一、引言
Hudi 作为数据湖领域的核心组件,其 Record Payload 机制是实现数据增量处理、去重合并的关键抽象,它定义了当新旧记录发生冲突时,如何决定最终保留哪条数据、如何合并字段。
在 Hudi 1.x 版本中,Record Payload 体系经历了重要的架构演进------从早期的HoodieRecordPayload接口逐步迁移到基于HoodieRecordMerger的新合并架构。
本文将介绍 Record Payload 的核心机制原理、不同实现类型的适用场景,以及最佳实践。
二、Record Payload 核心机制
HoodieRecordPayload是 Hudi 早期版本定义的核心接口,位于org.apache.hudi.common.model包下:
csharp
public interface HoodieRecordPayload<T extends HoodieRecordPayload> {
/**
* 与已有记录进行合并,返回合并后的记录。
* currentValue: 存储中已有的旧记录
*/
T preCombine(T oldValue);
/**
* 控制是否需要将该记录写入存储。
* 可用于实现"软删除"等逻辑。
*/
Option<IndexedRecord> combineAndGetUpdateValue(
IndexedRecord currentValue, Schema schema) throws IOException;
/**
* 插入场景下,获取最终要写入的记录。
*/
Option<IndexedRecord> getInsertValue(Schema schema) throws IOException;
}| 方法 | 调用时机 | 作用 |
|---|---|---|
| preCombine | 同一批次内去重 | 在写入前,对相同 Key 的记录进行预合并 |
| combineAndGetUpdateValue | Upsert 时与存储中旧记录合并 | 决定最终更新值,返回 Option.empty() 可实现删除 |
| getInsertValue | Insert 时 | 决定最终插入值 |
简单示例:
vbnet
┌─────────────────────┐
│ 一批数据进入 Hudi │
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ 按 Record Key 分组 │
└──────────┬──────────┘
│
┌──────────────┼──────────────┐
│ │ │
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ Key = A │ │ Key = B │ │ Key = C │
│ 2条记录 │ │ 1条记录 │ │ 3条记录 │
└────┬─────┘ └────┬─────┘ └────┬─────┘
│ │ │
▼ │ ▼
┌───────────────┐ │ ┌───────────────┐
│ preCombine │ │ │ preCombine │
│ (批内去重) │ │ │ (批内去重) │
└───────┬───────┘ │ └───────┬───────┘
│ │ │
▼ ▼ ▼
┌─────────────────────────────────────────┐
│ Index 查询已有记录 │
└──────────────────┬──────────────────────┘
│
┌────────────┼────────────┐
│ │ │
▼ ▼ ▼
已存在记录 不存在记录 已存在记录
│ │ │
▼ ▼ ▼
combineAndGet getInsert combineAndGet
UpdateValue Value UpdateValue
│ │ │
▼ ▼ ▼
┌─────────────────────────────────────────┐
│ 写入存储文件 │
└─────────────────────────────────────────┘三、Record Merger 核心机制
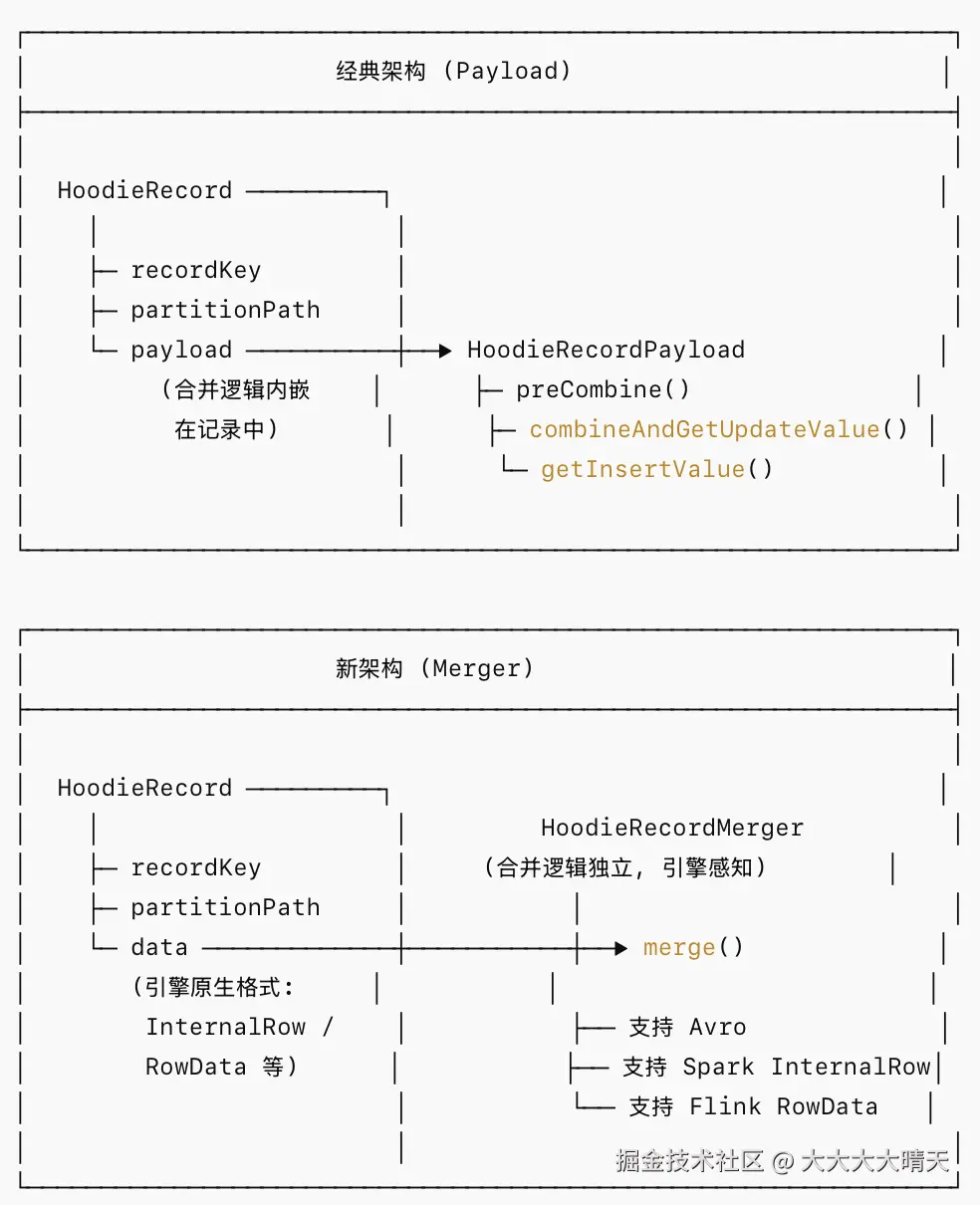
经典 HoodieRecordPayload 存在以下局限:
- 引擎耦合:Payload 内部直接操作 Avro
IndexedRecord,使得 Spark/Flink 等引擎的原生数据结构无法高效利用 - 性能瓶颈:每条记录都需要序列化/反序列化为 Avro 格式进行合并
- 扩展性不足:合并逻辑绑定在记录本身(Payload 是记录的一部分),难以灵活插拔
Hudi 1.x 引入了HoodieRecordMerger接口,将合并逻辑从记录中解耦:
csharp
public interface HoodieRecordMerger {
// 合并两条记录,返回合并结果及操作类型
Option<Pair<HoodieRecord, Schema>> merge(
HoodieRecord older,
Schema oldSchema,
HoodieRecord newer,
Schema newSchema,
TypedProperties props) throws IOException;
// 返回该 Merger 的唯一标识
String getMergerStrategy();
// 返回合并模式
HoodieRecordType getRecordType();
}HoodieRecordPayload VS HoodieRecordMerger
在 Hudi 1.x 中,通过以下配置指定合并策略(如果同时配置了hoodie.payload.class和hoodie.record.merger.strategy,Merger 优先级更高):
| 配置项 | 说明 |
|---|---|
| hoodie.payload.class | 经典 Payload 类(向后兼容) |
| hoodie.record.merger.strategy | 新 Merger 策略标识 |
| hoodie.record.merger.impls | Merger 实现类列表 |
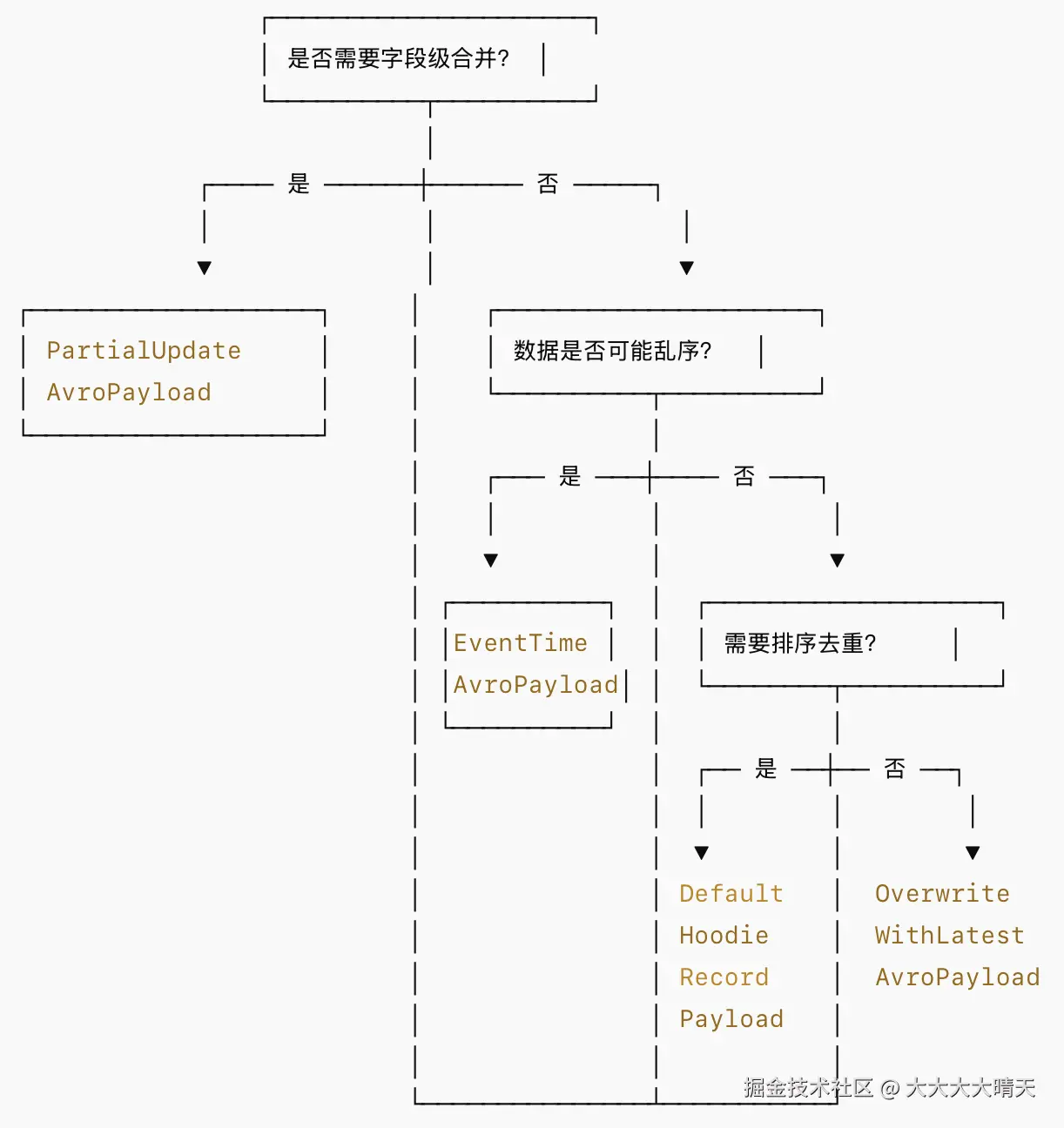
四、内置 Payload/Merger 类型与适用场景
1.主要内置类型总览
| Payload 类 | 对应 Merger 策略 | 排序依据 | 核心行为 | 典型场景 |
|---|---|---|---|---|
| DefaultHoodieRecordPayload | 默认 | precombine 字段 | 取 precombine 值较大的记录 | 通用 Upsert |
| OverwriteWithLatestAvroPayload | OVERWRITE_WITH_LATEST | 无(总是新值覆盖) | 新记录直接覆盖旧记录 | 全量快照覆盖 |
| EventTimeAvroPayload | --- | 事件时间字段 | 基于事件时间去重,处理乱序 | 流式乱序数据 |
| PartialUpdateAvroPayload | --- | precombine 字段 | 非 null 字段覆盖旧值 | 多流拼接/部分更新 |
| ExpressionPayload 1.x 新增 | CUSTOM | 可配置表达式 | 灵活的字段级合并规则 | 复杂合并需求 |
2.DefaultHoodieRecordPayload
kotlin
// 核心逻辑伪代码
preCombine(oldValue):
if (this.orderingVal >= oldValue.orderingVal)
return this
else
return oldValue
combineAndGetUpdateValue(currentValue):
if (this.orderingVal >= currentValue.orderingVal)
return this.record // 新值胜出
else
return currentValue // 旧值保留特点:
- 基于
hoodie.datasource.write.precombine.field指定的排序字段进行比较 - 整条记录级别的覆盖(非字段级)
- 是 Hudi 的默认 Payload
适用场景:标准 CDC 入湖、基于时间戳的去重
3.OverwriteWithLatestAvroPayload
kotlin
// 核心逻辑伪代码
preCombine(oldValue):
return this // 永远返回当前(新)记录
combineAndGetUpdateValue(currentValue):
return this.record // 永远覆盖特点:
- 不做任何比较,新来的数据无条件覆盖
- 性能最优(无需读取比较字段)
适用场景:全量同步覆盖、确保数据源有序的场景
4.EventTimeAvroPayload
kotlin
// 核心逻辑伪代码
combineAndGetUpdateValue(currentValue):
if (isDeleteRecord(this) && this.eventTime > currentValue.eventTime)
return empty() // 执行删除
if (this.eventTime >= currentValue.eventTime)
return this.record
else
return currentValue // 乱序数据被丢弃特点:
- 专为处理乱序设计
- 支持基于事件时间的删除标记
- 配合
hoodie.payload.event.time.field使用
适用场景:Kafka 多分区消费乱序、事件驱动架构
5.PartialUpdateAvroPayload
csharp
// 核心逻辑伪代码
combineAndGetUpdateValue(currentValue):
mergedRecord = new Record(schema)
for each field in schema:
if (newRecord.get(field) != null)
mergedRecord.set(field, newRecord.get(field)) // 用新值
else
mergedRecord.set(field, currentValue.get(field)) // 保留旧值
return mergedRecord特点:
- 字段级别的合并
- null 值表示"不更新该字段"
- 支持多流写入同一张表的不同字段
五、Upsert数据合并流程详解
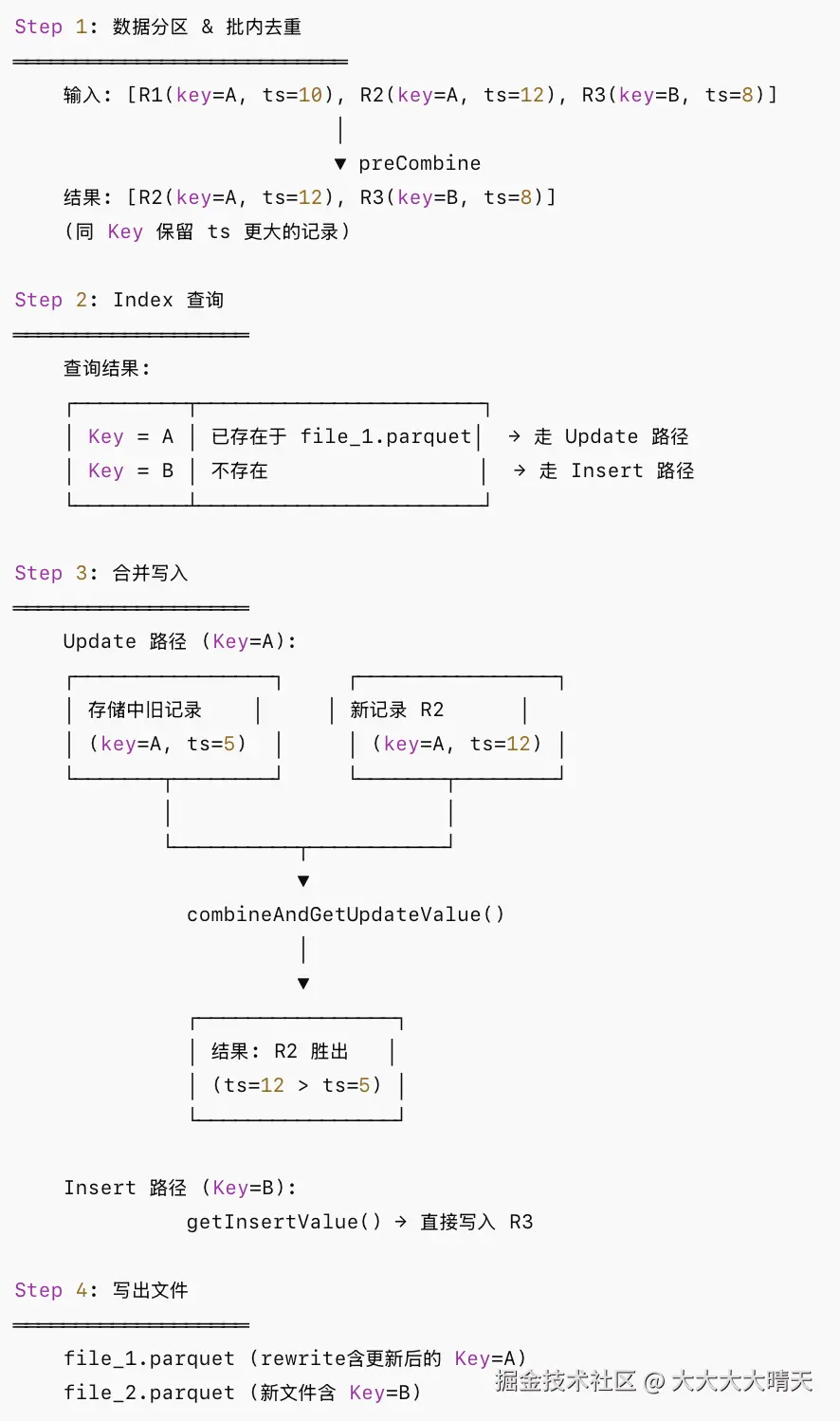
COW vs MOR 表的差异:
| 维度 | Copy-On-Write (COW) | Merge-On-Read (MOR) |
|---|---|---|
| 合并时机 | 写入时立即合并 | 读取/Compaction 时合并 |
| Payload 调用 | 写入阶段调用 combineAndGetUpdateValue | Compaction 阶段调用 |
| 写入开销 | 高(需重写整个文件) | 低(追加 Log 文件) |
| 读取开销 | 低(直接读 Base 文件) | 较高(需合并 Base + Log) |
| 适用场景 | 读多写少 | 写多读少/近实时场景 |
六、选型最佳实践