(叠甲:如有侵权请联系,内容都是自己学习的总结,一定不全面,仅当互相交流(轻点骂)我也只是站在巨人肩膀上的一个小卡拉米,已老实,求放过)
今天我们来聊一聊顺序表,顺序表是一种线性表,线性表的定义为------是n个具有相同特性的数据元素的有限序列,线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。这里的顺序表的物理结构是以数组的形式来存储的;
我们现在先分享一下静态顺序表,静态顺序表需要先使用宏定义,确认出数组的大小,缺点也在这里,不能够灵活的改变静态顺序表长度,但得益于数组是连续存储的有点,可以通过下标来访问其中的元素;静态顺序表的定义如下:
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#define N 7
typedef int SLdataType;
typedef struct Sqelist
{
SLdataType array[N];
size_t size;
}SqeList;补充一下size_t:size_t 是 C/C++ 标准库定义的一个核心无符号整数类型 ,专门用于表示 "内存大小、对象长度、数组下标" 这类非负的内存相关数值,是编写跨平台、健壮代码的关键类型之一。
size_t基本定义与本质
- 不是内置类型 :它是标准库通过
typedef定义的别名,而非 C/C++ 语言原生的int/long等类型。 - 定义位置 :
- C 语言:
<stddef.h>、<stdlib.h>、<string.h>等头文件 - C++:
<cstddef>(推荐,位于std命名空间)、<cstdlib>、<cstring>
- C 语言:
- 底层实现 :
- 32 位系统:通常是
unsigned int(32 位无符号整数) - 64 位系统:通常是
unsigned long long(64 位无符号整数) - 核心保证 :
size_t的大小始终等于系统的地址总线宽度 ,能容纳当前系统中最大可能对象的字节数。
- 32 位系统:通常是
补充一下#define _CRT_SECURE_NO_WARNINGS 1:是微软 Visual Studio 编译器特有的预处理宏定义,专门用于禁用 C 运行时库 (CRT) 中关于 "不安全函数" 的编译警告 (C4996)。
核心作用
- 屏蔽 C4996 警告:让你可以继续使用传统的 C 标准库函数,而不会被编译器提示 "该函数或变量可能不安全"
- 解决编译错误:如果你的项目开启了 "警告视为错误"(很多学校 / 公司的编译选项),不加这个宏会导致使用传统 C 函数的代码直接编译失败
为什么会有这个警告?
微软在 VS2005 及以后版本中,认为大量传统 C 标准库函数存在严重的安全隐患 ,主要是缓冲区溢出漏洞。这些函数不检查目标缓冲区的大小,容易被恶意利用导致程序崩溃或执行任意代码。
会触发 C4996 警告的常见函数
| 传统 "不安全" 函数 | 微软推荐的 "安全" 版本 | 存在的问题 |
|---|---|---|
scanf, printf |
scanf_s, printf_s |
不检查输入 / 输出缓冲区长度 |
strcpy, strcat |
strcpy_s, strcat_s |
字符串复制时可能越界 |
gets |
fgets |
已被 C11 标准彻底废弃,极度危险 |
sprintf, vsprintf |
sprintf_s, vsprintf_s |
格式化输出可能溢出缓冲区 |
strlen |
strnlen_s |
对非空终止字符串会导致内存越界 |
fopen, freopen |
fopen_s, freopen_s |
文件打开时的安全问题 |
关键使用规则
1.必须写在所有 #include 之前
cpp
// ✅ 正确:先定义宏,再包含头文件
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <string.h>
// ❌ 错误:头文件已经包含,宏定义无效
#include <stdio.h>
#define _CRT_SECURE_NO_WARNINGS 12.只对当前源文件有效 每个需要使用传统函数的.c/.cpp 文件都需要单独定义这个宏。
重要提醒
⚠️ 这个宏只是 "掩耳盗铃" :它不会修复任何安全问题,只是让编译器闭嘴。函数本身的缓冲区溢出漏洞依然存在。
更好的替代方案
1.使用 C++ 标准库(推荐)
cpp
// 代替scanf/printf
#include <iostream>
using namespace std;
int n;
cin >> n; // 自动处理类型和缓冲区
cout << n << endl;
// 代替strcpy/strcat
#include <string>
string s1 = "hello", s2 = "world";
string s3 = s1 + s2; // 自动管理内存2.使用标准 C 的安全函数
优先使用 C 标准中已经存在的安全版本,而不是微软特有的_s函数:
- 用
fgets代替gets - 用
snprintf代替sprintf - 用
strncpy+ 手动加 '\0' 代替strcpy
3.项目级禁用警告
在 VS 项目属性中设置: 项目属性 → C/C++ → 高级 → 禁用特定警告,添加4996
跨平台说明
_CRT_SECURE_NO_WARNINGS是微软独有的宏,在 GCC、Clang 等其他编译器中没有任何作用。如果你需要编写跨平台代码,应该:
- 避免使用
_s系列函数(非标准) - 使用标准 C 的安全函数
- 或者通过条件编译让宏只在 VS 下生效:
cpp
#ifdef _MSC_VER
#define _CRT_SECURE_NO_WARNINGS 1
#endif我们再来分享一下动态表,动态表使用到了指针,会用到扩容函数,接口实现
cpp
typedef int SLdataType;
typedef struct SqeList
{
SLdataType* arry;
size_t size;
size_t capacity;
}SeqList;
//动态顺序表的定义动态顺序表的各大接口定义
cpp
//动态表的初始化
void SeqListInit(SeqList* array, size_t capacity)
{
array->arry = NULL;
array->size = 0;
array->capacity = 0;
}
cpp
//动态表的扩容函数
void CheckCapcity(SeqList* array)
{
if (!array->capacity)
{
array->capacity = 4;
SLdataType* temp = (SLdataType*)realloc(array->arry, array->capacity * sizeof(SLdataType));
if (!temp)
{
perror("realloc 扩展失败");
}
array->arry = temp;
return;
}
if (array->size == array->capacity)
{
array->capacity = 2 * array->capacity;
SLdataType* temp = (SLdataType*)realloc(array->arry, array->capacity * sizeof(SLdataType));
if (!temp)
{
perror("realloc 扩展失败");
}
array->arry = temp;
return;
}
}C 语言 malloc、calloc、realloc 函数详解
calloc 和 realloc 与 malloc 并称为 C 语言三大动态内存分配函数 ,均定义在 <stdlib.h> 头文件中,用于在堆内存上分配可手动管理生命周期的内存块。三者核心区别在于分配方式、初始化行为和用途。
一、calloc 函数:分配并清零的数组内存
1. 函数原型
cpp
void *calloc(size_t num_elements, size_t element_size);2. 核心作用
分配一块连续的内存空间 ,总大小为 num_elements × element_size 字节,并且自动将所有字节初始化为 0 。这是它与 malloc 最本质的区别(malloc 只分配内存,内容为随机垃圾值)。
3. 参数与返回值
num_elements:要分配的元素个数element_size:单个元素的字节大小(通常用sizeof(类型)获取)- 返回值:
- 成功:返回指向分配内存起始地址的
void*指针,需强制类型转换为目标类型 - 失败:返回
NULL(内存不足时)
- 成功:返回指向分配内存起始地址的
4. 典型用法示例
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <stdlib.h>
int main() {
// 分配5个int类型的数组,每个元素自动初始化为0
int *arr = (int *)calloc(5, sizeof(int));
// 必须检查分配是否成功!
if (arr == NULL) {
perror("calloc 分配内存失败");
return 1;
}
// 输出:0 0 0 0 0(所有元素已清零)
for (int i = 0; i < 5; i++) {
printf("%d ", arr[i]);
}
// 用完必须释放内存
free(arr);
arr = NULL; // 防止野指针
return 0;
}- 与
malloc的对比
| 特性 | malloc(size_t total_size) |
calloc(size_t num, size_t size) |
|---|---|---|
| 初始化 | 不初始化,内容为随机值 | 所有字节初始化为 0 |
| 参数 | 总字节数 | 元素个数 × 单个元素大小 |
| 适用场景 | 不需要初始化的任意内存 | 需要清零的数组、结构体 |
| 性能 | 略快(无需清零) | 略慢(多了清零步骤) |
小技巧:如果需要手动清零,
calloc比malloc + memset更简洁,且在某些系统上更高效(操作系统可能已预先清零了空闲内存页)。
二、realloc 函数:调整已分配内存的大小
realloc 是三个函数中最复杂、最容易出错的一个,核心功能是修改之前已经分配的动态内存块的大小(扩大或缩小)。
- 函数原型
cpp
void *realloc(void *old_ptr, size_t new_total_size);2. 核心工作原理(关键!)
realloc 会根据当前内存布局,尝试用以下两种方式调整内存大小:
- 原地扩展(最优情况) :如果原内存块后面有足够的连续空闲空间,直接在原地址扩展,返回原指针,原数据完全保留。
- 异地迁移(常见情况) :如果原内存块后面没有足够空间,会:
- 重新分配一块大小为
new_total_size的新内存 - 将原内存中的数据完整复制到新内存的前半部分
- 自动释放原内存块
- 返回新的指针地址
- 重新分配一块大小为
3. 特殊情况处理
- 如果
old_ptr == NULL:等价于malloc(new_total_size) - 如果
new_total_size == 0:等价于free(old_ptr),返回NULL(C 标准规定,但不同编译器实现略有差异) - 如果
new_total_size < 原大小:会截断原内存,保留前new_total_size字节的数据,后面的部分被释放
4. 最常见的致命错误(90% 的初学者会踩坑)
❌ 错误用法:直接用原指针接收返回值
cpp
int *arr = (int *)malloc(5 * sizeof(int));
arr = (int *)realloc(arr, 10 * sizeof(int)); // 绝对禁止!后果 :如果 realloc 失败返回 NULL,原指针 arr 会被覆盖为 NULL,导致原来的内存块再也无法释放,造成永久性内存泄漏。
正确用法:用临时指针接收返回值
cpp
int *arr = (int *)malloc(5 * sizeof(int));
if (arr == NULL) { /* 错误处理 */ }
// 第一步:用临时指针接收realloc返回值
int *temp = (int *)realloc(arr, 10 * sizeof(int));
// 第二步:检查是否成功
if (temp == NULL) {
perror("realloc 扩展失败");
free(arr); // 原内存仍然有效,必须手动释放!
return 1;
}
// 第三步:成功后再赋值给原指针
arr = temp;典型用法示例
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
// 初始分配10字节的字符串缓冲区
char *str = (char *)malloc(10 * sizeof(char));
if (str == NULL) {
perror("malloc 失败");
return 1;
}
strcpy(str, "Hello");
printf("初始内容:%s,地址:%p\n", str, str);
// 扩展缓冲区到20字节
char *temp = (char *)realloc(str, 20 * sizeof(char));
if (temp == NULL) {
perror("realloc 失败");
free(str);
return 1;
}
str = temp;
strcat(str, " World!");
printf("扩展后内容:%s,地址:%p\n", str, str); // 地址可能不变也可能变
// 缩小缓冲区到6字节(只保留"Hello")
temp = (char *)realloc(str, 6 * sizeof(char));
if (temp == NULL) {
perror("realloc 缩小失败");
free(str);
return 1;
}
str = temp;
printf("缩小后内容:%s,地址:%p\n", str, str); // 字符串自动截断
free(str);
str = NULL;
return 0;
}三、三大动态内存分配函数对比
| 函数 | 原型 | 核心功能 | 初始化 | 适用场景 |
|---|---|---|---|---|
malloc |
void *malloc(size_t size) |
分配指定字节数的内存 | 不初始化 | 不需要清零的任意内存 |
calloc |
void *calloc(size_t num, size_t size) |
分配数组内存 | 所有字节清零 | 需要初始化的数组、结构体 |
realloc |
void *realloc(void *ptr, size_t size) |
调整已分配内存的大小 | 新扩展部分不初始化 | 动态扩容 / 缩容(如动态数组) |
四、通用注意事项(必须遵守)
1.所有动态内存必须手动释放
- 用
free(指针)释放,释放后内存归还给操作系统 - 只能释放由
malloc/calloc/realloc返回的指针,不能释放栈内存(如局部数组) - 禁止双重释放(同一个指针 free 两次),会导致程序崩溃
2.释放后立即将指针置为 NULL
cpp
free(arr);
arr = NULL; // 防止野指针,后续误访问会直接报错3.每次分配都必须检查返回值
内存不足时所有函数都会返回 NULL,解引用 NULL 指针会导致程序直接崩溃(段错误)。
4.realloc 不会自动初始化新扩展的内存
例如原内存是 5 个 int,扩展到 10 个 int 后,后 5 个 int 的内容是随机值,需要手动初始化。
5.realloc 迁移内存会导致所有指向原内存的指针失效
如果有多个指针指向同一块动态内存,realloc 迁移后这些指针都会变成野指针,需要全部更新为新地址。
当返回值为void时return后面可以什么都不跟吗?
完全可以 ,而且return;(后面什么都不跟)是void类型函数中唯一合法的 return 形式。
核心规则
void类型函数的含义是 "不返回任何值",因此:
- ✅ 允许 :
return;(不带任何表达式) - ❌ 禁止 :
return 0;、return x;等任何带表达式的 return 语句 - ✅ 允许 :函数执行到末尾没有任何 return 语句(会自动隐式执行
return;)
详细用法说明
1. return; 的作用:提前退出函数
void函数中的return语句不是用来返回值的 ,而是用来立即终止函数执行并返回到调用点。
cpp
#include <stdio.h>
void print_positive(int num) {
if (num <= 0) {
// 满足条件时提前退出,不执行后面的代码
return;
}
printf("正数:%d\n", num);
}
int main() {
print_positive(5); // 输出:正数:5
print_positive(-3); // 什么都不输出
return 0;
}2. 函数末尾的隐式 return
如果void函数执行到最后一个语句都没有遇到return,编译器会自动在函数末尾插入一个return;。因此下面两个函数完全等价:
cpp
// 版本1:显式写return
void say_hello() {
printf("Hello World!\n");
return; // 可以省略
}
// 版本2:隐式return(推荐写法,更简洁)
void say_hello() {
printf("Hello World!\n");
// 函数结束时自动执行 return;
}3. 空函数的写法
空函数(什么都不做的函数)可以写成以下任意一种形式,效果完全相同:
cpp
// 写法1:空函数体
void do_nothing() {}
// 写法2:显式return
void do_nothing() {
return;
}空函数通常用于占位、接口实现或回调函数的默认处理。
常见误区与注意事项
❌ 误区 1:在 void 函数中返回值
这是最常见的编译错误。任何带表达式的 return 语句在 void 函数中都是非法的:
cpp
void add(int a, int b) {
return a + b; // 编译错误!void函数不能返回值
}❌ 误区 2:混淆 void 函数和 main 函数
main 函数的返回值类型永远是 int,不是 void!
- 标准 C 写法:
int main(void)或int main(int argc, char *argv[]) - 虽然部分旧编译器(如 VC6)允许
void main(),但这是非标准、不可移植的写法 - C99 及以后标准规定:如果 main 函数末尾没有写
return 0;,编译器会自动插入一个
❌ 误区 3:非 void 函数省略 return
对于返回值类型不是 void 的函数,必须在所有可能的执行路径上都有 return 语句,否则会导致未定义行为(程序可能崩溃或返回随机值)。
cpp
int max(int a, int b) {
if (a > b) {
return a;
}
// 当a <= b时,没有return语句,未定义行为!
}正确示例:
cpp
int max(int a, int b) {
if (a > b) {
return a;
} else {
return b;
}
}总结
| 函数返回值类型 | 允许的 return 形式 | 末尾无 return 时的行为 |
|---|---|---|
void |
只能是 return; |
自动执行 return; |
int/char/float等 |
必须返回对应类型的值 | 未定义行为(C99 + 仅 main 函数自动返回 0) |
printf(a); 的错误原因与正确修改方法
printf(a); 是 C 语言中最常见的初学者错误,会导致编译警告或运行时崩溃(未定义行为)。
核心错误原因
printf 函数的第一个参数必须是格式字符串 (用双引号 " 括起来),而不是直接写变量名。格式字符串中通过格式说明符 (如 %d、%f)指定后续变量的输出类型。
如果直接写 printf(a);,编译器会把变量 a 的值当作内存地址去读取格式字符串,当 a 的值包含 % 字符时,会触发越界访问或输出垃圾数据。
按变量类型的正确修改方式
根据变量 a 的不同数据类型,使用对应的格式说明符:
| 变量类型 | 错误写法 | 正确写法 | 说明 |
|---|---|---|---|
| 整数(int) | printf(a); |
printf("%d", a); |
输出十进制整数 |
| 浮点数(float/double) | printf(a); |
printf("%f", a); |
输出浮点数(默认保留 6 位小数) |
| 字符(char) | printf(a); |
printf("%c", a); |
输出单个字符 |
| 字符串(char* /char \[\]) | printf(a); |
printf("%s", a); |
输出字符串 |
| 无符号整数(unsigned int) | printf(a); |
printf("%u", a); |
输出无符号十进制整数 |
| 十六进制整数 | printf(a); |
printf("%x", a); |
输出小写十六进制数 |
cpp
#include <stdio.h>
int main() {
int a = 10;
float b = 3.14;
char c = 'A';
char d[] = "Hello, World!";
// 正确输出不同类型的变量
printf("整数:%d\n", a);
printf("浮点数:%f\n", b);
printf("字符:%c\n", c);
printf("字符串:%s\n", d);
// 进阶:控制输出格式
printf("浮点数保留2位小数:%.2f\n", b);
printf("整数占5个字符宽度:%5d\n", a);
return 0;
}特殊情况:直接输出字符串常量
如果只是想输出固定的文本,不需要变量,直接把字符串写在 printf 的第一个参数位置即可:
cpp
// 正确
printf("Hello, World!\n");
// 错误(不需要加变量)
printf("%s", "Hello, World!\n"); // 虽然能运行,但多余更安全的替代方案
- 输出字符串:优先使用
puts(a);(会自动换行),比printf("%s", a);更安全,不会解析%字符 - 输出单个字符:使用
putchar(c);
常见延伸错误
1.格式说明符与变量类型不匹配
cpp
int x = 10;
printf("%f", x); // 错误:%f 用于浮点数,会输出垃圾值2.缺少参数:
cpp
printf("%d"); // 错误:没有提供要输出的变量3.多余参数:
cpp
int x = 10;
printf("Hello", x); // 警告:多余的参数 x 会被忽略C 语言打印地址的专用格式说明符:%p
%p 是 C 标准中专门用于打印指针(内存地址)的格式说明符,也是唯一跨平台安全、可移植的打印地址方式。
核心用法
打印地址需要两个关键部分:
%p:格式说明符,告诉 printf 这是一个指针类型&取地址符:获取变量在内存中的地址
基础示例
cpp
#include <stdio.h>
int main() {
int a = 100;
int *p = &a; // 指针变量p存储了a的地址
printf("变量a的值:%d\n", a);
printf("变量a的地址:%p\n", &a); // 最常用:直接打印变量地址
printf("指针p的值:%p\n", p); // 指针变量本身存储的就是地址
printf("指针p自己的地址:%p\n", &p); // 指针变量也有自己的内存地址
return 0;
}为什么不能用 %d 或 %x 打印地址?
这是初学者最常见的错误,绝对不推荐:
| 格式说明符 | 问题所在 | 风险 |
|---|---|---|
%d |
用于有符号整数,通常是 32 位 | 在 64 位系统上,地址是 64 位,会被截断,只显示低 32 位,导致地址错误 |
%x / %X |
用于无符号十六进制整数,通常是 32 位 | 同样存在64 位地址截断问题,且输出格式不标准 |
%llx |
用于 64 位整数 | 不具备可移植性,在 32 位系统上会出错 |
%p 的优势:自动适配当前系统的指针大小(32 位系统输出 32 位地址,64 位系统输出 64 位地址),是唯一符合 C 标准的跨平台写法。
常见地址打印场景
1. 打印数组地址
cpp
int arr[5] = {1, 2, 3, 4, 5};
printf("数组首地址:%p\n", arr); // 数组名本身就是首元素地址
printf("数组首地址:%p\n", &arr[0]);// 等价于上面
printf("第二个元素地址:%p\n", &arr[1]);- 打印字符串地址
cpp
char str[] = "Hello";
printf("字符串首地址:%p\n", str);
printf("第一个字符地址:%p\n", &str[0]);- 打印空指针
cpp
int *p = NULL;
printf("空指针的值:%p\n", p); // 通常输出 0x0 或 (nil)进阶:控制地址输出格式
- 强制显示 0x 前缀 :使用
%#p(大多数编译器默认已经显示 0x) - 固定宽度输出 :使用
%16p让地址占 16 个字符宽度,右对齐 - 左对齐输出 :使用
%-16p
cpp
int a = 10;
printf("标准格式:%p\n", &a);
printf("固定16位宽度:%16p\n", &a);
printf("左对齐16位:%-16p\n", &a);重要注意事项
1.%p 输出的是虚拟地址:不是物理内存地址,是操作系统给进程分配的虚拟地址空间
2.不同运行的地址不同:每次运行程序,变量的地址通常都会变化,这是正常的
3.不要直接修改地址值:直接操作内存地址非常危险,只有在嵌入式开发等特殊场景才会用到
使用注意事项
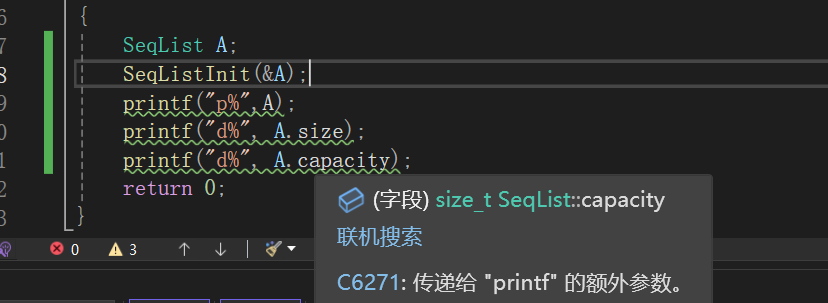
核心错误:格式说明符写反了!
你把 %d 写成了 d%,把 %p 写成了 p%,这是 C 语言初学者最容易犯的低级错误 ,也是编译器报 C6271 警告的直接原因。
为什么会报 C6271 警告?
printf 解析格式字符串的规则是:遇到 % 才认为后面跟着一个格式说明符。
当你写 printf("p%", A); 时:
printf看到字符串"p%",先输出字符p- 然后遇到
%,但%后面没有任何字符(字符串结束了) - 所以
printf认为这个格式字符串不需要任何参数 - 但你却额外传了参数
A,编译器就会警告:传递给 "printf" 的额外参数
逐行修正代码
cpp
printf("p%",A); // 错误1:格式符写反+类型不匹配
printf("d%", A.size); // 错误2:格式符写反
printf("d%", A.capacity); // 错误3:格式符写反+类型不匹配
// 1. 打印结构体A的地址(用%p,取地址符&)
printf("结构体A的地址:%p\n", &A);
// 2. 打印size成员(用%zu,因为size_t是无符号整数类型)
printf("size = %zu\n", A.size);
// 3. 打印capacity成员(同样用%zu)
printf("capacity = %zu\n", A.capacity);额外重要修正点
1.结构体不能直接用 %p 打印 :A 是 SeqList 结构体变量,不是指针。要打印它的地址必须加取地址符 &A。
2.size_t 类型必须用 %zu :你的代码提示里明确写了 size_t SeqList::capacity。size_t 在 64 位系统上是 64 位无符号整数,用 %d(32 位有符号)会导致类型不匹配,出现未定义行为。
3.一定要加换行符 \n:否则所有输出会连在一起,可读性极差。
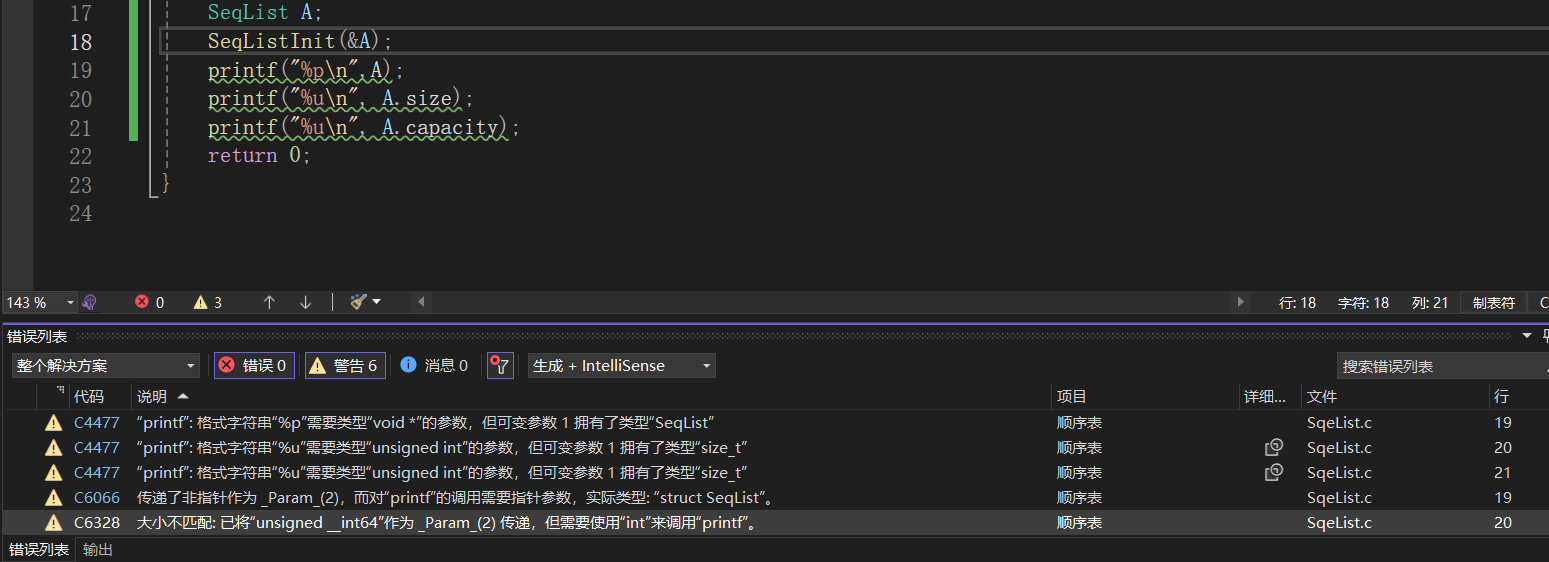
逐行精准解决所有 6 个警告
错误 1(第 19 行):结构体不能直接传给%p
警告原因
%p格式说明符只接受指针类型 (void*)- 你直接传了
A,它是SeqList结构体变量,不是指针 - 编译器报
C4477和C6066两个警告,本质是同一个问题
正确修改
必须加取地址符 &,获取结构体的内存地址:
cpp
// 错误写法
printf("%p\n", A);
// 正确写法
printf("结构体A的地址:%p\n", &A);错误 2(第 20、21 行):size_t 不能用 %u 打印
警告原因
- 你的代码提示明确显示
size和capacity是size_t类型 size_t在64 位系统上是 64 位无符号整数 (unsigned __int64)%u只对应32 位无符号整数 (unsigned int)- 类型和大小都不匹配,所以报
C4477和C6328警告
正确修改
使用 C 标准专门为size_t设计的格式说明符 %zu:
cpp
// 错误写法
printf("%u\n", A.size);
printf("%u\n", A.capacity);
// 正确写法
printf("size = %zu\n", A.size);
printf("capacity = %zu\n", A.capacity);Visual Studio 特殊说明
如果你用的是非常老的 VS 版本(VS2010 及以前),不支持%zu,可以临时用%Iu替代:
cpp
// 仅适用于老版本VS,不推荐
printf("size = %Iu\n", A.size);但强烈建议使用标准的%zu,所有现代编译器(VS2012+、GCC、Clang)都完美支持。
size_t 的正确承接变量与最佳实践
最标准、最安全、最可移植的答案是:用 size_t 类型本身来承接。
size_t 不是一个基本类型,而是 C 标准库定义的无符号整数类型别名,专门用来表示内存大小、数组长度、元素个数等 "不可能为负数" 的量。
一、为什么不能用 int/unsigned int 承接?
这是 90% 的 C 语言初学者都会犯的错误,也是你之前看到 C6328 警告的根本原因:
| 类型 | 32 位系统大小 | 64 位系统大小 | 最大取值 | 问题所在 |
|---|---|---|---|---|
int |
32 位 | 32 位 | 2147483647 | 有符号,无法表示大于 21 亿的数值;64 位系统下会截断高位 |
unsigned int |
32 位 | 32 位 | 4294967295 | 无符号,但 64 位系统下仍然是 32 位,会截断 64 位的size_t值 |
size_t |
32 位 | 64 位 | 随系统自动适配 | 完全匹配,无任何问题 |
致命后果 :当size_t的值超过unsigned int的最大值(4294967295)时,用unsigned int承接会导致数值完全错误,引发数组越界、内存泄漏等严重 bug。
二、正确的使用方式
1. 变量定义
cpp
#include <stddef.h> // size_t定义在这里,必须包含(很多头文件会间接包含,但显式包含更规范)
// 正确:用size_t承接size_t返回值
size_t len = strlen("hello world");
size_t arr_size = sizeof(int) * 100;
// 你的顺序表结构体正确定义
typedef struct {
int* arr;
size_t size; // 元素个数,必须是size_t
size_t capacity; // 容量,必须是size_t
} SeqList;2. 函数参数与返回值
cpp
// 正确:函数参数和返回值都用size_t
size_t SeqListGetSize(const SeqList* ps) {
assert(ps != NULL);
return ps->size;
}
void SeqListInsert(SeqList* ps, size_t pos, int val) {
assert(ps != NULL);
// 这里pos是size_t,所以不需要判断pos >= 0
assert(pos <= ps->size);
// ...
}3. 循环变量
cpp
// 正确:遍历数组用size_t作为循环变量
for (size_t i = 0; i < ps->size; i++) {
printf("%d ", ps->arr[i]);
}三、size_t 无符号特性的注意事项
size_t 是无符号整数,这意味着它永远不会是负数。这个特性带来了一些需要特别注意的坑:
坑 1:无符号数减法永远不会为负
cpp
size_t a = 5;
size_t b = 10;
// 错误!a - b 不是 -5,而是一个非常大的正数(4294967291)
if (a - b < 0) {
printf("a < b"); // 永远不会执行
}
// 正确写法:直接比较两个数
if (a < b) {
printf("a < b"); // 正常执行
}坑 2:不要用负数给size_t赋值
cpp
// 错误!-1会被转换为size_t的最大值
size_t x = -1;
printf("%zu\n", x); // 输出:18446744073709551615(64位系统)坑 3:与有符号数混合运算
cpp
int i = -1;
size_t s = 10;
// 错误!i会被转换为size_t,变成一个很大的正数
if (i < s) {
printf("i < s"); // 永远不会执行
}
// 正确写法:将size_t强制转换为有符号数(确保数值在int范围内)
if (i < (int)s) {
printf("i < s"); // 正常执行
}四、特殊情况:什么时候可以用其他类型?
1. 与旧代码兼容
如果你的代码需要和大量使用int表示长度的旧代码交互,可以临时用int承接,但必须添加范围检查:
cpp
size_t len = strlen(str);
// 确保长度不会超过int的最大值
assert(len <= INT_MAX);
int int_len = (int)len;2. 需要表示负数的场景
如果某个值可能为负数(比如函数返回 - 1 表示错误),请使用ssize_t(有符号版本的size_t):
cpp
#include <unistd.h> // ssize_t定义在这里
// 正确:read函数返回ssize_t,-1表示错误
ssize_t bytes_read = read(fd, buf, sizeof(buf));
if (bytes_read == -1) {
// 处理错误
}注意 :ssize_t是 POSIX 标准,不是 C 标准,在 Windows 上可能需要用__int64替代。
assert() 详解:C 语言最常用的调试利器
assert() 是 C 标准库提供的调试断言宏 (注意:它是宏,不是函数),专门用于在开发阶段快速定位程序员的逻辑错误,是数据结构(比如你正在写的顺序表)开发中必不可少的工具。
核心作用
验证程序中 "绝对应该成立" 的条件 。如果条件不成立,说明你的代码有 bug,assert() 会立刻终止程序,并打印出精确的错误位置和原因,帮你一秒定位问题。
基本用法
cpp
#include <assert.h> // 必须包含这个头文件
assert(表达式);- 当表达式为真时:什么都不做,程序继续运行
- 当表达式为假 时:
- 打印错误信息(包含:文件名、行号、出错的表达式内容)
- 调用
abort()函数强制终止程序
cpp
int divide(int a, int b) {
// 断言:除数绝对不能为0
assert(b != 0); // 如果b=0,程序立刻崩溃并报错
return a / b;
}
int main() {
divide(10, 0); // 这里会触发断言
return 0;
}触发断言时的输出
cpp
Assertion failed: b != 0, file test.c, line 4最重要的特性:发布版本自动消失
这是 assert() 最强大也最容易被误解的地方:
- 在调试版本(Debug)中:断言正常工作,帮你检查错误
- 在发布版本 (Release)中:所有断言会被完全编译掉,不产生任何代码,不影响程序性能
实现原理:在发布版本中编译器会自动定义 NDEBUG 宏,assert.h 头文件中会把 assert() 定义为空:
cpp
#ifdef NDEBUG
#define assert(expression) ((void)0)
#endif最佳实践与常见误区
✅ 正确用法
- 用来检查程序员的错误(比如空指针、越界访问、非法参数)
- 用来验证永远不应该发生的情况
- 每个断言只检查一个条件,方便定位
- 放在函数的开头,先做参数检查
❌ 绝对不要这么做
1.不要用 assert () 处理用户输入错误
cpp
// 错误!发布版本中这个检查会消失
int age;
scanf("%d", &age);
assert(age >= 0 && age <= 150); 用户输入错误是运行时错误,必须用 if 语句处理并给出友好提示。
2.不要在 assert () 中写有副作用的代码
cpp
// 致命错误!发布版本中i++不会执行
assert(i++ < 10);发布版本中这行代码会完全消失,i 的值永远不会增加。
3.不要用 assert () 代替错误处理
断言只用于调试,真正的错误处理(比如文件打开失败、内存分配失败)在发布版本中仍然需要处理。
assert() vs if 语句
| 场景 | 用 assert() |
用 if 语句 |
|---|---|---|
| 检查程序员的逻辑错误 | ✅ 是 | ❌ 否 |
| 检查用户输入错误 | ❌ 否 | ✅ 是 |
| 检查外部资源错误(文件、网络) | ❌ 否 | ✅ 是 |
| 需要在发布版本中保留检查 | ❌ 否 | ✅ 是 |
| 需要快速定位 bug 位置 | ✅ 是 | ❌ 否 |

LNK1168 错误:VS 最常见的非代码错误
这个错误和你的代码完全无关 ,是 VS 编译链接时的文件锁定问题,99% 的情况都是同一个原因:
核心原因
你上一次运行的 "顺序表.exe" 程序还在后台运行,没有完全退出 。 Windows 系统会锁定正在运行的可执行文件,不允许其他程序(包括 VS)修改或覆盖它。所以当 VS 编译出新的版本,想要写入D:\VS2022\项目\顺序表\x64\Debug\顺序表.exe时,就会报错 "无法打开进行写入"。
按成功率排序的解决方法
方法 1:一键解决(90% 的情况)
直接点击 VS 工具栏上的红色方块停止调试按钮(▶️ 旁边的那个)。
很多人以为关闭了控制台黑窗口程序就退出了,但有时候程序崩溃、卡在死循环或者断点处,窗口关了但进程还在后台运行。
方法 2:任务管理器手动杀进程(100% 解决)
如果方法 1 没用,直接手动结束进程:
- 按下
Ctrl + Shift + Esc打开任务管理器 - 在 "详细信息" 标签页中找到
顺序表.exe - 右键点击它,选择 "结束任务"
- 回到 VS,重新编译运行即可
方法 3:清理解决方案后重新生成
如果以上方法都不行,执行一次完整的清理:
- 右键点击解决方案资源管理器中的 "顺序表" 项目
- 选择 "清理"
- 清理完成后,再右键点击选择 "重新生成"
其他可能的原因(极少遇到)
1.杀毒软件拦截:某些杀毒软件会把你编译的程序误判为病毒,锁定文件。可以暂时关闭杀毒软件的实时防护试试。
2.文件权限问题:把项目文件夹放在系统盘(C 盘)的某些受保护目录下会导致权限不足。建议把项目放在 D 盘等非系统盘。
3.路径包含中文 / 特殊字符:虽然 VS2022 对中文路径支持好了很多,但偶尔还是会出问题。如果你的项目路径有中文,可以改成纯英文试试。
预防方法
每次重新运行程序之前,先点击一次停止调试按钮,确保上一个进程已经完全退出。特别是在调试有断点的代码时,很容易出现这个问题。
🆗以上是在写顺序表过程中引发的疑问与思考,接下来是关于我写的动态顺序表的完整代码;
cpp
//SeqList.h
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include <assert.h> //没这个assert()用不了
#include <stddef.h>
// size_t定义在这里,必须包含(很多头文件会间接包含,但显式包含更规范)
typedef int SLdataType;
typedef struct SeqList
{
SLdataType* arry;
size_t size;
size_t capacity;
}SeqList;
void SeqListInit(SeqList* A)
{
assert(A);
A->arry = NULL;
A->size = 0;
A->capacity = 0;
}
void CheckCapcity(SeqList* A)
{
assert(A);
if (!A->capacity)
{
A->capacity = 4;
SLdataType* temp = (SLdataType*)realloc(A->arry, A->capacity * sizeof(SLdataType));
if (!temp)
{
perror("realloc 扩容失败");
}
A->arry = temp;
printf("扩容成功,当前总容量为%zu\n", A->capacity);
return;
}
if (A->size == A->capacity)
{
A->capacity = 2 * A->capacity;
SLdataType* temp = (SLdataType*)realloc(A->arry, A->capacity * sizeof(SLdataType));
if (!temp)
{
perror("realloc 扩容失败");
}
A->arry = temp;
printf("扩容成功,当前总容量为%zu\n", A->capacity);
return;
}
}
void SeqListFrontIsert(SeqList* A,SLdataType data)
{
assert(A);
CheckCapcity(A);
for (size_t i = A->size; i >0;i--)
{
A->arry[i] = A->arry[i - 1];
}
A->arry[0] = data;
A->size++;
printf("%d头插成功\n",data);
}
void SeqListPrint(SeqList A)
{
if (!A.size)
{
printf("该顺序表为空,请输入数据之后再进行打印");
}
else
{
for (int i = 0; i < A.size; i++)
{
printf("%d ", A.arry[i]);
}
}
printf("\n");
}
void SeqListBackInsert(SeqList* A, SLdataType data)
{
assert(A);
CheckCapcity(A);
A->arry[A->size] = data;
A->size++;
printf("%d尾部插入成功\n", data);
}
int SeqListElementFind(SeqList A, SLdataType data)
{
if (!A.size)
{
printf("当前顺序表为空,请填入数据后再进行查找\n");
return -1;
}
else
{
for (size_t i = 0; i < A.size; i++)
{
if (A.arry[i] == data)
{
printf("找到你需要的数据了,它的存储位置在顺序表的%zu\n", i);
return (int)i;
}
}
}
printf("很遗憾,未能找到您需要的数据,无法进行后续操作\n");
return -1;
}
void SeqListDeleteFront(SeqList* A)
{
assert(A);
if (!A->size)
{
printf("该顺序表当前为空,请输入值后再进行删除\n");
}
else
{
for (size_t i = 0; i < A->size-1; i++)
{
A->arry[i] = A->arry[i + 1];
}
A->size--;
printf("头部删除执行成功\n");
}
}
void SeqListDeleteBack(SeqList* A)
{
assert(A);
if (!A->size)
{
printf("该顺序表当前为空,请输入值后再进行删除\n");
}
else
{
A->size--;
printf("尾部删成功\n");
}
}
void SeqListPointPositionDelete(SeqList* A,SLdataType data)
{
assert(A);
if (!A->size)
{
printf("该顺序表当前为空,请输入值后再进行删除\n");
return;
}
else
{
int Position = SeqListElementFind(*A, data);
if (Position == -1)
{
//printf("很抱歉,为找到您要删除的值,请重新输入\n");
//原本想进行补充说明,结果与SeqListElementFind函数中的说明重复了
return;
}
else
{
for (size_t i = Position; i < A->size - 1; i++)
{
A->arry[i] = A->arry[i + 1];
}
A->size--;
printf("%d删除成功\n", data);
}
}
}
void SeqListdestory(SeqList* A)
{
assert(A);
free(A->arry);
A->capacity = 0;
A->size = 0;
}
cpp
//SeqList.c
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include"SeqList.h"
int main()
{
//SeqList A;
//SeqListInit(&A);
//printf("结构体A的地址:%p\n", &A);
//printf("内部数组首地址:%p\n", A.arry); // 强烈建议加这行,验证初始化是否成功
//printf("size = %zu\n", A.size);
//printf("capacity = %zu\n", A.capacity);
//SeqListFrontIsert(&A, 5);
//SeqListFrontIsert(&A, 4);
//SeqListFrontIsert(&A, 3);
//SeqListFrontIsert(&A, 2);
//SeqListFrontIsert(&A, 1);
//SeqListBackInsert(&A, 6);
//SeqListBackInsert(&A, 7);
//SeqListBackInsert(&A, 8);
//SeqListBackInsert(&A, 9);
//SeqListBackInsert(&A, 10);
////SLdataType Position = SeqListElementFind(A, 6);
//A.arry[Position] = 11;
//SeqListPrint(A);
//printf("size = %zu\n", A.size);
//printf("capacity = %zu\n", A.capacity);
//SeqListdestory(&A);
//SeqListPrint(A);
//printf("size = %zu\n", A.size);
//printf("capacity = %zu\n", A.capacity);
//SeqListDeleteFront(&A);
//SeqListDeleteFront(&A);
//SeqListDeleteBack(&A);
//SeqListPrint(A);
//printf("size = %zu\n", A.size);
//printf("capacity = %zu\n", A.capacity);
//SeqListPointPositionDelete(&A, 10);
//SeqListPrint(A);
//printf("size = %zu\n", A.size);
//printf("capacity = %zu\n", A.capacity);
//SeqListPointPositionDelete(&A, 1);
//SeqListPrint(A);
//printf("size = %zu\n", A.size);
//printf("capacity = %zu\n", A.capacity);
//SeqListPointPositionDelete(&A, 7);
//SeqListPrint(A);
//printf("size = %zu\n", A.size);
//printf("capacity = %zu\n", A.capacity);
//int* p = NULL;
//printf("空指针的值:%p\n", p); // 通常输出 0x0 或 (nil)
//printf("P的地址:%p\n", &p);
return 0;
}