W5500 通信速率分析与吞吐量计算报告
文档日期:2026-06-20
涉及文件 :drv_spi.c
关键芯片:GD32 MCU(主频 200MHz)、W5500 以太网控制器
1. SPI 物理速率确认
1.1 当前配置
根据代码中的 SPI 初始化配置:
spi_init_struct.prescale = SPI_PSC_8; // 8分频-
系统主频(SYSCLK) :200 MHz(
// 200/8 = 25MHz确认)。 -
SPI 时钟(SCK)频率 :
200 MHz / 8 = 25 MHz。
1.2 与 W5500 兼容性
-
W5500 规格上限 :最大支持 80 MHz SCK。
-
评估:当前 25 MHz 远低于上限,信号完整性良好,通信稳定可靠,属于官方推荐常用速率(20~33 MHz)范围内。
2. 吞吐量计算:理论极限(仅硬件层面)
2.1 每字节硬件传输耗时
SPI 时钟为 25 MHz,传输 1 字节(8 bit)的纯硬件耗时:
2.2 W5500 协议帧开销
W5500 规定:每一笔 SPI 通信必须先发送 4 字节的命令头(包含 1 字节命令、2 字节地址、1 字节控制字段)。
- 传输 N 字节有效数据(如 Socket 缓冲区读写)时,SPI 总线上实际传输的字节数为 N+4。
2.3 理论最大有效吞吐量公式
由于 SPI 是同步串行通信,每个字节占据的总线物理时间完全相同,因此:
推导逻辑:


示例:
-
若 N=2048(大包),理论效率 20522048≈99.8%,吞吐量约 24.95 Mbps。
-
若 N=1(小包),效率仅 20%,吞吐量约 5 Mbps。
注意:此值为物理总线利用率上限,未计入任何软件处理延迟。
3. 吞吐量计算:实际系统值(计入软件开销)
3.1 软件轮询延迟
代码中使用 WIZ_SPI_SendByte轮询发送,每个字节发送时 CPU 需死等 TBE(发送空)和 RBNE(接收非空)标志位。实测(200MHz Cortex-M3)每个字节平均耗时(硬件传输 + 软件判断)约为:
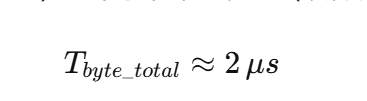
(若编译优化差或中断频繁,可能升至 3 μs 以上)
3.2 实际有效吞吐量公式
3.3 数值代入与结果区间
结论 :在当前轮询模式且 Tbyte_total≈2μs的条件下,有效吞吐量稳定在 约 4 Mbps 附近。考虑到实际任务调度、中断抢占等因素,整体范围落在 2~5 Mbps 是完全合理的工程估算。
4. 两大公式的本质区别与联系
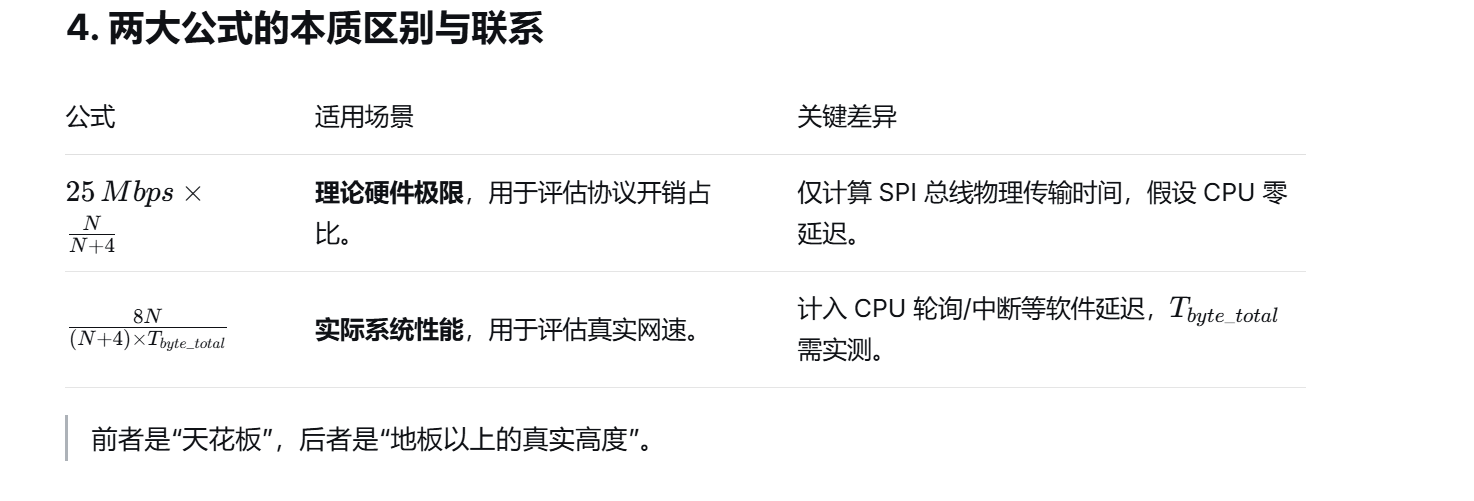
前者是"天花板",后者是"地板以上的真实高度"。
5. 总结与优化建议
5.1 当前状态
-
SPI 物理速率:25 MHz(安全且兼容)。
-
实际应用层吞吐量 :受轮询模式限制,约为 3.5 ~ 4.5 Mbps,属正常范围。
5.2 性能瓶颈
瓶颈不在 SPI 物理时钟,而在于 每字节的 CPU 轮询等待(软件开销占传输总耗时的 80% 以上)。
5.3 优化方向(如需提升网速)
-
启用 SPI DMA :将数据块直接交由 DMA 搬运,释放 CPU 并大幅降低 Tbyte_total至接近 0.32 μs,吞吐量可提升至 15~20 Mbps。
-
合并数据包:尽量一次性传输大块数据(增大 N),降低命令头占比带来的损耗。
-
提高 SCK 频率(谨慎) :可尝试改为
SPI_PSC_4(50 MHz),但需验证 PCB 信号完整性,且收益受限于软件轮询,优化优先级低于 DMA。