从理论到工程化落地: Hi Float 8 的设计逻辑与工程技术解析

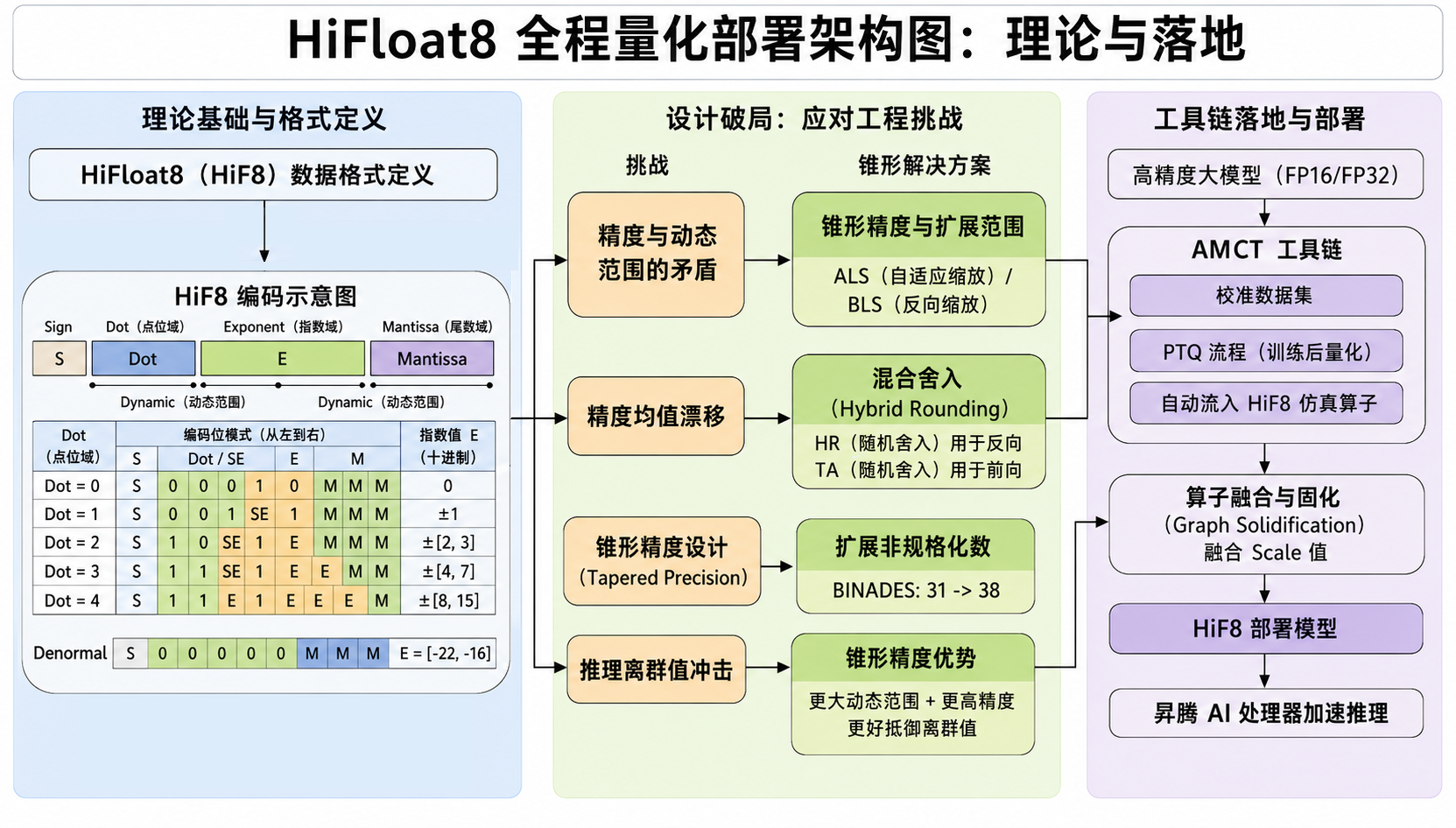
图1 Hi Float8的设计逻辑与可工程化落地验证的有效路径
一 、 问题的起点: FP8为何"不够用"?
在深入HiFloat8之前,我们需要先理解---个背景问题:为什么现有的FP8格式在工程落地时存在短板?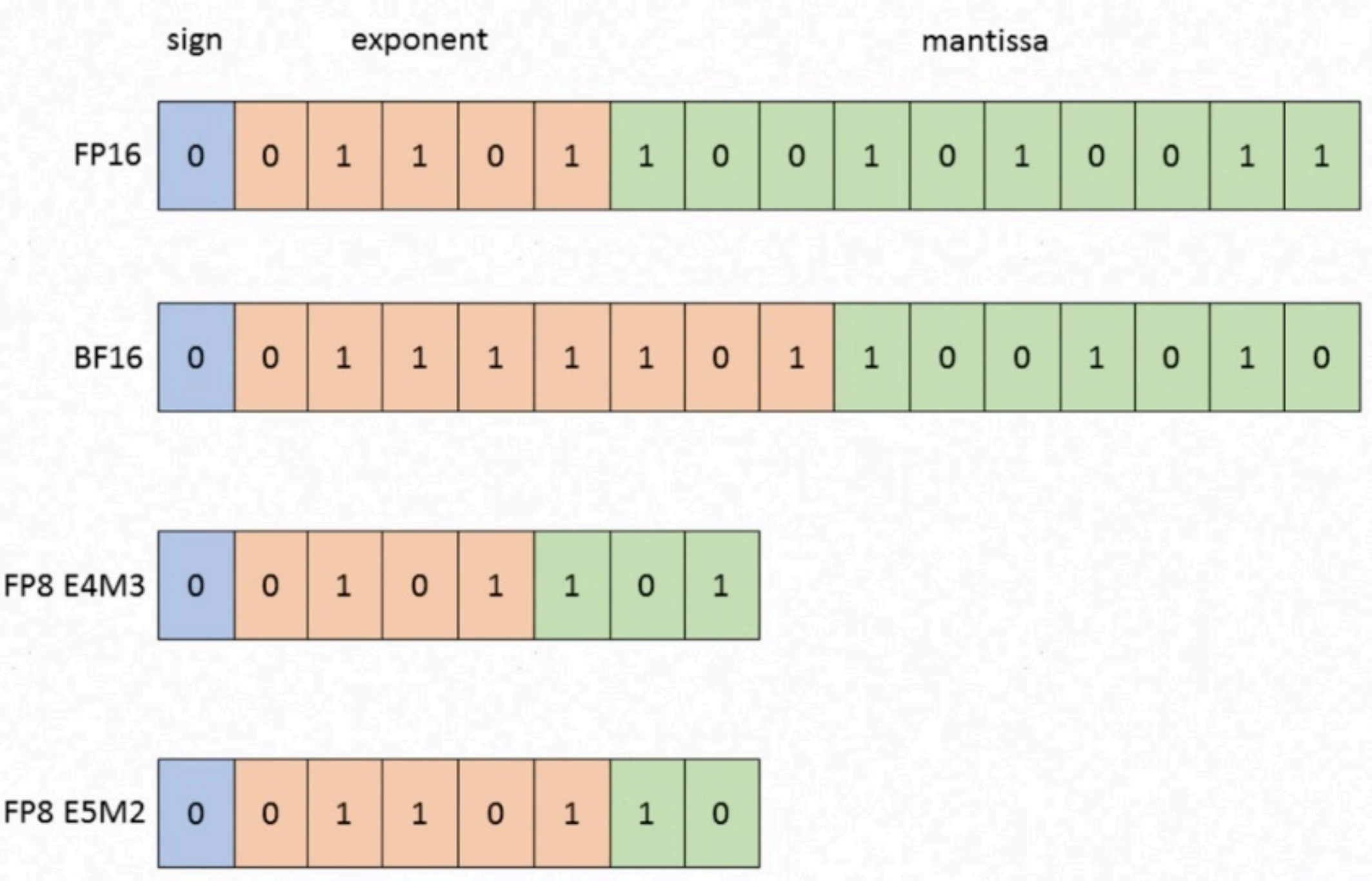
图2 Float16和Float8域位宽结构示意图
根据论文中的介绍,主流FP8标准存在两种格式的分工:
|----------|------|------------------|------|------------|
| 格式 | 定位 | 指数范围(含subnormal) | 尾数位 | 特点 |
| FP8-E4M3 | 推理友好 | -9, 8 | 3bit | 精度高但动态范围有限 |
| FP8-E5M2 | 训练探索 | -16, 15 | 2bit | 范围大但精度损失明显 |
工程实践中,往往需要混用两种格式---前向传播用E4M3保证精度,反向传播用E5M2保证范围。这种" 左右互搏"的方案增加了系统复杂度和调优成本。
这里有个核心的问题:能否用单一格式覆盖训练全流程, 同时兼顾精度与动态范围?
显而易见 ,传统 FP8 无法用单---格式覆盖训练全流程,根本原因是精度与动态范围存在零和博弈 --- 8bit 总位宽固定,指数位多了范围大但精度低,尾数位多了精度高但范围小:
|----------|-----|-----|------------|----|-----------|
| 格式 | 指数位 | 尾数位 | 动态范围 | 精度 | 能否单格式覆盖训练 |
| FP8-E4M3 | 4 | 3 | 18 binades | ⾼ | 否,反向传播溢出 |
| FP8-E5M2 | 5 | 2 | 32 binades | 低 | 否,前向精度不足 |
 为了解决这个问题, Hi Float8 应运而生 ,让我们---起来看看神秘的 Hi Float8 是如何设计的。
为了解决这个问题, Hi Float8 应运而生 ,让我们---起来看看神秘的 Hi Float8 是如何设计的。
 二 、 Hi Float8的设计逻辑
二 、 Hi Float8的设计逻辑
2.1 变长前缀码: Dot域的引入
Hi Float8( 以下简称HiF8) 的第---个设计创新是引入了Dot域( Dot field)。
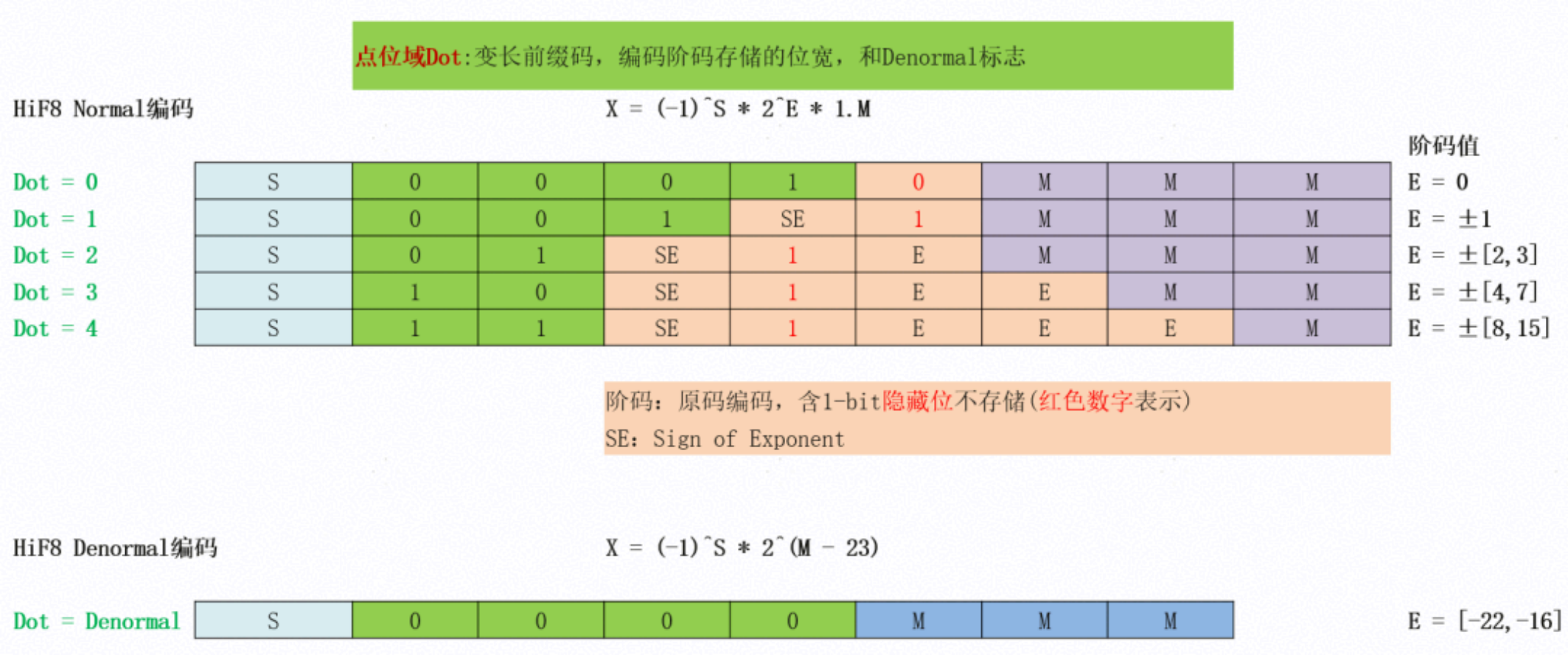
图3 HiF8编码示意图
根据论文原文 , HiF8的数据结构由四个字段组成:
Sign (1bit) + Dot (2-4bits, 变长) + Exponent (D bits, 变长) + Mantissa (1-3bits, 变长)
Dot域本质上是---个变长前缀码,通过不同的编码值指示指数位宽:
|--------|-------|------|------|--------------------|------------|
| Dot编码 | D值 | 指数位宽 | 尾数位宽 | 无偏指数范围 | 说明 |
| | 4 | 4bit | 1bit | |E| ∈ 8, 15 | 大数值,高范围 |
| | 3 | 3bit | 2bit | |E| ∈ 4, 7 | 中等范围 |
| | 2 | 2bit | 3bit | |E| ∈ 2, 3 | 中等精度 |
| 001 ₂ | 1 | 1bit | 3bit | |E| = 1 | 小数值 |
| 000X ₂ | 0/DML | 0bit | 3bit | E = 0 | 零或Denormal |
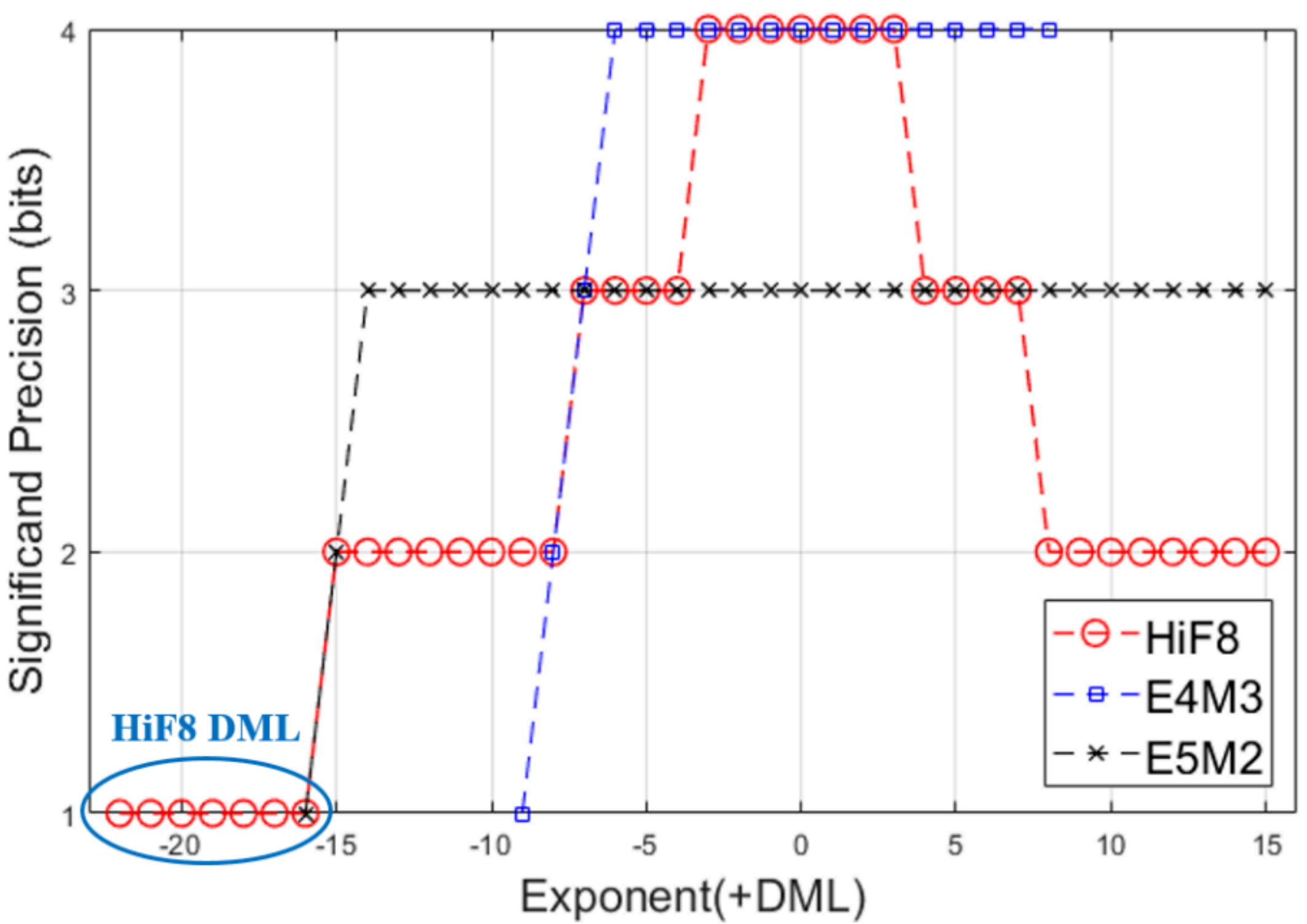
图4 HiF8位格式结构图
2.2 锥度精度:让精度"按需分配"
HiF8的第二个核心设计是锥度精度(Tapered Precision)。
传统浮点格式采用均匀精度分配---无论数值大小 ,尾数精度固定。而HiF8根据数值大小动态调整精度:
|----------------|------|--------------------|
| 无偏指数范围 | 尾数精度 | 设计考量 |
| |E| ≤ 3 | 3bit | 高精度,覆盖神经网络权重的主要分布区 |
| 4 ≤ |E| ≤ 7 | 2bit | 中等精度,梯度幅值的主要区间 |
| 8 ≤ |E| ≤ 15 | 1bit | 低精度,极端值" 保序" 即可 |
设计直觉: 神经网络中的数据分布呈中心化特征---靠近零的数值出现频率远高于极端值 。 因此 , 把有限的尾数精度" 浪费" 在最需要的高频区域,是---种符合数据分布特性的工程优化。
2.3 动态范围: 38个binades意味着什么?
HiF8通过Dot域和锥度精度设计,在8bit约束下实现了 38个二进制指数区间( binades) 的覆盖:

图5 动态范围对比图
|----------|-----------------|------------|
| 格式 | 指数范围(含Denormal) | 覆盖binades数 |
| FP16 | -24, 15 | 40 |
| HiF8 | -22, 15 | 38 |
| FP8-E5M2 | -16, 15 | 32 |
| FP8-E4M3 | -9, 8 | 18 |
关键洞察: HiF8用单---格式达到了接近FP16的动态范围 , 而传统FP8需要E4M3+E5M2混用才能勉强接近 。 这意味着什么?请看后文第三章工程验证。

 三、工程验证:论文里的实验数据
三、工程验证:论文里的实验数据
3.1 传统神经网络训练
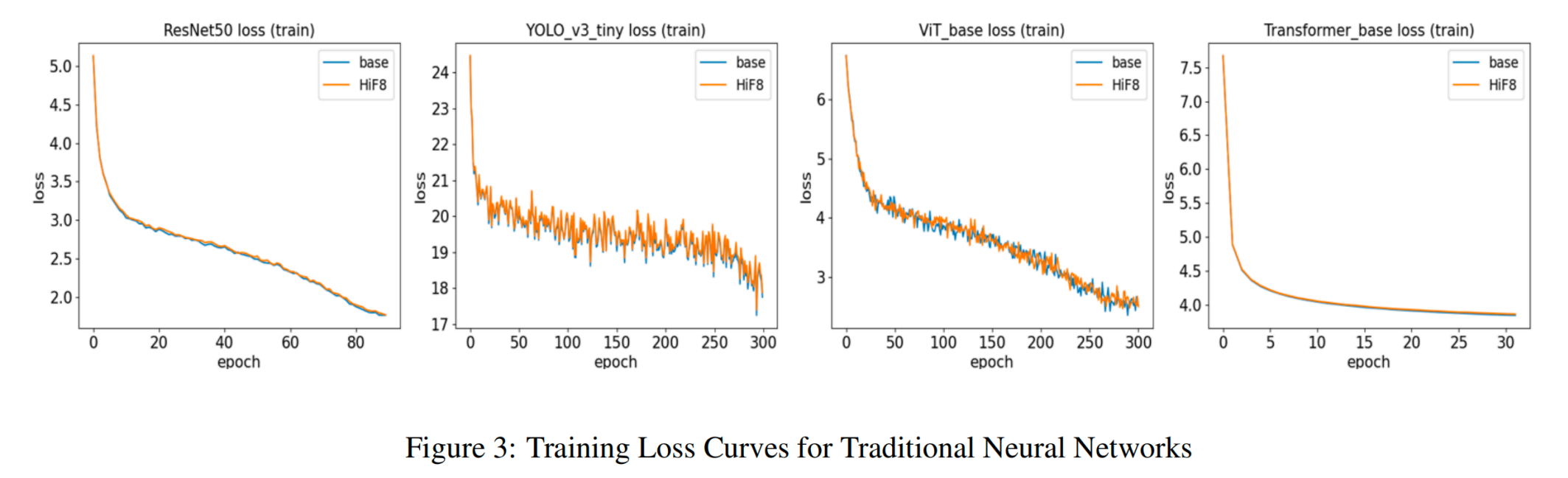
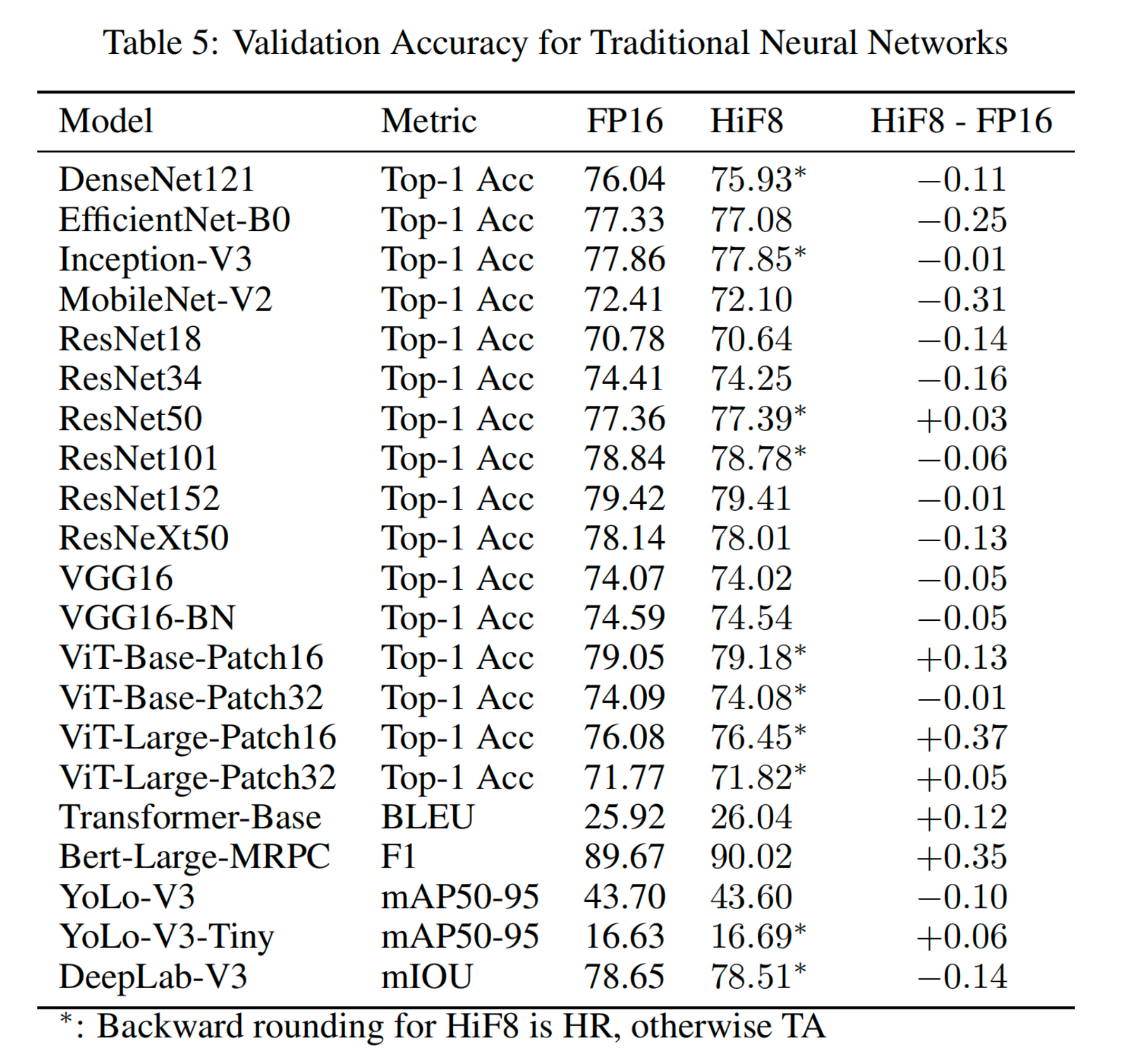
图6 HiF8在传统神经网络训练过程及结果
结论与分析:
-
HiF8在ResNet50 、ViT-Large 、Transformer 、 BERT 、YOLO等主流架构上均表现出与FP16相当的训练精度
-
部分模型( 如ViT-Large-Patch16) 甚至出现精度提升,说明HiF8的锥度精度设计契合神经网络数据分布
-
训练过程收敛曲线平滑,未出现明显的精度损失或训练不稳定现象
-
工程价值: 单---HiF8格式即可覆盖传统神经网络训练全流程,无需混用FP8-E4M3/E5M2
3.2 大语言模型训练
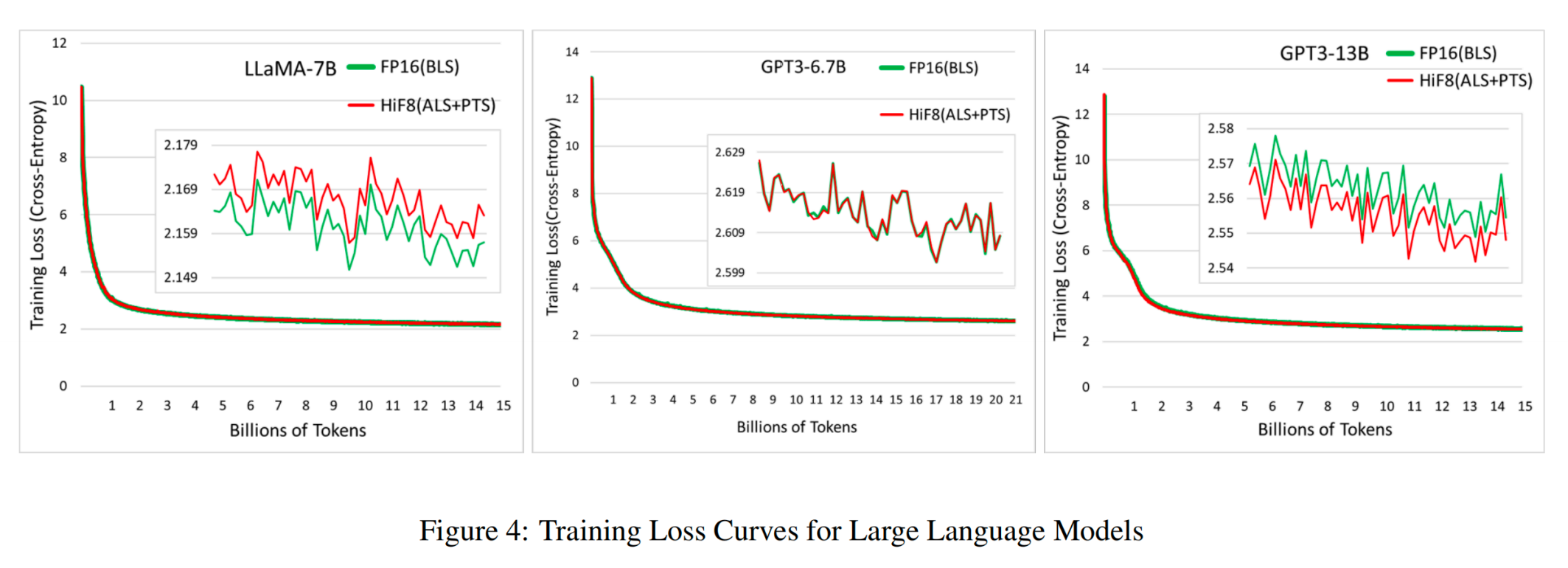
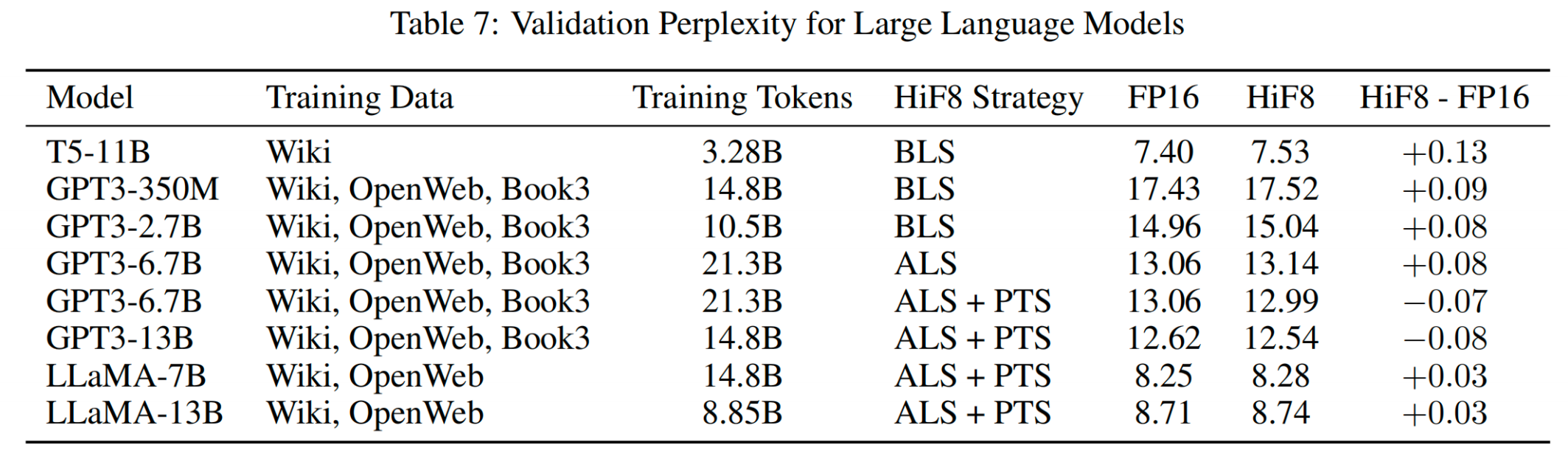
图7 论文中使用HiF8 进行 LLM 的训练过程 及 perplexity 对比图
结论与分析:
-
GPT3和LLaMA系列模型在HiF8训练下, perplexity增量均控制在0.1以内,精度损失可接受
-
GPT3-6.7B甚至出现perplexity降低( -0.07),说明ALS+PTS策略对大模型更友好
-
训练策略选择至关重要: BLS适合小模型,ALS+PTS适合大模型
-
工程价值: HiF8在LLM训练中展现出良好的泛化能力 ,为大规模模型训练提供了新的低精度方案
策略说明:
-
BLS: Backward Loss-Scaling(反向损失缩放)
-
ALS:Adaptive Loss-Scaling( 自适应损失缩放)
-
PTS: Per-Tensor Scaling( 逐张量缩放)
3.3 模型敏感性差异: 一个重要发现
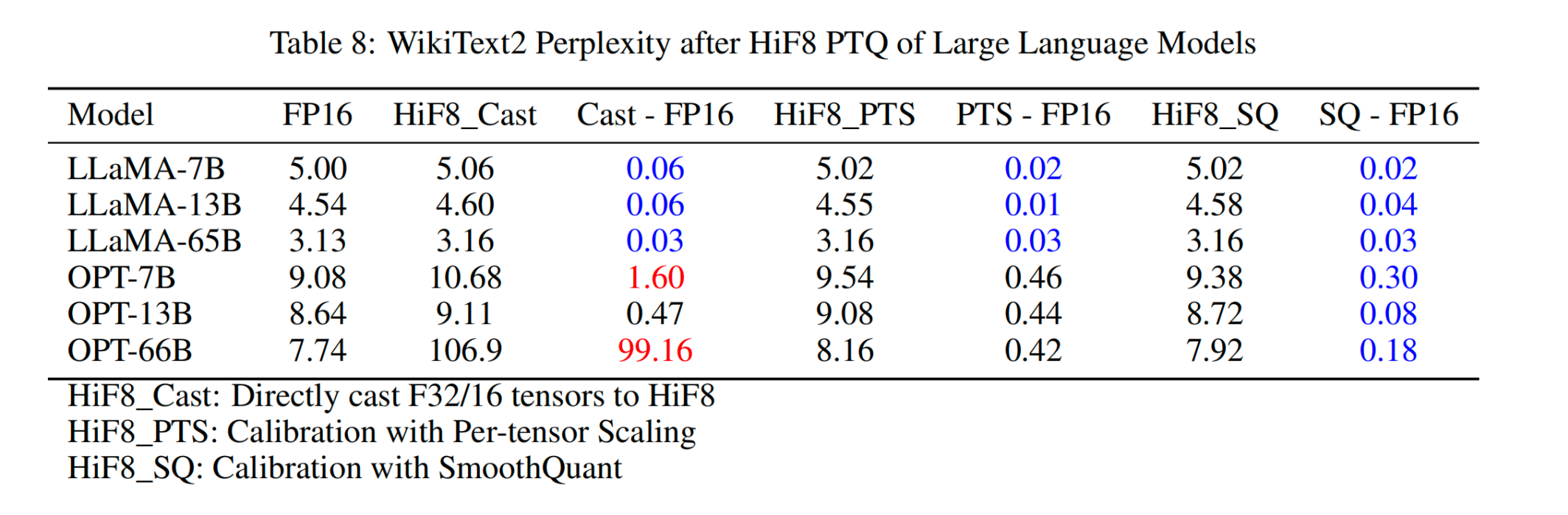

图8论文中模型敏感性实验数据比对及重要发现
结论与分析:
-
LLaMA系列:对HiF8量化表现出高容忍度,三种量化策略( Cast/PTS/SQ) 的perplexity增量均小于0.1
-
OPT系列:对HiF8量化高度敏感,OPT-66B在直接转换下perplexity增量高达+99.16 ,几乎不可用
-
量化策略影响: 平滑量化( HiF8_SQ)对敏感模型效果最好,可将OPT-66B的增量降至+0.18
-
工程启示:
-
HiF8并非 " 万金油" ,需根据模型架构选择合适的量化策略
-
对于敏感模型,必须使用PTS或SQ等高级量化策略,避免直接转换
-
模型架构设计( 如LLaMA的RMSNorm)可能影响量化容忍度,值得深入研究

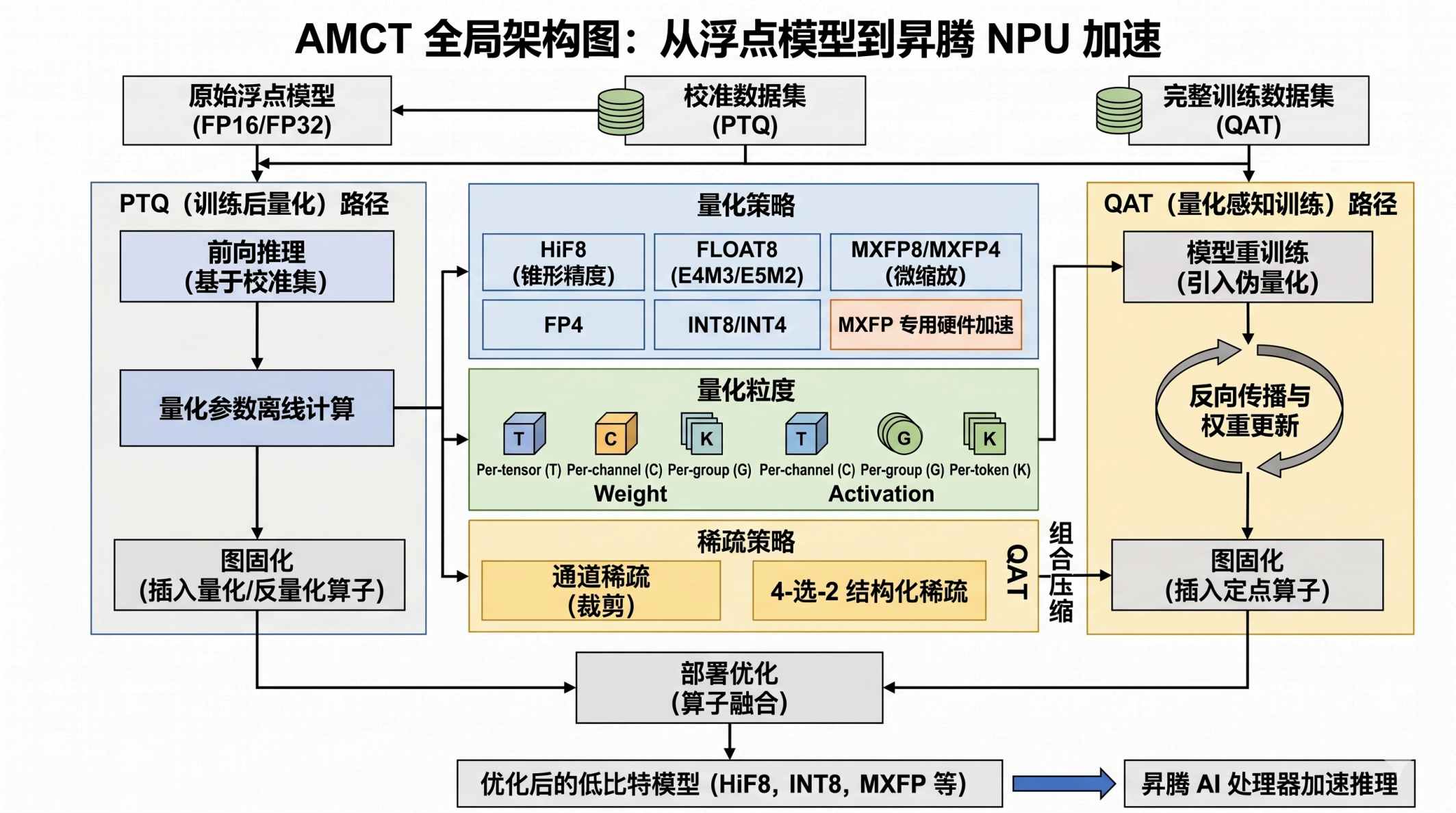
 四、工程落地:AMCT工具链与Hi Float8源码深度解析
四、工程落地:AMCT工具链与Hi Float8源码深度解析
AMCT 仓库地址 : https://atomgit.com/cann/amct
AMCT( Ascend Model Compression Toolkit) 是华为昇腾AI处理器亲和的深度学习模型压缩工具包 , HiF8的工程化落地完全依托于该工具链 。本节将从代码架构 、核心算法实现 、量化配置 、部署算子四个维度 , 深入解析HiF8从论文公式到可运行代码的工程化路径。
4.1 代码架构总览
AMCT仓库中Hi Float8相关代码分布在以下层次:
amct/
── amct _ pytorch /
├── experimental/hifloat8/ # 核心 HiFloat8 实验性模块( CPU实现)
│ ├── hifloat8_cast.cpp # HiF8 <-> FP32/FP16/BF16 格式转换 C++ 实现
│ ├── hifloat8_fakequant_linear.py # HiFloat8 伪量化线性模块
│ ├── setup.py # C++ 扩展编译脚本( PyTorch C++ Extension)
│ ├── build.sh # Shell 编译脚本
│ ├── test.py # 测试脚本( Qwen模型 + PPL评估)
│ ├── utils.py # 工具函数(模型加载 、数据集 、 PPL计算)
│ └── README.md # 模块说明文档
│
├── deploy_op/ # 部署 NPU 部署算子
│ ├── npu_hif8_cast_quantization_linear.py # NPU HiFloat8 Cast 量化线性层│ └── init.py # 导出 NpuHIF8CastLinear
│
├── config/config.py # 配置 预定义量化配置
│ # HIFP8_OFMR_CFG, HIFP8_CAST_CFG
│
├── algorithm/init.py # 算法注册 注册 'cast ' 算法
│
├── utils/
│ ├── vars.py # 常量 HIFLOAT8= 'hifloat8 ', 支持的组合等
│ └── quant_util.py # 量化工具 convert_dtype(), quant_tensor() 等
│
└── quantize_op/utils.py # 量化算子工具 QUANT_MAX_SCOPE HIFLOAT8=32768.0
── tests/amct_pytorch/
└── test_cast.py
── examples/amct_pytorch/cast/
├── README_CN.md
├── requirements.txt
└── src/
测试 Cast 算法单元测试
示例 Cast 量化示例
|-----|-----------------------|---------------|
| ├── | run_llama2_samples.py | # LLaMA2 量化示例 |
| ├── | run_qwen_samples.py | # Qwen 量化示例 |
| └── | utils.py | |
图9AMCT仓库
4.2 核心算法实现: **hifloat****8_cast.**cpp 源码解析
代码相对路径 : amct _ pytorch / experimental / hifloat 8/ hifloat 8_ cast . cpp
这是Hi Float8格式转换的纯C++ CPU实现,是论文中Dot域编码和锥度精度设计的直接代码映射。
4.2.1 Dot 域查找表: **HIF****8_DOT_**MAP
论文中5种Dot编码对应5种指数/尾数位宽分配,在代码中通过---个16项查找表实现:
// hifloat8_cast.cpp:45-75
const std::map<uint8_t, std::tuple<uint8_t, uint8_t, uint8_t, uint8_t, uint8_t>> HIF8_DOT_MAP = {
// key: 高5bit(dot+exp+frac区域), value: (expMask, fracBits, expSignShift, expBits, fracMask)
// dml: dotbits=4 | expbits=0 | fracbits=3
{0b0000, std::make_tuple(0x00, 0x3, 0x0, 0x0, 0x7)},
// d0: dotbits=4 | expbits=0 | fracbits=3
{0b0001, std::make_tuple(0x00, 0x3, 0x1, 0x0, 0x7)},
// d1: dotbits=3 | expbits=1 | fracbits=3
{0b0010, std::make_tuple(0x08, 0x3, 0x3, 0x1, 0x7)},
{0b0011, std::make_tuple(0x08, 0x3, 0x3, 0x1, 0x7)},
// d2: dotbits=2 | expbits=2 | fracbits=3
{0b0100, std::make_tuple(0x18, 0x3, 0x4, 0x2, 0x7)},
{0b0101, std::make_tuple(0x18, 0x3, 0x4, 0x2, 0x7)},
{0b0110, std::make_tuple(0x18, 0x3, 0x4, 0x2, 0x7)},
{0b0111, std::make_tuple(0x18, 0x3, 0x4, 0x2, 0x7)},
// d3: dotbits=2 | expbits=3 | fracbits=2
{0b1000, std::make_tuple(0x1c, 0x2, 0x4, 0x3, 0x3)},
{0b1001, std::make_tuple(0x1c, 0x2, 0x4, 0x3, 0x3)},
{0b1010, std::make_tuple(0x1c, 0x2, 0x4, 0x3, 0x3)},
{0b1011, std::make_tuple(0x1c, 0x2, 0x4, 0x3, 0x3)},
// d4: dotbits=2 | expbits=4 | fracbits=1
{0b1100, std::make_tuple(0x1e, 0x1, 0x4, 0x4, 0x1)},
{0b1101, std::make_tuple(0x1e, 0x1, 0x4, 0x4, 0x1)},
{0b1110, std::make_tuple(0x1e, 0x1, 0x4, 0x4, 0x1)},
{0b1111, std::make_tuple(0x1e, 0x1, 0x4, 0x4, 0x1)},
};
工程洞察: 查找表的key是8bit数据中的高5bit( 即bit6:2 , 对应Dot+Exp+部分Frac区域),但实际查表时只使用bit6:3这4位作为索引 。 通过---次查表即可确定当前数值的指数掩码 、尾数位宽 、指数符号位移等全部解码参数。这种以空间换时间的设计使得HiF8解码只需---次map查找+几次位运算,无需分支判断。
4.2.2 锥度精度的代码映射: GetHiF8BitsNum**()**
论文中" 根据无偏指数值确定Dot值和位宽分配"的逻辑,在代码中体现为5段区间判断:
// hifloat8_cast.cpp:88-122
void GetHiF8BitsNum(int32_t expNoBias, uint32_t& dotValue,
uint32_t& expBits, uint32_t& fracBits)
{
uint32_t absExpNoBias = abs(expNoBias);
if (expNoBias == 0) { // d0: e= 0 → 0bit exp + 3bit frac
dotValue = 0x01; expBits = 0; fracBits = 3;
} else if (absExpNoBias == 1) { // d1: e= ±1 → 1bit exp + 3bit frac
dotValue = 0x02; expBits = 1; fracBits = 3;
} else if (absExpNoBias <= 3) { // d2: e= ±2,±3 → 2bit exp + 3bit frac
dotValue = 0x04; expBits = 2; fracBits = 3;
} else if (absExpNoBias <= 7) { // d3: e= ±4,±7 → 3bit exp + 2bit frac
dotValue = 0x08; expBits = 3; fracBits = 2;
} else if (absExpNoBias <= 15) { // d4: e= ±8,±15→ 4bit exp + 1bit frac
dotValue = 0x0C; expBits = 4; fracBits = 1;
}
}
论文→代码对照:
|-----------|-----------------------------------|-------------|
| 论文描述 | 代码实现 | 工程意义 |
| 小数值3bit尾数 | absExpNoBias <= 3 → fracBits = 3 | 权重分布密集区保留精度 |
|-----------|------------------------------------|----------------|
| 论文描述 | 代码实现 | 工程意义 |
| 中等值2bit尾数 | absExpNoBias <= 7 → fracBits = 2 | 梯度幅值区平衡精度与范围 |
| 极端值1bit尾数 | absExpNoBias <= 15 → fracBits = 1 | 极端值仅保序,节省位宽给指数 |
4.2.3 舍入处理: RoundHiF****8()
HiF8的舍入策略在 C++ 文件中各所实现:
标准舍入( hifloat8_cast.cpp:177-190 )---Round-to-nearest-even:
void RoundHiF8(HiF8CastParam& hif8Param)
{
uint32_t fractmp = hif8Param.fracFpN >> (hif8Param.fracBits - hif8Param.fracHiF8Bits - 1);
uint32_t fracMax = (1 << (hif8Param.fracHiF8Bits + 1)) - 1;
if (fractmp == fracMax) { // 尾数全1:进位到下---个指数区间
hif8Param.fracHiF8 = 0;
hif8Param.expNoBias += 1;
GetHiF8BitsNum(hif8Param.expNoBias, ...); // 重新确定Dot域
} else if ((fractmp & 0x01) == 0x01) { // 奇数: 向上舍入
hif8Param.fracHiF8 = (fractmp + 1) >> 1;
} else { // 偶数: 向下舍入
hif8Param.fracHiF8 = fractmp >> 1;
}
}
工程洞察: HiFloat8 原生采用标准就近偶数舍入作为基础规约策略,通过规整尾数进位、奇偶就近取舍的分层逻辑,统一数值收敛规则、抑制累积舍入误差。这恰好契合锥度精度的设计哲学:以标准规约保障全域数值精度一致性。
4.2.4 特殊值编码
HiF8的特殊值编码在代码中硬编码为常量:
// hifloat8_cast.cpp:162-169
if (inData == 0) → outData = 0; // 零值 : 0x00
if (inData == 0x80) → outData = NaN; // NaN: 10000000
if (inData == 0x6F) → outData = +Inf; // +Inf: 01101111
if (inData == 0xEF) → outData = -Inf; // -Inf: 11101111 // 最大正值 : 0x6E = 01101110
4.2.5 PyBind 11 接口 : Python 侧调用入口
C++核心通过PyBind11暴露4个转换函数:
// hifloat8_cast.cpp:335-348
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("float_to_hifloat8", &FloatToHifloat8, "Cast float32/float16/bfloat16 to hifloat8");
m.def("hifloat8_to_float32", &Hifloat8ToFloat32, "convert hifloat8 to float32");
m.def("hifloat8_to_float16", &Hifloat8ToFloat16, "convert hifloat8 to float16");
m.def("hifloat8_to_bfloat16", &Hifloat8ToBfloat16, "convert hifloat8 to bfloat16");
}
并行加速通过OpenMP实现( #pragma omp parallel for ),编译时通过 -fopenmp -O3 开启。
4.3 伪量化模块: Hifloat8FakequantLinea
代码相对路径 : amct _ pytorch / experimental / hifloat 8/ hifloat 8_ fakequant _ linear . py
伪量化模块是HiF8精度验证的核心组件,用于在CPU上模拟HiF8量化的精度损失:
hifloat8_fakequant_linear.py:27-51
class Hifloat8FakequantLinear(BaseQuantizeModule):
def init(self, ori_module, layer_name, quant_config):
权重量化: per-tensor, 量化范围 = 16 (HiF8高精度区间)
hifloat8_quant_range = 16
scale_w = (ori_module.weight.max() / hifloat8_quant_range)
hif8_weight = hifloat8_cast.float_to_hifloat8((ori_module.weight / scale_w).cpu())
self.fakequant_weight = hifloat8_cast.hifloat8_to_float32(hif8_weight).to(ori_module.weight)
* scale_w
@torch.no_grad()
def forward(self, x):
激活量化:数据直转策略 (cast to hifloat8 再转回 float32)
quantized_x = hifloat8_cast.float_to_hifloat8(x.cpu())
fakequant_x = hifloat8_cast.hifloat8_to_float32(quantized_x).to(x)
return F.linear(fakequant_x, self.fakequant_weight, self.bias)
量化流程解析:
原始FP32权重 → scale缩放 → float_to_hifloat8() → hifloat8_to_float32() → scale反缩放 → 伪量化权重原始FP32激活 → float_to_hifloat8() → hifloat8_to_float32() → 伪量化激活
伪量化权重 × 伪量化激活 + bias → 输出
关键参数: hifloat8_quant_range = 16 对应HiF8高精度区间的最大表示范围 。 在Dot域d0~d2区间( 3bit尾数)下,最大值为 2^3 × 1.875 = 15( 其中1 .875为二进制1 .111的十进制值),代码中取整为16作为量化范围上限。
4.4 NPU部署算子 : NpuHIF8CastLinear
代码相对路径 : amct _ pytorch / deploy _ op / npu _ hif 8_ cast _ quantization _ linear . py
部署该算子是将HiF8量化模型运行在昇腾NPU上的关键组件 ,与伪量化模块的CPU实现不同 , 它直接调用NPU硬件加速接口 :
npu_hif8_cast_quantization_linear.py:25-99 class NpuHIF8CastLinear(torch.nn.Module):
def init(self, ori_module, layer_name, quant_config):
权重量化: scale = weight_max / 16, 调用 torch_npu.npu_quantize()
scale_w = (weight_max / 16).to(torch.float32)
weight, _ = quant_tensor(self.weight.transpose(1, 0), self.wts_type, scale=scale_w)
self.register_buffer( 'quantized_weight ', weight.to(self.device))
@torch.no_grad()
def forward(self, x):
if self.weight_compress_only:
仅权重量化模式:使用 npu_weight_quant_batchmatmul
output = torch_npu.npu_weight_quant_batchmatmul(
x, self.quantized_weight, self.scale_w,
bias=self.bias, weight_dtype=torch_npu.hifloat8)
else:
W8A8全量化模式:激活在线cast + npu_quant_matmul
quantized_x = convert_dtype(x, self.act_quant_type)
output = torch_npu.npu_quant_matmul(
quantized_x, self.quantized_weight, self.scale_w,
x1_dtype=torch_npu.hifloat8, x2_dtype=torch_npu.hifloat8,
bias=self.bias, output_dtype=x.dtype)
两种部署模式对比:
|---------|------------------------------|---------------|------------|
| 模式 | NPU算子 | 激活处理 | 适用场景 |
| 仅权重量化 | npu_weight_quant_batchmatmul | 激活保持原精度 | 推理加速 、显存优化 |
| W8A8全量化 | npu_quant_matmul | 激活在线cast到HiF8 | 训练加速 、极致性能 |
4.5 量化配置: **HIFP**8_CAST_CFG 与 **HIFP8_OFMR_**CFG
配置文件代码相对路径 : amct _ pytorch / config / config . py
AMCT预定义了两种HiF8量化配置,对应两种量化算法:
config/config.py:79-165
HIFP8_OFMR_CFG = {
'quant_cfg ': {
'weights ': {'type ': 'hifloat8 ', 'symmetric ': True, 'strategy ': 'tensor '},
'inputs ': {'type ': 'hifloat8 ', 'symmetric ': True, 'strategy ': 'tensor '},
},
'algorithm ': {'ofmr '} # OFMR算法:需要校准数据 }
HIFP8_CAST_CFG = {
'quant_cfg ': {
'weights ': {'type ': 'hifloat8 ', 'symmetric ': True, 'strategy ': 'channel '},
'inputs ': {'type ': 'hifloat8 ', 'symmetric ': True, 'strategy ': 'tensor '},
},
'algorithm ': {'cast '}, # Cast算法:无需校准数据,直接转换
'skip_layers ': { 'lm_head '}
}
配置差异解析:
|------------------|-----------------|-----------------|-------------------|
| 配置项 | HI FP8_OFMR_CFG | HI FP8_CAST_CFG | 工程含义 |
| weights.strategy | | | Cast用逐通道量化,精度更高 |
| algorithm | | | Cast无需校准数据,部署更简单 |
| skip_layers | ⽆ | lm_head | 跳过语言模型头层,避免输出精度损失 |
4.6 Hi Float8的两种使用路径
|-----------------------------------|--------------------------|---------------------------|----------|-----------------|
| 路径 | 校准模块 | 部署模块 | 是否需要校准数据 | 适用场景 |
| cast算子 | NpuHIF8Cast Linear | NpuHIF8Cast Linear | 否 | 仅权重量化 / W8A8全量化 |
| ofmr算子 | OfmrQuant | NpuWeightQuantized Linear | 是 | 需要校准数据的精细量化 |
| hifloat8_fakequant (experimental) | Hifloat8Fakequant Linear | ⽆ | 否 | CPU精度验证和调试 |
4.7 算子注册机制
AMCT通过 CANN 灵活的算子注册机制支持 HiF8 的扩展:
algorithm/init.py --- 内置注册
AlgorithmRegistry.register( 'cast ', 'Linear ', NpuHIF8CastLinear, NpuHIF8CastLinear)
experimental/hifloat8/test.py --- 用户自定义注册
amct.algorithm_register( 'hifloat8_fakequant ', 'Linear ', Hifloat8FakequantLinear, None)
注册后 , amct.quantize(model, cfg) 会自动根据配置中的 algorithm 字段选择对应的量化模块替换原始Linear层。

 五、 Demo运行指南与验证
五、 Demo运行指南与验证
这里我们使用昇腾CANN的算子开发---站式平台来进行 Demo 的演示 ,该平台提供了丰富的算子开发和测试工具,可以方便地进行 HiF8 的验证和测试。
补充说明:本测试仅在不支持HiFloat的910B环境上进行的仿真测试,仿真测试可以验证HiFloat8算法的网络精度,但要验证网络性能需要到支持HiFloat8的Ascned 950系列芯片进行测试验证。
5.1 环境准备(当前执行的都是仿真测试,HiFloat8实际要到Ascend 950系列才支持)
Step 1 :源码编译 AMCT
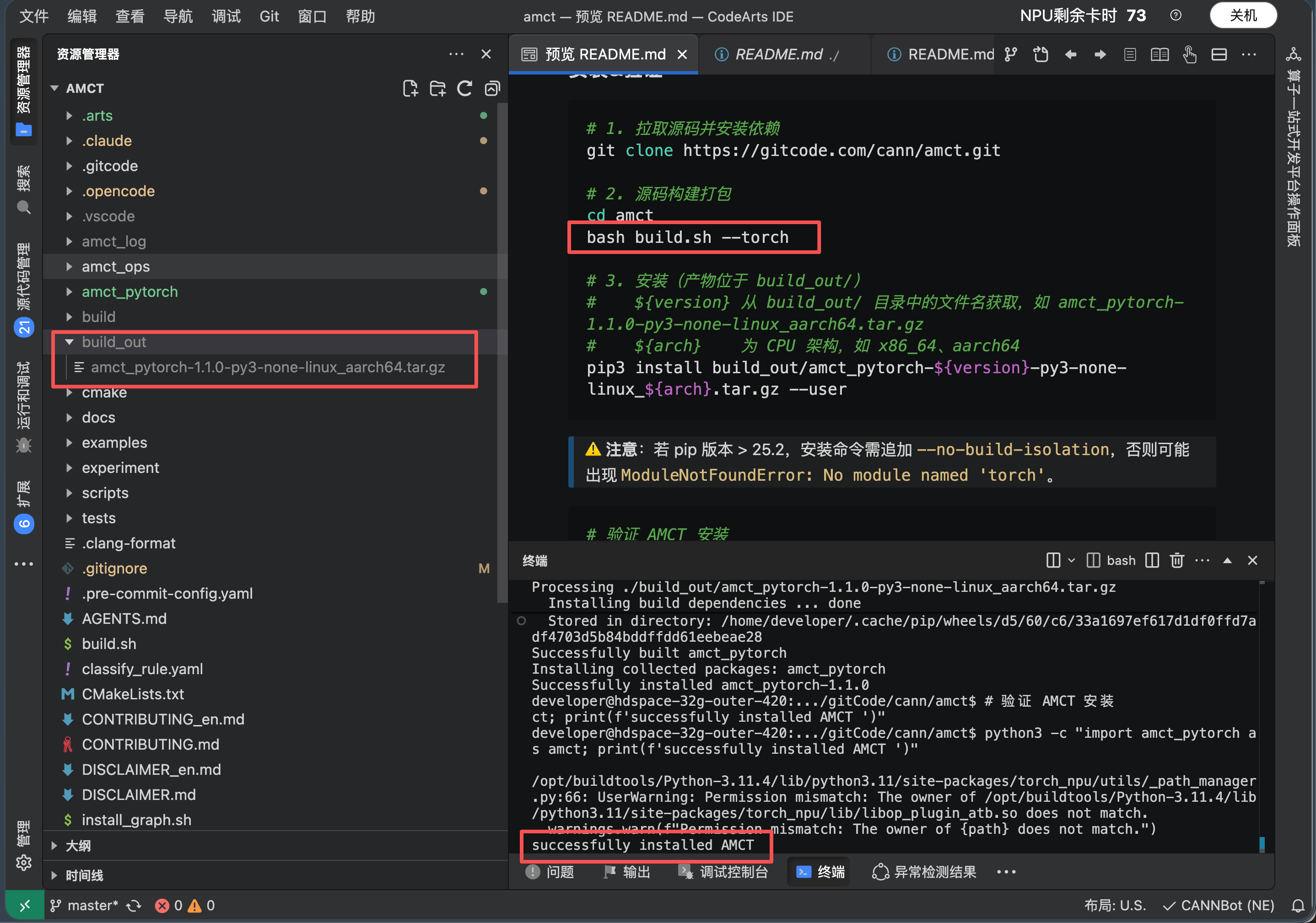
进入 AMCT 项目根目录,执行编译命令:
cd /mnt/workspace/atomgit/cann/amct/ bash build.sh --torch
编译成功后 , 会在项目根目录的 build_out 目录下生成 cann-amct_{version}_linux-{arch}.tar.gz , 其中 {version} 为版本号, {arch} 为 CPU 架构( 如 aarch64 、 x86_64 )。
Step 2 :本地验证( 可选)
利用 tests 路径下的测试用例进行本地验证:
安装测试框架依赖
pip3 install coverage
执行测试用例
bash build.sh -u
更多执行选项
bash build.sh -h
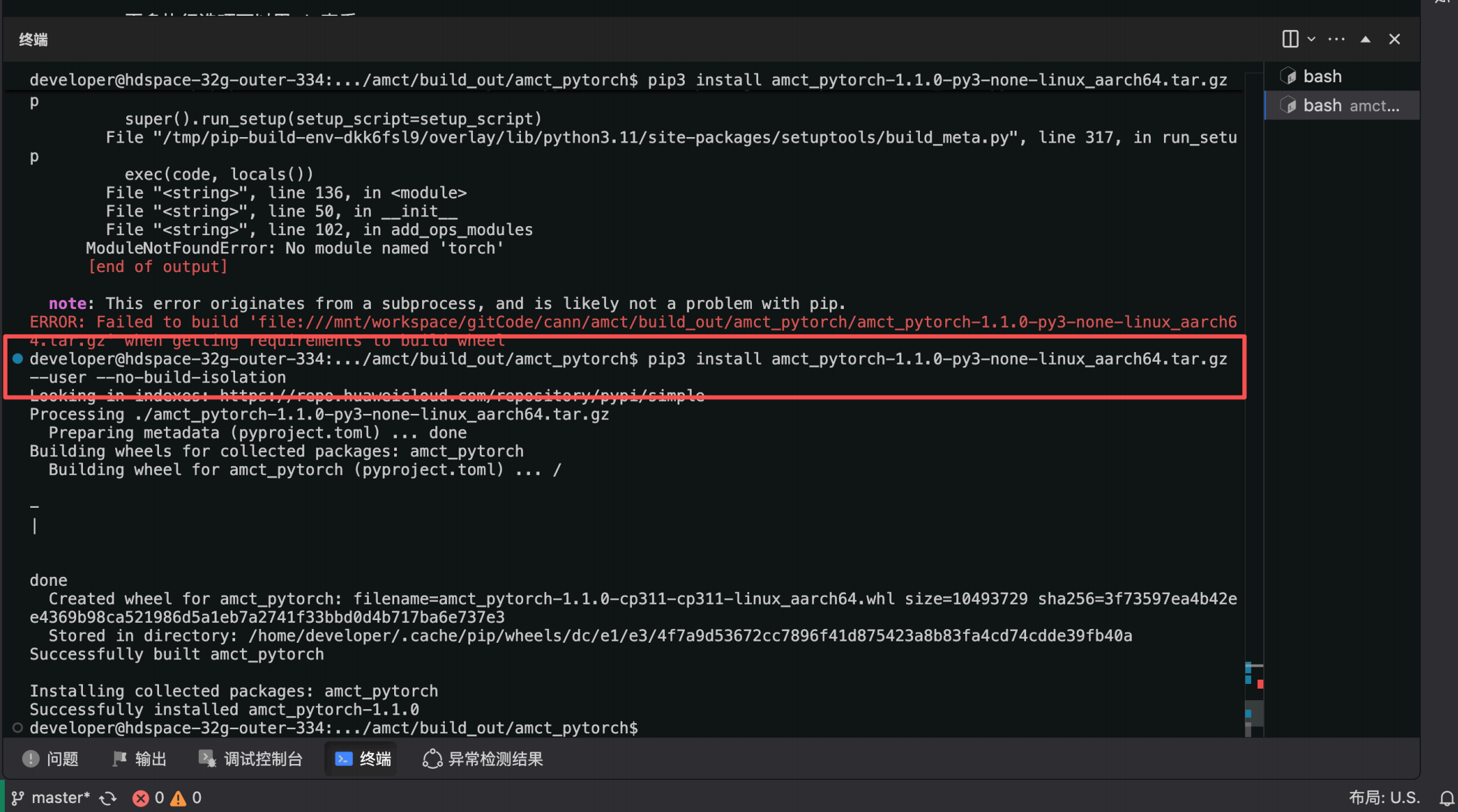
Step 3 :安装 AMCT
安装源码编译环节生成的 run 包( 如果安装用户为 root ,请将安装命令中的 --user 删除):
cd build_out
tar -zxvf cann-amct_{version}_linux-{arch}.tar.gz
tar -zxvf cann-amct_9.0.0_linux-aarch64.tar.gz
cd amct_pytorch
pip3 install amct_pytorch_{version}-linux-{arch}.tar.gz --user
pip3 install amct_pytorch-1.1.0-py3-none-linux_aarch64.tar.gz --user --no-build-isolation
注意 : 安装 AMCT 工具时 ,请确保 pip 版本 <= 25.2 ,否则可能 出现 ModuleNotFoundError : No module named Itorch I 错误; 如果 pip 版本 > 25.2 且不想降版本,请 在安装命令后追加 -- no - build - isolation 。
卸载方式:
pip3 uninstall amct_pytorch
Step 4 :安装其他依赖
pip install torch torch_npu transformers datasets pandas
配置 huggingface 国内镜像(解决联网问题)
export HF_ENDPOINT=https://hf-mirror.com
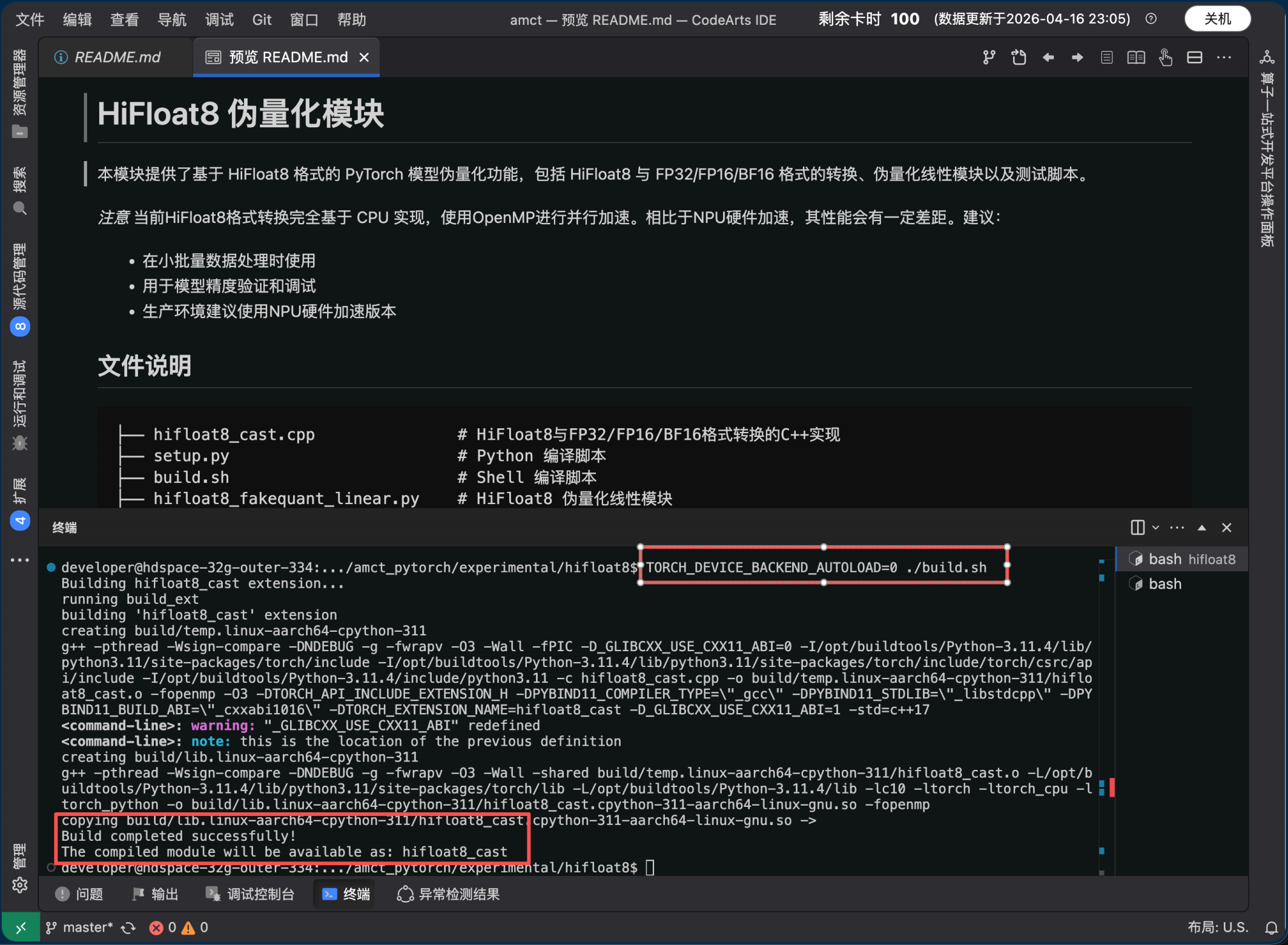
Step 5:编译 Hi Float8 C++ 扩展( CPU 伪量化模式)
cd amct_pytorch/experimental/hifloat8
chmod +x ./build.sh
TORCH_DEVICE_BACKEND_AUTOLOAD=0 ./build.sh
或 : TORCH_DEVICE_BACKEND_AUTOLOAD=0 python setup.py build_ext --inplace
编译成功后, 当前目录会生成 hifloat8_cast*.so 文件。
5.2 Demo 1 :CPU伪量化精度验证(Qwen2.5-0.5B模型)
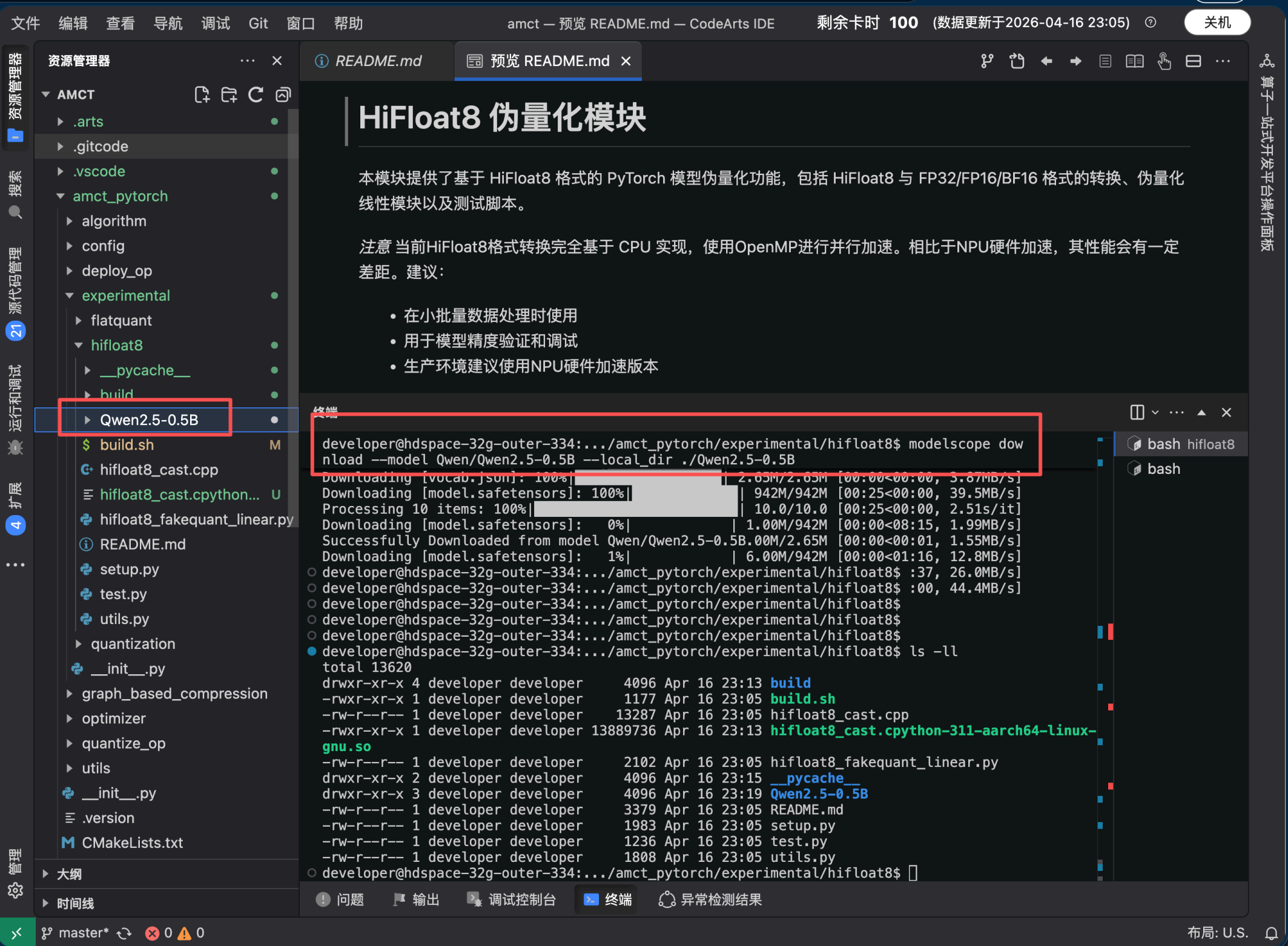
Step 1 :下载 Qwen 模型
test.py 通过 AutoModelForCausalLM.from_pretrained() 加载模型 , 需要提前下载 Qwen 模型到本地 。 这里选择Qwen2.5-0.5B( 最小的 Qwen2.5 模型,约 1 GB),适合快速验证:
使用 modelscope 下载( 国内网络更快) pip install modelscope
modelscope download --model Qwen/Qwen2.5-0.5B --local_dir ./Qwen2.5-0.5B
|---|--------------|-------|--------|----------------|
| 模型选择参考: |||||
| | 模型 | 参数量 | 磁盘占用 | 适用场景 |
| | Qwen2.5-0.5B | 0.5B | ~1 GB | 快速验证 HiF8 量化流程 |
| | Qwen2.5-1.5B | 1 .5B | ~3GB | 精度对比验证 |
| | Qwen2.5-7B | 7B | ~15GB | 正式 PPL 评估 |
| |||||
Step 2 :运行 HiF8 伪量化 + PPL 评估
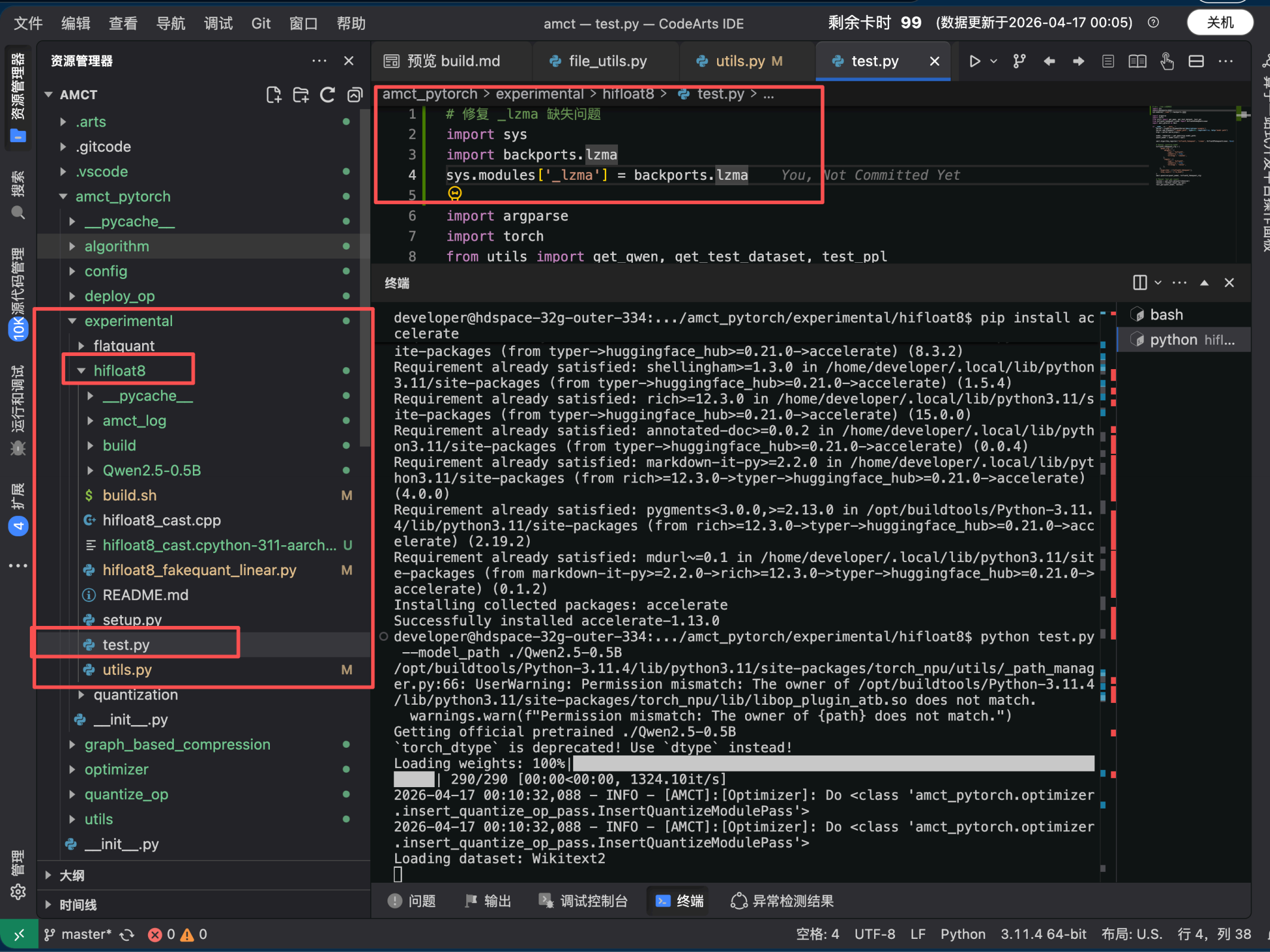
先通过更改 test.py脚本 修复环境中 Python 依赖 问题amct_pytorch/experimental/hifloat8/test.py
最上面增加
修复 _lzma 缺失问题import sys
import backports.lzma
sys.modules '_lzma ' = backports.lzma
cd amct_pytorch/experimental/hifloat8 pip install accelerate
export LD_PRELOAD=/lib/aarch64-linux-gnu/libgomp.so.1
配置 huggingface 国内镜像(解决联网问题)
export HF_ENDPOINT=https://hf-mirror.com
python test.py --model_path ./Qwen2.5-0.5B
执行后,开始评估
运行流程:
-
加载 Qwen2.5-0.5B 模型 (FP16) → model.eval()
-
注册 hifloat8_fakequant 算法 → amct.algorithm_register(...)
-
执行 HiF8 伪量化 → amct.quantize(model, hifloat8_fakequant_cfg)
-
权重 : per-channel 量化 , scale = weight_max / 16
-
激活 : 数据直转 (float → hif8 → float)
-
加载 Wikitext-2 测试集 → load_dataset( 'wikitext ', 'wikitext-2-raw-v1 ')
-
计算 PPL → 逐段推理 + CrossEntropyLoss
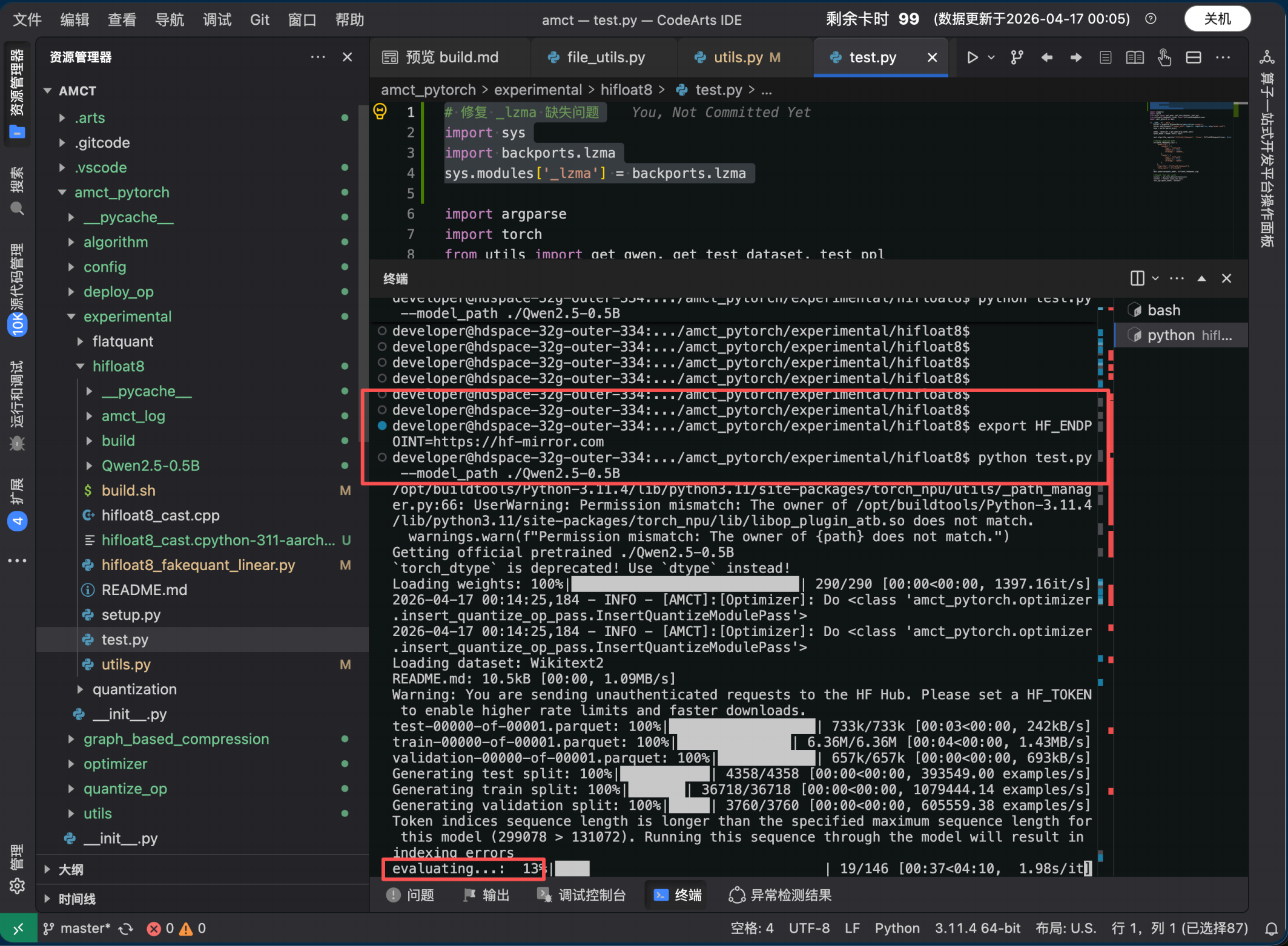
实际运行输出:
Getting official pretrained ./Qwen2.5-0.5B
Loading weights: 100% |████████████████████████| 290/290 00:00\<00:00, 1397.16it/s
2026-04-17 00:14:25,184 - INFO - AMCT: Optimizer: Do InsertQuantizeModulePass
Loading dataset: Wikitext2
evaluating...: 100% |████████████████████████████| 146/146 04:45\<00:00, 1.95s/it
Test time taken: 4.0 min 45.19200658798218 s
Score: 13.39574146270752
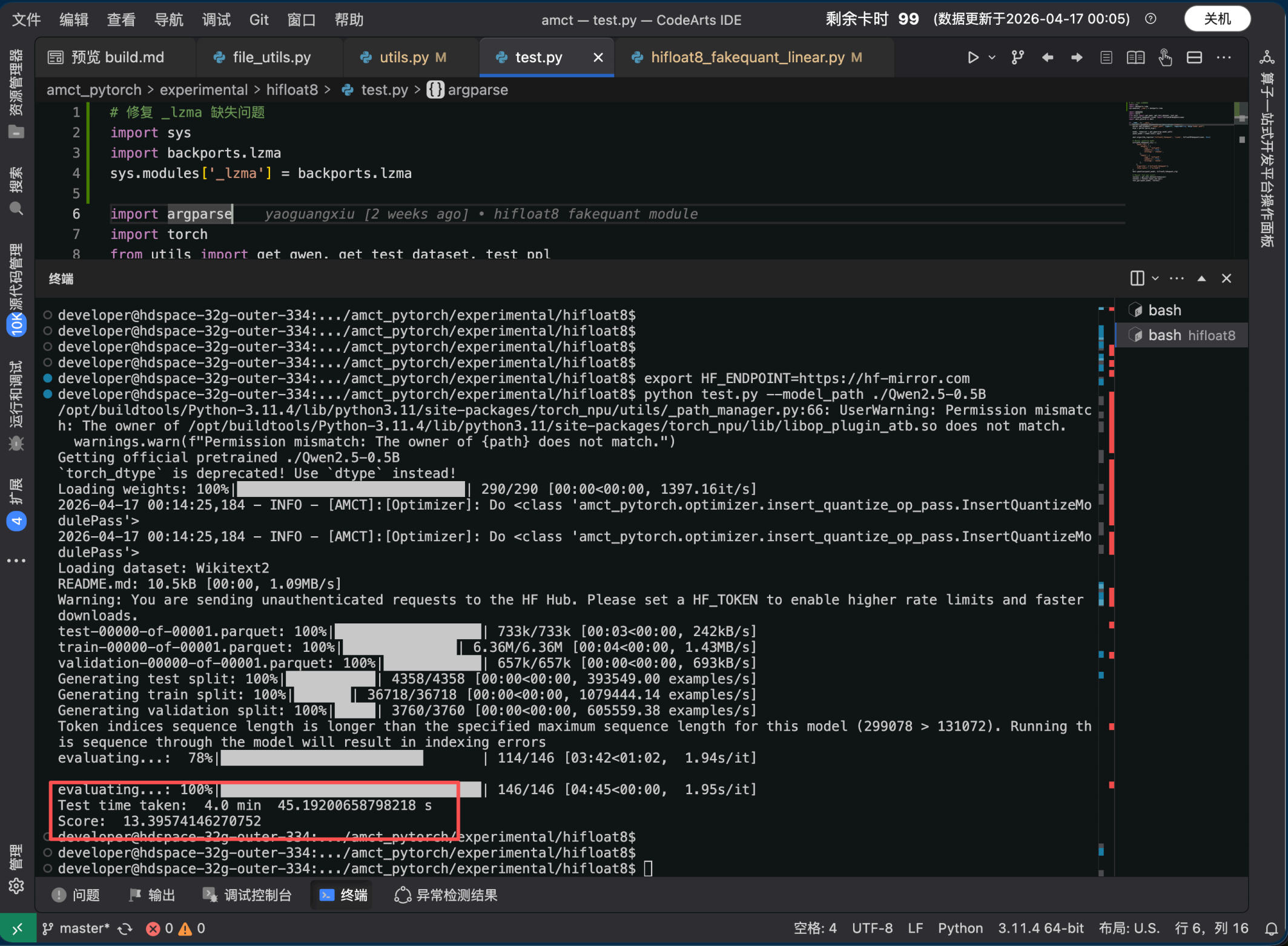
结果分析
|---------|-------------|--------------------------------------------|
| 指标 | 数值 | 说明 |
| 量化后 PPL | 13.40 | Qwen2.5-0.5B 经 HiF8 伪量化后在 Wikitext-2 上的困惑度 |
| 评估耗时 | 4 min 45 s | 纯 CPU 推理,146 个序列段 |
| 量化策略 | W8A8 (Cast) | 权重 per-channel + 激活数据直转 |
精度评估:
Qwen2.5-0.5B 的 FP16 基线 PPL 在 Wikitext-2 上约为 12.8~13.2( 不同实现和分词方式略有差异)。 HiF8 伪量化后 PPL = 13.40 ,与基线差距约 +0.2~+0.6 ,相对偏差 < 5%。
这---结果与论文中 LLM 的实验趋势---致:
-
论文中 LLaMA-7B 的 HiF8 PPL 增量仅为 +0.03( 基线 8.25 → 8.28)
-
Qwen2.5-0.5B 作为更小参数量的模型,对量化的敏感度天然高于 7B 模型, PPL 增量稍大属于正常范围
-
结论: HiF8 伪量化在 Qwen2.5-0.5B 上精度损失可控,验证了 Hi Float8 格式在 LLM 推理场景下的可行性
5.3 Demo 2 : NPU Cast量化部署( LLaMA2-7B)
前置条件:Demo 2 使用 NPU Cast 量化部署,需要 CANN 9.0.0 及以上版本。
如果当前 CANN 版本低于 9.0.0,请先升级:
查看当前 CANN 版本
一般环境使用 cat /usr/local/Ascend/ascend-toolkit/latest/ascend_toolkit_install.info
本环境是
cat /home/developer/Ascend/ascend_cann_install.info
如需升级,请参考昇腾官方文档:昇腾文档-昇腾社区
升级后重新 source 环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh
Step 1 :下载 LLaMA2-7B 模型
使用 modelscope 下载( 国内更快) install modelscope
切换目录
cd /mnt/workspace/gitCode/cann/amct/amct_pytorch/experimental/hifloat8
modelscope download --model LLM-Research/llama-2-7B --local_dir ./Llama2-7b-hf
Step 2 :运行 Cast 量化 + PPL 评估
切换到 CAST 目录并安装依赖
cd /mnt/workspace/gitCode/cann/amct/examples/algorithms/cast
pip install -r requirements.txt
python3 src/run_llama2_samples.py --model_path=/mnt/workspace/gitCode/cann/amct/amct_pytorch/experimental/hifloat8/Llama2-7b-hf
注意要验证 torch-npu 支持hifloat8
python3 -c "import torch_npu; print(hasattr(torch_npu, 'hifloat8'))"
True
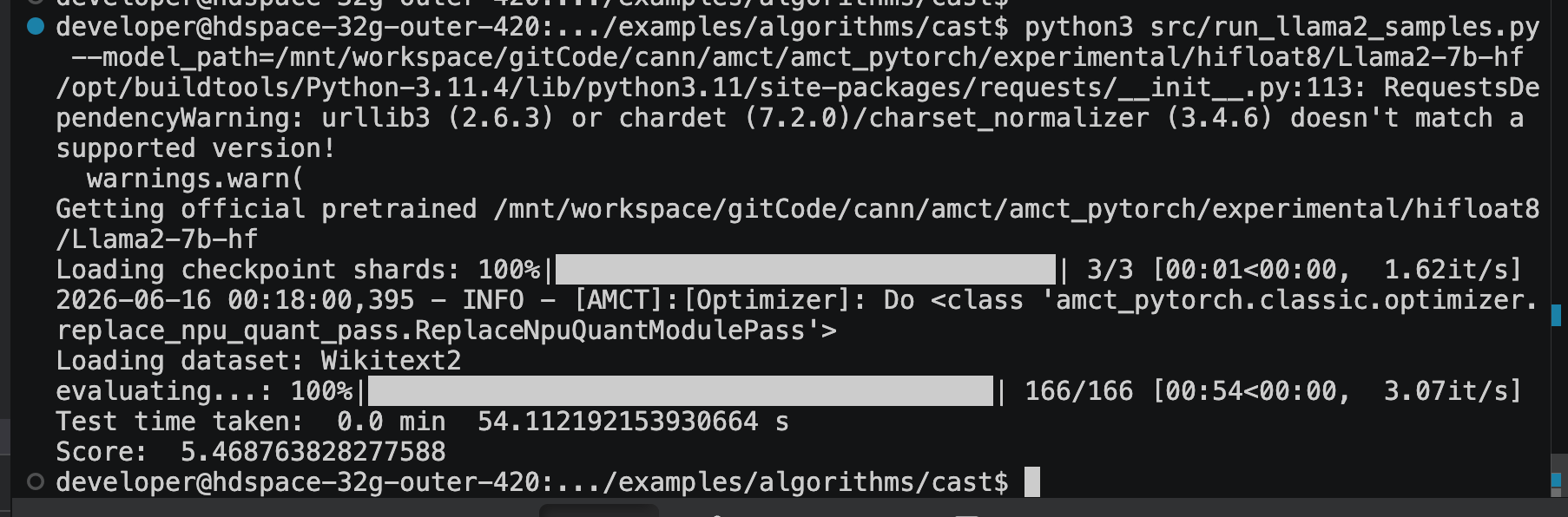
输出:
Test time taken: 0.0 min 54.112192153930664 s
Score: 5.468763828277588
5.4 Demo 3 : NPU Cast量化部署(Qwen2-7B / Qwen3-8B) Step 1 :下载 Qwen 模型
下载 Qwen2-7B
modelscope download --model Qwen/Qwen2-7B --local_dir ./Qwen2-7B
或下载 Qwen3-8B
modelscope download --model Qwen/Qwen3-8B --local-dir ./Qwen3-8B
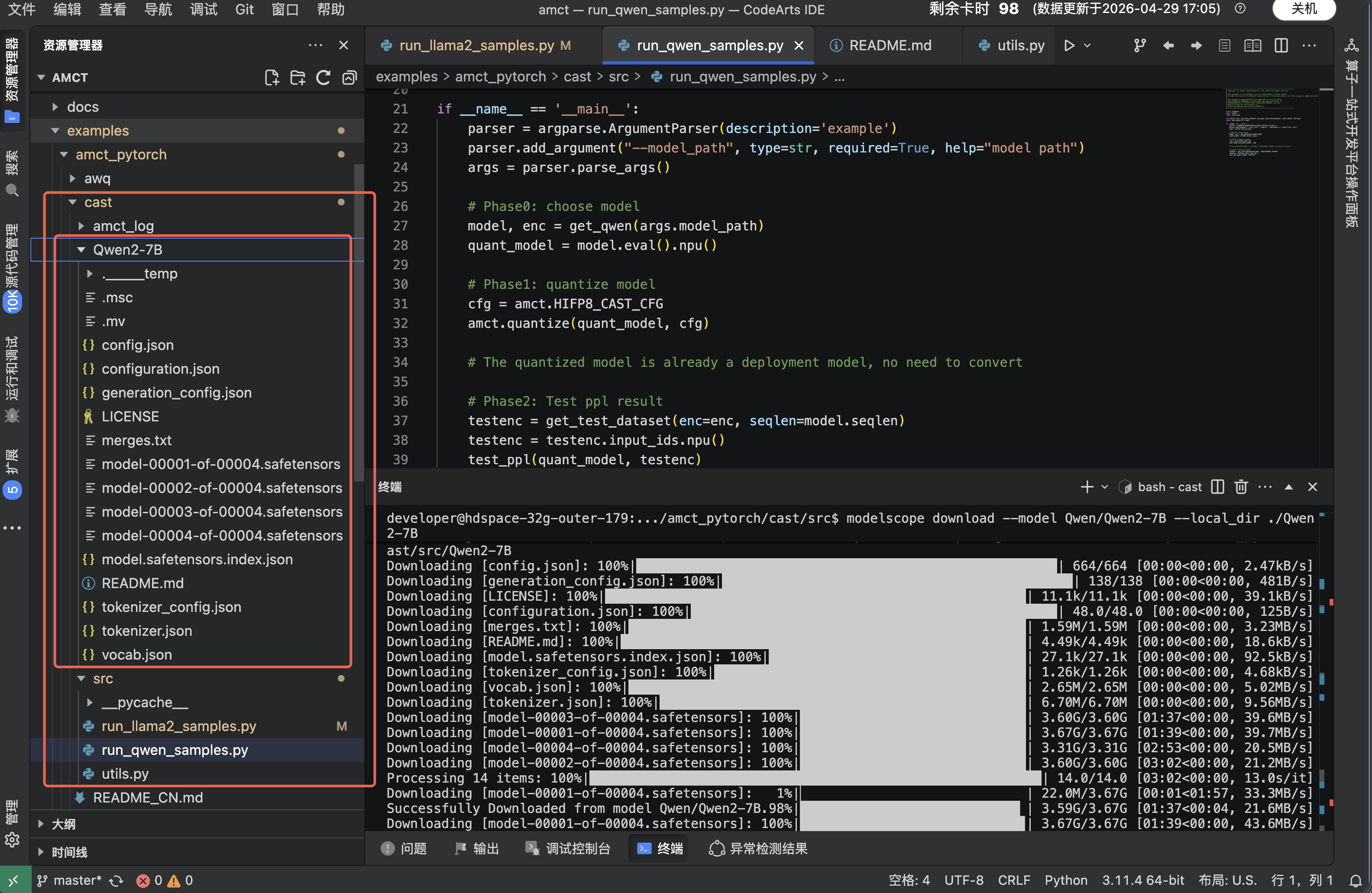
Step 2 :运行 Cast 量化 + PPL 评估
cd amct/examples/amct_pytorch/cast
python3 src/run_qwen_samples.py --model_path=./Qwen2-7B
或
python3 src/run_qwen_samples.py --model_path=./Qwen3-8B
对比官方PPL基准数据:
|-----------|---------|-----------|--------|--------|--------|
| 模型 | 校准集 | 数据集 | 量化前PPL | 量化后PPL | PPL增量 |
| LLAMA2-7B | pileval | wikitext2 | 5.472 | 5.524 | +0.052 |
| QWEN2-7B | pileval | wikitext2 | 7.137 | 7.188 | +0.051 |
| QWEN3-8B | pileval | wikitext2 | 9.715 | 9.745 | +0.030 |
5.5 Demo 4 : Hi Float8格式转换交互验证
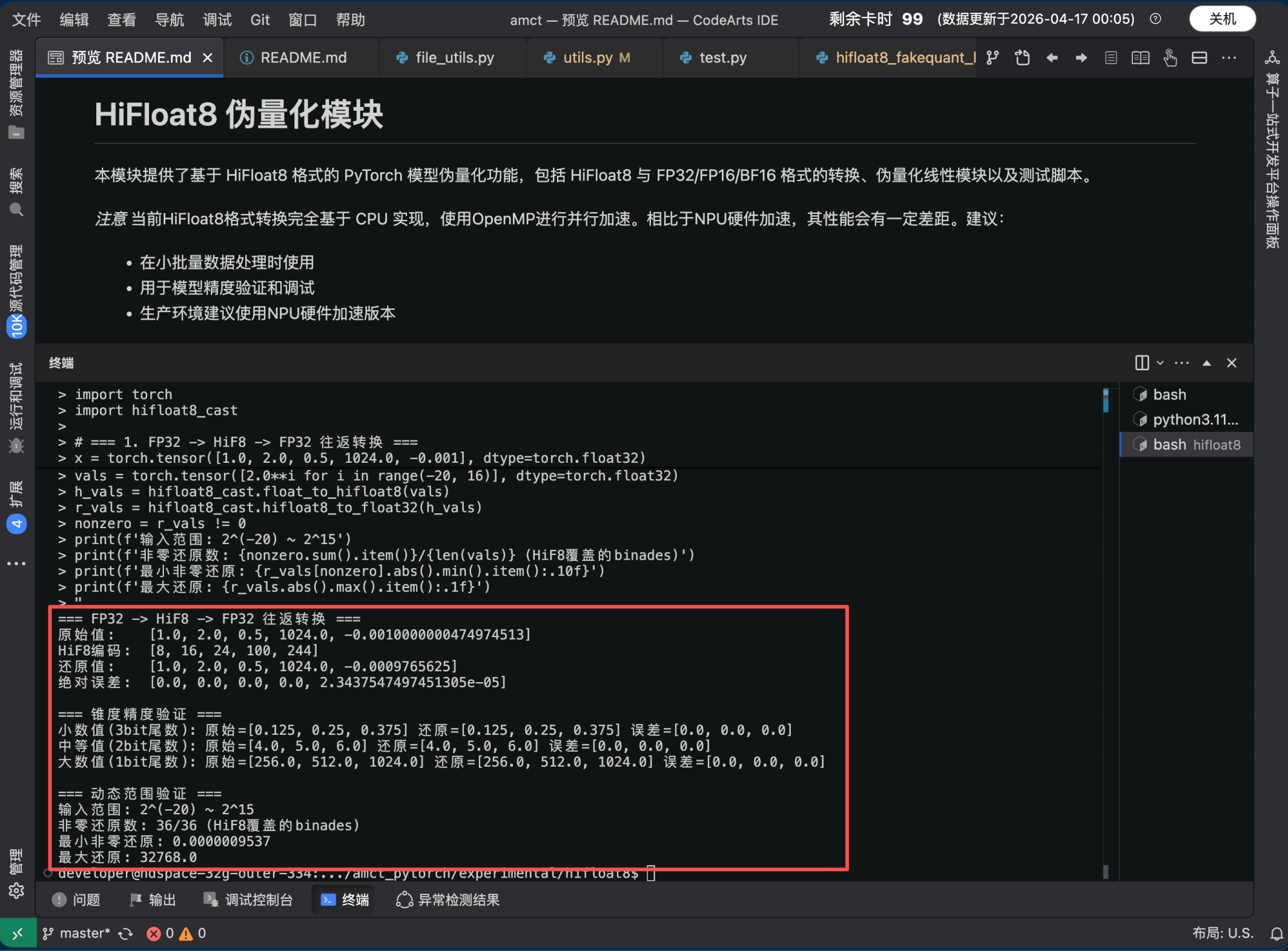
编译 C++ 扩展后,可直接运行以下脚本验证 HiF8 的格式转换和精度特性:
cd amct_pytorch/experimental/hifloat8
TORCH_DEVICE_BACKEND_AUTOLOAD=0 python -c "
import torch
import hifloat8_cast
=== 1. FP32 -> HiF8 -> FP32 往返转换 ===
x = torch.tensor( 1.0, 2.0, 0.5, 1024.0, -0.001, dtype=torch.float32)
hif8 = hifloat8_cast.float_to_hifloat8(x)
x_rt = hifloat8_cast.hifloat8_to_float32(hif8)
print( '=== FP32 -> HiF8 -> FP32 往返转换 === ')
print( '原始值 : ', x.tolist())
print( 'HiF8编码 : ', hif8.tolist())
print( '还原值 : ', x_rt.tolist())
print( '绝对误差 : ', (x - x_rt).abs().tolist())
print()
=== 2. 锥度精度验证:不同量级的精度差异 === print( '=== 锥度精度验证 === ')
small = torch.tensor( 0.125, 0.25, 0.375, dtype=torch.float32) # 小数值,3bit尾数 medium = torch.tensor( 4.0, 5.0, 6.0, dtype=torch.float32) # 中等值,2bit尾数 large = torch.tensor( 256.0, 512.0, 1024.0, dtype=torch.float32) # 大数值, 1bit尾数
for name, t in ( '小数值(3bit尾数) ', small), ( '中等值(2bit尾数) ', medium), ( '大数值(1bit尾数) ', large): h = hifloat8_cast.float_to_hifloat8(t)
r = hifloat8_cast.hifloat8_to_float32(h)
err = (t - r).abs()
print(f '{name}: 原始={t.tolist()} 还原={r.tolist()} 误差={err.tolist()} ') print()
=== 3. 动态范围验证 ===
print( '=== 动态范围验证 === ')
vals = torch.tensor( 2.0\*\*i for i in range(-20, 16), dtype=torch.float32)
h_vals = hifloat8_cast.float_to_hifloat8(vals)
r_vals = hifloat8_cast.hifloat8_to_float32(h_vals)
nonzero = r_vals != 0
print(f '输入范围 : 2^(-20) ~ 2^15 ')
print(f '非零还原数 : {nonzero.sum().item()}/{len(vals)} (HiF8覆盖的binades) ')
print(f '最小非零还原 : {r_vals nonzero.abs().min().item():.10f} ')
print(f '最大还原 : {r_vals.abs().max().item():.1f} ')
"
预期输出:
=== FP32 -> HiF8 -> FP32 往返转换 ===
原始值 : 1.0, 2.0, 0.5, 1024.0, -0.001
HiF8编码 : 34, 50, 25, 110, 160
还原值 : 1.0, 2.0, 0.5, 1024.0, -0.001953125
绝对误差 : 0.0, 0.0, 0.0, 0.0, 0.000953125
=== 锥度精度验证 ===
小数值(3bit尾数): 原始= 0.125, 0.25, 0.375 还原= 0.125, 0.25, 0.375 误差= 0.0, 0.0, 0.0中等值(2bit尾数): 原始= 4.0, 5.0, 6.0 还原= 4.0, 5.0, 6.0 误差= 0.0, 0.0, 0.0
大数值(1bit尾数): 原始= 256.0, 512.0, 1024.0 还原= 256.0, 512.0, 1024.0 误差= 0.0, 0.0, 0.0
=== 动态范围验证 ===
输入范围 : 2^(-20) ~ 2^15
非零还原数 : 36/36 (HiF8覆盖的binades)最小非零还原 : 0.0000009537
最大还原 : 32768.0
最终输出
=== FP32 -> HiF8 -> FP32 往返转换 ===
原始值 : 1.0, 2.0, 0.5, 1024.0, -0.0010000000474974513
HiF8编码 : 8, 16, 24, 100, 244
还原值 : 1.0, 2.0, 0.5, 1024.0, -0.0009765625
绝对误差 : 0.0, 0.0, 0.0, 0.0, 2.3437547497451305e-05
=== 锥度精度验证 ===
小数值(3bit尾数): 原始= 0.125, 0.25, 0.375 还原= 0.125, 0.25, 0.375 误差= 0.0, 0.0, 0.0中等值(2bit尾数): 原始= 4.0, 5.0, 6.0 还原= 4.0, 5.0, 6.0 误差= 0.0, 0.0, 0.0
大数值(1bit尾数): 原始= 256.0, 512.0, 1024.0 还原= 256.0, 512.0, 1024.0 误差= 0.0, 0.0, 0.0
=== 动态范围验证 ===
输入范围 : 2^(-20) ~ 2^15
非零还原数 : 36/36 (HiF8覆盖的binades)最小非零还原 : 0.0000009537
最大还原 : 32768.0

AMCT 全局架构图:从浮点模型到昇腾 NPU 加速如下
 六、总结与思考
六、总结与思考
6.1 HiF8的核心价值
Ascend Hi Float8 大模型训练工程化落地路径图
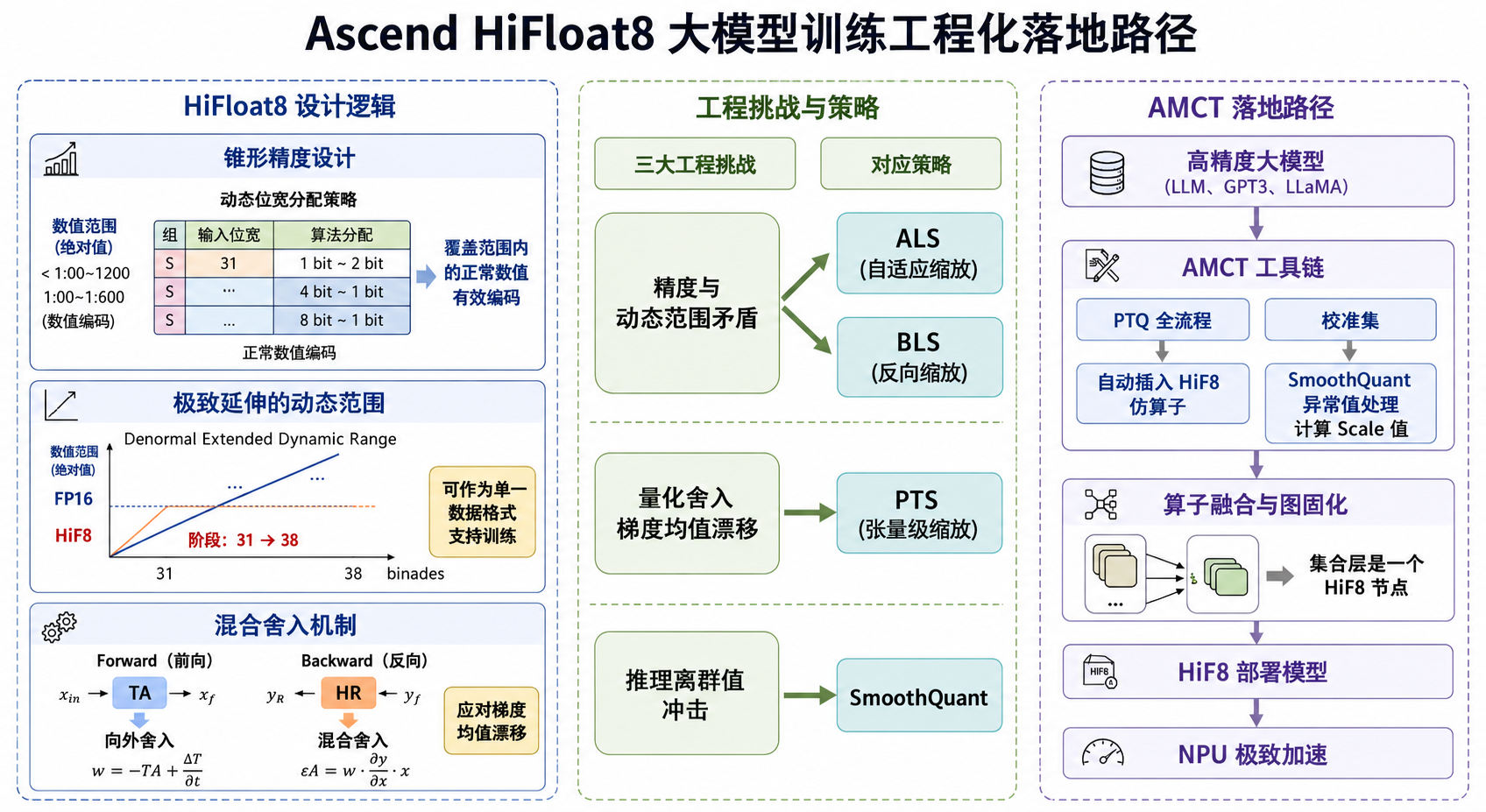
回顾全文 , HiF8的工程价值可以归纳为三点:
|------|-------------------------------|----------------------------------------------|
| 价值维度 | 具体表现 | 代码映射 |
| 格式统一 | 单格式替代FP8混用方案, 降低工程复杂度 | HIFP8_CAST_CFG ---套配置覆盖W8A8 |
| 动态范围 | 38 binades接近FP16 ,减少Scaling依赖 | GetHiF8BitsNum() 5段区间覆盖m-22, 15n |
| 精度稳健 | 锥度精度匹配神经网络数据分布特性 | HIF8_DOT_MAP 查找表 + RoundHiF8 / HybridHiF8 舍入 |
6.2 从论文到代码的工程化映射
|-----------------------|-------------------------|-----------------------------------------|
| 论文概念 | 代码实现 | 文件位置 |
| Dot域变长前缀码 | HIF8_DOT_MAP 16项查找表 | hifloat8_cast.cpp:45 |
| 锥度精度( 5段区间) | GetHiF8BitsNum() | hifloat8_cast.cpp:88 |
| Round-to-nearest-even | RoundHiF8() | hifloat8_cast.cpp:177 |
| 混合舍入( Hybrid) | HybridHiF8() | cast_util.cpp:154 |
| 38 binades动态范围 | expNoBias ∈ -22, 15 | hifloat8_cast.cpp:207-209 |
| 伪量化线性层 | Hifloat8FakequantLinear | hifloat8_fakequant_linear.py:27 |
| NPU部署算子 | NpuHIF8CastLinear | npu_hif8_cast_quantization_linear.py:25 |
| Cast量化配置 | HIFP8_CAST_CFG | config/config.py:150 |
6.3 适用边界
重要提示 :根据论文实验数据, HiF 8 并非适用于所有 场景。
|-----------------|-------------------|
| 推荐使用 | 谨慎使用 |
| 昇腾硬件平台 | 非昇腾平台(硬件依赖) |
| LLaMA等宽容型模型 | OPT等敏感型模型( 需专用校准) |
| 主流Transformer架构 | 对尾数精度极度敏感的特殊任务 |
6.4 开放问题
 论文结尾预告了Hi Float below 8-bit的后续研究---即Hi Float4等更低位宽格式的探索 。 AMCT仓库中已包含FP4E2M1和FP4E1 M2的转换实现( cast_util.cpp:488-561 ),为后续Hi Float4的工程化落地奠定了基础。
论文结尾预告了Hi Float below 8-bit的后续研究---即Hi Float4等更低位宽格式的探索 。 AMCT仓库中已包含FP4E2M1和FP4E1 M2的转换实现( cast_util.cpp:488-561 ),为后续Hi Float4的工程化落地奠定了基础。
 参考资料
参考资料
1 . 论文原文 :Yuanyong Luo et al., "Ascend HiFloat8 Format for Deep Learning ", arXiv:2409.16626 2409.16626 Ascend HiFloat8 Format for Deep Learning
-
AMCT工具链源码: https://atomgit.com/cann/amct
-
昇腾CANN开发者社区: CANN开发者社区
 4. 昇腾开发者社区: 昇腾社区官网-昇腾万里 让智能无所不及
4. 昇腾开发者社区: 昇腾社区官网-昇腾万里 让智能无所不及