扩散政策:通过行动扩散学习的身体运动政策
"扩散策略学习动作-分布得分函数的梯度,并通过一系列随机朗之万动力学 步骤,在推断过程中对该梯度场进行迭代优化。"
解读:朗之万动力学:
假设我们想从某个分布 p(x) 里采样,但没法直接采样。朗之万动力学会用下面的迭代:
xk+1 = xk + η/2 * ∇x log p(xk) + sqrt(η) z
z ~ N(0,I)
这一步有两个部分:
η/2 * ∇x log **p(xk)**是确定性方向,叫 drift。它把样本往高概率区域推。
sqrt(η) z是随机噪声,叫 diffusion。它让采样过程保持随机性,不会只滑到一个固定模式。
这里的:
∇x log **p(x)**叫 score,也就是 log density 对输入的梯度。直观说,它告诉你: 当前 x 应该往哪个方向移动,才更像来自真实数据分布的样本。
"为了充分释放扩散模型在物理机器人视觉运动政策学习中的潜力,本文提出了一系列关键技术贡献,包括引入后退视界控制 、视觉条件反射 以及时间序列扩散变换器。"
后退视界控制 :即"闭环动作序列预测:有效的行动表述应促进长期规划的时间一致性和顺畅性,同时允许对意外观察及时反应。为实现这一目标,我们承诺采用扩散模型在固定时间内产生的动作序列预测,然后再进行重新规划。具体来说,在时间步骤t,策略将最新的观察数据Ot步骤作为输入,并预测Tp步骤的动作,其中Ta步骤在机器人上执行,无需重新规划。这里,我们定义 To 为观测视界,Tp 为动作预测视野,Ta 为动作执行视野。这鼓励了时间动作的一致性,同时保持响应性。关于Ta的影响,更多细节见第4.3节。我们的表述还允许后退视界控制,Mayne和Michalska(1988)通过预热启动下一次推断设置,结合先前的动作序列预测,进一步提升动作平滑性。
"**• 闭环动作场面。**我们将策略预测高维动作序列的能力与远视界控制相结合,实现稳健执行。这种设计使政策能够以闭环方式持续重新规划行动,同时保持时间上的行动一致性,实现长远规划与响应性之间的平衡。
**• 视觉条件反射。**我们引入了视觉条件扩散策略,将视觉观察视为条件反射,而非联合数据分布的一部分。在这种表述中,策略无论去噪迭代如何,都会提取一次视觉表示,这大大减少了计算量,并实现了实时动作推断。
**• 时间序列扩散变压器。**我们提出了一种基于变压器的新型扩散网络,可最大限度减少典型CNN模型的过度平滑效应,并在需要高频动作变化和速度控制的任务中实现最先进的性能。"
论文引言提到了"• 稳定的训练。基于能量的训练策略通常需要负抽样来估计一个难以处理的 归一化 常数,这已知会导致训练不稳定(Du 等人(2020);Florence 等(2021)。"
连起来就看不懂了。其实"4.4 Training Stability"这一节就是在解释这句话。 解读:
- 什么是 energy-based policy
普通显式策略一般是:
a = fθ(o)
也就是输入观察 o,直接输出动作 a。
energy-based policy 不是直接输出动作,而是学习一个能量函数:
Eθ(o, a)
它输入:
o: observation,机器人看到的图像/状态
a: action,候选动作
输出一个标量 energy:
Eθ(o,a) 越低,表示这个动作越合理
Eθ(o,a) 越高,表示这个动作越不合理
推理时,策略要找低能量动作:
â = argmin_a Eθ(o,a)
Diffusion Policy 论文的相关工作部分也这样描述 implicit policy:每个 action 被赋予一个 energy value,动作预测就是找 minimal energy action;多个动作都可以低能量,所以它天然能表达多模态动作分布。
- 什么是 归一化 常数 Z
如果我们想把 energy 变成概率分布,通常写成:
πθ(a | o) = exp(-Eθ(o,a)) / Zθ(o)
其中:
Zθ(o) = ∫ exp(-Eθ(o,a')) da'
如果动作是离散的,就是:
Zθ(o) = Σ_a' exp(-Eθ(o,a'))
这个 Zθ(o) 就是 normalization constant,也叫 partition function。
它的作用是让概率加起来/积分起来等于 1:
∫ πθ(a | o) da = 1
没有 Z,exp(-Eθ(o,a)) 只是一个"未归一化分数",不能直接当概率。
- 为什么 Z 难以处理
因为 Zθ(o) 要对所有可能动作积分:
Zθ(o) = ∫ exp(-Eθ(o,a')) da'
机器人动作通常是连续的、高维的。比如一个 action sequence 可能包含未来多步动作:
a = a_t, a_{t+1}, ..., a_{t+H}
如果每步动作是 7 维,预测 16 步,那动作空间就是 112 维。你不可能枚举所有 a'。
而且 Eθ(o,a) 是神经网络,不是简单高斯分布,通常没有解析积分公式。所以 Zθ(o) 算不出来。Du et al. 对 EBM 的介绍里也写到,EBM 的概率形式是 exp(-Eθ(x))/Z(θ),但最大似然训练不直接可行,因为 Z(θ) 涉及整个输入空间上的积分。
- 为什么训练时会需要 negative sampling
假设专家示范里有一个正例:
πθ(a+ | o) 尽量大
负对数似然是:
−log πθ(a+ | o)
= Eθ(o,a+) + log Zθ(o)
这里有两件事:
Eθ(o,a+)
要求模型把专家动作能量压低。
log Zθ(o)
要求模型不要把所有动作的能量都压低。否则每个动作都高概率,分布就没意义。
问题是 Zθ(o) 算不出来,所以常见做法是采一些负例动作:
a1-, a2-, ..., aN-
然后用这些负例近似 denominator:
π̃θ(a+ | o) = exp(-Eθ(o,a+)) / exp(-Eθ(o,a+)) + Σ_j exp(-Eθ(o,aj-))
这就是类似 InfoNCE / contrastive learning 的训练方式。
Florence et al. 的 Implicit Behavioral Cloning 里就明确写了:训练会为每个样本生成 negative counter-examples,并使用 InfoNCE-style loss;这个 loss 等价于 pθ(y|x)=exp(-Eθ(x,y))/Z(x,θ) 的负对数似然,counter-examples 用来估计 Z。
所以 "negative sampling to estimate an intractable normalization constant" 的意思就是:
因为没法对所有动作积分求 Z,
所以只采一批"不是专家动作"的候选动作,
用它们近似所有可能动作对归一化项的贡献。
- 什么是 negative sample
在机器人策略里:
positive sample = 数据集里的专家动作 a+
negative sample = 采出来的其他候选动作 a-
比如观察是一张机器人面对物体的图,专家动作是:
向左绕过去抓
负例可能是:
向右撞过去
原地不动
夹爪乱开合
移动到无关位置
训练目标希望:
Eθ(o, a+) 低
Eθ(o, a-) 高
也就是专家动作比负例动作更合理。
- 为什么这样会导致训练不稳定
主要原因是:训练质量高度依赖负样本质量,而负样本本身很难采好。
如果负样本太简单,例如随机采一些明显乱来的动作:
a- = 完全不可能的动作
模型很快就能分开:
专家动作低能量
垃圾动作高能量
loss 看起来下降了,但模型没有学会区分"专家动作"和"看起来也合理但稍微差一点的动作"。推理时还是可能选错。
如果负样本太难,又可能出现 false negative:
a- 其实也是一个合理动作
尤其在多模态任务里,当前状态下可能有两种都合理的动作:
从左边推
从右边推
数据集里这次记录的是"从左边推",但你采出来的负例可能是"从右边推"。如果把它当负例,模型就会错误地把一个合理模式能量抬高,破坏多模态分布。还有一个问题是高维动作空间里的采样很难。随机负样本大多落在无意义区域;用 MCMC / Langevin 采样又慢,而且容易混合不好。Du et al. 也指出,contrastive divergence 训练 EBM 有训练稳定性困难,并且常常需要 spectral normalization、gradient clipping、调参、early stopping 等技巧。更严重的是,Zθ(o) 是随参数 θ 变化的。模型一更新,整个能量地形都变了,负样本分布也应该变。如果采样器跟不上模型变化,梯度估计就是偏的、噪声大的。结果可能出现:
某些没采到的动作区域被模型意外赋予很低能量
推理时 argmin 找到这些错误低能量动作
训练 loss 不一定能及时惩罚它们
这就是 energy-based policy 常见的不稳定来源。
- Diffusion Policy 怎么绕开这个问题
Diffusion Policy 不直接训练:
πθ(a|o) = exp(-Eθ(o,a)) / Zθ(o)
也不需要对动作采负例来估计 Z。
它训练的是 denoising / score:
εθ(Ot, At^0 + εk, k)
loss 是简单 MSE:
L = MSE(εk, εθ(Ot, At^0 + εk, k))
论文 Sec. 2.3 给出的就是这个条件 diffusion policy 训练目标。
直观说:
Energy-based policy:
学一个能量面 E(o,a),需要比较正例和负例
Diffusion Policy:
给专家动作加噪,训练模型把噪声预测出来
所以它不需要问:
这个专家动作相对于所有其他动作的归一化概率是多少?
而是问:
这个加噪动作应该往哪个方向去噪,才能回到专家动作分布?
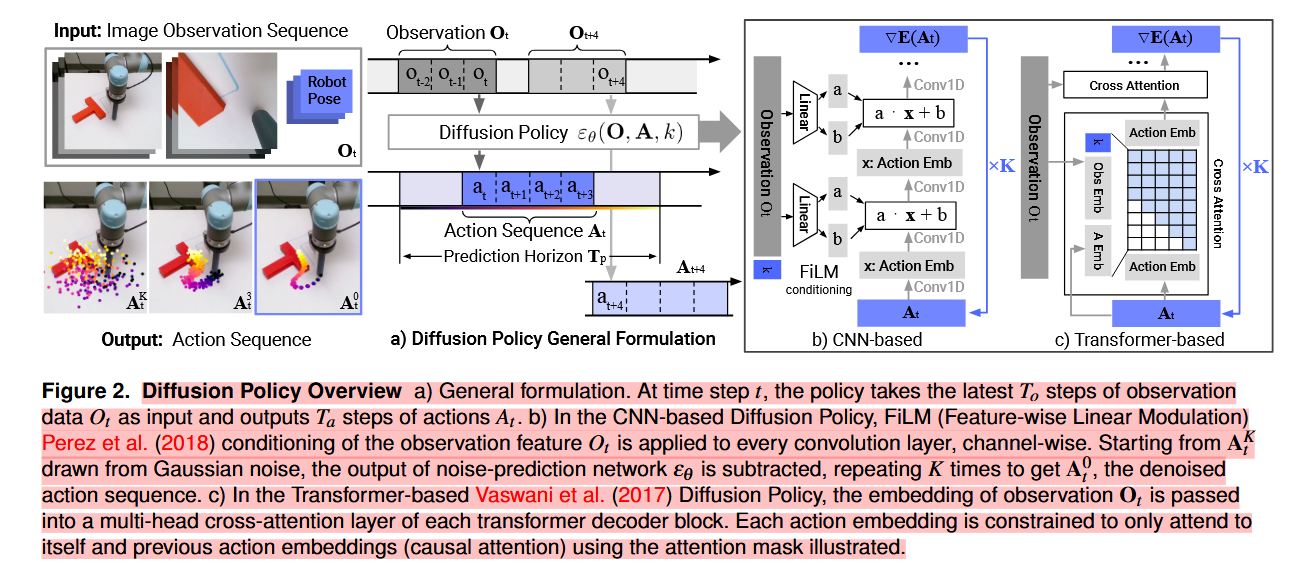
"图2。扩散政策概述 a)总体表述。在时间步t,策略以观察数据 Ot 的最新To步为输入,输出在T的行动 Ta 步 。b) 在基于CNN的扩散策略中,FiLM(特征方向线性调制)Perez等人(2018)对观测特征Ot的条件化 ,按通道对每个卷积层进行。从高斯噪声中得出的AtK出发,减去噪声预测网络εθ的输出,重复K次得到去噪作用序列At0。c) 基于Transformer的Vaswani等人(2017)《扩散策略》中,观测Ot的嵌入传递到每个变压器 解码器 块的多头交叉注意力层中。每个动作嵌入都被限制只关注自身和之前的动作嵌入(因果注意力),使用图示中的注意力掩码。"
本文对DDPM做了一些改动:

"视觉观察条件:我们使用DDPM来近似条件分布p(At |Ot )代替 Janner 等(2022a)用于规划的联合分布 p(At , Ot )。这种表述使模型能够基于观测预测作用,而无需推断未来状态,加快扩散过程并提高生成动作的准确性。捕捉条件分布 p(At |Ot ),我们将方程1修改为:"
引入Ot,变成条件DDPM。
"3.3 噪声调度
噪声调度由σ、α、γ和加法高斯噪声εk作为k的函数定义,目前已被积极研究。Ho等人(2020);尼科尔和达里瓦尔(2021)。底层噪声计划控制扩散策略捕捉动作信号高频和低频特性的程度。在对照任务中,我们实证发现iDDPM中提出的平方 余弦 计划(Square Cosine Schedule)最适合我们的需求。
3.4 加速推理以实现实时控制
我们以扩散过程作为机器人的策略;因此,拥有快速的推理速度对于闭环实时控制至关重要。去噪扩散隐式模型(DDIM) 方法由Song等人(2021)解耦训练和推断中的去噪迭代次数,从而使算法能够使用更少的推理迭代次数,从而加快过程。在我们的实际实验中,使用DDIM进行100次训练迭代和10次推理迭代,使Nvidia 3080 GPU的推理延迟降至0.1秒。"