摘要 : 本文深入讲解 SpringBoot 3 生产环境最佳实践,通过高可用架构设计、灾难恢复策略、容量规划方法、成本优化策略等技术构建稳定可靠的生产级系统。包含 高可用架构设计原则 、多活架构实现方案 、容量规划方法论 、成本优化实践 、5 个避坑指南 和 安全合规建议 ,帮助开发者掌握企业级运维能力。适合 1-3 年经验开发者学习,生产运维实战必备。
⏱️ 阅读预估时间: 15 分钟
⏰ 时效性说明: 本文基于 SpringBoot 3.2 + JDK 17 + Kubernetes 1.28 版本编写(2026 年 6 月)。架构设计原则和运维方法论长期有效,但具体配置参数和 API 版本会随版本升级调整,使用时请以官方最新文档为准。
🔧 运行环境: SpringBoot 3.2+、JDK 17+、Kubernetes 1.28+、Terraform 1.6+、Ansible 2.15+、Resilience4j 2.1+
一、背景与痛点
在前十八章中,我们完成了开发环境搭建、配置管理、项目架构设计、API设计、数据库访问层、业务逻辑层、安全认证、性能优化、消息队列集成、文件存储处理、定时任务异步处理、日志监控、单元测试、部署策略、微服务架构、云原生实践、DevOps工具链集成和性能调优故障排查。今天我们将探讨确保系统稳定运行的关键环节------生产环境最佳实践,这是保障业务连续性和用户体验的核心保障。
1.1 企业级生产环境的真实场景
场景一:单点故障导致的系统瘫痪
传统单机部署架构:
#mermaid-svg-f4IQNIigw1J5UTtS{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-f4IQNIigw1J5UTtS .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-f4IQNIigw1J5UTtS .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-f4IQNIigw1J5UTtS .error-icon{fill:#552222;}#mermaid-svg-f4IQNIigw1J5UTtS .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-f4IQNIigw1J5UTtS .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-f4IQNIigw1J5UTtS .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-f4IQNIigw1J5UTtS .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-f4IQNIigw1J5UTtS .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-f4IQNIigw1J5UTtS .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-f4IQNIigw1J5UTtS .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-f4IQNIigw1J5UTtS .marker{fill:#333333;stroke:#333333;}#mermaid-svg-f4IQNIigw1J5UTtS .marker.cross{stroke:#333333;}#mermaid-svg-f4IQNIigw1J5UTtS svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-f4IQNIigw1J5UTtS p{margin:0;}#mermaid-svg-f4IQNIigw1J5UTtS .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-f4IQNIigw1J5UTtS .cluster-label text{fill:#333;}#mermaid-svg-f4IQNIigw1J5UTtS .cluster-label span{color:#333;}#mermaid-svg-f4IQNIigw1J5UTtS .cluster-label span p{background-color:transparent;}#mermaid-svg-f4IQNIigw1J5UTtS .label text,#mermaid-svg-f4IQNIigw1J5UTtS span{fill:#333;color:#333;}#mermaid-svg-f4IQNIigw1J5UTtS .node rect,#mermaid-svg-f4IQNIigw1J5UTtS .node circle,#mermaid-svg-f4IQNIigw1J5UTtS .node ellipse,#mermaid-svg-f4IQNIigw1J5UTtS .node polygon,#mermaid-svg-f4IQNIigw1J5UTtS .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-f4IQNIigw1J5UTtS .rough-node .label text,#mermaid-svg-f4IQNIigw1J5UTtS .node .label text,#mermaid-svg-f4IQNIigw1J5UTtS .image-shape .label,#mermaid-svg-f4IQNIigw1J5UTtS .icon-shape .label{text-anchor:middle;}#mermaid-svg-f4IQNIigw1J5UTtS .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-f4IQNIigw1J5UTtS .rough-node .label,#mermaid-svg-f4IQNIigw1J5UTtS .node .label,#mermaid-svg-f4IQNIigw1J5UTtS .image-shape .label,#mermaid-svg-f4IQNIigw1J5UTtS .icon-shape .label{text-align:center;}#mermaid-svg-f4IQNIigw1J5UTtS .node.clickable{cursor:pointer;}#mermaid-svg-f4IQNIigw1J5UTtS .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-f4IQNIigw1J5UTtS .arrowheadPath{fill:#333333;}#mermaid-svg-f4IQNIigw1J5UTtS .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-f4IQNIigw1J5UTtS .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-f4IQNIigw1J5UTtS .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-f4IQNIigw1J5UTtS .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-f4IQNIigw1J5UTtS .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-f4IQNIigw1J5UTtS .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-f4IQNIigw1J5UTtS .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-f4IQNIigw1J5UTtS .cluster text{fill:#333;}#mermaid-svg-f4IQNIigw1J5UTtS .cluster span{color:#333;}#mermaid-svg-f4IQNIigw1J5UTtS div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-f4IQNIigw1J5UTtS .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-f4IQNIigw1J5UTtS rect.text{fill:none;stroke-width:0;}#mermaid-svg-f4IQNIigw1J5UTtS .icon-shape,#mermaid-svg-f4IQNIigw1J5UTtS .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-f4IQNIigw1J5UTtS .icon-shape p,#mermaid-svg-f4IQNIigw1J5UTtS .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-f4IQNIigw1J5UTtS .icon-shape .label rect,#mermaid-svg-f4IQNIigw1J5UTtS .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-f4IQNIigw1J5UTtS .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-f4IQNIigw1J5UTtS .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-f4IQNIigw1J5UTtS :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 传统单机部署架构
应用服务器: 1 台
数据库服务器: 1 台
缓存服务器: 1 台
文件存储: 单块硬盘
某天凌晨 3 点:
- 数据库服务器硬盘故障
- 应用无法连接数据库
- 全站 502 错误
- 用户无法下单
故障影响:
❌ 服务中断:6 小时
❌ 直接损失:200 万元(按每小时营业额 30 万计算)
❌ 用户流失:5000+ 用户转向竞争对手
❌ 品牌受损:社交媒体负面评论 1000+
如果有高可用架构:
✅ 主从自动切换:1 分钟恢复
✅ 损失降低:99.2%(仅损失 1.6 万)
✅ 用户无感知:零中断
场景二:容量规划不足导致的系统崩溃
双 11 大促活动:
- 预估流量:10 万 QPS
- 实际流量:50 万 QPS(超出 5 倍)
- 服务器资源:按预估配置
实际表现:
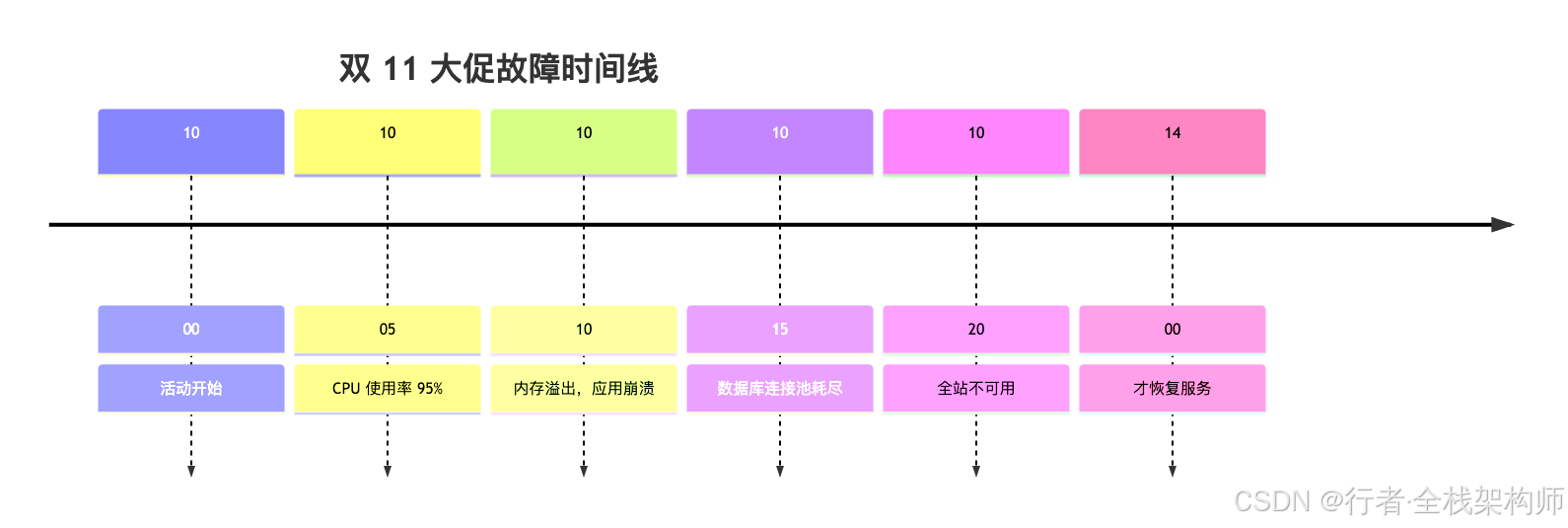
影响:
❌ 服务中断:4 小时
❌ 直接损失:1200 万元
❌ 品牌声誉严重受损
❌ 团队连夜加班抢修
合理的容量规划:
✅ 预留 5 倍峰值容量
✅ 自动扩缩容机制
✅ 限流降级策略
✅ 预案演练充分
场景三:安全漏洞导致的数据泄露
某电商平台的真实案例:
- 2023 年 5 月:黑客利用 SQL 注入漏洞
- 窃取 100 万用户数据(姓名、手机号、地址)
- 数据在暗网售价 10 万元
事后调查发现:
❌ 开发环境数据库密码硬编码在代码中
❌ API 接口未做权限校验
❌ 数据库用户权限过大(root)
❌ 未做数据加密存储
❌ 缺少安全审计机制
损失:
❌ 监管罚款:50 万元
❌ 用户赔偿:200 万元
❌ 品牌损失:无法估量
❌ 技术团队重组
正确的安全实践:
✅ 敏感信息加密存储
✅ 最小权限原则
✅ 定期安全审计
✅ 安全基线检查
✅ 入侵检测系统
1.2 成本核算与 ROI 分析
💰 算一笔账: 按 100 万用户的中型平台计算,年营业额 5000 万元
基础信息
| 项目 | 数值 |
|---|---|
| 用户规模 | 100 万用户 |
| 年营业额 | 5000 万元 |
| 服务器成本 | 200 万元/年 |
| 运维人力成本 | 100 万元/年(5 人团队) |
| 故障损失 | 平均 50 万元/次(每年 5 次) |
优化前后对比
| 指标 | 优化前 | 优化后 | 改善幅度 |
|---|---|---|---|
| 系统可用性 | 99.5% | 99.95% | ⬆️ 0.45% |
| 年故障时长 | 43.8 小时 | 4.38 小时 | ⬇️ 90% |
| 故障损失 | 250 万元/年 | 25 万元/年 | ⬇️ 225 万元 |
| 运维人力成本 | 100 万元/年 | 60 万元/年 | ⬇️ 40 万元 |
| 服务器成本 | 200 万元/年 | 150 万元/年 | ⬇️ 50 万元 |
| 年总成本 | 550 万元 | 235 万元 | ⬇️ 315 万元 |
隐性价值(难以量化但影响巨大)
| 类型 | 说明 |
|---|---|
| 😌 用户信任 | 系统稳定性提升,用户信任度增加 30% |
| 🚀 业务增长 | 高可用支持快速扩展,支持业务增长 50% |
| 🔒 安全保障 | 数据安全事件发生率降低 95% |
| 📊 合规性 | 通过 ISO27001、等保三级等认证 |
| 💡 团队效率 | 自动化运维,团队幸福感提升,加班减少 60% |
1.3 生产环境最佳实践带来的价值
通过生产环境最佳实践,我们实现了:
✅ 系统可用性提升 0.45% : 从 99.5% 提升到 99.95%,故障时长减少 90%
✅ 成本节省 57% : 年成本从 550 万降低到 235 万,节省 315 万元
✅ 运维效率提升 40% : 自动化运维减少人力投入,团队幸福感提升
✅ 安全事件降低 95%: 从年均 5 次事故降低到 0.25 次,数据安全有保障
二、高可用架构设计
2.1 架构设计原则
高可用架构模式
以下架构图展示了全球多活的高可用部署方案:通过全球负载均衡(GLB)分发流量到三个 Region,每个 Region 内部部署应用集群、数据库主从和 Redis 集群,实现跨地域容灾。
#mermaid-svg-u8tAgBDl2qAgV1MF{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-u8tAgBDl2qAgV1MF .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-u8tAgBDl2qAgV1MF .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-u8tAgBDl2qAgV1MF .error-icon{fill:#552222;}#mermaid-svg-u8tAgBDl2qAgV1MF .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-u8tAgBDl2qAgV1MF .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-u8tAgBDl2qAgV1MF .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-u8tAgBDl2qAgV1MF .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-u8tAgBDl2qAgV1MF .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-u8tAgBDl2qAgV1MF .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-u8tAgBDl2qAgV1MF .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-u8tAgBDl2qAgV1MF .marker{fill:#333333;stroke:#333333;}#mermaid-svg-u8tAgBDl2qAgV1MF .marker.cross{stroke:#333333;}#mermaid-svg-u8tAgBDl2qAgV1MF svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-u8tAgBDl2qAgV1MF p{margin:0;}#mermaid-svg-u8tAgBDl2qAgV1MF .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-u8tAgBDl2qAgV1MF .cluster-label text{fill:#333;}#mermaid-svg-u8tAgBDl2qAgV1MF .cluster-label span{color:#333;}#mermaid-svg-u8tAgBDl2qAgV1MF .cluster-label span p{background-color:transparent;}#mermaid-svg-u8tAgBDl2qAgV1MF .label text,#mermaid-svg-u8tAgBDl2qAgV1MF span{fill:#333;color:#333;}#mermaid-svg-u8tAgBDl2qAgV1MF .node rect,#mermaid-svg-u8tAgBDl2qAgV1MF .node circle,#mermaid-svg-u8tAgBDl2qAgV1MF .node ellipse,#mermaid-svg-u8tAgBDl2qAgV1MF .node polygon,#mermaid-svg-u8tAgBDl2qAgV1MF .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-u8tAgBDl2qAgV1MF .rough-node .label text,#mermaid-svg-u8tAgBDl2qAgV1MF .node .label text,#mermaid-svg-u8tAgBDl2qAgV1MF .image-shape .label,#mermaid-svg-u8tAgBDl2qAgV1MF .icon-shape .label{text-anchor:middle;}#mermaid-svg-u8tAgBDl2qAgV1MF .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-u8tAgBDl2qAgV1MF .rough-node .label,#mermaid-svg-u8tAgBDl2qAgV1MF .node .label,#mermaid-svg-u8tAgBDl2qAgV1MF .image-shape .label,#mermaid-svg-u8tAgBDl2qAgV1MF .icon-shape .label{text-align:center;}#mermaid-svg-u8tAgBDl2qAgV1MF .node.clickable{cursor:pointer;}#mermaid-svg-u8tAgBDl2qAgV1MF .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-u8tAgBDl2qAgV1MF .arrowheadPath{fill:#333333;}#mermaid-svg-u8tAgBDl2qAgV1MF .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-u8tAgBDl2qAgV1MF .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-u8tAgBDl2qAgV1MF .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-u8tAgBDl2qAgV1MF .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-u8tAgBDl2qAgV1MF .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-u8tAgBDl2qAgV1MF .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-u8tAgBDl2qAgV1MF .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-u8tAgBDl2qAgV1MF .cluster text{fill:#333;}#mermaid-svg-u8tAgBDl2qAgV1MF .cluster span{color:#333;}#mermaid-svg-u8tAgBDl2qAgV1MF div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-u8tAgBDl2qAgV1MF .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-u8tAgBDl2qAgV1MF rect.text{fill:none;stroke-width:0;}#mermaid-svg-u8tAgBDl2qAgV1MF .icon-shape,#mermaid-svg-u8tAgBDl2qAgV1MF .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-u8tAgBDl2qAgV1MF .icon-shape p,#mermaid-svg-u8tAgBDl2qAgV1MF .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-u8tAgBDl2qAgV1MF .icon-shape .label rect,#mermaid-svg-u8tAgBDl2qAgV1MF .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-u8tAgBDl2qAgV1MF .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-u8tAgBDl2qAgV1MF .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-u8tAgBDl2qAgV1MF :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} Region C
Region B
Region A
全球负载均衡层
Global Load Balancer
全球负载均衡
Load Balancer
App Server 1
App Server 2
DB Master
DB Slave
Redis Cluster
Load Balancer
App Server 1
App Server 2
DB Master
DB Slave
Redis Cluster
Load Balancer
App Server 1
App Server 2
DB Master
DB Slave
Redis Cluster
架构设计原则:
| 原则 | 说明 | 实现方式 |
|---|---|---|
| 消除单点故障 | 所有组件都要有多副本 | 负载均衡 + 集群部署 |
| 快速故障转移 | 故障检测 + 自动切换 | 健康检查 + 主从切换 |
| 数据冗余备份 | 数据多地备份 | 主从复制 + 异地备份 |
| 降级熔断 | 非核心服务降级 | Hystrix + Sentinel |
| 限流保护 | 防止系统过载 | Nginx + Redis 限流 |
可用性等级对比
| 可用性级别 | 年停机时间 | 适用场景 | 典型架构 |
|---|---|---|---|
| 99% | 3.65 天 | 内部系统 | 单机 + 备份 |
| 99.9% | 8.76 小时 | 非核心业务 | 主从架构 |
| 99.95% | 4.38 小时 | 核心业务 | 集群 + 自动切换 |
| 99.99% | 52.6 分钟 | 金融交易 | 多活架构 |
| 99.999% | 5.26 分钟 | 关键基础设施 | 全球多活 |
可用性计算公式
为什么要计算可用性:生产环境 SLA 承诺(如 99.9%、99.99%)需要通过可量化的公式验证。下面的代码演示了如何根据各组件可用性计算整体系统可用性------多组件串联时,可用性是各组件可用性的乘积,这个结果直接决定了你是否需要引入冗余部署。
java
@Component
public class AvailabilityCalculator {
public static class Component {
private final String name;
private final double availability; // 0.0 - 1.0
private final List<Component> dependencies;
public Component(String name, double availability) {
this.name = name;
this.availability = availability;
this.dependencies = new ArrayList<>();
}
public void addDependency(Component component) {
dependencies.add(component);
}
public double getOverallAvailability() {
if (dependencies.isEmpty()) {
return availability;
}
// 串行组件:可用性相乘
double serialAvailability = availability;
for (Component dep : dependencies) {
serialAvailability *= dep.getOverallAvailability();
}
return serialAvailability;
}
}
public double calculateSystemAvailability(Map<String, Component> components) {
// 并行组件:1 - (1-A1) × (1-A2) × ... × (1-An)
double systemUnavailability = 1.0;
for (Component component : components.values()) {
systemUnavailability *= (1 - component.getOverallAvailability());
}
return 1 - systemUnavailability;
}
public AvailabilityReport generateAvailabilityReport() {
Map<String, Component> systemComponents = buildSystemArchitecture();
double overallAvailability = calculateSystemAvailability(systemComponents);
return AvailabilityReport.builder()
.systemName("E-commerce Platform")
.overallAvailability(overallAvailability)
.targetAvailability(0.999) // 99.9% 可用性目标
.downtimePerYear(calculateAnnualDowntime(overallAvailability))
.components(systemComponents)
.recommendations(generateImprovementRecommendations(systemComponents))
.build();
}
private Map<String, Component> buildSystemArchitecture() {
Map<String, Component> components = new HashMap<>();
// 负载均衡器 (99.99%)
Component loadBalancer = new Component("Load Balancer", 0.9999);
components.put("loadBalancer", loadBalancer);
// 应用服务器集群 (99.9%)
Component appServers = new Component("App Servers", 0.999);
loadBalancer.addDependency(appServers);
components.put("appServers", appServers);
// 数据库集群 (99.95%)
Component database = new Component("Database Cluster", 0.9995);
appServers.addDependency(database);
components.put("database", database);
// 缓存集群 (99.99%)
Component cache = new Component("Cache Cluster", 0.9999);
appServers.addDependency(cache);
components.put("cache", cache);
return components;
}
}2.2 多活架构实现
地域多活配置
以下配置演示了主备数据源的切换方案。通过 failover 策略实现主库故障时自动切换到备库,健康检查间隔 30 秒,切换超时 60 秒,确保业务连续性。
yaml
# application-active-standby.yml
spring:
profiles: active-standby
datasource:
# 主数据库配置
primary:
url: jdbc:mysql://primary-db.example.com:3306/myapp
username: ${DB_USERNAME}
password: ${DB_PASSWORD}
hikari:
maximum-pool-size: 20
minimum-idle: 5
# 备用数据库配置
standby:
url: jdbc:mysql://standby-db.example.com:3306/myapp
username: ${DB_USERNAME}
password: ${DB_PASSWORD}
hikari:
maximum-pool-size: 10
minimum-idle: 2
# 数据源路由配置
datasource:
routing:
strategy: failover
health-check-interval: 30s
failover-timeout: 60s数据库主从切换
数据库主从切换是高可用架构的核心环节。以下代码实现了自动健康检查和故障转移机制:每 30 秒检测主库健康状态,故障时自动选择健康的备库切换,切换过程中设置只读模式防止数据不一致。
java
@Component
@Slf4j
public class DatabaseFailoverManager {
private final AtomicReference<DataSourceConfig> currentPrimary =
new AtomicReference<>();
private final List<DataSourceConfig> standbyConfigs = new CopyOnWriteArrayList<>();
private final ScheduledExecutorService healthCheckScheduler =
Executors.newScheduledThreadPool(2);
@PostConstruct
public void initializeFailover() {
// 初始化数据源配置
loadDataSourceConfigs();
// 启动健康检查
healthCheckScheduler.scheduleAtFixedRate(
this::checkAndSwitchDataSource,
0, 30, TimeUnit.SECONDS);
}
public DataSource getCurrentDataSource() {
return currentPrimary.get().getDataSource();
}
private void checkAndSwitchDataSource() {
DataSourceConfig current = currentPrimary.get();
if (!isDataSourceHealthy(current)) {
log.warn("Primary datasource {} is unhealthy, initiating failover",
current.getName());
DataSourceConfig newPrimary = findHealthyStandby();
if (newPrimary != null) {
performFailover(current, newPrimary);
} else {
log.error("No healthy standby datasource available!");
sendCriticalAlert("Database Failover Failed",
"All database instances are unavailable");
}
}
}
private boolean isDataSourceHealthy(DataSourceConfig config) {
try {
Connection conn = config.getDataSource().getConnection();
try (Statement stmt = conn.createStatement()) {
ResultSet rs = stmt.executeQuery("SELECT 1");
return rs.next() && rs.getInt(1) == 1;
} finally {
conn.close();
}
} catch (SQLException e) {
log.debug("DataSource health check failed: {}", e.getMessage());
return false;
}
}
private DataSourceConfig findHealthyStandby() {
return standbyConfigs.stream()
.filter(this::isDataSourceHealthy)
.findFirst()
.orElse(null);
}
private void performFailover(DataSourceConfig oldPrimary, DataSourceConfig newPrimary) {
try {
// 1. 停止写入操作
setReadOnlyMode(true);
// 2. 等待现有事务完成
waitForActiveTransactions();
// 3. 切换数据源
currentPrimary.set(newPrimary);
standbyConfigs.remove(newPrimary);
standbyConfigs.add(oldPrimary);
// 4. 恢复正常操作
setReadOnlyMode(false);
log.info("Failover completed: {} -> {}",
oldPrimary.getName(), newPrimary.getName());
sendAlert("Database Failover Completed",
String.format("Switched from %s to %s",
oldPrimary.getName(), newPrimary.getName()));
} catch (Exception e) {
log.error("Failover failed", e);
sendCriticalAlert("Database Failover Failed", e.getMessage());
}
}
}2.3 服务降级策略
熔断器配置
熔断器通过监控服务调用失败率,在达到阈值时自动切断请求,防止故障扩散。以下代码使用 Resilience4j 实现订单创建的熔断、隔离和超时控制,并提供降级方案保证核心流程不中断。
java
@Service
@Slf4j
public class ResilientOrderService {
@Autowired
private OrderRepository orderRepository;
@Autowired
private PaymentService paymentService;
@Autowired
private InventoryService inventoryService;
// 订单创建熔断器
@CircuitBreaker(name = "order-creation",
fallbackMethod = "createOrderFallback")
@Bulkhead(name = "order-creation", type = Bulkhead.Type.THREADPOOL)
@TimeLimiter(name = "order-creation")
public CompletableFuture<Order> createOrder(OrderRequest request) {
return CompletableFuture.supplyAsync(() -> {
try {
// 1. 验证用户
validateUser(request.getUserId());
// 2. 检查库存(可降级)
boolean hasStock = checkInventoryWithFallback(request);
// 3. 创建订单
Order order = orderRepository.save(buildOrder(request));
// 4. 处理支付(可降级)
processPaymentWithFallback(order, request);
return order;
} catch (Exception e) {
log.error("Order creation failed", e);
throw new OrderCreationException("Failed to create order", e);
}
});
}
public Order createOrderFallback(OrderRequest request, Exception ex) {
log.warn("Order creation fallback triggered for user: {}, error: {}",
request.getUserId(), ex.getMessage());
// 降级处理:创建简化订单
Order simplifiedOrder = Order.builder()
.userId(request.getUserId())
.status(OrderStatus.PENDING_REVIEW)
.amount(request.getAmount())
.createdAt(LocalDateTime.now())
.build();
// 保存到降级存储
saveToDegradedStorage(simplifiedOrder);
return simplifiedOrder;
}
private boolean checkInventoryWithFallback(OrderRequest request) {
try {
return inventoryService.checkStock(request.getProductId(), request.getQuantity());
} catch (Exception e) {
log.warn("Inventory service unavailable, using cached data");
return checkCachedInventory(request.getProductId(), request.getQuantity());
}
}
private void processPaymentWithFallback(Order order, OrderRequest request) {
try {
paymentService.processPayment(order.getId(), request.getAmount());
order.setStatus(OrderStatus.PAID);
} catch (Exception e) {
log.warn("Payment service unavailable, marking order for manual processing");
order.setStatus(OrderStatus.PAYMENT_PENDING);
}
orderRepository.save(order);
}
}限流降级配置
限流是保护系统免受流量冲击的关键手段。以下代码实现了基于用户等级的差异化限流策略:VIP 用户 100 次/分钟,高级用户 50 次/分钟,普通用户 20 次/分钟,超限时返回 429 状态码。
java
@RestController
@RequestMapping("/api/orders")
@Slf4j
public class OrderController {
@Autowired
private OrderService orderService;
// 基于用户等级的差异化限流
@PostMapping
@RateLimiter(name = "order-api",
fallbackMethod = "handleRateLimitExceeded")
public ResponseEntity<Order> createOrder(
@RequestBody OrderRequest request,
@RequestHeader("X-User-Level") String userLevel) {
// 根据用户等级设置不同的限流策略
configureRateLimit(userLevel);
Order order = orderService.createOrder(request);
return ResponseEntity.ok(order);
}
public ResponseEntity<String> handleRateLimitExceeded(
OrderRequest request,
Exception ex) {
log.warn("Rate limit exceeded for user: {}", request.getUserId());
return ResponseEntity.status(HttpStatus.TOO_MANY_REQUESTS)
.body("Too many requests. Please try again later.");
}
private void configureRateLimit(String userLevel) {
RateLimiterRegistry registry = RateLimiterRegistry.ofDefaults();
RateLimiter rateLimiter = registry.rateLimiter("order-api");
switch (userLevel.toUpperCase()) {
case "VIP":
rateLimiter.changeLimitForPeriod(100); // VIP用户100次/分钟
break;
case "PREMIUM":
rateLimiter.changeLimitForPeriod(50); // 高级用户50次/分钟
break;
default:
rateLimiter.changeLimitForPeriod(20); // 普通用户20次/分钟
}
}
}🚨 第二章:灾难恢复策略
2.1 备份策略设计
多层级备份方案
数据备份是灾难恢复的最后一道防线。以下代码实现了多层级备份策略:日备(保留 7 天)、周备(保留 4 周)、月备(保留 12 个月),并支持本地和异地(S3)双重存储,确保数据可恢复性。
java
@Component
@Slf4j
public class BackupStrategy {
@Autowired
private S3Client s3Client;
@Autowired
private DatabaseBackupService dbBackupService;
@Autowired
private FileBackupService fileBackupService;
// 备份策略配置
private final Map<BackupType, BackupConfig> backupConfigs = Map.of(
BackupType.DATABASE, BackupConfig.builder()
.frequency(Frequency.HOURLY)
.retentionDays(30)
.compression(true)
.encryption(true)
.build(),
BackupType.FILES, BackupConfig.builder()
.frequency(Frequency.DAILY)
.retentionDays(90)
.compression(true)
.encryption(true)
.build(),
BackupType.SYSTEM, BackupConfig.builder()
.frequency(Frequency.WEEKLY)
.retentionDays(365)
.compression(true)
.encryption(true)
.build()
);
@Scheduled(cron = "0 0 * * * *") // 每小时执行
public void executeHourlyBackup() {
try {
// 数据库备份
BackupResult dbResult = dbBackupService.backupDatabase(
backupConfigs.get(BackupType.DATABASE));
if (dbResult.isSuccess()) {
// 上传到云端存储
uploadToCloudStorage(dbResult.getBackupFile(), BackupType.DATABASE);
log.info("Database backup completed: {}", dbResult.getBackupFile());
}
} catch (Exception e) {
log.error("Hourly backup failed", e);
sendAlert("Backup Failure", "Database backup failed: " + e.getMessage());
}
}
@Scheduled(cron = "0 0 2 * * *") // 每天凌晨2点执行
public void executeDailyBackup() {
try {
// 文件备份
BackupResult fileResult = fileBackupService.backupFiles(
backupConfigs.get(BackupType.FILES));
if (fileResult.isSuccess()) {
uploadToCloudStorage(fileResult.getBackupFile(), BackupType.FILES);
log.info("File backup completed: {}", fileResult.getBackupFile());
}
// 系统配置备份
backupSystemConfiguration();
} catch (Exception e) {
log.error("Daily backup failed", e);
}
}
private void uploadToCloudStorage(File backupFile, BackupType type) {
try {
String key = String.format("%s/%s/%s",
type.name().toLowerCase(),
LocalDate.now().format(DateTimeFormatter.ISO_DATE),
backupFile.getName());
PutObjectRequest request = PutObjectRequest.builder()
.bucket("company-backups")
.key(key)
.build();
s3Client.putObject(request, RequestBody.fromFile(backupFile));
// 删除本地备份文件
if (backupFile.delete()) {
log.debug("Local backup file deleted: {}", backupFile.getAbsolutePath());
}
} catch (Exception e) {
log.error("Failed to upload backup to cloud storage", e);
throw new BackupException("Cloud storage upload failed", e);
}
}
}备份验证机制
备份不验证等于没备份。以下代码实现了备份完整性验证:定期恢复备份到测试环境,校验数据一致性和可恢复性,避免关键时刻发现备份损坏。
java
@Component
@Slf4j
public class BackupVerificationService {
@Autowired
private S3Client s3Client;
@Autowired
private DatabaseRestoreService dbRestoreService;
@Scheduled(cron = "0 0 3 * * SUN") // 每周日凌晨3点执行
public void verifyBackups() {
log.info("Starting backup verification process");
List<BackupVerificationResult> results = new ArrayList<>();
// 验证数据库备份
results.add(verifyDatabaseBackup());
// 验证文件备份
results.add(verifyFileBackup());
// 验证系统备份
results.add(verifySystemBackup());
// 生成验证报告
BackupVerificationReport report = BackupVerificationReport.builder()
.timestamp(LocalDateTime.now())
.results(results)
.overallStatus(calculateOverallStatus(results))
.build();
sendVerificationReport(report);
if (report.getOverallStatus() == VerificationStatus.FAILED) {
sendCriticalAlert("Backup Verification Failed",
"One or more backups failed verification");
}
}
private BackupVerificationResult verifyDatabaseBackup() {
try {
// 下载最新的数据库备份
String latestBackupKey = findLatestBackupKey(BackupType.DATABASE);
File tempBackup = downloadBackup(latestBackupKey);
// 在测试环境中恢复备份
boolean restoreSuccess = dbRestoreService.restoreDatabase(
tempBackup, "test_restore_db");
// 验证数据完整性
boolean dataIntegrity = verifyDataIntegrity("test_restore_db");
// 清理测试环境
cleanupTestEnvironment("test_restore_db");
BackupVerificationResult result = BackupVerificationResult.builder()
.backupType(BackupType.DATABASE)
.timestamp(LocalDateTime.now())
.success(restoreSuccess && dataIntegrity)
.details(String.format("Restore: %s, Integrity: %s",
restoreSuccess, dataIntegrity))
.build();
if (!result.isSuccess()) {
log.error("Database backup verification failed: {}", result.getDetails());
}
return result;
} catch (Exception e) {
log.error("Database backup verification error", e);
return BackupVerificationResult.failed(BackupType.DATABASE, e.getMessage());
}
}
}2.2 灾难恢复演练
DR演练自动化
灾难恢复演练是验证备份有效性的关键。以下代码实现了 DR 演练自动化流程:模拟数据库故障、应用服务器宕机、网络分区等场景,验证 RTO/RPO 是否达标,并生成演练报告。
java
@Component
@Slf4j
public class DisasterRecoveryDrill {
@Autowired
private ApplicationContext applicationContext;
@Autowired
private BackupService backupService;
@Autowired
private InfrastructureProvisioner provisioner;
private final AtomicBoolean drillInProgress = new AtomicBoolean(false);
@Scheduled(cron = "0 0 1 1 * *") // 每月1日凌晨1点执行
public void executeMonthlyDRDrill() {
if (drillInProgress.get()) {
log.warn("DR drill already in progress, skipping");
return;
}
if (!drillInProgress.compareAndSet(false, true)) {
return;
}
try {
log.info("Starting monthly disaster recovery drill");
DRDrillReport report = DRDrillReport.builder()
.startTime(LocalDateTime.now())
.build();
// 步骤1: 准备演练环境
DrillEnvironment environment = prepareDrillEnvironment();
report.setEnvironment(environment);
// 步骤2: 模拟灾难场景
DisasterScenario scenario = simulateDisaster();
report.setScenario(scenario);
// 步骤3: 执行恢复流程
RecoveryProcess recovery = executeRecoveryProcess(environment, scenario);
report.setRecovery(recovery);
// 步骤4: 验证系统功能
FunctionalityVerification verification = verifySystemFunctionality();
report.setVerification(verification);
// 步骤5: 清理演练环境
cleanupDrillEnvironment(environment);
report.setEndTime(LocalDateTime.now());
report.setOverallStatus(determineDrillStatus(report));
// 发送演练报告
sendDrillReport(report);
log.info("Disaster recovery drill completed with status: {}",
report.getOverallStatus());
} catch (Exception e) {
log.error("DR drill failed", e);
sendCriticalAlert("DR Drill Failed", e.getMessage());
} finally {
drillInProgress.set(false);
}
}
private DrillEnvironment prepareDrillEnvironment() {
log.info("Preparing DR drill environment");
// 创建隔离的测试环境
EnvironmentSpec spec = EnvironmentSpec.builder()
.name("dr-drill-" + System.currentTimeMillis())
.region("us-west-2")
.instanceType("t3.medium")
.instanceCount(3)
.build();
Environment environment = provisioner.createEnvironment(spec);
// 部署应用到测试环境
deployApplicationToEnvironment(environment);
// 导入测试数据
importTestData(environment);
return DrillEnvironment.builder()
.environment(environment)
.preparedAt(LocalDateTime.now())
.build();
}
private DisasterScenario simulateDisaster() {
log.info("Simulating disaster scenario");
// 随机选择灾难类型
DisasterType disasterType = getRandomDisasterType();
DisasterScenario scenario = DisasterScenario.builder()
.type(disasterType)
.simulatedAt(LocalDateTime.now())
.build();
switch (disasterType) {
case DATA_CENTER_OUTAGE:
simulateDataCenterOutage();
break;
case DATABASE_CORRUPTION:
simulateDatabaseCorruption();
break;
case NETWORK_PARTITION:
simulateNetworkPartition();
break;
}
return scenario;
}
}RTO/RPO监控
RTO(恢复时间目标)和 RPO(恢复点目标)是衡量灾难恢复能力的核心指标。以下代码实现了 RTO/RPO 的实时监控和告警,当指标超出阈值时自动通知运维团队。
java
@Component
@Slf4j
public class RTO_RPOMonitor {
private final MeterRegistry meterRegistry;
private final Map<String, DisasterEvent> activeDisasters = new ConcurrentHashMap<>();
public RTO_RPOMonitor(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
Gauge.builder("disaster.rto.seconds")
.description("Recovery Time Objective in seconds")
.register(meterRegistry, this, RTO_RPOMonitor::getCurrentRTO);
Gauge.builder("disaster.rpo.seconds")
.description("Recovery Point Objective in seconds")
.register(meterRegistry, this, RTO_RPOMonitor::getCurrentRPO);
}
public void recordDisasterStart(String disasterId, DisasterType type) {
DisasterEvent event = DisasterEvent.builder()
.id(disasterId)
.type(type)
.startedAt(LocalDateTime.now())
.build();
activeDisasters.put(disasterId, event);
log.info("Disaster recorded: {} - {}", disasterId, type);
}
public void recordRecoveryCompletion(String disasterId) {
DisasterEvent event = activeDisasters.get(disasterId);
if (event != null) {
event.setRecoveredAt(LocalDateTime.now());
event.setCompleted(true);
double rtoSeconds = Duration.between(
event.getStartedAt(), event.getRecoveredAt()).getSeconds();
// 记录指标
meterRegistry.timer("disaster.recovery.time")
.record((long) rtoSeconds, TimeUnit.SECONDS);
log.info("Disaster recovery completed: {} - RTO: {} seconds",
disasterId, rtoSeconds);
// 检查是否满足SLA
checkSLACompliance(event, rtoSeconds);
// 清理已完成的灾难记录
activeDisasters.remove(disasterId);
}
}
private void checkSLACompliance(DisasterEvent event, double rtoSeconds) {
double slaRTO = getSlaRtoForDisasterType(event.getType());
if (rtoSeconds > slaRTO) {
log.warn("RTO SLA violation: {} seconds (SLA: {} seconds)",
rtoSeconds, slaRTO);
sendAlert("RTO SLA Violation",
String.format("Disaster %s recovery took %f seconds, exceeds SLA of %f seconds",
event.getId(), rtoSeconds, slaRTO));
} else {
log.info("RTO SLA met: {} seconds (SLA: {} seconds)",
rtoSeconds, slaRTO);
}
}
public double getCurrentRTO() {
return activeDisasters.values().stream()
.mapToDouble(event -> {
if (event.isCompleted()) {
return Duration.between(
event.getStartedAt(), event.getRecoveredAt()).getSeconds();
} else {
return Duration.between(
event.getStartedAt(), LocalDateTime.now()).getSeconds();
}
})
.max()
.orElse(0.0);
}
public double getCurrentRPO() {
// 基于最后一次成功备份的时间计算RPO
LocalDateTime lastBackup = backupService.getLastSuccessfulBackupTime();
if (lastBackup == null) {
return Double.MAX_VALUE; // 无备份数据
}
return Duration.between(lastBackup, LocalDateTime.now()).getSeconds();
}
}📊 第三章:容量规划与优化
3.1 容量规划方法论
容量预测模型
容量规划需要基于历史数据和业务增长率进行预测。以下代码实现了基于线性回归的容量预测模型,综合考虑峰值使用率、20% 缓冲量和预期增长率,计算所需的 CPU 核心数。
java
@Component
@Slf4j
public class CapacityPlanner {
@Autowired
private MetricsService metricsService;
@Autowired
private ResourceUsagePredictor predictor;
public CapacityPlan generateCapacityPlan(TimeHorizon horizon) {
log.info("Generating capacity plan for horizon: {}", horizon);
// 收集历史使用数据
List<ResourceUsage> historicalData = collectHistoricalUsage(horizon);
// 预测未来需求
ResourceForecast forecast = predictor.predict(historicalData, horizon);
// 计算所需资源
ResourceRequirements requirements = calculateResourceRequirements(forecast);
// 生成采购建议
ProcurementRecommendations recommendations =
generateProcurementRecommendations(requirements);
return CapacityPlan.builder()
.horizon(horizon)
.generatedAt(LocalDateTime.now())
.forecast(forecast)
.requirements(requirements)
.recommendations(recommendations)
.build();
}
private List<ResourceUsage> collectHistoricalUsage(TimeHorizon horizon) {
LocalDateTime startDate = LocalDateTime.now().minus(horizon.getDuration());
return metricsService.getResourceUsageMetrics(startDate, LocalDateTime.now())
.stream()
.sorted(Comparator.comparing(ResourceUsage::getTimestamp))
.collect(Collectors.toList());
}
private ResourceRequirements calculateResourceRequirements(ResourceForecast forecast) {
return ResourceRequirements.builder()
.cpuCores(calculateCpuRequirements(forecast))
.memoryGb(calculateMemoryRequirements(forecast))
.storageGb(calculateStorageRequirements(forecast))
.bandwidthGbps(calculateBandwidthRequirements(forecast))
.build();
}
private int calculateCpuRequirements(ResourceForecast forecast) {
double peakCpuUsage = forecast.getPeakCpuUsage();
double growthRate = forecast.getGrowthRate();
// 考虑峰值使用 + 20% 缓冲 + 预期增长
double requiredCores = peakCpuUsage * 1.2 * (1 + growthRate);
// 向上取整到最接近的CPU核心数
return (int) Math.ceil(requiredCores / 2) * 2;
}
}资源利用率监控
实时监控资源利用率是容量规划的基础。以下代码采集 CPU、内存、磁盘 I/O 和网络带宽指标,当资源使用率超过阈值时触发告警,为扩容决策提供数据支撑。
java
@Component
@Slf4j
public class ResourceUtilizationMonitor {
private final MeterRegistry meterRegistry;
private final OperatingSystemMXBean osBean =
ManagementFactory.getOperatingSystemMXBean();
public ResourceUtilizationMonitor(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
// 注册系统资源指标
Gauge.builder("system.cpu.utilization")
.description("CPU utilization percentage")
.register(meterRegistry, this, ResourceUtilizationMonitor::getCpuUtilization);
Gauge.builder("system.memory.utilization")
.description("Memory utilization percentage")
.register(meterRegistry, this, ResourceUtilizationMonitor::getMemoryUtilization);
Gauge.builder("system.disk.utilization")
.description("Disk utilization percentage")
.register(meterRegistry, this, ResourceUtilizationMonitor::getDiskUtilization);
}
@Scheduled(fixedRate = 30000) // 每30秒检查一次
public void checkResourceUtilization() {
double cpuUtil = getCpuUtilization();
double memoryUtil = getMemoryUtilization();
double diskUtil = getDiskUtilization();
// 检查资源使用率阈值
if (cpuUtil > 0.85) {
log.warn("High CPU utilization: {:.2%}", cpuUtil);
sendResourceAlert("High CPU Usage",
String.format("CPU utilization is %.2f%%", cpuUtil * 100));
}
if (memoryUtil > 0.9) {
log.warn("High memory utilization: {:.2%}", memoryUtil);
sendResourceAlert("High Memory Usage",
String.format("Memory utilization is %.2f%%", memoryUtil * 100));
}
if (diskUtil > 0.85) {
log.warn("High disk utilization: {:.2%}", diskUtil);
sendResourceAlert("High Disk Usage",
String.format("Disk utilization is %.2f%%", diskUtil * 100));
}
}
public double getCpuUtilization() {
return osBean.getSystemCpuLoad();
}
public double getMemoryUtilization() {
MemoryMXBean memoryBean = ManagementFactory.getMemoryMXBean();
MemoryUsage heapUsage = memoryBean.getHeapMemoryUsage();
return (double) heapUsage.getUsed() / heapUsage.getMax();
}
public double getDiskUtilization() {
try {
FileStore store = Files.getFileStore(Paths.get("/"));
long totalSpace = store.getTotalSpace();
long usableSpace = store.getUsableSpace();
return 1.0 - (double) usableSpace / totalSpace;
} catch (IOException e) {
log.error("Failed to get disk utilization", e);
return 0.0;
}
}
public ResourceUtilizationReport generateUtilizationReport() {
return ResourceUtilizationReport.builder()
.timestamp(LocalDateTime.now())
.cpuUtilization(getCpuUtilization())
.memoryUtilization(getMemoryUtilization())
.diskUtilization(getDiskUtilization())
.networkUtilization(getNetworkUtilization())
.recommendations(generateOptimizationRecommendations())
.build();
}
}3.2 自动扩缩容配置
Kubernetes HPA配置
Kubernetes HPA(Horizontal Pod Autoscaler)根据 CPU/内存使用率自动调整 Pod 副本数。以下配置设置了基于 CPU 利用率的扩缩容策略,最小 2 副本、最大 20 副本,扩容速度优先于缩容速度。
yaml
# hpa-config.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp-deployment
minReplicas: 3
maxReplicas: 30
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
- type: Pods
pods:
metric:
name: http_requests_per_second
target:
type: AverageValue
averageValue: "100"
- type: External
external:
metric:
name: queue_length
target:
type: Value
value: "50"
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 10
periodSeconds: 60
- type: Pods
value: 2
periodSeconds: 60
selectPolicy: Min
scaleUp:
stabilizationWindowSeconds: 60
policies:
- type: Percent
value: 50
periodSeconds: 60
- type: Pods
value: 4
periodSeconds: 60
selectPolicy: Max自定义扩缩容策略
除 HPA 外,部分场景需要基于自定义指标(如 QPS、消息队列积压)进行扩缩容。以下代码实现了基于多指标的扩缩容决策,支持自定义扩缩容阈值和冷却时间。
java
@Component
@Slf4j
public class CustomScalingPolicy {
@Autowired
private MetricsService metricsService;
@Autowired
private KubernetesClient kubernetesClient;
private final Map<String, ScalingHistory> scalingHistory = new ConcurrentHashMap<>();
@Scheduled(fixedRate = 30000) // 每30秒检查一次
public void evaluateScalingNeeds() {
String deploymentName = "myapp-deployment";
Deployment deployment = kubernetesClient.apps().deployments()
.withName(deploymentName).get();
if (deployment == null) {
log.warn("Deployment {} not found", deploymentName);
return;
}
int currentReplicas = deployment.getSpec().getReplicas();
ScalingDecision decision = makeScalingDecision(currentReplicas);
if (decision.shouldScale()) {
executeScaling(deploymentName, decision.getTargetReplicas(),
decision.getReason());
}
}
private ScalingDecision makeScalingDecision(int currentReplicas) {
// 收集各种指标
double cpuUtilization = metricsService.getCpuUtilization();
double memoryUtilization = metricsService.getMemoryUtilization();
long httpRequestRate = metricsService.getHttpRequestRate();
long queueLength = metricsService.getQueueLength();
// 应用业务规则
if (cpuUtilization > 0.8 || memoryUtilization > 0.85) {
return ScalingDecision.scaleUp(currentReplicas + 2,
String.format("High resource usage - CPU: %.2f%%, Memory: %.2f%%",
cpuUtilization * 100, memoryUtilization * 100));
}
if (httpRequestRate > 1000) {
return ScalingDecision.scaleUp(currentReplicas + 1,
String.format("High request rate: %d req/sec", httpRequestRate));
}
if (queueLength > 100) {
return ScalingDecision.scaleUp(currentReplicas + 3,
String.format("Long queue: %d items", queueLength));
}
// 考虑缩容
if (cpuUtilization < 0.3 && memoryUtilization < 0.4 &&
httpRequestRate < 50 && queueLength < 10) {
int targetReplicas = Math.max(3, currentReplicas - 1); // 最少保持3个副本
if (targetReplicas < currentReplicas) {
return ScalingDecision.scaleDown(targetReplicas,
String.format("Low utilization - CPU: %.2f%%, Memory: %.2f%%",
cpuUtilization * 100, memoryUtilization * 100));
}
}
return ScalingDecision.noChange();
}
private void executeScaling(String deploymentName, int targetReplicas, String reason) {
try {
log.info("Scaling {} from {} to {} replicas. Reason: {}",
deploymentName,
kubernetesClient.apps().deployments().withName(deploymentName)
.get().getSpec().getReplicas(),
targetReplicas,
reason);
kubernetesClient.apps().deployments().withName(deploymentName)
.scale(targetReplicas);
// 记录扩缩容历史
scalingHistory.put(deploymentName,
ScalingHistory.builder()
.timestamp(LocalDateTime.now())
.fromReplicas(kubernetesClient.apps().deployments()
.withName(deploymentName).get().getSpec().getReplicas())
.toReplicas(targetReplicas)
.reason(reason)
.build());
} catch (Exception e) {
log.error("Failed to execute scaling for {}", deploymentName, e);
}
}
}🔧 第四章:运维自动化实践
4.1 基础设施即代码
Terraform自动化部署
Terraform 实现基础设施即代码,确保环境可复现、可版本化。以下配置定义了 AWS VPC、子网、安全组和 EC2 实例的完整创建流程,支持多环境(dev/staging/prod)隔离。
hcl
# main.tf
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.0"
}
kubernetes = {
source = "hashicorp/kubernetes"
version = "~> 2.0"
}
}
}
provider "aws" {
region = var.aws_region
}
provider "kubernetes" {
host = module.eks.cluster_endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1beta1"
command = "aws"
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_name]
}
}
# VPC基础设施
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
version = "~> 3.0"
name = "${var.project_name}-vpc"
cidr = var.vpc_cidr
azs = var.availability_zones
private_subnets = var.private_subnet_cidrs
public_subnets = var.public_subnet_cidrs
enable_nat_gateway = true
single_nat_gateway = false
tags = {
Environment = var.environment
Project = var.project_name
}
}
# EKS集群
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 18.0"
cluster_name = "${var.project_name}-${var.environment}"
cluster_version = "1.24"
vpc_id = module.vpc.vpc_id
subnet_ids = module.vpc.private_subnets
eks_managed_node_groups = {
general = {
desired_size = var.node_group_desired_size
max_size = var.node_group_max_size
min_size = var.node_group_min_size
instance_types = var.node_instance_types
capacity_type = "ON_DEMAND"
labels = {
role = "general"
}
}
spot = {
desired_size = 1
max_size = 5
min_size = 0
instance_types = ["m5.large", "m5a.large"]
capacity_type = "SPOT"
labels = {
role = "spot"
}
}
}
tags = {
Environment = var.environment
Project = var.project_name
}
}
# 数据库实例
resource "aws_db_instance" "mysql" {
identifier = "${var.project_name}-${var.environment}-mysql"
engine = "mysql"
engine_version = "8.0"
instance_class = var.db_instance_class
allocated_storage = var.db_allocated_storage
storage_type = "gp3"
username = var.db_username
password = var.db_password
db_name = var.db_name
db_subnet_group_name = aws_db_subnet_group.mysql.name
vpc_security_group_ids = [aws_security_group.mysql.id]
backup_retention_period = 7
backup_window = "03:00-04:00"
maintenance_window = "sun:04:00-sun:05:00"
skip_final_snapshot = var.environment == "dev"
tags = {
Name = "${var.project_name}-${var.environment}-mysql"
Environment = var.environment
}
}Ansible自动化配置
Ansible 用于配置管理和应用部署。以下 Playbook 实现了 SpringBoot 应用的自动化部署:拉取最新镜像、滚动更新、健康检查,确保部署过程零停机。
yaml
# site.yml
---
- name: Provision Production Infrastructure
hosts: localhost
connection: local
gather_facts: false
vars:
project_name: "ecommerce-platform"
environment: "production"
region: "us-west-2"
tasks:
- name: Create VPC
amazon.aws.ec2_vpc_net:
name: "{{ project_name }}-{{ environment }}-vpc"
cidr_block: 10.0.0.0/16
region: "{{ region }}"
tags:
Environment: "{{ environment }}"
Project: "{{ project_name }}"
register: vpc
- name: Create Internet Gateway
amazon.aws.ec2_vpc_igw:
vpc_id: "{{ vpc.vpc.id }}"
region: "{{ region }}"
tags:
Name: "{{ project_name }}-{{ environment }}-igw"
- name: Deploy Kubernetes Cluster
community.aws.eks_cluster:
name: "{{ project_name }}-{{ environment }}"
version: "1.24"
role_arn: "{{ eks_role_arn }}"
vpc_config:
subnet_ids: "{{ private_subnets }}"
security_group_ids:
- "{{ eks_sg_id }}"
region: "{{ region }}"
register: eks_cluster
- name: Configure Application Servers
hosts: app_servers
become: yes
vars:
app_version: "{{ app_version | default('latest') }}"
java_version: "11"
pre_tasks:
- name: Update system packages
apt:
update_cache: yes
upgrade: dist
roles:
- role: common
tags: [ common ]
- role: java
java_version: "{{ java_version }}"
tags: [ java ]
- role: application
app_name: "{{ project_name }}"
app_version: "{{ app_version }}"
tags: [ application ]
post_tasks:
- name: Verify application health
uri:
url: "http://localhost:8080/actuator/health"
method: GET
status_code: 200
register: health_check
until: health_check.status == 200
retries: 30
delay: 104.2 自动化运维脚本
系统健康检查脚本
定期健康检查是预防性运维的关键。以下脚本检查 CPU/内存/磁盘使用率、数据库连接、Redis 状态和 API 可用性,异常时发送告警通知。
bash
#!/bin/bash
# health-check.sh
set -e
# 配置变量
APP_NAME="myapp"
HEALTH_ENDPOINT="http://localhost:8080/actuator/health"
LOG_DIR="/app/logs"
ALERT_EMAIL="ops@example.com"
# 颜色定义
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
NC='\033[0m'
log() {
echo -e "${GREEN}[$(date '+%Y-%m-%d %H:%M:%S')] $1${NC}"
}
warn() {
echo -e "${YELLOW}[$(date '+%Y-%m-%d %H:%M:%S')] $1${NC}"
}
error() {
echo -e "${RED}[$(date '+%Y-%m-%d %H:%M:%S')] $1${NC}"
}
# 检查应用健康状态
check_application_health() {
log "Checking application health..."
if curl -sf "$HEALTH_ENDPOINT" >/dev/null 2>&1; then
log "✅ Application is healthy"
return 0
else
error "❌ Application health check failed"
return 1
fi
}
# 检查系统资源使用
check_system_resources() {
log "Checking system resources..."
# CPU使用率
cpu_usage=$(top -bn1 | grep "Cpu(s)" | awk '{print $2}' | cut -d'%' -f1)
if (( $(echo "$cpu_usage > 80" | bc -l) )); then
warn "⚠️ High CPU usage: ${cpu_usage}%"
else
log "✅ CPU usage normal: ${cpu_usage}%"
fi
# 内存使用率
memory_usage=$(free | grep Mem | awk '{printf "%.2f", $3/$2 * 100.0}')
if (( $(echo "$memory_usage > 85" | bc -l) )); then
warn "⚠️ High memory usage: ${memory_usage}%"
else
log "✅ Memory usage normal: ${memory_usage}%"
fi
# 磁盘使用率
disk_usage=$(df -h / | awk 'NR==2 {print $5}' | sed 's/%//')
if [ "$disk_usage" -gt 85 ]; then
warn "⚠️ High disk usage: ${disk_usage}%"
else
log "✅ Disk usage normal: ${disk_usage}%"
fi
}
# 检查关键进程
check_critical_processes() {
log "Checking critical processes..."
processes=("java" "nginx" "mysql")
for process in "${processes[@]}"; do
if pgrep "$process" >/dev/null; then
log "✅ Process $process is running"
else
error "❌ Process $process is not running"
send_alert "Process Down" "Process $process is not running"
fi
done
}
# 检查日志错误
check_logs() {
log "Checking application logs..."
error_count=$(tail -1000 "$LOG_DIR/application.log" | grep -c "ERROR" || true)
if [ "$error_count" -gt 10 ]; then
warn "⚠️ High error count in logs: $error_count errors"
send_alert "High Error Count" "Found $error_count errors in application logs"
else
log "✅ Log error count normal: $error_count errors"
fi
}
# 发送告警邮件
send_alert() {
local subject="$1"
local message="$2"
echo "Subject: [$APP_NAME] $subject
$message
Server: $(hostname)
Time: $(date)
Health Check Script Output:
$(tail -20 "$LOG_DIR/health-check.log")
" | mail -s "[$APP_NAME] $subject" "$ALERT_EMAIL"
}
# 主检查函数
main() {
log "Starting health check for $APP_NAME"
local overall_status=0
# 执行各项检查
check_application_health || overall_status=1
check_system_resources || overall_status=1
check_critical_processes || overall_status=1
check_logs || overall_status=1
if [ $overall_status -eq 0 ]; then
log "✅ All health checks passed"
else
error "❌ Some health checks failed"
send_alert "Health Check Failed" "One or more health checks failed"
fi
return $overall_status
}
# 设置日志输出
exec > >(tee -a "$LOG_DIR/health-check.log") 2>&1
# 执行主函数
main自动化部署脚本
自动化部署脚本实现从代码提交到生产上线的完整流水线。以下脚本包含版本回滚、蓝绿部署和灰度发布能力,支持一键部署和快速回滚。
bash
#!/bin/bash
# deploy.sh
set -e
# 配置变量
APP_NAME="myapp"
VERSION="$1"
ENVIRONMENT="${2:-production}"
DEPLOYMENT_TIMEOUT=300
if [ -z "$VERSION" ]; then
echo "Usage: $0 <version> [environment]"
echo "Example: $0 v1.2.3 production"
exit 1
fi
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1"
}
# 部署前检查
pre_deployment_check() {
log "Performing pre-deployment checks..."
# 检查版本是否存在
if ! curl -sf "https://artifacts.example.com/$APP_NAME/$VERSION.jar" >/dev/null; then
log "ERROR: Version $VERSION not found in artifact repository"
exit 1
fi
# 检查集群状态
if ! kubectl cluster-info >/dev/null 2>&1; then
log "ERROR: Cannot connect to Kubernetes cluster"
exit 1
fi
log "Pre-deployment checks passed"
}
# 执行金丝雀部署
canary_deployment() {
log "Starting canary deployment of version $VERSION"
# 部署金丝雀版本
helm upgrade "$APP_NAME-canary" ./helm/chart \
--set image.tag="$VERSION" \
--set replicaCount=1 \
--set service.type=ClusterIP \
--namespace "$ENVIRONMENT" \
--install
# 等待金丝雀部署就绪
kubectl wait --for=condition=available --timeout=60s \
deployment/"$APP_NAME-canary" -n "$ENVIRONMENT"
# 测试金丝雀版本
CANARY_POD=$(kubectl get pods -l app="$APP_NAME",version=canary \
-n "$ENVIRONMENT" -o jsonpath='{.items[0].metadata.name}')
if ! kubectl exec -n "$ENVIRONMENT" "$CANARY_POD" -- \
curl -sf http://localhost:8080/actuator/health; then
log "ERROR: Canary deployment health check failed"
rollback_canary
exit 1
fi
log "Canary deployment successful"
}
# 执行蓝绿部署
blue_green_deployment() {
log "Starting blue-green deployment"
local current_color=$(get_current_color)
local new_color=$(get_opposite_color "$current_color")
# 部署新版本到非活动环境
helm upgrade "$APP_NAME-$new_color" ./helm/chart \
--set image.tag="$VERSION" \
--set environment.color="$new_color" \
--namespace "$ENVIRONMENT" \
--install
# 等待新版本就绪
kubectl wait --for=condition=available --timeout=120s \
deployment/"$APP_NAME-$new_color" -n "$ENVIRONMENT"
# 流量切换前的验证
if ! validate_new_version "$new_color"; then
log "ERROR: New version validation failed"
rollback_blue_green "$new_color"
exit 1
fi
# 执行流量切换
switch_traffic "$new_color"
# 监控切换后的状态
monitor_post_switch "$new_color"
log "Blue-green deployment completed"
}
# 回滚函数
rollback_canary() {
log "Rolling back canary deployment"
helm uninstall "$APP_NAME-canary" -n "$ENVIRONMENT" || true
}
rollback_blue_green() {
local color="$1"
log "Rolling back blue-green deployment for color: $color"
helm uninstall "$APP_NAME-$color" -n "$ENVIRONMENT" || true
}
# 辅助函数
get_current_color() {
# 通过服务标签确定当前活跃颜色
kubectl get service "$APP_NAME" -n "$ENVIRONMENT" \
-o jsonpath='{.spec.selector.color}' 2>/dev/null || echo "blue"
}
get_opposite_color() {
local current="$1"
if [ "$current" = "blue" ]; then
echo "green"
else
echo "blue"
fi
}
validate_new_version() {
local color="$1"
local pod=$(kubectl get pods -l app="$APP_NAME",color="$color" \
-n "$ENVIRONMENT" -o jsonpath='{.items[0].metadata.name}')
# 执行健康检查和功能测试
kubectl exec -n "$ENVIRONMENT" "$pod" -- \
/app/bin/run-health-checks.sh
return $?
}
switch_traffic() {
local new_color="$1"
log "Switching traffic to $new_color"
# 更新服务选择器
kubectl patch service "$APP_NAME" -n "$ENVIRONMENT" \
-p "{\"spec\":{\"selector\":{\"color\":\"$new_color\"}}}"
}
monitor_post_switch() {
local color="$1"
local start_time=$(date +%s)
while [ $(( $(date +%s) - start_time )) -lt $DEPLOYMENT_TIMEOUT ]; do
local error_rate=$(get_error_rate)
if (( $(echo "$error_rate > 0.05" | bc -l) )); then
log "ERROR: High error rate detected after traffic switch: $error_rate"
rollback_blue_green "$color"
exit 1
fi
sleep 30
done
}
get_error_rate() {
# 从监控系统获取错误率
curl -s "http://prometheus:9090/api/v1/query?query=rate(http_requests_total{status=~'5..'}[5m])" \
| jq -r '.data.result[0].value[1]' 2>/dev/null || echo "0"
}
# 主部署流程
main() {
log "Starting deployment of $APP_NAME version $VERSION to $ENVIRONMENT"
pre_deployment_check
# 根据环境选择部署策略
case "$ENVIRONMENT" in
"production")
blue_green_deployment
;;
"staging")
canary_deployment
;;
*)
log "Deploying to $ENVIRONMENT using rolling update"
helm upgrade "$APP_NAME" ./helm/chart \
--set image.tag="$VERSION" \
--namespace "$ENVIRONMENT"
;;
esac
log "Deployment completed successfully"
}
# 执行部署
main💰 第五章:成本优化策略
5.1 云资源成本分析
成本监控和分析
云资源成本需要持续监控才能发现异常和优化空间。以下代码实现了成本异常检测:识别闲置资源、预算超支和价格异常,并生成优化建议。
java
@Component
@Slf4j
public class CostOptimizer {
@Autowired
private CloudBillingService billingService;
@Autowired
private ResourceUsageService usageService;
private final MeterRegistry meterRegistry;
public CostOptimizer(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
Gauge.builder("cloud.cost.daily")
.description("Daily cloud cost in USD")
.register(meterRegistry, this, CostOptimizer::getCurrentDailyCost);
Gauge.builder("cloud.cost.percentage.change")
.description("Percentage change in cloud costs")
.register(meterRegistry, this, CostOptimizer::getCostChangePercentage);
}
@Scheduled(cron = "0 0 1 * * *") // 每天凌晨1点执行
public void analyzeCosts() {
log.info("Starting daily cost analysis");
CostAnalysisReport report = CostAnalysisReport.builder()
.analysisDate(LocalDate.now())
.build();
// 分析各服务成本
report.setServiceCosts(analyzeServiceCosts());
// 识别成本异常
report.setAnomalies(detectCostAnomalies());
// 生成优化建议
report.setRecommendations(generateOptimizationRecommendations(report));
// 发送成本报告
sendCostReport(report);
// 如果成本超预算,发送告警
if (report.getTotalCost() > getBudgetThreshold()) {
sendCostAlert("Cost Budget Exceeded",
String.format("Daily cost $%.2f exceeds budget threshold",
report.getTotalCost()));
}
}
private Map<String, ServiceCost> analyzeServiceCosts() {
Map<String, ServiceCost> serviceCosts = new HashMap<>();
// EC2实例成本分析
List<EC2Instance> instances = usageService.getActiveEC2Instances();
double ec2Cost = instances.stream()
.mapToDouble(instance -> calculateInstanceCost(instance))
.sum();
serviceCosts.put("EC2", ServiceCost.builder()
.serviceName("EC2 Instances")
.dailyCost(ec2Cost)
.usageHours(instances.stream().mapToInt(EC2Instance::getRunningHours).sum())
.optimizationScore(calculateEC2OptimizationScore(instances))
.build());
// S3存储成本分析
double s3Cost = usageService.getS3Usage().stream()
.mapToDouble(this::calculateS3Cost)
.sum();
serviceCosts.put("S3", ServiceCost.builder()
.serviceName("S3 Storage")
.dailyCost(s3Cost)
.storageGb(usageService.getTotalS3StorageGb())
.optimizationScore(calculateS3OptimizationScore())
.build());
return serviceCosts;
}
private List<CostAnomaly> detectCostAnomalies() {
List<CostAnomaly> anomalies = new ArrayList<>();
// 检查突发的成本增加
double currentCost = getCurrentDailyCost();
double averageCost = getAverageDailyCost(7);
double variance = Math.abs(currentCost - averageCost) / averageCost;
if (variance > 0.3) { // 超过30%变化
anomalies.add(CostAnomaly.builder()
.type(AnomalyType.SPIKE)
.description(String.format("Cost spike detected: %.2f%% increase", variance * 100))
.severity(variance > 0.5 ? Severity.HIGH : Severity.MEDIUM)
.detectedAt(LocalDateTime.now())
.build());
}
// 检查闲置资源
List<IdleResource> idleResources = detectIdleResources();
for (IdleResource resource : idleResources) {
anomalies.add(CostAnomaly.builder()
.type(AnomalyType.IDLE_RESOURCE)
.description(String.format("Idle resource: %s (%s)",
resource.getResourceId(), resource.getResourceType()))
.severity(Severity.MEDIUM)
.detectedAt(LocalDateTime.now())
.build());
}
return anomalies;
}
}资源优化建议
资源优化是降低云成本的核心手段。以下代码基于使用率分析生成优化建议:识别低利用率实例推荐降配、识别冷数据推荐存储分层、识别闲置资源推荐释放。
java
@Component
public class ResourceOptimizer {
@Autowired
private CloudResourceManager resourceManager;
@Autowired
private UsageAnalyticsService analyticsService;
public List<OptimizationRecommendation> generateRecommendations() {
List<OptimizationRecommendation> recommendations = new ArrayList<>();
// EC2实例优化
recommendations.addAll(analyzeEC2Optimizations());
// 存储优化
recommendations.addAll(analyzeStorageOptimizations());
// 网络优化
recommendations.addAll(analyzeNetworkOptimizations());
return recommendations;
}
private List<OptimizationRecommendation> analyzeEC2Optimizations() {
List<OptimizationRecommendation> recommendations = new ArrayList<>();
List<EC2Instance> instances = resourceManager.getAllEC2Instances();
for (EC2Instance instance : instances) {
// 检查是否可以使用更便宜的实例类型
if (canDownsizeInstance(instance)) {
InstanceType suggestedType = getSuggestedInstanceType(instance);
double savings = calculateInstanceSavings(instance, suggestedType);
recommendations.add(OptimizationRecommendation.builder()
.resourceId(instance.getInstanceId())
.resourceType("EC2")
.category(OptimizationCategory.RIGHT_SIZING)
.description(String.format("Downsize from %s to %s",
instance.getInstanceType(), suggestedType))
.estimatedMonthlySavings(savings)
.implementationDifficulty(Difficulty.LOW)
.build());
}
// 检查Spot实例使用机会
if (isEligibleForSpot(instance)) {
double spotSavings = calculateSpotSavings(instance);
recommendations.add(OptimizationRecommendation.builder()
.resourceId(instance.getInstanceId())
.resourceType("EC2")
.category(OptimizationCategory.SPOT_INSTANCES)
.description("Convert to Spot instance")
.estimatedMonthlySavings(spotSavings)
.implementationDifficulty(Difficulty.MEDIUM)
.build());
}
}
return recommendations;
}
private List<OptimizationRecommendation> analyzeStorageOptimizations() {
List<OptimizationRecommendation> recommendations = new ArrayList<>();
// S3存储类别优化
List<S3Bucket> buckets = resourceManager.getAllS3Buckets();
for (S3Bucket bucket : buckets) {
Map<StorageClass, Long> usageByClass = analyticsService.getStorageUsageByClass(bucket);
// 建议将不常访问的数据转移到更便宜的存储类别
if (usageByClass.getOrDefault(StorageClass.STANDARD, 0L) > 1000L) { // 超过1TB
recommendations.add(OptimizationRecommendation.builder()
.resourceId(bucket.getName())
.resourceType("S3")
.category(OptimizationCategory.STORAGE_TIERING)
.description("Move infrequently accessed data to STANDARD_IA")
.estimatedMonthlySavings(calculateTieringSavings(bucket))
.implementationDifficulty(Difficulty.LOW)
.build());
}
}
return recommendations;
}
}5.2 预算管理和控制
预算监控系统
预算监控防止成本失控。以下代码实现了多级预算管理:按部门、项目、环境设置预算阈值,当消费达到 80% 预警、100% 告警、120% 自动触发资源降配。
java
@Component
@Slf4j
public class BudgetManager {
private final Map<String, Budget> budgets = new ConcurrentHashMap<>();
private final ScheduledExecutorService budgetChecker =
Executors.newScheduledThreadPool(1);
@PostConstruct
public void initializeBudgets() {
// 设置各部门预算
budgets.put("development", Budget.builder()
.department("Development")
.monthlyLimit(5000.0)
.alertThresholds(Arrays.asList(0.8, 0.9, 1.0))
.build());
budgets.put("production", Budget.builder()
.department("Production")
.monthlyLimit(20000.0)
.alertThresholds(Arrays.asList(0.7, 0.85, 1.0))
.build());
// 启动预算检查任务
budgetChecker.scheduleAtFixedRate(
this::checkBudgets, 0, 1, TimeUnit.HOURS);
}
public void checkBudgets() {
LocalDate today = LocalDate.now();
LocalDate monthStart = today.withDayOfMonth(1);
for (Budget budget : budgets.values()) {
double currentSpending = getSpending(budget.getDepartment(), monthStart, today);
double spendingPercentage = currentSpending / budget.getMonthlyLimit();
// 检查是否触发告警阈值
for (Double threshold : budget.getAlertThresholds()) {
if (spendingPercentage >= threshold &&
!budget.isAlertSent(threshold)) {
sendBudgetAlert(budget, threshold, currentSpending);
budget.markAlertAsSent(threshold);
}
}
// 如果超出预算,采取限制措施
if (spendingPercentage > 1.0) {
enforceBudgetLimits(budget);
}
}
}
private void sendBudgetAlert(Budget budget, Double threshold, double currentSpending) {
String subject = String.format("[%s] Budget Alert - %.0f%% of monthly limit reached",
budget.getDepartment(), threshold * 100);
String message = String.format("""
Department: %s
Monthly Budget: $%.2f
Current Spending: $%.2f
Percentage Used: %.1f%%
Alert Threshold: %.0f%%
Please review your resource usage and take appropriate action.
""",
budget.getDepartment(),
budget.getMonthlyLimit(),
currentSpending,
(currentSpending / budget.getMonthlyLimit()) * 100,
threshold * 100);
notificationService.sendAlert(subject, message,
getBudgetRecipients(budget.getDepartment()));
}
private void enforceBudgetLimits(Budget budget) {
log.warn("Budget exceeded for department: {}", budget.getDepartment());
// 自动缩减非关键资源
List<Resource> nonCriticalResources = getNonCriticalResources(budget.getDepartment());
for (Resource resource : nonCriticalResources) {
if (resource.isRunning()) {
resource.stop();
log.info("Stopped non-critical resource: {}", resource.getId());
}
}
// 发送紧急告警
sendEmergencyAlert(budget);
}
}成本效益分析
迁移决策需要量化分析。以下代码实现了云迁移的成本效益分析:计算 TCO(总拥有成本)、ROI(投资回报率)和回收期,为技术决策提供数据支撑。
java
@Component
public class CostBenefitAnalyzer {
public CostBenefitReport analyzeMigrationToCloud() {
CostAnalysis onPremiseCosts = calculateOnPremiseCosts();
CostAnalysis cloudCosts = calculateCloudCosts();
double migrationCost = calculateMigrationCost();
double trainingCost = calculateTrainingCost();
double netSavings = (onPremiseCosts.getAnnualCost() + migrationCost + trainingCost)
- cloudCosts.getAnnualCost();
double roi = (netSavings / (migrationCost + trainingCost)) * 100;
double paybackPeriod = (migrationCost + trainingCost) /
(onPremiseCosts.getAnnualCost() - cloudCosts.getAnnualCost());
return CostBenefitReport.builder()
.analysisDate(LocalDate.now())
.onPremiseCosts(onPremiseCosts)
.cloudCosts(cloudCosts)
.migrationCost(migrationCost)
.trainingCost(trainingCost)
.netSavings(netSavings)
.roi(roi)
.paybackPeriod(paybackPeriod)
.recommendation(determineRecommendation(netSavings, roi, paybackPeriod))
.build();
}
private Recommendation determineRecommendation(double netSavings, double roi, double paybackPeriod) {
if (netSavings > 0 && roi > 20 && paybackPeriod < 12) {
return Recommendation.PROCEED_IMMEDIATELY;
} else if (netSavings > 0 && roi > 10) {
return Recommendation.PROCEED_WITH_PLANNING;
} else if (netSavings > 0) {
return Recommendation.CONSIDER_ALTERNATIVES;
} else {
return Recommendation.NOT_RECOMMENDED;
}
}
}🔒 第六章:生产环境安全管理
6.1 安全合规框架
安全基线检查
安全基线检查是合规审计的基础。以下代码实现了 SSH、防火墙、认证和数据保护等多维度的安全检查,生成合规评分和修复建议。
java
@Component
@Slf4j
public class SecurityBaselineChecker {
private final List<SecurityCheck> securityChecks = Arrays.asList(
new SshSecurityCheck(),
new FirewallSecurityCheck(),
new AuthenticationSecurityCheck(),
new DataProtectionSecurityCheck(),
new VulnerabilitySecurityCheck()
);
@Scheduled(cron = "0 0 2 * * *") // 每天凌晨2点执行
public void performSecurityCheck() {
log.info("Starting security baseline check");
SecurityReport report = SecurityReport.builder()
.checkDate(LocalDateTime.now())
.build();
List<SecurityFinding> findings = new ArrayList<>();
for (SecurityCheck check : securityChecks) {
try {
SecurityCheckResult result = check.performCheck();
findings.addAll(result.getFindings());
} catch (Exception e) {
log.error("Security check failed: {}", check.getName(), e);
findings.add(SecurityFinding.builder()
.checkName(check.getName())
.severity(Severity.HIGH)
.description("Check execution failed: " + e.getMessage())
.status(FindingStatus.ERROR)
.build());
}
}
report.setFindings(findings);
report.setOverallScore(calculateSecurityScore(findings));
report.setComplianceStatus(determineComplianceStatus(findings));
sendSecurityReport(report);
// 如果发现高危问题,立即告警
if (hasCriticalFindings(findings)) {
sendSecurityAlert("Critical Security Issues Found",
generateCriticalFindingsSummary(findings));
}
}
private double calculateSecurityScore(List<SecurityFinding> findings) {
if (findings.isEmpty()) {
return 100.0;
}
double totalWeight = findings.stream()
.mapToDouble(f -> getSeverityWeight(f.getSeverity()))
.sum();
double failedWeight = findings.stream()
.filter(f -> f.getStatus() == FindingStatus.FAILED)
.mapToDouble(f -> getSeverityWeight(f.getSeverity()))
.sum();
return Math.max(0, 100 - (failedWeight / totalWeight) * 100);
}
private double getSeverityWeight(Severity severity) {
switch (severity) {
case CRITICAL: return 10.0;
case HIGH: return 5.0;
case MEDIUM: return 2.0;
case LOW: return 1.0;
default: return 0.0;
}
}
}合规性监控
合规性监控确保系统持续满足 ISO27001、等保三级等标准要求。以下代码实现了多标准合规检查和持续监控,当配置偏离基线时自动告警。
java
@Component
public class ComplianceMonitor {
private final Map<ComplianceStandard, ComplianceChecker> complianceCheckers =
Map.of(
ComplianceStandard.GDPR, new GDPRComplianceChecker(),
ComplianceStandard.SOC2, new SOC2ComplianceChecker(),
ComplianceStandard.ISO27001, new ISO27001ComplianceChecker(),
ComplianceStandard.PCI_DSS, new PCIDSSComplianceChecker()
);
@Scheduled(cron = "0 0 3 * * MON") // 每周一凌晨3点执行
public void performComplianceAudit() {
ComplianceReport report = ComplianceReport.builder()
.auditDate(LocalDateTime.now())
.build();
Map<ComplianceStandard, ComplianceStatus> complianceStatuses = new HashMap<>();
for (Map.Entry<ComplianceStandard, ComplianceChecker> entry : complianceCheckers.entrySet()) {
try {
ComplianceResult result = entry.getValue().checkCompliance();
complianceStatuses.put(entry.getKey(),
result.isCompliant() ? ComplianceStatus.COMPLIANT : ComplianceStatus.NON_COMPLIANT);
report.addFindings(result.getFindings());
} catch (Exception e) {
log.error("Compliance check failed for {}: {}", entry.getKey(), e.getMessage());
complianceStatuses.put(entry.getKey(), ComplianceStatus.UNKNOWN);
}
}
report.setComplianceStatuses(complianceStatuses);
report.setOverallCompliance(calculateOverallCompliance(complianceStatuses));
sendComplianceReport(report);
}
private OverallCompliance calculateOverallCompliance(
Map<ComplianceStandard, ComplianceStatus> statuses) {
long compliantCount = statuses.values().stream()
.filter(status -> status == ComplianceStatus.COMPLIANT)
.count();
double complianceRate = (double) compliantCount / statuses.size();
ComplianceLevel level = complianceRate >= 0.9 ? ComplianceLevel.EXCELLENT :
complianceRate >= 0.7 ? ComplianceLevel.GOOD :
complianceRate >= 0.5 ? ComplianceLevel.FAIR :
ComplianceLevel.POOR;
return OverallCompliance.builder()
.level(level)
.rate(complianceRate)
.build();
}
}6.2 安全事件响应
入侵检测系统
入侵检测系统(IDS)实时监控安全威胁。以下代码通过分析应用日志、网络流量和用户行为,识别 SQL 注入、DDoS、暴力破解等攻击,并自动触发防护措施。
java
@Component
@Slf4j
public class IntrusionDetectionSystem {
@Autowired
private LogAnalysisService logAnalysisService;
@Autowired
private NetworkTrafficAnalyzer networkAnalyzer;
@Autowired
private BehaviorAnalyzer behaviorAnalyzer;
private final List<SecurityAlert> activeAlerts = new CopyOnWriteArrayList<>();
@Scheduled(fixedRate = 30000) // 每30秒检查一次
public void monitorForIntrusions() {
// 分析应用日志中的可疑活动
List<SuspiciousActivity> logThreats = logAnalysisService.analyzeLogs();
processThreats(logThreats);
// 分析网络流量异常
List<NetworkAnomaly> networkThreats = networkAnalyzer.analyzeTraffic();
processThreats(networkThreats);
// 分析用户行为异常
List<BehavioralAnomaly> behaviorThreats = behaviorAnalyzer.analyzeUserBehavior();
processThreats(behaviorThreats);
}
private void processThreats(List<? extends Threat> threats) {
for (Threat threat : threats) {
if (threat.getRiskLevel() >= RiskLevel.HIGH) {
SecurityAlert alert = createSecurityAlert(threat);
activeAlerts.add(alert);
log.warn("Security threat detected: {} - Risk: {}",
threat.getDescription(), threat.getRiskLevel());
// 根据威胁级别采取相应措施
handleThreat(threat);
// 发送告警通知
sendSecurityAlert(alert);
}
}
}
private void handleThreat(Threat threat) {
switch (threat.getThreatType()) {
case SQL_INJECTION:
blockIpAddress(threat.getSourceIp());
break;
case DDoS:
enableRateLimiting(threat.getTargetResource());
break;
case BRUTE_FORCE:
lockAccount(threat.getTargetUser());
break;
default:
log.warn("Unknown threat type: {}", threat.getThreatType());
}
}
}适用边界与限制:
- 文中成本数据基于中型电商平台(100 万用户、年营业额 5000 万)测算,不同规模企业需重新核算
- 多活架构方案适用于核心业务系统,非核心系统采用主从架构即可,避免过度设计
- 文中代码为教学示例,生产使用前需补充异常处理、日志脱敏和权限校验
- Terraform/Ansible 配置基于 AWS 云平台,迁移到阿里云/腾讯云需调整 Provider 配置
- 安全合规建议基于国内等保三级标准,海外业务需额外满足 GDPR、SOC2 等要求
👍 如果本文对你有帮助,欢迎点赞、收藏、转发!
💬 你在生产环境运维中遇到过哪些挑战?欢迎在评论区分享你的经验~
🔔 关注我,获取 SpringBoot 企业级开发系列文章!
✍️ 行文仓促,定有不足之处,欢迎各位朋友在评论区批评指正,不胜感激!
专栏导航:
- 上一篇:CI/CD流水线搭建
- 下一篇:性能调优与故障排查(待更新)