Agent之Wiki:Karpathy-LLM-Wiki的简介、安装和使用方法、案例应用之详细攻略
目录
[1)Obsidian 插件安装](#1)Obsidian 插件安装)
[2)LLM 提供方配置](#2)LLM 提供方配置)
[3)GitHub 复现仓库的本地工作流](#3)GitHub 复现仓库的本地工作流)
[1)导入资料与执行 ingest](#1)导入资料与执行 ingest)
Karpathy-LLM-Wiki的 简介
Karpathy's LLM Wiki 可以理解为一种"LLM 驱动的个人知识库/第二大脑"模式:你把文章、笔记、PDF、会议记录、网页摘录等原始材料喂给系统,LLM 负责抽取实体、概念、关系,并把它们组织成可查询、可链接、会持续演化的 Wiki。Obsidian 插件页直接把它定义为"AI-powered structured knowledge base",而 GitHub 仓库则说明它是"self-maintaining personal knowledge base powered by LLMs"。
这个模式之所以引起关注,是因为它抓住了一个很朴素的问题:知识不是缺少存储,而是缺少结构化组织与持续维护。Karpathy 的原始思路在社区插件页里被概括为:把你的笔记当作原材料,让 LLM 负责架构工作,自动提取实体和概念,织成带双向链接、自动索引和聊天界面的结构化 Wiki。
整体上,这套方法的核心不是"再做一个 RAG",而是把原始资料持续编译成一个会自己生长的、可互联的知识维基。Karpathy 在帖里说,他最近很有用的做法是:用 LLM 为研究兴趣建立个人知识库,把更多 token 花在"知识"而不是"代码"上;社区实现仓库则把它描述为"先读一遍来源,再构建一个持久的、互相链接的 wiki",并且明确表示它不是每次都去重新搜索原始文档。
社交媒体平台地址 :https://x.com/karpathy/status/2039805659525644595
视频讲解地址 :https://www.youtube.com/watch?v=iXd0t60YmMw
obsidian实现的插件地址 :Karpathy LLM Wiki - Obsidian Plugin
网友复现的Github地址 :GitHub - balukosuri/llm-wiki-karpathy · GitHub
1、核心思想及其实现步骤
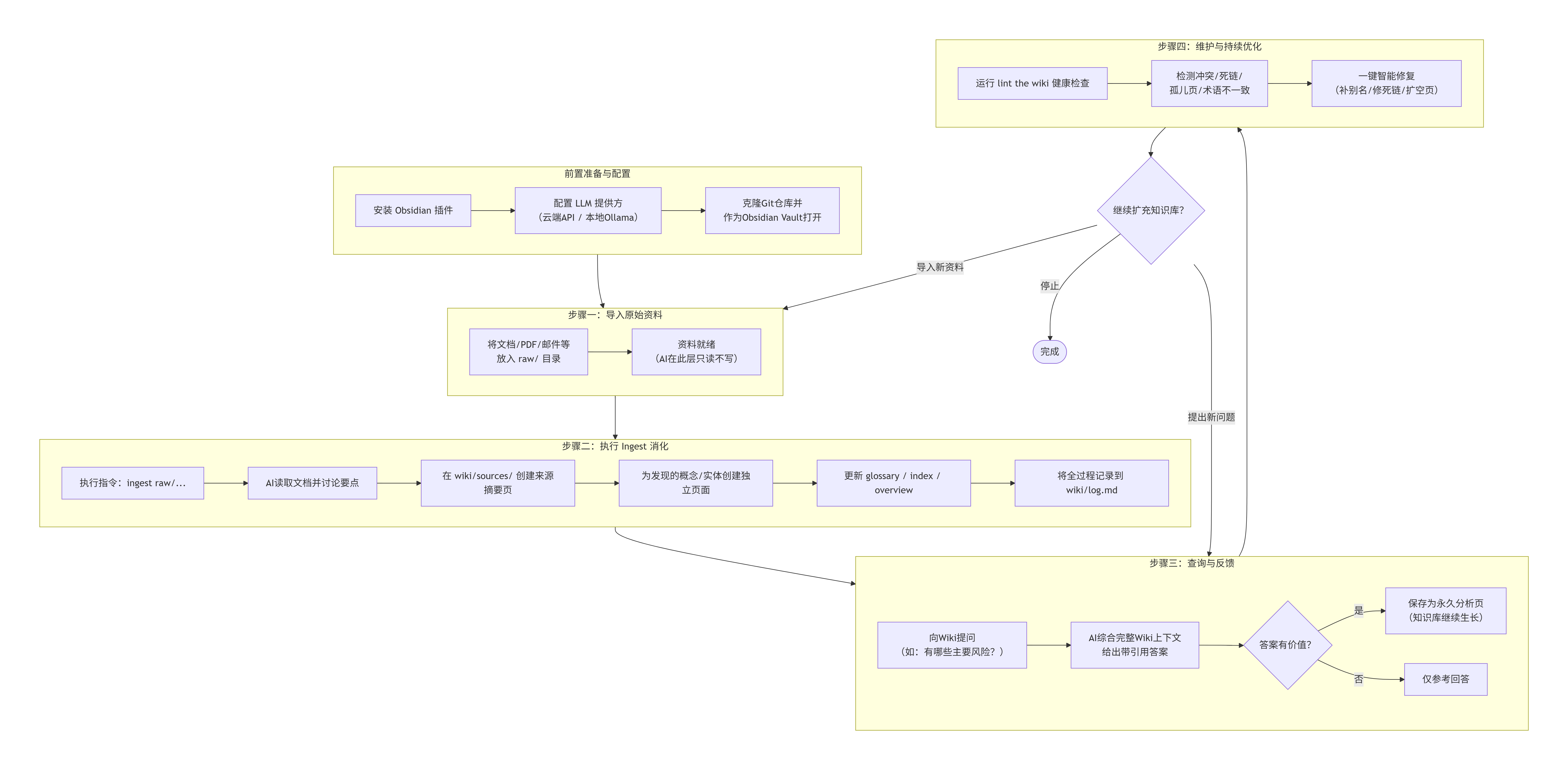
这个方案的核心思想是:给 LLM 整个 Wiki 上下文,而不是切碎后的片段检索。Obsidian 插件页的 Model Selection Guide 明确写到,它遵循 Karpathy 的哲学:把完整 Wiki 上下文喂给 LLM,不做 chunked RAG retrieval;页面还直接解释了为什么不推荐 RAG------因为 RAG 会把知识碎片化,削弱 LLM 在完整知识图谱上跨页推理的能力。
第一步是准备原始来源,把资料放到 raw/ 里;仓库把 raw/ 明确标成"AI reads, never writes"的只读层,而 wiki/ 则是 AI 生成并维护的知识层。仓库结构还把 CLAUDE.md 定义为 schema 和操作手册,wiki/index.md 作为主目录,wiki/overview.md 作为大局摘要,wiki/glossary.md 作为术语和风格规范,wiki/log.md 记录所有活动。
第二步是 ingest,也就是让 LLM 读取一个来源文件并展开成维基页面。仓库的流程是:读文档、和你讨论要点、在 wiki/sources/ 里创建来源摘要页、为发现的产品/特性/人物/概念创建新页面、更新 glossary、更新 index、必要时更新 overview,并把全过程记录到 wiki/log.md。仓库还说,单个来源可能会影响 5 到 15 个 wiki 页面,且这些变化会在 Obsidian 里实时出现。
第三步是查询与反馈。你可以直接问 Wiki 问题,例如"我所有来源里有哪些主要风险",LLM 会综合 Wiki 给出带引用的答案,并询问你要不要把这个答案保存成永久分析页。这样,提问本身会反过来让知识库更丰富。
第四步是维护。仓库里专门提供了 lint the wiki 的健康检查,会找出页面冲突、过时说法、孤儿页、缺失链接、术语不一致等问题;Obsidian 插件页也把 Lint wiki 列为核心命令,并支持自动修复缺失别名、重复页、死链接、空页面等问题。
2、网友评价
看公开可见的"反馈信号",这个项目的社区接受度是比较高的。Obsidian 官方插件页给它的官方评分是 95/100,显示大约 6k downloads,并写明它支持 9 种语言、而且"actively maintained, continuously evolving"。
GitHub 复现仓库也能看到明显的社区热度:balukosuri/llm-wiki-karpathy 是公开仓库,页面显示有 181 stars 和 77 forks,说明已经有不少人把它当成可参考、可改造的实现。
从社区页面的文案风格也能看出整体评价倾向:Obsidian 插件页把它描述为"AI-powered structured knowledge base",并强调它能把笔记变成 connected wiki、支持实时浏览、可点击链接、私有本地运行,这些都在社区讨论里属于很强的正反馈点。
3、特点
|----------------------|--------------------------------------------------------------------------------------------|
| 核心机制:非传统 RAG | 并非每次都重新检索原始文档,而是先读取一次来源,生成持续累积的 interlinked wiki;插件页将"全 Wiki 上下文"列为首选策略。 |
| 强调知识结构而非单次问答 | 回答自动携带 \[wiki-links],答案成为通向知识图谱的新入口;每个答案都带回知识图谱的链路。 |
| 重视知识质量 | 提供实体/概念抽取、强制别名、重复检测与合并、智能知识融合、冲突保留并标注来源、原始引语保留、内容截断保护等功能,确保 Wiki 越用越干净、可信。 |
| 注重维护自动化 | 除 lint 外,还提供 一键智能修复(one-click smart fix)、别名补全、死链修复、孤儿页连接、空页扩展等维护动作,形成持续保养机制。 |
| 多语言与跨语言知识友好 | UI 原生支持 9 种语言,并有 269+ UI 字段完成本地化;知识层面支持通过 aliases、translations、abbreviations 进行跨语言重复检测和联接。 |
| 本地优先、隐私友好 | 无后端、无追踪、无数据收集,内容仅存于本地 vault;仅主动配置的 LLM API 会接触发送的文本。同时支持 Ollama、LM Studio 等本地模型。 |
Karpathy-LLM-Wiki的安装和使用方法
1、安装
1)Obsidian 插件安装
Obsidian 社区插件页给出的推荐方式很直接:在 Obsidian 里进入 Settings → Community plugins,点击 Browse 搜索 "Karpathy LLM Wiki",然后 Install 再 Enable;也可以直接在社区插件页面点击 Add to Obsidian 安装。
如果手动安装,插件页说明需要下载 main.js、manifest.json、styles.css 三个文件,把它们放进 Obsidian 插件目录下的 karpathywiki 文件夹里,再刷新并启用。页面还提供了开发安装方式:git clone、pnpm install、pnpm build。
2)LLM 提供方配置
安装后,需要到 Settings → Karpathy LLM Wiki 里选择模型提供方。插件页列出的选项包括 Anthropic、Google Gemini、OpenAI、DeepSeek、Kimi、GLM、MiniMax、LM Studio、Ollama、OpenRouter 以及自定义提供方;如果是 Ollama 这类本地方案,则不需要 API key。配置完成后可以点击 Fetch Models、Test Connection,再保存设置。
3)GitHub 复现仓库的本地工作流
GitHub 复现仓库的推荐流程是:先 git clone,然后用 Cursor 打开项目;如果你用的是别的 AI agent(比如 Claude Code、Codex),就把 CLAUDE.md 的内容放进它的上下文。接着在 Obsidian 里把同一个目录作为 vault 打开,这样你能在左边和 AI 对话,在右边实时看 wiki 页面生成。
2、使用方法
1)导入资料与执行 ingest
仓库建议把任何来源材料放进 raw/,包括产品规格、设计文档、PRD、会议纪要、网页文章、风格指南、PDF、报告、邮件线程、竞品资料等。随后在 Cursor 里输入类似 ingest raw/my-document.pdf 的指令,AI 会读取文件、讨论要点、创建来源页、生成实体/概念页、更新 glossary 和 index,并记录到 log。
2)查询与维护
资料导入后,可以直接问问题;如果答案有价值,还可以让 AI 把它存成新的分析页。每隔十次左右 ingest 一次,仓库建议跑 lint the wiki 做健康检查,自动找出冲突、死链、空页、孤儿页和术语不一致等问题。
3)辅助学习资源
YouTube 视频标题就是 "Karpathy's LLM Wiki - Full Beginner Setup Guide",说明社区已经把这套方法整理成了面向新手的完整配置教程,适合作为上手补充。
Karpathy-LLM-Wiki的案例应用
处理一个来源、多个概念"的知识场景
最清晰的示例来自 Obsidian 插件页的 Example 部分:当输入 sources/machine-learning.md,里面只有机器学习的简要说明和三类方法(Supervised、Unsupervised、Reinforcement),系统会自动生成一个概念页 wiki/concepts/supervised-learning.md,并在 frontmatter 中写入 type: concept、sources: "\[\[sources/machine-learning]"]、aliases: "监督学习", "Supervised Learning" 等元数据。
这个例子说明它特别适合处理"一个来源、多个概念"的知识场景:一份资料不只是被摘要,还会被拆成实体页、概念页、来源页,并带着 related concepts、related entities、source mentions 继续向外扩展。
从输入类型看,仓库适合的真实场景非常广:产品规格、会议纪要、网页文章、风格指南、PDF 报告、邮件线程、竞品文档都可以作为原始素材进入 raw/。这意味着它很适合做研究笔记库、项目知识库、竞品分析库、产品资料库,或者个人"研究兴趣第二大脑"。
问答型研究助手
仓库示例里就直接用"我所有来源里有哪些主要风险"这样的提问方式,并让 LLM 输出带引用的答案;这说明它可以用在风险总结、主题归纳、跨文档对比、观点冲突分析等场景。