报表制作和整形
1、将结果集转置为一行
问题:你想将多行中的值转换为单行中的列。例如,有一个结果集,它显示了每个部门的员工数量。
sql
DEPTNO CNT
------ ----------
10 3
20 5
30 6而你要调整输出的格式,让这个结果集展示如下结果。
sql
DEPTNO_10 DEPTNO_20 DEPTNO_30
--------- ---------- ----------
3 5 6这是一个经典示例,它以不同于存储形状的方式呈现数据。
解决方案:使用 CASE 和聚合函数 SUM 来转置这个结果集。
sql
select sum(case when deptno=10 then 1 else 0 end) as deptno_10,
sum(case when deptno=20 then 1 else 0 end) as deptno_20,
sum(case when deptno=30 then 1 else 0 end) as deptno_30
from emp;
deptno_10 | deptno_20 | deptno_30
-----------+-----------+-----------
3 | 5 | 6
(1 row)2、将结果集转置为多行
问题:通过为给定列中每个不同的值都创建一列,你想将行转换为列,但与上一节的实例不同,你想输出多行。与转置为一行一样,转置为多行也是一种基本的数据整形方法。
例如,你想返回每位员工及其职位(JOB),但当前使用的查询返回的结果集如下所示。
sql
JOB ENAME
--------- ----------
ANALYST SCOTT
ANALYST FORD
CLERK SMITH
CLERK ADAMS
CLERK MILLER
CLERK JAMES
MANAGER JONES
MANAGER CLARK
MANAGER BLAKE
PRESIDENT KING
SALESMAN ALLEN
SALESMAN MARTIN
SALESMAN TURNER
SALESMAN WARD你想调整结果集的格式,让每种职位各为一列。
sql
CLERKS ANALYSTS MGRS PREZ SALES
------ -------- ----- ---- ------
MILLER FORD CLARK KING TURNER
JAMES SCOTT BLAKE MARTIN
ADAMS JONES WARD
SMITH ALLEN不同于上一节的实例,本实例的结果集包含多行。上一节介绍的方法对本实例不管用,因为按 JOB 分组并使用MAX(ENAME) 时,将为每个 JOB 都返回一个 ENAME,即像上一节的实例一样,将只返回一行。要解决这个问题,必须让每个 JOB/ENAME 组合都是独一无二的。这样使用聚合函数来删除 NULL 时,就不会丢失任何 ENAME了。
使用排名函数 ROW_NUMBER OVER 让每个 JOB/ENAME组合都是独一无二的。使用 CASE 表达式和聚合函数MAX 对结果集进行转置,并按窗口函数 ROW_NUMBEROVER 返回的值分组。
sql
select max(case when job='CLERK'
then ename else null end) as clerks,
max(case when job='ANALYST'
then ename else null end) as analysts,
max(case when job='MANAGER'
then ename else null end) as mgrs,
max(case when job='PRESIDENT'
then ename else null end) as prez,
max(case when job='SALESMAN'
then ename else null end) as sales
from (
select job,
ename,
row_number()over(partition by job order by ename) rn
from emp
) x
group by rn;
clerks | analysts | mgrs | prez | sales
--------+----------+-------+------+--------
MILLER | | JONES | | TURNER
SMITH | | | | WARD
JAMES | SCOTT | CLARK | | MARTIN
ADAMS | FORD | BLAKE | KING | ALLEN
(4 rows)首先,借助窗口函数 ROW_NUMBER OVER 让每一个JOB/ENAME 组合都是独一无二的。
sql
select job,
ename,
row_number()over(partition by job order by ename) rn
from emp
JOB ENAME RN
--------- ---------- ----------
ANALYST FORD 1
ANALYST SCOTT 2
CLERK ADAMS 1
CLERK JAMES 2
CLERK MILLER 3
CLERK SMITH 4
MANAGER BLAKE 1
MANAGER CLARK 2
MANAGER JONES 3
PRESIDENT KING 1
SALESMAN ALLEN 1
SALESMAN MARTIN 2
SALESMAN TURNER 3
SALESMAN WARD 4通过给每一个 ENAME 指定一个在当前职位中独一无二的"行号",可以防范因两位员工具有相同名字和职位而带来的问题。这里的目标是,确保在按行号(RN)分组的情况下,使用 MAX 不会导致结果集中的任何员工丢失。解决这个问题时,这是最重要的步骤。如果没有这一步,外部查询中的聚合就会删除原本要返回的行。
3、对结果集进行逆转置
问题:你想将列转换为行。请看下面的结果集:
sql
DEPTNO_10 DEPTNO_20 DEPTNO_30
---------- ---------- ----------
3 5 6你想将它转换成下面这样。
sql
DEPTNO COUNTS_BY_DEPT
------ --------------
10 3
20 5
30 6你可能注意到了,上面的第一个结果集就是 12.1 节实例的输出。为了在本实例中使用这个结果集,可以使用如下查询将其存储在视图中。
sql
create view emp_cnts as (
select sum(case when deptno=10 then 1 else 0 end) as deptno_10,
sum(case when deptno=20 then 1 else 0 end) as deptno_20,
sum(case when deptno=30 then 1 else 0 end) as deptno_30
from emp
);在接下来的解决方案和讨论中,将引用这个查询创建的视图 EMP_CNTS。
解决方案:从要获得的结果集很容易看出,可以对 EMP 表使用COUNT 和 GROUP BY 来生成它。但这里假设数据并不是以行的方式存储的:数据可能是非规范化的,而聚合值存储在多列中。
要将列转换为行,可以使用笛卡儿积。我们需要事先知道要转换为行的列数,因为用来生成笛卡儿积的表表达式的基数不能小于要转置的列数。
本解决方案不会创建非规范化数据表,而会使用 11 节实例中的解决方案来创建一个"宽"结果集。完整的解决方案如下所示。
sql
select dept.deptno,
case dept.deptno
when 10 then emp_cnts.deptno_10
when 20 then emp_cnts.deptno_20
when 30 then emp_cnts.deptno_30
end as counts_by_dept
from emp_cnts cross join (
select deptno
from dept
where deptno <= 30) dept;4、将结果集逆转置为一列
问题:你想将查询返回的所有列值都放在一列中,并返回它们。例如,你想返回 10 号部门所有员工的 ENAME、JOB 和SAL,并想将这 3 个值放在一列中。为此,你要为每位员工返回 3 行,并在员工之间添加一个空白行。你想返回的结果集如下所示。
sql
EMPS
----------
CLARK
MANAGER
2450
KING
PRESIDENT
5000
MILLER
CLERK
1300解决方案:关键是结合使用递归 CTE 和笛卡儿积来为每位员工返回4 行数据。使用笛卡儿连接,可以在每一行中返回一个列值,并在员工之间添加空白行。
使用窗口函数 ROW_NUMBER OVER 根据 EMPNO 给行排名(1~4),然后使用 CASE 表达式将 3 列转换为 1 列(在 PostgreSQL 和 MySQL 中,必须在 WITH 后面添加关键字 RECURSIVE)。
sql
with four_rows (id)
as
(
select 1
union all
select id+1
from four_rows
where id < 4
)
,
x_tab (ename,job,sal,rn )
as
(
ect e.ename,e.job,e.sal,
row_number()over(partition by e.empno
order by e.empno)
from emp e
join four_rows on 1=1
)
select
case rn
when 1 then ename
when 2 then job
when 3 then cast(sal as char(4))
end emps
from x_tab;5、消除结果集中的重复值
问题:你正在制作一张报表,当多行的同一列的值相同时,你希望这个列值只显示一次。例如,你想从 EMP 表返回DEPTNO 和 ENAME 并按 DEPTNO 分组,但对于每个DEPTNO,只想显示一次。你想返回如下结果集。
sql
DEPTNO ENAME
------ ---------
10 CLARK
KING
MILLER
20 SMITH
ADAMS
FORD
SCOTT
JONES
30 ALLEN
BLAKE
MARTIN
JAMES
TURNER
WARD解决方案:这是一个简单的格式设置问题,使用窗口函数 LAG OVER可以轻而易举地解决。
sql
select
case when lag(deptno)over(order by deptno) = deptno then null
else deptno
end DEPTNO, ename
from emp;
deptno | ename
--------+--------
10 | MILLER
| CLARK
| KING
20 | SCOTT
| JONES
| SMITH
| ADAMS
| FORD
30 | WARD
| TURNER
| ALLEN
| BLAKE
| MARTIN
| JAMES
(14 rows)Oracle 用户也可以用 DECODE 替代 CASE。
sql
select to_number(
decode(lag(deptno)over(order by deptno),
deptno,null,deptno)
) deptno, ename
from emp;6、转置结果集以简化涉及多行的计算
问题:你要执行的计算涉及来自多行的数据,为简化工作,你想将这些行转置为列,这样你需要的所有数据都会出现在同一行中。
薪水总额最高的部门是 20 号部门。要确认这一点,可以执行下面的查询。
sql
select deptno, sum(sal) as sal
from emp
group by deptno
DEPTNO SAL
------ ----------
10 8750
20 10875
30 9400你想计算 10 号部门的薪水总额和 30 号部门的薪水总额分别比 20 号部门的薪水总额少多少,最终结果如下所示。
sql
d20_10_diff d20_30_diff
------------ ----------
2125 1475解决方案:使用聚合函数 SUM 和 CASE 表达式对部门薪水总额进行转置,然后在 SELECT 列表中编写计算薪水总额之差的表达式。
sql
select d20_sal - d10_sal as d20_10_diff,
d20_sal - d30_sal as d20_30_diff
from (
select sum(case when deptno=10 then sal end) as d10_sal,
sum(case when deptno=20 then sal end) as d20_sal,
sum(case when deptno=30 then sal end) as d30_sal
from emp
) totals_by_dept;
d20_10_diff | d20_30_diff
-------------+-------------
2125 | 1475
(1 row)也可以使用 CTE 来编写这个查询,有些人可能觉得这样做可读性更高。
sql
with totals_by_dept (d10_sal, d20_sal, d30_sal) as (
select
sum(case when deptno=10 then sal end) as d10_sal,
sum(case when deptno=20 then sal end) as d20_sal,
sum(case when deptno=30 then sal end) as d30_sal
from emp
)
select d20_sal - d10_sal as d20_10_diff,
d20_sal - d30_sal as d20_30_diff
from totals_by_dept;7、创建尺寸固定的数据桶
问题:你想将数据划分到大小相同的桶中,其中每个桶包含的元素个数是事先定好的。总桶数可能未知,但你要确保每个桶中都包含 5 个元素。例如,你想基于 EMPNO 值将 EMP表中的员工分组,每组包含 5 位员工,如下面的结果所示。
sql
GRP EMPNO ENAME
--- ---------- -------
1 7369 SMITH
1 7499 ALLEN
1 7521 WARD
1 7566 JONES
1 7654 MARTIN
2 7698 BLAKE
2 7782 CLARK
2 7788 SCOTT
2 7839 KING
2 7844 TURNER
3 7876 ADAMS
3 7900 JAMES
3 7902 FORD
3 7934 MILLER解决方案:使用排名函数可以极大地简化这个问题的解决方案。将行排名后,要创建大小为 5 的桶,只需执行除法运算并将商向上取整。
使用窗口函数根据 EMPNO 对员工进行排名,然后除以 5以创建分组。(如果你使用的是 SQL Server,请将CEIL 替换为 CEILING。)
sql
select ceil(row_number()over(order by empno)/5.0) grp,
empno,
ename
from emp;
grp | empno | ename
-----+-------+--------
1 | 7369 | SMITH
1 | 7499 | ALLEN
1 | 7521 | WARD
1 | 7566 | JONES
1 | 7654 | MARTIN
2 | 7698 | BLAKE
2 | 7782 | CLARK
2 | 7788 | SCOTT
2 | 7839 | KING
2 | 7844 | TURNER
3 | 7876 | ADAMS
3 | 7900 | JAMES
3 | 7902 | FORD
3 | 7934 | MILLER
(14 rows)8、创建预定数量的桶
问题:你想将数据划分到数量固定的几个桶中。例如,你想将EMP 表中的员工划分到 4 个桶中,结果如下所示。
sql
GRP EMPNO ENAME
--- ----- ---------
1 7369 SMITH
1 7499 ALLEN
1 7521 WARD
1 7566 JONES
2 7654 MARTIN
2 7698 BLAKE
2 7782 CLARK
2 7788 SCOTT
3 7839 KING
3 7844 TURNER
3 7876 ADAMS
4 7900 JAMES
4 7902 FORD
4 7934 MILLER这是一种组织分类数据的常见方式,因为在很多分析中,将一个集合分成多个规模相同的集合是重要的第一步。例如,通过计算这些分组的平均薪水或其他平均值,或许能够揭示查看各个值时被波动掩盖的趋势。
这个问题与 7 节的问题相反。在 7 节中,桶的数量是未知的,但每个桶包含的元素个数是事先定好的,而在这个问题中,可能不知道每个桶中有多少个元素,但要创建的桶的个数是固定(已知)的。
解决方案:由于现在很多 RDBMS 支持函数 NTILE,因此这个问题的解决方案很简单。NTILE 会将一个有序集合划分到指定数量的桶中。如果集合元素无法均分,就将多出来的元素放到前面的桶中,本实例要返回的结果集反映了这一点:第 1 个桶和第 2 个桶分别有 4 行数据,而第 3 个桶和第 4 个桶分别只有 3 行数据。
使用窗口函数 NTILE 创建 4 个桶。
sql
select
ntile(4)over(order by empno) grp,
empno,
ename
from emp;
grp | empno | ename
-----+-------+--------
1 | 7369 | SMITH
1 | 7499 | ALLEN
1 | 7521 | WARD
1 | 7566 | JONES
2 | 7654 | MARTIN
2 | 7698 | BLAKE
2 | 7782 | CLARK
2 | 7788 | SCOTT
3 | 7839 | KING
3 | 7844 | TURNER
3 | 7876 | ADAMS
4 | 7900 | JAMES
4 | 7902 | FORD
4 | 7934 | MILLER
(14 rows)9、创建水平直方图
问题:你想使用 SQL 来创建沿水平方向延伸的直方图。例如,你想以水平直方图的方式显示每个部门的员工数量,在直方图中每个星号(*)表示一位员工。你想返回的结果集如下所示。
sql
DEPTNO CNT
------ ----------
10 ***
20 *****
30 ******解决方案:本解决方案的关键是,使用聚合函数 COUNT 和 GROUPBY DEPTNO 来计算每个部门的员工数量。然后,将COUNT 返回的值传递给一个字符串函数,以生成相应数量的 * 字符。
DB2:使用函数 REPEAT 生成直方图。
sql
select deptno,
repeat('*',count(*)) cnt
from emp
group by deptno;Oracle、PostgreSQL 和 MySQL:使用函数 LPAD 生成相应数量的 * 字符。
sql
select deptno,lpad('*',count(*),'*') as cnt
from emp
group by deptno;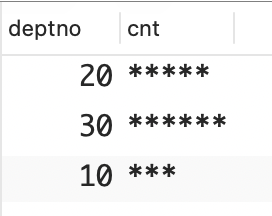
SQL Server:使用函数 REPLICATE 生成直方图。
sql
select deptno,replicate('*',count(*)) cnt
from emp
group by deptno;10、创建垂直直方图
问题:你想生成一个从下往上延伸的直方图。例如,你想以垂直直方图的方式显示每个部门的员工数量,每位员工用一个* 字符表示。你想返回的结果集如下所示。
sql
D10 D20 D30
--- --- ---
*
* *
* *
* * *
* * *
* * *解决方案:这个问题的解决方案以本章前面使用的一种方案为基础:使用函数 ROW_NUMBER OVER 来唯一地表示每个部门的每位员工。使用聚合函数 MAX 来转置结果集,并根据函数 ROW_NUMBER OVER 返回的值进行分组。(如果你使用的是 SQL Server,请不要在 ORDER BY 子句中使用DESC。)
sql
select max(deptno_10) d10,
max(deptno_20) d20,
max(deptno_30) d30
from (
select row_number()over(partition by deptno order by empno) rn,
case when deptno=10 then '*' else null end deptno_10,
case when deptno=20 then '*' else null end deptno_20,
case when deptno=30 then '*' else null end deptno_30
from emp
) x
group by rn
order by 1 desc, 2 desc, 3 desc;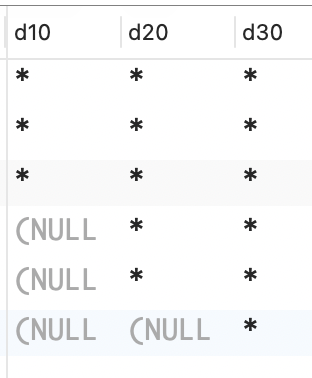
11、返回未被用作分组依据的列
问题:你正在编写一个 GROUP BY 查询,并要返回未包含在GROUP BY 子句中的列。这通常是不可能的,因为未被用作分组依据的列在各行中不是唯一的。
假设你想找出每个部门中薪水最高和薪水最低的员工,以及每个职位中薪水最高和薪水最低的员工。你要显示每位员工的名字、所属部门、职位和薪水。你想返回的结果集如下所示。
sql
DEPTNO ENAME JOB SAL DEPT_STATUS JOB_STATUS
------ ------ --------- ----- --------------- --------------
10 MILLER CLERK 1300 LOW SAL IN DEPT TOP SAL IN JOB
10 CLARK MANAGER 2450 LOW SAL IN JOB
10 KING PRESIDENT 5000 TOP SAL IN DEPT TOP SAL IN JOB
20 SCOTT ANALYST 3000 TOP SAL IN DEPT TOP SAL IN JOB
20 FORD ANALYST 3000 TOP SAL IN DEPT TOP SAL IN JOB
20 SMITH CLERK 800 LOW SAL IN DEPT LOW SAL IN JOB
20 JONES MANAGER 2975 TOP SAL IN JOB
30 JAMES CLERK 950 LOW SAL IN DEPT
30 MARTIN SALESMAN 1250 LOW SAL IN JOB
30 WARD SALESMAN 1250 LOW SAL IN JOB
30 ALLEN SALESMAN 1600 TOP SAL IN JOB
30 BLAKE MANAGER 2850 TOP SAL IN DEPT可惜在 SELECT 子句中包含所有这些列将影响分组。来看一个例子。员工 KING 的薪水最高,你想使用下面的查询来验证这一点。
sql
select ename,max(sal)
from empgroup by ename这个查询将返回 EMP 表中的全部 14 行数据,而不是员工KING 及其薪水。问题出在分组上:MAX(SAL) 被应用于每个 ENAME。上述查询的意思好像是找出薪水最高的员工,但它实际上做的是找出 EMP 表中每位员工的最高薪水。本实例将介绍如何在 GROUP BY 子句中不包含ENAME 列的情况下返回它。
解决方案:使用内嵌视图找出相应部门和职位的最高薪水和最低薪水,然后只保留获得这些薪水的员工。
使用窗口函数 MAX OVER 和 MIN OVER 找出相应部门和职位的最高薪水和最低薪水,然后保留薪水为相应部门或职位的最高薪水或最低薪水的行。
sql
select deptno,ename,job,sal,
case when sal = max_by_dept
then 'TOP SAL IN DEPT'
when sal = min_by_dept
then 'LOW SAL IN DEPT'
end dept_status,
case when sal = max_by_job
then 'TOP SAL IN JOB'
when sal = min_by_job
then 'LOW SAL IN JOB'
end job_status
from (
select deptno,ename,job,sal,
max(sal)over(partition by deptno) max_by_dept,
max(sal)over(partition by job) max_by_job,
min(sal)over(partition by deptno) min_by_dept,
min(sal)over(partition by job) min_by_job
from emp
) emp_sals
where sal in (max_by_dept,max_by_job,
min_by_dept,min_by_job);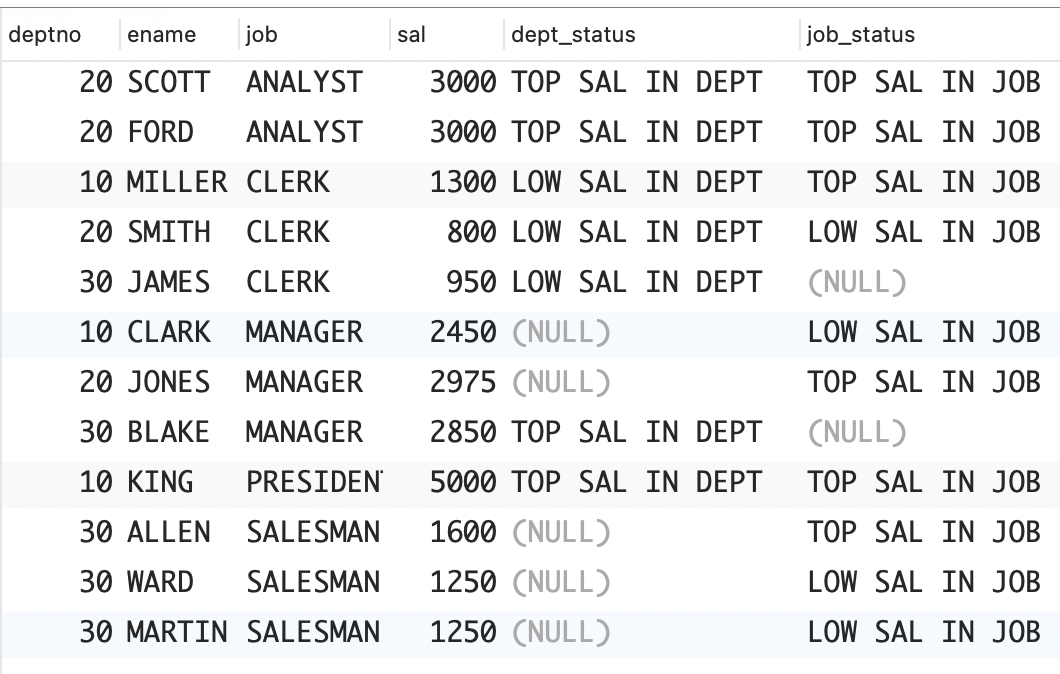
12、计算简单的小计
问题:在本实例中,你想创建一个结果集,其中包含小计(聚合分组的特定列)和总计(聚合整张表的特定列)。一个这样的结果集既包含 EMP 表中每种职位的薪水总额,也包含 EMP 表中所有薪水的总额,其中每种职位的薪水总额为小计,所有薪水的总额为总计。这种结果集如下所示。
sql
JOB SAL
--------- ----------
ANALYST 6000
CLERK 4150
MANAGER 8275
PRESIDENT 5000
SALESMAN 5600
TOTAL 29025解决方案:GROUP BY 子句的 ROLLUP 扩展完美地解决了这个问题。如果你使用的 RDBMS 不支持 ROLLUP,则可以使用标量子查询或 UNION 查询来解决这个问题,只是难度更大。
DB2 和 Oracle:使用聚合函数 SUM 计算薪水总额,并使用 GROUP BY 的ROLLUP 扩展将结果组织为小计(针对不同职位)和总计(针对整张表)。
sql
select case grouping(job)
when 0 then job
else 'TOTAL'
end job,
sum(sal) sal
from emp
group by rollup(job);SQL Server 和 MySQL:首先,使用聚合函数 SUM 计算薪水总额,并使用 WITHROLLUP 将结果组织为小计(针对不同职位)和总计(针对整张表)。然后,使用 COALESCE 给总计行提供标签TOTAL。(如果不这样做,该行的 JOB 列将为NULL。)
sql
select coalesce(job,'TOTAL') job,sum(sal) sal
from emp
group by job with rollup;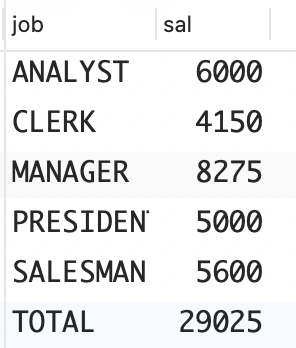
在 SQL Server 中,也可以像 Oracle/DB2 解决方案那样使用函数 GROUPING(而不是函数 COALESCE)来确定 聚合等级。
PostgreSQL:与 SQL Server 和 MySQL 解决方案类似,也可以使用GROUP BY 的 ROLLUP 扩展,但语法稍有不同。
sql
select coalesce(job,'TOTAL') job, sum(sal) sal
from emp
group by rollup(job);
job | sal
-----------+-------
TOTAL | 29025
CLERK | 4150
PRESIDENT | 5000
MANAGER | 8275
SALESMAN | 5600
ANALYST | 6000
(6 rows)13、计算各种可能的小计
问题:你想找出不同部门、职位、职位 / 部门组合的薪水小计,同时显示整个 EMP 表的薪水总计。换言之,你想返回如下结果集。
sql
DEPTNO JOB CATEGORY SAL
------ --------- --------------------- -------
10 CLERK TOTAL BY DEPT AND JOB 1300
10 MANAGER TOTAL BY DEPT AND JOB 2450
10 PRESIDENT TOTAL BY DEPT AND JOB 5000
20 CLERK TOTAL BY DEPT AND JOB 1900
30 CLERK TOTAL BY DEPT AND JOB 950
30 SALESMAN TOTAL BY DEPT AND JOB 5600
30 MANAGER TOTAL BY DEPT AND JOB 2850
20 MANAGER TOTAL BY DEPT AND JOB 2975
20 ANALYST TOTAL BY DEPT AND JOB 6000
CLERK TOTAL BY JOB 4150
ANALYST TOTAL BY JOB 6000
MANAGER TOTAL BY JOB 8275
PRESIDENT TOTAL BY JOB 5000
SALESMAN TOTAL BY JOB 5600
10 TOTAL BY DEPT 8750
30 TOTAL BY DEPT 9400
20 TOTAL BY DEPT 10875
GRAND TOTAL FOR TABLE 29025解决方案:最近几年,对于 GROUP BY 语法的扩展使得以上问题解决起来易如反掌。如果你使用的 RDBMS 没有提供计算各种小计的扩展,就必须手动计算它们,为此可以使用自连接或标量子查询。
DB2:在 DB2 中,需要使用 CAST 将 GROUPING 返回的结果转换为数据类型 CHAR(1)。
sql
select deptno,
job,
case cast(grouping(deptno) as char(1))||
cast(grouping(job) as char(1))
when '00' then 'TOTAL BY DEPT AND JOB'
when '10' then 'TOTAL BY JOB'
when '01' then 'TOTAL BY DEPT'
when '11' then 'TOTAL FOR TABLE'
end category,
sum(sal)
from emp
group by cube(deptno,job)
order by grouping(job),grouping(deptno);Oracle:结合使用 GROUP BY 子句的 CUBE 扩展和拼接运算符||。
sql
select deptno,
job,
case grouping(deptno)||grouping(job)
when '00' then 'TOTAL BY DEPT AND JOB'
when '10' then 'TOTAL BY JOB'
when '01' then 'TOTAL BY DEPT'
when '11' then 'GRAND TOTALFOR TABLE'
end category,
sum(sal) sal
from emp
group by cube(deptno,job)
order by grouping(job),grouping(deptno);SQL Server:使用 GROUP BY 子句的 CUBE 扩展。在 SQL Server中,需要使用 CAST 将 GROUPING 返回的结果转换为数据类型 CHAR(1),并使用拼接运算符 +(而不像在 Oracle 中那样使用运算符 ||)。
sql
select deptno,
job,
case cast(grouping(deptno)as char(1))+
cast(grouping(job)as char(1))
when '00' then 'TOTAL BY DEPT AND JOB'
when '10' then 'TOTAL BY JOB'
when '01' then 'TOTAL BY DEPT'
when '11' then 'GRAND TOTAL FOR TABLE'
end category,
sum(sal) sal
from emp
group by deptno,job with cube
order by grouping(job),grouping(deptno);PostgreSQL:PostgreSQL 解决方案与 SQL Server 解决方案类似,但CUBE 扩展和拼接运算符的语法稍有不同。
sql
select deptno,job ,
case concat(
cast (grouping(deptno) as char(1)),
cast (grouping(job) as char(1)))
when '00' then 'TOTAL BY DEPT AND JOB'
when '10' then 'TOTAL BY JOB'
when '01' then 'TOTAL BY DEPT'
when '11' then 'GRAND TOTAL FOR TABLE'
end category,
sum(sal) as sal
from emp
group by cube(deptno,job);
deptno | job | category | sal
--------+-----------+-----------------------+-------
| | GRAND TOTAL FOR TABLE | 29025
20 | CLERK | TOTAL BY DEPT AND JOB | 1900
30 | MANAGER | TOTAL BY DEPT AND JOB | 2850
10 | MANAGER | TOTAL BY DEPT AND JOB | 2450
10 | PRESIDENT | TOTAL BY DEPT AND JOB | 5000
20 | ANALYST | TOTAL BY DEPT AND JOB | 6000
30 | SALESMAN | TOTAL BY DEPT AND JOB | 5600
10 | CLERK | TOTAL BY DEPT AND JOB | 1300
20 | MANAGER | TOTAL BY DEPT AND JOB | 2975
30 | CLERK | TOTAL BY DEPT AND JOB | 950
30 | | TOTAL BY DEPT | 9400
10 | | TOTAL BY DEPT | 8750
20 | | TOTAL BY DEPT | 10875
| CLERK | TOTAL BY JOB | 4150
| PRESIDENT | TOTAL BY JOB | 5000
| MANAGER | TOTAL BY JOB | 8275
| SALESMAN | TOTAL BY JOB | 5600
| ANALYST | TOTAL BY JOB | 6000
(18 rows)MySQL:MySQL 只提供了前述解决方案使用的部分功能,准确地说是没有提供函数 CUBE。因此,在 MySQL 中,需要使用多个 UNION ALL 来生成各种可能的小计。
sql
select deptno, job,
'TOTAL BY DEPT AND JOB' as category,
sum(sal) as sal
from emp
group by deptno, job
union all
select null, job, 'TOTAL BY JOB', sum(sal)
from emp
group by job
union all
select deptno, null, 'TOTAL BY DEPT', sum(sal)
from emp
group by deptno
union all
select null,null,'GRAND TOTAL FOR TABLE', sum(sal)
from emp;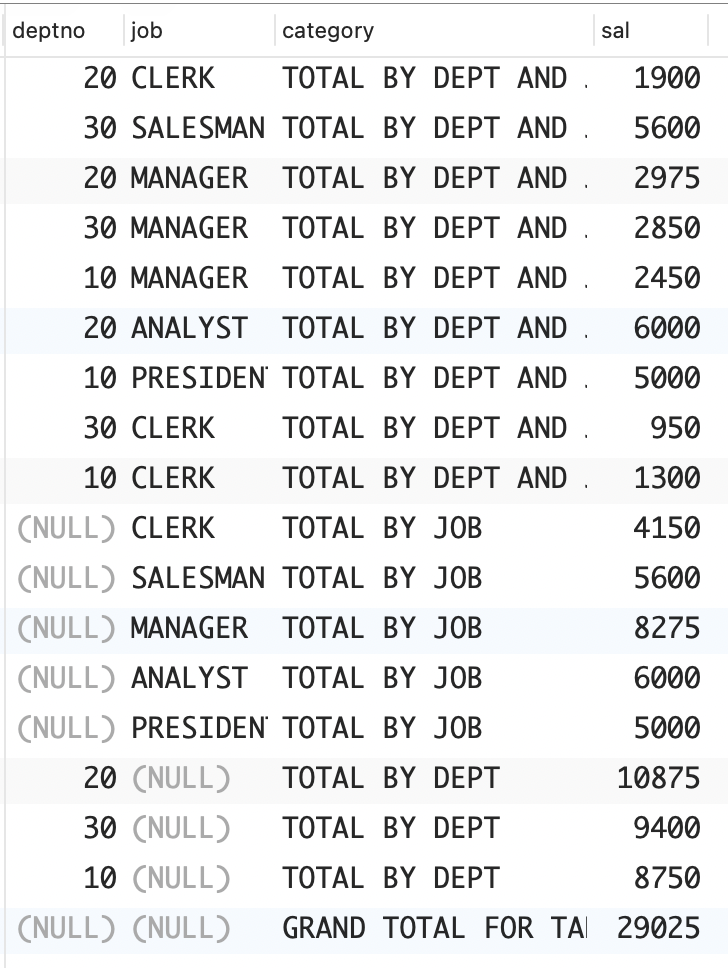
14、标出非小计行
问题:在使用 GROUP BY 子句的 CUBE 扩展生成的报表中,你想将 GROUP BY 子句生成的行同 CUBE 或 ROLLUP 生成的行区分开。
下面的结果集是使用 GROUP BY 子句的 CUBE 扩展生成的,其显示了 EMP 表中的薪水分布情况。
sql
DEPTNO JOB SAL
------ --------- -------
29025
CLERK 4150
ANALYST 6000
MANAGER 8275
SALESMAN 5600
PRESIDENT 5000
10 8750
10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
20 10875
20 CLERK 1900
20 ANALYST 6000
20 MANAGER 2975
30 9400
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600这张报表包含不同 DEPTNO 和 JOB 组合的薪水小计,不同 DEPTNO 的薪水小计,不同 JOB 的薪水小计以及整个EMP 表的薪水总计,而你想清晰地指出不同的聚合等级。换言之,你想标出各个聚合值所属的类别,即 SAL 列值表示的是不同 DEPTNO 的小计,不同 JOB 的小计,还是总计?你希望返回的结果集如下所示。
sql
DEPTNO JOB SAL DEPTNO_SUBTOTALS JOB_SUBTOTALS
------ --------- ------- ---------------- -------------
29025 1 1
CLERK 4150 1 0
ANALYST 6000 1 0
MANAGER 8275 1 0
SALESMAN 5600 1 0
PRESIDENT 5000 1 0
10 8750 0 1
10 CLERK 1300 0 0
10 MANAGER 2450 0 0
10 PRESIDENT 5000 0 0
20 10875 0 1
20 CLERK 1900 0 0
20 ANALYST 6000 0 0
20 MANAGER 2975 0 0
30 9400 0 1
30 CLERK 950 0 0
30 MANAGER 2850 0 0
30 SALESMAN 5600 0 0解决方案:使用函数 GROUPING 来指出哪些值是 CUBE 或 ROLLUP生成的小计(超级聚合值)。下面的解决方案适用于PostgreSQL、DB2 和 Oracle。
sql
select deptno, jo) sal,
grouping(deptno) deptno_subtotals,
grouping(job) job_subtotals
from emp
group by cube(deptno,job);与 DB2 和 Oracle 解决方案相比,SQL Server 解决方案的唯一不同之处是 CUBE/ROLLUP 子句的书写方式。
sql
select deptno, job, sum(sal) sal,
grouping(deptno) deptno_subtotals,
grouping(job) job_subtotals
from emp
group by deptno,job with cube;15、使用CASE表达式来标识行
问题:你想将特定列(比如 EMP 表中的 JOB 列)的值转换为"布尔"标志。例如,你想返回如下结果集。
sql
ENAME IS_CLERK IS_SALES IS_MGR IS_ANALYST IS_PREZ
------ -------- -------- ------ ---------- -------
KING 0 0 0 0 1
SCOTT 0 0 0 1 0
FORD 0 0 0 1 0
JONES 0 0 1 0 0
BLAKE 0 0 1 0 0
CLARK 0 0 1 0 0
ALLEN 0 1 0 0 0
WARD 0 1 0 0 0
MARTIN 0 1 0 0 0
TURNER 0 1 0 0 0
SMITH 1 0 0 0 0
MILLER 1 0 0 0 0
ADAMS 1 0 0 0 0
JAMES 1 0 0 0 0这样的结果集很有用,不仅可以帮助调试,还可以提供不同于典型结果集的数据视图。
解决方案:使用 CASE 表达式来评估每位员工的 JOB,并返回 1 或0,以指出员工的职位。对于每种可能的职位,都需要编写一个 CASE 表达式,以生成相应的列值。
sql
select ename,
case when job = 'CLERK'
then 1 else 0
end as is_clerk,
case when job = 'SALESMAN'
then 1 else 0
end as is_sales,
case when job = 'MANAGER'
then 1 else 0
end as is_mgr,
case when job = 'ANALYST'
then 1 else 0
end as is_analyst,
case when job = 'PRESIDENT'
then 1 else 0
end as is_prez
from emp
order by 2,3,4,5,6;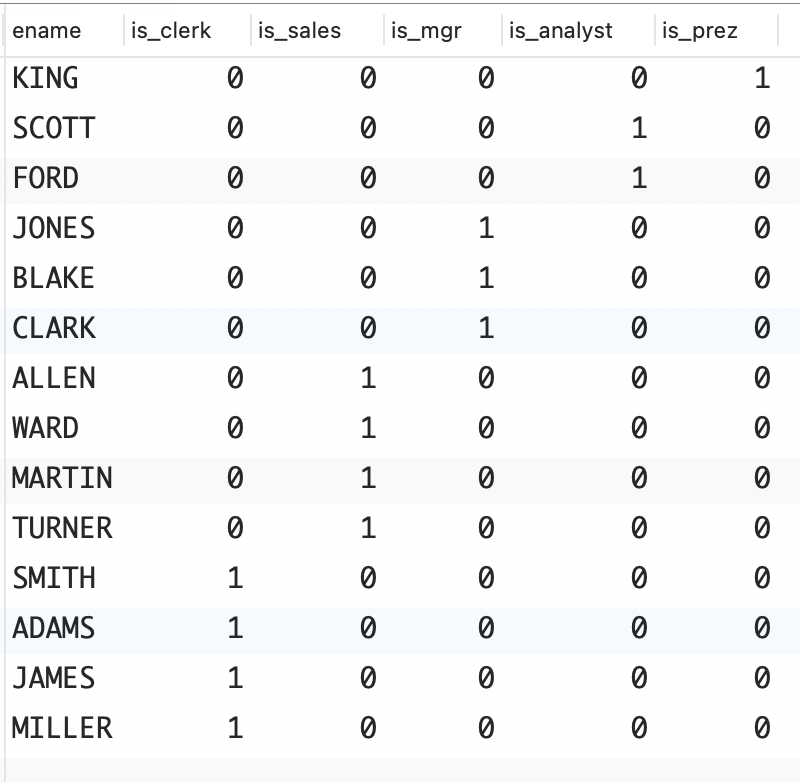
16、创建稀疏矩阵
问题:你想创建一个稀疏矩阵,比如下面这个对 EMP 表中DEPTNO 列和 JOB 列进行转置而得到的稀疏矩阵。
sql
D10 D20 D30 CLERKS MGRS PREZ ANALS SALES
---------- ---------- ---------- ------ ----- ---- ----- ------
SMITH SMITH
ALLEN ALLEN
WARD WARD
JONES JONES
MARTIN MARTIN
BLAKE BLAKE
CLARK CLARK
SCOTT SCOTT
KING KING
TURNER TURNER
ADAMS ADAMS
JAMES JAMES
FORD FORD
MILLER MILLER解决方案:使用 CASE 表达式来创建稀疏的行列转换结果。
sql
select case deptno when 10 then ename end as d10,
case deptno when 20 then ename end as d20,
case deptno when 30 then ename end as d30,
case job when 'CLERK' then ename end as clerks,
case job when 'MANAGER' then ename end as mgrs,
case job when 'PRESIDENT' then ename end as prez,
case job when 'ANALYST' then ename end as anals,
case job when 'SALESMAN' then ename end as sales
from emp;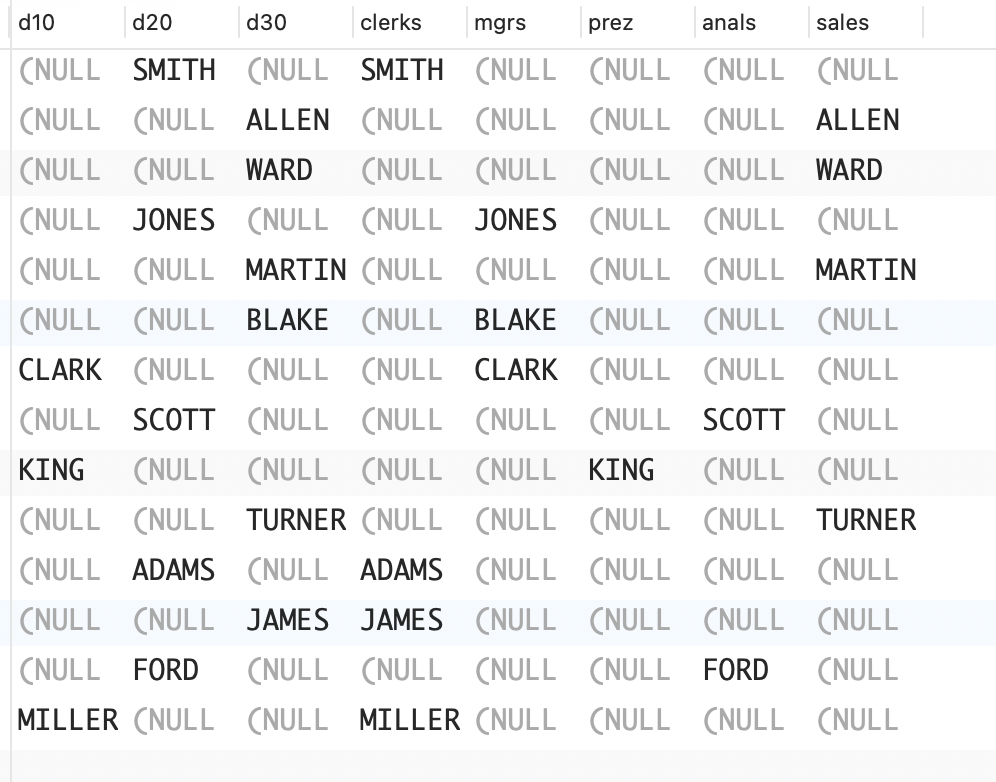
17、按时间分组
问题:你想按时段汇总数据。例如,你有一个交易日志,你想以5 秒为间隔对交易数据进行分组和汇总。TRX_LOG 表包含的数据行如下所示。
sql
create table trx_log(
TRX_ID INTEGER,
TRX_DATE DATE,
TRX_CNT INTEGER
);
insert into trx_log values
(1, '28-JUL-2020 19:03:07',44),
(2, '28-JUL-2020 19:03:08',18),
(3, '28-JUL-2020 19:03:09',23),
(4, '28-JUL-2020 19:03:10',29),
(5, '28-JUL-2020 19:03:11',27),
(6, '28-JUL-2020 19:03:12',45),
(7, '28-JUL-2020 19:03:13',45),
(8, '28-JUL-2020 19:03:14',32),
(9, '28-JUL-2020 19:03:15',41),
(10,'28-JUL-2020 19:03:16',15),
(11,'28-JUL-2020 19:03:17',24),
(12,'28-JUL-2020 19:03:18',47),
(13,'28-JUL-2020 19:03:19',37),
(14,'28-JUL-2020 19:03:20',48),
(15,'28-JUL-2020 19:03:21',46),
(16,'28-JUL-2020 19:03:22',44),
(17,'28-JUL-2020 19:03:23',36),
(18,'28-JUL-2020 19:03:24',41),
(19,'28-JUL-2020 19:03:25',33),
(20,'28-JUL-2020 19:03:26',19);而你想返回如下结果集。
sql
GRP TRX_START TRX_END TOTAL
--- -------------------- -------------------- ----------
1 28-JUL-2020 19:03:07 28-JUL-2020 19:03:11 141
2 28-JUL-2020 19:03:12 28-JUL-2020 19:03:16 178
3 28-JUL-2020 19:03:17 28-JUL-2020 19:03:21 202
4 28-JUL-2020 19:03:22 28-JUL-2020 19:03:26 173解决方案:将全部数据按条目进行分桶,每桶包含 5 行数据。实现这种逻辑分组的方式有多种,本实例使用的是 7 节介绍的方法,即用 TRX_ID 值除以 5。
创建好"分组"后,使用聚合函数 MIN、MAX 和 SUM 找出每个分组的起始时间、终止时间和交易总数。(在 SQLServer 中,应该使用 CEILING 而不是 CEIL。)
sql
select ceil(trx_id/5.0) as grp,
min(trx_date) as trx_start,
max(trx_date) as trx_end,
sum(trx_cnt) as total
from trx_log
group by ceil(trx_id/5.0);
grp | trx_start | trx_end | total
-----+------------+------------+-------
3 | 2020-07-28 | 2020-07-28 | 202
1 | 2020-07-28 | 2020-07-28 | 141
4 | 2020-07-28 | 2020-07-28 | 173
2 | 2020-07-28 | 2020-07-28 | 178
(4 rows)18、同时对不同的分组/分区进行聚合
问题:你想同时聚合不同的维度。例如,你想返回一个结果集,其中列出了每位员工的名字、所属部门、所属部门的员工数、所属职位的员工数以及整个 EMP 表中的员工总数。结果集如下所示。
sql
ENAME DEPTNO DEPTNO_CNT JOB JOB_CNT TOTAL
------ ------ ---------- --------- -------- ------
MILLER 10 3 CLERK 4 14
CLARK 10 3 MANAGER 3 14
KING 10 3 PRESIDENT 1 14
SCOTT 20 5 ANALYST 2 14
FORD 20 5 ANALYST 2 14
SMITH 20 5 CLERK 4 14
JONES 20 5 MANAGER 3 14
ADAMS 20 5 CLERK 4 14
JAMES 30 6 CLERK 4 14
MARTIN 30 6 SALESMAN 4 14
TURNER 30 6 SALESMAN 4 14
WARD 30 6 SALESMAN 4 14
ALLEN 30 6 SALESMAN 4 14
BLAKE 30 6 MANAGER 3 14解决方案:使用窗口函数 COUNT OVER,并指定要进行聚合的数据分区(分组)。
sql
select ename,
deptno,
count(*)over(partition by deptno) deptno_cnt,
job,
count(*)over(partition by job) job_cnt,
count(*)over() total
from emp;
19、聚合移动值区间
问题: 你想计算移动聚合,比如 EMP 表的移动薪水总计。你想从第一位员工的 HIREDATE 开始,计算 90 天内的薪水总计,以便了解从第一位员工获聘到最近一位员工获聘期间,90 天内的薪水波动情况。你想返回如下结果集。
sql
HIREDATE SAL SPENDING_PATTERN
----------- ------- ----------------
17-DEC-200 800 800
20-FEB-2011 1600 2400
22-FEB-2011 1250 3650
02-APR-2011 2975 5825
01-MAY-2011 2850 8675
09-JUN-2011 2450 8275
08-SEP-2011 1500 1500
28-SEP-2011 1250 2750
17-NOV-2011 5000 7750
03-DEC-2011 950 11700
03-DEC-2011 3000 11700
23-JAN-2012 1300 10250
09-DEC-2012 3000 3000
12-JAN-2013 1100 4100解决方案:如果你使用的 RDBMS 支持相关的窗口函数,并允许在框架或窗口子句中指定移动窗口,那么这个问题解决起来将易如反掌。关键是在窗口函数中按 HIREDATE 排序,然后再指定一个 90 天的移动窗口(起点为第一位员工的获聘日期)。计算的总薪水为当前员工获聘日期前 90 天内所有获聘员工(包括当前员工)的薪水总和。如果没有可供使用的窗口函数,则可以使用标量子查询,但解决方案将更复杂。
DB2 和 Oracle:在 DB2 和 Oracle 中,使用窗口函数 SUM OVER,并按HIREDATE 排序。在窗口或框架子句中,指定 90 天的区间,以计算当前员工以及之前 90 天内获聘的其他所有员工的薪水总和。在 DB2 中,不能在窗口函数的 ORDERBY 子句中指定 HIREDATE,必须按 DAYS(HIREDATE)排序,如下述代码的第 3 行所示。
sql
select hiredate,
sal,
sum(sal)over(order by days(hiredate)
range between 90 preceding
and current row) spending_pattern
from emp e;相比于 DB2 解决方案,Oracle 解决方案更简单,因为在 Oracle 中,可以在窗口函数中将日期时间数据类型作为排序依据。
sql
select hiredate,
sal,
sum(sal)over(order by hiredate
range between 90 preceding
and current row) spending_pattern
from emp e;MySQL:使用窗口函数 SUM OVER,但语法稍有不同。
sql
select hiredate,
sal,
sum(sal)over(order by hiredate
range interval 90 day preceding ) spending_pattern
from emp e;PostgreSQL 和 SQL Server:使用标量子查询来计算当前员工获聘日期前 90 天内获聘的所有员工的薪水总和。
sql
select e.hiredate,
e.sal,
(select sum(sal) from emp d
where d.hiredate between e.hiredate-90
and e.hiredate) as spending_pattern
from emp e
order by 1;20、转置包含小计的结果集
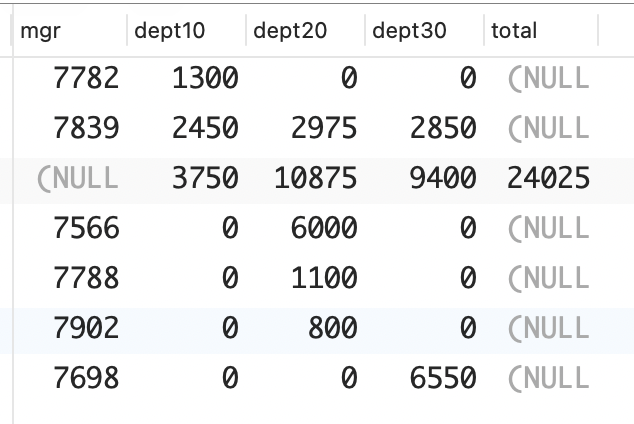
问题:你想制作一张包含小计的报表,再对其进行转置,以生成可读性更强的报表。例如,你被要求制作一张报表,其中列出了每个部门、每个部门的管理者以及各个管理者下属的员工的薪水总和。另外,你还想返回两种小计:每个部门由管理者管理的员工的薪水总和;结果集中的所有薪水之和(部门小计之和)。当前,你已经有如下报表:
sql
DEPTNO MGR SAL
------ ---------- ----------
10 7782 1300
10 7839 2450
10 3750
20 7566 6000
20 7788 1100
20 7839 2975
20 7902 800
20 10875
30 7698 6550
30 7839 2850
30 9400
24025但要提供一张可读性更强的报表,因此要将上面的结果集转换成下面这样,让报表的含义更清晰。
sql
MGR DEPT10 DEPT20 DEPT30 TOTAL
---- ---------- ---------- ---------- ----------
7566 0 6000 0
7698 0 0 6550
7782 1300 0 0
7788 0 1100 0
7839 2450 2975 2850
7902 0 800 0
3750 10875 9400 24025解决方案:首先,使用 GROUP BY 扩展 ROLLUP 来生成小计。然后,执行经典转置操作(使用聚合和 CASE 表达式)来生成所需的报表列。使用函数 GROUPING 可以轻松地确定哪些值为小计(由 ROLLUP 生成的)。根据你使用的RDBMS 对 NULL 值的排序方式,可能需要在解决方案中添加 ORDER BY,让最终的输出类似于前面的结果集。
DB2 和 Oracle:使用 GROUP BY 扩展 ROLLUP 来生成小计,然后使用CASE 表达式将数据转换为可读性更强的报表。
sql
select mgr,
sum(case deptno when 10 then sal else 0 end) dept10,
sum(case deptno when 20 then sal else 0 end) dept20,
sum(case deptno when 30 then sal else 0 end) dept30,
sum(case flag when '11' then sal else null end) total
from (
select deptno,mgr,sum(sal) sal,
cast(grouping(deptno) as char(1))||
cast(grouping(mgr) as char(1)) flag
from emp
where mgr is not null
group by rollup(deptno,mgr)
) x
group by mgr;SQL Server:使用 GROUP BY 扩展 ROLLUP 来生成小计,然后使用CASE 表达式将数据转换为可读性更强的报表。
sql
select mgr,
sum(case deptno when 10 then sal else 0 end) dept10,
sum(case deptno when 20 then sal else 0 end) dept20,
sum(case deptno when 30 then sal else 0 end) dept30,
sum(case flag when '11' then sal else null end) total
from (
select deptno,mgr,sum(sal) sal,
cast(grouping(deptno) as char(1))+
cast(grouping(mgr) as char(1)) flag
from emp
where mgr is not null
group by deptno,mgr with rollup
) x
group by mgr;PostgreSQL:使用 GROUP BY 扩展 ROLLUP 来生成小计,然后使用CASE 表达式将数据转换为可读性更强的报表。
sql
select mgr,
sum(case deptno when 10 then sal else 0 end) dept10,
sum(case deptno when 20 then sal else 0 end) dept20,
sum(case deptno when 30 then sal else 0 end) dept30,
sum(case flag when '11' then sal else null end) total
from (
select deptno,mgr,sum(sal) sal,
concat(cast (grouping(deptno) as char(1)),
cast(grouping(mgr) as char(1))) flag
from emp
where mgr is not null
group by rollup (deptno,mgr)
) x
group by mgr;
mgr | dept10 | dept20 | dept30 | total
------+--------+--------+--------+-------
7839 | 2450 | 2975 | 2850 |
| 3750 | 10875 | 9400 | 24025
7902 | 0 | 800 | 0 |
7698 | 0 | 0 | 6550 |
7788 | 0 | 1100 | 0 |
7782 | 1300 | 0 | 0 |
7566 | 0 | 6000 | 0 |
(7 rows)MySQL:使用 GROUP BY 扩展 ROLLUP 来生成小计,然后使用CASE 表达式将数据转换为可读性更强的报表。
sql
select mgr,
sum(case deptno when 10 then sal else 0 end) dept10,
sum(case deptno when 20 then sal else 0 end) dept20,
sum(case deptno when 30 then sal else 0 end) dept30,
sum(case flag when '11' then sal else null end) total
from (
select deptno,mgr,sum(sal) sal,
concat( cast(grouping(deptno) as char(1)) ,
cast(grouping(mgr) as char(1))) flag
from emp
where mgr is not null
group by deptno,mgr with rollup
) x
group by mgr;