由于博主在学习Transformer的时候没有做什么记录,导致期末考试完之后,学的关于Transformer的知识点和细节都忘掉了,所以写一个系列在重新详细的学习一下这个变形金刚模型,以此来记录下来,供后续的复习使用,也供大家参考,如果哪里写错了还请见谅,在评论区发言,博主看到后会及时回复修改的.
共同开始学习这本圣经《Attention Is All You Need 》
先放一张Transformer的具体架构图:
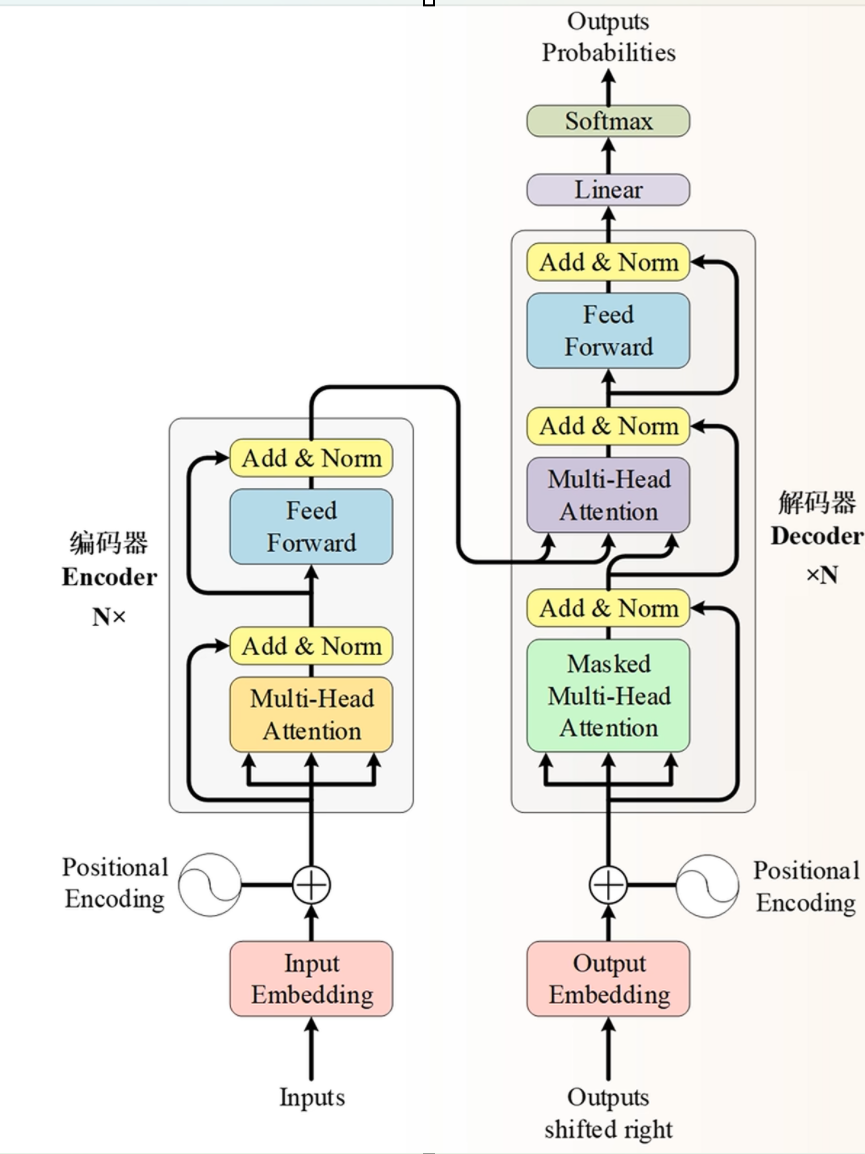
首先什么是embeding模型?
直接从地基开始:Embedding(嵌入)。
在 Transformer 的架构图中,可以看到最底层的那个粉色方块写着 "Input Embedding"(以及右边的 "Output Embedding")。
1. 什么是 Embedding?
简单来说,Embedding 是一个翻译官 ,它的工作是把人类的文字(单词/字)转换成计算机能理解的数学向量(一串数字)。
但在深度学习中,它不仅仅是"转换",更重要的是**"降维"和"提取语义"**。
想象一下,我们词表里有 10,000 个单词。那么该采用什么方法把文字翻译为一串数字呢?下面的方法是在机器学习中常用的一些编码方法:
方法 A:用序号(ID)。
- "苹果"是 1,"香蕉"是 2,"飞机"是 1000。
- 问题:计算机处理数字时,会觉得 2 比 1 大,但这在语言中没意义(香蕉并不比苹果"大")。而且 1 和 2 很接近,1 和 1000 很远,但语义上不一定如此。
方法 B:One-Hot 编码(独热编码)。
- "苹果"是
[1, 0, 0, ...](长度 10,000 的向量)。 - "香蕉"是
[0, 1, 0, ...]。 - 问题:太浪费空间了(稀疏),而且无法表达两个词之间的相似度(所有向量在这个空间里都是垂直正交的,距离都一样)。
方法 C:Embedding(Transformer 用的方法)。
- 它把每个词映射到一个固定维度的实数向量中。
- 比如 "苹果" 变成
[0.1, -0.5, 0.8, ...]。 - 比如 "香蕉" 变成
[0.2, -0.4, 0.9, ...]。 - 比如 "飞机" 变成
[0.9, 0.1, -0.2, ...]。
2. Embedding 在 Transformer 中的具体细节
在《Attention Is All You Need》这篇论文中,Embedding 层有以下几个关键特征:
A. 查表 机制
你可以把 Embedding 层想象成一个巨大的矩阵(表格)。
- 行数 = 词表大小(Vocabulary Size)。比如论文中约 37,000 个词。
- 列数 = 模型的隐藏层维度(Dimension, 记作 d m o d e l d_{model} dmodel)。论文中 d m o d e l = 512 d_{model} = 512 dmodel=512。
每当输入一个词(比如索引为 5 的词),模型就去这个矩阵的第 5 行,把那 512 个数字抄下来。这就是这个词的 Embedding。
B. 它是"可学习"的(Trainable)
这非常重要!刚开始训练时,Embedding 矩阵里的数字 字。
- ** 训练目标**:让语义相似的词,在数学空间里的距离更近。
- 结果:训练完后,"King" 和 "Queen" 的向量距离会很近,"Cat" 和 "Dog" 会很近,但 "Cat" 和 "Car" 就会比较远。
C. 一个特殊的细节:缩放(Scaling)
在论文的 3.4 节 Embeddings and Softmax 中,作者提到了一个容易被忽略的细节:
"In the embedding layers, we multiply those weights by d m o d e l \sqrt{d_{model}} dmodel ."
即: 取出 Embedding 向量后,作者将其乘以了 512 \sqrt{512} 512 (大约 22.6)。
为什么?
为了配合后面的 Positional Encoding(位置编码) 。后续的位置编码数值是直接加在 Embedding 上的。如果没有这个缩放,Embedding 的数值可能较小,加上位置编码后,语义信息就有可能会被位置信息"淹没"。乘以 d m o d e l \sqrt{d_{model}} dmodel 是为了让 Embedding 的数值分布和位置编码在同一个量级上,保持梯度的稳定。
并行化Embedding
Embedding 的过程是高度"并行化"的。甚至可以说,整个 Transformer 架构, 在训练阶段最引以为傲的特性就是并行计算,而 Embedding 层作为第一步,自然也是并行的。
1. 为什么是并行的?
让我们在加深一下 Embedding 到底在做什么。
假设你要翻译一句话:"I love AI"。
这三个词对应的 ID 可能是 [10, 52, 99]。
如果是串行(像 RNN):
- 先读入 "I" (10),去查表,拿到向量 v 1 v_1 v1。
- 等待 v 1 v_1 v1 处理完,状态更新后,再读入 "love" (52),查表,拿到向量 v 2 v_2 v2。
- ...以此类推。
这就是"时间步"(Time Step)的概念,必须要一步一步来。
如果是并行:
计算机看到的不是三个独立的任务,而是一个矩阵索引操作 。输入是一个包含所有 ID 的张量``Input = 10, 52, 99`。
Embedding 层会同时(在同一个计算周期内)去查找第 10行、第 52行 和 第 99行的数据。
类比:
- 串行:像去图书馆借书,只有一个柜台,你们三个人排队,第一个人借完,第二个人才能借。
- 并行 :像去超市的自动储物柜,你们三个人同时走到各自的柜子前,在同一瞬间把各自的东西(向量)取了出来。
2. 数学上的独立性
在 Embedding 层,单词之间是互不认识,互不干扰的。
- "I" 变成向量的过程,不需要知道 "love" 是什么。
- "love" 变成向量的过程,也不需要等待 "I" 的结果。
因为它们只是简单的"查表"操作。在 GPU 这种擅长大规模矩阵运算的硬件上,计算 1 个词的 Embedding 和计算 100 个词的 Embedding,耗时几乎是一样的(只要没超过显存限制)。
3. 并行意味着什么?
在 Transformer 之前,主流模型是 RNN/LSTM。RNN 最大的痛点就是无法并行。哪怕你要翻译的句子已经全部在电脑里了,RNN 也必须从左读到右。这导致训练非常慢。
而 Transformer 的设计(包括 Embedding 和后面的 Attention)允许模型一口气把整句话(甚至整篇文章)全部吃进去,同时处理所有的词。这就是为什么 Transformer 训练效率极高,能够利用大规模数据训练出 GPT 这样的大模型。
虽然 Embedding 本身的操作永远是并行的(只要输入一批词,就同时出结果),但在不同阶段,我们"喂"给它的方式不同:
- 训练时(Training):并行。我们把整句英语答案(Ground Truth)直接扔进去,所有词的 Embedding 瞬间完成。
- 推理/生成时(Inference):串行 。当你在这个对话框里看我打字时,是一个词一个词蹦出来的。这时候,模型是先生成第一个词,做 Embedding,算出结果,再生成第二个词...... 但这并不是因为 Embedding 层不支持并行,而是因为生成任务本身的逻辑决定了输出的时候必须先有上文,才能猜下文。
如果你要用一句话概括 Embedding 在 Transformer 里的作用:
Embedding 是一个可训练的查找表,它将离散的单词 ID 映射为 512 维的稠密向量,捕捉单词的语义信息,并为后续的注意力机制(Attention)提供数学计算的基础。
Positional Encoding(位置编码)
Transformer 的并行计算虽然极大地提高了效率,但它导致模型"脸盲"了------它分不清单词的前后顺序。
如果没有位置编码,对 Transformer 来说,"The man killed the tiger" 和 "The tiger killed the man" 是完全一样的输入,因为它们包含的单词集合完全一致。为了解决这个问题,论文作者提出了 Positional Encoding (PE)。
1. 核心操作:是"拼接"还是"相加"?
直觉做法:很多初学者会觉得,应该在词向量后面追加一个数字。比如 "Apple" 的向量是 512 维,我在第 513 维加上位置编号"1"。
- 论文做法 :Element-wise Sum(逐元素相加)。
细节:
Transformer 直接把 位置向量(PE) 加到了 词向量(Embedding) 上。公式如下:
I n p u t = E m b e d d i n g ( x ) + P o s i t i o n a l E n c o d i n g ( p o s ) Input = Embedding(x) + PositionalEncoding(pos) Input=Embedding(x)+PositionalEncoding(pos)
这意味着:
- PE 的维度必须和 Embedding 的维度完全一样(都是 d m o d e l = 512 d_{model} = 512 dmodel=512)。
- 加上 PE 后,原始的词义信息(Embedding)会被"污染"吗?
- 答案:从数学上看确实混合了。但你可以理解为,Embedding 把词义放在了超高维空间的一个点,而 PE 只是把这个点在这个空间里稍微"挪动"了一下。因为维度很高(512维),这种挪动通常不会掩盖掉原始语义,反而给这个语义附加了"我就在这个位置"的属性。
2. 位置编码的数学原理(实现细节)
论文没有使用简单的整数(1, 2, 3...)或可学习的位置向量,而是选择了一组固定的正弦和余弦函数。
为什么要搞这么复杂
如果只用 1, 2, 3...:
- 句子越长,数字越大,可能导致数值爆炸,压过 Embedding 的权重。
- 训练时见过的最长句子是 100 词,测试时来了个 110 词的,模型就懵了(无法外推)。
论文中的公式
对于位置 p o s pos pos(第几个词)和维度 i i i(向量里的第几个数字):
- 偶数维度 ( 2 i 2i 2i) : P E ( p o s , 2 i ) = sin ( p o s / 10000 2 i / d m o d e l ) PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
- 奇数维度 ( 2 i + 1 2i+1 2i+1) : P E ( p o s , 2 i + 1 ) = cos ( p o s / 10000 2 i / d m o d e l ) PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
这一段到底在讲什么
这里有一个绝妙的**"多尺度"概念。你可以把它想象成一个 二进制时钟或者机械式里程表**。
- 低维度( i i i 很小的时候): 分母小,频率高。正弦波变化非常快。这就像时钟上的"秒针",或者是里程表最右边转得飞快的那一位。
- 高维度( i i i 很大的时候): 分母大(接近 10000),频率极低。正弦波拉得很长。这就像时钟上的"时针",或者里程表最左边很久才动一下的那一位。
结论 :每个位置 p o s pos pos 都会对应一个独一无二的 512 维向量纹理。
- 前面的维度在疯狂震荡。
- 后面的维度在缓慢变化。
- 这种组合构成了该位置的"指纹"。
3. 你可能会问为什么一定要用正弦/余弦?
论文作者明确给出了理由:
"We chose this function because it would allow the model to easily learn to attend by relative positions."
关键词:相对位置(Relative Position)。
在自然语言中,绝对位置(第 100 个词)往往不如相对位置("not" 后面紧跟着 "happy")重要。
根据三角函数公式:
sin ( α + β ) = sin α cos β + cos α sin β \sin(\alpha + \beta) = \sin\alpha \cos\beta + \cos\alpha \sin\beta sin(α+β)=sinαcosβ+cosαsinβ
cos ( α + β ) = cos α cos β − sin α sin β \cos(\alpha + \beta) = \cos\alpha \cos\beta - \sin\alpha \sin\beta cos(α+β)=cosαcosβ−sinαsinβ
这意味这:
位置 p o s + k pos+k pos+k 的编码向量,可以被线性地表示为位置 p o s pos pos 的编码向量的函数。
通俗解释 :
如果你知道位置 p o s pos pos 的向量,你想算出它后面第 k k k 个位置的向量,你只需要对 p o s pos pos 的向量做一个**线性变换(旋转矩阵乘法)**就能得到。
这让 Transformer 的 Attention 机制很容易学习到"关注我不远处那个词"这样的模式,无论这两个词出现在句子的开头还是结尾。
4. 其他实现细节
A. Dropout 的应用
在 Embedding 和 Positional Encoding 相加之后,立刻接了一个 Dropout 层。
"We apply dropout to the sums of the embeddings and the positional encodings... The rate is P d r o p = 0.1 P_{drop} = 0.1 Pdrop=0.1."
作用:防止过拟合。这强迫模型不仅要依赖特定的位置信息,还要具备一定的鲁棒性。
B. 此时的张量形状
到这一步结束,我们的数据形状依然没有变:
- Input :
[Batch_Size, Sequence_Length](单词 ID) - After Embedding :
[Batch_Size, Sequence_Length, 512] - After Positional Encoding :
[Batch_Size, Sequence_Length, 512](形状不变,数值变了)
到现在为止,模型已经做好了准备工作:
- Embedding:把单词变成了有意义的数值向量(并行查表)。
- Scaling :把向量放大了 d m o d e l \sqrt{d_{model}} dmodel 倍。
- PE:把包含顺序信息的波纹加到了向量上。
- Dropout:随机扔掉了一些数据以防死记硬背。
这一套处理完的 [Batch_Size, Seq_Len, 512] 的矩阵,要被送入 Transformer 最核心、最伟大的结构------Encoder 了。
如果觉得不错的话,期待一波吧!