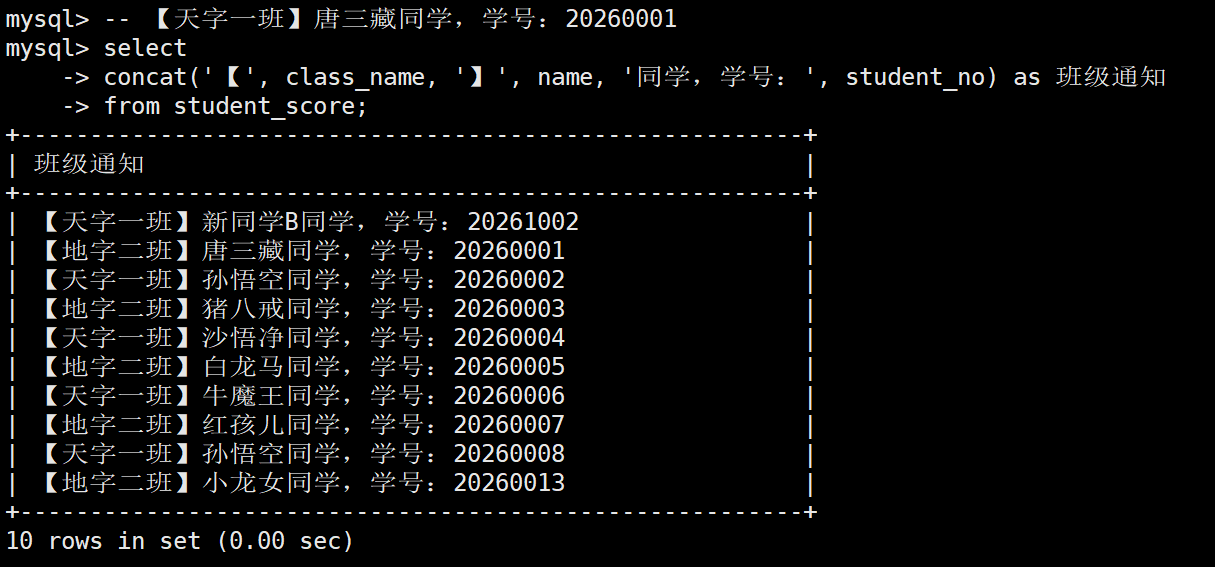
2.2 隐私数据脱敏
业务场景: 根据国家网络安全与个人隐私保护法,管理系统在展示学生列表时,不能直接裸露展示完整的学号和姓名,必须进行去隐私化(脱敏)处理
-
姓名规则:只保留姓氏,后面用一个 * 号遮蔽(如:唐三藏 -> 唐*)
-
学号规则:保留前 4 位和后 2 位,中间两位用 ** 遮蔽(如:20260001 -> 2026**01)
sql
SELECT
name AS 原始姓名,
CONCAT(LEFT(name, 1), '*') AS 脱敏姓名,
student_no AS 原始学号,
CONCAT(LEFT(student_no, 4), '**', RIGHT(student_no, 2)) AS 脱敏学号
FROM student_score;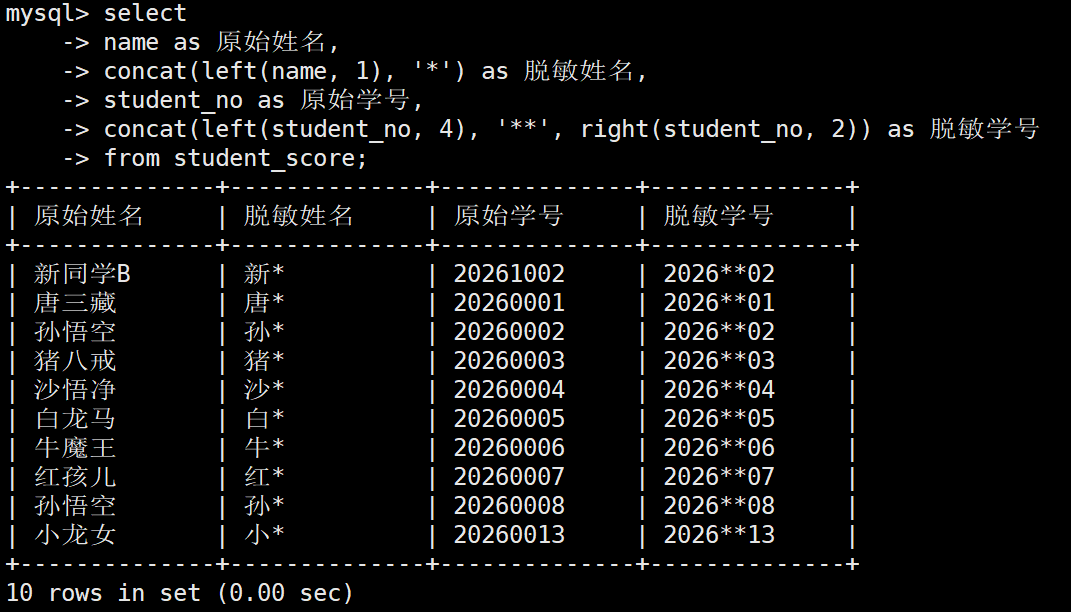
四、数学函数
在数据库中,除了处理文本和日期,我们也经常需要进行数值计算。虽然复杂的算法通常交由应用层处理,但诸如四舍五入、数据均值的取整、求绝对值以及抽取幸运用户(随机数)等底层操作,直接在数据库中利用数学函数解决,会具备更高的执行效率和精度优势
1. 核心数学函数分类详解
1.1 绝对值与求余运算
-
ABS(x): 返回 x 的绝对值
-
MOD(n, m): 返回 n 除以 m 的余数(模运算),其效果等同于使用运算符 %。常用于奇偶数过滤或分布式分库分表的路由判定
sql
-- 验证绝对值与求余
SELECT ABS(-12.5) AS 绝对值, MOD(10, 3) AS 余数, 5 % 2 AS 运算符求余;1.2 取整与四舍五入
在金融、报表等对数字敏感的场景中,如何处理小数点后的尾数至关重要。MySQL 提供了三种数值修正策略:
-
CEIL(x) 或 CEILING(x): 向上取整。返回大于或等于 x 的最小整数(不管小数位是多少,只要有值就直接向前进一位)
-
FLOOR(x): 向下取整。返回小于或等于 x 的最大整数(直接砍掉所有小数位,保留整数部分)
-
ROUND(x, d): 四舍五入。保留 x 的 d 位小数。如果不指定 d,则默认 d=0(即直接四舍五入到整数)
| 输入数值 (x) | CEIL(x) (向上) | FLOOR(x) (向下) | ROUND(x, 1) (四舍五入) |
|---|---|---|---|
| 3.14 | 4 | 3 | 3.1 |
| 3.68 | 4 | 3 | 3.7 |
| -3.14 | -3 | -4 | -3.1 |
sql
SELECT CEIL(3.14) AS 向上, FLOOR(3.68) AS 向下, ROUND(3.68, 1) AS 四舍五入;1.3 随机数函数
- RAND(): 返回一个 0 到 1.0 之间的随机浮点数(即 0 <= RAND() < 1.0)
生成指定范围的随机整数
如果需要生成一个 min, max 闭区间内的随机整数(例如生成验证码、随机分配卡券),可以配合 FLOOR 采用以下通用换算公式:
sql
-- 示例:随机生成一个 1 到 100 之间的整数
SELECT FLOOR(RAND() * 100) + 1 AS 随机百数;2. 数学函数实战案例
下面我们继续结合学生成绩表,通过两组教务系统业务需求,演示数学函数的综合应用
2.1 期末平均成绩的规整化展示
业务场景: 随着之前加分政策和多次修改,学生的各科平均分出现了大量的小数。教务处要求导出一份成绩简报,要求:
-
数学平均分直接向下取整(抹去零头,防止虚高)
-
语文平均分要求向上取整
-
英语平均分要求严格执行四舍五入,且保留 1 位小数
sql
SELECT
class_name AS 班级,
FLOOR(AVG(math_score)) AS 数学规整分,
CEIL(AVG(chinese_score)) AS 语文规整分,
ROUND(AVG(english_score), 1) AS 英语四舍五入分
FROM student_score
GROUP BY class_name;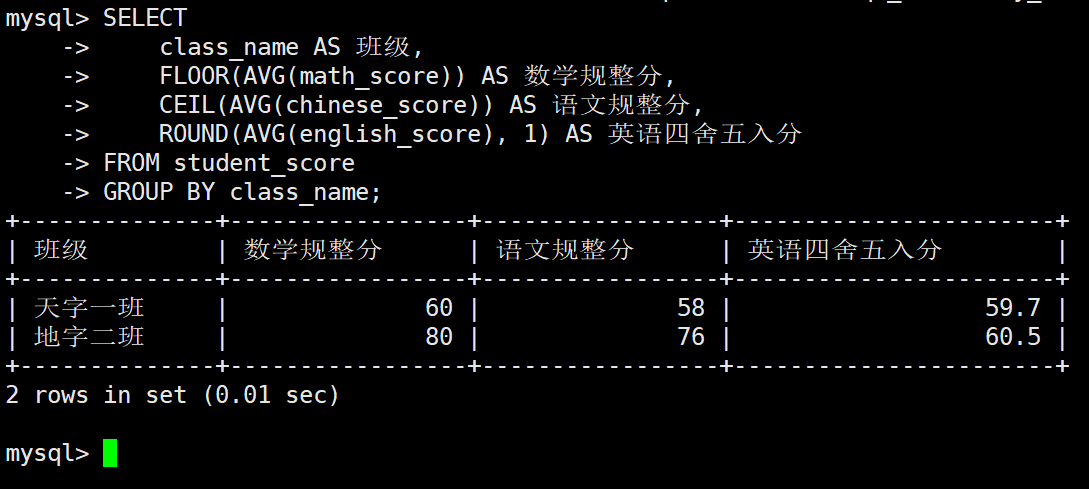
2.2 课堂随机点名
业务场景: 老师在 "天字一班" 讲课时,希望通过系统实现公平的随机抽查点名,每次只需要随机抽取 1 名幸运同学起来回答问题
sql
-- 利用 RAND() 函数动态扰乱排序,再用 LIMIT 截取第一条
SELECT student_no, name
FROM student_score
WHERE class_name = '天字一班'
ORDER BY RAND()
LIMIT 1;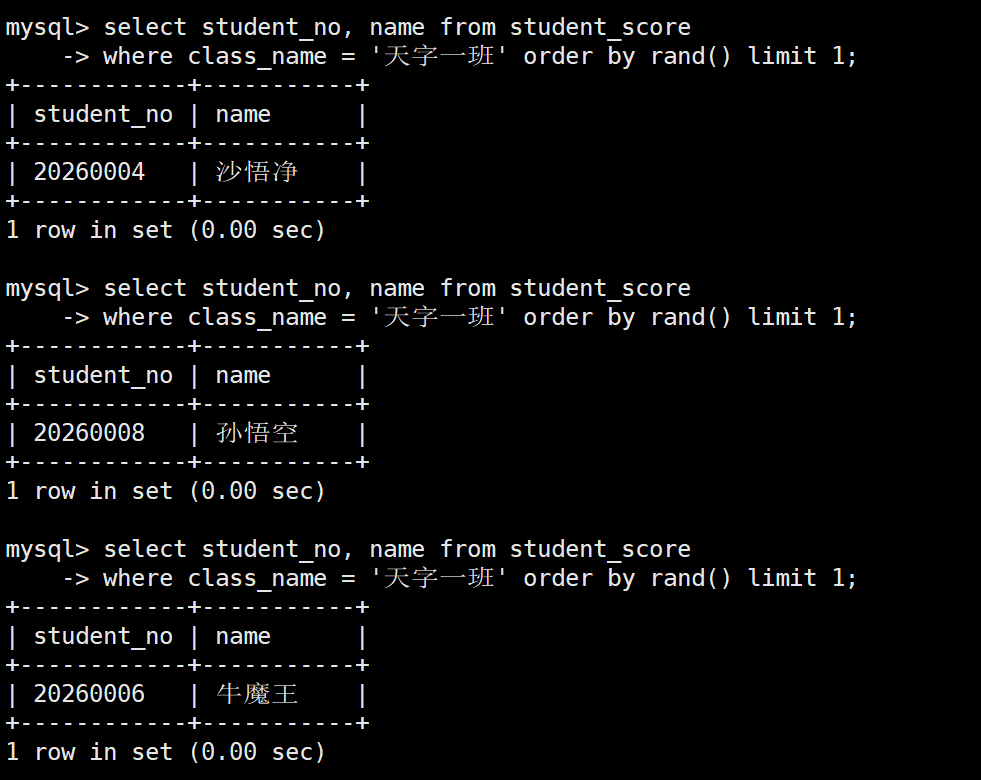
在上述案例中,因为学生表数据量极小,使用 ORDER BY RAND() 非常方便。 但是在生产环境下,如果单表数据量超过 1 万条,强烈禁止使用这种写法
-
致命原因: ORDER BY RAND() 的底层执行机制是:MySQL 会为表里的每一行记录都生成一个临时的随机专属计算值,然后把整张表加载到内存中进行一次全表级别的重新排序。当表里有百万级数据时,这会导致 CPU 直接飙升至 100%,引发数据库瞬间卡死
-
大表随机替代方案: 先在后端代码中通过 MAX(id) 和 MIN(id) 计算出主键范围,随机生成几个目标 id,再通过 WHERE id IN (随机id) 的索引扫描方式精准获取行数据
五、其他常用函数
在前几章中,我们掌握了日期、文本和数值的清洗方法。然而在更复杂的业务场景下,数据还需要具备 "智能转换" 的能力
例如:报表需要根据成绩自动打上 "优秀"、"良好"、"不及格" 的标签;或者当数据为 NULL 时需要提供一个默认备用值。这就需要用到 MySQL 流程控制函数 。同时,为了安全审计,我们也需要掌握获取数据库当前状态的系统信息函数
1. 流程控制函数
流程控制函数赋予了 SQL 语句根据不同条件执行不同分支的能力,相当于把编程语言中的 if-else 或 switch-case 搬到了数据库内部
三元运算符:IF()
- IF(expr1, expr2, expr3): 如果表达式 expr1 的结果为 TRUE(非空非零),则函数返回 expr2 的值;否则返回 expr3 的值
判断空值:IFNULL()
- IFNULL(expr1, expr2): 如果 expr1 的值不为 NULL,则返回 expr1 本身;如果 expr1 的值为 NULL,则返回备用值 expr2。这在规避聚合函数计算陷阱时是绝对的刚需
多分支判断:CASE WHEN
当面临超过两个以上的条件分支时,使用 IF() 会导致嵌套过深。此时应当使用 CASE WHEN 表达式
语法结构
sql
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE default_result
END- 系统会自上而下逐个匹配 WHEN 后面的条件,一旦某个条件成立,立即返回对应的 THEN 结果,并直接跳出整个 CASE 结构;如果所有条件都不满足,则返回 ELSE 后的默认值
2. 系统与环境信息函数
在进行数据库权限管理、编写触发器或执行安全审计时,我们需要随时掌握 "是谁在什么环境下操作数据库"
-
VERSION(): 返回当前 MySQL 服务器的版本号
-
DATABASE(): 返回正在使用的数据库名称(如果没有选择任何数据库,则返回 NULL)
-
USER() : 返回当前连接数据库的真实用户名及主机地址,常用于追踪未授权的外部访问
sql
-- 快速获取当前数据库环境快照
SELECT VERSION() AS 版本, DATABASE() AS 当前库, USER() AS 当前用户;3. 流程控制函数生产级实战案例
下面我们再次回到 学生成绩表,看看流程控制函数是如何在实际教务管理系统中使用的
3.1 解决缺考造成的连锁影响
业务场景: 我们在前面的章节中提到过,小龙女同学因为数学和英语缺考,两科成绩均为 NULL。在计算她的三科总分时:
sql
-- 致命问题:由于 NULL 参与计算,小龙女的总分会直接变成 NULL
SELECT name, (chinese_score + math_score + english_score)
AS 总分 FROM student_score;教务处要求:凡是缺考的科目,在计算总分时一律按 0 分处理,不能让总分变成 NULL
sql
SELECT
name AS 姓名,
chinese_score AS 语文,
IFNULL(math_score, 0.00) AS 数学修正,
IFNULL(english_score, 0.00) AS 英语修正,
(chinese_score + IFNULL(math_score, 0.00) + IFNULL(english_score, 0.00)) AS 修正后总分
FROM student_score;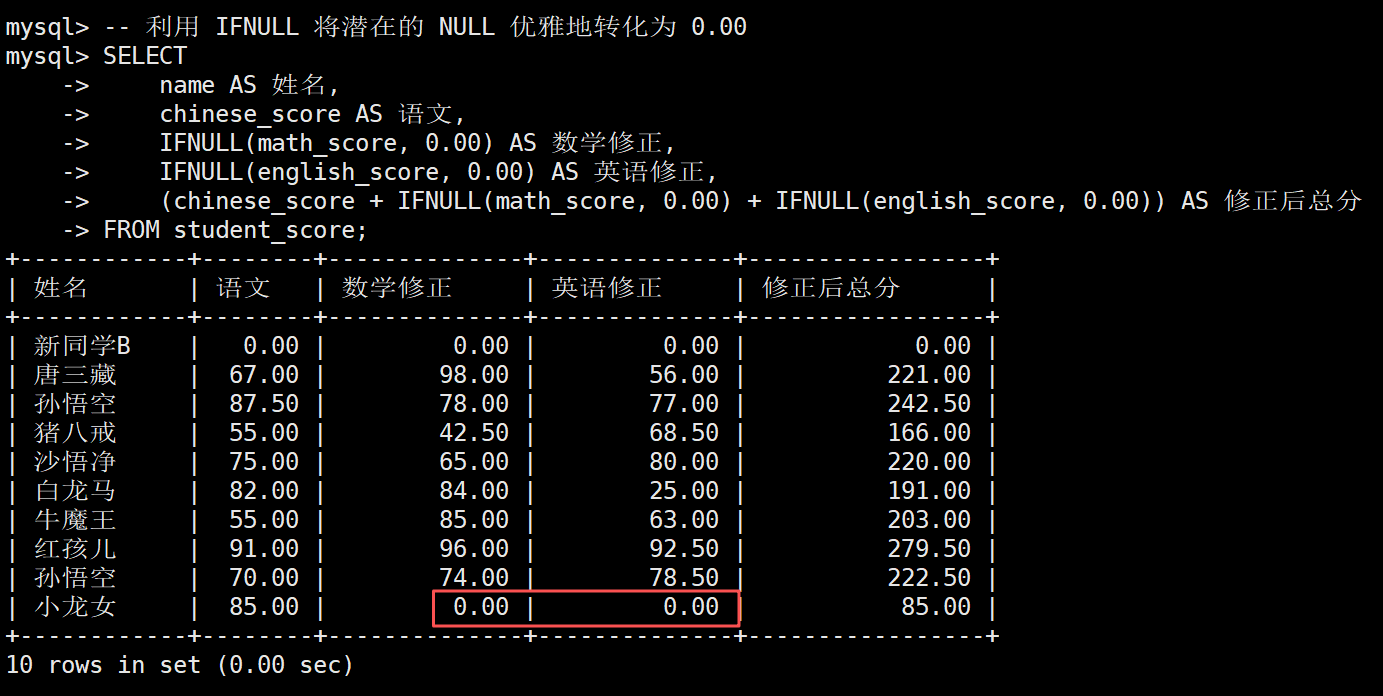
3.2 生成多维度的学生成绩考核报告
业务场景: 期末考试结束,教务处需要输出一份动态的 "成绩等第评估报告"
-
单科考核(以数学为例):大于等于 90 分为 "优秀";大于等于 80 分为 "良好";大于等于 60 分为 "及格";低于 60 分为 "不及格";缺考(NULL)的显示 "需补考"
-
综合状态:只要有任意一门科目低于 60 分(或缺考),该学生的状态就显示为 "需重点关注",否则显示 "正常"
sql
SELECT
student_no AS 学号,
name AS 姓名,
math_score AS 数学原分,
-- 1. 数学多分支等第评定
CASE
WHEN math_score IS NULL THEN '需补考'
WHEN math_score >= 90.00 THEN '优秀'
WHEN math_score >= 80.00 THEN '良好'
WHEN math_score >= 60.00 THEN '及格'
ELSE '不及格'
END AS 数学评价,
-- 2. 跨学科联合条件状态判定
IF(
chinese_score < 60.00
OR IFNULL(math_score, 0) < 60.00
OR IFNULL(english_score, 0) < 60.00,
'需重点关注',
'正常'
) AS 学业状态
FROM student_score;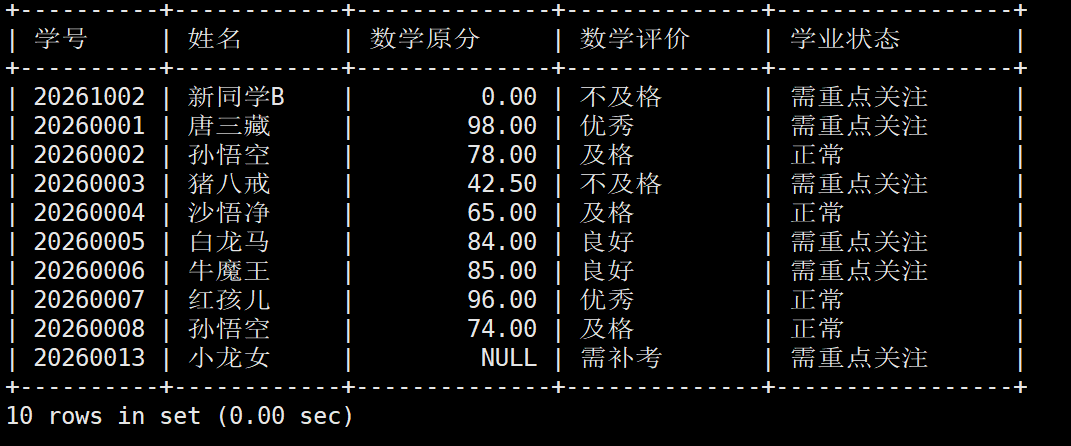
将条件逻辑上移至 MySQL 内部执行后,我们既避免了在后端编写大量 if-else 判断,又能让数据库直接生成具有 "商业智能" 特性的最终报表
实战 OJ:统计字符串中逗号出现次数
**题目要求:**统计 strings 表中每一行 string 字段里逗号 , 出现的次数。
|----|----------------|
| id | string |
| 1 | 10,A,B,C,D |
| 2 | A,B,C,D,E,F |
| 3 | A,11,B,C,D,E,G |
题目示例中 10,A,B 的逗号数为 2,A,B,C,D 的逗号数为 3
**核心思路:**原字符串长度 - 去掉逗号后的字符串长度
SQL:
sql
select
id,
length(string) - length(replace(string, ',', '')) as cnt
from strings;实现分析:
sql
length(string)表示原字符串长度
sql
replace(string, ',', '')表示把字符串中的逗号替换为空字符串
sql
length(string) - length(replace(string, ',', ''))得到的就是被删掉的逗号数量,也就是逗号出现次数
这道题本质考察的是:LENGTH + REPLACE 的使用。属于非常典型的字符串函数实战题
总结
综上所述,我们学习了 MySQL 中常见的内置函数,包括日期时间函数、字符串函数、数学函数以及部分流程控制函数,并结合具体案例体会了这些函数在实际开发中的应用场景
通过这些内置函数,我们可以直接在 SQL 层面对数据进行计算、格式化、转换和处理,大大减少了应用程序中的额外逻辑代码。同时,通过 OJ 实战题的练习,也进一步体会到了多个函数组合使用所带来的强大数据处理能力
不过,随着业务场景越来越复杂,仅仅依靠单表查询往往已经无法满足需求。例如:
查询多个条件组合的数据;对查询结果再次筛选;将多个查询结果合并分析;在一个查询中嵌套另一个查询;
这些都属于更复杂的 SQL 查询场景
因此,在下一篇中,我们将开始学习 MySQL 中的复合查询,包括子查询、联合查询以及多种复杂查询技巧,进一步提升 SQL 的数据分析与处理能力
