GO学习笔记 | 第二章节 GO语言基础 | 方法(函数)&& 控制结构 && 内置类型
核心内容 :方法声明、函数式编程、控制结构(if/for/switch) 、内置类型
前置知识:变量声明、常量声明(iota)、包管理
文章目录
- [GO学习笔记 | 第二章节 GO语言基础 | 方法(函数)&& 控制结构 && 内置类型](#GO学习笔记 | 第二章节 GO语言基础 | 方法(函数)&& 控制结构 && 内置类型)
-
- 一、两个注意点
-
- [1.1 GOPATH 目录结构](#1.1 GOPATH 目录结构)
- [1.2 iota 回顾](#1.2 iota 回顾)
- 二、方法声明
- 三、函数式编程
-
- [3.1 函数是第一等公民](#3.1 函数是第一等公民)
- [3.2 方法作为返回值](#3.2 方法作为返回值)
- [3.3 闭包(Closure)](#3.3 闭包(Closure))
- [3.4 匿名函数立即调用](#3.4 匿名函数立即调用)
- 四、不定参数
-
- [4.1 基本用法](#4.1 基本用法)
- [4.2 传递切片](#4.2 传递切片)
- [4.3 不定参数的本质](#4.3 不定参数的本质)
- 五、defer(延迟调用)
-
- [5.1 基本用法](#5.1 基本用法)
- [5.2 执行顺序:后进先出(LIFO)](#5.2 执行顺序:后进先出(LIFO))
- [5.3 defer 与闭包](#5.3 defer 与闭包)
-
- [情况1:defer 直接跟函数调用](#情况1:defer 直接跟函数调用)
- [情况2:defer 跟闭包](#情况2:defer 跟闭包)
- [情况3:defer 传参给闭包](#情况3:defer 传参给闭包)
- [5.4 defer 修改返回值(带名字的返回值)](#5.4 defer 修改返回值(带名字的返回值))
- [5.5 defer 常见用途](#5.5 defer 常见用途)
-
- [1. 资源释放](#1. 资源释放)
- [2. 解锁](#2. 解锁)
- [3. 计时](#3. 计时)
- 六、控制结构
- 七、方法调用总结
- 八、控制结构总结
- 九、内置类型:数组(Array)
-
- [9.1 数组声明与初始化](#9.1 数组声明与初始化)
- [9.2 长度 vs 容量](#9.2 长度 vs 容量)
- [9.3 数组的特性与限制](#9.3 数组的特性与限制)
- 十、内置类型:切片(Slice)
-
- [10.1 从数组到切片:删掉长度就行](#10.1 从数组到切片:删掉长度就行)
- [10.2 用 make 创建切片](#10.2 用 make 创建切片)
- [10.3 append:往切片追加元素](#10.3 append:往切片追加元素)
- [10.4 子切片以及核心难点:切片的底层数组共享](#10.4 子切片以及核心难点:切片的底层数组共享)
- 十一、内置类型:Map
-
- [11.1 Map 的创建与基本操作](#11.1 Map 的创建与基本操作)
- [11.2 判断 key 是否存在](#11.2 判断 key 是否存在)
- [11.3 遍历顺序](#11.3 遍历顺序)
- [11.4 关于 channel](#11.4 关于 channel)
- [11.5 comparable概念](#11.5 comparable概念)
- 十二、陷阱
-
- 陷阱1:函数重载
- 陷阱2:递归没有退出条件
- [陷阱3:defer 参数立即计算](#陷阱3:defer 参数立即计算)
- [陷阱4:for-range 取地址](#陷阱4:for-range 取地址)
- [陷阱5:map 遍历顺序](#陷阱5:map 遍历顺序)
- [陷阱6:数组不能 append](#陷阱6:数组不能 append)
- 陷阱7:切片底层数组共享
- [陷阱8:map 遍历顺序随机](#陷阱8:map 遍历顺序随机)
- [陷阱9:map 取不存在的 key 返回零值](#陷阱9:map 取不存在的 key 返回零值)
一、两个注意点
1.1 GOPATH 目录结构
GOPATH/
├── src/ ← 源代码放在这里
├── bin/ ← go install 安装的命令
└── pkg/ ← go get 下载的依赖包注意事项:
- 项目代码放在
src目录下 - 如果不在
src目录下,需要显式指定模块名 - 依赖缓存问题:可以删除整个
pkg/mod目录重新拉取
1.2 iota 回顾
go
const (
A = iota // 0
B // 1
C // 2
)
// 复杂用法(了解即可)
const (
Flag1 = 1 << iota // 1 (二进制: 001)
Flag2 // 2 (二进制: 010)
Flag3 // 4 (二进制: 100)
)建议:基本用法掌握即可,复杂用法了解就行。
二、方法声明
2.1 方法签名
go
func 方法名(参数列表) 返回值 {
// 方法体
}组成部分:
func关键字- 方法名(大写 = 包外可访问,小写 = 包内私有)
- 参数列表
- 返回值
- 方法体
2.2 参数声明
基础写法
go
// 无参数
func Func1() {}
// 单个参数
func Func2(a int) {}
// 多个参数
func Func3(a int, b string, c bool) {}
// 同类型简写 连续声明
func Func4(a, b, c int) {} // 三个都是 intGo 不支持函数重载
go
// ❌ 编译错误!Go 不支持函数重载
func Add(a, b int) int { return a + b }
func Add(a, b float64) float64 { return a + b } // 错误:重复定义
func Add(a, b, c int) int { return a + b + c } // 错误:重复定义替代方案:
- 使用不同的函数名:
AddInt,AddFloat,AddThree - 使用泛型(Go 1.18+)
- 使用可变参数
2.3 返回值
不带名字的返回值
go
// 无返回值
func Func1() {}
// 单个返回值
func Func2() int {
return 42
}
// 多个返回值
func Func3() (string, int) {
return "hello", 18
}带名字的返回值
name,age就是返回值的名字,你返回的时候必须返回两个值
go
// 带名字的返回值
func Func4() (name string, age int) {
name = "大明"
age = 18
return // 裸 return,自动返回 name 和 age
}
// 等价于
func Func4() (name string, age int) {
return "大明", 18
}
//这个返回的就是对应类型的零值,string对应空字符串,int对应0
func Func5()(name string,age int){
return
}注意事项:
- 要么都带名字,要么都不带名字
- 带名字会扩大作用域(从方法开始到这个函数的结束)
- 个人习惯:不带名字,避免作用域污染
接收返回值
go
//正常情况下
var name string = "daming"
var age int = 18
name,age =func3() //这是没有新变量,因为name和age已经声明了
// 全部接收 name1和age1都没有声明,得用:=,这两个是新变量
name1, age1 := Func3()
// 忽略某个返回值(用下划线)
name2, _ := Func3() // 只接收 name,忽略 age
_, age2 := Func3() // 只接收 age,忽略 name
// 一个都不接收
Func3()
// ❌ 错误::= 左边必须至少有一个新变量 name和age都是已经声明过的变量,不能用:=
name, age := Func3()
name, age := Func3() // 编译错误:no new variables
// ✅ 正确:至少有一个新变量
name3, age := Func3() // name3 是新变量2.4 递归
go
func Recursive(n int) {
if n > 10 {
return // 必须有退出机制!
}
println(n)
Recursive(n + 1)
}⚠️ 重要警告:
- 必须有退出机制 ,否则会导致 stack overflow
- 生产环境常见错误:A 调 B,B 调 C,C 调 A(循环递归)
- Go 的 goroutine 栈默认只有 2KB,很容易溢出
stack overflow 解决:
- 面试时:优化代码,找到递归退出条件
- 不要试图通过调大栈大小来解决(治标不治本)
三、函数式编程
3.1 函数是第一等公民
含义:函数可以像变量一样使用。
用法1:函数赋值给变量

go
func Hello() {
println("hello")
}
func main() {
myFunc := Hello // 注意:没有括号!
myFunc() // 调用
}⚠️ 常见错误:
go
myFunc := Hello() // ❌ 这是调用函数,把返回值赋给 myFunc
myFunc := Hello // ✅ 这是把函数本身赋给 myFunc用法2:带参数的函数赋值
go
func Add(a, b int) int {
return a + b
}
func main() {
myAdd := Add
result := myAdd(1, 2) // 调用时传参数
}用法3:局部方法(匿名函数)
go
func Outer() {
// 定义局部方法
inner := func() {
println("inner function")
}
inner() // 调用
}
// inner() // ❌ 错误:inner 只在 Outer 内部可用注:
1.fn和inner之前都没有声明过
2.后面的函数不写函数名
使用场景:
- 方法很长,想抽出一部分逻辑
- 但不想让别人使用(连同一个包的人都不想给用)
- 非常罕见的用法
3.2 方法作为返回值
go
//意思是我返回一个返回值为string的func函数
func GetFunc() func() string {
return func() string {
return "hello"
}
}
func main() {
fn := GetFunc()
result := fn() // "hello"
}Option 模式:
看不懂先跳过,不要紧的都,后面学的会了再回头来看就是了
go
// 返回一个配置函数
type Option func(*Config)
func WithTimeout(timeout time.Duration) Option {
return func(c *Config) {
c.Timeout = timeout
}
}3.3 闭包(Closure)
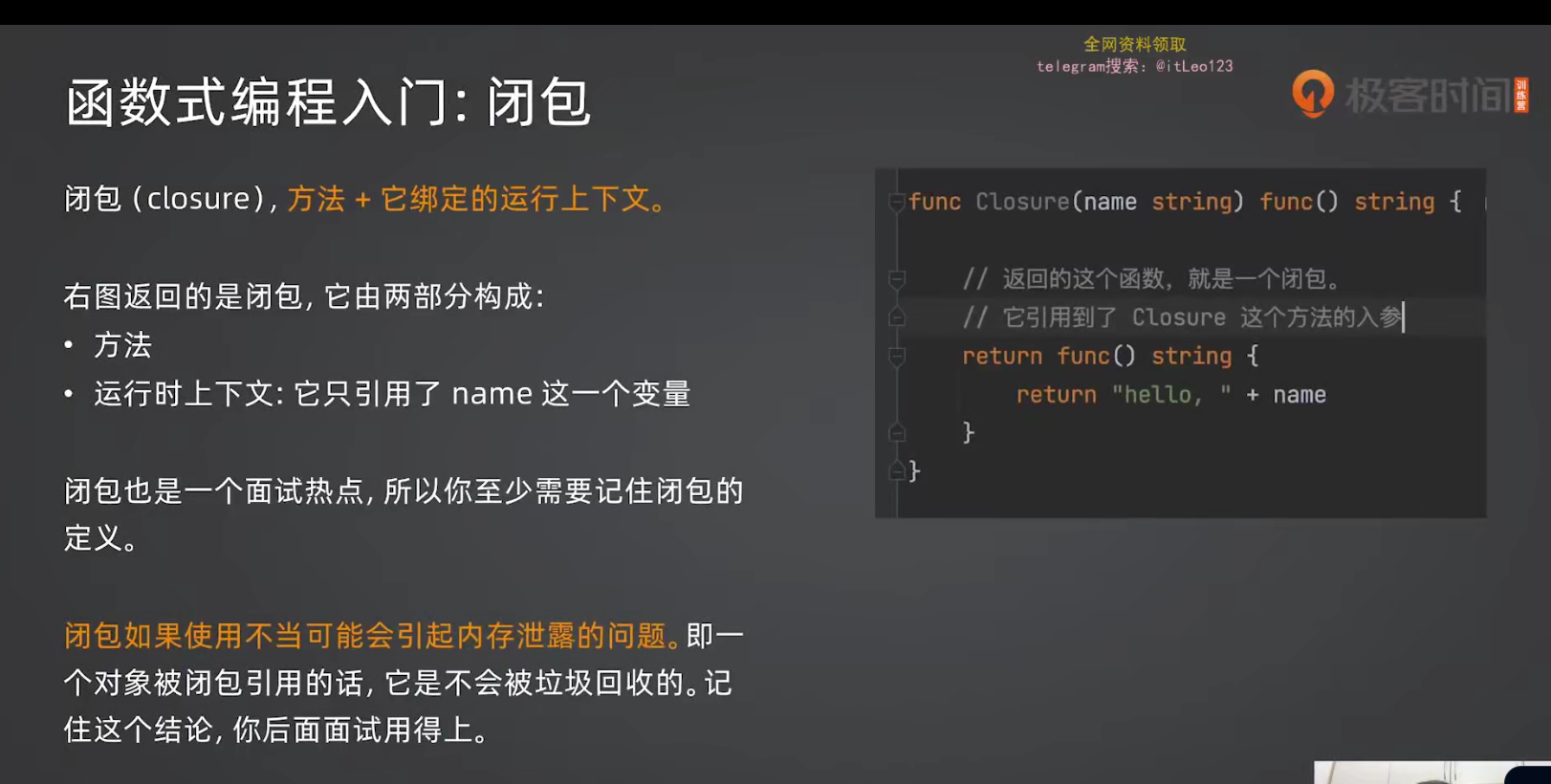
定义:方法 + 绑定的运行上下文
go
func Closure(name string) func() string {
return func() string {
return "hello " + name // 使用了外部的 name
}
}
func main() {
fn := Closure("大明")
// fn 已经脱离了 Closure(即closure已经调用结束了),但仍要使用 name,其实也就是说明大明在fn的上下文,必须要等fn用完name以后才会回收
println(fn()) // "hello 大明"
}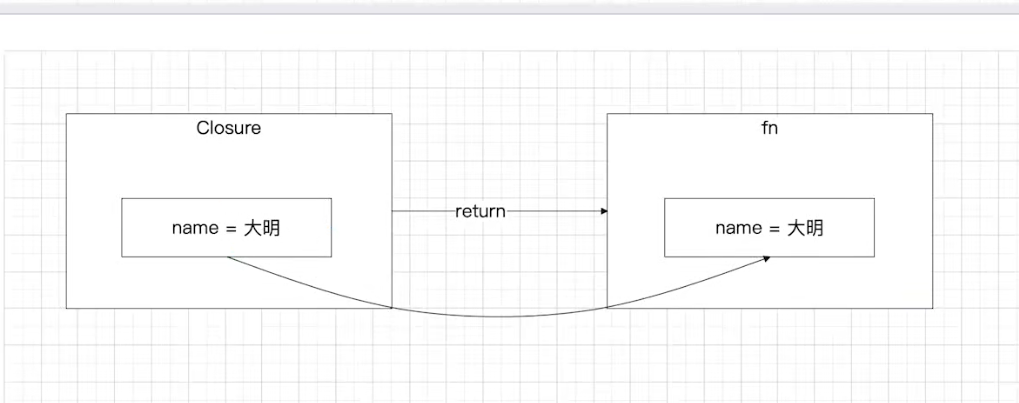
关键点:
- 返回的函数仍可使用外部变量
- 外部变量不会被销毁,直到返回的函数用完
- 垃圾回收会自动管理
闭包修改外部变量
理解起来就是c可以看做一个对象一样的东西,count就是它的一个成员变量,然后它负责它的++。当然底层实现是什么样子并不清楚,只是可以这么理解一下
go
func Counter() func() int {
count := 0
return func() int {
count++ // 修改外部变量
return count
}
}
func main() {
c := Counter()
println(c()) // 1
println(c()) // 2
println(c()) // 3
c2 := Counter()
println(c2()) // 1(新的闭包,新的 count)
}3.4 匿名函数立即调用
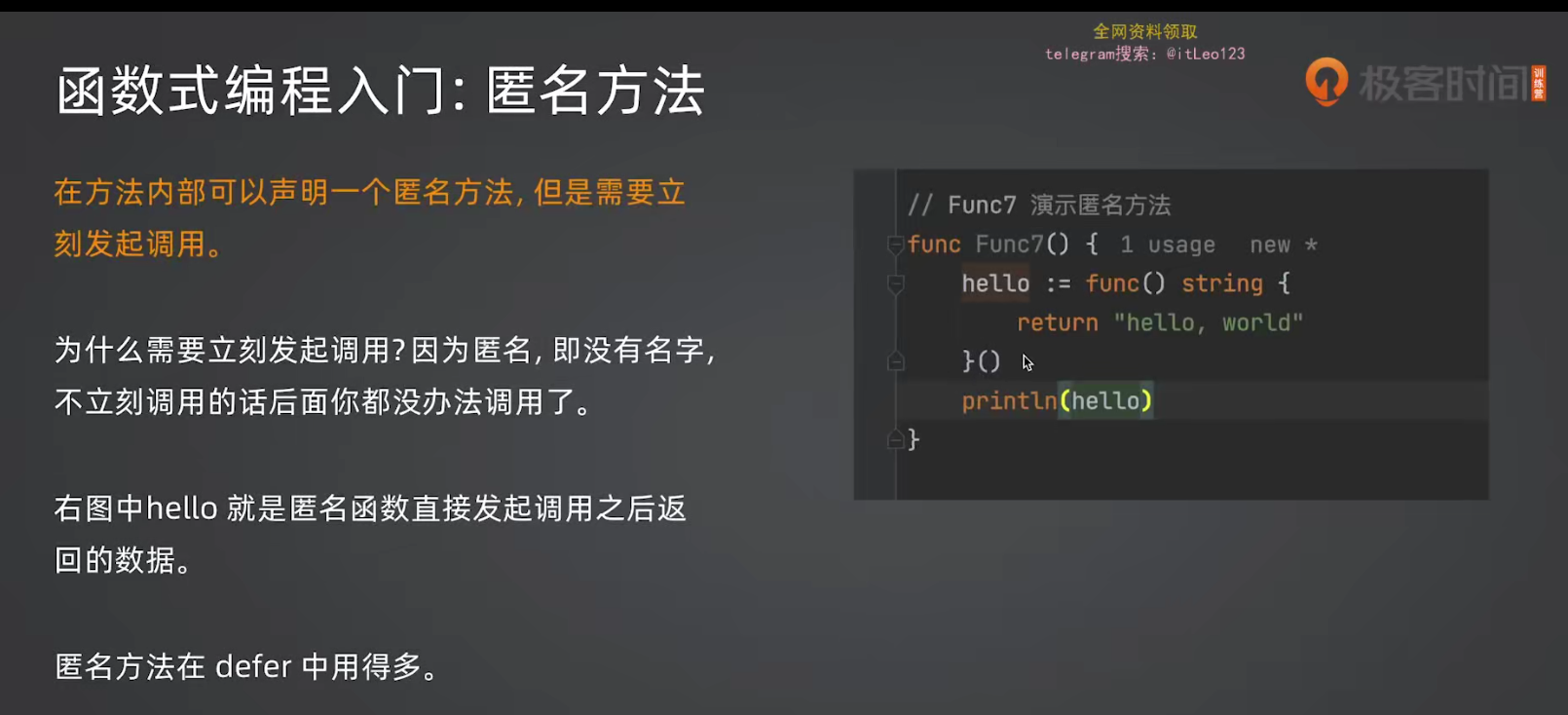
go
func main() {
result := func() string {
return "hello"
}() // 定义完立即调用
println(result) // "hello"
}这个result在这里是作为函数的返回值,是string类型的。而不是func类型的函数,所以下面才可以直接打印出来
常见用法:defer
go
defer func() {
println("cleanup")
}() // 匿名函数立即调用,返回值给 defer四、不定参数
类似于C++的args包参数(可变参模板编程部分),详情可以参见侯捷c++11标准课笔记
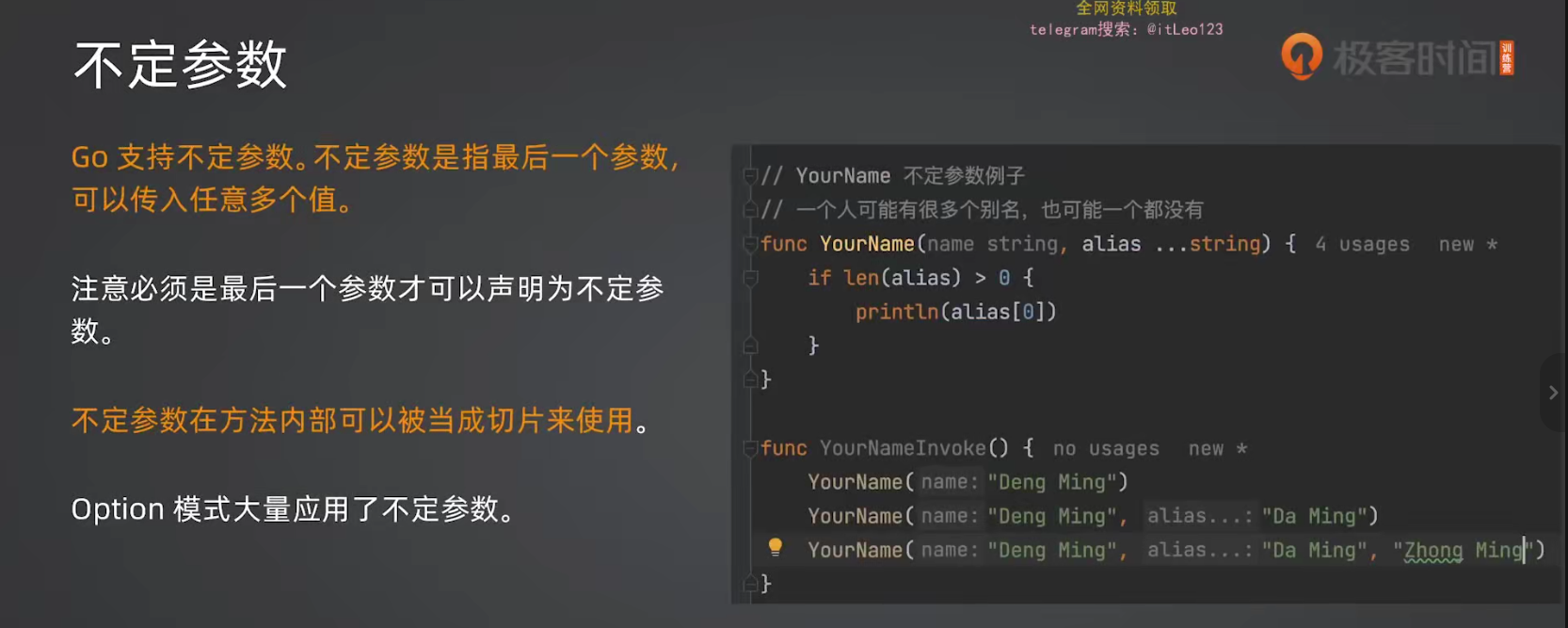
4.1 基本用法
go
func PrintNames(names ...string) {
for _, name := range names {
println(name)
}
}
func main() {
PrintNames() // 不传也可以
PrintNames("Alice") // 传一个
PrintNames("Alice", "Bob", "Charlie") // 传多个
}语法 :...类型 表示不定参数,必须是最后一个参数。
4.2 传递切片
go
func PrintNames(names ...string) {
// ...
}
func main() {
names := []string{"Alice", "Bob", "Charlie"}
PrintNames(names...) // 注意:必须加 ...
}⚠️ 常见错误:
go
PrintNames(names) // ❌ 编译错误
PrintNames(names...) // ✅ 正确4.3 不定参数的本质
不定参数在方法内部就是一个切片(暂且理解为数组):
go
func PrintNames(names ...string) {
// names 的类型是 []string
fmt.Printf("%T\n", names) // []string
}五、defer(延迟调用)
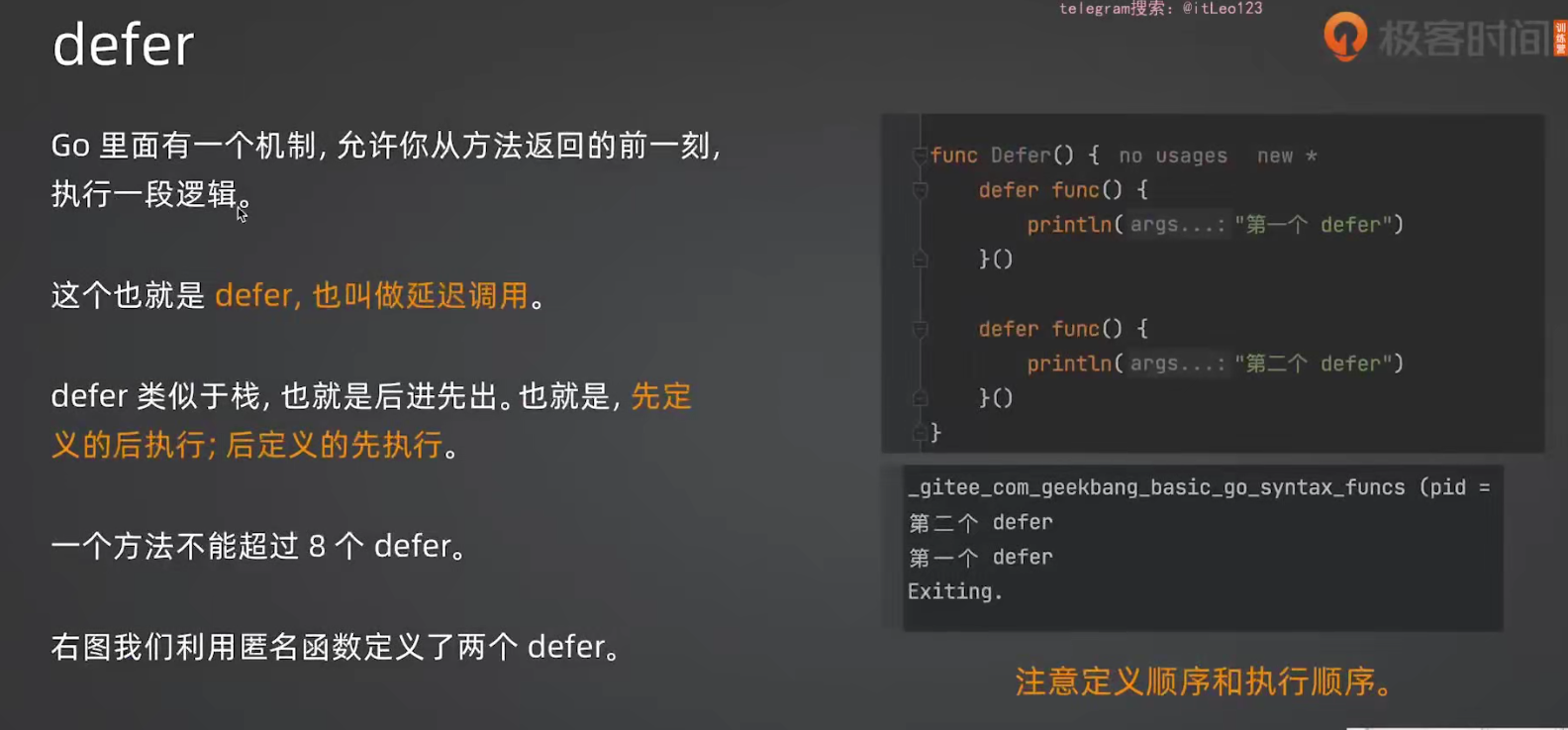
5.1 基本用法
go
func main() {
defer println("world")
println("hello")
// 输出:hello
// world
}作用:在方法返回前一刻执行。
5.2 执行顺序:后进先出(LIFO)
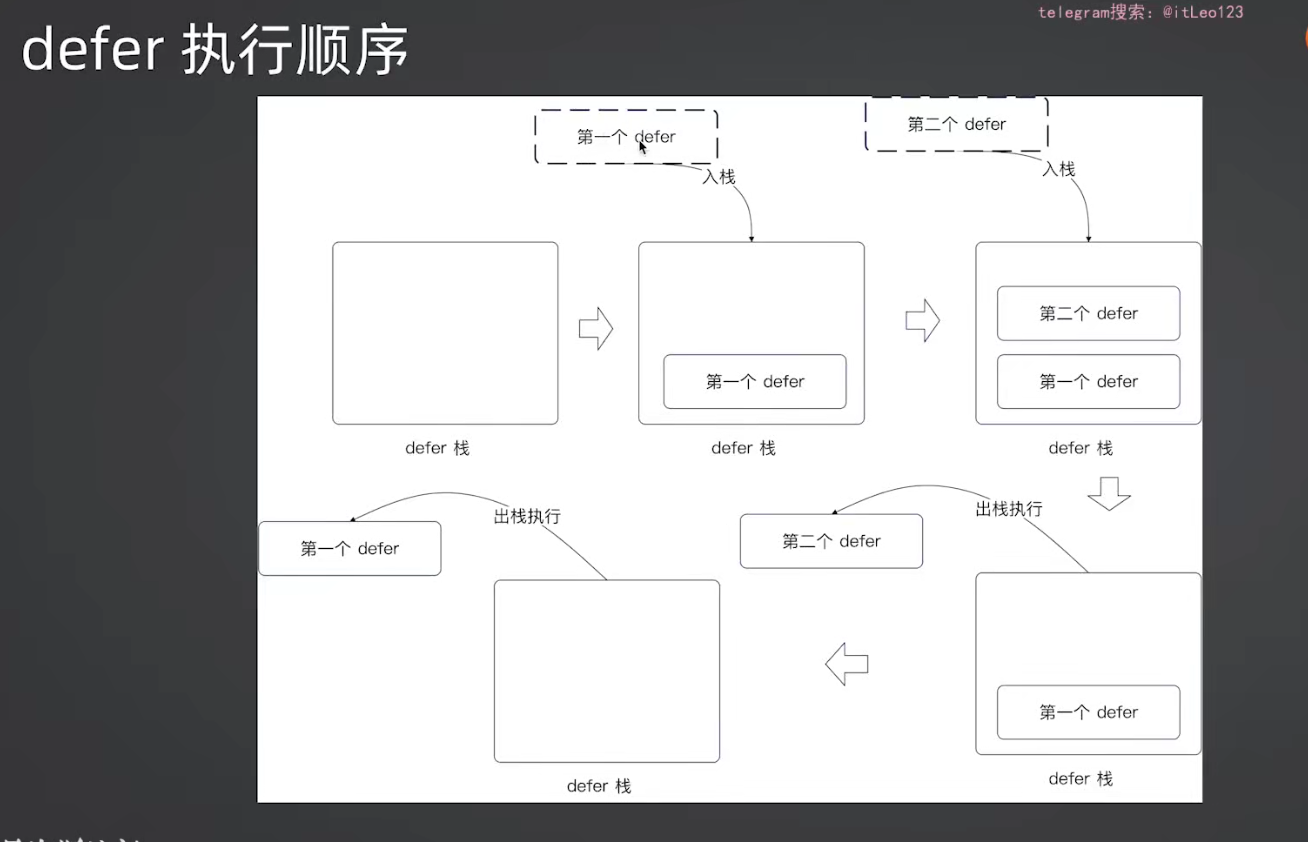
go
func main() {
defer println("1")
defer println("2")
defer println("3")
println("hello")
// 输出:hello
// 3
// 2
// 1
}类比:栈(Stack)结构。
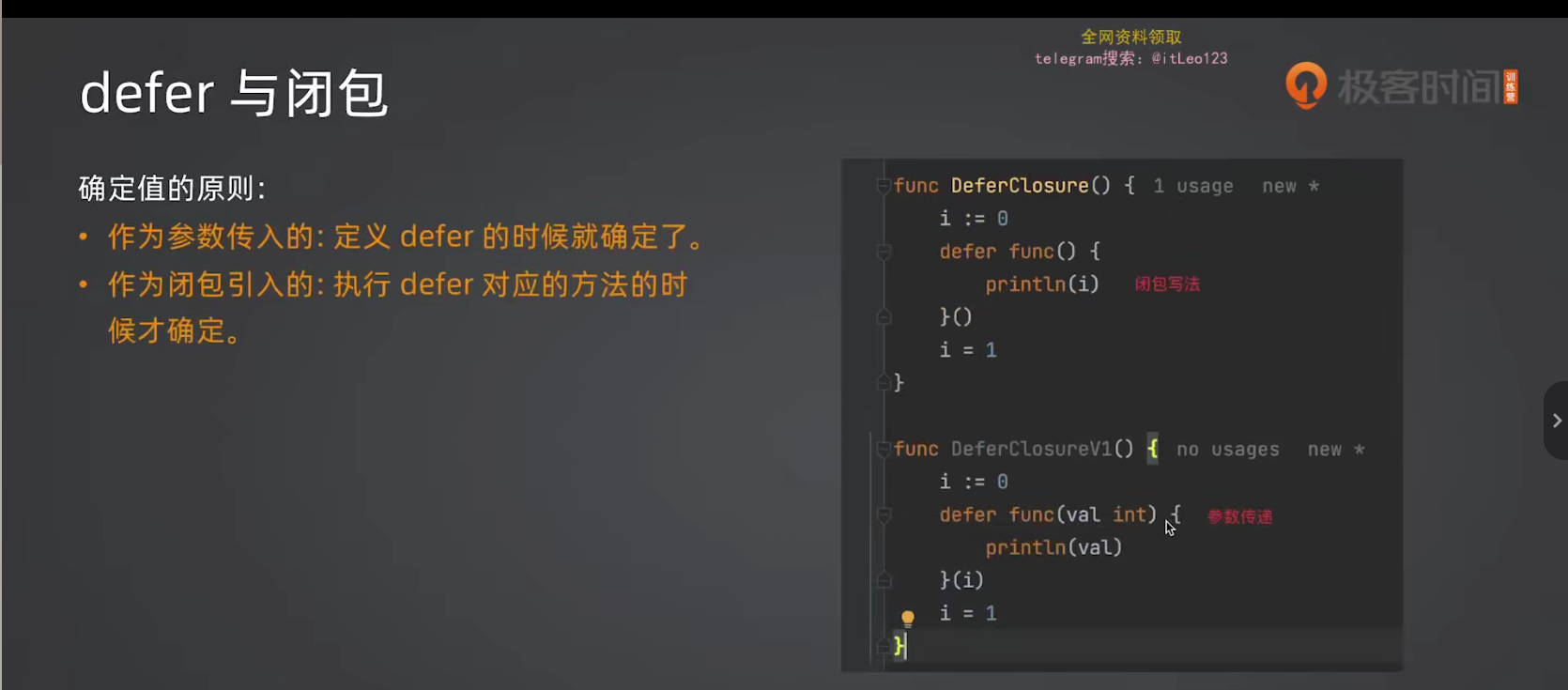
5.3 defer 与闭包
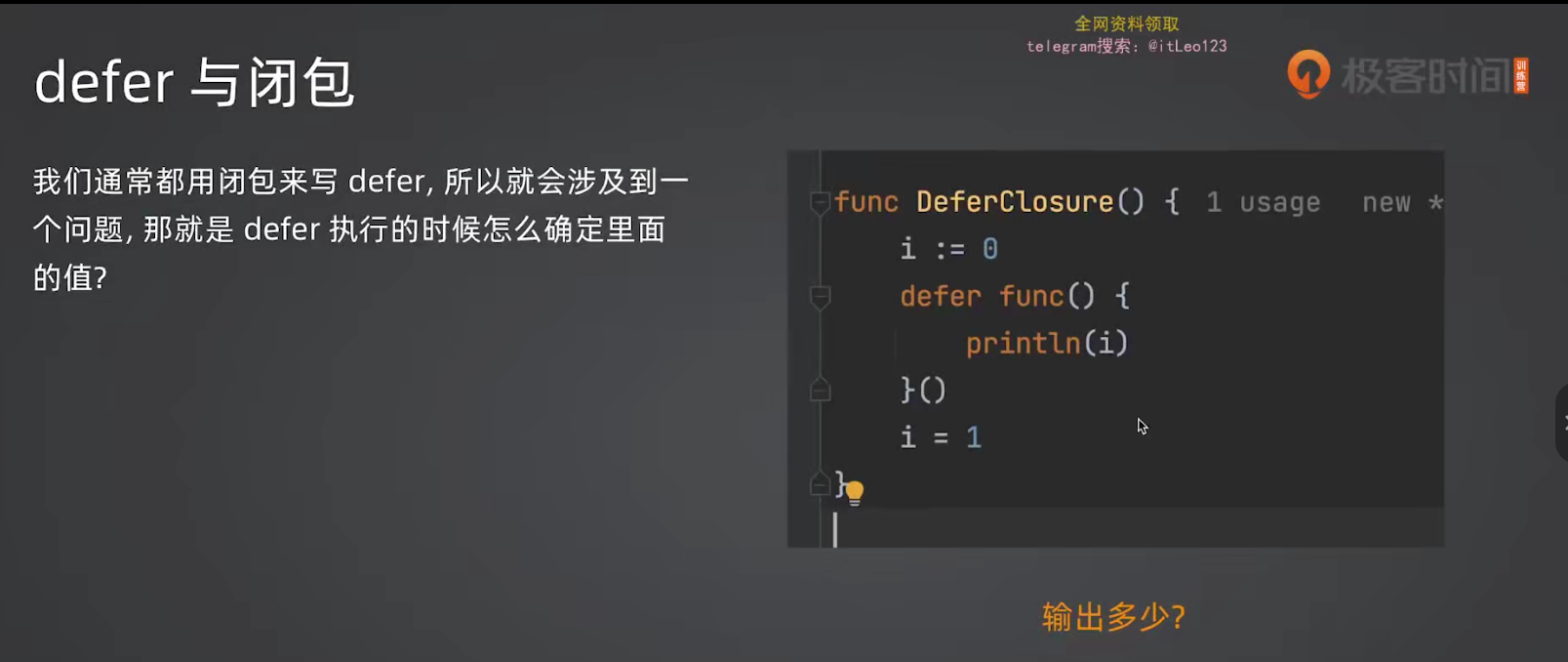
输出为1
图中第一段代码输出为1,第二段代码输出为0
可以这么理解,第一段代码是延迟调用而且没有参数,用的i的局部变量等他执行的时候i已经被改了
而第二段代码延迟调用但是运行到这段代码的时候已经把i=0传递进去了,变成func的局部变量了(或者说把i=0复制给了val),和i没关系了,所以i后面不管怎么改都无所谓了
情况1:defer 直接跟函数调用
go
func main() {
i := 0
defer fmt.Println(i) // 输出:0
i++
}解释 :defer 会立即计算参数值(0),延迟的是函数调用。
情况2:defer 跟闭包
go
func main() {
i := 0
defer func() {
fmt.Println(i) // 输出:1
}()
i++
}解释:闭包在真正执行时才取值,此时 i 已经是 1。
情况3:defer 传参给闭包
go
func main() {
i := 0
defer func(v int) {
fmt.Println(v) // 输出:0
}(i)
i++
}解释:参数 i 立即计算(0),延迟的是闭包调用。
5.4 defer 修改返回值(带名字的返回值)
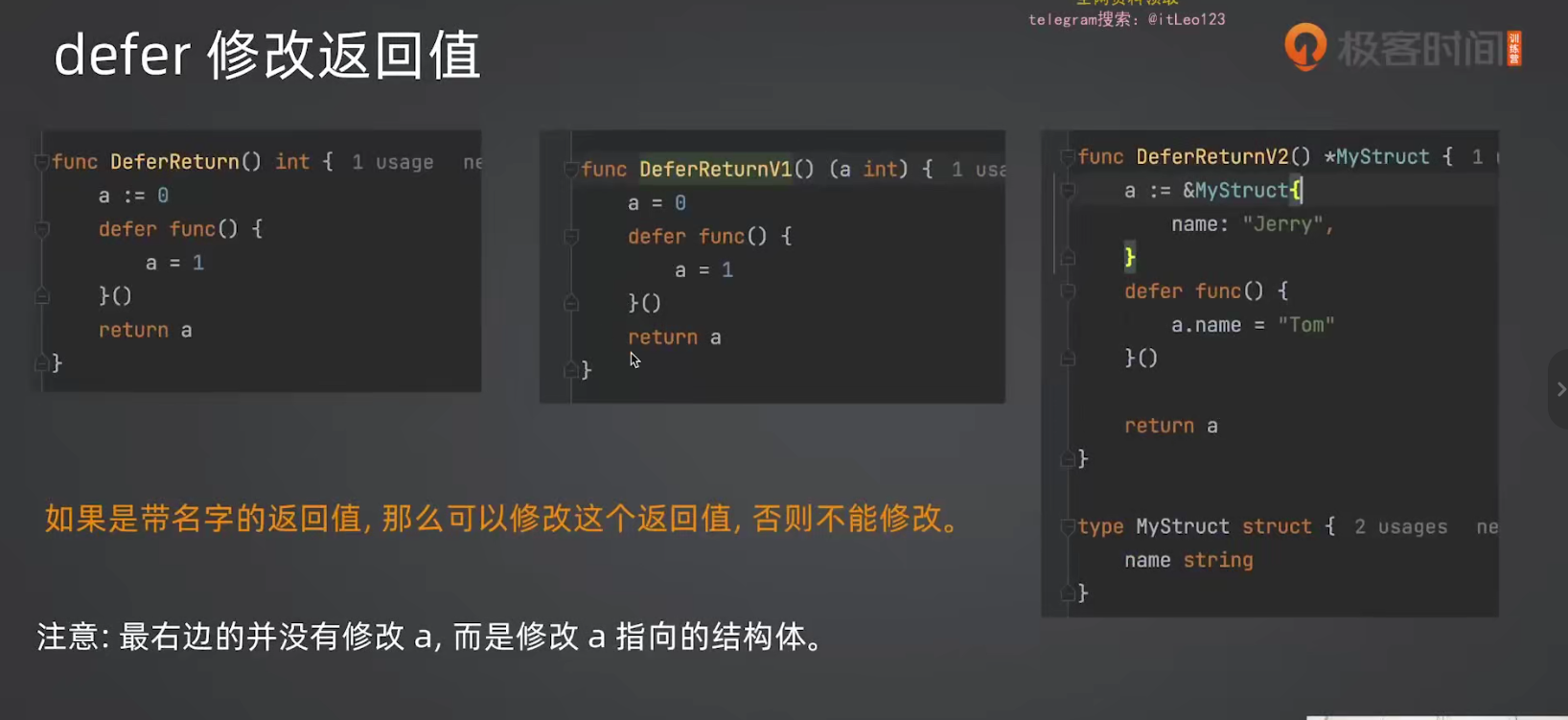
go
// ❌ 无法修改
func ReturnV1() int {
a := 0
defer func() {
a = 1 // 修改的是局部变量 a,不是返回值
}()
return a // 已经把 0 写入返回值,再改 a 没用
}
// ✅ 可以修改
func ReturnV2() (a int) { // 带名字的返回值
defer func() {
a = 1 // 修改的就是返回值本身
}()
return // 裸 return,返回 a
}
func main() {
println(ReturnV1()) // 0
println(ReturnV2()) // 1
}原理:
- 带名字的返回值:返回值在方法开始时就有固定位置,defer 修改的是这个位置
- 不带名字的返回值:return 时复制值到返回位置,defer 修改的是局部变量
5.5 defer 常见用途
1. 资源释放
go
func Query() {
db := OpenDB()
defer db.Close() // 确保关闭
// 执行业务逻辑...
}2. 解锁
go
func DoSomething() {
mu.Lock()
defer mu.Unlock()
// 执行业务逻辑...
}3. 计时
go
func SlowFunc() {
defer func(start time.Time) {
println("耗时:", time.Since(start))
}(time.Now())
// 执行业务逻辑...
}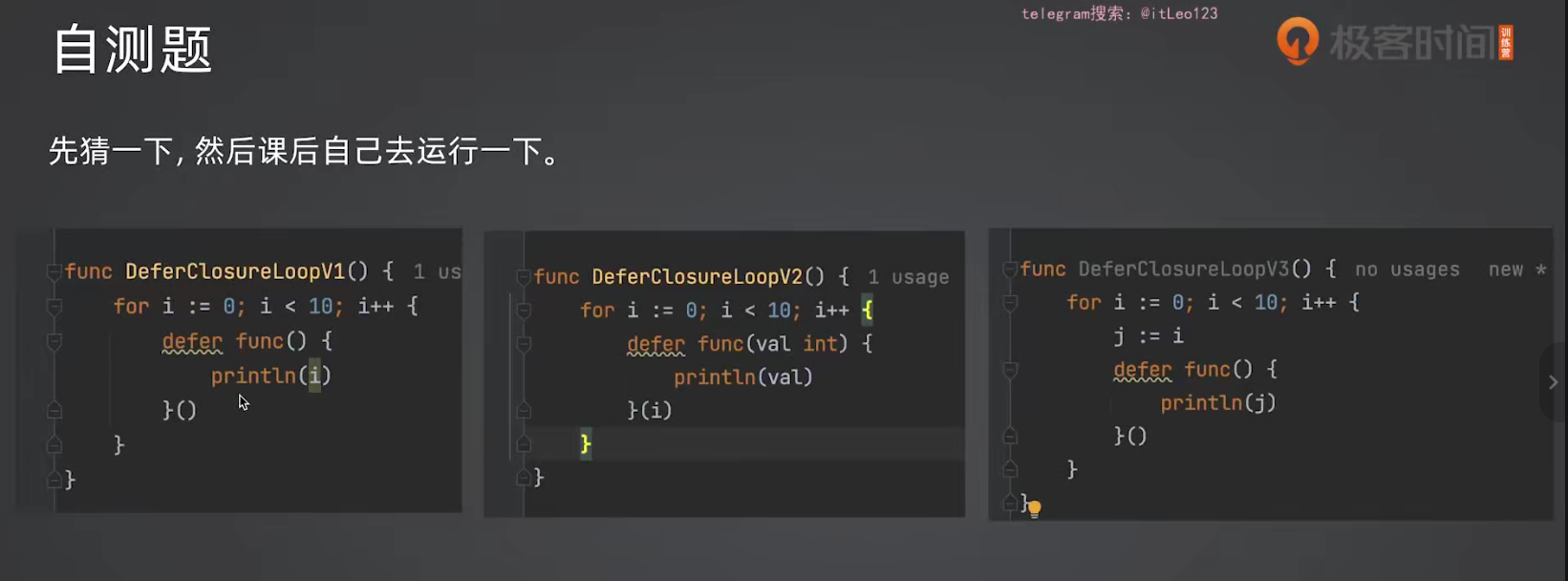
第一个全是10,并且i的地址都是同一个。其实就是每一次都是同一个i,然后最后加完了才执行循环里面的func执行了10遍,打出来了10个10
第二个是9,8,7,6,5,4,3,2,1,0,并且val的地址也一直在变。而第二个每次都把i=1,i=2之类的直接传给val了,每个func都不一样,都有自己的val,然后最后倒着输出出来就是9,8,7,...了
第三个是9,8,7,6,5,4,3,2,1,0,并且j的地址也一直在变。j每一轮循环都是一个新的变量,所以地址也会不同,所以结果和第二个一样

六、控制结构
6.1 if-else
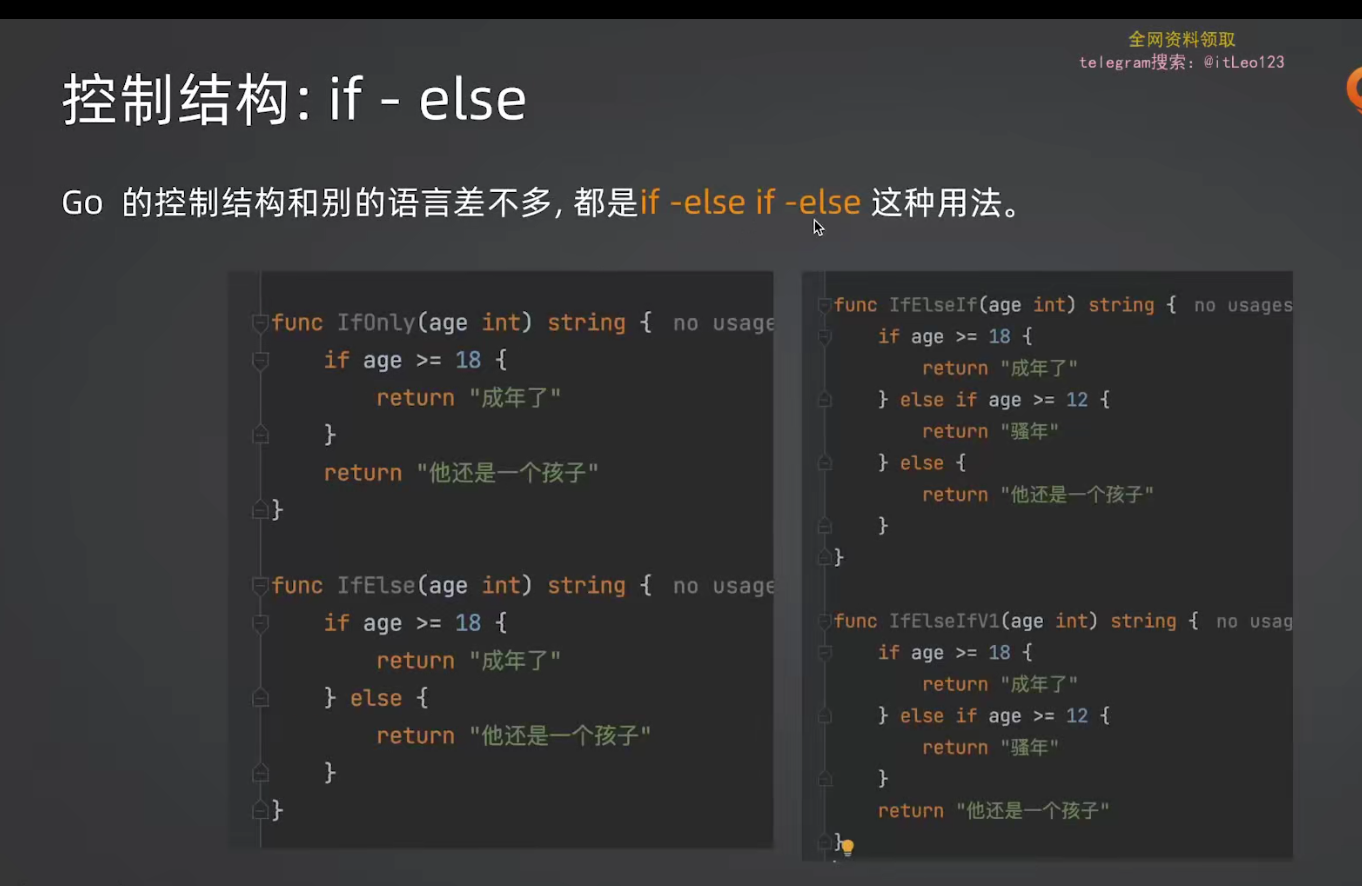
基本用法
go
if age >= 18 {
println("成年了")
}if-else
go
if age >= 18 {
println("成年了")
} else {
println("未成年")
}if-else if-else
go
if age >= 60 {
println("老年")
} else if age >= 18 {
println("成年")
} else if age >= 12 {
println("青少年")
} else {
println("儿童")
}注意:
- 条件成立进入分支后,不会继续判断其他分支
- 编译器不会检查条件是否有重叠
if 中定义变量
go
// 在 if 中定义变量,作用域只在 if-else 块内
if distance := calcDistance(a, b); distance < 100 {
println("很近")
} else if distance < 1000 {
println("有点远")
} else {
println("很远")
}
// distance 在这里不可用常见写法对比:
go
// 写法1:if 中定义(推荐)
if err := doSomething(); err != nil {
return err
}
// 写法2:传统写法
err := doSomething()
if err != nil {
return err
}6.2 for 循环
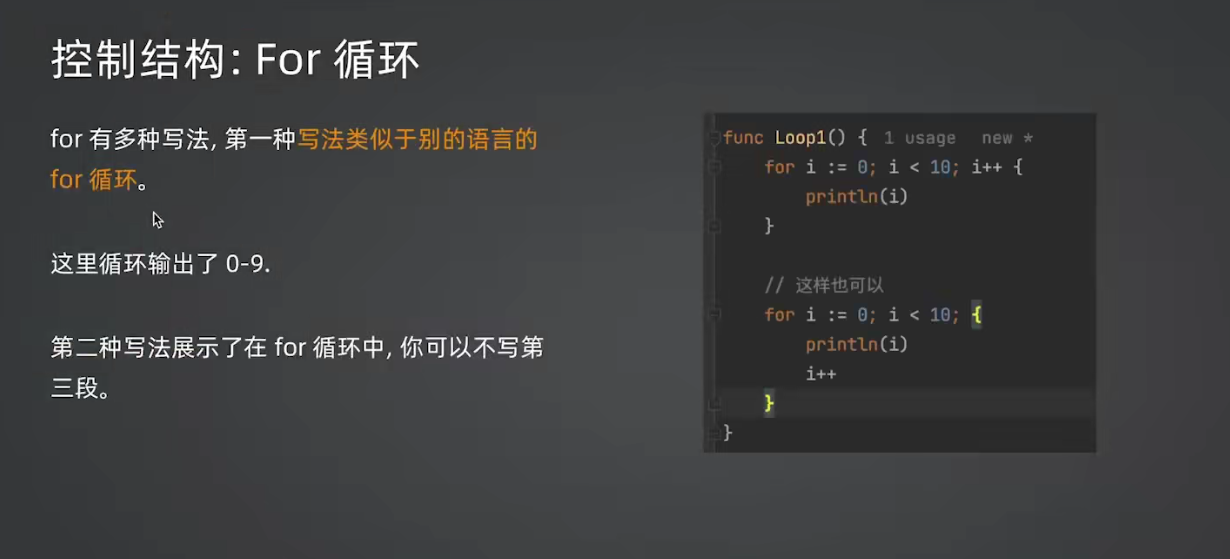

经典 for 循环
go
for i := 0; i < 10; i++ {
println(i)
}省略部分
go
// 省略初始化和后置语句(类似 while)
i := 0
for i < 10 {
println(i)
i++
}
// 只有条件(类似 while)
for condition {
// ...
}
// 死循环
for {
// ...
}for range 遍历
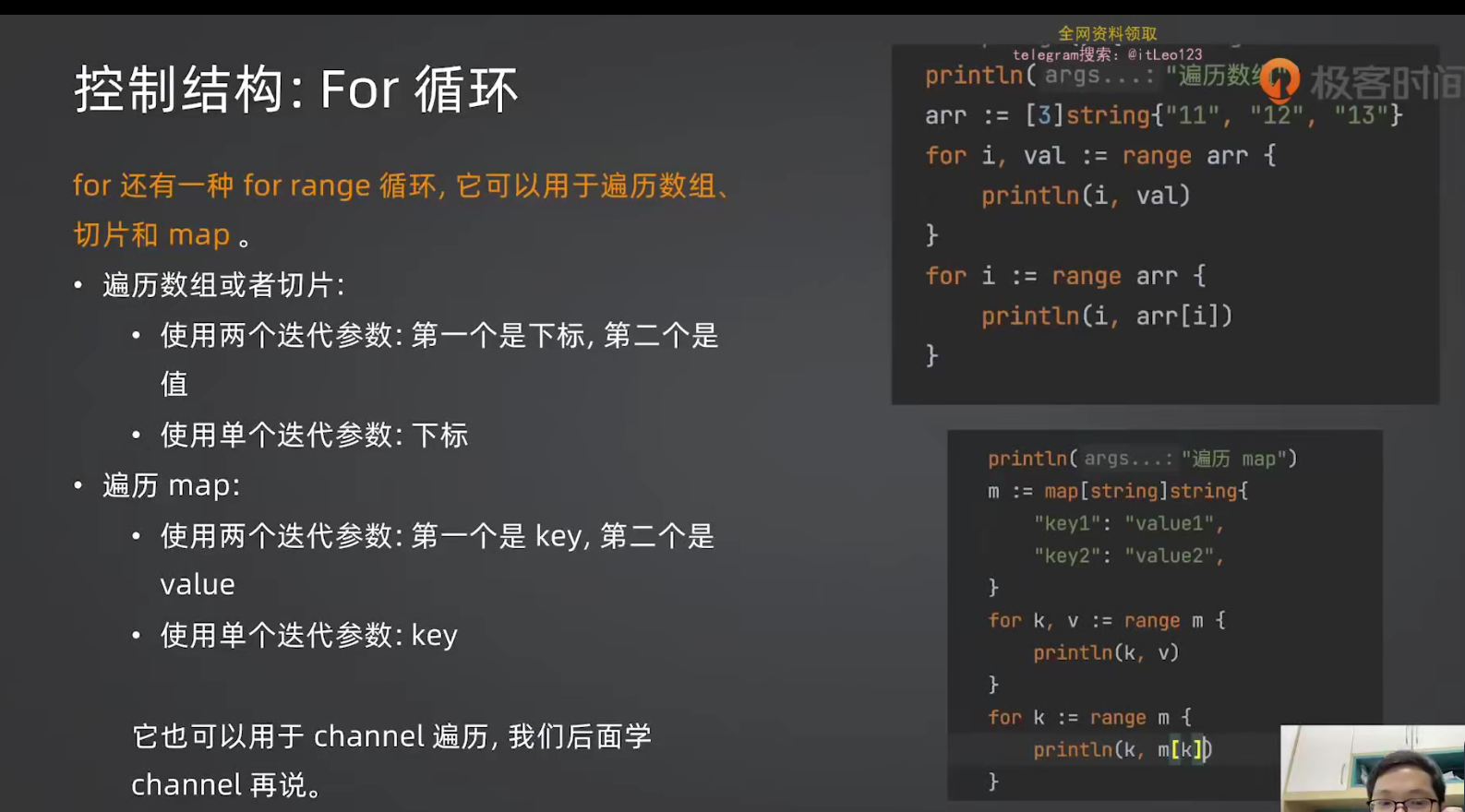
遍历数组/切片:
go
arr := []int{10, 20, 30}
// 获取下标和值
for index, value := range arr {
println(index, value)
}
// 输出:
// 0 10
// 1 20
// 2 30
//用下标访问也可以
for index := range arr {
println(index, arr[index])
}
// 只获取下标
for index := range arr {
println(index)
}
// 只获取值(用下划线忽略下标)
for _, value := range arr {
println(value)
}遍历 map:
go
m := map[string]int{
"k1": 100,
"k2": 200,
}
// 获取 key 和 value
for k, v := range m {
println(k, v)
}
// 获取 key 和 value
for k := range m {
println(k, m[k])
}
// 只获取 key
for k := range m {
println(k)
}⚠️ 重要警告:map 遍历顺序是随机的!
go
m := map[string]int{"a": 1, "b": 2, "c": 3}
for k := range m {
println(k)
}
// 每次运行顺序可能不同!不要依赖 map 的遍历顺序!
break 和 continue
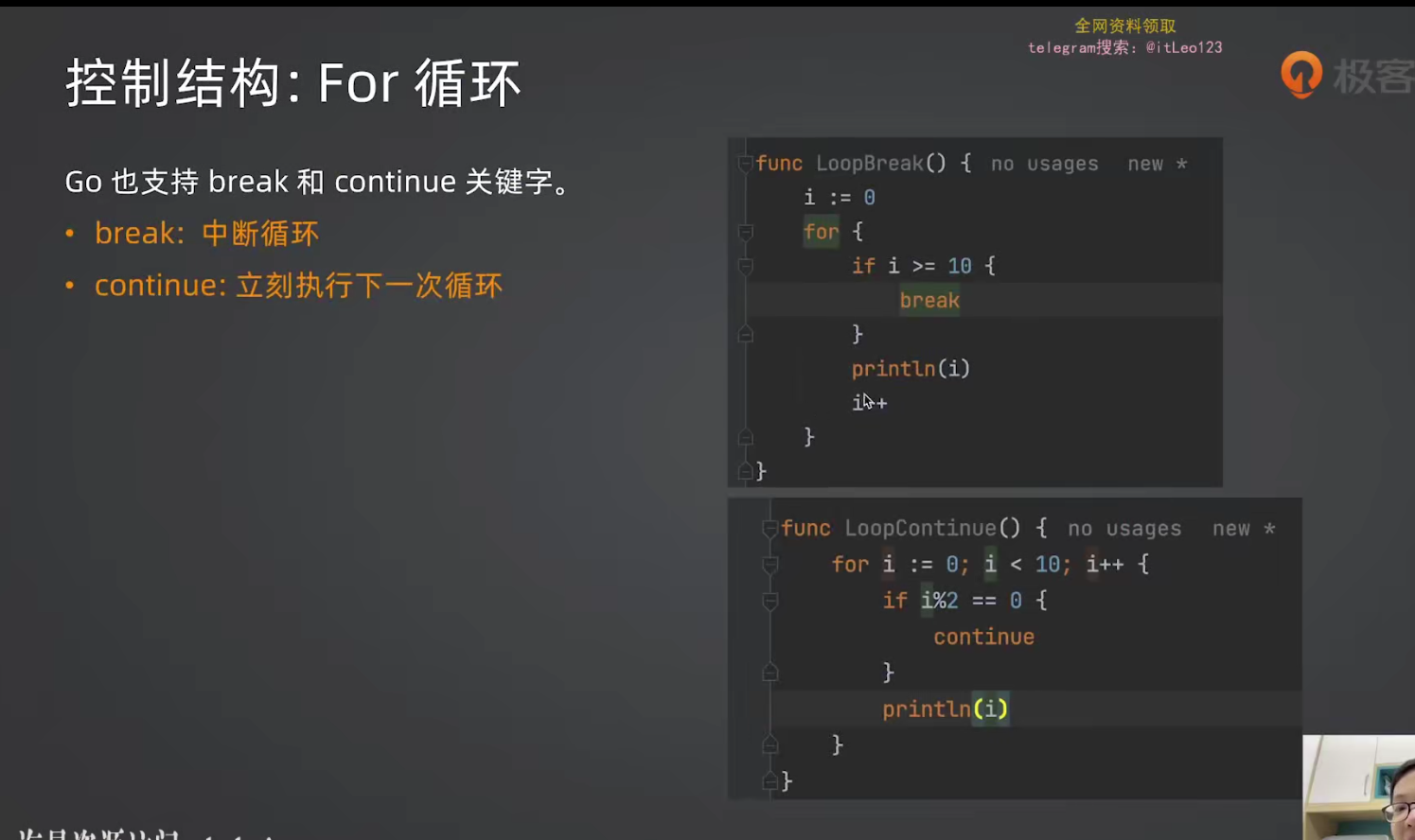
go
// break:跳出循环
for i := 0; i < 100; i++ {
if i > 10 {
break // i > 10 时跳出循环
}
println(i)
}
// continue:跳过本次循环
for i := 0; i < 10; i++ {
if i%2 == 1 {
continue // 奇数跳过
}
println(i) // 只输出偶数
}⚠️ for-range 天坑:迭代变量地址相同
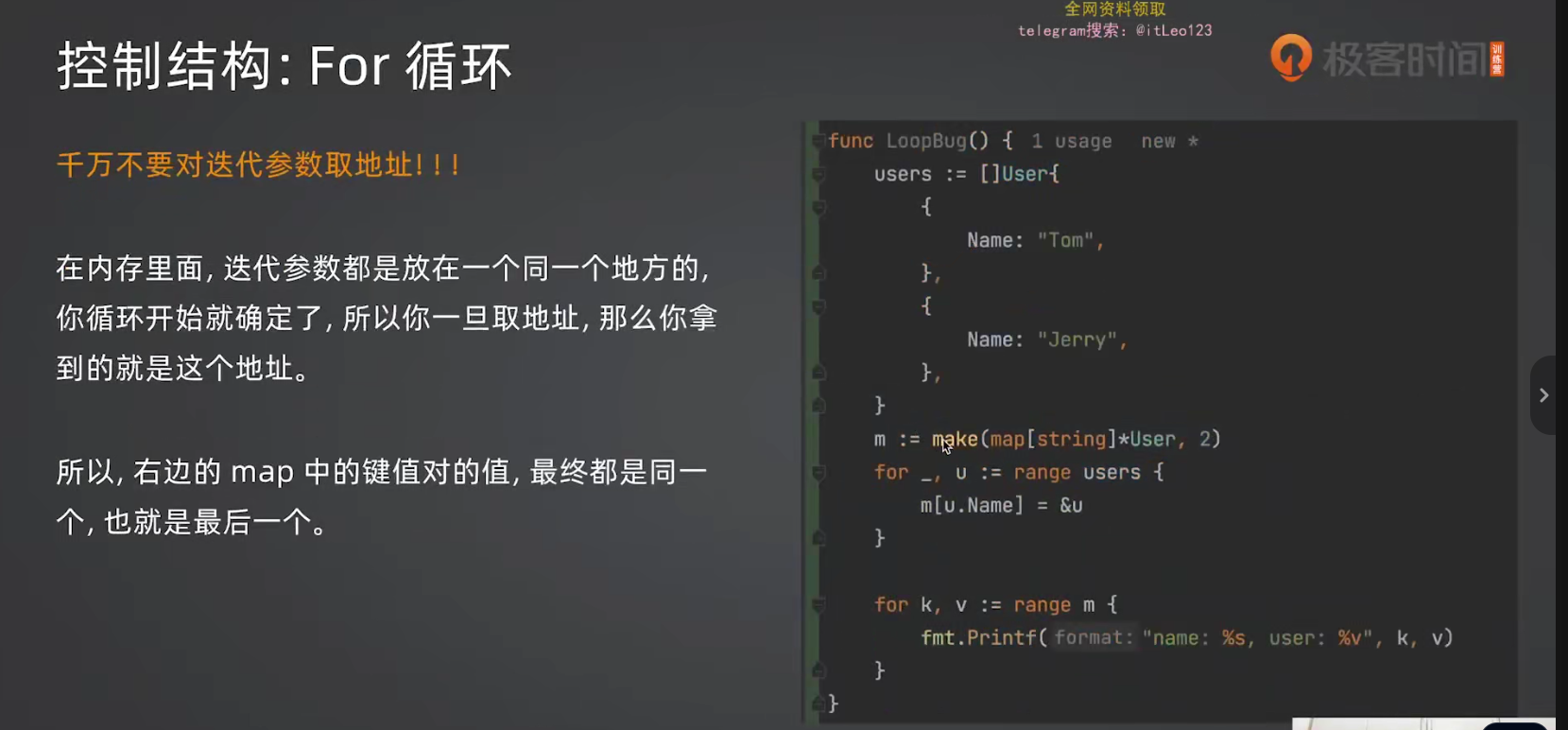
go
users := []User{
{Name: "Alice"},
{Name: "Bob"},
}
var ptrs []*User
for _, u := range users {
ptrs = append(ptrs, &u) // ❌ 错误!所有 ptrs 指向同一个地址
}
// 结果:ptrs[0] 和 ptrs[1] 指向同一个对象!正确做法:
go
for i := range users {
ptrs = append(ptrs, &users[i]) // ✅ 正确
}原则:不要对 for-range 的迭代变量(u)取地址!
6.3 switch

基本用法
go
switch status {
case 1:
println("初始化")
case 2:
println("运行中")
case 3:
println("已停止")
default:
println("未知状态")
}注意:
- 不需要写
break,Go 自动 break - 如果想继续执行下一个 case,用
fallthrough(很少用)
省略 switch 表达式
go
switch {
case age >= 60:
println("老年")
case age >= 18:
println("成年")
case age >= 12:
println("青少年")
default:
println("儿童")
}区别:
switch value:判断 value 等于哪个 caseswitch:判断哪个 case 条件为 true
switch 中定义变量
go
switch status := getStatus(); status {
case 1:
println("初始化")
case 2:
println("运行中")
default:
println("未知状态")
}
// status 在这里不可用七、方法调用总结
| 特性 | 说明 |
|---|---|
| 多返回值 | Go 支持方法返回多个值,这是与其他语言的重要区别 |
| 作用域控制 | 首字母大写 = 包外可访问,小写 = 包内私有 |
| 带名字的返回值 | 可以通过名字让返回值含义更清晰 |
| 函数是第一等公民 | 支持函数式编程,初学能看懂即可 |
| 闭包 | 方法 + 绑定的运行上下文 |
| defer | 后进先出(LIFO),在方法返回前执行 |
八、控制结构总结
| 结构 | 特点 |
|---|---|
| if-else | 可以在 if 中定义变量,作用域只在 if-else 块内 |
| for | 经典 for、while 形式、死循环、for range |
| for range | 遍历数组、切片、map;map 遍历顺序随机 |
| switch | 不需要 break,可以省略 switch 表达式 |
九、内置类型:数组(Array)
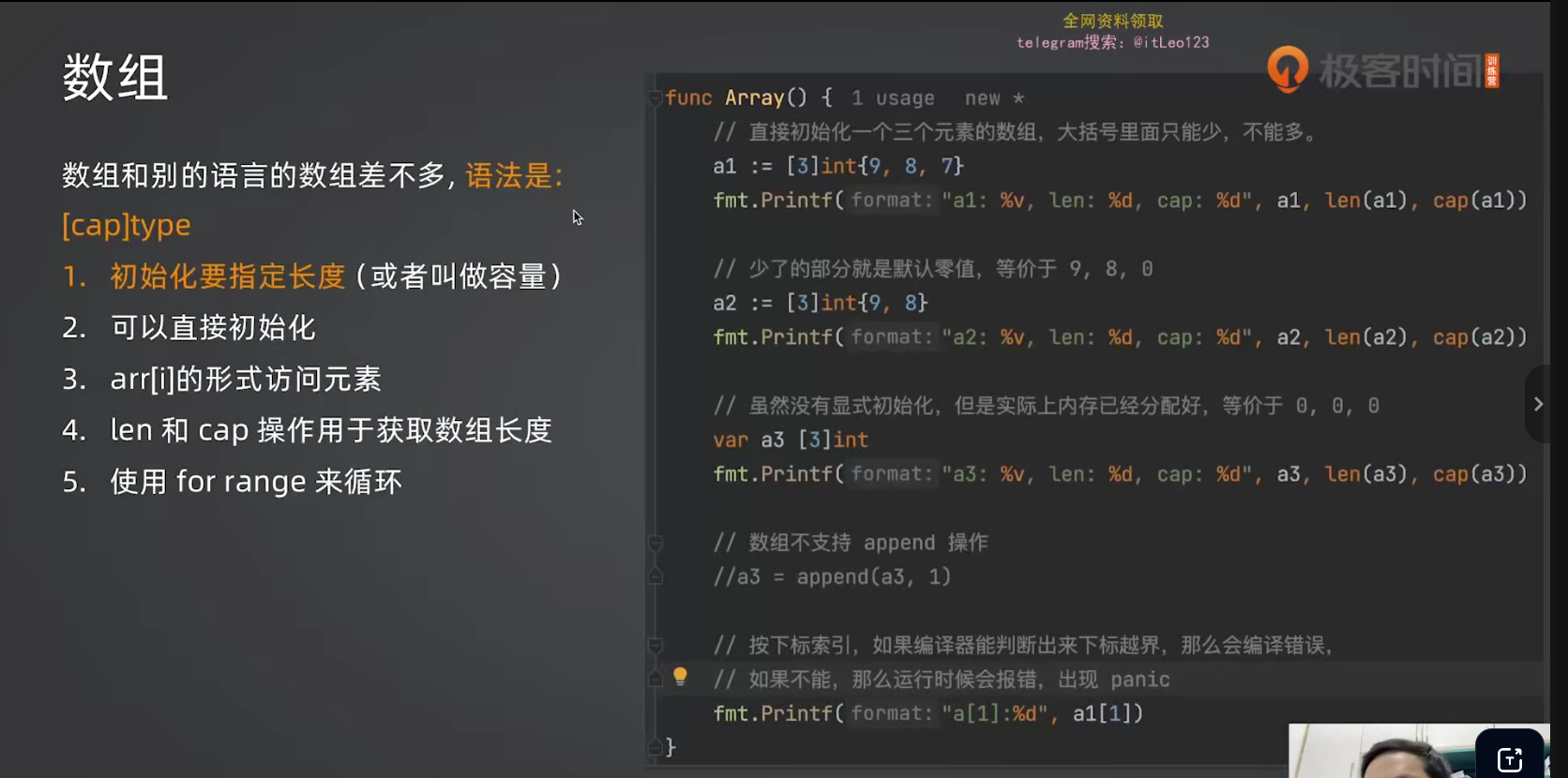
9.1 数组声明与初始化
go
// 声明一个长度为 3 的 int 数组
var a [3]int
// 直接初始化
a1 := [3]int{8, 7, 9}
// 只初始化部分元素,其余为零值
a2 := [3]int{8, 7} // [8, 7, 0]
// 一个都不初始化,全是零值
a3 := [3]int{} // [0, 0, 0]9.2 长度 vs 容量
Go 的数组同时有 len(长度)和 cap(容量)两个概念:
len:已经放了多少个元素cap:最多能放多少个元素
对于数组来说,len 和 cap 永远相等。
go
a := [3]int{8, 7}
fmt.Println(len(a)) // 3
fmt.Println(cap(a)) // 39.3 数组的特性与限制
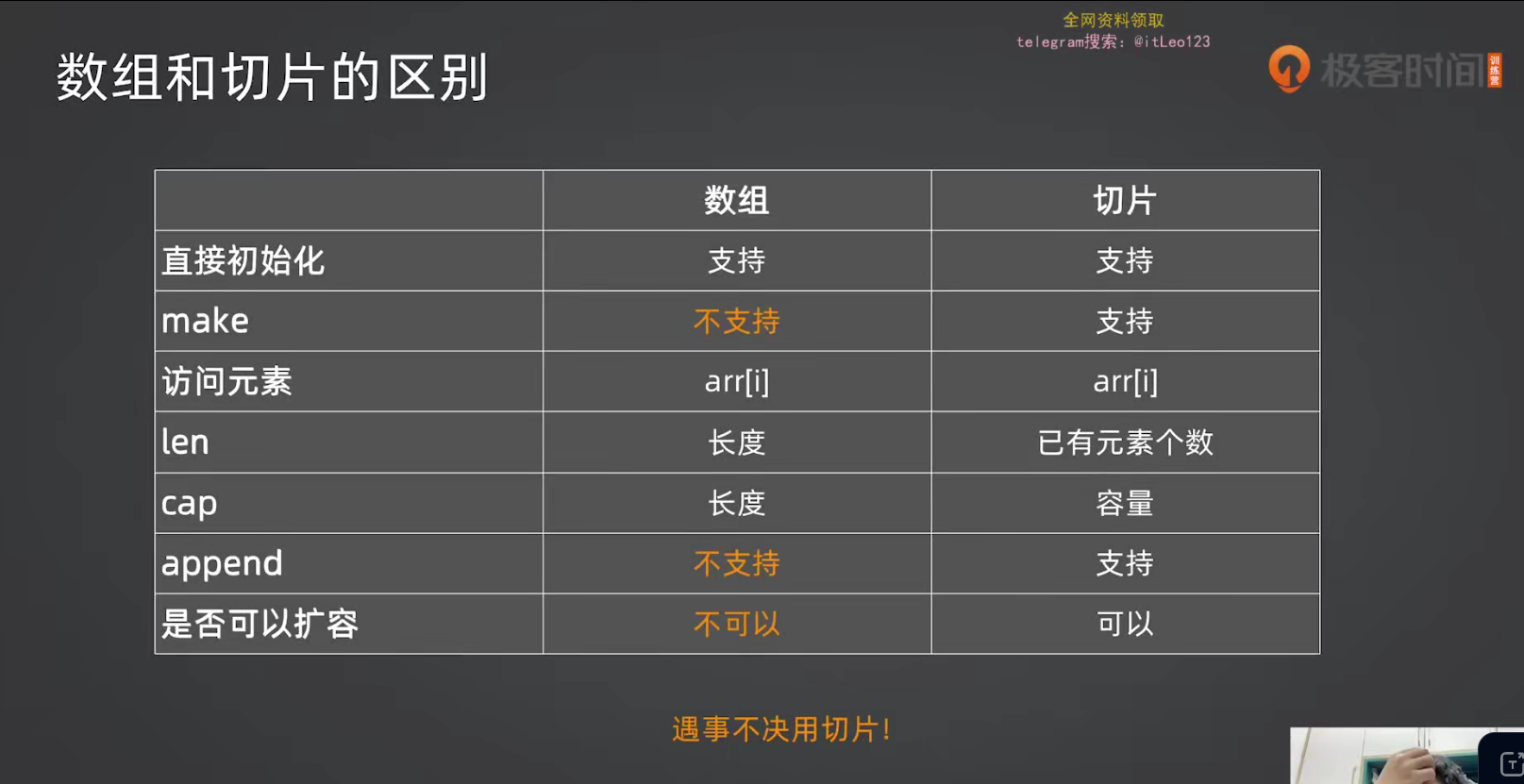
- 长度固定,不可改变 :不能对数组使用
append - 下标访问有编译期检查:下标越界连编译都通不过
- 可以用 for range 遍历,和其他类型一样
go
// 编译错误:下标越界
a := [3]int{1, 2, 3}
fmt.Println(a[3]) // invalid argument: index 3 out of bounds实际开发中绝大多数场景都用切片。基本不用数组。
十、内置类型:切片(Slice)
切片是 Go 独有的概念,可以理解为动态数组。
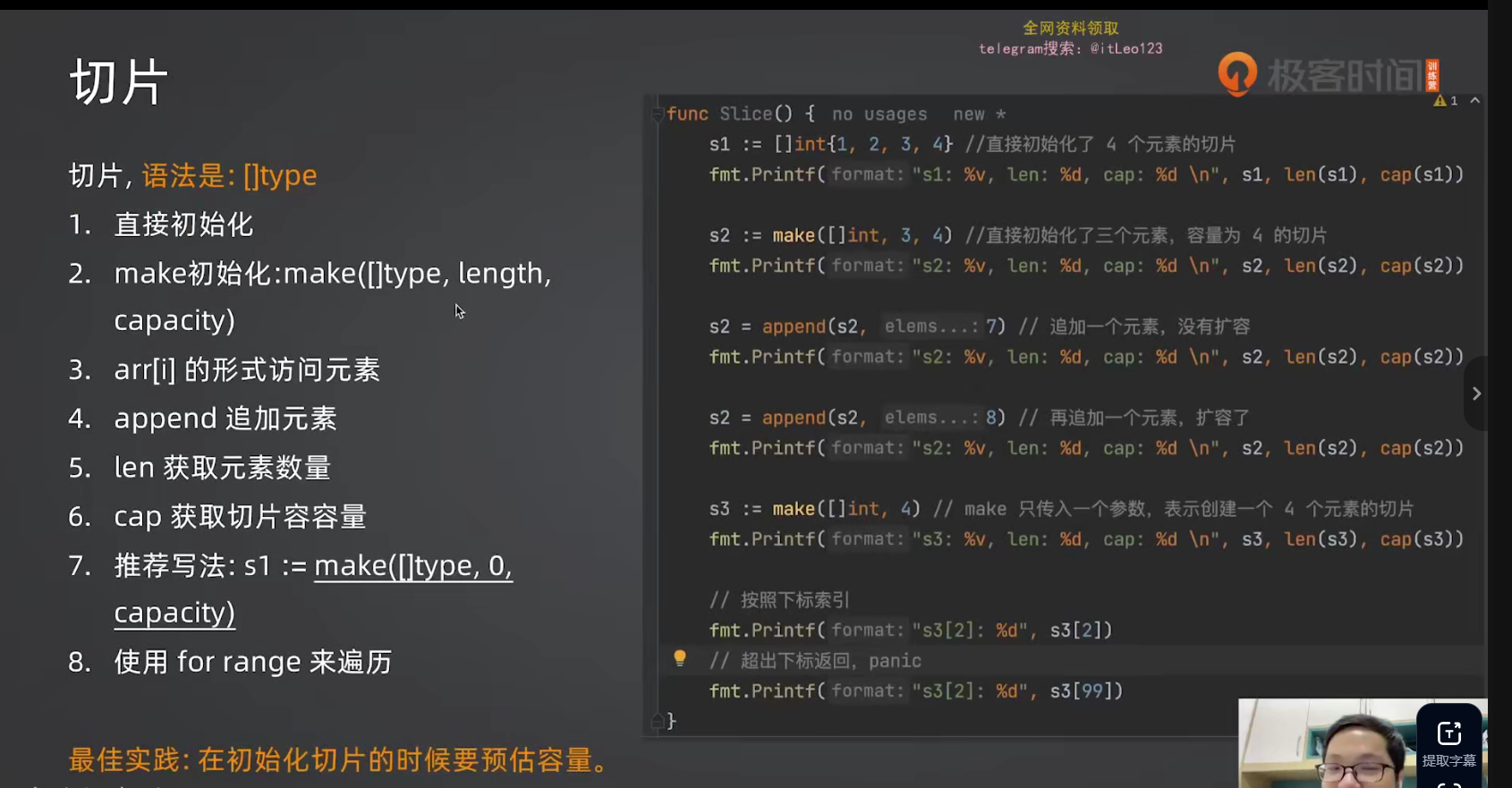

10.1 从数组到切片:删掉长度就行
go
// 数组:有长度
a := [3]int{1, 2, 3}
// 切片:没长度
s := []int{1, 2, 3}就这么一个方括号里有没有数字的区别。
10.2 用 make 创建切片
go
// make(类型, 长度, 容量)
s1 := make([]int, 3, 4) // len=3, cap=4
// 只传一个参数:长度 = 容量
s2 := make([]int, 4) // len=4, cap=4| 参数 | 含义 |
|---|---|
| 第 1 个参数 | 切片类型 |
| 第 2 个参数 | 长度(len),当前已有元素个数 |
| 第 3 个参数(可选) | 容量(cap),底层数组的大小 |
10.3 append:往切片追加元素
go
//往往这样进行初始化,长度设置为0,容量不为0,然后要加什么再用append加
s := make([]int, 0, 3) // 空切片,容量 3
s = append(s, 1) // [1], len=1, cap=3
s = append(s, 2) // [1 2], len=2, cap=3
s = append(s, 3) // [1 2 3], len=3, cap=3
s = append(s, 4) // [1 2 3 4], len=4, cap=6(扩容了!)
//或者
s := make([]int, 3) // 空切片,容量 3
s[0]=1
s[2]=2
s[3]=410.4 子切片以及核心难点:切片的底层数组共享
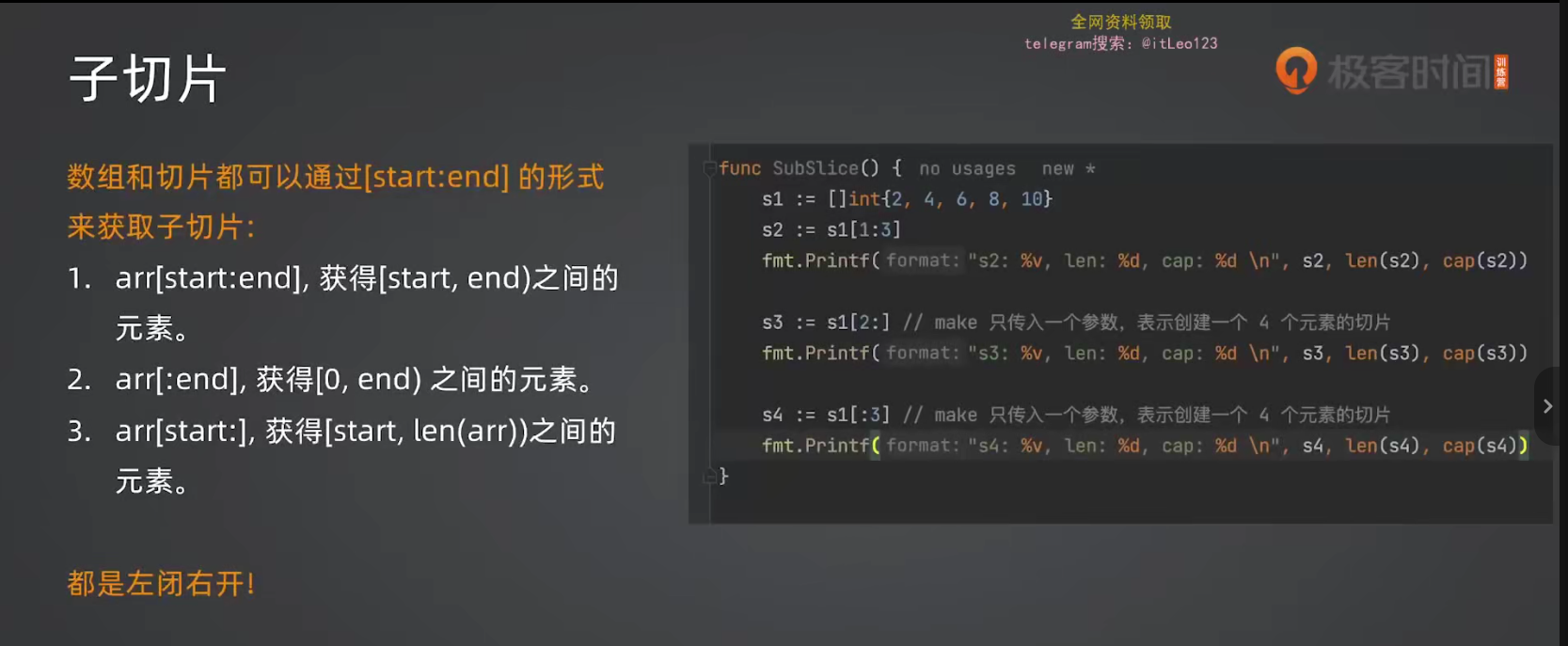

这是切片最重要、也是最容易踩坑的概念。
go
s1 := make([]int, 3, 4) // [0 0 0], len=3, cap=4
s2 := s1 // s2 和 s1 指向同一个底层数组!
s2[0] = 100
fmt.Println(s1[0]) // 100 ------ s1 也被改了!理解:切片本身只是一个窗口,多个切片可以共享同一个底层数组。修改一个切片的内容,其他共享同一底层数组的切片也会受影响。
扩容切断共享
go
s1 := make([]int, 3, 4) // [0 0 0], len=3, cap=4
s2 := s1 // 共享底层数组
s2 = append(s2, 1) // cap 还够,追加到共享数组
fmt.Println(s1[0]) // 0(没被影响,因为追加的是第 4 个位置)
s2 = append(s2, 2) // cap 不够了,扩容,分配新数组
s2[0] = 999
fmt.Println(s1[0]) // 0 ------ 扩容后已经不共享了十一、内置类型:Map
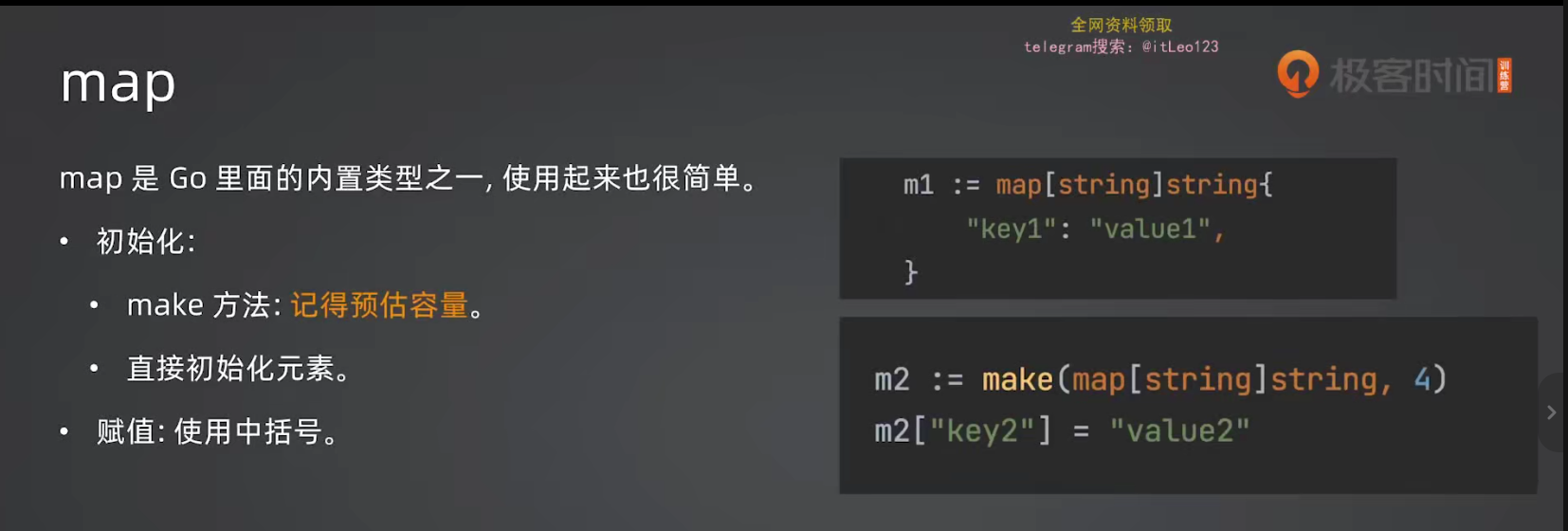
11.1 Map 的创建与基本操作
go
// 用 make 创建
m1 := make(map[string]int)
// 直接初始化
m2 := map[string]int{
"k1": 100,
"k2": 200,
}
// 赋值 也可以叫做插入
m1["key"] = 42
// 取值
v := m1["key"]
// 删除
delete(m1, "key")
// 容量
m2 := make(map[string]int,12)11.2 判断 key 是否存在
如果不存在而你又接收了,那就给你一个零值
go
v, ok := m1["key"]
if ok {
fmt.Println("存在, 值为", v)
} else {
fmt.Println("不存在")
}11.3 遍历顺序
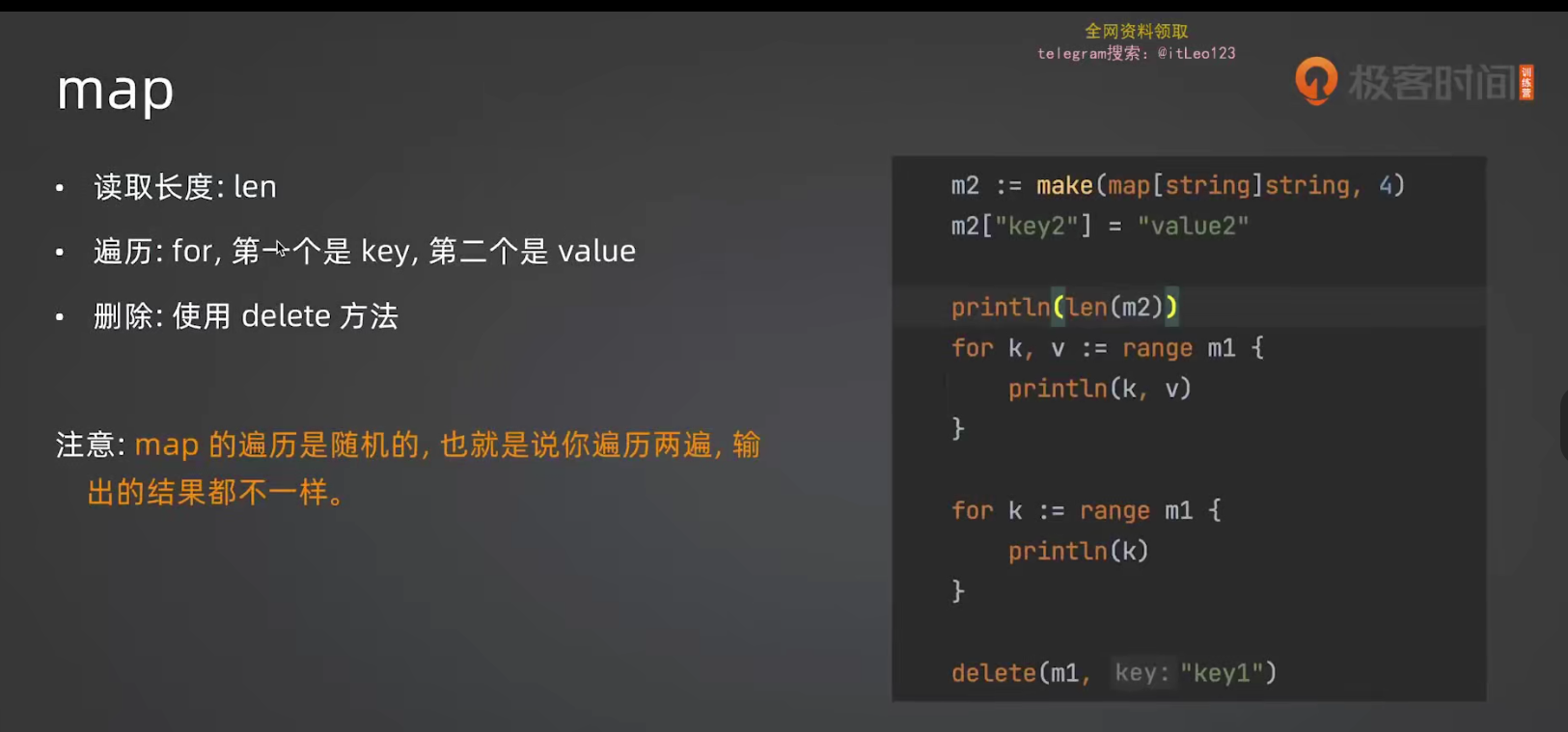
不要依赖 map 的遍历顺序! 每次 for range 遍历 map,顺序可能不同。
go
m := map[string]int{"a": 1, "b": 2, "c": 3}
for k := range m {
println(k)
}
// 每次运行的输出顺序可能不一样!11.4 关于 channel
Go 还有一个内置类型 channel,用于 goroutine 之间的通信。到后续并发章节再详细讲。
11.5 comparable概念

十二、陷阱
陷阱1:函数重载
go
// ❌ Go 不支持函数重载
func Add(a, b int) int { return a + b }
func Add(a, b float64) float64 { return a + b } // 编译错误陷阱2:递归没有退出条件
go
// ❌ stack overflow
func Recursive(n int) {
Recursive(n + 1) // 没有退出条件!
}陷阱3:defer 参数立即计算
go
i := 0
defer fmt.Println(i) // 输出 0,不是 1
i++陷阱4:for-range 取地址
go
for _, u := range users {
ptrs = append(ptrs, &u) // ❌ 所有 ptrs 指向同一个地址
}陷阱5:map 遍历顺序
go
// ❌ 不要依赖 map 的遍历顺序
for k := range m {
// 顺序是随机的!
}陷阱6:数组不能 append
go
// 编译错误
a := [3]int{1, 2, 3}
a = append(a, 4) // first argument to append must be slice陷阱7:切片底层数组共享
go
s1 := make([]int, 3, 4)
s2 := s1
s2[0] = 100
fmt.Println(s1[0]) // 100 ------ s1 被意外修改!陷阱8:map 遍历顺序随机
go
m := map[string]int{"a": 1, "b": 2, "c": 3}
for k := range m {
// 顺序每次都可能不同,不要依赖!
}陷阱9:map 取不存在的 key 返回零值
go
m := map[string]int{"a": 1}
v := m["b"] // v = 0(int 的零值),不会报错
// 正确做法:用逗号 ok 模式
v, ok := m["b"]