09d-斯坦福 CS336 作业三:缩放定律(Scaling Laws)📈
本文档详解斯坦福 CS336 课程的作业三,聚焦语言模型的缩放定律(Scaling Laws)。通过理论与实践相结合的方式,帮助读者理解如何在给定计算预算下最优地分配模型大小和训练 token 数,以及如何拟合缩放曲线预测模型性能 🎯
This document explains Assignment 3 of Stanford CS336 course, focusing on Scaling Laws for language models. It helps readers understand how to optimally allocate model size and training tokens under a given compute budget, and how to fit scaling curves to predict model performance 🎯
术语表 / Terminology
| 术语 / Term | 中文 | 说明 / Description |
|---|---|---|
| Scaling Laws | 缩放定律 | 描述模型性能与模型大小、数据量、计算量之间关系的经验法则 |
| IsoFLOPs | 等计算量 | 保持总计算量(FLOPs)不变,改变模型大小和数据量的配置 |
| FLOPs | 浮点运算次数 | Floating Point Operations,衡量计算成本的单位 |
| Compute Budget | 计算预算 | 训练模型时可用的总计算量限制 |
| Compute-Optimal | 计算最优 | 在给定计算预算下达到最佳性能的配置 |
| Power Law | 幂律 | 数学关系 y=a×x−b,描述缩放趋势 |
| Kaplan Laws | Kaplan 定律 | OpenAI 2020 年提出的早期缩放定律 |
| Chinchilla Laws | Chinchilla 定律 | DeepMind 2022 年提出的计算最优缩放定律 |
| Loss | 损失 | 交叉熵损失(Cross-Entropy Loss),衡量模型预测误差 |
章节阅读路线图 🗺️ / Chapter Reading Roadmap
- 缩放定律概述 📊 / Overview of Scaling Laws → 理解缩放定律的核心概念和历史发展
- Kaplan 缩放定律(2020) 📐 / Kaplan Scaling Laws → 学习早期的幂律关系和过拟合分析
- Chinchilla 缩放定律(2022) 🦫 / Chinchilla Scaling Laws → 掌握计算最优的模型与数据配比
- IsoFLOPs 分析方法 🔬 / IsoFLOPs Analysis Method → 理解等计算量下的实验设计
- 作业三任务详解 📝 / Assignment 3 Tasks → 拆解三个核心任务的要求和实现思路
- 拟合缩放曲线 📈 / Fitting Scaling Curves → 学习如何使用幂律函数拟合实验数据
- 优化计算预算分配 ⚖️ / Optimizing Compute Budget → 找到最佳的模型大小和 token 数配比
- 总结 🎯 / Summary → 回顾核心要点和实际应用价值
1. 缩放定律概述 📊 / Overview of Scaling Laws
📖 Note: 本章介绍缩放定律的核心概念和历史发展 / This chapter introduces the core concepts and historical development of scaling laws.
1.1 什么是缩放定律?🤔
缩放定律(Scaling Laws) 是描述神经网络性能(通常是损失 Loss)与关键因素(模型大小、训练数据量、计算量)之间关系的经验法则(Empirical Rules) 📏。
直观类比 🎨:想象你在投资理财产品
- 模型大小 = 你投入的本金多少
- 数据量 = 你投资的时间长短
- 计算量 = 你花费的总成本(本金 × 时间)
- 损失 = 你的投资风险(越低越好)
缩放定律告诉我们:如何分配本金和时间,才能让风险最低、收益最高? 💰
1.2 为什么需要缩放定律?🎯
在训练大语言模型(LLM)时,我们面临一个核心问题:
💭 给定固定的计算预算(比如 100 万美元的 GPU 费用),应该训练多大的模型?用多少数据?
如果没有缩放定律,我们只能盲目尝试:
- ❌ 训练一个小模型,用过量的数据 → 浪费计算资源
- ❌ 训练一个超大模型,用很少的数据 → 严重过拟合
- ✅ 找到计算最优(Compute-Optimal) 的配置 → 性能最大化
缩放定律的价值 💎:
- 预测性能 📈:在小规模实验后,预测大规模模型的表现
- 指导决策 🧭:在有限预算下,选择最佳的模型大小和数据量
- 节省成本 💰:避免浪费计算资源在次优配置上
- 理解趋势 🔍:揭示模型性能随规模变化的内在规律
1.3 缩放定律的发展历史 📅
| 时间 | 研究 | 核心发现 |
|---|---|---|
| 2020 | Kaplan 等(OpenAI)🏢 | 损失与模型大小、数据量呈幂律关系 |
| 2022 | Hoffmann 等(DeepMind)🧠 | Chinchilla 定律:模型大小和 token 数应等比例缩放 |
| 2023-2024 | 后续研究 🔬 | 验证和扩展缩放定律到更大规模 |
关键转折点 🔄:
- Kaplan(2020) 认为:应该训练更大的模型 ,用相对较少的数据,在收敛前停止训练
- Chinchilla(2022) 发现:Kaplan 的模型严重欠训练(Under-trained) ,应该同时增加模型大小和数据量
缩放定律参考资料:
- Scaling Laws for Neural Language Models -- arXiv ⭐值得阅读
- Training Compute-Optimal Large Language Models -- arXiv ⭐值得阅读
- Neural scaling law -- Wikipedia
- Kaplan Scaling Laws: Predicting Language Model Performance -- mbrenndoerfer.com
- Chinchilla Scaling Laws: Compute-Optimal LLM Training -- mbrenndoerfer.com
2. Kaplan 缩放定律(2020)📐 / Kaplan Scaling Laws
📖 Note: 本章学习 OpenAI 2020 年提出的早期缩放定律 / This chapter learns the early scaling laws proposed by OpenAI in 2020.
2.1 核心发现 🔍
Kaplan 等人(2020)在论文《Scaling Laws for Neural Language Models》中研究了语言模型在交叉熵损失(Cross-Entropy Loss)上的经验缩放规律 📊。
三大核心发现 💎:
-
幂律关系(Power-Law Relationship) 📈
损失 L 与模型大小 N、数据集大小 D、计算量 C 之间都遵循幂律(Power Law):
L(N)=(NNc)αN+L0
L(D)=(DDc)αD+L0其中:📝
- N:模型参数量(Number of Parameters)
- D:训练 token 数量(Dataset Size)
- Nc,Dc:特征尺度(Characteristic Scale)
- αN,αD:幂律指数(Power-Law Exponent)
- L0:不可约损失(Irreducible Loss),数据集的内在噪声
-
架构细节影响很小 🏗️
在很大范围内,网络宽度(Width)或深度(Depth)等架构细节对性能影响微乎其微。
-
最优计算分配 ⚖️
给定固定计算预算,更大的模型更样本高效(Sample-Efficient),应该:
- 训练非常大的模型
- 使用相对适度的数据量
- 在收敛前显著提前停止训练(Stop Significantly Before Convergence)
2.2 幂律的直观理解 💡
什么是幂律? 🤔
幂律是一种数学关系,形式为 y=a×x−b。在双对数坐标(Log-Log Plot)上,幂律表现为一条直线 📏。
直观类比 🎨:想象你在减肥
- 第 1 个月:减 10 斤(效果显著)
- 第 2 个月:减 5 斤(效果减半)
- 第 3 个月:减 2.5 斤(效果再次减半)
- ...
每次努力的效果都在递减,但永远不会达到零------这就是幂律的特征。
在缩放定律中 📊:
- 模型大小增加 10 倍 → 损失下降一个固定比例
- 数据量增加 10 倍 → 损失下降另一个固定比例
- 这种趋势可以跨越7 个数量级(7 Orders of Magnitude)
2.3 过拟合分析 🎭
Kaplan 发现了一个简单方程描述过拟合(Overfitting) 与模型/数据集大小的关系:
L(N,D)=(NNc)αN+(DDc)αD+L0
解读 🔍:
- 第一项:模型不够大导致的误差(欠拟合误差)
- 第二项:数据不够多导致的误差(过拟合误差)
- 第三项:数据集的内在噪声(不可约误差)
直观理解 🎯:
- 如果 N 很小, NNc 很大 → 模型太简单,学不会(欠拟合)
- 如果 D 很小, DDc 很大 → 数据太少,死记硬背(过拟合)
- 要同时增大 N 和 D,才能让两项都变小
Kaplan 定律参考资料:
- Scaling Laws for Neural Language Models 原文 -- arXiv ⭐值得阅读
- Kaplan Scaling Laws: Predicting Language Model Performance -- mbrenndoerfer.com ⭐值得阅读
- MIT 6.7960 Lecture 20: Scaling Laws -- MIT OpenCourseWare
- AI Scaling Laws Explained -- Medium
3. Chinchilla 缩放定律(2022)🦫 / Chinchilla Scaling Laws
📖 Note: 本章掌握 DeepMind 2022 年提出的计算最优缩放定律 / This chapter masters the compute-optimal scaling laws proposed by DeepMind in 2022.
3.1 核心发现 🔍
Hoffmann 等人(2022)在论文《Training Compute-Optimal Large Language Models》中训练了超过 400 个语言模型(从 7000 万到 160 亿参数),得出了颠覆性的结论 🧠。
Chinchilla 定律的核心 💎:
🎯 对于计算最优训练,模型大小和训练 token 数应该等比例缩放:模型大小每翻一倍,训练 token 数也应翻一倍。
数学表达 📐:
Doptimal≈20×N
其中:📝
- Doptimal:最优训练 token 数
- N:模型参数量
这意味着 💡:一个 70 亿参数的模型,应该用约 1400 亿 token 训练( 70B×20=1400B)。
3.2 Chinchilla vs Kaplan 对比 ⚔️
| 特性 | Kaplan(2020)🏢 | Chinchilla(2022)🧠 |
|---|---|---|
| 模型大小趋势 | 越大越好 📈 | 与数据量等比例缩放 ⚖️ |
| 数据量建议 | 相对较少 📉 | 与模型大小匹配 📊 |
| 训练策略 | 提前停止(Early Stopping)🛑 | 训练到收敛 ✅ |
| 核心发现 | 幂律关系 📐 | 20:1 的最优比例 🔢 |
| 实验规模 | 较少模型 | 400+ 个模型 🔬 |
关键差异 🔄:
- Kaplan 认为应该训练超大模型,用较少数据,在收敛前停止
- Chinchilla 发现之前的模型严重欠训练(Significantly Under-Trained)
3.3 Chinchilla 的实验验证 🧪
DeepMind 团队用实验验证了他们的理论:
Chinchilla 模型 🦫:
- 参数量:70B(700 亿)
- 训练数据:1.4T token(1.4 万亿)
- 计算预算:与 Gopher(280B 参数)相同
性能对比 📊:
| 模型 | 参数量 | MMLU 准确率 |
|---|---|---|
| Gopher | 280B | ~60% |
| GPT-3 | 175B | ~62% |
| Chinchilla | 70B | 67.5% ⭐ |
结论 💎:Chinchilla 用更少的参数 (70B vs 280B),但更多的数据 ,在相同计算预算下大幅超越了所有大模型!
3.4 为什么 Chinchilla 更重要?🎯
对业界的冲击 💥:
- GPT-3 欠训练 😱:175B 参数的 GPT-3 应该用更多数据训练
- 节省计算成本 💰:Chinchilla 用 1/4 的参数达到更好的效果,推理和微调成本大幅降低
- 指导后续模型 🧭:Llama、PaLM 等后续模型都参考了 Chinchilla 的比例
直观类比 🎨:想象你在准备考试
- Kaplan 策略:买一本超厚的参考书(大模型),但只看前几章(少数据)
- Chinchilla 策略:买一本适中的书(适中模型),但反复精读每一页(多数据)
- 结果:Chinchilla 策略考试成绩更好!📚
Chinchilla 定律参考资料:
- Training Compute-Optimal Large Language Models 原文 -- arXiv ⭐值得阅读
- Chinchilla Scaling Laws: Compute-Optimal LLM Training -- mbrenndoerfer.com ⭐值得阅读
- 【万字硬核】Training Compute-Optimal Large Language Models -- 知乎
- Chinchilla Proves GPT-3 Under-Trained -- LinkedIn
- Chinchilla scaling: A replication attempt -- Epoch AI
4. IsoFLOPs 分析方法 🔬 / IsoFLOPs Analysis Method
🔬 Note: 本章理解等计算量下的实验设计 / This chapter understands the experimental design under equal compute.
4.1 什么是 IsoFLOPs?🤔
IsoFLOPs (等计算量)是一种实验设计方法:保持总计算量(FLOPs)不变,改变模型大小和数据量的组合 ⚖️。
计算量公式 📐:
C≈6×N×D
其中:📝
- C:总计算量(FLOPs)
- N:模型参数量
- D:训练 token 数
- 6:每个 token 的近似 FLOPs 系数(前向 + 反向传播)
4.2 IsoFLOPs 实验设计 🧪
核心思路 💡:
给定固定的计算预算 C,我们可以选择不同的 (N,D) 组合:
| 配置 | 模型大小 N | Token 数 D | 计算量 C=6ND |
|---|---|---|---|
| A | 10M | 100B | 6×109 |
| B | 100M | 10B | 6×109 |
| C | 1B | 1B | 6×109 |
| D | 10B | 100M | 6×109 |
目标 🎯:找到哪个配置的损失最低(Lowest Loss)。
4.3 IsoFLOPs Profile 📊
IsoFLOPs Profile 是一张图,显示在固定计算预算下,不同模型大小的损失变化 📈。
典型趋势 🔍:
- 模型太小 → 欠拟合,损失高
- 模型太大 → 数据不足,过拟合,损失高
- 中间某个点 → 计算最优,损失最低 ⭐
IsoFLOPs Profile 图表 👁️:
下图展示了 Chinchilla 论文中的 IsoFLOP 曲线(来源:mbrenndoerfer.com):
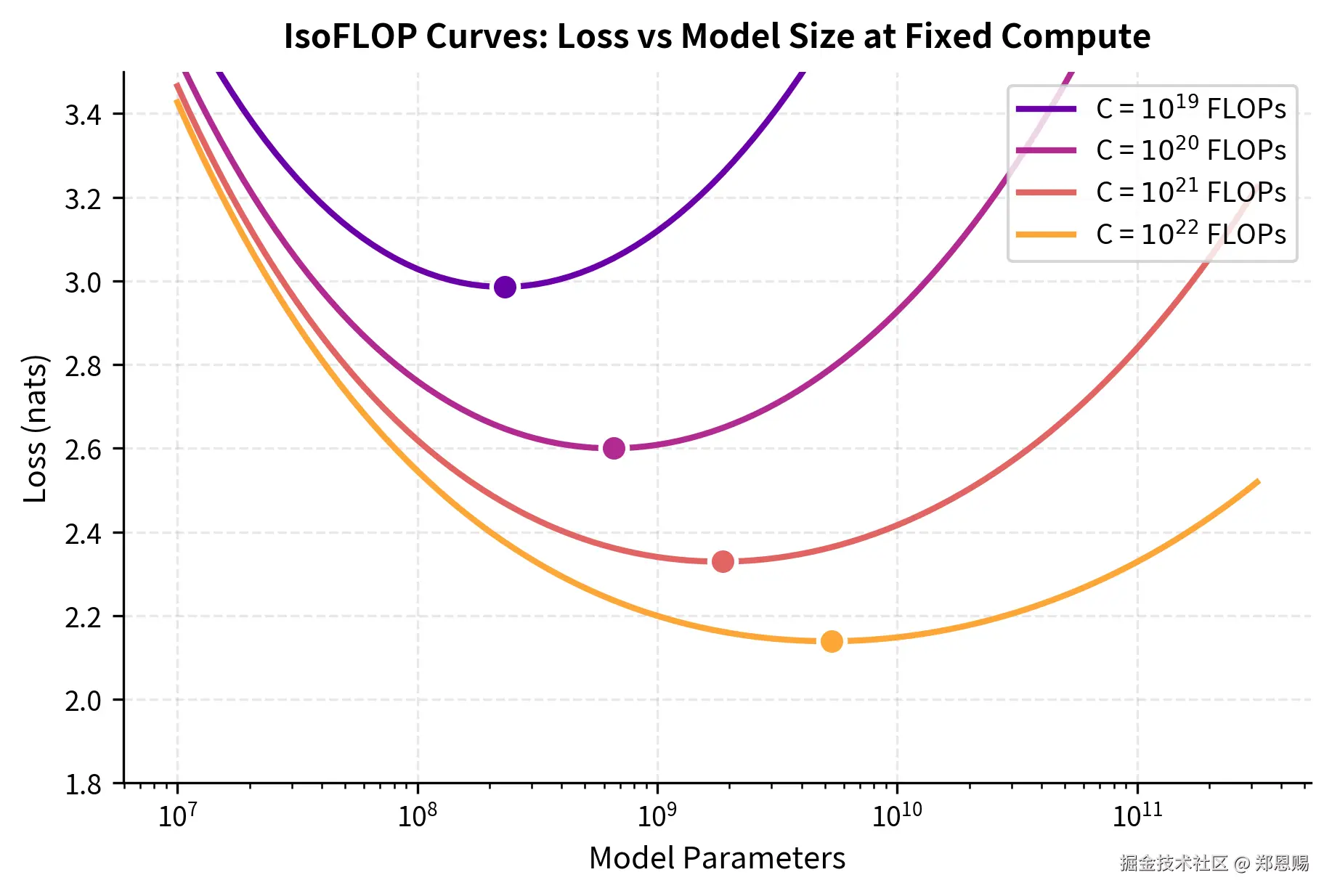
图解读 🔍:
这张图是理解 IsoFLOPs 分析的核心可视化工具 💎:
-
横轴(X 轴) 📏:模型大小(Model Size),从左到右逐渐增大
- 左侧:小模型(如 10M、100M 参数)
- 右侧:大模型(如 10B、100B 参数)
-
纵轴(Y 轴) 📊:损失值(Loss),从下到上逐渐增大
- 下方:低损失(性能好)✅
- 上方:高损失(性能差)❌
-
每条曲线 🌈:代表一个固定的计算预算(Fixed Compute Budget)
- 例如:最上方的曲线可能是 1018 FLOPs(计算预算小,损失高)
- 下方的曲线可能是 1019、 1020 FLOPs 等(计算预算大,损失低)
- 关键规律:计算预算越大,曲线位置越靠下(损失越低)
-
曲线的形状 📈:呈 U 型(或山谷型)
- 左侧上升 ⬆️:模型太小,容量不足,欠拟合(Underfitting)
- 右侧上升 ⬆️:模型太大,数据不足,过拟合(Overfitting)
- 底部最低点 ⭐:计算最优配置(Compute-Optimal)
-
最优点的移动 🎯:
- 随着计算预算增加(从上到下的曲线),最优点向右移动
- 这意味着:预算越大,最优模型越大
- 但关键是:最优 token 数也在同步增加
直观类比 🎨:想象你在调音响的均衡器
- 低音太多 → 声音浑浊
- 高音太多 → 声音刺耳
- 均衡 → 音质最佳 🎵
IsoFLOPs 分析就是在找这个"均衡点"。
关键洞察 💡:
从图中可以清晰看到:
- 每条 IsoFLOP 曲线都有明确的最低点(Clear Minimum)
- 这个最低点对应的就是该计算预算下的最优模型大小
- 随着预算增加,最优点沿着一条隐藏的最优路径移动
- 这条路径就是 Chinchilla 发现的 D≈20N 比例线
4.4 为什么用 IsoFLOPs?🎯
优势 💎:
- 公平比较 ⚖️:所有配置使用相同计算量,排除计算成本差异
- 找到最优 🎯:直接定位给定预算下的最佳配置
- 验证理论 🔬:检验 Kaplan 和 Chinchilla 的预测
- 指导实践 🧭:为实际训练提供可操作的建议
实际应用 🛠️:
- 在训练大模型前,先用小规模 IsoFLOPs 实验找到最优比例
- 避免盲目训练浪费计算资源
IsoFLOPs 参考资料:
- Scaling Laws for Neural Language Models -- arXiv ⭐值得阅读
- MIT 6.7960 Lecture 20: Scaling Laws -- MIT OpenCourseWare ⭐值得阅读
- LLM Scaling Laws: From GPT-3 to o3 -- Substack
5. 作业三任务详解 📝 / Assignment 3 Tasks
📝 Note: 本章拆解 CS336 作业三的三个核心任务 / This chapter breaks down the three core tasks of CS336 Assignment 3.
5.1 任务概览 🎯
CS336 作业三聚焦于缩放定律(Scaling Laws),包含三个主要任务 📋:
- 拟合缩放定律 📈:使用提供的 IsoFLOPs 训练数据拟合缩放曲线
- 实验收集缩放数据 🔬:在有限的 FLOPs 预算下查询训练 API
- 优化计算预算分配 ⚖️:分析如何在给定计算预算下最优地分配模型大小和训练 token 数
5.2 任务一:拟合缩放定律 📈 / Task 1: Fit Scaling Laws
任务目标 🎯:
使用课程提供的 IsoFLOPs 训练数据,拟合出缩放曲线,验证 Kaplan 或 Chinchilla 的幂律关系 🔬。
具体步骤 📝:
-
加载数据 📂
- 读取 IsoFLOPs Profile 数据(通常包含模型大小 N、token 数 D、损失 L)
- 数据格式可能是 CSV 或 JSON
-
定义幂律函数 📐
使用 Kaplan 的公式:
L(N)=A×N−α+L0或者包含数据的完整形式:
L(N,D)=NαA+DβB+E其中:📝
- A,B:缩放系数
- α,β:幂律指数
- E:不可约损失(Irreducible Loss)
-
曲线拟合 📊
- 使用
scipy.optimize.curve_fit进行非线性最小二乘拟合 - 或者在双对数坐标(Log-Log Plot)上用线性回归
- 使用
-
验证拟合质量 ✅
- 计算 R2 值(决定系数)
- 可视化拟合曲线与实验数据点的对比
代码示例框架 💻:
python
import numpy as np # 导入 NumPy 用于数值计算 🔢
from scipy.optimize import curve_fit # 导入曲线拟合工具 📊
import matplotlib.pyplot as plt # 导入绘图模块 📈
"""定义幂律损失函数
参数:
N: 模型参数量
A: 缩放系数
alpha: 幂律指数
L0: 不可约损失
返回:
预测损失值
"""
def power_law_loss(N, A, alpha, L0):
return A * (N ** (-alpha)) + L0 # 返回幂律损失,数据流动:N[数组] → L[数组]
# 加载 IsoFLOPs 数据 📂
# model_sizes = [...] # 模型大小列表
# losses = [...] # 对应的损失值列表
# 拟合曲线 📊
# popt, pcov = curve_fit(power_law_loss, model_sizes, losses)
# 可视化 📈
# plt.loglog(model_sizes, losses, 'o', label='Data')
# plt.loglog(model_sizes, power_law_loss(model_sizes, *popt), '-', label='Fit')关键理解 💡:
- 在双对数坐标 上,幂律表现为直线 📏
- 斜率 = 幂律指数 −α
- 截距 = log(A)
拟合缩放定律参考资料:
- Scaling Laws for Neural Language Models -- arXiv ⭐值得阅读
- Kaplan Scaling Laws: Predicting Language Model Performance -- mbrenndoerfer.com
- 斯坦福 CS336 课程官网 -- Stanford
5.3 任务二:实验收集缩放数据 🔬 / Task 2: Collect Scaling Data
任务目标 🎯:
在有限的 FLOPs 预算下,查询课程提供的训练 API,收集不同配置下的训练数据 🧪。
具体步骤 📝:
-
理解 FLOPs 预算 💰
计算量公式:
C=6×N×D给定总预算 C,需要选择多个 (N,D) 组合。
-
设计实验配置 🧭
例如,给定 C=6×1018 FLOPs:
配置 模型大小 N Token 数 D 验证 1 10M 100B 6×107×1011=6×1018 ✅ 2 100M 10B 6×108×1010=6×1018 ✅ 3 1B 1B 6×109×109=6×1018 ✅ -
查询训练 API 🔌
对每个配置,调用 API 获取训练后的损失值:
python# 伪代码示例 💻 for N, D in configurations: # 遍历所有配置组合 loss = training_api.query(N=N, D=D) # 查询训练 API,返回损失值 results.append({'N': N, 'D': D, 'loss': loss}) # 保存结果到列表 -
记录结果 📊
- 保存每个配置的最终损失
- 可能还需要记录训练曲线(Loss Curve)
关键挑战 ⚠️:
- 预算有限 :不能尝试所有配置,需要智能选择有代表性的点
- API 限制:可能有调用次数限制,需要合理规划
- 噪声处理:训练结果可能有随机性,需要多次运行取平均
直观类比 🎨:想象你在调咖啡配方
- 预算 = 你只有 100 元买咖啡豆
- 配置 = 不同深浅烘焙(模型大小)和研磨粗细(数据量)的组合
- 目标 = 找到最好喝的配置(最低损失)
实验收集数据参考资料:
- 斯坦福 CS336 课程官网 -- Stanford ⭐值得阅读
- 斯坦福 CS336 GitHub 作业仓库 -- GitHub
- Scaling Laws for Language Models -- Scribd
5.4 任务三:优化计算预算分配 ⚖️ / Task 3: Optimize Compute Budget
任务目标 🎯:
分析如何在给定计算预算下最优地分配 模型大小和训练 token 数,找到最佳的训练配置 🏆。
具体步骤 📝:
-
理解计算最优(Compute-Optimal) 💎
根据 Chinchilla 定律:
Doptimal≈20×N代入计算量公式:
C=6×N×(20N)=120N2解得最优模型大小:
Noptimal=120C最优 token 数:
Doptimal=20×120C -
使用拟合的缩放定律预测 📈
从任务一得到了缩放曲线后,可以预测任意配置的损失:
python# 预测不同配置的损失 💻 def predict_loss(N, D, params): A, alpha, beta, E = params # 解包拟合参数 return A / (N ** alpha) + B / (D ** beta) + E # 返回预测损失 # 在预算约束下搜索最优配置 🔍 best_config = None best_loss = float('inf') for N in model_size_range: # 遍历可能的模型大小 D = C / (6 * N) # 根据预算计算对应的 token 数 loss = predict_loss(N, D, fitted_params) # 预测该配置的损失 if loss < best_loss: # 如果找到更低的损失 best_loss = loss # 更新最优损失 best_config = {'N': N, 'D': D} # 更新最优配置 -
验证 Chinchilla 比例 ✅
检查找到的最优配置是否接近 D=20N 的比例。
-
给出建议 💡
基于分析结果,给出实际训练的建议:
- 推荐模型大小
- 推荐训练 token 数
- 预期达到的损失值
关键理解 💡:
- Kaplan 策略:偏向更大的模型,更少的数据
- Chinchilla 策略:模型和数据等比例缩放(20:1)
- 实际选择:取决于具体任务和数据集特性
直观类比 🎨:想象你在投资组合中分配资金
- 股票(模型大小)= 高风险高回报
- 债券(数据量)= 低风险稳定收益
- 最优配置 = 找到风险和收益的最佳平衡点 ⚖️
优化预算分配参考资料:
- Training Compute-Optimal Large Language Models -- arXiv ⭐值得阅读
- Chinchilla Scaling Laws: Compute-Optimal LLM Training -- mbrenndoerfer.com ⭐值得阅读
- 【万字硬核】Training Compute-Optimal Large Language Models -- 知乎
6. 拟合缩放曲线 📈 / Fitting Scaling Curves
📈 Note: 本章详细学习如何使用幂律函数拟合实验数据 / This chapter details how to fit experimental data using power-law functions.
6.1 幂律函数的数学形式 📐
基础幂律 🔢:
L(N)=A×N−α+L0
完整形式(包含模型大小和数据量) 📊:
L(N,D)=NαA+DβB+E
参数解释 📝:
- A,B:缩放系数(Scaling Coefficients),反映模型和数据的重要性
- α,β:幂律指数(Power-Law Exponents),通常在 0.05 到 0.1 之间
- E:不可约损失(Irreducible Loss),数据集的内在噪声下限
6.2 拟合方法 🔧
方法一:非线性最小二乘拟合(Nonlinear Least Squares)
使用 scipy.optimize.curve_fit:
python
from scipy.optimize import curve_fit # 导入曲线拟合工具 📊
"""完整幂律损失函数
参数:
ND: 拼接的 (N, D) 数组 [N1, N2, ..., D1, D2, ...]
A: 模型缩放系数
alpha: 模型幂律指数
B: 数据缩放系数
beta: 数据幂律指数
E: 不可约损失
返回:
预测损失数组
"""
def full_power_law(ND, A, alpha, B, beta, E):
N = ND[:len(ND)//2] # 提取前半部分为模型大小
D = ND[len(ND)//2:] # 提取后半部分为 token 数
return A / (N ** alpha) + B / (D ** beta) + E # 返回完整幂律损失
# 准备数据 📂
# ND_combined = np.concatenate([model_sizes, token_counts])
# losses = np.array([...])
# 执行拟合 📊
# popt, pcov = curve_fit(full_power_law, ND_combined, losses, p0=[1.0, 0.1, 1.0, 0.1, 1.0])
# 提取参数 📝
# A, alpha, B, beta, E = popt方法二:对数线性回归(Log-Log Linear Regression)
在双对数坐标上,幂律变成线性关系:
log(L−L0)=log(A)−α×log(N)
python
import numpy as np # 导入 NumPy 🔢
# 对数据取对数 📊
# log_N = np.log(model_sizes)
# log_loss = np.log(losses - L0)
# 线性回归 📈
# alpha, log_A = np.polyfit(log_N, log_loss, 1)
# A = np.exp(log_A)6.3 评估拟合质量 ✅
决定系数 R2 📊:
R2=1−∑(yi−yˉ)2∑(yi−y^i)2
其中:📝
- yi:实际损失值
- y^i:预测损失值
- yˉ:平均损失值
解读 💡:
- R2=1:完美拟合
- R2>0.95:非常好的拟合
- R2>0.9:良好的拟合
可视化检查 👁️:
python
import matplotlib.pyplot as plt # 导入绘图模块 📈
# 绘制实验数据 📊
plt.loglog(model_sizes, losses, 'o', label='Experimental Data')
# 绘制拟合曲线 📈
# N_fit = np.linspace(min(N), max(N), 100)
# L_fit = power_law_loss(N_fit, A, alpha, L0)
# plt.loglog(N_fit, L_fit, '-', label=f'Fit: $R^2={r2:.3f}$')
plt.xlabel('Model Size (Parameters)') # 设置 x 轴标签
plt.ylabel('Cross-Entropy Loss') # 设置 y 轴标签
plt.title('Scaling Law Fit') # 设置标题
plt.legend() # 显示图例
plt.grid(True, which='both', ls='--') # 显示网格
plt.show() # 显示图表拟合方法参考资料:
- Scaling Laws for Neural Language Models -- arXiv ⭐值得阅读
- Kaplan Scaling Laws: Predicting Language Model Performance -- mbrenndoerfer.com
- MIT 6.7960 Lecture 20: Scaling Laws -- MIT OpenCourseWare
7. 优化计算预算分配 ⚖️ / Optimizing Compute Budget
⚖️ Note: 本章学习如何在给定计算预算下找到最佳配置 / This chapter learns how to find the optimal configuration under a given compute budget.
7.1 计算预算约束 📊
计算量公式 📐:
C=6×N×D
约束优化问题 🎯:
最小化:约束:L(N,D)=NαA+DβB+E6ND=Cbudget
7.2 拉格朗日乘数法求解 🔧
使用拉格朗日乘数法(Lagrange Multipliers):
L(N,D,λ)=NαA+DβB+E+λ(6ND−C)
对 N、 D、 λ 求偏导并令其为 0:
∂N∂L=−αNα+1A+6λD=0
∂D∂L=−βDβ+1B+6λN=0
∂λ∂L=6ND−C=0
解得最优比例 💎:
ND=αβ
Chinchilla 的发现 🦫:
实验测得 α≈β,因此:
D≈20×N
7.3 实际求解步骤 📝
步骤 1:确定计算预算 💰
python
C_budget = 1e18 # 1e18 FLOPs 💰步骤 2:使用 Chinchilla 比例 🦫
python
# 根据 D = 20N 和 C = 6ND 求解 📐
# C = 6 × N × 20N = 120N²
N_optimal = np.sqrt(C_budget / 120) # 计算最优模型大小
D_optimal = 20 * N_optimal # 计算最优 token 数步骤 3:验证结果 ✅
python
# 验证计算量 📊
C_actual = 6 * N_optimal * D_optimal # 计算实际使用的 FLOPs
print(f"预算:{C_budget:.2e} FLOPs")
print(f"实际:{C_actual:.2e} FLOPs")
print(f"最优模型大小:{N_optimal:.2e} 参数")
print(f"最优 token 数:{D_optimal:.2e}")
print(f"比例 D/N = {D_optimal/N_optimal:.1f}")步骤 4:预测损失 📈
python
# 使用拟合的缩放定律预测损失 🔮
L_optimal = A / (N_optimal ** alpha) + B / (D_optimal ** beta) + E
print(f"预期损失:{L_optimal:.4f}")7.4 数值搜索方法 🔍
如果缩放定律形式复杂,无法解析求解,可以用数值搜索:
python
"""在预算约束下搜索最优配置
参数:
C_budget: 计算预算(FLOPs)
params: 拟合的缩放定律参数 (A, alpha, B, beta, E)
返回:
最优配置字典 {'N': 模型大小, 'D': token数, 'loss': 损失}
"""
def search_optimal_config(C_budget, params):
A, alpha, B, beta, E = params # 解包参数
best_config = None # 初始化最优配置
best_loss = float('inf') # 初始化最优损失为正无穷
# 遍历可能的模型大小 🔍
N_range = np.logspace(7, 11, 100) # 从 10M 到 100B,取 100 个点
for N in N_range: # 遍历每个模型大小
D = C_budget / (6 * N) # 根据预算计算 token 数
# 预测损失 📊
loss = A / (N ** alpha) + B / (D ** beta) + E
# 更新最优配置 ✅
if loss < best_loss: # 如果找到更低的损失
best_loss = loss # 更新最优损失
best_config = {'N': N, 'D': D, 'loss': loss} # 更新最优配置
return best_config # 返回最优配置
# 使用示例 💻
# params = (A, alpha, B, beta, E)
# optimal = search_optimal_config(1e18, params)7.5 实际应用建议 💡
对于不同预算的配置建议 📋:
| 计算预算 | 推荐模型大小 | 推荐 Token 数 | 适用场景 |
|---|---|---|---|
| 1018 FLOPs | ~100M | ~2B | 学术研究、原型验证 |
| 1019 FLOPs | ~300M | ~6B | 中型项目 |
| 1020 FLOPs | ~1B | ~20B | 工业级应用 |
| 1021 FLOPs | ~3B | ~60B | 大规模商用 |
关键原则 🎯:
- 遵循 Chinchilla 比例 ⚖️: D≈20N
- 不要过早停止训练 🛑:训练到损失收敛
- 验证实验 🧪:在大规模训练前,先用小规模 IsoFLOPs 实验验证
- 考虑实际约束 🛠️:显存限制、训练时间、数据获取成本
优化预算参考资料:
- Training Compute-Optimal Large Language Models -- arXiv ⭐值得阅读
- Chinchilla Proves GPT-3 Under-Trained -- LinkedIn
- LLM Scaling Laws: From GPT-3 to o3 -- Substack
8. 总结 🎯 / Summary
8.1 核心要点回顾 📝
| 概念 | 关键内容 | 公式/比例 |
|---|---|---|
| 缩放定律 | 性能与规模呈幂律关系 📈 | L(N)=A×N−α+L0 |
| Kaplan 定律 | 大模型 + 少数据 + 提前停止 🏢 | 偏向增大模型 |
| Chinchilla 定律 | 模型与数据等比例缩放 🦫 | D≈20N |
| IsoFLOPs | 固定计算量下找最优配置 🔬 | C=6ND |
| 计算最优 | 在预算下最小化损失 ⚖️ | Noptimal=C/120 |
8.2 作业三的核心价值 💎
-
理论联系实际 🌉
- 从论文中的缩放定律 → 实际拟合实验数据
- 理解抽象的幂律关系如何指导工程实践
-
培养直觉 💡
- 通过 IsoFLOPs 实验,建立对"多大模型配多少数据"的直觉
- 理解为什么 Chinchilla 的比例更优
-
工程能力 🛠️
- 学习曲线拟合技术
- 掌握在约束条件下优化配置的方法
- 为未来训练大模型打下基础
8.3 实际应用意义 🌍
对业界的指导价值 💼:
- GPT-4、Llama、PaLM 等大模型都参考了缩放定律来设计配置
- 节省计算成本:避免在次优配置上浪费数百万美元的 GPU 费用
- 预测性能:在训练前就能预估模型的最终表现
对研究者的启示 🔬:
- 缩放定律可能不是永恒的,在更大规模下可能出现相变(Phase Transition)
- 需要持续验证和更新缩放定律
- 理解缩放定律的理论机制(为什么是幂律?)仍是开放问题
8.4 下一步学习方向 🧭
虽然本文档聚焦于作业三的内容,但缩放定律领域还有很多值得探索的方向:
- 稀疏模型的缩放定律 🕸️:MoE(Mixture of Experts)架构的缩放规律
- 多模态缩放定律 🖼️:文本、图像、音频联合训练的缩放规律
- 推理期缩放定律 🔍:测试时计算(Test-Time Compute)的缩放规律
- 理论解释 📐:为什么神经网络遵循幂律?与统计物理的联系
总结参考资料:
- Scaling Laws for Neural Language Models -- arXiv ⭐值得阅读
- Training Compute-Optimal Large Language Models -- arXiv ⭐值得阅读
- Neural scaling law -- Wikipedia
- 斯坦福 CS336 课程官网 -- Stanford
- LLM Scaling Laws: From GPT-3 to o3 -- Substack
最后更新时间:2026-06-23