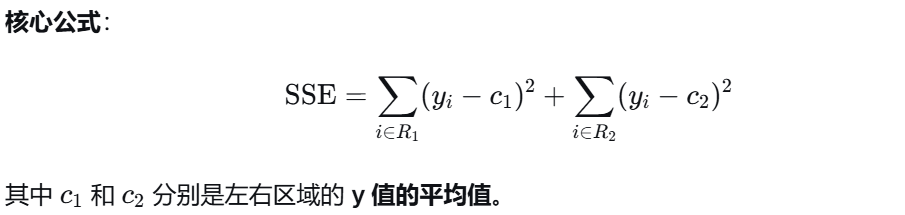朴素贝叶斯分类预测
🧠 朴素贝叶斯分类预测 ------ 通用计算流程(4步法)
Step 1:计算先验概率 P(Y)
统计训练集中每个类别 Y 出现的频率:

Step 2:计算条件概率 P(A∣Y) 和 P(B∣Y)
在给定类别 Y 的条件下,统计属性取特定值的比例:

关键假设:朴素贝叶斯要求属性相互独立,所以我们将 P(A∣Y)和 P(B∣Y) 直接相乘。
Step 3:计算后验概率(核心公式)
忽略归一化常数(证据因子 P(X)),计算类别 Y 的"得分":
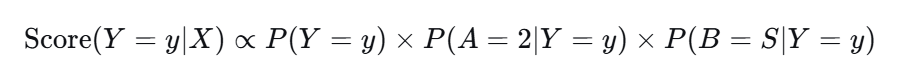
(对于不同类别,分母 P(A=2,B=S)是一样的,所以直接比较分子即可)
Step 4:做出预测
比较各类别的得分,取得分最大的类别作为预测结果。
📊 手算演示(含示例数据集)
为了给你演示具体计算,我构建了一个满足题目要求的小型训练集(共 10 个样本):
| 序号 | A(取值1/2/3) | B(取值S/M/L) | Y(类别) |
|---|---|---|---|
| 1 | 1 | S | 正类(P) |
| 2 | 2 | M | 正类(P) |
| 3 | 2 | S | 正类(P) |
| 4 | 3 | L | 正类(P) |
| 5 | 1 | S | 负类(N) |
| 6 | 1 | S | 负类(N) |
| 7 | 2 | S | 负类(N) |
| 8 | 3 | M | 负类(N) |
| 9 | 3 | L | 负类(N) |
| 10 | 1 | L | 负类(N) |
待预测样本:X=(A=2,B=S)
① 计算先验概率 P(Y)

② 计算条件概率(基于类别分组)




注意 :如果题目要求输出具体的"后验概率值",需要将上述得分除以证据因子 P(A=2,B=S)。但在分类决策中,由于分母相同,通常只比较分子大小即可。
⚠️ 考试/面试必看:两个核心陷阱与特殊处理

逻辑斯蒂回归
1. 预测方程的标准形式(背下来!)
逻辑斯蒂回归的预测分两步走:
第一步:计算线性得分(跟线性回归一样)
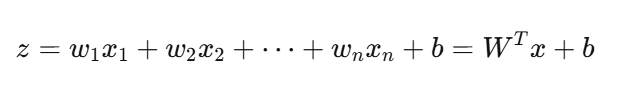
(这里 z 可以是负无穷到正无穷的任意实数。)
第二步:套上 Sigmoid 函数,把 z 压缩成概率
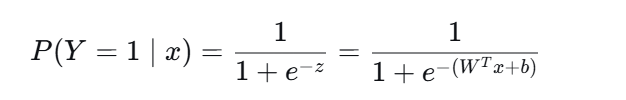
通俗理解:模型先给样本"打分"(z),分数越高越可能是正类;然后用一个 S 形的函数(Sigmoid)把这个分数换算成"百分比概率"。
2. 从方程看"预测规则"(如何得出类别)
拿到概率后,我们通常以 0.5 为分界线(阈值)来决定类别:
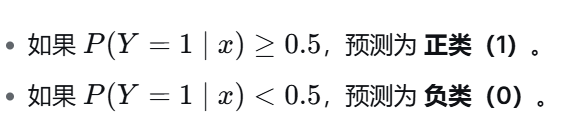
由于 Sigmoid 函数是单调递增的,这个判断规则等价于:
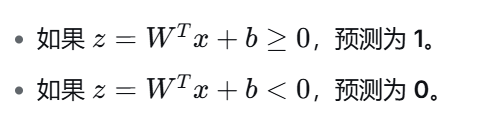
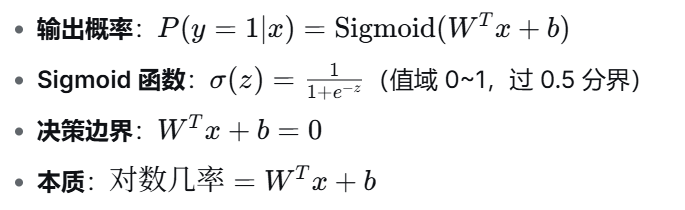
这里的
就是逻辑回归的决策边界(Decision Boundary)。在二维平面上它是一条直线,在三维空间里是一个平面。
关联规则支持度、置信度
1. 核心定义与公式(必背!)
假设我们有一条关联规则 X → Y (表示"购买了 X 的人也会购买 Y"),总事务数为 N:
-
支持度(Support) :衡量规则覆盖多少数据(频次)。
-
公式 :
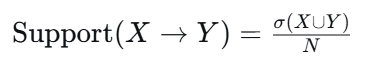
-
其中 σ(X∪Y) 是同时包含 X 和 Y 的事务个数。
-
含义:所有订单中,同时买 X 和 Y 的比例。如果支持度太低,说明这条规则只是"偶然事件",没有统计意义。
-
-
置信度(Confidence) :衡量规则预测有多准(条件概率)。
-
公式 :
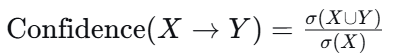
-
含义 :在已经买了 X 的订单中,同时买了 Y 的比例。即 P(Y∣X)。
-
重要区分 :σ(西格玛)指的是"支持度计数 "(绝对次数),而支持度 是"概率"(相对比例)。考试时千万看清题目问的是"计数"还是"百分比"!
2. 🧮 手算示例(经典购物篮)
假设超市有 5 笔交易数据,现在要计算规则 {牛奶} → {面包} 的支持度和置信度。
| 事务ID | 购买的商品 |
|---|---|
| T1 | 牛奶, 面包, 鸡蛋 |
| T2 | 牛奶, 啤酒 |
| T3 | 面包, 鸡蛋, 可乐 |
| T4 | 牛奶, 面包, 啤酒 |
| T5 | 牛奶, 面包 |
计算步骤:
-
确定总事务数(N):N = 5
-
计算支持度计数:
-
同时包含"牛奶"和"面包"的事务有:T1, T4, T5 → 共 3 笔。
-
所以 σ(牛奶∪面包)=3
-
-
计算前提(左侧 X)的计数:
- 包含"牛奶"的事务有:T1, T2, T4, T5 → 共 4 笔。
-
套用公式:
-
支持度 = 3/5=0.6(即 60%)
-
置信度 = 3/4=0.75(即 75%)
-
解读:所有订单中有 60% 同时买了牛奶和面包;在买了牛奶的顾客中,有 75% 的人会买面包。
基尼系数(Gini Index) 、熵(Entropy) 和信息增益/基尼增益(Gain)
1. 三大不纯度度量(衡量节点"有多乱")
在分裂之前,决策树必须用数字来衡量当前节点(数据集)的混乱程度。常用的有三个指标,但前两个是绝对主力:
(1)基尼系数(Gini Index)------ CART算法默认,sklearn默认
-
公式 :
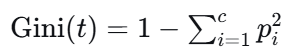
-
通俗理解 :从当前节点随机抽两个样本,它们属于不同类别的概率。
-
取值范围:二分类中 0, 0.5。
-
Gini = 0:完全纯净(全是同一类)。
-
Gini = 0.5:最混乱(两类各占 50%)。
-
-
特点:计算速度极快(只有乘法和减法,没有对数运算)。
(2)熵(Entropy) / 信息增益(Information Gain)------ ID3/C4.5算法
-
公式 :
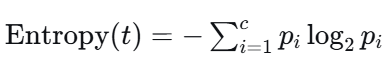
-
通俗理解:衡量数据的"不确定性"。越难猜,熵越大。
-
取值范围:二分类中 0, 1。
-
Entropy = 0:完全纯净。
-
Entropy = 1:最混乱(两类各占 50%)。
-
-
特点 :对不纯度的变化比基尼系数更敏感(曲线更陡),但计算稍慢(涉及 log 运算)。
(3)分类误差(Classification Error)------ 仅用于剪枝,不用于分裂
-
公式 :
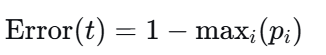
-
为什么不常用 :它对不纯度变化不敏感。比如节点 (4正, 1负) 和 (4正, 2负),误差都是 0.2,无法区分谁更纯,所以从不作为分裂准则。
序数型知道"谁大谁小",但不知道"大了多少";连续型不仅知道"谁大谁小",还知道"具体大了多少"。
2. 增益(Gain)------ 连接"度量"与"划分"的桥梁
有了度量指标,怎么决定用哪个特征来分裂?答案是计算增益(Gain)。
-
核心公式:

(这里的 I 可以是基尼系数,也可以是熵)
-
通俗理解 :增益 = 分裂前的混乱程度 - 分裂后子节点的加权平均混乱程度。这个差值越大,说明这个特征让数据变得越"纯净"。
-
决策树的分裂规则(贪心算法):
-
遍历所有特征。
-
对每个特征,尝试所有可能的分割点。
-
计算每个分割点的"增益"。
-
选择"增益最大"的特征和分割点进行分裂。
-
命名细节 :如果你用基尼系数计算这个差值,就叫做**"基尼增益"** ;如果你用熵计算,就叫做**"信息增益"** 。虽然名字不同,但背后的逻辑完全一样------都是找降低不纯度最多的那个切法。
3. 决策树划分的完整逻辑(三步走)
在算法层面,节点分裂是这样一步步执行的:
-
Step 1:计算父节点不纯度(比如当前节点有 10 个样本,6正4负,算出基尼或熵)。
-
Step 2:尝试划分并计算子节点不纯度:
-
如果是标称属性(如性别):按类别分叉(男/女),计算每个子节点的加权不纯度。
-
如果是连续属性 (如年龄):先将数据排序,尝试所有相邻值的中点作为阈值(如
年龄 < 25和年龄 ≥ 25),找到加权不纯度最小的那个切点。
-
-
Step 3:计算增益并选择 :
算出所有特征(及其切点)的增益值,谁大选谁 。把数据切成两半(或几半),然后对子节点递归执行 Step 1~3,直到触发停止条件。
4. 🧮 手算对比(基尼 vs 熵,一眼看透)
假设父节点有 10 个样本:6 个"是" ,4 个"否"。
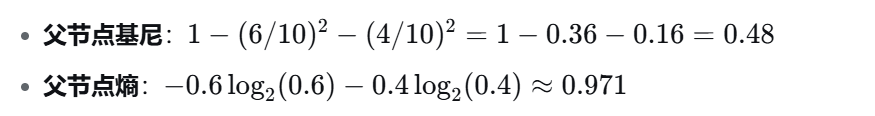
假设用某个特征分裂后,两个子节点分别为 (3正, 0负) 和 (3正, 4负):
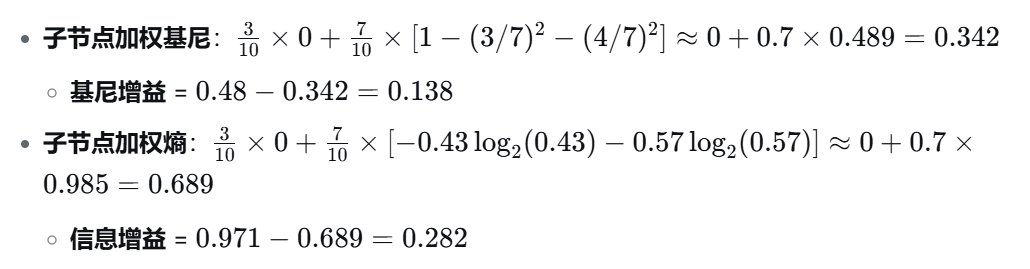
可以看到,无论用基尼还是熵,增益值最高的那个特征一定是同一个特征。所以在工程中,两者最终选出来的分裂点几乎一模一样。
ROC 曲线 + AUC 计算

📊 第一步:数据准备与排序
根据题目,正类为 +,负类为 -。
-
总正例数(P):实例 1, 2, 5, 6 → P=4
-
总负例数(N):实例 3, 4, 7, 8 → N=4
将数据按照后验概率 P(+∣X,M1) 从高到低排序,并整理如下(这是计算 ROC 最关键的起始步骤):
| 排序后序号 | 原实例 | 真实标签 | 预测概率 | 累计 TP | 累计 FP | TPR (TP/4) | FPR (FP/4) | ROC 坐标点 |
|---|---|---|---|---|---|---|---|---|
| 起点 | - | - | - | 0 | 0 | 0 | 0 | (0, 0) |
| 1 | 3 | - | 0.78 | 0 | 1 | 0 | 0.25 | (0.25, 0) |
| 2 | 1 | + | 0.62 | 1 | 1 | 0.25 | 0.25 | (0.25, 0.25) |
| 3 | 5 | + | 0.48 | 2 | 1 | 0.50 | 0.25 | (0.25, 0.50) |
| 4 | 7 | - | 0.38 | 2 | 2 | 0.50 | 0.50 | (0.50, 0.50) |
| 5 | 4 | - | 0.31 | 2 | 3 | 0.50 | 0.75 | (0.75, 0.50) |
| 6 | 6 | + | 0.12 | 3 | 3 | 0.75 | 0.75 | (0.75, 0.75) |
| 7 | 8 | - | 0.05 | 3 | 4 | 0.75 | 1.00 | (1.00, 0.75) |
| 8 | 2 | + | 0.04 | 4 | 4 | 1.00 | 1.00 | (1.00, 1.00) |
计算逻辑详解 (以排序后第 5 步为例):
当阈值降到 0.31 时,预测为正类的样本是排在前 5 个的(原实例 3, 1, 5, 7, 4)。
其中真实为正类(+)的有 2 个(实例 1, 5),所以累计 TP=2;真实为负类(-)的有 3 个(实例 3, 7, 4),所以累计 FP=3。
因此 TPR=2/4=0.50,FPR=3/4=0.75。
📈 第二步:绘制 ROC 曲线(手画指引)
你可以在答题纸上按以下坐标点连线绘图:
-
横轴(X):FPR
-
纵轴(Y):TPR
-
关键转折点 :
(0,0) → (0.25, 0) → (0.25, 0.25) → (0.25, 0.5) → (0.5, 0.5) → (0.75, 0.5) → (0.75, 0.75) → (1.0, 0.75) → (1.0, 1.0)
(如果老师要求平滑曲线,用折线连接上述各点即可;二分类模型的 ROC 通常就是这种阶梯状折线。)
🧮 第三步:使用梯形法则计算 AUC
AUC 是 ROC 曲线下的面积,只计算横轴(FPR)发生变化的水平移动段。公式为:
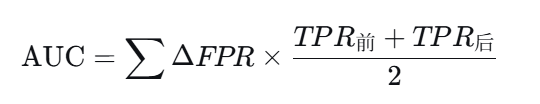
结合上表,我们逐段计算(只取 ΔFPR>0 的区间):
| 区间(FPR 变化) | ΔFPRΔFPR(底边宽) | 平均 TPR 高度 | 本段面积 |
|---|---|---|---|
| 0 → 0.25 | 0.25 | 0+02=020+0=0 | 0.25 × 0 = 0 |
| 0.25 → 0.50 | 0.25 | 0.50+0.502=0.5020.50+0.50=0.50 | 0.25 × 0.50 = 0.125 |
| 0.50 → 0.75 | 0.25 | 0.50+0.502=0.5020.50+0.50=0.50 | 0.25 × 0.50 = 0.125 |
| 0.75 → 1.00 | 0.25 | 0.75+0.752=0.7520.75+0.75=0.75 | 0.25 × 0.75 = 0.1875 |
最终 AUC 值:
AUC=0+0.125+0.125+0.1875=0.4375
-
结论 :模型 M1 的 AUC = 0.4375。
-
意义 :AUC < 0.5,说明该分类模型 M1 的预测效果 "差于随机猜测"(随机猜测为 0.5)。
回归决策树
📊 原始数据
| 序号 | x | y |
|---|---|---|
| 1 | 5 | 0.2 |
| 2 | 7 | 0.4 |
| 3 | 10 | 0.5 |
| 4 | 15 | 0.6 |
目标 :构建一个深度为 1 的回归树桩(即只分裂一次),找到最优的切分点。
第一步:确定所有候选切分点(阈值)回归树只会在 相邻两个 x 值的中间点 进行切分。
第二步:计算每个切分点下的总平方误差(SSE)