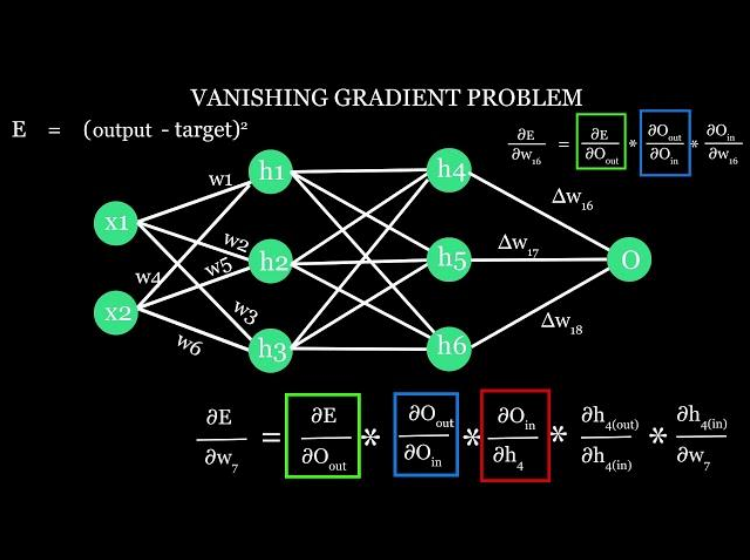
上图反应的是反向传播的完整数学过程,下面详细解读图中所示:
第一部分:图中网络结构字母含义
图里的圆圈和连线,代表了数据的流动路径:
- x1,x2x_1, x_2x1,x2 (Input) :输入层 。代表你喂给网络的数据(比如预测房价时,x1x_1x1 是面积,x2x_2x2 是地段)。
- h1h_1h1 到 h6h_6h6 (Hidden) :隐藏层 。这是网络内部的"打工人",负责提取特征。此图里有6个节点,说明至少有两层隐藏层(比如 h1,h2,h3h_1, h_2, h_3h1,h2,h3 是第一层,h4,h5,h6h_4, h_5, h_6h4,h5,h6 是第二层)。
- OOO (Output) :输出层。网络最终给出的预测值(比如预测出的房价)。
- w7,w16,w17,w18w_7, w_{16}, w_{17}, w_{18}w7,w16,w17,w18 等 :权重 。图里每一条连线上都有一个 www,它代表了两个神经元之间连接的"强弱"。w7w_7w7 特指连接某个隐藏层节点(比如 h4h_4h4)和输出层 OOO 的那条线上的权重。
第二部分:误差公式 EEE 解读
图的上方有一个公式:
E=(output−target)2E = (\text{output} - \text{target})^2E=(output−target)2
- EEE (Error) :误差/损失 。代表网络预测得有多离谱。我们的目标是让 EEE 变成 0。
- output :输出值 ,也就是上面说的 OOO(网络算出来的结果)。
- target :目标值/真实值,也就是标准答案。
- ()2()^2()2 (平方):为什么要平方?两点原因:一是把负数变成正数(算错多和算错少都是错,惩罚力度一样);二是让误差大的情况受到"加倍"的惩罚(比如误差是2,平方后变成4;误差是10,平方后变成100,逼迫网络优先解决大误差)。
第三部分:核心推导公式
图的下方那一长串偏导数连乘,这是整张图的灵魂。我们以 ∂E∂w7\frac{\partial E}{\partial w_7}∂w7∂E 为例拆解:
1. 整体符号:∂E∂w7\frac{\partial E}{\partial w_7}∂w7∂E
- ∂\partial∂:偏导数符号。你可以粗暴地把它理解为**"微小的变化量"**。
- ∂E∂w7\frac{\partial E}{\partial w_7}∂w7∂E 的完整白话翻译 :"如果我把 w7w_7w7 这条线上的权重轻轻拨动一点点 (比如增加0.001),最终的误差 EEE 会跟着变化多少 ?"这个算出来的值,就叫梯度。
2. 链式法则拆解:
因为 w7w_7w7 不能直接作用于 EEE,中间隔了好多层,所以要用链式法则(乘法)一层层剥开。图上把它拆成了几个部分相乘:
- 第一环:∂E∂O\frac{\partial E}{\partial O}∂O∂E
- 含义 :输出值 OOO 变动一点,误差 EEE 变动多少?
- 本质 :这一步只和误差公式 E=(O−target)2E = (O - \text{target})^2E=(O−target)2 有关。根据求导法则,这一项等于 2×(O−target)2 \times (O - \text{target})2×(O−target)。它只是告诉你"现在误差有多大,方向是正还是负"。
- 第二环及以后:∂O∂中间变量⋅∂中间变量∂更中间变量...\frac{\partial O}{\partial \text{中间变量}} \cdot \frac{\partial \text{中间变量}}{\partial \text{更中间变量}} \dots∂中间变量∂O⋅∂更中间变量∂中间变量...
- 含义:顺着网络从后往前推,一层一层算。
- 关键点 :这些分数中,必然会包含激活函数的导数(比如 Sigmoid 函数的导数)。
第四部分:执行判决(权重更新 Δw\Delta wΔw)
图的底部写着 Δw16\Delta w_{16}Δw16、Δw17\Delta w_{17}Δw17 等。
- Δ\DeltaΔ (Delta):在数学里代表**"变化量"**。
- Δw16\Delta w_{16}Δw16 :意思是"权重 w16w_{16}w16 需要调整的幅度"。
- 更新公式(图里省略了,但必定存在) :w16_新=w16_旧−学习率×∂E∂w16w_{16\新} = w{16\旧} - \text{学习率} \times \frac{\partial E}{\partial w{16}}w16_新=w16_旧−学习率×∂w16∂E
- 算出了梯度(责任大小),乘以一个系数(学习率),然后从原来的权重中减去它,这就完成了一次"学习"。
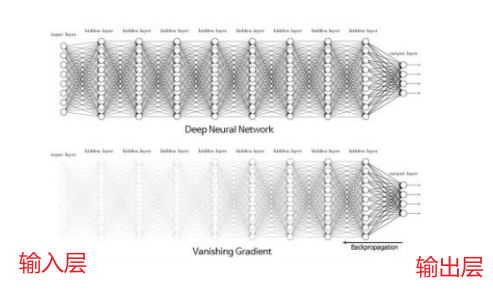
第五部分:引出"梯度消失问题"?
现在,我们把视线聚焦在标题 VANISHING GRADIENT PROBLEM 上。
假设图里的网络使用的是传统的 Sigmoid 激活函数 。Sigmoid 函数有一个致命的数学特性:无论输入是什么,它的导数(斜率)最大只有 0.25。(下期详细介绍激活函数)
再看回我们算梯度的公式,它是一连串的乘法 :
∂E∂w底层=∂E∂O×(导数1)⏟≤0.25×(导数2)⏟≤0.25×(导数3)⏟≤0.25×⋯×∂h∂w底层\frac{\partial E}{\partial w_{\text{底层}}} = \frac{\partial E}{\partial O} \times \underbrace{(\text{导数}1)}{\le 0.25} \times \underbrace{(\text{导数}2)}{\le 0.25} \times \underbrace{(\text{导数}3)}{\le 0.25} \times \dots \times \frac{\partial h}{\partial w_{\text{底层}}}∂w底层∂E=∂O∂E×≤0.25 (导数1)×≤0.25 (导数2)×≤0.25 (导数3)×⋯×∂w底层∂h
我们来看看不同位置的权重,算梯度时有什么区别:


**结果就是:靠近输入层的那些权重,根本就不更新! 它们就像是"死"掉了一样,前几层网络学不到任何东西。
这就是著名的 VANISHING GRADIENT PROBLEM(梯度消失问题) 的完整逻辑:因为反向传播时的连乘机制 ,导致底层网络的梯度像水汽一样"消失"了。
为了减轻梯度消失问题一般使用如图所述三种方式
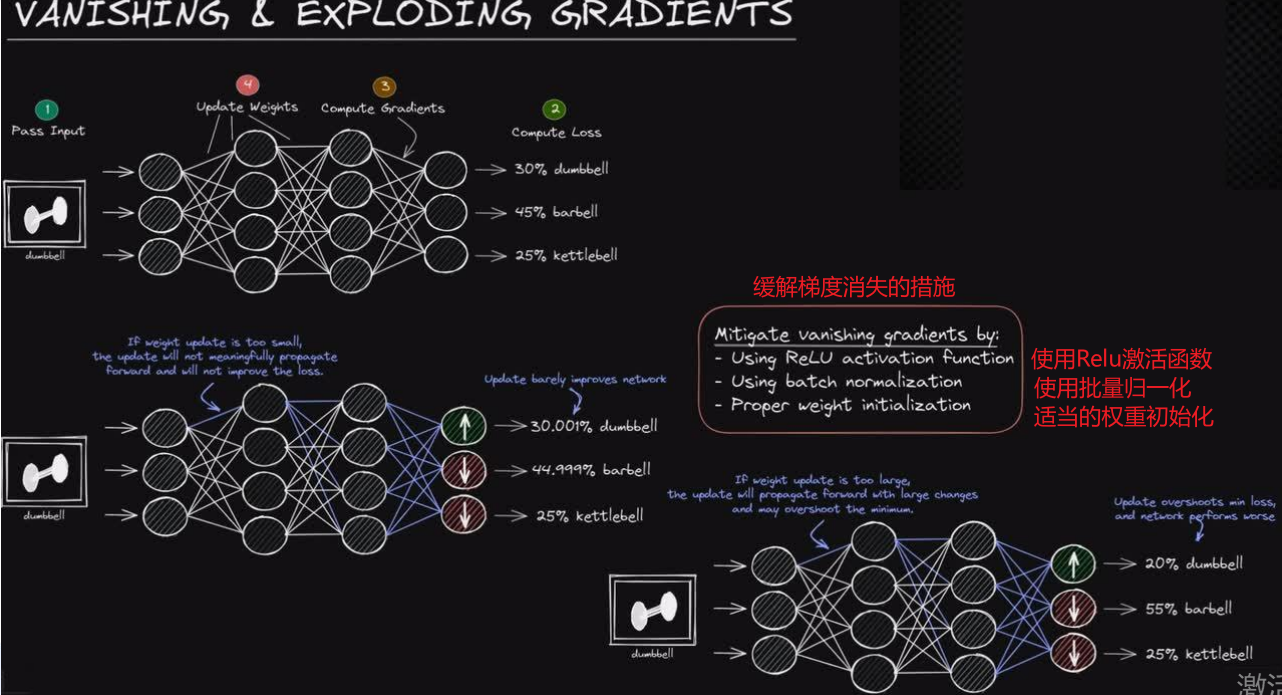
其实梯度爆炸也是同理,只不过梯度消失是一堆小于0的连乘导致最后越来越小,而梯度爆炸是一堆大于0的连乘导致最后越来越大。