适用版本 :Chrome/Edge 114+ | Manifest V3 | 2026年6月
阅读收益:了解一个浏览器扩展如何从 AI 网页提取内容、还原公式、重建表格,并导出为可编辑的 Word 文档
前言
上一版本的插件有一个明显的问题------导出为doc文件,老版本的格式致使很多设备难以打开(当然复制内容至自己新建文件中也是可以的),故新版本改变了方案,实现了docx的导出;由于AI输出内容可能会随网页版更新,导致原有的捕获格式不正确,故插件的更新的是必要的,这里仅提供该版本的技术方案。
一、功能概览
NQ-Assistant 是一个浏览器扩展 ,为 DeepSeek / ChatGPT / Claude / Kimi / 豆包 五个 AI 平台提供统一的导出体验:
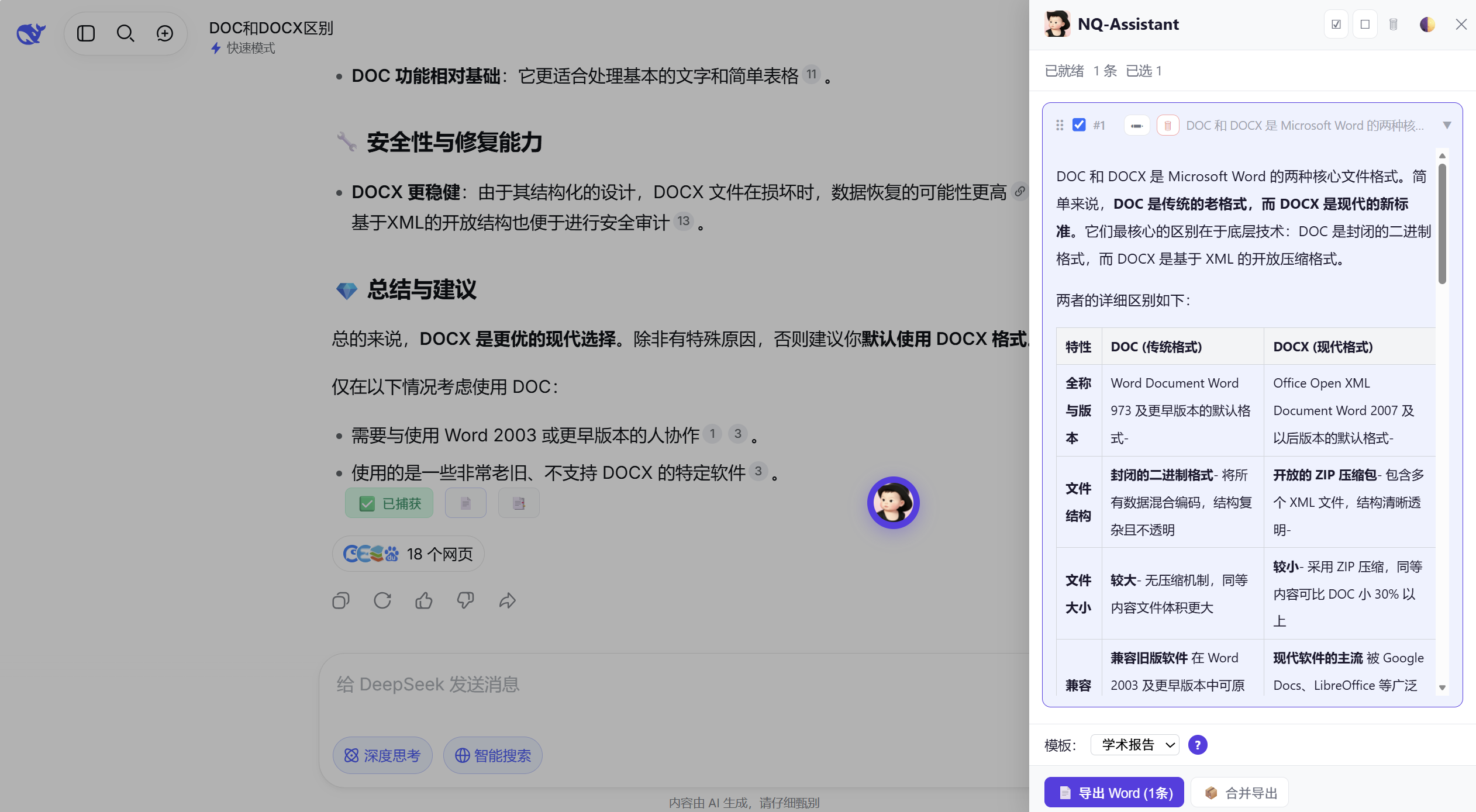
| 功能 | 说明 |
|---|---|
| 📋 一键捕获 | 每条 AI 回复旁自动注入按钮,点击即捕获 |
| 📄 直接导出 | 对话页内直接导出 Word / PDF,无需进侧栏 |
| 🧹 自动清洗 | 自动去除思考过程、引用编号、搜索摘要等噪声 |
| 📊 表格还原 | 豆包 div 表格自动重建为 <table>,Turndown 绕过修复 |
| ✏️ 编辑公式 | LaTeX 公式转为 Word OMML 可编辑公式(支持分式、根式、矩阵、积分等) |
| 🎨 多模板 | 学术报告 / 技术文档 / 会议纪要 / 原始输出 四种模板 |
| 🌓 深色主题 | 侧栏支持亮色/暗色切换 |
| 🔢 目录生成 | 可选的自动生成 TOC |
二、整体架构
AI 网页 (DeepSeek/ChatGPT/Claude/Kimi/豆包)
│
▼ content.js ← 注入按钮 + DOM 清洗 + 表格重建 + 公式还原
│
▼ background.js ← 消息中转 + chrome.storage 持久化
│
▼ sidepanel.js ← markdown-it 渲染 + 模板导出 Word/PDF
│
▼ Word 文档 ← docx 库生成 .docx (OMML 可编辑公式)技术栈
| 层 | 技术 |
|---|---|
| 浏览器扩展 | Manifest V3 + Side Panel API |
| Markdown 解析 | marked(导出端)+ markdown-it(预览端) |
| 公式处理 | KaTeX → LaTeX 还原 → latex2omml 转 OMML |
| Word 生成 | docx 库(原生 OMML 支持) |
| HTML→Markdown | Turndown(带表格预提取旁路) |
三、核心技术实现
3.1 多平台 DOM 提取与清洗管线
javascript
// 平台自动检测
const PLATFORMS = {
deepseek: { host:'chat.deepseek.com', message:'.ds-message', markdown:'.ds-markdown' },
doubao: { host:'doubao.com', message:'[class*="side-by-side-messages"]', markdown:'__SELF__' },
// ... chatgpt, claude, kimi
};8 层清洗管线(按执行顺序):
- KaTeX/MathJax 还原 --- 选择器覆盖
.katex、[class*="math-inline"]、math[data-mjx-texclass],12 级提取链(data-mjx-tex→data-latex→annotation→svg[data-latex]→script[math/tex]等) - DOM 诊断 --- 统计标签分布、表格候选、公式属性(调试用)
- 代码块规范化 --- 提取语言标签,移除运行按钮
- 表格重建 --- 嵌套行结构检测(豆包专属)+ 平铺网格兜底
- 标题规范化 --- div 伪标题转为 h1-h6
- 思考过程移除 --- 过滤 think/reasoning 区块
- UI 元素清理 --- 移除按钮/工具栏(保护表格内部元素)
- 引用链接清理 --- 过滤 citation/reference 标记
3.2 豆包表格识别(关键难点)
豆包使用嵌套 div 行结构 (外部容器 → 行 div → 单元格 div),不同于 DeepSeek 的标准 <table> 写法。
旧方案:仅检测同一父节点的平级子节点数量。豆包 2×3 表格只有 2 个子节点(两行)< 阈值 4,完全跳过。
新方案:两阶段检测
- Phase 1:
detectRowPattern()检测嵌套行模式(所有子节点同标签 + 各含等量单元子节点 + className 黑名单过滤) - Phase 2:
detectFlatColumnCount()平铺网格兜底
Turndown 绕过 :表格 DOM 正确重建后,Turndown 内置规则仍无法转换 <table> → Markdown 管道线。htmlToMarkdown 中提前用 DOM 替换法提取 <table>,转为 [NQTBL0] 纯文本标记,Turndown 处理后再用正则换回 Markdown 表格。
3.3 数学公式 OMML 转换
采集端(content.js):
- 优先从
<script type="math/tex">提取权威 LaTeX 源码(findMathContainer定位容器) - 兜底从 annotation / SVG data-latex / MathJax alttext 提取
- 纯文本数学(无 LaTeX 控制符)以 Cambria Math 斜体输出,避免产生乱码 OMML
导出端(md2docx.js / latex2omml.js):
preProcessMath保护$$...$$避免被 marked 误解析pushTextWithMath检测行内$...$,含控制符(\^_{})的走latex2docx生成 OMMLlatex2omml支持:分式\frac、根式\sqrt、求和\sum、积分\int、矩阵\begin{bmatrix}、希腊字母、间距命令\quad/\qquad、\text{...}空格保留等- 未知环境(
\begin{aligned}等)不丢弃,压平为多行表达式显示
3.4 导出模板系统
| 模板 | 字体 | 字号 | 用途 |
|---|---|---|---|
| 学术报告 | SimSun 宋体 | 12pt | 论文/报告 |
| 技术文档 | Microsoft YaHei | 11pt | 技术方案 |
| 会议纪要 | Microsoft YaHei | 11pt | 会议记录 |
| 原始输出 | Consolas 等宽 | 10pt | 保留 Markdown 原文 |
- 直接导出(对话页按钮)默认用"学术报告"
- 侧栏导出可选模板,
compatibilityModeVersion: 12确保新旧 Word 均能渲染 OMML
四、测试覆盖
| 测试项 | DeepSeek | 豆包 |
|---|---|---|
| 按钮注入 | ✅ | ✅ |
| 表格识别 | ✅ | ✅ |
| 代码块高亮 | ✅ | ✅ |
| 行内公式 OMML | ✅ | ✅ |
| 块级公式 OMML | ✅ | ✅ |
矩阵 \begin{bmatrix} |
✅ | ← |
间距命令 \quad |
✅ | --- |
| 思考过程过滤 | ✅ | ✅ |
| 引用编号清理 | ✅ | ✅ |
| 直接导出 Word | ✅ | ✅ |
| PDF 导出 | ✅ | ✅ |
五、安装与使用
bash
git clone https://github.com/NQLOVELSJ/NQ_Assitant.git- 打开
chrome://extensions,开启「开发人员模式」 - 点击「加载解压缩的扩展」→ 选择项目文件夹
- 打开任意支持的 AI 平台,AI 回复下方出现 📋 预览 按钮
- 点击预览 → 侧栏捕获;或直接点击 📄 导出 Word / 📑 PDF
- 快捷键
Ctrl+E快速导出
六、项目文件结构
ai-export-extension/
├── content.js ← 核心:DOM 清洗 + 公式还原 + 表格重建 + 按钮注入
├── sidepanel/
│ ├── sidepanel.html ← 侧栏 UI
│ ├── sidepanel.js ← 渲染 + 编辑 + 模板导出
│ └── sidepanel.css
├── lib/
│ ├── md2docx.js ← Markdown → docx 转换(raw 模式支持)
│ ├── latex2omml.js ← LaTeX → OMML 公式转换
│ ├── docx.bundle.js ← docx 库
│ ├── marked.min.js ← Markdown 解析器
│ ├── katex.min.js ← 侧栏公式渲染
│ └── turndown.min.js ← HTML → Markdown 转换
├── background.js ← Service Worker
├── manifest.json
└── 测试/ ← 测试数据与导出对比文档本文基于 NQ-Assistant v2.3.4 实际代码编写,所有功能均可直接验证。