云原生时代,自动扩缩容几乎是每个云平台、微服务系统和 Kubernetes 集群绕不开的问题。
请求来了,资源不够,用户响应时间变长;资源给多了,云账单又开始刺眼。更麻烦的是,现代应用通常不是一个单体服务,而是一组相互调用的微服务。某个服务下面可能有多个容器实例,每个容器的负载、队列、资源状态都不一样。
那么问题来了:系统到底应该扩哪个容器?扩多少?什么时候缩?怎样在保证 QoS 的同时,不把云成本打爆?
本文解读的论文 《STAR: Spatial-temporal autoscaling for cloud applications with deep reinforcement learning》 就是在回答这个问题。
这篇论文发表在 Expert Systems With Applications, 2026 ,属于 Elsevier 旗下的应用人工智能方向期刊。论文 DOI 为 10.1016/j.eswa.2026.132105。从期刊定位看,它不是偏纯理论的机器学习论文,而是典型的"AI 方法解决复杂工程问题"的应用型研究。该期刊通常被认为是 SCI/SCIE 收录、JCR Q1、中科院一区 TOP、CCF-C 人工智能方向期刊,不过具体分区和级别建议以所在单位采用的最新目录为准。
一、论文要解决什么问题?
这篇论文关注的是 cloud application autoscaling,也就是云应用自动扩缩容。
更具体地说,它研究的是:在一个由多个服务和容器组成的云应用中,如何根据不断变化的用户请求,动态调整容器资源,使应用响应时间尽可能低,同时 VM 租用成本不超过预算。
论文把优化目标写成两部分:
一部分是应用的平均响应时间 MRT,代表用户体验;另一部分是成本超预算惩罚,代表云资源费用控制。
也就是说,STAR 并不是单纯追求"响应越快越好",而是在问一个更现实的问题:
在给定成本预算下,怎样把响应时间压到最低?
这其实很符合现在云成本治理,也就是 FinOps 的思路。工程系统不是无限资源竞赛,而是在性能和成本之间找平衡。
二、为什么自动扩缩容很难?
如果只是一个单体应用,扩缩容相对简单:CPU 高了就扩,CPU 低了就缩。
但微服务系统复杂很多。
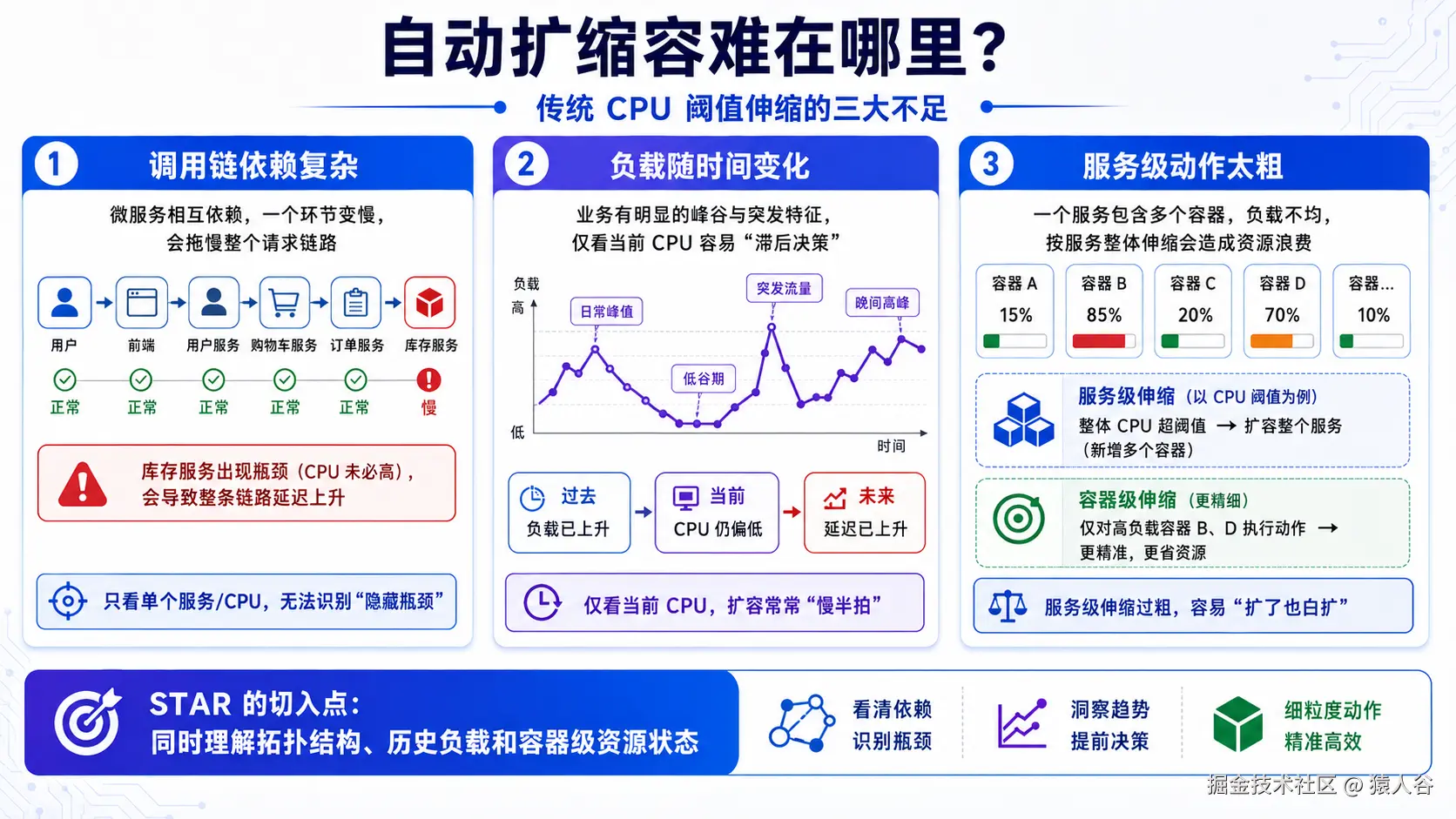
第一,服务之间存在调用依赖。
比如一个用户请求可能先经过 front-end,再调用 cart、browse,最后经过 checkout。如果中间某个容器成为瓶颈,整条请求链都会被拖慢。只看单个容器的 CPU 或队列,容易误判真正的瓶颈位置。
第二,负载有时间变化规律。
电商、内容平台、企业系统的请求量往往有周期、峰谷、突发等模式。如果只看当前时刻,很容易扩容滞后或缩容过早。
第三,服务级扩缩容粒度不够。
很多已有方法是按服务扩缩容,例如某个服务整体扩容。但在实际系统中,一个服务可能有多个容器实例,不同容器的资源状态和负载不完全相同。服务级统一调整可能造成资源浪费。
STAR 认为,已有 DRL 自动扩缩容方法主要有两个局限:
- 没有同时显式建模应用内部的空间依赖和容器历史负载变化。
- 多数方法仍停留在服务级扩缩容,缺少容器级细粒度资源调整能力。
这正是 STAR 的切入点。
三、学术界目前怎么做自动扩缩容?
论文把相关工作大致分成两类。
第一类是 启发式/规则型方法。
典型代表包括 AWS Auto Scaling、Kubernetes HPA 等。这类方法通常依赖阈值,例如 CPU 利用率超过 80% 就扩容,低于 60% 就缩容。优点是简单、稳定、容易部署;缺点是规则依赖专家经验,对动态负载和复杂微服务拓扑适应性不足。
还有一些方法会加入预测模块,例如 ProScale 用简单移动平均 SMA 预测未来负载,再用启发式策略扩缩容。这比纯阈值方法更主动,但仍然依赖人工规则,预测误差也会传导到扩缩容决策中。
第二类是 RL/DRL 方法。
强化学习把自动扩缩容看成一个序列决策问题:系统观察当前状态,执行扩缩容动作,环境反馈响应时间和成本,模型逐步学习更优策略。
已有方法包括 SARSA、Q-learning、DQN、TD3 等。例如 DeepScale 使用 DQN 做扩缩容决策,DRPC 使用 TD3 并支持在线重训练。
DRL 的优势是自适应能力强,但在工程落地中也面临一些挑战:状态空间大、动作空间复杂、训练不稳定、线上部署风险高。而且不少 DRL 方法并没有很好利用微服务拓扑结构和历史负载信息。
四、STAR 的核心想法:空间 + 时间 + 容器级动作
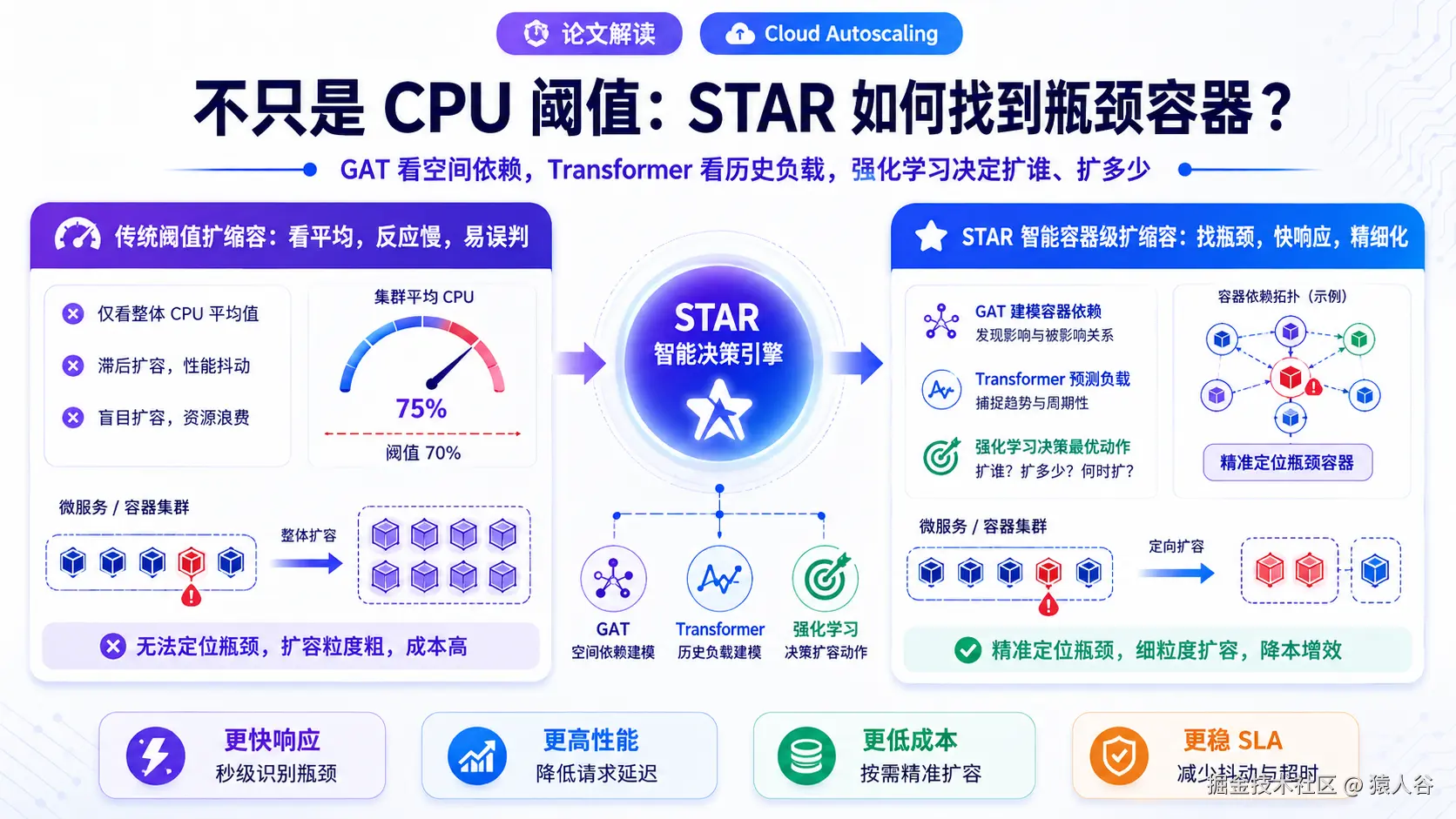
STAR 的全称是 Spatial-Temporal Autoscaling。名字已经说明了它的核心思想:同时建模空间依赖和时间变化。
如果用一句话概括 STAR:
GAT 负责看清"服务拓扑里谁影响谁",Transformer 负责看懂"每个容器过去的负载趋势",层级动作网络负责决定"先动哪个容器、动多少资源"。
论文提出了三个关键模块。
1. 用 GAT 捕获空间依赖
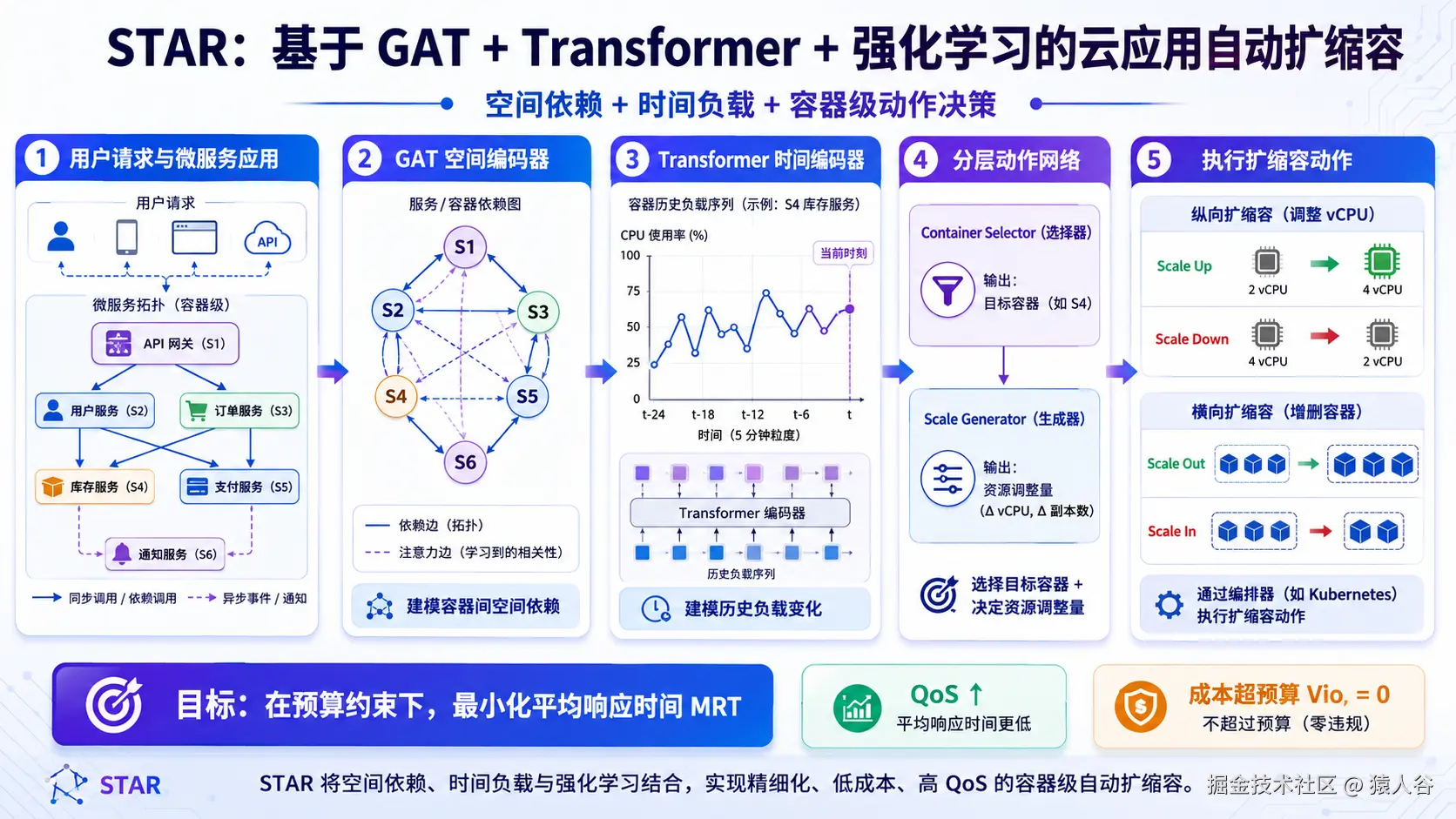
STAR 把云应用表示成一张图。
图中的节点是容器,边表示容器之间的执行顺序或调用依赖。这样,微服务应用不再是一堆独立资源点,而是一个有结构的图。
然后,STAR 使用 Graph Attention Network,GAT 来学习每个容器的空间表示。
GAT 的好处是可以给不同邻居分配不同注意力权重。换句话说,模型不只是知道"这个容器和哪些容器相连",还可以学习"哪些相邻容器对当前容器更重要"。
这对于自动扩缩容很关键。因为一个容器是否该扩容,不仅取决于它自己的负载,也取决于它在整个调用链中的位置,以及上下游容器的状态。
论文中特别强调,STAR 同时聚合前驱节点和后继节点的信息,也就是建模双向空间依赖。这比只看单向调用关系更完整。
2. 用 Transformer 捕获时间负载模式
除了空间结构,STAR 还为每个容器记录历史工作负载,也就是过去多个扩缩容决策点处理的请求数量。
这些历史负载序列会输入到 Transformer 的 self-attention 模块中,得到每个容器的时间特征表示。
为什么用 Transformer?
论文的理由是,Transformer 的自注意力机制更适合捕获长期时间依赖,比传统 RNN、LSTM、GRU 更能识别复杂负载变化模式。
实验中,作者也做了替换实验:把 Transformer 换成 LSTM 或 GRU 后,效果变差。这说明时间编码器确实对 STAR 有帮助。
不过这里也有一个细节值得注意:STAR 最后用了 mean pooling 把时间序列 embedding 汇总成一个历史表示。这个设计简单稳定,但可能会弱化最近时刻的突发峰值信息。这也是后续可以继续优化的地方。
3. 用层级动作网络实现容器级扩缩容
有了空间表示和时间表示之后,STAR 需要做动作决策。
它没有直接输出"每个服务扩几个实例",而是设计了一个层级动作网络:
第一层叫 Container Selector,负责选择最需要调整的目标容器。
第二层叫 Scale Generator,负责决定对这个目标容器调整多少资源。
这里要注意,STAR 并不是让 Scale Generator 直接输出"创建容器"或"删除容器"。更准确地说,它先输出一个 vCPU 调整量,然后系统再根据当前 VM 剩余资源和目标容器状态,用规则把这个调整量转换成具体动作。
如果需要增加资源,并且当前 VM 剩余 vCPU 足够,就对目标容器做纵向扩容;如果 VM 剩余资源不够,就可能创建新的容器实例,也就是横向扩容。
如果需要减少资源,就先减少目标容器的 vCPU;如果缩减幅度足够大,也可能删除目标容器,也就是横向缩容。
所以 STAR 的动作可以理解为两步:
先选择哪个容器,再决定资源调整量;最后由规则把调整量落到纵向扩缩容或横向增删容器上。
这个设计有两个好处。
第一,它支持容器级细粒度扩缩容。相比服务级统一扩缩容,容器级动作可以减少资源浪费。
第二,它能适应容器数量变化。传统神经网络如果每个输出神经元绑定一个服务或容器,当容器数量变化时结构就不灵活。STAR 的 Container Selector 是对每个容器打分,再选优先级最高的容器,因此可以支持动态容器集合。
当然,这里也有一个设计取舍:STAR 每次决策只调整一个容器。作者认为这样可以避免资源剧烈波动,保持系统稳定。但在突发大流量场景下,这也为后续多容器协同调整留下了优化空间。
五、STAR 用什么强化学习算法训练?
STAR 使用的是 ESRL,Evolutionary Strategy-based Reinforcement Learning。
它不是常见的 DQN、PPO 或 TD3,而是一种基于进化策略的强化学习方法。
简单理解,ESRL 会维护一组策略参数扰动个体,让它们分别在模拟环境中跑一轮,根据最终表现更新策略参数。
它的特点是:
- 不依赖每一步 reward,只需要 episode 结束后的整体 return。
- 训练过程相对稳定。
- 超参数较少。
- 适合在离线模拟环境中并行评估。
论文中,STAR 的 fitness 定义为:
负的平均响应时间 - 超预算惩罚
也就是响应时间越低、成本越不超预算,策略得分越高。
作者也承认,ESRL 的样本效率可能不如 TD3、SAC 这类 off-policy 方法。但他们认为 STAR 是在历史 trace 和模拟环境中离线训练,不直接影响生产系统,因此样本效率问题可以接受。
六、实验设计与主要结果
STAR 的实验设置比较完整。
论文使用了 NASA、Wiki、Ali 等真实用户请求 trace,并结合三种应用架构 A11、A12、A13,构造了多个实验场景。每个 autoscaling 决策间隔是 3 分钟。
对比方法包括:
- AWS-Scale:阈值型扩缩容方法。
- ProScale:基于 SMA 预测的启发式方法。
- DeepScale:DQN-based autoscaling 方法。
- DRPC:基于 TD3 的分布式强化学习方法。
实验主要指标是平均响应时间 MRT 和成本超预算程度 Vio。
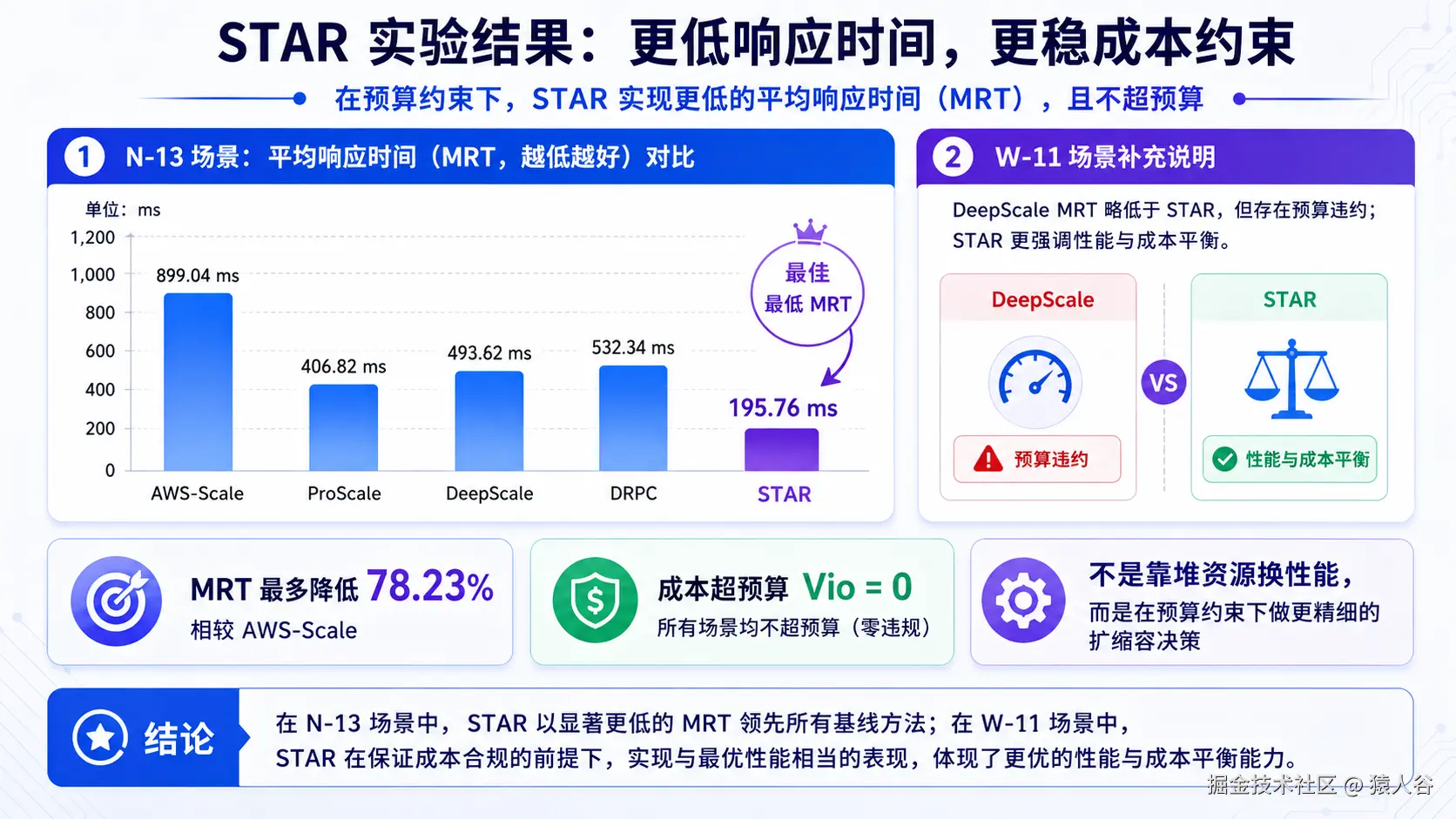
结果显示,STAR 在大多数场景下都取得最低 MRT,并且所有场景中成本超预算为 0。
例如在 N-13 场景中:
- AWS-Scale MRT 为 899.04 ms。
- ProScale MRT 为 406.82 ms。
- DeepScale MRT 为 493.62 ms。
- DRPC MRT 为 532.34 ms。
- STAR MRT 为 195.76 ms。
论文报告 STAR 最多可降低 78.23% 的平均响应时间,同时保持 VM 租用成本不超过每天 200 美元预算。
一个值得注意的场景是 W-11:DeepScale 的 MRT 为 318.29 ms,略优于 STAR 的 350.16 ms,但 DeepScale 的 Vio 为 34.75,说明它存在明显预算违约,而 STAR 的 Vio 为 0。
这说明 STAR 的优势不是单纯把资源堆上去换响应时间,而是在成本约束下做平衡。
七、消融实验说明了什么?
STAR 的消融实验很有价值,因为它回答了一个关键问题:这个模型真的需要 GAT 和 Transformer 吗?
答案是:需要。
作者分别去掉空间编码器和时间编码器。结果显示,两者缺失都会导致性能下降。
这说明自动扩缩容确实不能只看当前容器状态,也不能只看历史负载,而是需要同时理解:
- 容器在整个应用拓扑中的位置;
- 容器自身负载随时间变化的趋势。
作者还把 GAT 替换成 GCN 和 GraphSAGE。结果显示,GAT 效果最好。这说明注意力机制对不同邻居赋权,在微服务拓扑建模中有优势。
同时,作者把 Transformer 替换成 LSTM 和 GRU。结果显示,Transformer 也更优。说明 self-attention 在捕获容器历史负载模式方面更适合该任务。
八、这篇论文的亮点
我认为这篇论文有三个主要亮点。
第一,问题定义比较贴近真实云成本管理。
很多 autoscaling 论文只关注 SLA violation 或资源利用率,而 STAR 明确把预算纳入目标函数。这和真实云平台里的成本控制需求更一致。
第二,方法组合自然。
微服务系统有拓扑结构,所以用 GNN;负载有历史变化,所以用 Transformer;容器数量动态变化,所以用层级动作网络。这几个设计不是硬凑,而是和问题结构对应得比较好。
第三,实验比较全面。
主实验之外,论文还做了泛化能力分析、不同预算分析、尾延迟分析、消融实验、GAT 层数分析、Transformer 层数分析、ESRL 超参数分析、PPO 对比实验和惩罚系数分析。这让论证比单纯报一个主结果更可信。
对我来说,STAR 最值得借鉴的地方,不是简单把 GAT、Transformer 和 RL 拼在一起,而是它把云应用自动扩缩容重新表述为一个结构化决策问题:
既要理解服务拓扑,也要理解负载时间模式,还要在成本约束下做细粒度动作选择。
这种"结构感",很可能也是下一代云资源调度研究的关键。
九、从工程落地看,STAR 还可以继续往前走
STAR 已经给出了一个很完整的研究框架:它把微服务拓扑、历史负载和容器级动作决策结合起来,在实验中也取得了比较好的性能与成本平衡。
不过,如果从真实云平台和 Kubernetes 生产环境的角度看,这类方法要真正落地,仍然有一些值得继续探索的问题。
第一,实验环境与真实生产环境之间仍有差距。
论文中的实验主要基于真实 workload trace 和模拟环境。这样的设置有助于控制变量,也便于系统性比较不同方法。但真实 Kubernetes 集群会更复杂,例如调度延迟、容器冷启动、镜像拉取、网络抖动、多租户干扰、监控延迟、节点资源碎片等问题,都会影响扩缩容策略的实际效果。
因此,后续如果能在更接近生产环境的 Kubernetes 集群中验证 STAR,会更有助于判断它在真实系统中的稳定性和工程价值。
第二,离线训练策略仍需要面对负载漂移问题。
STAR 主要依赖历史 workload trace 在模拟环境中训练策略,然后用于后续推理。这种方式相对安全,不会直接在线上环境中试错,也更适合研究阶段的实验验证。
但真实业务中的负载经常会变化。比如业务版本发布、营销活动、突发热点、外部依赖异常,都可能让历史模式不再适用。此时,如果策略无法持续适应新的负载分布,效果可能会下降。
论文作者也在结论中提到,未来可以研究在线 DRL 算法,对策略进行周期性微调。这个方向很有价值,但也需要额外考虑安全性,避免模型在生产环境中进行高风险探索。
第三,每次只调整一个容器是一种稳定性设计,但也可能限制响应速度。
STAR 的层级动作网络每次会先选择一个目标容器,再决定资源调整量。这种设计有助于避免资源剧烈波动,让扩缩容过程更平滑。
但在突发大流量场景中,瓶颈可能不是单点,而是多个服务或多个容器同时出现压力。如果每个决策周期只调整一个容器,系统可能需要多轮操作才能恢复到理想状态,响应速度可能不够快。
因此,一个自然的扩展方向是:在保证稳定性的前提下,让策略一次选择 Top-K 个容器进行协同调整,或者引入 multi-agent RL,让多个服务或容器智能体协同决策。
第四,目前动作空间主要围绕 vCPU,资源维度还可以继续扩展。
论文主要关注 vCPU 资源调整。对于很多 CPU 密集型应用来说,这是合理的,因为 CPU 往往直接影响请求处理速度。
但在真实系统中,瓶颈不一定总是 CPU。很多应用的性能问题可能来自内存、网络、磁盘 I/O,甚至 GPU。比如缓存服务可能更依赖内存,数据处理任务可能更依赖 I/O,AI 推理服务则可能更依赖 GPU。
因此,后续如果能把 STAR 扩展到多资源 autoscaling,例如同时考虑 CPU、memory、network、I/O、GPU 等资源,会更贴近复杂生产系统的实际需求。
第五,预算约束目前主要通过惩罚项处理,未来可以进一步引入更严格的安全约束。
STAR 把成本超预算作为惩罚项放入优化目标中。实验结果显示,STAR 在所有场景中都没有超过预算,这说明惩罚项在实验设置下是有效的。
不过从优化建模角度看,惩罚项仍然属于软约束。也就是说,模型并不是被严格禁止做出超预算动作,而是在超预算后受到惩罚。
对于生产环境来说,预算、SLA、安全边界往往需要更强的约束机制。后续可以考虑 constrained RL、safe RL、CPO 等方向,把"不超过预算"从惩罚项进一步提升为更严格的决策约束。
第六,workload prediction 模块也会影响最终效果。
STAR 的状态输入中包含 predicted workload,也就是对下一调度周期负载强度的预测。这个预测模型是预先训练并固定的。
这意味着 STAR 并不是完全从原始监控指标端到端学习策略。它的效果不仅取决于 GAT、Transformer 和 ESRL,也会受到 workload prediction 质量影响。
如果预测模块在突发流量、业务变更或异常场景下失准,扩缩容策略也可能受到影响。因此,未来可以考虑把负载预测和扩缩容决策做得更紧密,例如引入联合训练机制,或者让预测模块不仅预测请求量,还预测瓶颈传播、队列积压和链路延迟变化。
第七,可复现性还可以进一步增强。
论文使用了真实 trace 和模拟环境,但数据可用性是 available on request,并不是完整公开仓库式复现。
对于云资源调度这类系统研究来说,如果能提供更完整的模拟器、配置文件、训练脚本、trace 处理流程和实验复现指南,会更方便后续研究者复现、比较和扩展。
如果把这些问题再往前推一步,STAR 后续比较自然的扩展方向包括:
- 从离线训练走向在线安全微调;
- 从单容器动作扩展到多容器协同动作;
- 从 vCPU 扩展到 CPU、memory、network、I/O、GPU 等多资源 autoscaling;
- 从预算惩罚项走向 constrained RL / safe RL 这类更严格的约束优化;
- 从模拟环境进一步走向真实 Kubernetes 集群验证;
- 从单独预测 workload,走向预测模块与扩缩容策略的联合优化。
这些方向并不是对 STAR 的否定。恰恰相反,它们说明 STAR 已经把自动扩缩容问题推进到了一个更接近真实系统的位置:不只是"什么时候扩容",而是"在复杂拓扑、动态负载和成本约束下,如何做更稳、更细、更安全的自治决策"。
从这个角度看,STAR 的价值不仅在于实验结果更好,也在于它为后续云原生资源调度研究留下了很清晰的扩展方向。 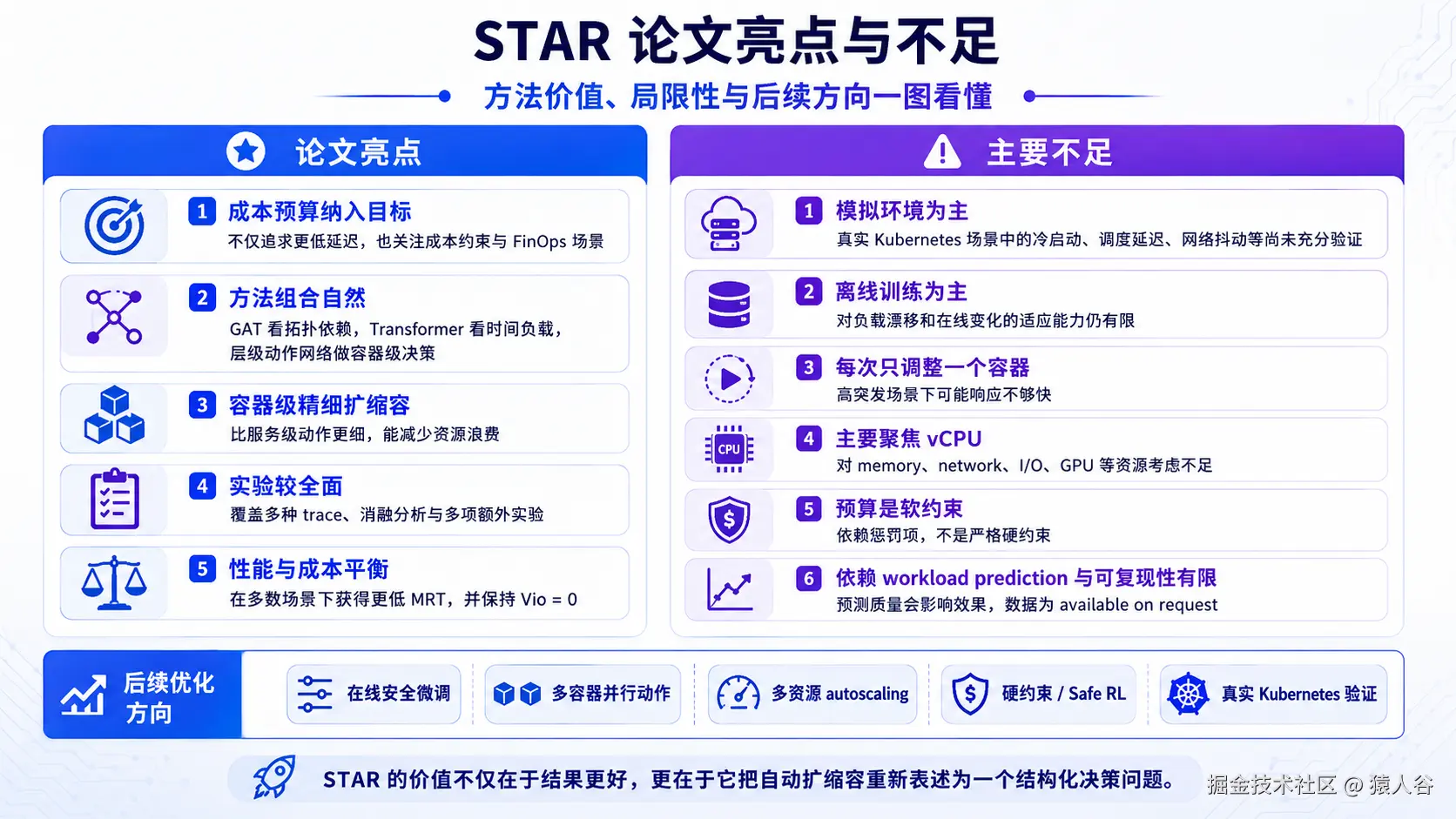
十、总结
STAR 是一篇思路比较完整的云应用自动扩缩容论文。
它的核心贡献可以概括为一句话:
用 GAT 捕获容器间空间依赖,用 Transformer 捕获容器历史负载模式,再通过层级动作网络实现容器级细粒度扩缩容。
相比传统阈值方法和已有 DRL 方法,STAR 更充分利用了微服务系统的结构信息和时间信息,因此在实验中取得了更好的响应时间与成本平衡。
从生产级落地角度看,STAR 仍有进一步验证和增强空间,例如真实 Kubernetes 环境验证、在线适应、多资源协同、硬约束优化等。
如果你的研究方向是云原生资源调度、Kubernetes autoscaling、DRL for cloud computing,STAR 很适合作为一篇重点阅读论文。它不仅提供了一个可参考的模型结构,也暴露了这个方向下一步值得做的问题:
更真实的环境、更安全的在线学习、更复杂的多资源协同决策。
从更大的视角看,云资源调度正在从"基于阈值的自动化"走向"基于结构理解和策略学习的自治化"。STAR 还不是终点,但它给了一个很好的样本:未来的云平台,不仅要知道 CPU 高不高,更要知道瓶颈在哪里、负载会怎么变化、成本边界在哪里,以及下一步应该最先调整谁。
原论文信息
解读论文如下:
Zhengxin Fang, Hui Ma, Gang Chen, and Shiping Chen. (2026). STAR: Spatial-temporal autoscaling for cloud applications with deep reinforcement learning . Expert Systems With Applications, 319 , 132105. DOI: 10.1016/j.eswa.2026.132105
本文仅为个人学习与技术解读,重点关注 STAR 在云应用自动扩缩容、空间-时间建模和容器级资源调整方面的设计思路。如有理解不准确之处,以原论文内容为准。