目录
可变模板参数
可变模板参数是C++11中新增的一个特性,它对参数高度泛化,能够让我们创建可以接受可变参数的函数模板和类模板。在C++11之前,类模板和函数模板中只能包含固定数量的模板参数,可变模板参数无疑是一个巨大的改进,但由于可变参数模板比较抽象,因此使用起来需要一定的技巧
在C++11之前其实也有可变参数的概念,比如printf函数就能够接收任意多个参数,但这是函数参数的可变参数,并不是模板的可变参数
1.基本语法
C++11⽀持可变参数模板,也就是说⽀持可变数量参数的函数模板和类模板,可变数⽬的参数被称 为参数包,存在两种参数包:模板参数包,表⽰零或多个模板参数;函数参数包:表⽰零或多个函 数参数。
cpp
template <class ...Args> void Func(Args... args) {}
template <class ...Args> void Func(Args&... args) {}
template <class ...Args> void Func(Args&&... args) {}我们用省略号来指出一个模板参数或者函数参数表示一个包,在模板参数列表中class ...或者template...表示接下来的参数表示多个或者零个参数,函数参数列表中类型名在函数参数列表中,类型名后⾯跟...指出 接下来表⽰零或多个形参对象列表;函数参数包可以⽤左值引⽤或右值引⽤表⽰,跟前⾯普通模板 ⼀样,每个参数实例化时遵循引⽤折叠规则。
函数可变列表是去实例化多个不同参数的函数模板,在实现对应类型的参数。
这⾥我们可以使⽤sizeof...运算符去计算参数包中参数的个数。
sizeof...在这里已经变成计算参数包内参数个数的函数
cpp
template <class ...Args>
void Print(Args&&... args)
{
cout << sizeof...(args) << endl;
}
int main()
{
double x = 2.2;
Print(); // 包⾥有0个参数
Print(1); // 包⾥有1个参数
Print(1, string("xxxxx")); // 包⾥有2个参数
Print(1.1, string("xxxxx"), x); // 包⾥有3个参数
return 0;
}2.包扩展
对于一个参数包我们除了计算包内参数的个数还要使用里面的参数,为了使用里面的参数就需要进行包扩展。扩展一个包就是将他分解为构成的元素,对每个元素应用模式,获的扩展后的列表。
C++还⽀持更复杂的包扩展,直接将参数包依次展开依次作为实参给⼀个函数去处理。
cpp
using namespace std;
void Showlist()
{
cout << endl;
}
template<class T,class... Arges>
void Showlist(T&& t, Arges... arges)
{
cout << t<<" ";
Showlist(arges...);
}
template <class ...Args>
void Print(Args... args)
{
Showlist(args...);
}
int main()
{
Print();
Print(1);
Print(1, string("xxxxx"));
Print(1, string("xxxxx"), 2.2);
return 0;
}
注意:函数参数为0的函数不能删去,因为包扩展是函数编译时生成的,如果改成在Showlist函数中加入if(sizeof...(arge...)==0)return ;是运行时两者不同
还有另外通过函数递归实现包扩展的方式
cpp
using namespace std;
template <class T>
const T& GetArg(T&& t)
{
cout << t << " ";
return t;
}
template<class...Arges>
void Arguements(Arges... arges)
{}
template <class ...Args>
void Print(Args&&... args)
{
Arguements(GetArg(args)...);
}
int main()
{
Print();
Print(1);
Print(1, string("xxxxx"));
Print(1, string("xxxxx"), 2.2);
return 0;
}本质可以理解为编译器编译时,包的扩展模式
3.empalce系列接⼝
cpp
template <class... Args> void emplace_back (Args&&... args);
template <class... Args> iterator emplace (const_iterator position,
Args&&... args);C++11以后STL容器新增了empalce系列的接⼝,empalce系列的接⼝均为模板可变参数,功能上 兼容push和insert系列,但是empalce还⽀持新玩法,假设容器为container<T>,empalce还⽀持直接插⼊构造T对象的参数 ,这样有些场景会更⾼效⼀些,可以直接在容器空间上构造T对象。
传递参数包过程中,如果是 Args&&... args 的参数包,要⽤完美转发参数包,⽅式如下 std::forward(args)... ,否则编译时包扩展后右值引⽤变量表达式就变成了左值。
cpp
#include<list>
// emplace_back总体⽽⾔是更⾼效,推荐以后使⽤emplace系列替代insert和push系列
int main()
{
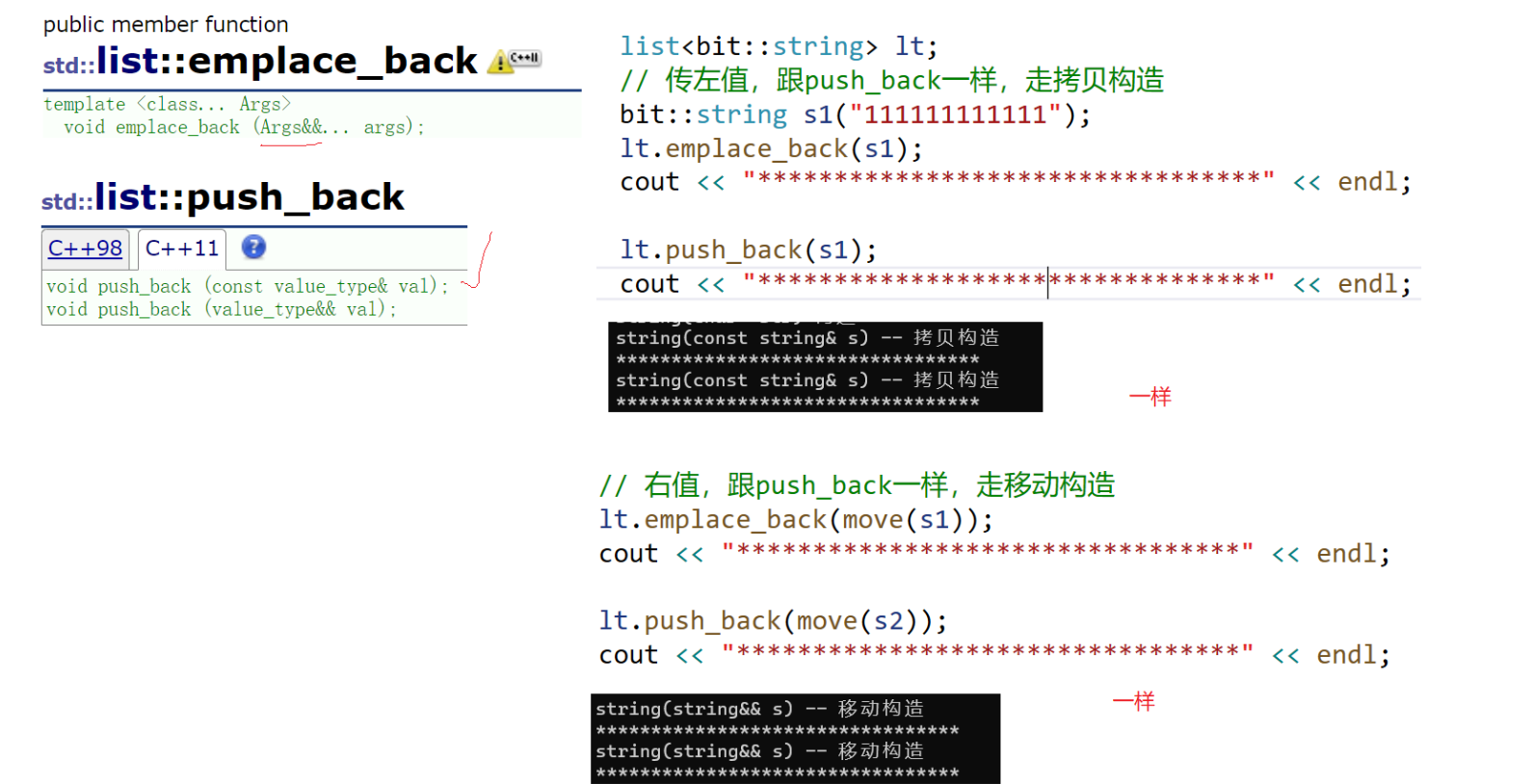
list<bit::string> lt;
// 传左值,跟push_back⼀样,⾛拷⻉构造
bit::string s1("111111111111");
lt.emplace_back(s1);
cout << "*********************************" << endl;
// 右值,跟push_back⼀样,⾛移动构造
lt.emplace_back(move(s1));
cout << "*********************************" << endl;
// 直接把构造string参数包往下传,直接⽤string参数包构造string
// 这⾥达到的效果是push_back做不到的
lt.emplace_back("111111111111");
cout << "*********************************" << endl;
list<pair<bit::string, int>> lt1;
// 跟push_back⼀样
// 构造pair + 拷⻉/移动构造pair到list的节点中data上
pair<bit::string, int> kv("苹果", 1);
lt1.emplace_back(kv);
cout << "*********************************" << endl;
// 跟push_back⼀样
lt1.emplace_back(move(kv));
cout << "*********************************" << endl;
////////////////////////////////////////////////////////////////////
// 直接把构造pair参数包往下传,直接⽤pair参数包构造pair
// 这⾥达到的效果是push_back做不到的
lt1.emplace_back("苹果", 1);
cout << "*********************************" << endl;
return 0;
}
 总体而言:emplace接口系列兼容push和insert系列的功能,但部分场景下emplace是直接构造而insert和push是构造加移动构造或者构造加拷贝构造,emplace性能更好,更推荐使用。
总体而言:emplace接口系列兼容push和insert系列的功能,但部分场景下emplace是直接构造而insert和push是构造加移动构造或者构造加拷贝构造,emplace性能更好,更推荐使用。
lambda函数
1.基本语法
1.lambda 表达式本质是⼀个匿名函数对象,跟普通函数不同的是他可以定义在函数内部。 lambda 表达式语法使⽤层⽽⾔没有类型,所以我们⼀般是⽤auto或者模板参数定义的对象去接 收 lambda 对象。
2.lambda表达式的格式: capture-list (parameters)-> return type { function boby };
3.capture-list捕捉列表:该列表总是出现在 lambda 函数的开始位置,编译器根据\[\]来判断接下来的代码是否为 lambda 函数,捕捉列表能够捕捉上下⽂中的变量供 lambda 函数使 ⽤,捕捉列表可以传值和传引⽤捕捉。
4.(parameters) :参数列表,与普通函数的参数列表功能类似,如果不需要参数传递,则可以连 同()⼀起省略。
5.->return type :返回值类型,⽤追踪返回类型形式声明函数的返回值类型,没有返回值时此 部分可省略。⼀般返回值类型明确情况下,也可省略,由编译器对返回类型进⾏推导。
6.{function boby} :函数体,函数体内的实现跟普通函数完全类似,在该函数体内,除了可以使⽤其参数外,还可以使⽤所有捕获到的变量,函数体为空也不能省略。
2.捕捉列表
1.lambda 表达式中默认只能⽤ lambda 函数体和参数中的变量,如果想⽤外层作⽤域中的变量就需要进⾏捕捉,lambda函数通过捕捉列表捕捉外层变量的方式共有三种:
1.在捕捉列表中显示的传值捕捉和传引用捕捉,捕捉的变量用逗号隔开
例如:a,b,\&z,a,b是传值捕捉,z是传引用捕捉
2 .在捕捉列表中隐示捕捉,=是隐示值捕捉,\&是隐式引用捕捉,这样我们在lambda函数中调用了那些外部变量,编译器就可以捕捉那些变量。
3.显示捕捉和隐式捕捉混合使用,例如\&,a,b表示a,b变量是值捕捉,其他变量是引用捕捉,=,\&a同理a是引用捕捉,其他变量是值捕捉,当使⽤混合捕捉时,第⼀个元素必须是 &或=,并且&混合捕捉时,后⾯的捕捉变量必须是值捕捉,同理=混合捕捉时,后⾯的捕捉变量必 须是引⽤捕捉。
2.lambda函数可以捕捉在lambda函数之前定义的变量,并且全局变量和静态局部变量不需要捕捉,同时也意味着在lambda定义在全局时捕捉列表必须为空。
3.捕捉列表中的变量默认是被const修饰的,传值捕捉的元素即在lambda函数中不可改变,在参数列表后加mutable可以改变常量性,也就说使⽤该修饰符后,传值捕捉的对象就可以修改了,但是修改还是形参对象,不会影响实参。使⽤该修饰符后,参数列表不可省略(即使参数为空)。
cpp
int x = 0;
// 捕捉列表必须为空,因为全局变量不⽤捕捉就可以⽤,没有可被捕捉的变量
auto func1 = []()
{
x++;
};
int main()
{
// 只能⽤当前lambda局部域和捕捉的对象和全局对象
int a = 0, b = 1, c = 2, d = 3;
auto func1 = [a, &b]
{
// 值捕捉的变量不能修改,引⽤捕捉的变量可以修改
//a++;
b++;
int ret = a + b;
return ret;
};
cout << func1() << endl;
// 隐式值捕捉
// ⽤了哪些变量就捕捉哪些变量
auto func2 = [=]
{
int ret = a + b + c;
return ret;
};
cout << func2() << endl;
// 隐式引⽤捕捉
// ⽤了哪些变量就捕捉哪些变量
auto func3 = [&]
{
a++;
c++;
d++;
};
func3();
cout << a << " " << b << " " << c << " " << d << endl;
// 混合捕捉1
auto func4 = [&, a, b]
{
//a++;
//b++;
c++;
d++;
return a + b + c + d;
};
func4();
cout << a << " " << b << " " << c << " " << d << endl;
// 混合捕捉1
auto func5 = [=, &a, &b]
{
a++;
b++;
/*c++;
d++;*/
return a + b + c + d;
};
func5();
cout << a << " " << b << " " << c << " " << d << endl;
// 局部的静态和全局变量不能捕捉,也不需要捕捉
static int m = 0;
auto func6 = []
{
int ret = x + m;
return ret;
};
// 传值捕捉本质是⼀种拷⻉,并且被const修饰了
// mutable相当于去掉const属性,可以修改了
// 但是修改了不会影响外⾯被捕捉的值,因为是⼀种拷⻉
auto func7 = [=]()mutable
{
a++;
b++;
c++;
d++;
return a + b + c + d;
};
cout << func7() << endl;
cout << a << " " << b << " " << c << " " << d << endl;
return 0;
}3.基本原理
lambda 的原理和范围for很像,编译后从汇编指令层的⻆度看,压根就没有 lambda 和范围for 这样的东西。范围for底层是迭代器,⽽lambda底层是仿函数对象,也就说我们写了⼀个 lambda 以后,编译器会⽣成⼀个对应的仿函数的类 。 仿函数的类名是编译按⼀定规则⽣成的,保证不同的 lambda⽣成的类名不同,lambda参数/返 回类型/函数体就是仿函数operator()的参数/返回类型/函数体, lambda 的捕捉列表本质是⽣成 的仿函数类的成员变量,也就是说捕捉列表的变量都是 lambda 类构造函数的实参,当然隐式捕捉,编译器要看使⽤哪些就传那些对象。
3.C++11新增
1.默认的移动构造和移动赋值
在C++中原本有六个默认成员函数:构造函数、析构函数、拷贝构造、赋值运算符重载、取地址重 载、const取地址重载。默认成员函数就是我们不写编译器会自己生成的函数,在C++11中新增了移动构造和移动赋值运算符重载。
**如果没有主动生成移动构造,且析构函数、拷贝构造、赋值运算符重载都没有生成则编译器会自己生成默认移动构造,**默认⽣成的移动构造函数,对于内置类型成员会执 ⾏逐成员按字节拷⻉,⾃定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调⽤ 移动构造,没有实现就调⽤拷⻉构造。
移动赋值运算符重载和移动构造默认生成规则类似。如果提供了移动构造或者移动赋值,编译器不会⾃动提供拷⻉构造和拷⻉赋值。
2.defult和delete
C++11可以让你更好的控制要使⽤的默认函数。假设你要使⽤某个默认的函数,但是因为⼀些原因 这个函数没有默认⽣成。⽐如:我们提供了拷⻉构造,就不会⽣成移动构造了,那么我们可以使⽤ default关键字显⽰指定移动构造⽣成。
如果能想要限制某些默认函数的⽣成,在C++98中,是该函数设置成private,并且只声明补丁已, 这样只要其他⼈想要调⽤就会报错。在C++11中更简单,只需在该函数声明加上=delete即可,该语 法指⽰编译器不⽣成对应函数的默认版本,称=delete修饰的函数为删除函数。
cpp
class Person
{
public:
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
{}
Person(const Person& p)
:_name(p._name)
, _age(p._age)
{}
Person(Person&& p) = default;
//Person(const Person& p) = delete;
private:
string _name;
int _age;
};
int main()
{
Person s1;
Person s2 = s1;
Person s3 = std::move(s1);
return 0;
}3.STL中⼀些变化
新增了unordered_map和unordered_set,以及右值引⽤和移动语义相关的push/insert/emplace系列 接⼝和移动构造和移动赋值,还有initializer_list版本的构造等,还有范围for,这些已经讲过就不细讲了。
4.包装器
1.function
std::function 是⼀个类模板,也是⼀个包装器。 std::function 的实例对象可以包装存储其他的可以调⽤对象,包括函数指针、仿函数、 lambda 、 bind 表达式等,存储的可调⽤对象被称为std::function 的⽬标。若std::function 不含⽬标,则称它为空。调⽤空 std::function 的⽬标导致抛出std::bad_function_call异常。
function原型:
cpp
template <class T>
class function; // undefined
template <class Ret, class... Args>
class function<Ret(Args...)>;函数指针,仿函数,lamabda函数类型各不相同,function的作用体现在统一类型,对他们进行包装就可以在很多地方⽅便声明可调⽤对象的类型
在包装静态成员函数时必须在指定类域且加&才能取到地址,
包装普通成员函数时必须,因为普通成员函数参数中隐含了this指针,因此在function包装时参数中也要加入对应类的指针或者对应类名,这是因为通过函数指针调用类内部成员函数要用.*操作符,如果给的是类指针就会先解引用再调用函数,给的是对象就会直接调用函数。
cpp
#include<functional>
using namespace std;
int Func(int a, int b)
{
return a + b;
}
class Funtor
{
public:
int operator()(int a, int b)
{
return a + b;
}
};
class Plus
{
public:
Plus(int a=1, int b=2)
:_a(a),
_b(b)
{}
static int plusi(int a, int b)
{
return a + b;
}
double plusd(int a, int b)
{
return (double)a * b;
}
private:
int _a = 0;
int _b = 1;
};
int main()
{
function<int(int, int)> f1 = Func;
function<int(int, int)> f2 = Funtor();
function<int(int, int)>f3 = [=](int a, int b) {return a + b; };
function<int(int, int)>f4 = &Plus::plusi;
function<double(Plus*,int, int)>f5 = &Plus::plusd;
Plus plus;
f5(&plus, 1, 1);
function<double(Plus, int, int)>f6 = &Plus::plusd;
f6(plus, 1, 1);
function<double(Plus&&, int, int)>f7 = &Plus::plusd;
f7(Plus(), 1, 1);
return 0;
}2.bind
cpp
simple(1)
template <class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);
with return type (2)
template <class Ret, class Fn, class... Args>
/* unspecified */ bind (Fn&& fn, Args&&... args);bind 是⼀个函数模板,它也是⼀个可调⽤对象的包装器,可以把他看做⼀个函数适配器,对接收 的fn可调⽤对象进⾏处理后返回⼀个可调⽤对象。 bind 可以⽤来调整参数个数和参数顺序。 bind 也在这个头⽂件中。
调⽤bind的⼀般形式: auto newCallable = bind(callable,arg_list); 其中 newCallable本⾝是⼀个可调⽤对象,arg_list是⼀个逗号分隔的参数列表,对应给定的callable的参数。当我们调⽤newCallable时,newCallable会调⽤callable,并传给它arg_list中的参数。
arg_list中的参数可能包含形如_n的名字,其中n是⼀个整数,这些参数是占位符,表⽰ newCallable的参数,它们占据了传递给newCallable的参数的位置。数值n表⽰⽣成的可调⽤对象 中参数的位置:_1为newCallable的第⼀个参数,_2为第⼆个参数,以此类推。_1/_2/_3....这些占 位符放到placeholders的⼀个命名空间中。
使用bind一般有两个用途(1)交换参数位置(2)减少参数个数

function和bind可以在一起使用,将成员函数对象绑死就不需要每次都传递了,bind就常用绑死一些参数。
cpp
#include<functional>
using namespace std;
using placeholders::_1;
using placeholders::_2;
using placeholders::_3;
class Plus
{
public:
static int Plusi(int a, int b)
{
return a + b;
}
double Plusd(double a, double b)
{
return a + b;
}
};
int main()
{
function<double(Plus, double, double)> func2 = &Plus::Plusd;
Plus plus;
func2(plus, 1.1, 1.1);
function<double(double, double)> func1 = bind(&Plus::Plusd, Plus(), _1, _2);
func1(1.1, 1.1);
return 0;
}