根据论文PAIWorld: A 3D-Consistent World Foundation Model for Robotic Manipulation整理
世界基础模型(World Foundation Models, WFMs)正在快速从单点观察的潜在动态模块,演进为能够模拟复杂物理环境的大规模视频生成系统。然而,当这些模型面向机器人操作场景时,一个根本性的挑战浮现出来:现有的世界模型大多以单视角视频为媒介,缺乏机器人系统所必需的多视角三维一致性。针对这一问题,中国科学院工业人工智能研究所的研究团队提出了PAIWorld框架,通过构建显式的跨视角通信通路并引入三维几何监督信号,显著提升了多视角视频生成中的三维一致性,在机器人操作基准测试中取得了领先成绩。
一、从单视角模拟到多视角具身智能
近年来,以Sora、Cosmos、CogVideoX、Wan等为代表的大规模视频扩散模型,展示了学习物理世界动态规律的惊人潜力。这些模型通过在像素或潜空间中对未来视觉观测进行预测,能够生成时间连贯、物理合理的视觉推演序列,为基于模型的规划、策略进化以及数据合成提供了强有力的支撑。特别是NVIDIA推出的Cosmos平台,基于扩散Transformer(DiT)架构,在互联网规模数据上训练,为物理AI应用提供了高质量的世界模拟能力。
然而,机器人操作系统的感知方式与消费级视频场景存在本质差异。在真实的机器人平台中,腕部相机、第三视角相机、眼在手相机等多路视觉源同时工作,为策略学习提供互补的几何与语义线索。当世界模型作为这类系统的模拟器时,它必须在所有视角上同时生成未来观测,并维持严格的三维一致性:同一物体在不同视角中应处于几何兼容的位置,深度与纹理信息应当连贯一致。任何跨视角的物体漂移、深度矛盾或纹理错位,都会直接削弱推演轨迹的物理可信度,并将误差传播到下游的规划与控制环节。
现有的多视角世界建模方法尚不能满足这一需求。单视角模型如Cosmos、CogVideoX、Vista等虽然在时序预测上表现优异,但架构上天然受限于单一视角。部分支持多视角输入的方法,如Genie和iVideoGPT,通常采用将不同视角的token在序列维度上简单拼接的策略。这种"扁平拼接"方式将多视角token与时序token等同对待,未引入任何显式的跨视角几何推理机制,导致模型必须完全依赖数据驱动来隐式发现视角间的对应关系。随着视角数量增加与场景复杂度提升,这种隐式学习的可靠性迅速下降。
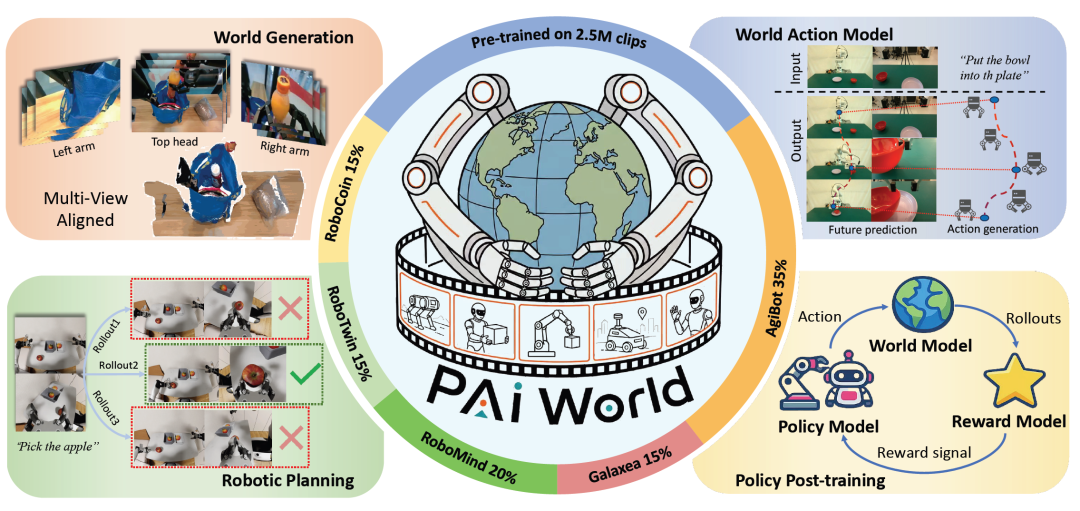
图1 PAIWorld是一个面向机器人操作的三维一致多视角世界基础模型,在2.5M多视角视频片段上预训练,可支撑多视角世界生成、世界行动模型、机器人规划以及策略后训练等下游应用
二、三维一致性缺失的根源:两大根本性缺陷
研究团队对现有方法的失效模式进行了深入追溯,将其归因于两个层面的根本性缺陷。第一,缺乏显式的跨视角通信机制。扁平拼接并未为不同视角提供专门的信息交换通道,每个视角的token在注意力计算中无法区分同视角与跨视角token,导致各视角在生成过程中事实上处于相互隔离的状态,无法协调预测或消解跨视角冲突。第二,缺乏三维几何先验。即便存在通信通路,如果没有监督信号指明几何正确的跨视角结构应当具备何种特征,模型很容易退化为表面捷径------例如简单地在视角间复制纹理或匹配颜色直方图------而非学习真正的三维结构。
这一分析揭示了一个关键洞察:架构层面的通信通路与训练目标层面的几何监督必须同时存在,二者缺一不可。仅有通信通路而无几何引导,信息流动无法保证内容的三维合理性;仅有几何先验而无跨视角通路,各视角虽能提升自身的三维感知,但约束条件无法传播到其他视角,跨视角不一致性依然持续。唯有当两者协同工作时,系统才能实现真正的多视角三维一致性:通路负责传输信息,而监督目标确保这些信息在几何上可靠。
三、PAIWorld的技术框架:两大支柱与三大组件
基于上述分析,PAIWorld在DiT流匹配世界基础模型之上,构建了两个技术支柱,通过三个轻量级模块化组件实现。第一支柱为跨视角通信通路,由两个协同工作的组件构成:几何感知跨视角注意力(Geometry-Aware Cross-View Attention)模块在DiT中开辟了显式的视角间信息交换通道;几何旋转位置编码(Geometric Rotary Position Embedding, Geo-RoPE)则将相机光线方向与外参位姿编码进注意力机制,使通路倾向于沿几何对应的token路由信息。第二支柱为几何学习目标,由潜在三维REPA(Latent 3D-REPA)实现,它通过将DiT的中间表征与冻结的三维基础模型(Depth Anything 3)提取的三维感知特征对齐,为跨视角交互提供几何监督信号。
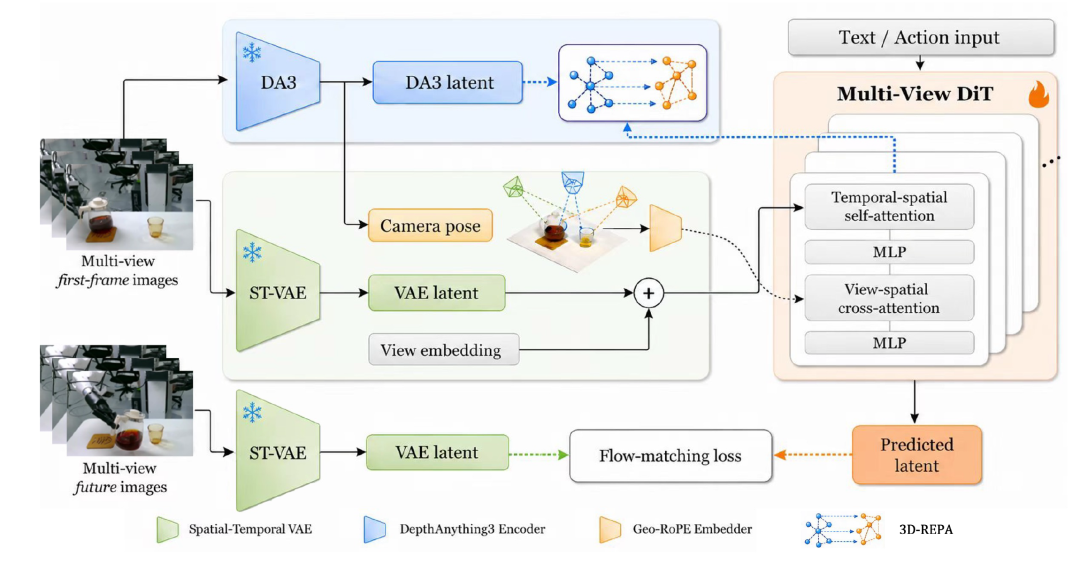
图2 PAIWorld框架概览。基于DiT流匹配骨干网络,两大技术支柱通过三个组件实现:支柱一包括几何感知跨视角注意力与Geo-RoPE;支柱二为Latent 3D-REPA,从Depth Anything 3提取三维感知特征提供监督
3.1 问题设定与基础架构
在形式化层面,考虑一个配备V个相机的机器人操作系统,每个相机提供视频流。在时刻t,系统观测到一组图像及其对应的相机内参与外参。给定条件信号(文本描述或动作序列)以及上下文帧,多视角视频生成的目标是建模条件分布。除了单视角的保真度之外,生成的多视角视频必须满足多视角三维一致性要求:在每一时刻,所有视角应当能够对应到一个连贯的三维场景,即同一三维位置在不同视角中的投影必须满足底层极线几何约束。
PAIWorld采用基于DiT的流匹配目标,在预训练视频VAE的潜空间中运行。遵循Wan2.1的设计,空间-时间VAE将视频在时空维度上压缩为紧凑的潜表征,显著降低了token数量,使多视角视频建模成为可能。条件信号通过自适应层归一化(AdaLN)注入DiT块。对于动作条件生成,研究团队将机器人动作渲染为空间动作图,沿通道维度与噪声潜变量拼接,使模型能够在像素空间中理解动作语义,而非从抽象向量中学习隐式映射。
3.2 几何旋转位置编码 Geo-RoPE
为了将三维几何信息编码进注意力机制,PAIWorld引入了Geo-RoPE,通过旋转位置编码分别处理像素级光线方向与视角级相机位姿。对于每个注意力头,查询与键向量被均分为两个子空间:光线子空间与位姿子空间,每个子空间接收独立的几何编码。
在光线子空间中,对于视角v中空间位置(h,w)处的token,研究团队通过相机内参将像素反投影至世界空间,并经过相机旋转的逆变换归一化得到三维光线方向。该方向被循环扩展以填充频率槽位,作为RoPE旋转的位置坐标。在位姿子空间中,每个视角提取一个12维的位姿特征向量,涵盖欧拉角、平移向量、相机中心位置以及光轴方向,该向量在视角内所有空间位置共享。这种双分量设计确保光线子空间捕获细粒度的像素级几何对应关系,而位姿子空间编码视角级身份,避免空间变化信号与空间均匀信号之间的干扰。
3.3 几何感知跨视角注意力
标准DiT块中的时序自注意力在每个视角内独立运行,未提供显式的跨视角交互。为打开跨视角通信通路,PAIWorld在选定的DiT层中插入专用的跨视角注意力子块。对于每个时刻,所有视角的特征图首先经过投影,随后由Geo-RoPE根据各自相机几何进行旋转。由于每个视角按照自身几何旋转,视角v的查询与视角v'的键仅当二者观测同一三维点时获得高内积,几何对应的跨视角token自然获得更高的注意力权重。门控机制通过AdaLN-Zero初始化为零,确保预训练的单视角模型权重在初始化时被精确保留,新模块在训练过程中逐步发挥作用。
此外,周期性的空间拼接自注意力将视角与空间维度展平为单一token轴,在同一时刻内对所有空间位置与所有视角执行联合的时空自注意力,为跨视角块提供更广的感受野。然而,研究团队明确指出,架构通路本身并不充分:它仅塑造了信息流动的方式,却无法规定内容的三维一致性。没有显式几何目标,通路仍可能退化为纹理复制或特征平均等捷径。
3.4 潜在三维REPA:几何监督信号
为跨视角交互提供几何学习信号,PAIWorld提出了Latent 3D-REPA,一种token关系蒸馏目标,用于将DiT的中间表征与冻结三维基础模型的特征对齐。研究团队采用Depth Anything 3作为三维感知特征提取器,该模型能够从任意视角图像中恢复深度、三维点云图以及相机内外参,编码了丰富的几何先验。
蒸馏过程不直接回归三维特征,而是监督token之间的关系结构。在DiT的选定中间层,特征图经过轻量级三维卷积投影头映射到目标维度,与Depth Anything 3的冻结特征构成对应。由于两个编码器的特征空间存在差异,直接对齐绝对值并不合适,因此团队监督token间的成对余弦相似度矩阵。为降低计算开销,采用锚点采样策略:随机选取K个锚点token,计算所有token与每个锚点的相似度,形成采样相似度矩阵。空间项在单帧内操作,捕获帧内的几何关系;时序项在整段视频上操作,捕获跨帧关系。随机锚点采样将复杂度从二次降至线性,同时保留了有效的梯度信号。
3.5 联合机制:通路监督的协同
两个支柱的耦合形成了强化循环。Geo-RoPE将各视角置于共享的三维坐标系中,使跨视角注意力能够在几何对应位置交换信息;Latent 3D-REPA确保交换的内容具有几何意义,因为共同的参考框架使监督约束能够连贯地传播到所有视角,而非坍缩为单视角捷径。消融实验验证了二者组合的超加性效应:单独添加通信通路或几何目标仅带来有限的指标提升,而同时启用两者时,三维一致性指标实现了远超各自增益之和的跃升。
四、实验验证与基准测试
PAIWorld基于Cosmos-Predict2.5构建,拥有约14B参数,采用Cosmos-Reason1作为文本条件编码器。模型在约250万段多视角机器人操作视频上预训练,数据来源包括AgiBot-World(35%)、RoboMIND(20%)、Galaxea(15%)、RoboTwin(15%)和RoboCOIN(15%),涵盖多样化的本体形态、操作任务与相机配置。训练在200张NVIDIA H200 GPU上进行,共30,000次迭代,耗时约7天。
4.1 WorldArena基准:综合排名第一
WorldArena基准提供了七项细粒度指标,从多个维度分解世界模型质量。PAIWorld在该基准上取得了综合排名第一的成绩,EWMScore达到70.67%,相较第二名GenieEnvisioner-Sim2.0-2B的68.26%拉开了2.41个百分点的明显差距。尤其在Motion Quality(动作质量)指标上,PAIWorld以79.66%的成绩大幅领先,反映了其在动作条件推演中对时间连贯、物理合理动态的强大建模能力。这一优势直接对应了框架在跨视角几何一致性上的设计目标,因为物理合理的推演必须以准确的三维结构为基础。
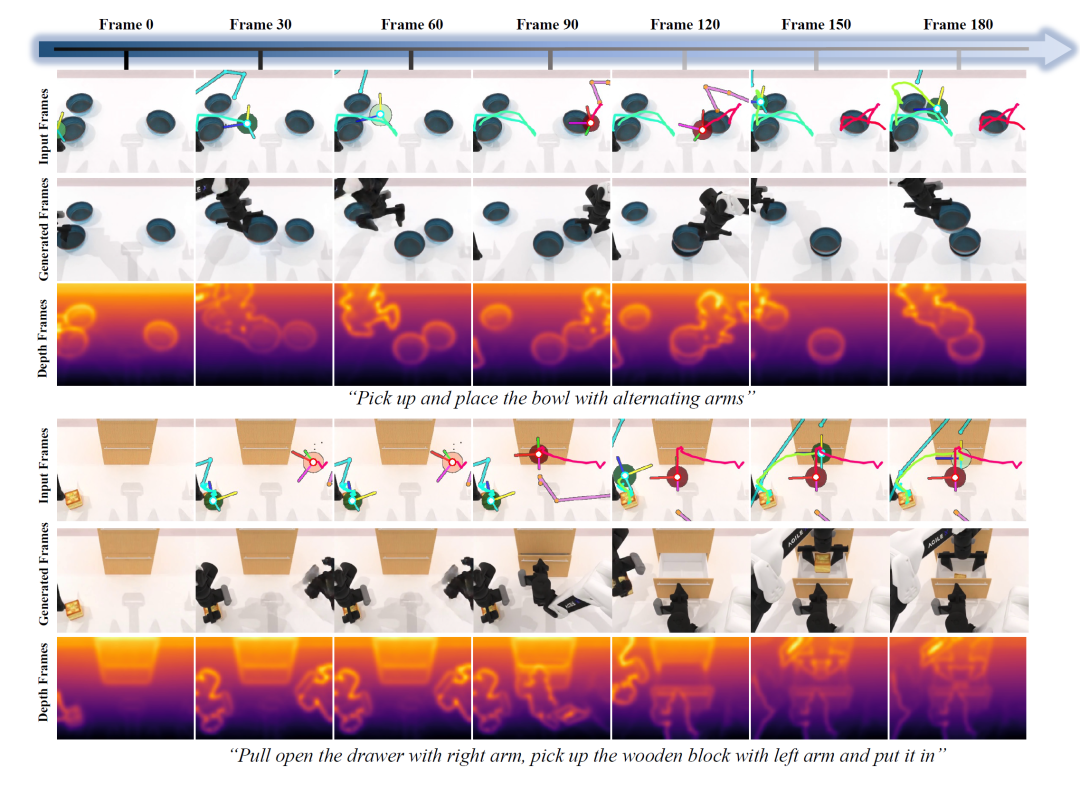
图3 WorldArena基准上的定性结果。每一行展示从初始观测和指令动作序列生成的未来推演,PAIWorld能够产生物理合理的动态,物体交互与运动遵循动作指令,场景布局在长时推演中保持稳定
70.67%
EWMScore 综合得分
79.66%
Motion Quality 动作质量
74.40%
Controllability 可控性
4.2 AgiBot-Challenge2026:场景一致性最佳
在AgiBot-Challenge2026基准上,PAIWorld以0.8245的EWMScore获得综合排名第二,超越了Wild Path、VIPL-GENUN等强劲对手。更为突出的是,PAIWorld在Scene Consistency(场景一致性)指标上取得了0.9041的最佳成绩,这直接证明了显式跨视角几何推理对多视角相干性的显著提升。nDTW指标达到0.9531,表明生成的轨迹与真实动作序列高度吻合,验证了空间动作图条件策略的有效性。
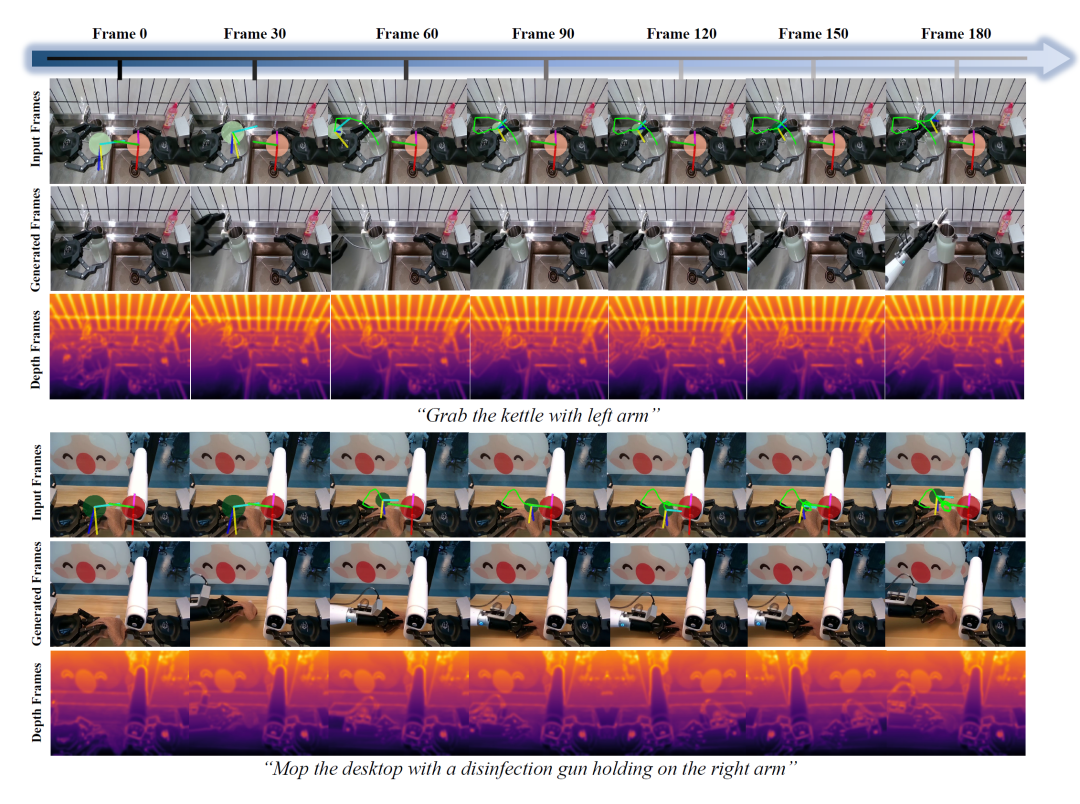
图5 AgiBot-Challenge2026基准上的定性结果。针对多样化的操作任务,PAIWorld生成的未来帧能够忠实反映执行的机器人动作,末端执行器与物体运动紧密跟踪真实轨迹,预测帧在长时程中保持清晰与时序连贯
4.3 文本条件多视角生成:六项指标领先
在AgiBot-World基准的文本条件多视角生成任务中,PAIWorld与Genie-Envisioner、Cosmos-Predict2.5和Wan2.1等先进基线进行了对比。在七项评测指标中,PAIWorld在六项上取得最佳。感知质量方面,SSIM达到0.7683,LPIPS降至0.1844,相较次优方法在LPIPS上提升了45%,表明生成帧具有更锐利的边缘与更忠实的结构。分布保真度方面,FID为45.04,较Wan2.1的56.47提升了20%。
最具说服力的是直接量化多视角三维重建误差的MEt3R指标:PAIWorld以14.20的成绩领先,相较第二名Genie-Envisioner的15.75提升了10%。Geometric一致性得分(基于Sampson极线距离)同样最优。定性对比显示,基线方法存在明显的跨视角物体漂移与纹理错位,而PAIWorld在不同视角间保持了连贯的三维结构、一致的深度分布与对齐的纹理。

图7 多视角视频生成定性对比。与Genie-Envisioner相比,PAIWorld生成的跨视角输出具有显著更强的几何一致性,物体位置、深度结构与纹理对齐在不同视角间保持协调
4.4 消融实验:验证互补性设计
为验证两个技术支柱的互补性,研究团队在AgiBot-World基准上进行了消融研究。从扁平多视角token拼接的骨干网络出发,单独添加跨视角注意力通路(无几何监督)使MEt3R提升了0.93;单独添加Latent 3D-REPA目标(无跨视角通路)使MEt3R提升了0.72。然而,同时启用两者时,MEt3R提升了2.64,显著超过了各自增益之和(1.65)。这一超加性跃升正是两个支柱形成强化循环的实证标志:通路传输信息,目标使信息三维一致,唯有耦合才能将一致性连贯地传播到所有视角。同时,SSIM、LPIPS与FID在双组件同时启用时改善最为明显,确认了几何增益并未以牺牲视觉保真度为代价。
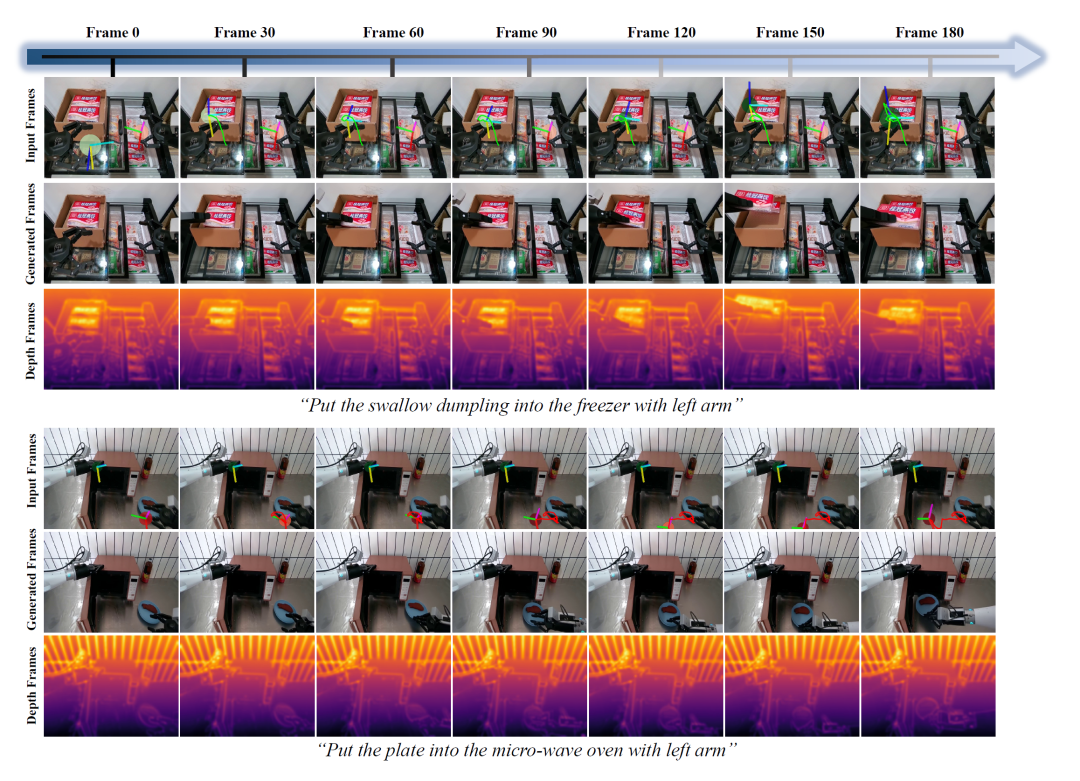
图6 AgiBot-Challenge2026额外定性结果。在更多操作任务中,PAIWorld产生的动作忠实推演中,物体与夹爪运动遵循指令动作,同时保持精细的视觉细节
五、下游应用与未来展望
PAIWorld的三维一致多视角生成能力可直接赋能多种下游具身智能任务。在基于模型的机器人规划中,物理合理的想象推演为轨迹优化提供了可靠的模拟环境;在世界行动模型(World Action Model)中,改进的三维一致性增强了动作与视觉因果之间的对齐;在多视角策略后训练中,高质量的多视角合成数据能够提升操作策略的泛化性能。
研究团队展望了若干值得深入探索的方向。首先,将物理交互建模------包括接触动力学、可变形物体与流体模拟------纳入世界模型,将推动三维一致性从几何层面向物理感知层面延伸。其次,面向长程规划场景,需要通过层次化或循环架构在扩展的时序推演中维持三维一致性。第三,将世界模型与世界行动模型耦合,构建世界模型驱动的数据闭环:世界模型生成多样化的想象经验,世界行动模型从这些经验中学习改进策略,改进后的策略反过来收集更高质量的现实世界数据以进一步精炼世界模型,从而实现具身智能体的持续自我改进与自主进化。第四,研究团队计划基于该世界建模框架开发工业制造基础模型,面向生产线动态调度与制造过程实时控制等应用,其中精确的物理模拟与多视角监控对智能制造至关重要。
六、结语
PAIWorld通过系统性的分析指出,多视角三维一致性需要架构与目标两个层面的协同 remedy:显式的跨视角通信通路负责在不同视角间路由信息,三维几何监督目标确保这些信息在物理结构上可靠。几何感知跨视角注意力与Geo-RoPE共同构建了第一条通路,Latent 3D-REPA提供了第二条支柱。两者缺一不可的耦合设计,使PAIWorld在机器人操作的世界模型基准测试中取得了领先的多视角三维一致性表现,为具身智能的规划、模拟与数据合成提供了更加坚实可靠的基础。
具身智能&世界模型blog: https://jinxindeep.github.io/blog/blog2026.html