我们团队最近在折腾内部数据查询自动化,结果发现,就算用上最新的大模型,面对真实的业务数据问题,回答准确率也惨不忍睹。直到我们深入研究了 Anthropic 公开的内部实践,才意识到:问题根本不在模型能力,而在工程架构。 他们做到了 95% 以上的内部查询准确率,而关键就在一套叫做"技能"的系统上。
不靠模型硬扛,靠工程架构
Anthropic 的内部数据栈面对的挑战和我们一样:数据表上千张,业务概念模糊,定义经常变。一个简单的"Q3 的 MAU 是多少?"就可能把模型绕晕------MAU 到底用哪个表?怎么算?要不要去重?如果模型自己瞎猜,错误率极高。
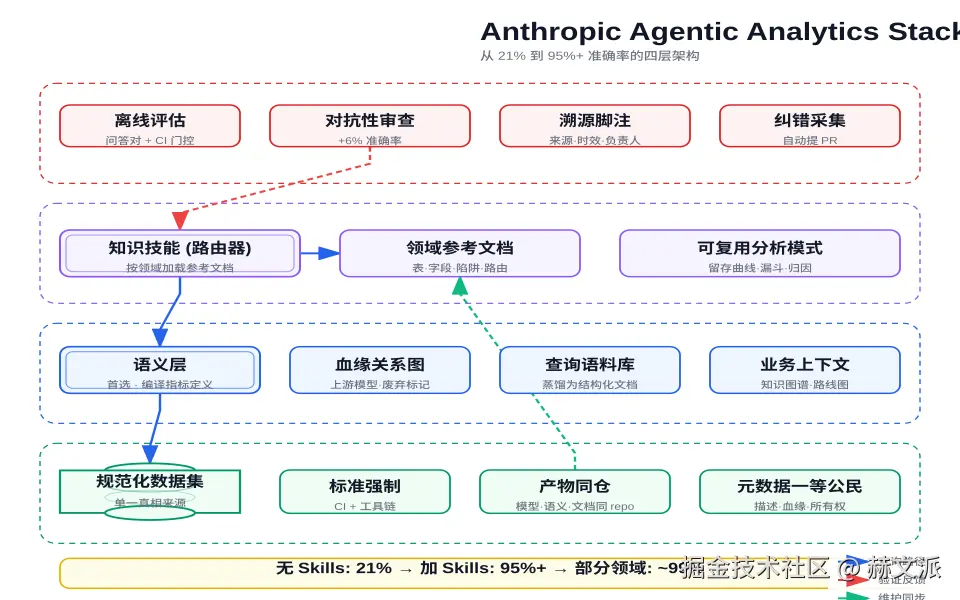
他们的解决方案不是换一个更聪明的模型,而是构建了一个四层架构,把模型严格框定在正确的轨道上运行。
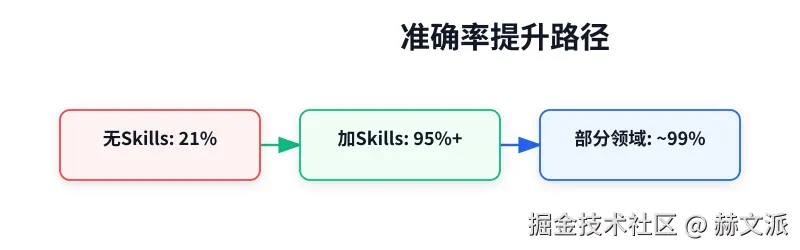
这个架构里,最值钱的是第三层------技能。没有技能,Claude 只能答对 21% 的数据分析问题;加上技能后,准确率飙升到 95% 以上。 这不是模型的进步,是给模型装上了"导航仪"。
技能系统:如何把经验"教"给 AI
技能的本质,是把人类专家处理数据问题的过程,编码成机器可读的文档。它不是简单的 FAQ,而是一套完整的决策流程和参考信息。
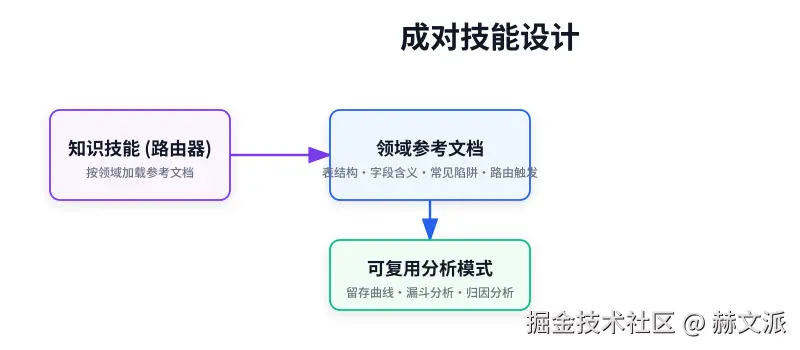
成对设计是精髓:一个"知识技能"文件作为路由器,里面列出所有可能的业务领域(如用户、营收、增长)和对应的判断规则。当问题进来时,Claude 先看这个文件,判断该用哪个领域的参考文档。
以"用户"领域为例,参考文档(比如 domain_users.md)里会明确写好:
- 核心概念定义:什么是"核心用户"?(日活≥5天/月)
- 关键表和字段 :数据在
analytics.dau表,字段user_id,active_days。 - 标准计算逻辑:计算留存率必须用的 SQL 模板。
- 常见坑点 :注意时区、注意
active_days字段的刷新延迟。
markdown
# 文件: skills/knowledge_routing.md
## 路由规则
1. 问题涉及 **用户数量、活跃、留存、流失** -> 跳转 `users_skill`
2. 问题涉及 **收入、订阅、付费、ARPU** -> 跳转 `revenue_skill`
3. 问题涉及 **实验、A/B 测试、显著性** -> 跳转 `experiments_skill`
4. 其他 -> 要求澄清
# 文件: skills/users_skill.md
## 核心定义
- **核心用户 (Core User)**:自然月内活跃天数 ≥ 5 天的独立用户。
- **留存率 (Retention)**:指定时间窗后仍活跃的用户比例。
- **数据表**:`analytics.monthly_user_activity`
- **关键字段**:
- `user_id`: 用户唯一标识
- `month`: 月份 (YYYY-MM-01 格式)
- `active_days`: 月内活跃天数
- `is_core`: 是否核心用户(由 `active_days >= 5` 计算得出)查询模板
计算月留存率:
sql
WITH core_users AS (
SELECT user_id
FROM analytics.monthly_user_activity
WHERE month = '2026-04' AND is_core = true
),
next_month_active AS (
SELECT DISTINCT user_id
FROM analytics.daily_user_activity
WHERE activity_date BETWEEN '2026-05-01' AND '2026-05-31'
)
SELECT
COUNT(DISTINCT cu.user_id) AS core_user_count,
COUNT(DISTINCT nma.user_id) AS retained_count,
(COUNT(DISTINCT nma.user_id) * 100.0 / COUNT(DISTINCT cu.user_id)) AS retention_rate
FROM core_users cu
LEFT JOIN next_month_active nma ON cu.user_id = nma.user_id;维护是关键 。Anthropic 发现,如果不持续维护技能,准确率会在一个月内从 95% 跌到 65%。因此,他们把技能维护嵌入到了日常开发流程:大约 90% 的数据模型 PR 都会同步包含一个技能文件的变更。 改了字段名或逻辑,必须更新对应的技能文档,PR 才会被合并。
对抗性审查:用子代理"找茬"
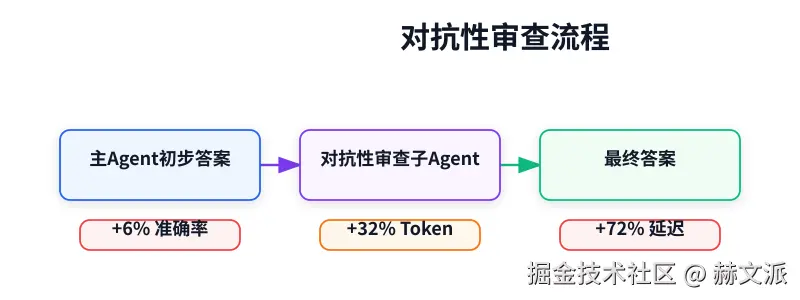
即使有了技能,模型有时还是会"走神",生成看起来合理但实际错误的答案。为此,Anthropic 引入了对抗性审查子代理。
这个子代理的工作不是帮忙,而是专门"找茬"。它会拿到主代理生成的初步答案,然后以最挑剔的姿态,去质疑每一个假设:
- "你用的表确定是最新的吗?"
- "这个计算逻辑和
users_skill.md里的模板一致吗?" - "这个数字上周还是 72%,现在突然变 65%,你确定查对了?"
python
# 对抗性审查子代理的简化逻辑示意
def adversarial_review(preliminary_answer, query, relevant_skills):
"""
子代理的任务:尽全力推翻主代理的答案。
"""
challenges = []
# 1. 检查来源一致性
if preliminary_answer.source_tier == "raw_table":
challenges.append("为什么没有使用语义层?这违反了架构优先级。")
# 2. 逻辑挑战
sql_in_answer = extract_sql(preliminary_answer)
skill_template = get_sql_template(relevant_skills)
if not logic_equivalent(sql_in_answer, skill_template):
challenges.append("生成的SQL与技能模板中的逻辑不一致,请核实。")
# 3. 数据合理性检查
historical_data = query_historical_metrics(query.metric)
if is_anomaly(preliminary_answer.value, historical_data):
challenges.append(f"数值 {preliminary_answer.value} 与历史趋势 {historical_data} 差异显著,需要人工复核。")
return challenges这个审查代价不小:Token 消耗增加 32%,延迟增加 72% ,但换来了准确率额外 6% 的提升。在精度要求极高的业务场景下,这个权衡是划算的。他们也试过把审查子代理换成更便宜的模型,结果发现丢失了大部分准确率收益,速度提升却很小,得不偿失。
四大踩坑:他们试过但行不通的方法
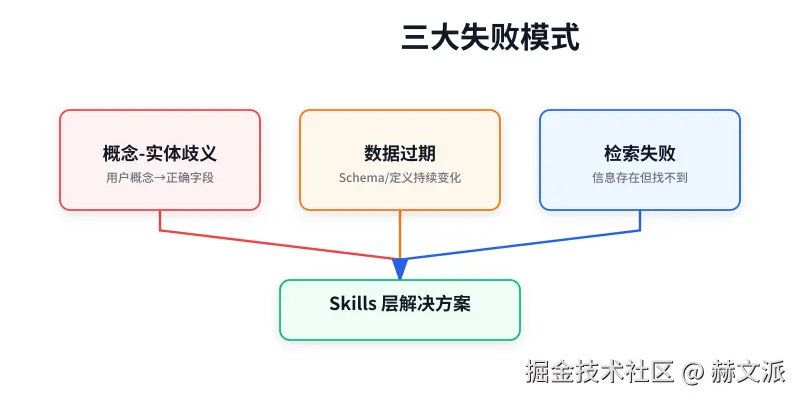
Anthropic 在构建这套系统时,也走了不少弯路。这些失败的实验对我们特别有参考价值:
- 试图让 LLM 自动生成语义层 :想让大模型看几张原始表,自动生成标准的指标和维度定义。结果对评估分数产生了净负影响。机器无法理解业务上下文,生成的定义可能统计正确但业务意义全错。人的审核和沉淀不可替代。
- 文档优化超过3轮迭代 :想用 LLM 不断润色技能文档,使其更清晰。但发现连续超过3轮迭代后,评估分数开始下降。模型会把文档"优化"得脱离原始意图,过度简化或改变关键细节。
- 直接用原始SQL检索作为参考 :曾尝试把数千个历史SQL查询文件直接塞给模型当参考。结果发现,准确率变动不到1个百分点。信息就在那儿,模型也看到了,但它不会用,无法从海量原始代码中提取出稳定可靠的过程。
- 静默失败是最难缠的敌人 :一个错误答案如果看起来合理,就很难被发现。因此,他们强制要求每个回答都带溯源页脚,标注信息来自语义层(最可信)、还是参考文档、还是原始表,以及数据的最后更新时间。
这套方法论,你能怎么用?
Anthropic 的案例揭示了一个核心真相:在企业级AI应用中,将工作流程编码成"技能",其重要性远高于模型本身的智能水平。
如果你正试图在团队内部用AI解决数据查询问题,可以按这个路径入手:
- 先不急着上模型,把团队最常问的Top 20个数据问题,及其标准答案和查询过程,整理成几份清晰的Markdown文档。这就是你的初始"技能"。
- 严格定义数据源优先级,强制AI必须先查你整理好的文档(类似语义层),找不到再去原始表里碰运气。
- 建立反馈闭环,当AI答错时,不仅要修正答案,更要追问:是技能文档没写清楚?还是有新的业务逻辑没更新进去?把每一次纠错都变成一次技能维护的机会。
与其不断追新换更贵的模型,不如花时间把团队的数据知识沉淀下来,变成机器能读、能执行的工程资产。这才是让AI在企业内部真正"可用"而非仅仅"好玩"的关键。真正的智能化,不是让AI自己变得聪明,而是把我们的智慧和经验,系统化地注入到它运行的框架里。从一份Markdown技能文档开始,你的团队也能走出这条路。