第 1 章 解密线上数据库高频故障
在日常业务开发中,绝大多数开发者仅停留在掌握 SQL 基础语法的层面,能够完成功能开发,却难以应对生产环境高并发下的各类诡异数据库故障。本章从真实线上故障场景入手,对比测试与生产环境的核心差异,厘清普通开发者与资深数据库工程师的认知差距,统一全书业务案例模型与学习范式,逐层梳理 MySQL 整体架构和 InnoDB 内核核心能力,为后续深入拆解事务、锁、MVCC、日志、索引等底层原理,搭建完整的全局知识框架。
1.1 场景复盘:测试环境正常,生产一并发就崩的诡异现象
绝大多数开发者学习 MySQL,都会陷入一个认知悖论:SQL 语法完全掌握、单条语句执行正常、本地测试毫无问题,一旦上线遭遇真实业务并发,立刻爆出各类诡异故障。
你在项目里一定遇过这些难以复现、无从下手的线上问题:明明只是更新单行库存,却意外锁住整表,导致大量下单接口排队超时;明明用主键精准更新,依旧触发间隙锁、随机死锁;低峰期业务平稳,一到活动秒杀就出现库存超卖、订单重复;数据库没有慢 SQL、索引看着正常,性能却随机间歇性卡顿;同一时刻查询库存,前后结果忽新忽旧,对账始终对不齐。
这类故障最大特点:测试几乎永远复现不了。测试环境并发低、事务执行快、连接少,InnoDB 的锁竞争、MVCC 版本可见性、脏页刷盘、缓存淘汰这些底层机制根本触发不到;但到了生产高并发、海量读写、长事务堆积的场景,所有隐藏在内核里的隐患会全部暴露出来。
很多人遇到问题只会简单归罪于并发太高、服务器配置不够、数据库不稳定,一味升级硬件、扩容节点,却始终治标不治本。真正的根源很简单:只会表层 SQL 语法,完全不懂一条 SQL 在 InnoDB 内核的完整执行链路,不理解事务、锁、MVCC、日志、缓存之间的协作规则。
语法正确 ≠ 内核安全;
测试正常 ≠ 生产稳妥。
这也是普通开发和资深数据库工程师最核心的差距。
1.1.1 真实生产案例一:并发扣库存引发超卖,测试完全正常
电商秒杀场景非常典型,商品库存只有 100 件,测试环境少量并发压测完全正常,一旦上线活动瞬间涌入几百并发请求,直接出现库存负数、超卖下单,业务对账严重出错。
出错的业务写法非常普遍:先查库存、再判断、最后单独更新库存,两条 SQL 不在同一事务做原子控制。
首先查询商品当前库存:
sql
SELECT stock FROM goods WHERE id = 1001;判断库存充足后,执行库存扣减:
sql
UPDATE goods SET stock = stock - 1 WHERE id = 1001;测试环境并发量小,请求串行执行,前后两条 SQL 间隔极短,不会出现重叠;但生产高并发下,大量线程同时执行第一条 SELECT,同时读到库存为 100,全部判定可以下单,再同时执行 UPDATE 扣减,最终库存被扣成负数,形成严重超卖。这类问题测试永远复现不了,只有生产高并发、热点行争抢时才会彻底暴露。
1.1.2 真实生产案例二:下单与更新库存交叉逻辑,线上随机死锁
很多业务下单流程里,既要更新商品库存,又要插入订单记录,事务中两张表操作顺序不统一,测试环境没事,生产频繁爆出死锁:
sql
Deadlock found when trying to get lock; try restarting transaction截取一段线上真实 MySQL 死锁日志:
sql
LATEST DETECTED DEADLOCK
------------------------
2026-05-23 14:22:15 0x7f2b18162700
*** (1) TRANSACTION:
TRANSACTION 324567, ACTIVE 0 sec starting index read
mysql tables in use 2, locked 2
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s)
UPDATE goods SET stock=stock-1 WHERE id=1001
*** (2) TRANSACTION:
TRANSACTION 324568, ACTIVE 0 sec starting index read
mysql tables in use 2, locked 2
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s)
INSERT INTO order_info(order_no,goods_id,user_id)
VALUES('20260523142215001',1001,100088)
*** WE ROLL BACK TRANSACTION (2)本质原因是两个事务锁住资源顺序相反,互相持有对方需要的行锁,形成循环等待。测试环境事务执行极快、并发低,死锁概率几乎为零;生产高并发、事务执行链路变长,死锁直接变成常态故障。
1.1.3 测试环境正常、生产必出问题的底层根源
结合以上测试与生产环境的差异对比,我们可以提炼出导致这类问题的核心底层逻辑:
1. 并发量级不同
测试低并发、请求串行化,几乎没有锁竞争;生产高并发、热点行争抢严重,行锁、间隙锁冲突被无限放大。
2.事务长短不同
测试业务逻辑简单、事务毫秒级快速提交,锁持有时间极短;生产接口链路复杂、嵌套远程调用、业务逻辑繁重,容易形成长事务,锁持有时间大幅拉长,阻塞和超时概率暴增。
3. InnoDB 底层机制触发程度不同
测试环境数据量小、访问量低,BufferPool 缓存命中率极高,几乎无脏页、无频繁刷盘,MVCC 版本链很短;
生产环境海量数据、高频读写,脏页不断产生、后台频繁刷盘,BufferPool 冷热数据频繁置换,长事务又会导致 Undo 版本链持续膨胀,缓存、MVCC、脏页淘汰、日志落盘全部被高强度触发。
4. 资源负载完全不在一个量级
测试数据库连接数空闲、磁盘 IO 压力极小;生产连接打满、IO 负载高、SQL 执行变慢,进一步拉长事务和锁占用时间,形成恶性循环。
不少开发者习惯聚焦业务代码与 SQL 语法,容易忽略 InnoDB 底层运行机制,这就是测试好好的,一上线就各种诡异故障的根本原因。
图 1-1 直观对比了测试与生产环境中 MySQL 的表现差异:
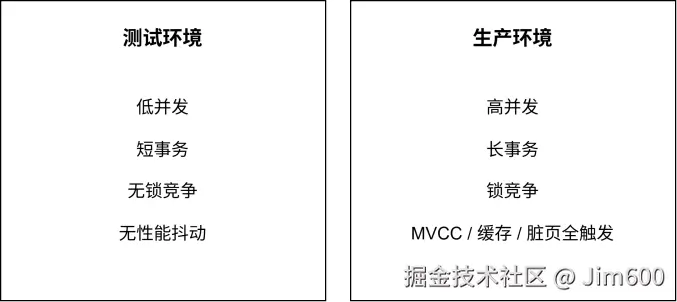
图 1-1 测试环境与生产环境 MySQL 表现差异对比
1.2 普通开发者与高级 DBA 的核心差距:不在语法,在执行链路认知
市面上多数 MySQL 入门教程与技术书籍,教学逻辑都高度同质化:从基础语法入手,讲解增删改查、联表查询、聚合函数、索引基础用法,最后简单提及事务和隔离级别。这类内容可以帮你完成基础业务开发,却完全无法应对线上高并发场景。
生产环境真正致命的故障,几乎没有语法错误,全部是内核机制引发的隐性风险:
多数开发者往往只关注 SQL 字面语法与执行结果;而资深开发与 DBA 更关注整条 SQL 的内核执行链路,能够预判加锁行为、数据可见性与并发风险。
简单来说,普通开发者靠经验写 SQL,高级工程师靠内核认知写 SQL。本书的核心目的,就是帮你补齐这套内核认知,让你从只会写语法正确的 SQL,进阶为能写出线上安全、高并发、高性能的 SQL。
1.3 MySQL 整体架构
本书摒弃传统书籍零散堆砌知识点的模式,全书唯一主线:一套真实电商下单业务。所有内核原理、故障场景、性能调优、落地规范,全部围绕这条业务链路展开,逆向拆解、闭环讲解,彻底避免知识点碎片化、案例割裂的问题。
电商下单是互联网最典型的交易场景,天然包含查询、更新、插入、分页查询四类高频 SQL 行为,覆盖读、写、分页、联表,几乎包含所有线上常见数据库问题。
完整业务逻辑如下:
-
用户发起下单请求,查询商品库存与价格,校验商品可下单;
-
库存充足后,扣减对应商品库存,防止超卖;
-
生成用户订单,写入订单表;
-
用户查看历史订单,分页查询个人订单列表。
完整电商下单业务流程可参见图 1-2。
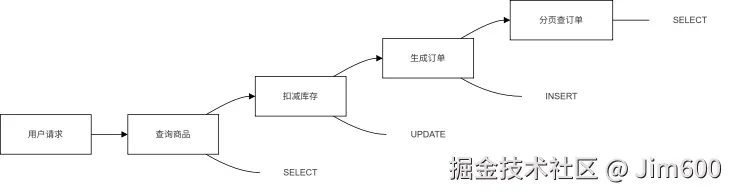
图 1-2 电商下单业务全链路流程
一条简单的下单链路,一条 SQL 从客户端发起,到最终返回结果,会完整走完 MySQL 两大核心层级:Server 服务层与 InnoDB 存储引擎层,每一层都对应一套核心机制,也是本书后续章节要逐一拆解的内容。
1.3.1 MySQL Server 层执行逻辑
Server 层是 MySQL 所有存储引擎共用的一层,不负责具体数据存储,只做请求处理、语法解析、优化与调度,包含连接器、解析器、语义分析、查询优化器、执行器。
1.3.2 InnoDB 存储引擎层执行逻辑
真正的事务、锁、MVCC、缓存、日志、索引全部在 InnoDB 引擎层实现,也是线上故障的根源所在:包含 BufferPool 缓存、索引管理、行级锁机制、MVCC 多版本、Undo/Redo 日志、崩溃恢复、脏页刷盘整套体系。
1.3.3 下单 SQL 跨层完整执行链路
以扣减库存语句 UPDATE goods SET stock = stock - 1 WHERE id = ? 为例,完整跨层执行链路可分为以下步骤:
-
客户端发起请求,通过连接器建立连接并完成身份与权限校验;
-
经过 Server 层语法解析、语义校验,优化器选定主键索引,生成最优执行计划;
-
执行器调用 InnoDB 引擎,通过聚簇索引定位数据页,从 BufferPool 读取缓存数据;
-
施加行级排他锁,生成 MVCC 数据版本,写入 Undo 日志与 Redo 日志;
-
修改内存数据生成脏页,事务提交后异步刷盘,最终释放锁资源。
你写的每一条业务 SQL,底层都要走完这套复杂链路。测试环境链路走得快、冲突少;生产高并发下每一个环节的隐患都会被放大,最终演变成超卖、死锁、卡顿、数据错乱。
事务、锁、MVCC、Redo 日志、Undo 日志、Binlog、索引、BufferPool 缓存、ChangeBuffer、自适应哈希索引、碎片问题、SQL 性能陷阱......
所有你听过、踩过坑的 InnoDB 核心知识点,全部隐藏在这套简单的下单业务中。
本书将从这条业务出发,逐个拆解底层原理,用真实业务场景解释抽象内核概念,真正做到学完即用。
1.4 全书统一业务库表说明
为了保证全书案例统一、逻辑连贯,避免频繁切换业务场景带来的理解成本,本书后续所有章节的故障复盘、原理演示与调优实战,将统一基于以下三张核心业务表展开。
1.4.1 goods 商品表
核心作用:承担全书写操作核心场景,用于复现并发更新丢失、行锁退化表锁、间隙锁阻塞、死锁、长事务风险、库存超卖等线上问题。
sql
CREATE TABLE goods (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(100) COMMENT '商品名称',
price DECIMAL(10,2) COMMENT '商品价格',
stock INT DEFAULT 0 COMMENT '库存数量',
create_time DATETIME
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品表';
CREATE INDEX idx_goods_price ON goods(price);说明:
id:主键唯一索引
idx_goods_price:普通二级索引,专门用于第 3 章锁范围、临键锁、间隙锁场景演示
1.4.2 order_info 订单表
核心作用:承担全书读操作性能场景,用于复现索引失效、深度分页卡顿、排序临时表、视图性能隐患、幻读、数据不一致等问题。
sql
CREATE TABLE order_info (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT COMMENT '自增主键',
user_id INT UNSIGNED NOT NULL COMMENT '用户ID',
goods_id INT UNSIGNED NOT NULL COMMENT '商品ID',
order_no VARCHAR(32) NOT NULL COMMENT '订单编号',
total_amount DECIMAL(10,2) NOT NULL COMMENT '订单金额(元)',
pay_status TINYINT NOT NULL DEFAULT 0 COMMENT '支付状态:0-未支付,1-已支付',
create_time DATETIME NOT NULL COMMENT '下单时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单表';
CREATE UNIQUE INDEX idx_order_no ON order_info(order_no);
CREATE INDEX idx_user_id ON order_info(user_id);
CREATE INDEX idx_goods_id ON order_info(goods_id);
CREATE INDEX idx_order_createtime ON order_info(create_time);说明:
id:主键唯一索引
idx_order_createtime:时间普通索引,用于范围更新、临键锁、锁范围对比案例
1.4.3 user 用户表
核心作用:辅助联表查询、exists/in 性能对比、多表关联优化场景,拓展复杂 SQL 调优思路。
sql
CREATE TABLE user (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(50) COMMENT '用户名',
phone VARCHAR(20) COMMENT '手机号',
`status` tinyint DEFAULT 1,
`create_time` datetime DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
CREATE UNIQUE INDEX idx_phone ON user(phone);本书所有线上故障、性能问题、内核演示,均基于以上三张表展开,所有原理都贴合真实业务,确保你学到的知识可以直接落地到项目中。
1.5 InnoDB 四大不可替代的核心能力
在 MySQL 众多存储引擎中,唯有 InnoDB 成为互联网高并发交易系统的唯一首选,根本原因在于它拥有四大不可替代的核心能力,这也是全书重点拆解的内核基石,支撑起现代互联网海量业务的稳定运行。
第一,完整支持 ACID 事务与四大隔离级别。商品库存、订单交易、支付流水等核心业务,必须保证数据一致性,事务可以确保一组操作要么全部成功、要么全部失败,避免出现库存超卖、订单异常等致命问题。
第二,完善的行级锁机制。InnoDB 支持行锁、意向锁、间隙锁、临键锁,高并发读写场景下,不同行的数据可以并行操作,不会互相阻塞,支撑海量用户同时下单的高并发场景。
第三,MVCC 多版本并发控制。实现了无锁快照读,普通查询不需要加锁,读写互不阻塞,极大提升数据库并发能力,这也是 MySQL 可以支撑大规模互联网业务的关键。
第四,可靠的崩溃恢复机制。通过 Redo 日志、Undo 日志、Binlog 日志,保证服务器断电、宕机后,数据不会丢失,事务不会错乱,保障核心业务数据安全。
可以说,现代互联网的高并发交易业务,本质就是依托 InnoDB 内核能力运行。仅掌握 SQL 语法,往往只能满足测试环境功能开发;理解 InnoDB 内核机制,才能写出适配线上高并发场景的稳妥 SQL。
从本章开始,我们正式从真实业务故障出发,逐层击穿 InnoDB 所有底层核心原理,彻底搞懂 MySQL 线上所有疑难问题。
1.6 InnoDB 整体架构完整详解
前面我们已经了解 MySQL 基础架构、SQL 全生命周期、全书业务模型与 InnoDB 四大核心能力。但很多开发者学事务、锁、MVCC、日志时,都是零散孤立记忆:知道什么是锁、什么是 MVCC、什么是 RedoLog,却不知道这些组件在 InnoDB 架构里处在什么位置、谁依赖谁、谁先谁后、一条 SQL 怎么走完全流程。
如果不懂整体架构,后面学的锁、MVCC、日志都是碎片化知识点,容易记混、理解很浅,遇到线上复杂故障也没法从全链路视角定位根原因。所以本节我们做全书总纲领铺垫,把 MySQL 整体分层、InnoDB 内部所有核心模块、各自职责、相互依赖关系一次性讲透,为后面第 2 章事务、第 3 章锁、第 4 章 MVCC、第 5 章日志打下全局架构基础。
1.6.1 架构整体分层总览
MySQL 整体架构分为两大核心层级:Server 服务层与 InnoDB 存储引擎层,两层各司其职、协同完成整条 SQL 的请求处理与数据持久化。
1. Server 层
该层独立于具体存储引擎,为 MySQL 所有存储引擎所共用。主要包含连接器、解析器、优化器、执行器与 Binlog 组件,整体负责客户端连接管理、语法解析、查询优化、执行调度与逻辑日志记录,不参与实际数据存储、行锁控制与事务底层实现。
2. InnoDB 引擎层
真正的事务机制、行级锁、MVCC 多版本、Undo/Redo 日志、缓冲池、索引管理、数据持久化与崩溃恢复等核心能力,都由 InnoDB 引擎层内部实现,也是线上并发故障、锁等待、死锁、数据一致性问题的核心来源。
一条完整 SQL 的执行流转顺序为:从客户端发起请求,依次经过 Server 服务层做解析与优化,再交由 InnoDB 引擎层完成内存读写、锁控制、日志写入,最终落地到磁盘数据文件持久化保存。
MySQL 整体架构分层关系可直观参见图 1-3。
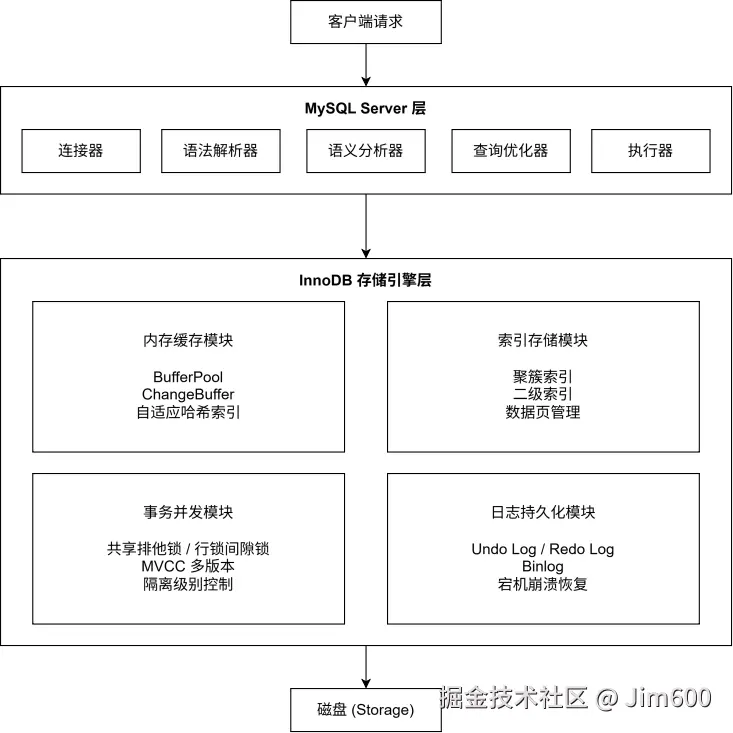
图 1-3 MySQL 整体分层架构
1.6.2 Server 层核心组件拆解
1. 连接器
负责 TCP 连接、身份认证、权限校验、维持会话。我们平时登录 MySQL、应用连接池建立连接,都由连接器管理。
2. 解析器
接收 SQL,做词法、语法解析,生成语法树,检查语法是否合法,语法错直接在这里报错,不会走到后面执行阶段。
3. 优化器
MySQL 核心智能模块:选择索引、决定 JOIN 顺序、选择代价最小的执行路径,生成最优执行计划。我们写同一条 SQL,优化器可能选出不同索引,直接决定性能好坏。
4. 执行器
按照优化器生成的执行计划,调用对应存储引擎的接口,完成查询、更新、写入操作。
5. Binlog
属于 Server 层逻辑日志,跟 InnoDB 引擎无关,MyISAM 也有。
职责:记录所有 DDL/DML 逻辑语句,用于主从复制、数据备份、误操作恢复。
1.6.3 InnoDB 引擎层核心模块总览
理清 MySQL 双层架构之后,我们再深入走进 InnoDB 内部体系。
InnoDB 并不是单一的存储组件,而是一套分工明确、高度协同的复合内核系统,整体由缓冲池、事务锁、MVCC 多版本、日志管理、磁盘表空间以及后台线程几大核心子系统构成。后续全书所有章节,都是围绕这套内核体系逐一拆解原理、复盘线上故障、沉淀开发规范,提前建立整体认知,能让后面零散知识点不再碎片化、不再孤立难理解。
1.6.4 BufferPool 缓冲池核心作用
BufferPool 是 InnoDB 高性能设计的根基,也是支撑互联网高并发业务的核心内存模块。它主要负责缓存业务数据页与各类索引页,让绝大多数读写请求优先命中内存,不必频繁访问低速磁盘。同时还会在内存中维护修改后的脏页,配合后台线程延迟刷盘,避免大量随机 IO 带来的性能损耗;事务元数据、锁信息、MVCC 版本链相关数据,也都会统一托管在缓冲池中,从整体架构上保障数据库低延迟、高吞吐的运行能力。
1.6.5 事务与锁模块
事务与锁是把控并发安全、解决写写互斥的核心内核模块。
整套事务生命周期管理、事务 ID 分配、提交与回滚机制都在这里统一调度;
同时 InnoDB 完整的意向锁、行记录锁、间隙锁、临键锁以及死锁检测、锁等待队列,也都归属这套子系统统筹管理。线上出现的更新丢失、锁阻塞、随机死锁、库存超卖等问题,根源几乎都出自事务与锁的机制设计,也是本书第 2 章、第 3 章重点攻坚的核心内容。
1.6.6 MVCC 多版本模块
MVCC 是实现读写互不阻塞、支撑海量查询并发的关键设计。
它依托 UndoLog 构建完整数据版本链,再配合 ReadView 事务快照,做精准的数据可见性判定。通过多版本机制,InnoDB 天然支撑 RC、RR 两大主流隔离级别,普通查询无需加锁即可安全读取历史快照,真正做到高并发场景下读写互不争抢,这也是 MySQL 能承载大规模互联网业务的底层底气,我们将在第 4 章完整拆解整套运行逻辑。
1.6.7 日志模块分工
InnoDB 三套日志体系职责边界清晰、各司其职,各自承担不可替代的作用。
RedoLog 作为引擎层物理日志,核心专注宕机崩溃恢复,保证已提交事务数据绝不丢失,采用顺序循环写入的方式兼顾性能与安全。
UndoLog 一身承担两大核心能力,既支撑事务执行失败后的回滚操作,又为 MVCC 多版本提供历史版本链存储。
而 Binlog 归属 MySQL Server 层逻辑日志,和存储引擎无关,主要服务主从复制、数据备份与误操作时间点恢复,并不参与崩溃恢复。
三者定位极易混淆,本章只做架构层级铺垫,详细原理与生产调优统一放在第 5 章深入讲解。
1.6.8 后台线程作用
InnoDB 并不会把繁重的 IO 清理、日志刷新、脏页落盘等任务交给前台业务请求,而是全部由专属后台线程异步调度、后台默默完成。包括脏页异步刷盘、无用 Undo 版本链回收、日志定时刷新、实例启动后的崩溃重做与回滚,都由后台线程在业务低峰平稳执行。正是把大量耗时 IO 任务后置异步处理,才让前台业务 SQL 能够保持极致低延迟,不被底层繁重操作拖累。
1.6.9 磁盘表空间与数据页
InnoDB 所有业务数据、各类索引,最终都会持久化在磁盘表空间文件中,并且以固定 16KB 数据页作为最小管理单位。无论是聚簇索引、二级索引,还是普通业务行数据,都规整存储在数据页内部。我们日常接触的索引检索、行锁锁定、MVCC 版本链回溯,底层本质都是在数据页内完成逻辑匹配与状态维护,理解表空间与数据页组织结构,是学好索引、锁机制、碎片原理的必备前置基础。
1.6.10 一条更新 SQL 全架构完整复盘
我们以电商业务最常见的库存更新语句为例,串联整条请求在 MySQL 全架构中的流转过程,建立完整链路印象。业务发起更新请求后,先经过连接器完成连接与权限校验,经由解析器做语法合规判定,再由查询优化器筛选最优索引、生成执行计划,交由执行器调用 InnoDB 引擎接口。InnoDB 优先从 BufferPool 缓冲池中读取对应数据页,对热点行施加行级排他锁,同时生成 Undo 历史版本,在内存中完成数据修改产生脏页,同步写入 RedoLog 日志缓冲区。待事务正常提交后,再由 Server 层记录 Binlog,最终依靠后台线程异步将内存脏页刷入磁盘、释放事务与锁资源。整条流程完整串起 Server 层、缓冲池、锁机制、MVCC、Undo、Redo、Binlog 与后台线程,后续所有内核知识点,都能在这条链路中找到对应的位置与作用。
1.7 本书学习方法论
本书完全颠覆传统教学模式,采用生产逆向学习法,全书遵循统一讲解逻辑:先呈现线上难以复现的诡异故障现象,再对问题进行定位剖析,进而逆向拆解背后的 InnoDB 底层内核原理,给出对应的问题根治方案,最终沉淀为可直接落地的开发编码规范。
每一章、每一节、每一个知识点,都严格遵循这套讲解范式。先抛出真实线上故障场景引发思考,再带着疑问拆解底层运行机制,解释故障产生的根本原因,最后给出解决方案并固化为开发规范。
你学完本书,不再只是死记硬背什么是锁、什么是 MVCC、什么是事务隔离级别这类抽象概念,而是真正具备实战排障能力:遇到数据库卡顿、锁等待、死锁、数据不一致、性能抖动等问题,能够瞬间脑补出整条 SQL 的内核执行链路,精准定位根因,写出线上安全、并发可靠、性能优异的业务 SQL 与事务代码。
整套逆向实战学习范式的完整闭环逻辑,如下图所示。
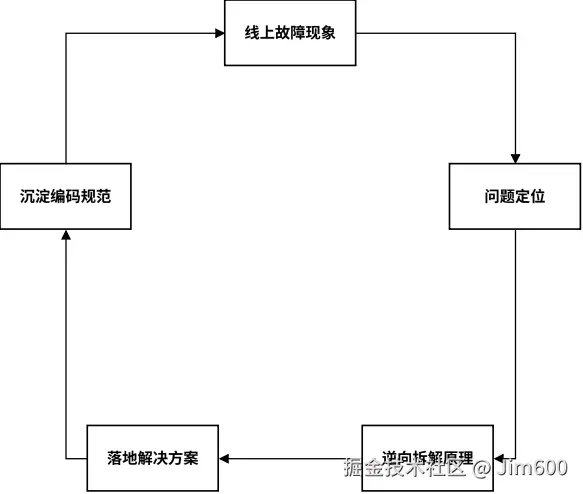
图 1-4 学习方法论闭环
1.8 本章小结
本章首先指出广大开发者普遍存在的认知局限:大多只掌握 SQL 基础语法,不了解 InnoDB 底层运行机制,因而出现测试环境一切正常,上线高并发生产环境却频发超卖、死锁、锁等待、数据不一致、性能间歇性卡顿等疑难问题。
通过典型业务故障场景与实际案例,对比梳理了测试与生产环境的核心区别,并从并发量级、事务长短、InnoDB 底层机制触发、系统资源负载四个维度,剖析了两类环境表现差异的内在根源。
在此基础上,厘清了普通开发者与资深数据库工程师的核心差距:不在于 SQL 编写本身,而在于能否读懂 SQL 在 MySQL 中的完整内核执行链路,预判锁行为、数据可见性及各类并发隐患。
随后介绍了 MySQL 整体架构,确立以电商下单业务作为全书统一主线,并规范了商品表、订单表、用户表三套业务模型,为后续原理讲解提供统一落地场景。
同时梳理了 InnoDB 四大核心能力,逐层拆解 MySQL Server 层与 InnoDB 存储引擎层的组件构成、职责分工与协作逻辑,区分了 RedoLog、UndoLog、Binlog 的定位与作用,完整呈现了一条更新 SQL 的全架构流转过程。
最后提出本书专属的逆向实战学习方法论,遵循从线上故障现象切入、开展问题定位、拆解底层原理、给出落地方案、沉淀编码规范的完整学习闭环,为全书后续章节的讲解思路与知识框架确立了统一标准。
本章为后续系统学习事务隔离、行锁间隙锁、MVCC、日志机制、索引原理及 SQL 性能调优,搭建了完整的全局知识框架。