Nature连续上线三篇多智能体科研论文
作者:史国鑫,崔钊鸣,王科涵,陈昊涵
论文一:打通从科学假设到实验验证的科学发现闭环
如何基于海量数据与文献,生成具有创新性的科学假设,进行严谨的实验验证,是现在科研的关键问题。Google团队基于Gemini模型构建了多智能体系统 Co-Scientist。该系统实现了跨学科科学假设的自动生成与自我进化,并成功在真实的生物医学实验中得到了验证。

引用格式:Gottweis J, Weng W H, Kohli P, et al. Accelerating scientific discovery with Co-ScientistJ. Nature, 2026. DOI: 10.1038/s41586-026-10644-y.
Co-Scientist 在内部模拟了一整个人类科研团队的工作流。当人类科学家给出研究目标后,它不再是简单地搜集资料并输出单一结论,而是利用充裕的推理时间,开启一个让内部多智能体反复辩论、排名和演化的自动化迭代流程(如图1所示)。
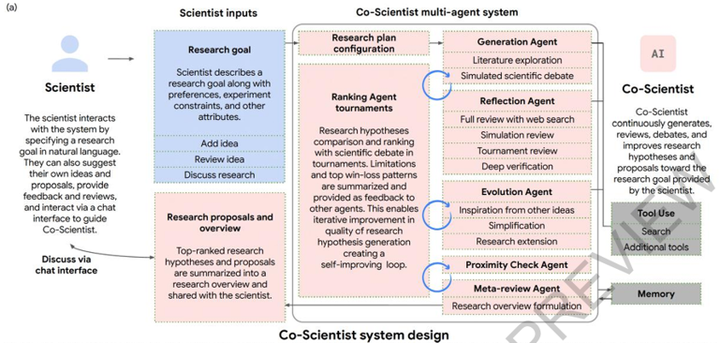 图1:Co-Scientist系统设计图
图1:Co-Scientist系统设计图
在这个流程中,系统后台会先生成海量的初步研究假设,并让这些假设相互进行逻辑校验和论证比对。通过一套等级打分机制,系统会对所有假设进行优劣排序,淘汰掉有明显错误或缺乏创新性的内容。接着,系统提取高分方案的特征,结合跨学科知识进行逻辑重构,推导出更完善的科学假设。最终,整理出详尽的研究综述,交由人类科学家审核并决定后续的实验方向,实现了人类专家与人工智能协作的科学发现闭环(如图2所示)。
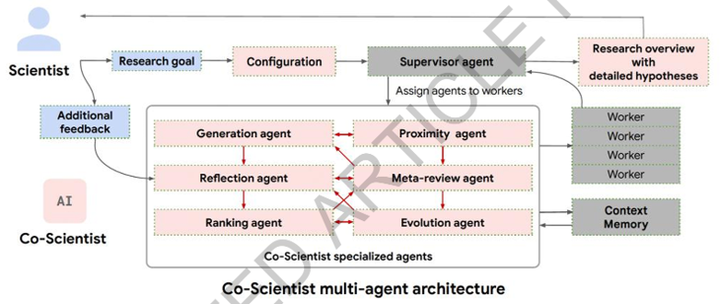 图2:Co-Scientist多智能体架构图
图2:Co-Scientist多智能体架构图
为了高效运转上述这种复杂的持续推理流程,该架构设有一个 Supervisor 调度智能体作为全局统筹节点,负责动态管理异步任务队列,并将具体工作派发给多类专业执行智能体并发处理:
(1) Generation 生成智能体负责检索海量文献并合成初始的研究假设;
(2) Reflection 反思智能体会调用外部工具执行深度交叉验证,逐层排查假设中的逻辑缺陷并严格核实事实准确性与新颖性;
(3) Ranking 排序智能体通过引入锦标赛机制,组织各个候选假设进行严谨的相互辩论与打分评级;
(4) Evolution 演化智能体基于评级结果,通过跨领域信息重组、类比和优化现有高分方案,推导并生成更高阶的假设;
(5) Proximity 相似度智能体同步计算假设间的语义关联并进行聚类去重,确保探索空间的多样性;
(6) Meta-review 元审查智能体负责汇总所有的评审与辩论记录,提取共性缺陷并将经验作为全局反馈直接注入后续的推理循环中。
同时,所有智能体在协同运行中产生的数据、试错记录和审查建议都会被实时写入全局上下文记忆库,确保长周期推理过程中的信息连贯与互通。正是这种架构设计,使得系统能够在推理阶段持续投入庞大的算力,完成复杂的自我进化。
Co-Scientist团队否定了AI能完全取代人类科学家。文中数据显示,人类的介入和引导会让系统生成质量更好的结果。如图3所示,随着计算迭代,人类专家参与引导的科学假设(蓝线),其质量最终超越了纯 AI 自发生成的假设(红线)。
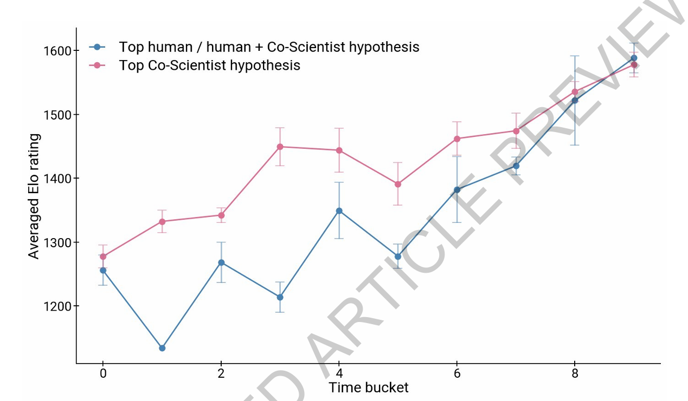 图3:人机协作评分曲线图
图3:人机协作评分曲线图
若无专家设定临床约束并主导方向,系统极易因源文献质量参差不齐或基础大模型固有幻觉产生无临床价值的输出。
** 这篇论文确立了专家在环的协作机制:AI 承担多学科文献阅读、高并发假设生成与智能体间的自我辩论。人类专家则负责定义研究边界、提供初始反馈,并对 AI 生成的候选方案进行审查和实验资源分配决策。**
** 论文通过三项高难度真实验证展示了系统的转化效能:**
 图4: Co-Scientist 在急性髓系白血病 (AML) 药物重定位中的应用与细胞实验验证
图4: Co-Scientist 在急性髓系白血病 (AML) 药物重定位中的应用与细胞实验验证
(1)系统为急性髓系白血病 (AML) 筛选出全新单药和协同联合用药方案。正如图4右侧的细胞存活率曲线所示,系统不仅挖掘出已有临床证据的药物,更独立提名了完全未被测试过的全新候选药物,体外数据证实其具备显著的肿瘤杀伤力。
 图5:Co-Scientist预测肝纤维化全新表观遗传靶点及人类肝脏类器官实验验证
图5:Co-Scientist预测肝纤维化全新表观遗传靶点及人类肝脏类器官实验验证
(2)系统成功预测肝纤维化的三个全新表观遗传靶点,匹配的药物中包含 FDA 已批准药物,并在人类肝脏类器官实验中证实其具备显著抗纤维化活性,且未引起任何细胞毒性。
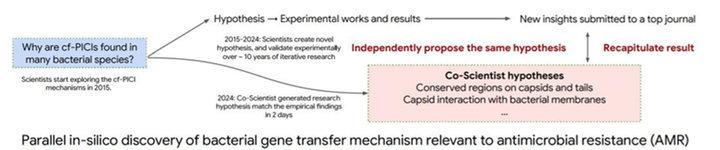 图6:Co-Scientist独立推演出的抗菌耐药性 (AMR) 细菌基因转移机制
图6:Co-Scientist独立推演出的抗菌耐药性 (AMR) 细菌基因转移机制
(3)基于极少初始背景,系统在2天内独立推演出抗菌耐药性 (AMR) 相关的细菌基因转移机制。如图6右侧对比所示,这一由 AI 仅用 2 天高效推演出的结果,与人类顶尖科学家耗时多年迭代验证、当时尚未正式发表的最新实验发现完全吻合。
当前系统仍面临诸如数据壁垒、事实性幻觉等挑战,但 Co-Scientist 成功打通从科学假设到实验验证的闭环,已确凿无疑地证明:科学发现的范式,正在从AI 辅助计算正式迈入AI 参与思考的新纪元。
论文二:完成从文献调研到科学假设流程
与第一篇论文不同,本文关注如何从海量文献与实验数据中提炼关键线索,形成具有创新性且可验证的科学假设。该研究构建了一种面向科学发现自动化的多智能体系统,将背景调研、假设生成、实验设计、数据分析与迭代优化整合到统一流程中,为AI驱动的科学发现提供了新的系统范式。

引用格式:GHAREEB A E, CHANG B, MITCHENER L, et al. A multi-agent system for automating scientific discoveryJ. Nature, 2026. DOI:10.1038/s41586-026-10652-y.
Robin是全球首个实现"文献调研-假设生成-实验设计-数据分析-迭代优化"全流程自动化的科学发现多智能体系统,其核心架构由三个功能高度专业化、职责明确分工的语言智能体组成:Crow(简洁文献检索智能体)、Falcon(深度文献评估智能体)和Finch(自主科学数据分析智能体)。三者基于框架协同调度,形成了"知识获取-知识合成-知识验证"的完整科学推理闭环,所有核心决策均由自主完成,人类仅需执行实验操作并提供原始数据。
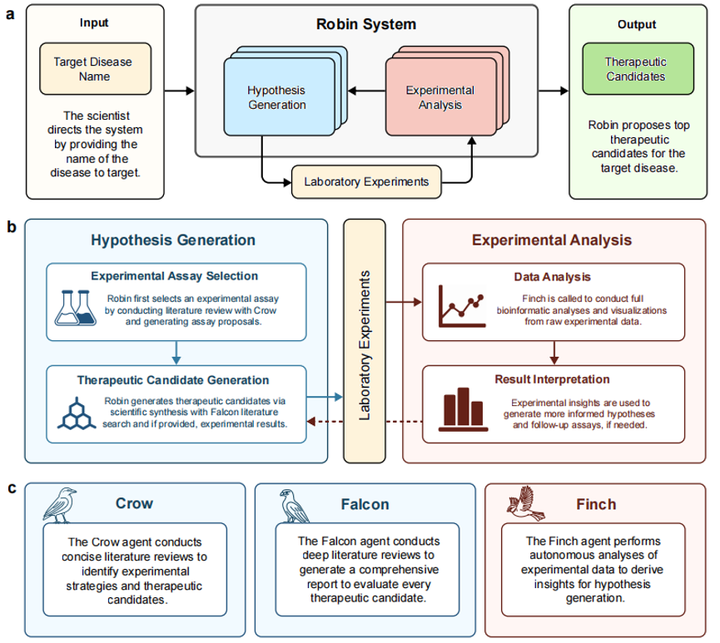 图1 Robin系统的架构与工作流程:A) 根据目标疾病名称,Robin可生成假设并筛选出最具潜力的治疗候选方案进行实验验证;该系统能自主分析实验原始数据,整合科学见解并提出更新的治疗假说;B) Robin通过与语言智能体交互来生成假设并分析实验数据;C) Crow和Falcon分别用于执行精炼型与深度型文献检索,以收集指导假说构建所需信息;Finch则负责对实验数据进行分析,Robin据此提取关键洞见为下一阶段假说生成提供依据。
图1 Robin系统的架构与工作流程:A) 根据目标疾病名称,Robin可生成假设并筛选出最具潜力的治疗候选方案进行实验验证;该系统能自主分析实验原始数据,整合科学见解并提出更新的治疗假说;B) Robin通过与语言智能体交互来生成假设并分析实验数据;C) Crow和Falcon分别用于执行精炼型与深度型文献检索,以收集指导假说构建所需信息;Finch则负责对实验数据进行分析,Robin据此提取关键洞见为下一阶段假说生成提供依据。
Robin最革命性的突破,在于它首次将科学发现的完整智力链条完全自动化。人类只需输入一个疾病名称,系统就能自主走完全部核心步骤,最终产出可验证的临床级候选药物。整个过程中,人类科学家仅需执行AI设计的实验并上传原始数据,所有智力决策均由AI独立完成。
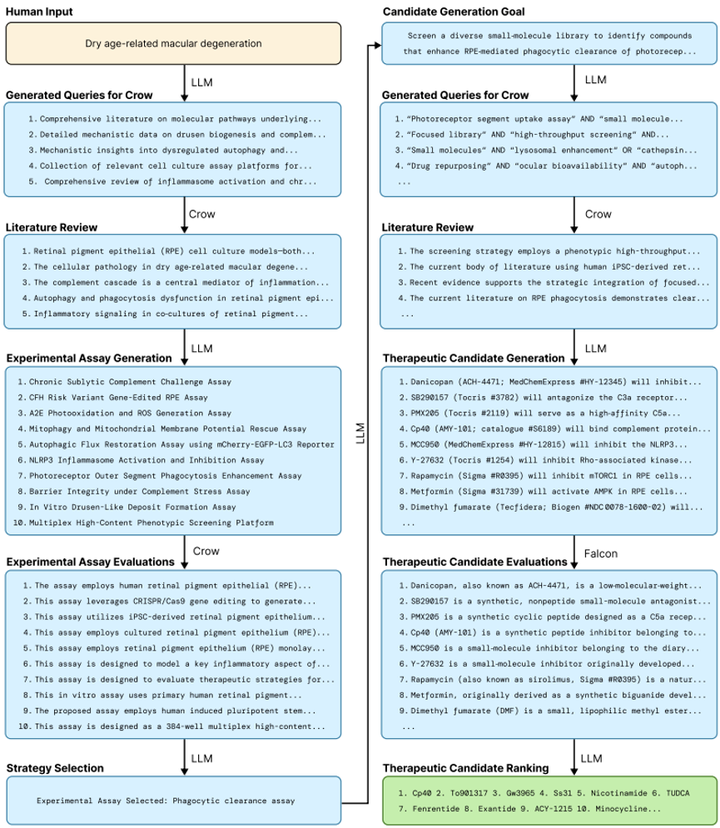 图 2 Robin实验检测方法及治疗候选药物假说生成的详细工作流程示例
图 2 Robin实验检测方法及治疗候选药物假说生成的详细工作流程示例
以下是基于干性年龄相关性黄斑变性(dAMD)案例的Robin完整工作流程逐环节深度拆解:
疾病机制探索与最优实验模型锁定
Robin接收目标疾病名称后,调用o4-mini生成科学问题,由Crow智能体执行批量文献检索;针对10种潜在致病机制生成对应体外实验方案,再由 Claude 3.7 Sonnet LLM法官通过两两比较和BTL模型排序,最终锁定增强RPE细胞吞噬功能为核心干预靶点及最优实验模型。
候选药物生成与科学严谨性排序
基于选定靶点,Crow智能体检索约400篇文献构建药物知识基础;Robin初步生成30个候选药物,由Falcon智能体进行多维度深度评估并生成完整报告;LLM法官再次通过BTL模型排序,筛选出Top5候选药物进入实验验证。
原始实验数据端到端自主分析
人类上传原始流式数据后,Robin启动10条独立的Finch数据分析轨迹并行处理;通过元分析统计各结论出现频率,生成标注支持度的共识性报告,有效解决了生物数据解释主观性和LLM输出随机性问题。
迭代优化与更优药物发现
Robin基于首轮实验结果提出RNA-seq机制解析建议,Finch完成转录组分析揭示ABCA1上调的关键机制;随后启动第二轮药物筛选,结合新机制重新检索文献并评估排序,最终发现效果更优的利帕舒地尔,完成完整科学发现闭环,全程耗时不到6个月。
该研究的核心价值在于展示了人工智能如何推动科学研究完成"从0到1"的突破。系统首先跳出既有研究路径依赖,通过大规模文献梳理重新识别疾病发生的关键机制,将研究焦点从传统干预方向转向细胞功能衰退这一更本质的病理环节;随后围绕新的科学假设开展候选策略筛选与实验验证,证明增强细胞自身清除能力具有显著效果;在此基础上,系统进一步根据实验反馈迭代研究方向,并主动设计转录组实验解析潜在分子机制,最终发现关键基因表达变化和新的潜在治疗靶点。整体来看,该工作打通了"文献理解---科学假设---实验验证---机制解析---靶点发现"的完整闭环,体现了多智能体系统在复杂科学问题中自主提出问题、验证问题并深化认知的能力。
论文三:面向可评分科研任务的自动化软件生成系统
这篇论文让AI不只是单纯写代码,而是能够围绕科研目标自动生成、执行并持续优化软件方案。Google团队提出自动化科研辅助系统ERA。该系统面向具有明确评价指标的科研任务,将任务描述、数据接口、评价函数与研究想法统一输入,由大语言模型生成候选程序,并通过沙盒执行、结果评分和树搜索机制不断迭代优化,最终获得高性能科研软件方案。不同于传统代码补全或AutoML,ERA将科研软件开发转化为一个可验证、可评分、可持续搜索的自动化过程,为大模型参与经验科学研究提供了新的系统范式。
引用格式:Aygün E, Belyaeva A, Comanici G, et al. An AI system to help scientists write expert-level empirical software J. Nature, 2026. DOI: 10.1038/s41586-026-10658-6.
这篇论文提出的系统名为ERA(Empirical Research Assistance)。它面向的是科研计算中一类更具体的问题:当一个科学任务可以用明确指标评价时,能否让 AI 自动生成、执行并改进相应的软件方案。
论文中将这类软件称为 empirical software,即以可测量质量指标为优化目标的科研软件。ERA的基本思路是将软件开发过程改写为一个程序搜索问题。系统首先接收任务描述、数据接口、评价函数和可能的研究想法;随后由大语言模型生成候选代码;候选代码在沙盒环境中执行并获得分数;树搜索算法根据历史代码的表现选择下一步扩展节点;新的代码继续被生成、执行和评分。最终,系统返回搜索过程中得分最高的程序。
本文的主要贡献在于把 LLM 代码改写、真实执行反馈、树搜索选择机制和外部研究想法注入结合起来,形成面向可评分科研任务的自动化软件优化框架。论文在Kaggle、单细胞数据整合、COVID-19 预测、时间序列预测、遥感分割、神经活动预测和困难积分求解等任务上进行了验证,其中单细胞任务中生成了 40 个超过公开榜单已发表方法的方案,COVID-19 预测中生成了 14 个超过官方 CovidHub ensemble 的策略。
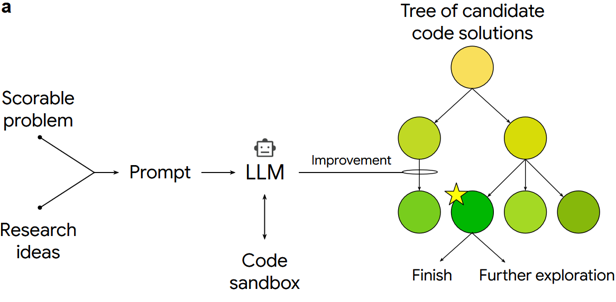 图1 ERA 算法示意图 图注:ERA的总体流程:可评分任务和研究想法输入 LLM,候选代码在沙盒中执行评分,并由树搜索选择后续扩展方向。
图1 ERA 算法示意图 图注:ERA的总体流程:可评分任务和研究想法输入 LLM,候选代码在沙盒中执行评分,并由树搜索选择后续扩展方向。
ERA 的核心机制是将科研软件开发从一次性代码生成转化为可评分的程序搜索。系统会把每一个候选程序作为搜索树中的代码节点,在沙盒环境中真实运行,并根据任务评价函数获得分数;随后通过PUCT选择机制,在已有高分方案和访问较少的新方向之间进行权衡。ERA会保留完整的历史搜索路径,将父节点代码、运行结果和评分反馈给大语言模型,持续生成新的候选代码。这样一来,当某条代码修改路线收益变小时,系统可以回到其他历史节点继续探索,而不是局限于当前版本反复微调,从而实现"利用已有优解"和"探索潜在新解"的动态平衡。
更进一步,ERA 并不是单纯依靠模型随机改写代码,而是将外部研究想法注入搜索过程。论文中使用的研究想法来源包括高被引论文、专业教材、搜索引擎结果,以及Gemini Deep Research和AI co-scientist生成的建议。这些想法不会直接作为最终答案,而是进入提示词,引导大语言模型在代码层面进行方法重组与结构性改写。以单细胞RNA测序批次整合任务为例,ERA并非简单复现已有方法,而是将不同方法的优势进行组合,在全局批次校正和局部近邻图建模之间形成新的技术路线。实验结果表明,多类ERA生成方案超过公开榜单,说明该系统的能力不止于调参优化,而是能够在已有科学方法之间进行自动化重组与迭代创新。
ERA也有明确限制。首先,如果指标不能真实反映科学价值,系统可能得到高分但解释意义有限的方案。其次,树搜索需要反复执行候选代码,计算成本随节点数量增加而上升。论文中提到,很多任务在 300---1000 个节点后得分趋于饱和,这意味着搜索预算本身也是系统性能的一部分。再次,ERA 主要优化的是经验软件表现,而不是直接完成理论发现、因果解释或实验设计判断。论文也强调,经验预测模型优化与真正科学发现之间仍需区分,后者还涉及机制解释、理论约束和科学意义评估。
ERA 提供的是一种面向可评分科研任务的自动化软件生成范式。对于机器学习和智能体研究而言,这篇工作的价值在于说明:当评价函数、执行环境和搜索策略被明确设计后,LLM 可以被嵌入一个可验证、可迭代的科研软件优化系统中,而不是仅作为文本或代码生成接口使用。