一、全文思维导图
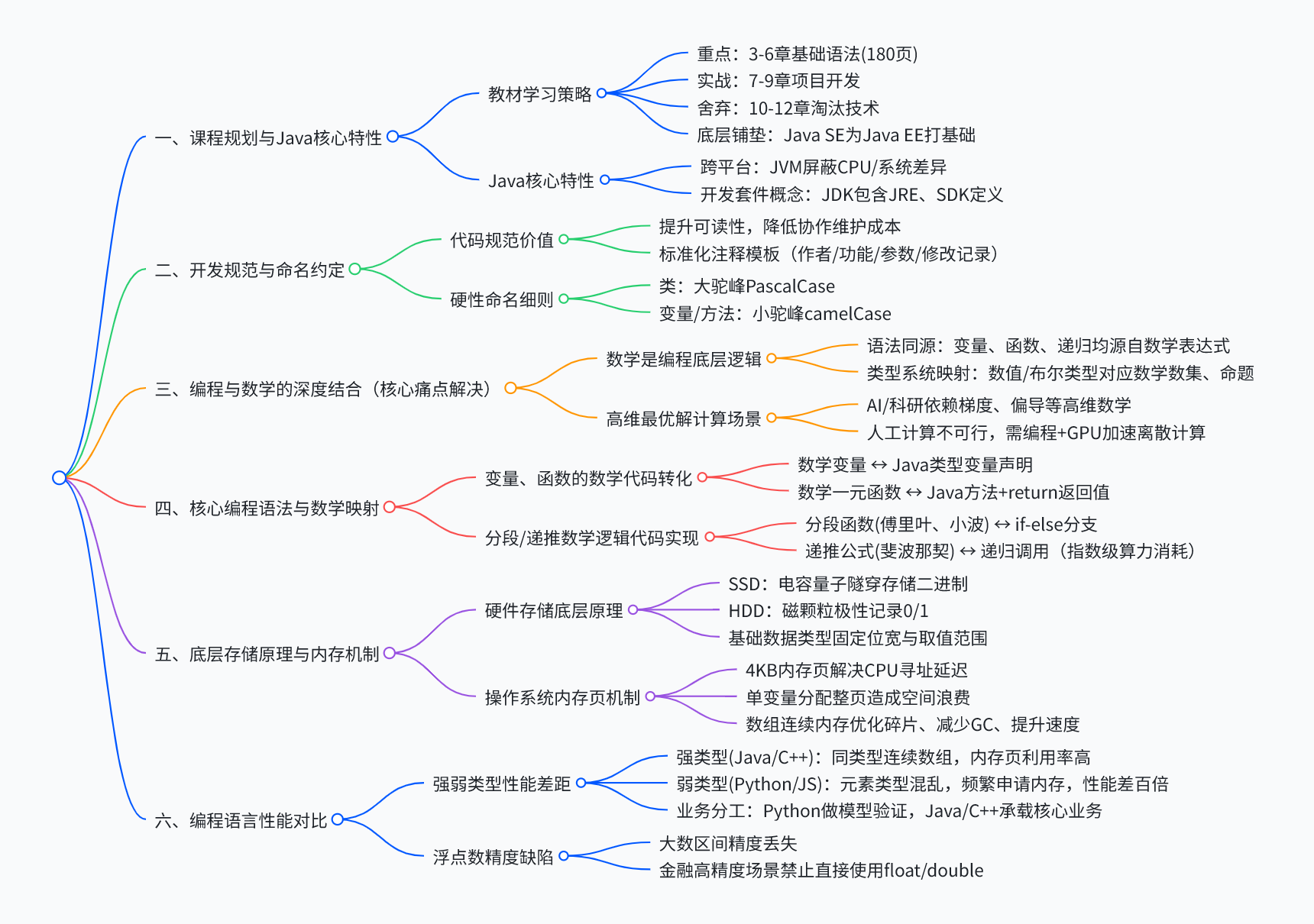
二、课程规划与Java核心特性(零基础系统化学习指南)
1.1 教材章节分层学习策略(精准避坑、高效提分)
本次课程摒弃传统逐页通读的低效学习方式,结合企业实战需求与技术迭代现状,对教材章节进行精细化分层,明确核心学习重心、实战落地内容与淘汰无效知识点,彻底杜绝无效学习。
核心必学章节(3-6章,180页) :是整个Java学习的基石,也是后续所有开发的核心底层。章节完整覆盖Java SE标准版全部基础语法,包含变量、数据类型、运算符、流程控制、数组、方法、面向对象入门等核心知识点,配套基础类库的使用详解。这180页内容是后续项目实战、框架学习、企业开发的前置核心,要求全员吃透、熟练手写、理解底层,不允许死记硬背。
实战应用章节(7-9章) :无新增基础语法,核心作用是学以致用。基于3-6章的基础语法,落地小型实战项目,训练代码逻辑思维、问题排查能力、基础工程思维。重点锻炼语法灵活运用能力,打破"会语法不会写代码"的学习痛点,衔接理论与实战。
淘汰废弃章节(10-12章):内容均为老旧、淘汰、无企业应用场景的技术。随着Java版本持续迭代,相关API、设计逻辑已被全新技术替代,目前企业开发完全不用,课程明确无需学习,节省大量学习时间,聚焦核心刚需技术。
技术层级关系:Java SE(基础语法+核心类库)是地基,Java EE(企业级Web开发、微服务开发)是上层建筑,所有高级开发能力均建立在SE基础之上,基础语法不扎实,后续框架学习会出现严重底层短板。
1.2 Java语言核心特性与核心术语详解
(1)跨平台、体系结构中立(Java核心王牌优势)
跨平台性是Java能够长期霸占企业级开发主流地位的核心原因,核心依托**JVM(Java虚拟机)**实现"一次编译,到处运行"。
编译原理:Java源代码(.java文件)编译生成跨平台的字节码文件(.class文件),字节码不绑定任何硬件架构与操作系统。运行时由对应平台的JVM解析翻译字节码,适配本地系统运行。
适配范围:全面兼容x86、ARM、RISC-V等主流CPU架构,完美适配Windows、MacOS、Linux、服务器嵌入式系统等全场景操作系统,是后端服务、嵌入式开发、大数据开发的首选语言。
(2)开发环境核心术语深度辨析(零基础必懂)
三者为包含与被包含关系,是Java开发的基础环境,必须精准区分,避免环境配置误区:
JDK(Java开发工具包) :面向开发者的完整工具包,内置JRE+开发编译工具(javac编译工具、java运行工具、调试工具、打包工具等),是开发Java程序的必备环境,所有编程人员必须安装。
JRE(Java运行环境):面向程序运行的环境,仅包含JVM虚拟机和Java核心基础类库,无任何开发、编译能力,仅用于运行已编译好的Java程序,服务器部署场景仅需安装JRE即可。
SDK(软件开发工具包):通用行业概念,并非Java专属。泛指所有平台、第三方服务提供的配套开发工具、示例代码、API文档,例如阿里云SDK、微信支付SDK,用于快速对接第三方功能。
三、工程开发规范与命名约定(企业级标准)
3.1 代码规范化的核心工程价值
个人学习可以随意编码,但企业开发的核心是团队协作,代码规范是工程化开发的第一准则,直接决定项目的可维护性、迭代效率与bug率。
核心价值:1、提升代码可读性,任意团队成员均可快速读懂代码逻辑,降低沟通成本;2、便于代码交接、版本迭代、功能拓展,避免单人代码"私有化";3、规范代码结构可减少隐性bug,降低排查难度;4、标准化注释便于问题追溯、责任划分,适配大型项目运维。
3.2 企业强制注释标准(完整模板)
所有自定义类、方法、核心代码块必须添加标准化注释,缺一不可,核心包含五大要素:
1、作者信息:标注开发人员姓名/工号;2、功能描述:精准说明当前类/方法的核心作用、业务场景;3、参数说明:详细标注入参含义、数据类型、取值限制、可为空规则;4、返回值说明:标注出参数据、返回状态、异常返回逻辑;5、维护信息:最后修改时间、修改内容、联系方式。
3.3 统一命名规范细则(硬性准则)
Java命名严格遵循行业统一标准,杜绝拼音、乱大小写、无意义命名(如a、b、c、temp):
类名:大驼峰命名法(PascalCase):所有单词首字母大写,无下划线、无横线,采用英文语义化命名,精准对应业务功能。示例:UserManager、OrderService、DataAnalysis。
变量、成员变量、普通方法名:小驼峰命名法(camelCase):首个单词首字母小写,后续所有单词首字母大写,语义化见名知意。示例:userAge、orderNum、getUserInfo()、calculateTotalPrice()。
补充规范:常量全部大写、下划线分隔;包名全部小写,杜绝特殊字符。
四、编程与数学深度结合(破解「只懂语法不懂底层」核心痛点)
绝大多数Java学习者的核心瓶颈:熟练背诵语法、能仿写代码,但不懂底层原理、不会解决复杂计算问题、无法看懂AI与算法底层,根本原因是割裂了编程与数学的同源关系。耿超老师核心观点:数学是所有编程语言的底层基石,编程语法只是数学逻辑的代码化翻译。
4.1 数学是编程的底层核心逻辑
(1)语法完全同源:编程语法源于数学语法
Java核心基础语法并非凭空创造,完全沿用数学的定义逻辑、运算逻辑、逻辑判断逻辑,二者可以双向精准转化:
数学变量定义:人为限定变量类型、赋值,如"设整数x=9",对应编程中类型声明+变量赋值的完整逻辑;数学函数定义:限定自变量定义域、定义运算规则,对应编程方法的入参、方法体运算、return返回值;数学递推、迭代逻辑,对应编程递归、循环逻辑。所有编程基础语法,本质都是数学逻辑的标准化代码封装。
(2)类型系统精准映射数学体系
Java强类型的核心设计逻辑,完全对标数学中的数集与逻辑命题,类型约束的本质是规范数据范围、优化内存占用、保障计算精准度:
int整型 → 数学整数集,用于整数运算;float/double浮点型 → 数学实数(小数、无理数),用于浮点运算;boolean布尔型 → 数学真假命题,仅存在真、假两种状态,用于逻辑判断、条件分支。强类型语言提前限定数据类型,避免数据类型混乱,大幅提升内存利用率与计算效率,这也是强类型语言性能远优于弱类型语言的底层根源。
4.2 高维最优解问题的计算挑战与解决方案
(1)高维计算的应用场景与数学支撑
人工智能算法、大数据分析、科研仿真、工业建模的本质,都是多变量、高维度、非线性的最优解求解问题。现实场景中,一个结果往往受数十上百个因素影响(即高维特征),无法通过基础数学求解,必须依赖高等数学核心知识:空间曲面计算、多元函数偏导数、梯度下降算法、极值求解、矩阵运算等。
例如AI模型训练,核心是通过梯度下降不断修正参数,最小化损失函数,全程基于高维数学运算,无数学基础则完全无法理解算法底层。
(2)人工计算瓶颈与算力解决方案
高维运算存在致命人工短板:变量维度多、运算量极大、迭代次数极多,人工计算耗时数月甚至数年,且极易出错、无法迭代。因此工业界统一解决方案:编程离散化切割+GPU并行算力硬算。
通过Java、C++等高性能语言,将连续的高维数学公式离散化为可迭代的代码逻辑,结合GPU多线程并行计算能力,批量完成海量运算,快速求解最优解,是目前AI、科研、工业计算的唯一高效方案。
五、Java核心语法与数学精准映射(实操落地详解)
5.1 变量与函数的数学-代码双向翻译
(1)变量声明的精准映射
数学表述:设整数 x = 9(核心要素:限定数据类型为整数、定义变量名、赋值)
Java代码翻译:int x = 9;
核心细节补充:Java严格延续数学的变量定义逻辑,同时补充编程语法规则,必须声明数据类型匹配数学数集,语句必须以分号结尾,代表逻辑结束,与数学公式的完整性定义完全契合。
(2)自定义函数的精准映射
数学函数定义:f(x) = 2x - 7(核心:自变量x、运算规则、函数返回结果、x存在定义域限制)
Java代码完整翻译:
// 对应数学函数f(x)=2x-7 int f(int x) { return 2 * x - 7; }
精准对应关系:方法入参int x 对应数学自变量与定义域(限定x为整数);方法体运算逻辑 对应数学公式运算规则;return 关键字 完全等价于数学公式中的等号,输出函数最终运算结果。
5.2 区间分段函数与递归调用的数学本质
(1)分段函数的代码实现逻辑
数学中大量核心函数为分段函数,在不同定义域内拥有不同运算规则,典型代表:傅里叶变换、小波变换、阶跃函数等,是信号处理、图像算法、数据分析的核心基础。
编程落地方式:通过if-else条件分支划分定义域区间,不同区间执行对应的数学运算逻辑,完美复刻分段函数的数学特性,实现复杂函数的计算机求解。
(2)递归调用的底层本质与缺陷
核心定义 :递归代码的本质 = 数学递推公式的直接代码实现,所有递归场景均可对应数学数列递推逻辑,最典型的就是斐波那契数列。
数学递推公式:F(n)=F(n-1)+F(n-2),初始值F(1)=1、F(2)=1
递归代码完全复刻该逻辑,无需复杂循环,即可实现数列求解。
底层致命缺陷(重点) :Java递归每次调用都会在JVM内存中创建独立的栈帧,保存当前方法参数、局部变量、执行状态,每一次调用都是一次独立内存拷贝。随着递归深度增加,内存开销、计算量呈指数级增长,极易出现栈内存溢出(StackOverflowError),因此工业级开发中,复杂递推场景优先使用循环替代递归。
六、硬件存储与Java内存底层原理(性能差异根源)
6.1 主流存储介质物理底层原理
计算机所有数据最终均以二进制0/1形式存储,不同硬件的存储原理不同,直接决定读写性能,也间接影响Java程序运行效率:
SSD固态硬盘:核心依靠电容充放电、量子隧穿效应存储0和1,通过电压高低区分二进制状态。无机械运动结构,读写速度极快、响应延迟低、抗震性强,是目前主流设备的标配存储。
HDD机械硬盘:核心依靠盘片磁颗粒的磁极极性存储0和1,通过磁头读写磁颗粒数据。存在机械转动、磁头移动的物理延迟,读写速度慢、噪音大、抗震差,仅用于大容量低成本存储。
6.2 Java基本数据类型位宽与取值范围底层逻辑
Java基本数据类型为固定位宽设计,位数直接决定内存占用大小、数值存储范围,是强类型高效内存利用的基础:
1、byte:8位二进制,占用1字节内存,取值范围-128~127,适用于极小数值存储,极致节省内存;2、int:32位二进制,占用4字节内存,是整数默认类型,适配绝大多数日常整数运算;3、long:64位二进制,占用8字节内存,用于超大整数、时间戳、唯一标识存储。
取值范围底层原理:n位二进制有符号数取值范围为-2\^{n-1} \\sim 2\^{n-1}-1,完美解释byte、int、long的数值边界,底层逻辑严谨无漏洞。
6.3 内存页机制与数组性能优化核心原理
(1)内存页的设计目的
CPU运算速度极快,但从内存读取数据存在寻址延迟。为解决CPU等待数据的性能瓶颈,操作系统统一引入**内存页(默认4KB)**机制,不再单次读取单个字节数据,而是一次性读取一整页内存数据,大幅减少CPU寻址次数,降低延迟、提升读写效率。
(2)单变量存储的内存浪费问题
Java单个基础变量内存占用极小(如int仅4字节),但操作系统的内存分配最小单位是4KB内存页 。即便只存储4字节数据,系统也会为其分配完整的4KB内存页,剩余空间全部闲置,大量零散变量会造成严重的内存空间浪费、内存碎片过多,导致程序GC(垃圾回收)频繁触发,严重降低运行速度。
(3)数组的底层性能优化优势
Java数组是同类型数据连续内存存储结构,所有元素类型统一、内存地址连续,可完整填满分配的内存页,彻底解决内存碎片化问题。核心优势:1、最大化利用内存页空间,无闲置浪费;2、减少内存申请次数,降低系统开销;3、大幅减少GC垃圾回收频率;4、CPU批量读取连续内存数据,读写效率指数级提升。这也是数组比零散定义变量性能更强的底层核心原因。
七、主流编程语言深度性能对比与工程落地选型
7.1 强类型与弱类型语言核心差异
(1)内存利用与性能差距根源
强类型语言(Java、C++):变量、数组必须严格限定数据类型,数组元素类型统一、内存连续规整,完美适配操作系统内存页机制,内存利用率接近100%,计算效率极高,适合高并发、大数据量、高精度运算场景。
弱类型语言(Python、JavaScript) :无严格类型约束,数组可混合存储数字、字符串、对象等任意类型数据,底层无法分配连续内存,每新增不同类型元素都需要单独申请内存页,产生大量内存碎片和系统开销,性能损耗极其严重。同等运算量下,强弱类型语言性能差距可达数百倍。
(2)企业工程化分工与选型标准
Python :语法简洁、开发效率高,无需关注底层内存,适合高校教学、AI算法原型验证、数据分析、脚本辅助开发。但因性能短板,绝不用于企业核心业务、高并发后端服务。
Java/C++:内存可控、性能强悍、稳定性高、并发能力强,是企业级核心业务、后端服务、大数据框架、底层引擎的核心开发语言,承担系统核心算力与业务逻辑。
行业通用落地模式:Python做算法原型快速验证,验证通过后由Java/C++重构落地为线上工程,兼顾开发效率与线上性能。
7.2 浮点数精度缺陷、成因与避坑方案
(1)精度丢失核心成因
float、double浮点型采用二进制科学计数法存储,存在天然精度缺陷:在数值趋近于0的小区间内,精度较高;随着数值不断增大,浮点数值之间的最小间隔会持续变大,小数部分无法精准存储,直接导致计算精度丢失,出现计算误差。
(2)业务场景禁忌与解决方案
绝对禁忌:金融支付、账单结算、精密计量、汇率计算等对精度要求极高的场景,禁止使用float、double直接运算,会造成资金误差、数据错误、线上事故。
标准解决方案:Java中统一使用BigDecimal高精度运算类处理金融数值计算,彻底规避浮点数精度丢失问题。