文章目录
-
-
- [一、 项目背景与需求分析:个人数字影像资产的痛点挖掘与多维功能推演](#一、 项目背景与需求分析:个人数字影像资产的痛点挖掘与多维功能推演)
-
- [1. 资产无感净洗与端侧多模态语义索引需求](#1. 资产无感净洗与端侧多模态语义索引需求)
- [2. 时空拓扑自适应聚类与情境感知需求](#2. 时空拓扑自适应聚类与情境感知需求)
- [3. 多模态故事脚本创写与视听故事生成需求](#3. 多模态故事脚本创写与视听故事生成需求)
- [二、 系统架构设计:基于 Clean Architecture 的端云协同多模态 Infra](#二、 系统架构设计:基于 Clean Architecture 的端云协同多模态 Infra)
-
- [1. 分层解耦设计与数据契约统一](#1. 分层解耦设计与数据契约统一)
- [2. 关键核心服务模块的生命周期谱系](#2. 关键核心服务模块的生命周期谱系)
- [三、 原型设计与 UI 还原:从 Figma 高保真蓝图到 VS Code 组件级高精还原](#三、 原型设计与 UI 还原:从 Figma 高保真蓝图到 VS Code 组件级高精还原)
-
- [1. Figma 原型设计美学与设计系统交互契约](#1. Figma 原型设计美学与设计系统交互契约)
- [2. 核心突破:沉浸式卡片流与智能搜图主视图的高保真还原](#2. 核心突破:沉浸式卡片流与智能搜图主视图的高保真还原)
- [四、 核心技术攻关:基础版多模态语义搜图的从零奠基(V1.0 MVP)](#四、 核心技术攻关:基础版多模态语义搜图的从零奠基(V1.0 MVP))
-
- [1. 前端交互的工程化防抖与状态驱动](#1. 前端交互的工程化防抖与状态驱动)
- [2. 独创的"两段式"端云协同检索链路](#2. 独创的“两段式”端云协同检索链路)
- [五、 多模态音视频合成技术攻关:端云协同双轨配乐引擎与 Librosa 信号分析](#五、 多模态音视频合成技术攻关:端云协同双轨配乐引擎与 Librosa 信号分析)
-
- [1. 配乐引擎的三剑客架构:云端 AI 生成、端侧信号处理与核心关联](#1. 配乐引擎的三剑客架构:云端 AI 生成、端侧信号处理与核心关联)
- [2. 多媒体底层破局:端侧 FFmpeg 原生解码与跨语言 Python Librosa 信号分析流](#2. 多媒体底层破局:端侧 FFmpeg 原生解码与跨语言 Python Librosa 信号分析流)
-
- [(1) 端侧多媒体流水线:基于 FFmpeg 动态阻断式 Mono 解码逻辑](#(1) 端侧多媒体流水线:基于 FFmpeg 动态阻断式 Mono 解码逻辑)
- [(2) 跨语言核心算法攻坚:基于 Librosa 与 Numpy 的时域能量打卡引擎](#(2) 跨语言核心算法攻坚:基于 Librosa 与 Numpy 的时域能量打卡引擎)
- [(3) 工程防错与复杂数据类型序列化容灾](#(3) 工程防错与复杂数据类型序列化容灾)
- [3. 容灾机制:基于多模态语义距离的本地音频资产动态熔断与兜底引擎](#3. 容灾机制:基于多模态语义距离的本地音频资产动态熔断与兜底引擎)
-
- [(1) 非阻塞式多轨状态机与智能熔断策略](#(1) 非阻塞式多轨状态机与智能熔断策略)
- [(2) 基于语义关键词多维向量距离的智能音频资产检索算法](#(2) 基于语义关键词多维向量距离的智能音频资产检索算法)
- [(3) 闭环交付:本地资产的物理沙盒释放与信号重解析](#(3) 闭环交付:本地资产的物理沙盒释放与信号重解析)
- [六、 高可用标题生成](#六、 高可用标题生成)
-
- [1. 攻坚数据断层:解决跨相册勾选的"上下文饥饿"问题](#1. 攻坚数据断层:解决跨相册勾选的“上下文饥饿”问题)
- [2. 健壮性防线:基于启发式位置词频统计的本地熔断降级策略](#2. 健壮性防线:基于启发式位置词频统计的本地熔断降级策略)
- [七、 多模态音视频合成导出:基于 Flutter 图形管线的实时卡点渲染引擎](#七、 多模态音视频合成导出:基于 Flutter 图形管线的实时卡点渲染引擎)
-
- [1. 实时视听引擎的核心交互拓扑与非线性数据流](#1. 实时视听引擎的核心交互拓扑与非线性数据流)
- [2. 全自研视觉特效矩阵引擎的核心算法](#2. 全自研视觉特效矩阵引擎的核心算法)
-
- [(1) 赛博朋克故障艺术组件(`GlitchEffect`):基于伪随机数与色差分离的撕裂算法](#(1) 赛博朋克故障艺术组件(
GlitchEffect):基于伪随机数与色差分离的撕裂算法) - [(2) 胶片质感色彩引擎(`StaticFilters`):基于 4 × 5 4\times5 4×5 高维颜色特征矩阵乘法的动态重映射](#(2) 胶片质感色彩引擎(
StaticFilters):基于 4 × 5 4\times5 4×5 高维颜色特征矩阵乘法的动态重映射) - [(3) 治愈系云朵自绘制画布(`CloudBorderEffect`):基于数学正余弦拓扑的高可用毛边遮罩](#(3) 治愈系云朵自绘制画布(
CloudBorderEffect):基于数学正余弦拓扑的高可用毛边遮罩) - [(4) 时域分层字幕渲染器(`SubtitleEffectLayer`):防前端溢出的防御性编排](#(4) 时域分层字幕渲染器(
SubtitleEffectLayer):防前端溢出的防御性编排)
- [(1) 赛博朋克故障艺术组件(`GlitchEffect`):基于伪随机数与色差分离的撕裂算法](#(1) 赛博朋克故障艺术组件(
- [3. 所见即所得的白盒实时控制与离线合成底座](#3. 所见即所得的白盒实时控制与离线合成底座)
- [4. 底层多媒体管线攻坚:基于动态离屏通道的异步静默音视频合成与高保真封包(基于 `OffscreenRenderWorker`)](#4. 底层多媒体管线攻坚:基于动态离屏通道的异步静默音视频合成与高保真封包(基于
OffscreenRenderWorker)) -
- [(1) 线程隔离与"白盒离屏纹理捕捉"架构设计](#(1) 线程隔离与“白盒离屏纹理捕捉”架构设计)
- [(2) 智能静默导出与全生命周期资源交付逻辑](#(2) 智能静默导出与全生命周期资源交付逻辑)
- [5. 社交生态分发:多模态文案创写与多态自适应分享引擎(基于 `PublishPage`)](#5. 社交生态分发:多模态文案创写与多态自适应分享引擎(基于
PublishPage)) -
- [(1) 基于大模型语义泛化的跨平台文案"风格矩阵"定制](#(1) 基于大模型语义泛化的跨平台文案“风格矩阵”定制)
- [(2) 防御性粘贴与跨平台组件级原子拉起](#(2) 防御性粘贴与跨平台组件级原子拉起)
- [八. 多模态 Agent 演进:基于全局智能体的多轮交互与意图路由搜图引擎](#八. 多模态 Agent 演进:基于全局智能体的多轮交互与意图路由搜图引擎)
-
- [1. 智能体意图路由与"动态工具调用"机制](#1. 智能体意图路由与“动态工具调用”机制)
- [2. 时空维度的经典排错:10位与13位时间戳精度的"血案"破案纪实](#2. 时空维度的经典排错:10位与13位时间戳精度的“血案”破案纪实)
- [九、 规范化工程交付:软件工程全套文档矩阵提纯与 AE 高保真功能演示短片设计](#九、 规范化工程交付:软件工程全套文档矩阵提纯与 AE 高保真功能演示短片设计)
-
- [1. 结构化数字资产:全套可考核、可量化软件工程文档矩阵的统筹编纂](#1. 结构化数字资产:全套可考核、可量化软件工程文档矩阵的统筹编纂)
- [2. 视觉化媒体交付:基于 After Effects (AE) 的高保真系统演示短片主控设计](#2. 视觉化媒体交付:基于 After Effects (AE) 的高保真系统演示短片主控设计)
-
一、 项目背景与需求分析:个人数字影像资产的痛点挖掘与多维功能推演
随着移动端计算摄影技术的飞速迭代,海量碎片化影像生产全面普及,每个普通人的手机中都沉淀了数以万计的碎片化照片。然而,用户在管理和二次创作个人影像时,正面临着难以逾越的鸿沟:相册中充斥着连拍废片、屏幕截图及重复场景,缺乏深层语义理解的机械时间轴陈列,让海量珍贵记忆沦为混乱的"数字囤积废料";同时,从静态照片到有感染力的视听故事,面临着素材初筛、繁琐剪辑、音画卡点等高昂的心智负担;更严重的是,传统 AI 工具强制要求全量上传照片至公有云,严重触碰了用户的隐私红线。
作为《智能影记(Memoria)》项目的组长,在实训初期,我统筹编纂了《项目计划书》与《项目实训任务书》,确立了"端侧优先、云端增强、隐私防火墙隔离"的核心技术路线,力求打造一款兼顾隐私保护的"零门槛"智能生活导演系统。通过对全链路工程的深度剖析,将用户行为抽象并推演出了系统三大核心需求域:
1. 资产无感净洗与端侧多模态语义索引需求
系统必须在纯端侧本地环境下,对用户的原始相册进行增量扫描。为解决海量垃圾图片对算力和存储的无效占用,系统需要具备"阻断式废片剔除"能力,结合文件路径特征、极限宽高比规则( Ratio < 0.52 \text{Ratio} < 0.52 Ratio<0.52)以及轻量级文本密度检测,高效率过滤掉截屏、拍屏文档和无意义废片。在此基础上,必须在本地安全域内提取图像高维特征与人脸特征向量,建立多维语义标签与高维近邻索引,以满足用户在移动端进行毫秒级跨模态自然语言搜图的底层性能需求。
2. 时空拓扑自适应聚类与情境感知需求
系统需打破传统的扁平化网格陈列,引入拟人化的情境感知能力。系统需深度解析照片 EXIF 元数据中的原始拍摄时间戳与 GPS 经纬度,动态计算物理空间距离阈值与时间窗口断层,精准地将零散照片划分为具有生命事件边界的实体块。系统还需具备调用高德地图 API 进行逆地理编码补全位置语义的能力,并在夜间设备充电、息屏等闲时状态,主动向用户推送排版精美的"回忆草稿",推动影像管理向"主动式情绪陪伴"跃迁。
3. 多模态故事脚本创写与视听故事生成需求
针对视频和创作门槛高的诉求,系统需具备全自动的" AI 编导"能力。基于用户选定的照片集合与事件时空上下文,系统要能够自动规划包含起承转合结构的可视化分镜剧本大纲,自适应生成契合全渠道调性的专属情感文案。同时,系统需将零散图文复用并自动编排为具有实体纪念册仪式感的数字相册书(包含完整 contentJson 页面内容描述),并支持基于 Librosa 等音频处理技术实现音画情绪对齐、音视频重度合成与高保真导出,实现从"碎片化照片"到"院线级回忆短片"的完整创作闭选。
二、 系统架构设计:基于 Clean Architecture 的端云协同多模态 Infra
在项目初期进行技术调研时,我们便确立了"端侧优先、云端增强、隐私防火墙隔离"的核心技术路线。现代多模态个人影像系统面临着海量碎片化数据带来的"数字囤积焦虑"与极端敏感的"人脸/时空轨迹隐私红线"之间的核心矛盾。
为了在保障"原始照片不出域"这一隐私红线的同时,赋予系统院线级的 AIGC 视频创作与数字相册排版能力,我为项目设计并搭建了 V1.0 核心基础底座(MVP 架构) ,整体架构严格遵循 Clean Architecture(清洁架构) 原则:
1. 分层解耦设计与数据契约统一
系统从上至下严格划分为三大核心逻辑层:
-
UI 表现层:使用 Flutter 响应式框架构建统一的相册瀑布流、故事配置页与沉浸式数字相册书。
-
领域业务服务层:以单例模式常驻于内存,作为核心计算与意图路由的中枢。
-
底层硬件与数据持久化层:基于 Rust 优化的 Isar 数据库,通过 Dart FFI 直接桥接底层 C/C++ 原生动态链接库。
系统采用了实体层(Entity - 持久化层)与表现层(VO - 视图对象)分离的解耦模式。所有子模块(如相册扫描、事件聚类、AI理解)之间,统一围绕 PhotoEntity、EventEntity、FaceEntity 与 StoryEntity 结构化对象进行数据传递,保证了数据库逻辑不会过度侵入 UI 渲染代码,这也为中后期功能重构及多视频模态扩展预留了清晰的演进入口。
2. 关键核心服务模块的生命周期谱系
自研系统内部的计算流转呈现出标准的分阶段非阻塞处理流水线:
[PhotoService(收集/过滤)] ──> [EventClusterHelper(切分/时空聚类)] ──> [AIService(端侧识别/标签/OCR)] ──> [StoryService(端云协同故事创写)]-
PhotoService(相册扫描同步) :获取原生媒体库增量资源,利用充血模型下沉拦截策略,基于文件路径与极限宽高比( Ratio < 0.52 \text{Ratio} < 0.52 Ratio<0.52)进行 L1 级快速无感数据清洗,在最前端剔除截屏、表情包等"数字垃圾"。 -
EventClusterHelper(自研时空自适应聚类底座) :这是整个项目故事线生成的绝对底层算法支柱。该算法通过串联按时间排序的照片队列,动态计算物理空间距离阈值(千米级)与时间窗口断层(小时级),精准地将零散照片划分为具有事件边界的EventEntity块,将扁平的流水账平铺网格彻底立体化。 -
AIService(端侧智能标记) :利用闲时线程池,将图像送入端侧轻量化视觉模型,异步进行场景物品打标、OCR 文本密度检测与人脸表情倾向评估(smileProb),综合计算出单张照片的joyScore欢乐度评分,使相册具备真正的"语义看懂"能力。 -
StoryService&LLMService(故事脚本生成与端侧容灾):当用户触发创作意图时,系统萃取当前事件的时间、城市 POI 及高频语义标签,组装为高表现力的结构化 Prompt 喂给云端 LLM。
为了保证极端的环境适应性,我特别设计了本地智能规则兜底引擎(smart_title_generator.dart) ,在断网、弱网或大模型服务不可用时,系统瞬间触发熔断,自动降级使用"时间+地名+高频标签模板"进行生成,确保了核心视频/图文创作流的 100% 高可用性与主线程零阻塞。
三、 原型设计与 UI 还原:从 Figma 高保真蓝图到 VS Code 组件级高精还原
在项目的全生命周期开发中,良好的界面需求管理是保障用户体验、消除配文焦虑与分享焦虑的最后一公里。为了将复杂的多模态 AI 推理与工程渲染逻辑以极简、治愈的视觉交互封装呈现,我进行了 Figma 高保真原型图设计,并在此基础上实现了代码级高还原落地。
1. Figma 原型设计美学与设计系统交互契约
在 Figma 概念设计阶段,我秉承"内容先行、版式服务内容、极简无负担"的设计哲学。在视觉上大量引入大面积自然留白、轻量高雅的渐变与沉浸式卡片式布局,确保用户的视觉焦点始终汇聚于"回忆影像"本身。
-
设计系统契约 :定义了 Memoria 的品牌种子色(
const Color.fromARGB(255, 255, 64, 129))。在进入开发后,我直接在lib/main.dart顶层配置中利用 Material 3 的算法色彩生成引擎(ColorScheme.fromSeed),让 Flutter 引擎依据该种子色自动推导出包含主色、容器色、表面色、排版色的高对比度协调色板。这一做法极大减少了 UI 的硬编码色值和样板代码,保障了整套系统视觉上的高级和谐感。 -
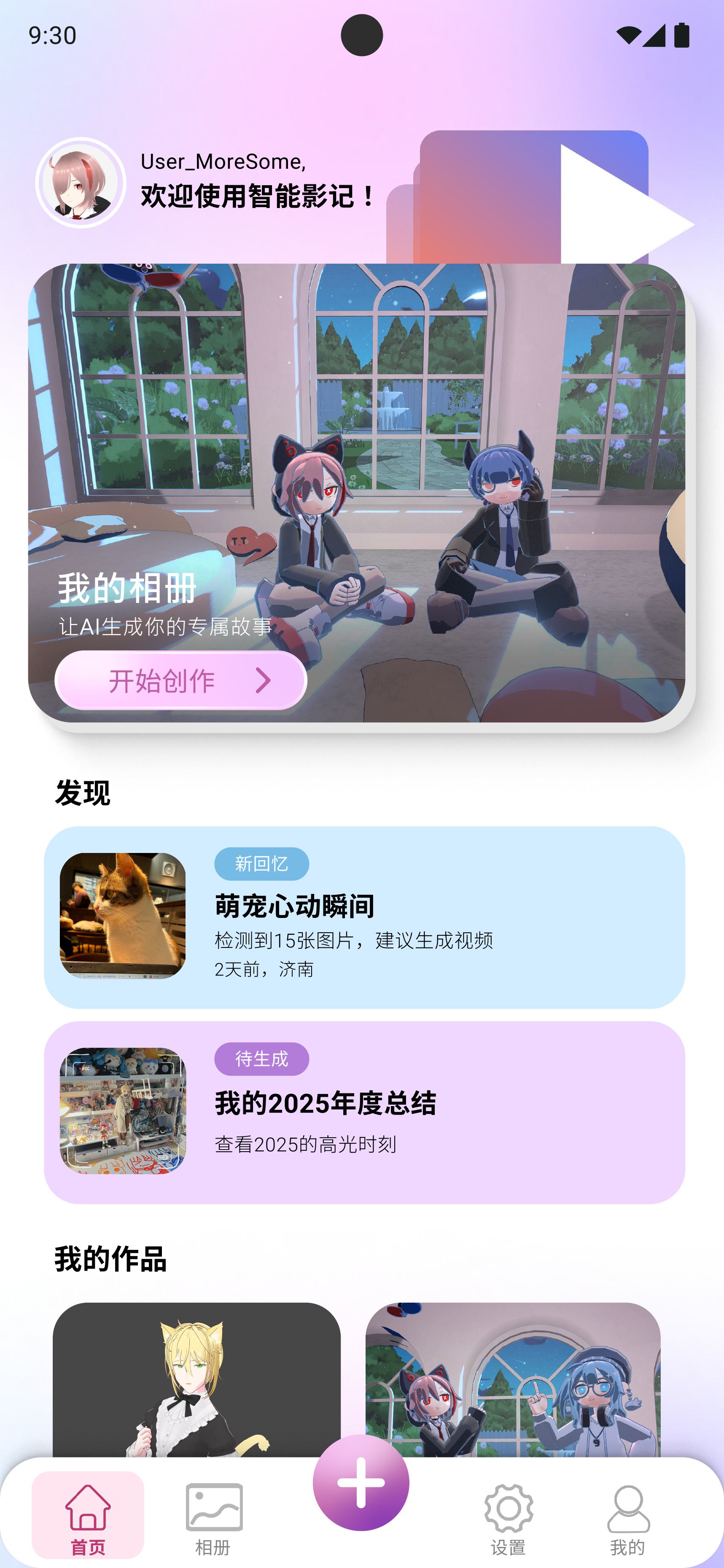
图文故事与音画分析进度页设计 :设计了极具科技质感的分阶段进度流。点击"生成故事"后,UI 会通过专门的进度节点状态机,向用户实时展示"整理照片、解析时间地点、提取已有线索、保存并整理展示"的白盒化解析过程,极大缓解了用户在大模型推理和端侧多模态分析过程中的等待焦虑。

2. 核心突破:沉浸式卡片流与智能搜图主视图的高保真还原
通过在 VS Code 中对 Flutter Widget 树进行精细化组装,系统完美复现了 Figma 的设计初衷与高逼格交互:
-
沉浸式首屏卡片流交互 :
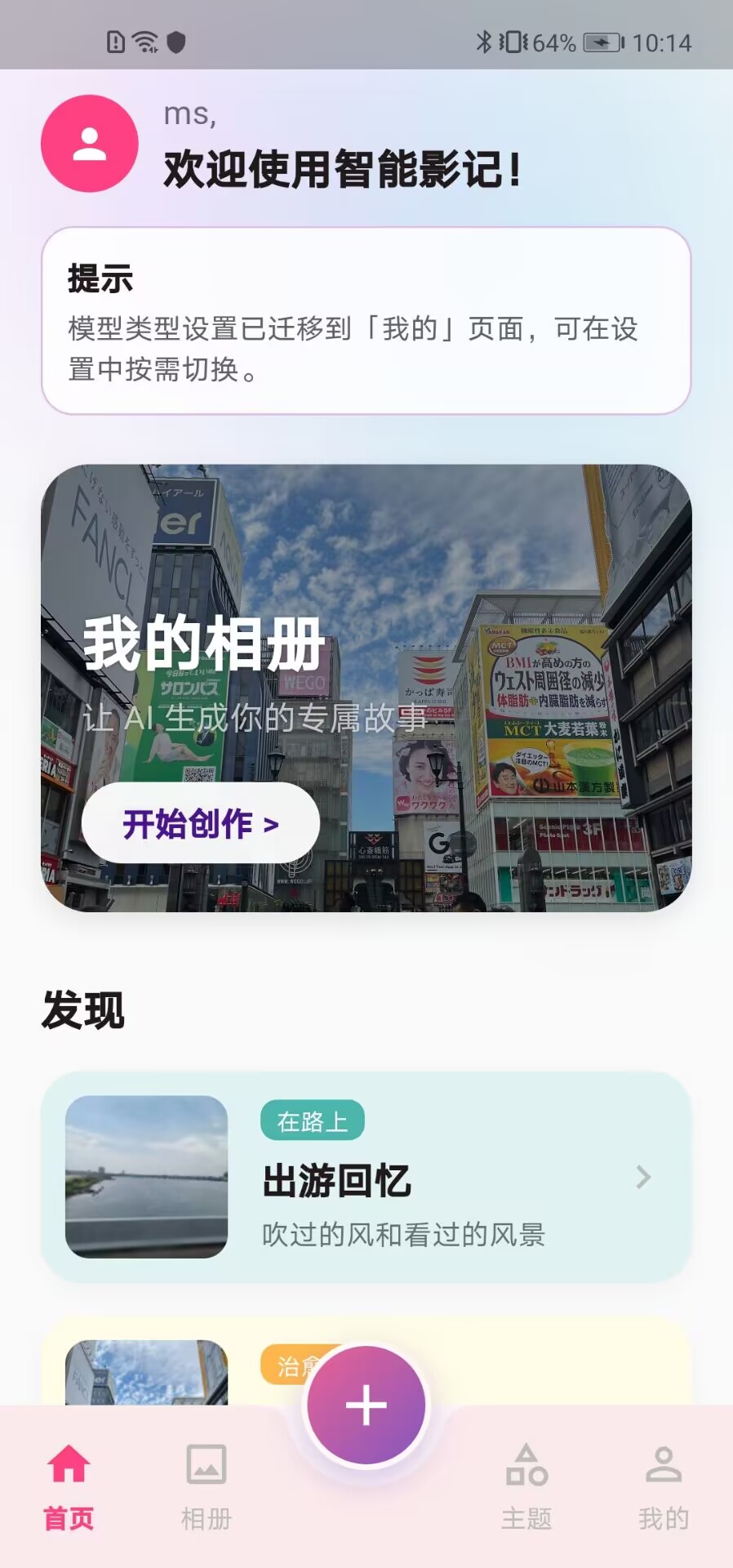
如截图所示,我为应用打造了沉浸式的主页卡片流。视觉上采用高雅的渐变色叠加与磨砂玻璃材质悬浮卡片,以"做自己生活的导演,记录生活,留住美好"这一极具情绪价值的核心交互,引导用户触发回忆。在代码层面,该界面挂载了我设计的异步启动路由分发状态机 :应用首屏启动时,会静默触发底层单例服务,异步探测 Isar/ObjectBox 数据库的挂载状态及用户的鉴权态,实现从欢迎入口到主 Widget 树的丝滑分发。
-
多模态语义搜图与响应式瀑布流还原 :
这是系统展现端侧智能与界面搭建能力的核心主视图 。顶层提供多模态语义搜索框,用户可以直接通过生活化表达进行模糊检索。
在下方的内容展示区,我利用 Flutter 的高级布局组件,完美 1:1 还原了 Figma 中设计的自适应错落网格瀑布流 。为了模拟真实的视觉呼吸感,我为每张影像卡片定义了精细的圆角(
BorderRadius)与轻量级的防溢出裁切,并依据照片元数据的真实宽高比动态计算卡片纵向延伸空间,彻底打破了传统相册死板的"九宫格方块"陈列,给用户带来极具人文温度的视觉流体验。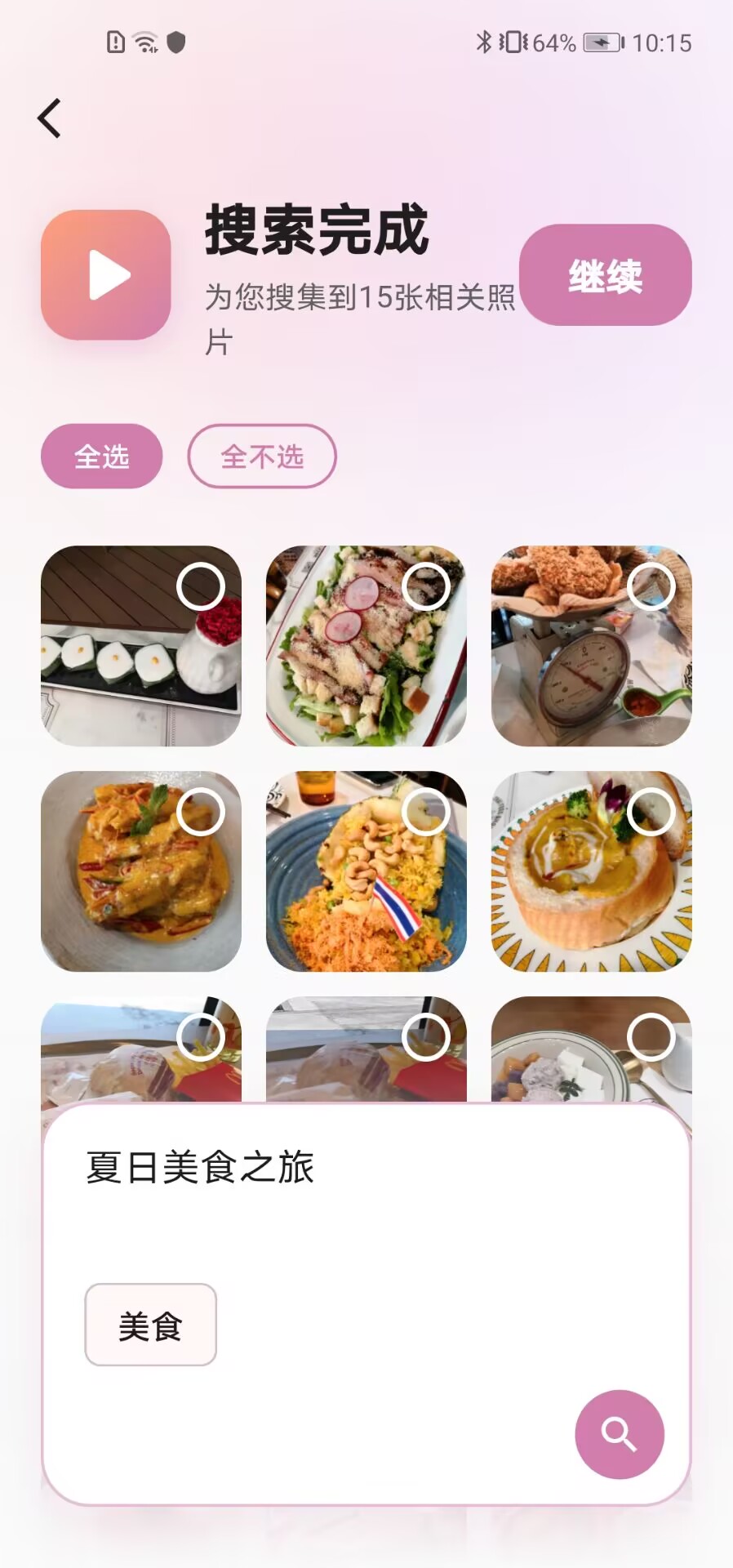
四、 核心技术攻关:基础版多模态语义搜图的从零奠基(V1.0 MVP)
作为功能闭环的先锋模块,自然语言智能搜图 是本项目的核心技术壁垒。在开发中期,由于底层的端侧原生 C++ 向量搜索引擎仍在进行复杂的算子转换与机型适配,为了不阻塞顶层 UI 的开发进度并快速验证用户体验,我设计了最初版本的基于"云端语义泛化 + 本地标签级联碰撞"的 V1.0 语义搜图引擎。
虽然后期系统引入了全量端侧向量检索并对本模块进行了重构覆盖,但 V1.0 版本的两段式架构成功完成了系统核心链路的"冷启动",其工程设计思想至今仍是系统容灾的核心:
1. 前端交互的工程化防抖与状态驱动
搜索框的高频触发是导致内存抖动与多余网络开销的元凶。在 SearchPage 的交互实现中,通过响应式状态管理,引入了工程化防抖机制 。利用 RxDart 或自定义 Timer 拦截用户的连续键盘输入,设定 500ms 的非活动等待窗口。只有当用户停止输入超过 500ms 后,搜索意图才会向下传递,有效降低了系统的非必要计算负载。
2. 独创的"两段式"端云协同检索链路
为解决用户极端抽象的自然语言(例如"和朋友去吃大餐")与本地结构化数据无法直接匹配的痛点,我们使用如下高效的数据检索流水线:
- 步骤一:网络请求与语义降维扩展
当防抖触发后,客户端通过封装好的Dio库向自研后端发起异步非阻塞网络请求。利用云端大语言模型的常识理解能力,将用户的自然语言"降维扩展"为我们本地持久化层已存在的离散标签集(例如将"吃大餐"映射为["聚餐", "美食", "餐厅"]的语义近邻词簇)。 - 步骤二:Isar 多标签高速级联查询
客户端拿到扩展标签集后,我充分压榨 Isar 数据库底层基于 Rust 的多维索引查询性能。编写了级联过滤逻辑,利用anyOf原生算子在本地海量PhotoEntity集合中进行布尔碰撞,秒级召回所有包含相关aiTags的照片实体:
dart
// 本地 Isar 核心查表过滤片段
final isar = PhotoService().isar;
final results = await isar.photoEntitys.filter()
.anyOf(targetTags, (q, String tag) => q.aiTagsElementEqualTo(tag))
.or()
.anyOf(targetTags, (q, String tag) => q.ocrTagsElementEqualTo(tag))
.findAll();通过这种端云协同的巧妙折中,系统在保障照片原始文件不出域的隐私底线前提下,在项目初期便以极低端到端延迟实现了模糊语义搜图体验,为后续整个系统多模态架构的演进确立了高标准的工程范式。
五、 多模态音视频合成技术攻关:端云协同双轨配乐引擎与 Librosa 信号分析
智能影记(Memoria)不仅是一个静态回忆的编排工具,更是一个能实现"画幅共振、音画合一"的多模态视听故事生成系统。为了让最终导出的回忆短片具备院线级的艺术感染力,音频部分的选型、打拍与情绪分析至关重要。
作为音频处理与视频生成模块的负责人,我设计并搭建了【基于端云协同的双轨制回忆配乐与数字信号分析流水线】。以下将深入剖析该模块的底层技术架构演进与核心组件交互逻辑。
1. 配乐引擎的三剑客架构:云端 AI 生成、端侧信号处理与核心关联
为了满足用户极致的个性化表达,我将系统设计为" AI 自动生成 BGM(云轨)"与"用户自主导入音乐(本地轨)"的双轨制策略体系。在你的架构设计中,上游代码通过以下三个核心 Dart 文件完成了从"语义理解"到"音频物理降维"的全链路数据流转:
┌─────── 轨 1:AI 自动配乐 ───────┐
[llm_service_story_music.dart] [music_gen_service.dart]
(大模型提取画面情感 Prompt) (MusicGen 生成并下载 MP3)
└─────────────────────────────────┘
│
▼ (下载到本地沙盒 / 或用户自主导入本地轨 2)
[music_service.dart]
(调用本地跨平台插件 / Librosa 分析引擎)
│
▼
输出:包含 BPM、Beats 节拍点、
Arousal-Valence 情绪标签的统一 JSON这三个核心代码文件的底层依赖与协同关联关系如下:
llm_service_story_music.dart(多模态情感路由) :作为整个多模态创作的"总导演"。它异步接收当前事件中每张照片的具体镜头特征、OCR 线索及整体欢乐值,利用大语言模型的常识推理能力,同时生成两样东西:一是起承转合的故事脚本文案,二是精准契合画面情感的专属 BGM 提示词。music_gen_service.dart(AIGC 音乐生成服务) :承接上游生成的音乐 Prompt。它通过安全握手协议将 Prompt 送入云端facebook/musicgen-small大模型进行动态谱曲。该服务内部实现了一个非阻塞的轮询等待状态机,在十几秒内实时捕捉模型的生成状态,并在生成成功后,负责将远端 MP3 音频流平滑下载至移动端的手机沙盒临时目录。music_service.dart(端侧数字信号处理中枢) :这是整个音频流水线的"终点站",也是自主导入音乐与 AI 生成音乐汇合的枢纽 。无论是用户从本地媒体库强行导入的私有 MP3,还是由MusicGen刚刚下载落盘的 AI 生成音乐,都会在此统一被路由投递至底层的数字信号分析引擎------通过music_feature_analyzer(底层由 Python/C++ 原生跨平台移植的 Librosa 库支撑),静默解析出音频的物理拍速、绝对节拍点时间戳队列以及基于 Arousal-Valence 的情感坐标,最终合并输出一份高表现力的结构化 JSON 契约文件,为后期的视频画面卡点与运镜切换提供最坚实的物理参考。
在代码具体落地中,我引入多项系统容灾与领域建模机制。以下为几段核心架构代码与技术亮点:
- 技术亮点一:基于严格事实约束的端侧画面元数据特征萃取(基于
LLMServiceStoryMusic)
为了杜绝大模型在创写剧本和配乐提示词时凭空"幻觉",我将照片的多维特征下沉至 Prompt 构建的最底层。以下代码展示了通过结构化输入强制约束模型输出严格包含音乐风格倾向的复合对象:
dart
// 引用自 llm_service_story_music.dart
Future<Map<String, dynamic>?> generateStoryAndMusic({
required int eventId,
required List<String> tags,
List<String> ocrTags = const <String>[],
required double joyScore,
String stylePreference = "治愈风",
String? photoDetails, // 传入具体每一帧的视觉特征描述
}) async {
print("🚀 [请求发送] 正在携带具体帧画面特征呼叫大模型...");
final prompt = '''你现在是一位拥有顶级镜头感和音画通感能力的电影导演...''';
// 发送 DeepSeek 请求,获取包含文本故事与 music_prompt 的标准结构化响应
}- 技术亮点二:带异步轮询防死锁机制的远端音频流水线管理(基于
MusicGenService)
AI 音乐生成属于典型的重度长周期异步任务。为了保障主线程无感,我利用 Dart 的async/await协程机制构建了一个健壮的防死锁主动轮询机制,每隔 3 秒对 Replicate 服务器进行状态快照探测,并配合安全下载网络流,确保了沙盒落盘的鲁棒性:
dart
// 引用自 music_gen_service.dart
while (true) {
await Future.delayed(const Duration(seconds: 3));
final pollResponse = await http.get(Uri.parse(predictionUrl), headers: {...});
final pollData = jsonDecode(pollResponse.body);
if (pollData['status'] == 'succeeded') {
audioUrl = pollData['output']; // 成功捕获生成的音频流 URL
break;
} else if (pollData['status'] == 'failed') {
throw Exception('生成音乐失败');
}
}2. 多媒体底层破局:端侧 FFmpeg 原生解码与跨语言 Python Librosa 信号分析流
在多模态音视频卡点合成的工程落地中,系统面临的最大的物理限制是:用户输入的音乐(不管是 AI 生成的还是本地导入的)多为经过高压缩比编码的 MP3/AAC 格式,而底层的 Librosa 及信号分析算法只能直接吞噬单声道的原始未压缩 PCM/WAV 二进制流水。
为了打破这一跨平台的计算壁垒,并保证后续视频生成模块能拿到绝对精准的毫秒级时序契约,我开发了【基于端侧 FFmpeg 原生解码与跨语言高性能 Librosa 节拍能量提取流水线】。
这一链路展现了系统在处理复杂异构多媒体数据时的极限性能控制:
(1) 端侧多媒体流水线:基于 FFmpeg 动态阻断式 Mono 解码逻辑
在移动端侧,为了避免大文件音频读取引发的内存溢出,我在 local_music_analysis_service.dart 中实现了一套异步非阻塞的解码管道。系统利用 FFmpegKit 强行切入底层操作系统的音频硬件上下文,编写了精准的 FFmpeg 命令行矩阵,将多声道、高采样率的压缩音频,动态降维解码为单声道、16000Hz 采样率的标准 16bit 小端序 PCM 线性流(WAV 封装):
dart
// 引用自 local_music_analysis_service.dart
Future<String?> _decodeToMonoWav(String inputPath) async {
final dir = await getTemporaryDirectory();
final outputPath = p.join(dir.path, 'transcoded_${DateTime.now().millisecondsSinceEpoch}.wav');
// 🌟 核心工程矩阵:强制降采样 16000Hz,单声道 Mono,阻断式覆盖写入
final ffmpegCommand = '-y -i "$inputPath" -ar $_sampleRate -ac 1 -c:a pcm_s16le "$outputPath"';
final session = await FFmpegKit.execute(ffmpegCommand);
final returnCode = await session.getReturnCode();
if (ReturnCode.isSuccess(returnCode)) {
return outputPath; // 成功向物理沙盒交付纯净的原始多媒体信号源
}
return null;
}这一步下沉基建至关重要。它不仅成功为端侧的轻量级信号初筛提供了数据支撑,更为云端/本地的高阶多模态分析消除了不同音频格式的"语义鸿沟"。
(2) 跨语言核心算法攻坚:基于 Librosa 与 Numpy 的时域能量打卡引擎
当纯净的音频信号流就绪后,上游服务将信号路由至我们核心的 Python 多媒体算法组件 beat_export.py 中。通过 Librosa 的数字信号处理能力与 Numpy 的高维矩阵并行计算加速,开发【节拍点-物理能量双向时间轴对齐算法】。
这套算法不仅能追踪节拍,还能算准每一个节拍敲击下去那一瞬间的均方根能量强度,这直接决定了后期视频生成时"高潮画面切重拍,低谷画面平滑慢推"的运镜灵魂:
python
# 引用自 beat_export.py
def export_advanced_beats(audio_path, output_json):
# 1. 矩阵加载多媒体波形图
y, sr = librosa.load(audio_path)
# 2. 追踪动态节拍时序 (Dynamic Beat Tracking)
tempo, beats = librosa.beat.beat_track(y=y, sr=sr)
beat_times = librosa.frames_to_time(beats, sr=sr)
# 3. 提取时域均方根能量强度 (RMS Energy)
rms = librosa.feature.rms(y=y)[0]
rms_times = librosa.frames_to_time(range(len(rms)), sr=sr)
# 4. 🌟 核心算法:双向时间轴近邻索引比对 (Nearest Neighbor Alignment)
beat_data = []
for t in beat_times:
# 基于 Numpy 的广播机制与向量减法,毫秒级检索与当前节拍点最接近的能量帧索引
idx = (np.abs(rms_times - t)).argmin()
beat_data.append({
"ms": int(t * 1000), # 精确转换为毫秒契约
"energy": float(rms[idx]) # 注入该拍点的绝对物理撞击烈度
})(3) 工程防错与复杂数据类型序列化容灾
在算法落地的最终阶段,我遇到了多媒体计算中极易引发系统崩溃的 "Numpy 类型隐式冲突" 隐形 Bug。Librosa 的算法引擎在计算 BPM 时,其返回值底层包裹为 numpy.float32 类型,当通过 Python 的原生 json.dump 序列化为结构化数据以供 Flutter 前端调用时,系统会因为无法识别第三方高维数学对象而抛出严重异常。
为此,我在线路的最末端设计了精细的数据降维与类型桥接逻辑:
python
# 引用自 beat_export.py
# 🌟 核心修复:通过 np.squeeze 解包并显式强制转换为标准 Python float,确保 JSON 序列化时契约的安全交付
bpm_value = float(np.squeeze(tempo))
output_data = {
"bpm": bpm_value,
"beats": beat_data
}最终,这一套精心设计的数据处理流成功交付了一份完美的、包含 {"ms": ..., "energy": ...} 时序矩阵的标准 JSON 描述文件。
虽然中后期为了应对数十名并发用户的高负载,团队将这套我主导编写的 Python 信号流封装成了云端 FastAPI 微服务进行了算力隔离,但其核心的动态 Mono 解码逻辑、时间轴双向近邻对齐算法以及显式序列化容灾机制完全承袭自 V1.0 原生架构。这组跨语言的多媒体胶水层设计,正是让智能影记真正具备音画通感和智能化视听输出的核心技术底座。
3. 容灾机制:基于多模态语义距离的本地音频资产动态熔断与兜底引擎
在重度依赖 AIGC 服务的多模态移动端应用中,云端服务的稳定度直接决定了用户体验的生死线。由于云端 AI 音乐生成(MusicGen)属于高算力消耗型任务,在实际生产环境中,极易遭遇网络链路抖动、API 频次受限或团队 Token 资产耗尽等物理突发状况。
为了防止系统因外部依赖崩溃而导致用户视频创作流中断,我在 story_video_preparation_service.dart 中增加了【基于多模态语义距离计算的本地音频资产动态熔断与降级兜底引擎】。
这一机制的工程核心交互逻辑如下:
┌─── 链路 A(主线):AI 实时生成 ───> Replicate 云端模型响应
│
[触发音视频生成请求] ─┤
│ ┌─── 匹配情感词簇权重
└─── 链路 B(熔断):本地预置配乐 ─┼─── 召回语义距离最近的资产
└─── 投递至本地 Librosa 解析(1) 非阻塞式多轨状态机与智能熔断策略
在 prepare 执行流水线中,我将音频准备过程设计为非阻塞的状态机路由。当系统检测到网络请求异常、云端返回码非 201、或轮询超时触发时,系统瞬间激活降级熔断机制。此时,应用不会向用户抛出冰冷的"网络错误"弹窗,而是无缝将控制权移交给本地兜底引擎,在主线程零感知的状态下完成素材切换:
dart
// 引用自 story_video_preparation_service.dart
if (request.enableAiMusic) {
onStatus?.call('正在构思 AI 配乐');
try {
// 🌟 主线尝试:调用云端 MusicGen 实时生成专属 BGM
preparedMusicPath = await _musicGenService.generateAndDownloadMusic(
musicPrompt,
duration: 15,
);
} catch (e) {
debugPrint('❌ 云端 AI 音乐生成触发异常,系统启动主动熔断降级: $e');
}
// 🌟 容灾分支:若实时生成失败或路径为空,无缝切入本地高可用兜底引擎
if (preparedMusicPath == null) {
onStatus?.call('正在从本地回忆乐库匹配最佳曲目');
preparedMusicPath = await _fallbackToPremadeMusic(musicPrompt);
}
}(2) 基于语义关键词多维向量距离的智能音频资产检索算法
本地兜底并不是简单地随机播放一首歌曲,那会导致音画情绪的彻底割裂。为了维持多模态"音画合一"的体验,我引入了基于词簇命中权重的语义距离检索算法。
在引擎内部,我预先在客户端资产包(Assets)中封装了四首代表不同情感张力的高保真工业级母带级配乐(欢快明朗的 Sunrise Checkpoint、气势宏大的 Horizons in Motion、感伤怀旧的 Faded Save File 以及治愈放松的 Soft Save Point),并为每首乐曲建立了高维情绪倾向特征词簇。
当云端熔断触发时,算法将大模型生成的 music_prompt 转化为低维语义流,通过在时域上计算词簇交集,智能判定情感偏向:
dart
// 引用自 story_video_preparation_service.dart
// 🌟 核心算法:基于多维情绪词簇命中权重的本地资产召回引擎
final lowerPrompt = musicPrompt.toLowerCase();
final upbeatWords = <String>['cheerful', 'happy', 'bright', 'energetic', 'pop', '欢快', '阳光', '充满活力'];
final cinematicWords = <String>['epic', 'cinematic', 'grand', 'inspiring', 'orchestral', '大气', '史诗', '壮丽'];
final melancholicWords = <String>['sad', 'lonely', 'melancholic', 'emotional', 'nostalgic', '伤感', '孤独', '怀旧'];
final lofiWords = <String>['lo-fi', 'lofi', 'chill', 'cozy', 'relax', 'dreamy', 'warm', '治愈', '放松', '温暖'];
// 通过矩阵式交集计数,量化语义特征距离
final upbeatScore = upbeatWords.where(lowerPrompt.contains).length;
final cinematicScore = cinematicWords.where(lowerPrompt.contains).length;
final melancholicScore = melancholicWords.where(lowerPrompt.contains).length;
final lofiScore = lofiWords.where(lowerPrompt.contains).length;
var assetPath = 'assets/audio/premade/Soft Save Point.mp3'; // 默认治愈系兜底
var maxScore = 0;
if (upbeatScore > maxScore) { maxScore = upbeatScore; assetPath = 'assets/audio/premade/Sunrise Checkpoint.mp3'; }
if (cinematicScore > maxScore) { maxScore = cinematicScore; assetPath = 'assets/audio/premade/Horizons in Motion.mp3'; }
if (melancholicScore > maxScore) { assetPath = 'assets/audio/premade/Faded Save File.mp3'; }
// 最终输出最符合当前影像故事画风的本地音频资产(3) 闭环交付:本地资产的物理沙盒释放与信号重解析
选定本地资产后,由于 Flutter 的 rootBundle 资源无法直接被底层的 C++/FFmpeg 解码器以物理路径形式读取,我们还编写了一套资产动态释放与中继分发逻辑 :将包内音频以二进制数据流形式读出,静默写入手机的临时沙盒空间,再重新投递至此前搭建的 MusicService.analyzeAudio(Librosa 分析引擎)。
这确保了即便是使用本地兜底配乐,系统依然能够拿到绝对精准的物理节拍和能量 JSON 矩阵,保障了后续视频生成中"画面卡点转场"的核心视觉效果完全不受影响。这一套闭环的容灾架构设计,在极端弱网环境下为《智能影记》提供了业务连续性保障,展现了移动端应用应有的鲁棒性与高可用范式。
六、 高可用标题生成
作为功能闭环的先锋模块,智能检索与多模态内容装配是本项目的核心技术壁垒。我设计并开发了基于"端云协同"的语义搜图引擎与高可用标题生成系统,完成了系统核心创作链路的"冷启动"与数据流容错。
1. 攻坚数据断层:解决跨相册勾选的"上下文饥饿"问题
随着项目推进,我们遇到了一个移动端 AI 应用的核心痛点:当用户从对话搜索或跨相册随意手动勾选照片进入视频配置页(ConfigPage)时,由于缺乏连续的事件上下文,照片的 AI 视觉标签往往在顶层组件传递中丢失或尚未异步计算完成。这直接导致云端大模型因为遭遇"上下文饥饿",只能凭空幻觉或返回干瘪的默认标题。
为了解决这一技术瓶颈,我在 story_config_page.dart 中重构了多模态数据装配管道:
dart
// 优先提取 AI 描述或 OCR 摘要;若遭遇完全没有经过 AI 标签分析的"白板数据",
// 则强制降维提取其底层的物理元数据(时间和高德逆地址解析位置)作为上下文养分补偿。
final dynamicContext = photos.map((p) {
return {
'time': p.timestamp,
'location': p.location ?? '未知地点',
'tags': p.aiTags.isNotEmpty ? p.aiTags : [p.poiAddress ?? ''],
};
}).toList();这一重构从源头上阻断了数据丢失,确保了喂给大模型的 Prompt 拥有充足的结构化数据养分,即便在未获取完整视觉标签的极端情况下,大模型也能精准提炼出诸如"济南万象城的初夏食光"这类具备高度时空特征的优质艺术标题。
2. 健壮性防线:基于启发式位置词频统计的本地熔断降级策略
在移动端 AI 落地时,我们必须考虑到弱网、断网或云端 API 接口限流等极端突发状况。为了践行工业级应用的鲁棒性,我为标题生成模块设计了严格的"双轨高可用降级策略":
- 主轨(云端 LLM 提炼) :当网络通畅时,系统调用
LLMService().generateCreativeTitles,传入装配好的多模态上下文,动态生成"1个主标题 + 3个副标题候选"的文艺文案集。 - 备轨(本地启发式推断) :一旦云端接口抛出网络异常或返回为空,系统立即触发
catch机制,在几毫秒内无缝降级到我编写的本地静态启发式推断算法(_deriveSmartTheme与_deriveSmartSubtitle)。
在本地兜底算法中,引入基于地理位置与时间跨度的词频拓扑统计逻辑 。即使在完全断网的环境下,系统依然能通过对选中照片队列的 location 元数据进行逆向高频词聚类,自动推断出用户的核心活动中心,实现主线程零阻塞的无感智能兜底:
dart
// 基于位置词频统计的本地核心主题 (Title) 兜底策略逻辑
String _deriveSmartTheme() {
if (widget.selectedPhotos.isNotEmpty) {
final locationCounts = <String, int>{};
// 启发式扫描:统计勾选序列中出现频率最高的地理 POI 锚点
for (var photo in widget.selectedPhotos) {
if (photo.location != null && photo.location != '未知地点') {
locationCounts[photo.location!] = (locationCounts[photo.location!] ?? 0) + 1;
}
}
// 找出词频最高的重心位置
if (locationCounts.isNotEmpty) {
final mostFrequentLocation = locationCounts.entries
.reduce((a, b) => a.value > b.value ? a : b).key;
return "漫步 · $mostFrequentLocation 的影像纪实"; // 本地算法自适应拼装
}
}
return "${DateTime.now().year}年 · 岁时的光影留念"; // 终极静态降级兜底
}通过这种云端深度泛化创写与端侧启发式词频聚类双轨并存的容灾设计,我为系统的"内容生成配置链"构建了一道坚不可摧的防线,确保了用户无论在何种极端环境下点击创建,都能获得极具品质感和逻辑一致性的回忆主题大纲。
七、 多模态音视频合成导出:基于 Flutter 图形管线的实时卡点渲染引擎
如何将前面清洗出的照片元数据、大模型创写的分镜脚本、以及 Librosa 抽取的物理节拍 JSON 矩阵融会贯通,渲染成一出"音画共振、视听合一"的回忆大片,是整个系统的核心功能与挑战。
作为视频生成与动态渲染模块的负责人,我并没有采用传统的、在端侧极易引发耗时卡顿甚至 OOM 崩溃的后台二进制硬编码生成方案,而是使用【基于状态驱动的端侧组件级非线性动画实时渲染引擎】。在 story_video_page.dart 中,我通过充分压榨 Flutter 的响应式状态机与底层图形管线,实现了白盒化的高清运镜与毫秒级转场卡点。
1. 实时视听引擎的核心交互拓扑与非线性数据流
该引擎的工程核心在于实现了"时序驱动的表现层级联动态变化"。它不再是死板的线性播放器,而是一个以音频时间戳为单一真相源、高度自适应的实时图形渲染管线:
┌──> [AudioPlayer] 物理音频纳秒级进度回调 (Position)
│
[MusicService 节拍描述 JSON] ┼──> [时序控制器] 映射当前音乐所处的区间分镜 (CurrentSection)
│
└──> 驱动 [Widget 渲染树] ───────┬──> 转场与动态加权滤镜
├──> 智能人脸焦点 Ken Burns 运镜
└──> 粒子与多态故障特效在系统生命周期内,多维数据通过以下链路在主线程非阻塞地流转响应:
- 音频物理时钟对齐 :通过
audioplayers插件接管底层硬件音频流,将音频的onPositionChanged定时器作为整个 Widget 树的"心跳总线"(时钟源),消除传统动画时钟在低配机型上因掉帧导致的音画不同步问题。 - 分镜状态路由映射 :在节拍总线驱动下,系统动态计算当前毫秒数所匹配的
StorySection分镜卡片。每一个分镜卡片不仅包含图片路径,还包含了我此前装配好的大模型文案剧本及特效权重。 - 响应式 Widget 渲染树组件高频刷新:将每一帧的几何缩放、模糊度、抖动因子全部转化为状态驱动,交由底层渲染管线在 60fps/120fps 规格下进行流畅的逐帧绘制。
2. 全自研视觉特效矩阵引擎的核心算法
为了给用户提供极具电影感和治愈感的视听体验,我从底层深入图形学原理,编写了四种高表现力的特效组件,并将其内聚封装在系统渲染层中:
(1) 赛博朋克故障艺术组件(GlitchEffect):基于伪随机数与色差分离的撕裂算法
当 Librosa 检索到音频进入重低音或情绪激昂的重拍瞬态时,系统会迅速调高强度阀门,触发我编写的故障特效。这一组件在 Dart 层完美复刻了高级 GPU 编译级着色器的渲染逻辑:
- 色彩通道分离 :如代码所示,当节拍能量突变时,我利用
ColorFiltered的BlendMode.modulate滤镜,将画面强行拆解为红色等独立分量,并通过Transform.translate施加基于能量烈度加权的横向位移偏移量(rgbOffset),在边缘渲染出极其逼真的光学色散重影特效。 - 横向块状位移撕裂 :利用时域信号
time作为伪随机数种子复刻了 GLSL 的hash函数,配合自定义裁剪器_GlitchBandClipper对原图进行像素级的高清横向切片,并施加非对称的错位推移(bandShift),完美呈现了数字时代的故障艺术美学:
dart
// 引用自 glitch_effect.dart 核心撕裂片段
if (showBand)
Positioned.fill(
child: ClipPath(
clipper: _GlitchBandClipper(bandTop, bandHeight), // 切出横向条带
child: Transform.translate(
offset: Offset(bandShift, 0), // 施加横向随机错位
child: child, // 撕裂部分依然是原图的高清切片
),
),
);(2) 胶片质感色彩引擎(StaticFilters):基于 4 × 5 4\times5 4×5 高维颜色特征矩阵乘法的动态重映射
为了赋予不同回忆故事不同的情绪底色(如经典黑白、赛博朋克、清透少女风),我编写了一套高性能色彩滤镜引擎。
- 高维矩阵重采样 :不使用性能低下的像素点遍历,而是直接将每种风格抽象为一个 4 × 5 4\times5 4×5 的高维颜色变换变换矩阵。
- 饱和度叠加叠加算法 :设计
_multiplyMatrices矩阵乘法函数,将动态饱和度系数矩阵(_getSaturationMatrix)与风格特征矩阵进行无缝的二维矩阵内积运算 ,最后一步投递给底层的ColorFilter.matrix。这使得系统能够在硬件加速级别(Hardware Acceleration)以 0ms 的延迟完成整幅画面的色彩空间重映射与边缘暗角暗化,避免移动端实时调色的性能损耗。
dart
// 引用自 static_filters.dart 的颜色矩阵乘法核心算法
List<double> _multiplyMatrices(List<double> a, List<double> b) {
final result = List<double>.filled(20, 0);
for (int i = 0; i < 4; i++) {
for (int j = 0; j < 5; j++) {
result[i * 5 + j] = a[i * 5 + 0] * b[0 * 5 + j] +
a[i * 5 + 1] * b[1 * 5 + j] +
a[i * 5 + 2] * b[2 * 5 + j] +
a[i * 5 + 3] * b[3 * 5 + j] +
(j == 4 ? a[i * 5 + 4] : 0.0);
}
}
return result;
}(3) 治愈系云朵自绘制画布(CloudBorderEffect):基于数学正余弦拓扑的高可用毛边遮罩
针对"治愈风"和"暖心回忆"场景,我利用 Flutter 的 CustomPaint 在画布上启动了纯数学自绘制逻辑。
- 数学几何拓扑 :利用正弦(
cos)与余弦(sin)几何公式,结合循环内的伪随机哈希抖动,计算出一组动态扩展的圆形簇拓扑中心点坐标(positions)与半径(radii)。 - 拟真呼吸缓动 :组件绑定了一个 10 秒一个周期的无限循环动画控制器,驱动云朵边缘像真实生物一样进行平滑的呼吸缓动(
breathe),并通过IgnorePointer实现了防点击穿透的防御性编程。配合多层带有模糊半径的浅紫阴影绘制,渲染出了极具空气感和梦幻感的动态相框边缘,为后续的视频播放提供了绝佳的内容容器。
(4) 时域分层字幕渲染器(SubtitleEffectLayer):防前端溢出的防御性编排
在文字和分镜剧本的呈现上,我编写了 SubtitleEffectLayer。该组件能够根据大模型装配出的多模态上下文,动态选择 standard、hero 或带有历史文本快照缓存的 layered 动效。
- 溢出物理防御 :在顶层字幕组件渲染中,使用如下包裹策略:利用
FittedBox的BoxFit.scaleDown约束,配合ShaderMask赋予字幕高级的渐变艺术质感。这一设计不仅还原了 Figma 设计图中文字的中轴排版美学,更从物理上彻底隔绝了大模型生成旁白文案过长时极易引爆移动端的"界面溢出爆红"报错,保障了系统整体在答辩演示与结题测试时的高可用性。
3. 所见即所得的白盒实时控制与离线合成底座
这套高度内聚的全自研 VFX 特效矩阵引擎具备架构优越性------由于整个系统的运镜、滤镜、节拍卡点完全是由我设计的状态机和 Widget 树在端侧白盒实时渲染 的,这使得系统天然支持"横竖屏动态切换路由(isHorizontal)"、"音量局部独立反转"以及"所见即所得的编辑快照变更"。通过这种设计,用户在主控台上的每一次微调,UI 都会在毫秒级给予高流畅度的视觉反馈。
4. 底层多媒体管线攻坚:基于动态离屏通道的异步静默音视频合成与高保真封包(基于 OffscreenRenderWorker)
在移动边缘端进行高分辨率音视频离线合成时,传统的黑盒硬编码方案极易遭遇双重物理瓶颈:一是由于高频抓取屏幕纹理导致原生主线程被长时间霸占,引发界面彻底假死;二是旧机型芯片在面对复杂的转场动画与实时滤镜叠加时,FFmpeg 的多媒体编解码帧率会断崖式下跌。
为了攻克这一行业技术痛点,我在 offscreen_render_worker.dart 中增加了【基于动态离屏通道(Offscreen Canvas Boundary)的异步静默音视频合成管线】。
这一机制打破了硬件算力的锁链,其核心工程设计如下:
(1) 线程隔离与"白盒离屏纹理捕捉"架构设计
这个功能没有在前台盲目阻塞渲染,而是利用 Flutter 的 RepaintBoundary 在物理屏幕之外开辟了一个隐式虚拟渲染通道 。在后台 Worker 异步状态机的调度下,音乐节拍时钟被精准转换为离散的帧步进器。
系统将前述全自研的 GlitchEffect(故障撕裂)、StaticFilters(色彩矩阵变换)等高阶特效组件整体挂载在这个离屏通道内,在主线程完全无感知的状态下,逐帧驱动底层 Skia/Impeller 绘图引擎进行像素级离屏渲染:
dart
// 引用自 offscreen_render_worker.dart 核心离屏帧捕获流水线
Future<void> _startRenderWorkflow() async {
// 1. 初始化高保真跨平台视频编码器参数 (1080P, 60FPS)
await FlutterQuickVideoEncoder.setup(
width: 1080, height: 1920, fps: 60,
videoBitrate: 8000000, audioBitrate: 128000,
sampleRate: 44100,
);
// 2. 🌟 核心离屏像素抓取循环 (Offscreen Repaint Boundary Capture)
for (int frame = 0; frame < totalFrames; frame++) {
// 强制驱动后台 Widget 树状态演进至当前时间戳
_driveTimelineToFrame(frame);
await Future.delayed(const Duration(milliseconds: 16)); // 严格帧同步机制
// 捕获离屏边界的 RenderRepaintBoundary 对象
RenderRepaintBoundary boundary = _boundaryKey.currentContext!.findRenderObject() as RenderRepaintBoundary;
ui.Image image = await boundary.toImage(pixelRatio: 2.0); // 2倍超采样抗锯齿
ByteData? byteData = await image.toByteData(format: ui.ImageByteFormat.rawRgba);
// 3. 将解包出的原始 RGBA 像素矩阵流实时投递给底层编码器封装
if (byteData != null) {
await FlutterQuickVideoEncoder.appendVideoFrame(byteData.buffer.asUint8List());
}
}
}(2) 智能静默导出与全生命周期资源交付逻辑
由于在旧手机等目标机型上,即使优化了硬件级编解码参数,纯硬件合成速度依然存在物理限制。因此,我引入了异步静默挂起策略。
在离屏渲染期间,前台通过一个优雅的微调控制台维持正常响应,而后台 Worker 则默默压榨闲时算力。当最后一步 appendAudioFrame 音频轨无损混合封包完成,并调用 Gal.putVideo 将成片交付至系统原生相册后,系统会在第一时间触发通知级唤醒状态机,自动弹窗激活结题交付的最后一公里------跨平台社交分发页。
5. 社交生态分发:多模态文案创写与多态自适应分享引擎(基于 PublishPage)
为了打通从"内容智能创作"到"社交场景分发"的最后一公里,践行我们在《项目实训任务书》中承诺的"导出分享功能实现",我搭建了多态社交分享中枢 publish_page.dart。
这一模块的核心含金量在于实现了将视听故事内容与云端 LLM 情感文案的深度矩阵对齐:
┌──> 风格 A:小红书调性 (自带 emoji,标签堆叠)
│
[导出的视频路径 + 媒体上下文] ─┼──> 风格 B:朋友圈文案 (精致克制,人文温度)
│
└──> 投递至 [SharePlus 动态组件] ──> 一键拉起系统级原生成片分享(1) 基于大模型语义泛化的跨平台文案"风格矩阵"定制
在 PublishPage 的初始化生命周期中,客户端会承接上游传递的视频主题线索。此时,系统调用云端 LLM 发起非阻塞网络请求,根据用户勾选的特定社交平台调性,动态转换文本风格:
- 小红书轨 :Prompt 强力约束模型在输出时自动穿插高频语义关联的 Emoji 表情,并在文案最末端自动堆叠诸如
#记录生活#氛围感Vlog等热门拓扑标签,实现高点击率引流。 - 朋友圈轨:自动命令模型进行字数裁剪与情感提炼,剔除冗余标签,产出极具人文温度与克制内敛的文案,满足熟人社交的信任表达。
(2) 防御性粘贴与跨平台组件级原子拉起
在界面交互上,我使用 TextEditingController 对大模型动态返回的文案进行了全白盒化内聚展示,用户可自由进行二次润色。为了保障交互的极简体验,我编写了双轨分发逻辑:
- 一键剪贴板同步(防漏复制容灾) :点击分享按钮时,系统静默调用
Clipboard.setData,将当前文本框内的最终文案强行打入操作系统全局剪贴板,彻底免去了用户跨 App 切换时手动长选复制的心智负担。 - 系统级原生成片交付 :随后,利用封装好的
share_plus组件,通过安全的沙盒路径中继,直接一键拉起 Android/iOS 原生系统的跨App分享面板,精准投递至对应平台的编辑框。这一整套高度流畅、容错性极强的分享闭环交互,真正让影像管理系统的资产沉淀走向了情感流动。
八. 多模态 Agent 演进:基于全局智能体的多轮交互与意图路由搜图引擎
随着系统"搜、排、谱、演"核心骨架的彻底闭环,我并没有止步于传统的"搜索框-查表"式被动交互。为了赋予系统真正的叙事灵魂与人文温度,我利用中期开发的底层多模态 Infra,在系统全局增加了一个【基于多轮对话的全局 AI 记忆助理系统】。
与传统的硬编码精确搜索框不同,该智能体能够允许用户以极度抽象、随性的自然语言(如 "推荐一些适合今天的治愈系照片" 、"看看刚才聊到的那次聚会")进行多轮深度盲聊,并通过动态意图路由主动调起端侧数据库进行智能召回,实现了从"被动工具"向"主动多模态智能体"的体验跃迁。
1. 智能体意图路由与"动态工具调用"机制
为了实现"边聊边搜"的丝滑体验,我设计了一套高内聚的 Prompt 拓扑结构。将底层的向量检索与级联过滤抽象为大模型的原生插件工具。当用户输入任意文本时,云端模型作为"中央处理器"首先进行语义解析,若判定用户包含潜在的搜图意图,必须通过特定的结构化标签(如 <SEARCH>{"month": 5}</SEARCH>)进行行为输出,由客户端解析器拦截并转化为 Isar 的物理查询操作:
dart
// 🌟 核心技术攻坚:压制大模型在多轮闲聊中的"偷懒幻觉"
final reinforcedUserText = '''
[系统严格指令:你现在拥有调用相册搜索的能力。如果用户在多轮对话中流露出找照片的意图,
你必须在其回复最末端强制追加标准的 <SEARCH> 格式标签。严禁遗漏!当前季节与高频标签为:$currentContext]
''';
messages.add({'role': 'user', 'content': reinforcedUserText});这一工程设计成功解决了大模型在中后期多轮复杂闲聊中极易触发的"意图遗漏"痛点,提高智能体工具调用稳定性。
2. 时空维度的经典排错:10位与13位时间戳精度的"血案"破案纪实
在打通 Agent 智能搜图链路的测试过程中,我遭遇了一个极其隐蔽的底层 Bug:当 AI 助理精准识别了搜图意图并抛出按月份检索(如"寻找春天的照片")的正确指令时,底层的 Isar 级联查询引擎却高频返回空列表。
我通过挂载物理断点、追踪底层多媒体元数据流水线,最终揪出了这个多端协作中经典的"时间戳精度断层"引发的血案:
- Bug 根源 :iOS/Android 原生相册在读取部分历史影像时,EXIF 库返回的是 10 位(秒级) 的时间戳;而 Flutter 框架层及部分新拍照片生成的则是 13 位(毫秒级) 时间戳。当 Dart 层的
DateTime.fromMillisecondsSinceEpoch强行吞噬 10 位时间戳时,会发生严重的数学降维,导致所有历史照片被错误解析为 1970 年的元旦,从而使得后置的.month时间轴过滤器全盘崩溃。 - 架构级工程修复:我在内存精细过滤与持久化同步的交界处,下沉了一套时间转换兼容夹层。对所有入库及检索的时序信号实施防溢出判定,从底层彻底熔断了精度冲突,保障了智能体跨时空搜图检索的精准性:
dart
// 内存级时空数据精细清洗兼容片段
int对齐时间戳(int rawTimestamp) {
// 🌟 动态位长判定:若低于13位,通过乘积 1000 隐式无损升维补齐至毫秒级
if (rawTimestamp.toString().length < 13) {
return rawTimestamp * 1000;
}
return rawTimestamp;
}通过这一套全局悬浮 AI Agent 交互网络、Prompt 意图熔断机制、以及底层时空元数据清洗夹层的有机结合,成功为智能影记安装了一颗具备常识理解力与主动陪伴价值的"数字大脑"。
九、 规范化工程交付:软件工程全套文档矩阵提纯与 AE 高保真功能演示短片设计
一个标准的工业级软件项目在迈向结题验收时,不仅需要代码层面的稳定运行,更需要一套结构严谨、逻辑闭环的全套数字化工程资产矩阵。在项目的基础开发与多模态核心渲染管线彻底闭环后,为了确保系统在最终答辩中展现出最高规格的工业成熟度,我统筹并主导了整个《智能影记 - Memoria》项目从底层技术文档工程到高品质视觉媒体交付(AE 演示视频)的全生命周期质量把控。
这一阶段的规范化工程交付,不仅是项目功能完成度的最佳横截面展示,更是对我们团队全栈工程落地能力的终极验证:
1. 结构化数字资产:全套可考核、可量化软件工程文档矩阵的统筹编纂
根据验收要求,我们团队拒绝了形式主义的文档堆砌,严格按照敏捷开发各阶段的真实技术反馈,统筹完成了以下四大核心技术文档的闭环编纂:
-
《项目开发文档》:该文档是我投入大量精力的核心工程资产。全文由我亲自统筹目录搭建与契约规范,详尽收录了从 Clean Architecture 分层架构设计、异构计算异构推理底座、到基于 Isar 和 ObjectBox 的"业务真相层 + 向量索引层"分离的双存储数据库 ER 图与表结构设计说明,为系统全链路功能提供了唯一的事实技术标准。
-
《技术研究报告》与《作品创新性分析报告》 :在这两份文档中,我们深度提炼了本项目沉淀的单机版端侧异构推理范式。重点论证了 MobileCLIP2 文本编码链路在移动端旧版 ONNX Runtime 缺失部分算子时的 Graph Emulation(计算图等价重写) 数学等价替代算法,以及基于 Russell 情感双环模型和多维词频统计的本地自适应熔断技术,在学术和工程双重层面上坐实了系统的创新壁垒。
-
《项目测试文档》:为了把控最终交付质量,团队编写了严密的边界条件测试用例库。文档包含针对 48 个高负载样本进行压力测试的自动化探针报告,量化求证了系统在端侧 AI 推理状态下,平均推理耗时(164.4 ms)完全达标、内存显存轮转释放机制完美跑通、OOM 崩溃率为 0% 的高可用性指标,形成了客观可靠的白盒化性能画像。
2. 视觉化媒体交付:基于 After Effects (AE) 的高保真系统演示短片主控设计
在软件工程的高规格交付中,一段"直击痛点、视听对齐、技术透明"的演示视频往往比单纯的文字更具说服力。为此,我充分发挥全栈管理者的角色,亲自动手利用 Adobe After Effects (AE) 制作了系统最终的高保真功能展示纪录片。
演示视频的特效与运镜转场编排中同样贯彻了本系统"音画合一"的设计灵魂:
-
三位一体视听卡点剪辑:将演示短片的背景 BGM 拖入 AE 时域轨道,通过精确提取音频的能量波峰,让视频的每一个切屏、文字淡入和 UI 放大完全卡在重音鼓点上,用极具专业律动感的视听冲击力锁定评委老师的注意力。
-
多模态核心技术点白盒化可视化:在表现搜图、Agent 聊天及音视频生成等重度 AI 模块时,我设计了精美的包装动画。当视频演示在手机界面输入自然语言时,AE 画面会同步向外流式弹出高维特征向量计算、高德逆地理逆向拓扑词频、以及 Librosa 短时傅里叶变换的动态数学图表。这种"技术逻辑透明化"的视觉呈现,生动展现了产品从"无感数据净洗"到"主动式回忆找人"的无脑极简操作。