1. 研究背景
该代码面向回归预测问题,特别是当数据集包含多个输入特征且目标变量为连续数值时。支持向量回归(SVR)是一种强大的非参数建模方法,适用于小样本、非线性、高维数据。为了提升模型的可解释性,代码进一步引入**SHAP(SHapley Additive exPlanations)**值分析,用于量化每个输入特征对预测结果的贡献,帮助研究人员理解模型决策逻辑,辅助特征筛选或因子解释。
2. 主要功能
- 数据预处理:自动归一化(最大最小归一化),支持样本打乱与训练/测试集划分(默认8:2)。
- SVR模型训练:采用高斯径向基核函数(RBF),使用ISDA求解器,自动调整核尺度。
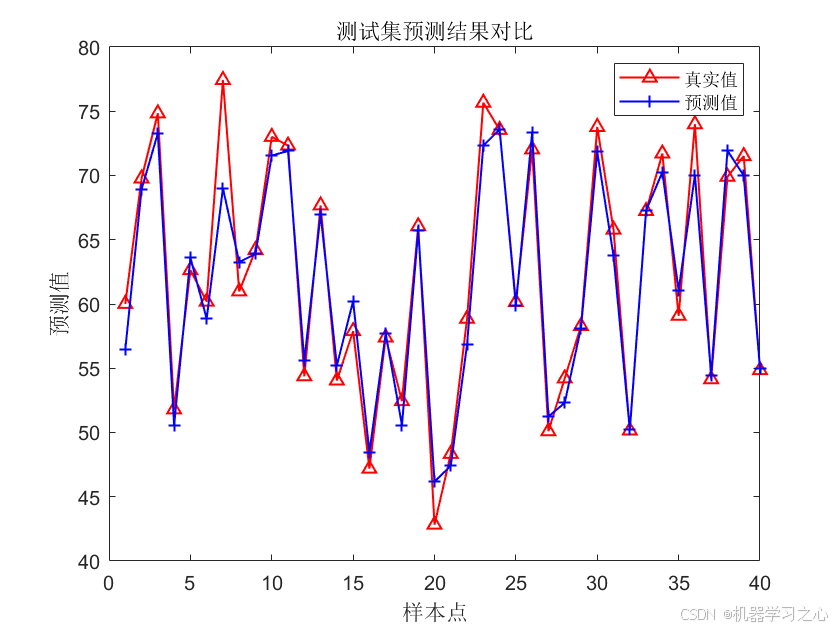
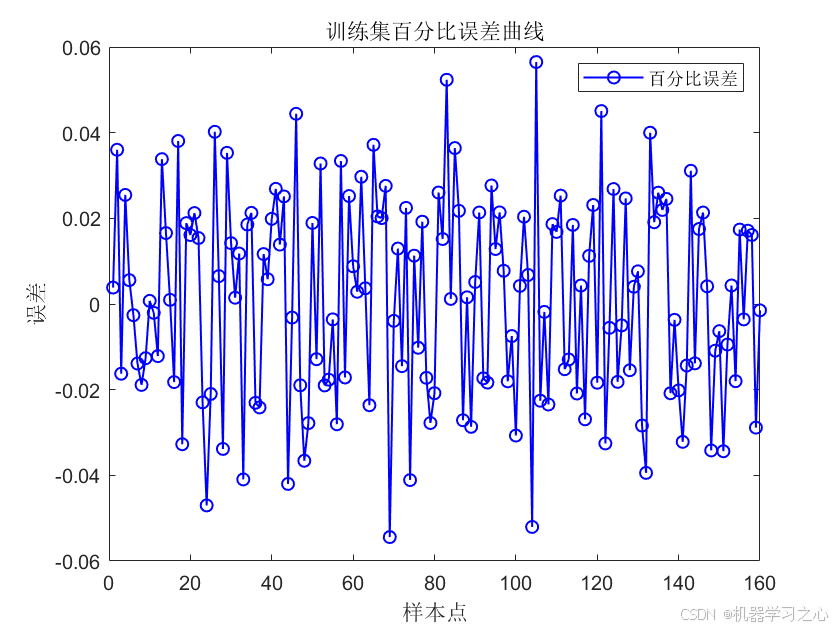
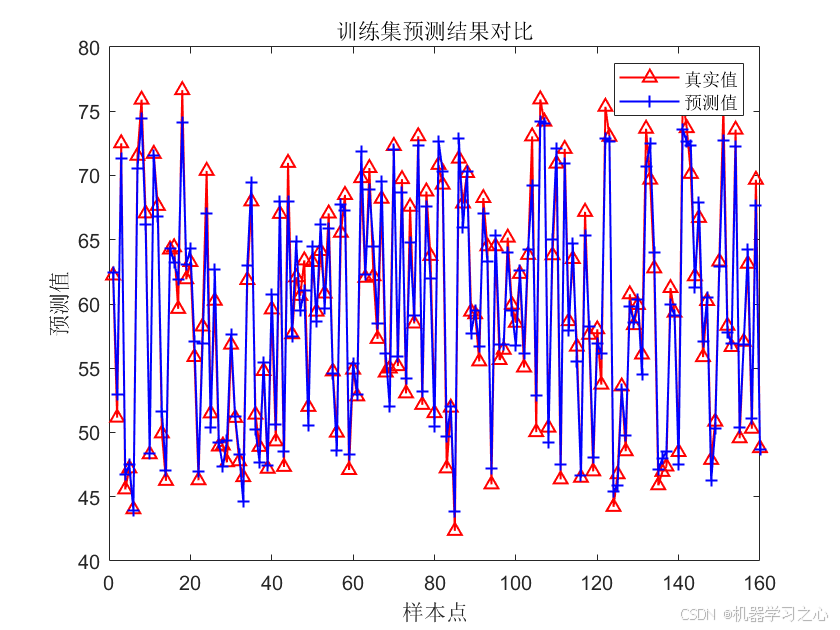
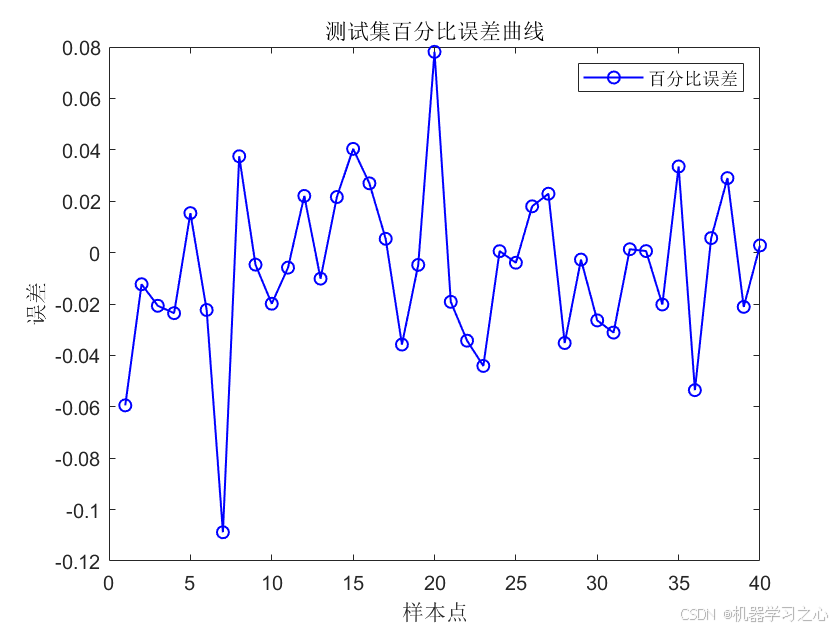
- 模型评估 :计算训练集和测试集的 R²、MAE、RMSE,并绘制预测值对比图、百分比误差曲线及回归拟合图。
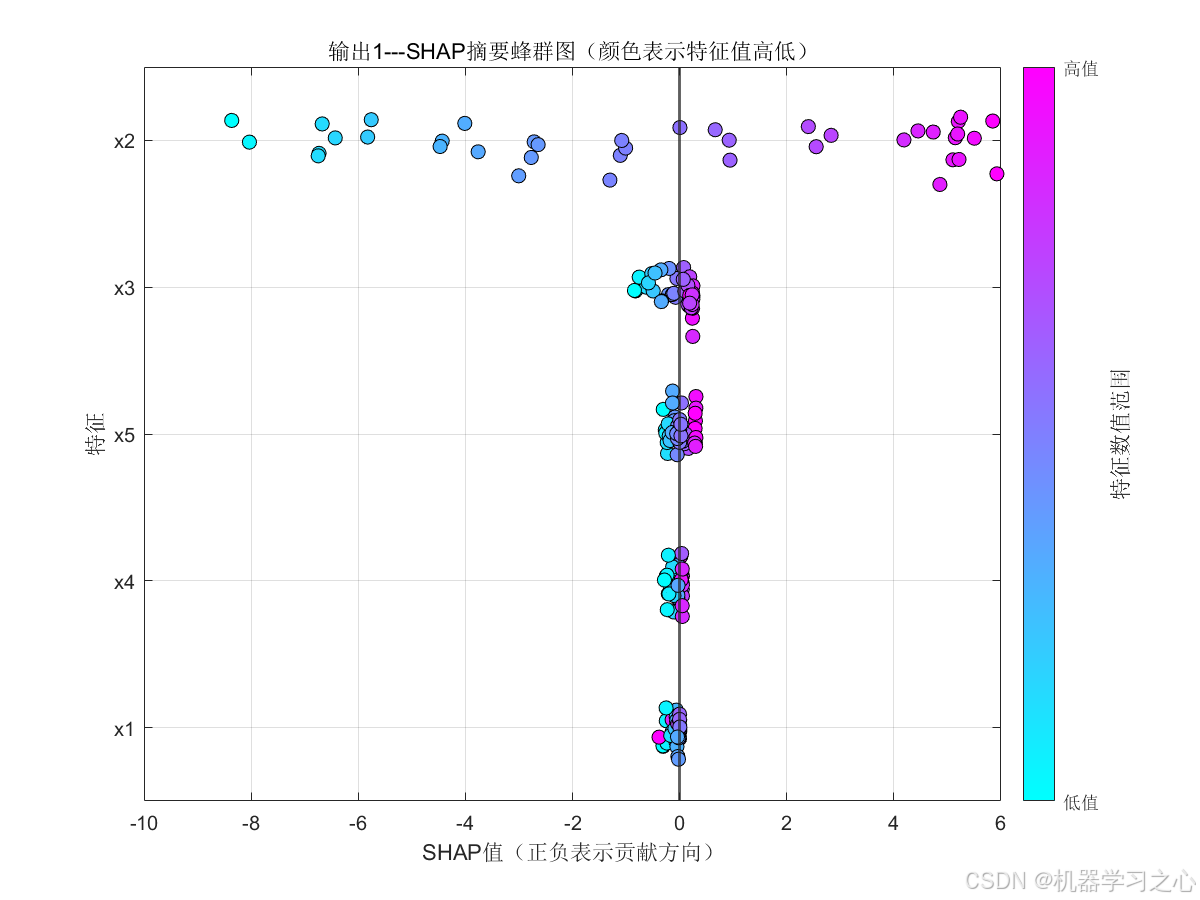
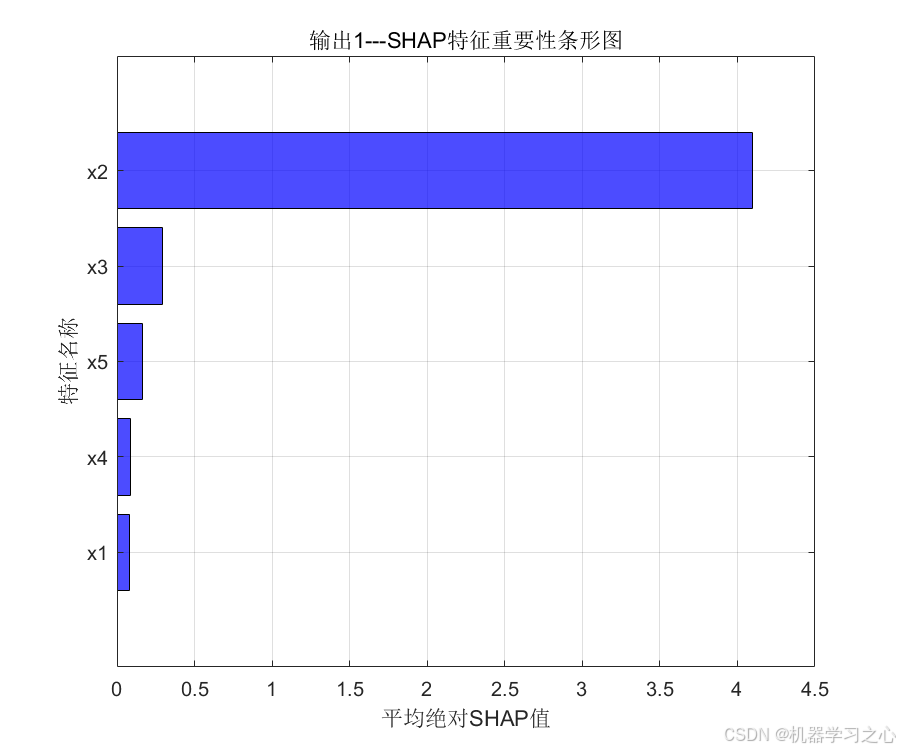
- 特征重要性分析 :调用自定义函数
shapley_function计算SHAP值,并对测试集样本进行可视化(该函数未给出,推测输出柱状图或蜂群图)。 - 新数据预测 :支持加载新的输入数据(
新的多输入.xlsx),利用已训练模型和归一化参数进行预测并输出结果。
3. 算法步骤(按代码执行顺序)
- 初始化 :清空工作区、关闭图窗、固定随机种子(
rng(2222))以确保结果可复现。 - 数据导入 :从
回归数据.xlsx读取数值矩阵res和特征名称names。 - 归一化 :对输入特征
X和目标Y分别执行mapminmax映射至 0,1 区间,并保存归一化参数(psin,psout)。 - 划分数据集:根据用户选择(打乱/不打乱),按8:2比例划分训练集和测试集。
- 训练SVR模型 :使用
fitrsvm,指定核函数为'gaussian',求解器为'ISDA',核尺度设为'auto'(自动估计)。 - 仿真预测:对训练集和测试集分别预测(输出为归一化值)。
- 反归一化 :将预测值还原至原始量纲,得到
pre1(训练)和pre2(测试)。 - 性能评估:计算RMSE、R²、MAE,并显示在命令行。
- 结果可视化 :绘制训练/测试集的真实值与预测值对比图、百分比误差图、以及
plotregression拟合图。 - SHAP值计算 :调用
shapley_function,传入训练好的模型、测试集特征、特征名称及输出个数,绘制特征重要性图。 - 新数据预测 :读取
新的多输入.xlsx,调用newpre函数(推测内部包含归一化与预测流程)输出预测结果。
4. 技术路线
- 预处理:归一化消除量纲影响,样本随机划分避免顺序偏差。
- 建模 :采用ε-不敏感损失函数的SVR,通过核函数将输入映射到高维特征空间,在高维空间进行线性回归,从而解决原始空间的非线性问题。
- 优化求解:使用迭代单变量数据算法(ISDA)加速二次规划求解,适合大规模数据。
- 后处理:反归一化还原预测值,多指标评估泛化能力。
- 可解释性增强:引入SHAP方法,基于博弈论Shapley值分配特征贡献,提供全局和局部解释。
5. 公式原理(核心公式)

6. 参数设定
| 参数 | 设定值 | 含义 |
|---|---|---|
| 随机种子 | rng(2222) |
固定随机打乱和核尺度自动估计的随机性 |
| 核函数 | 'gaussian' |
高斯径向基核(RBF) |
| 求解器 | 'ISDA' |
迭代单变量数据算法,适合中大规模回归 |
| 核尺度 | 'auto' |
自动根据数据子采样估计合适的尺度因子 |
| 训练集占比 | 0.8 |
80%样本用于训练,20%用于测试 |
| 归一化范围 | [0, 1] |
所有特征和目标均映射到0,1 |
| 其他SVR参数(未显式设置) | 采用MATLAB默认值,如Epsilon自动确定,BoxConstraint(即C)为1 |
7. 运行环境
- 软件 :MATLAB(版本建议 R2018b 及以上,因
fitrsvm和plotregression需对应工具箱)。 - 必需工具箱 :
- Statistics and Machine Learning Toolbox(提供
fitrsvm、predict、mapminmax) - Deep Learning Toolbox(可选,若
shapley_function依赖) - 若使用
plotregression,需 Neural Network Toolbox(或 Deep Learning Toolbox)。
- Statistics and Machine Learning Toolbox(提供
- 数据文件 :需在当前路径下准备
回归数据.xlsx(含特征和标签)及新的多输入.xlsx(仅含特征)。 - 自定义函数 :需提供
shapley_function.m和newpre.m文件。
8. 应用场景
- 工程领域:如材料性能预测(强度、硬度)、能源消耗预测、设备故障预警中的关键参数贡献分析。
- 经济金融:房价预测、股票收益率预测,并解释宏观经济指标的影响权重。
- 环境科学:空气质量指标(PM2.5)预测,识别主要污染源因子。
- 生物医学:基于生理指标预测疾病进展,辅助医生理解风险因素。
- 任何需要 "预测+可解释性"的回归任务,尤其当特征维度适中、样本量中等时,SVR配合SHAP能提供兼顾精度与解释性的解决方案。