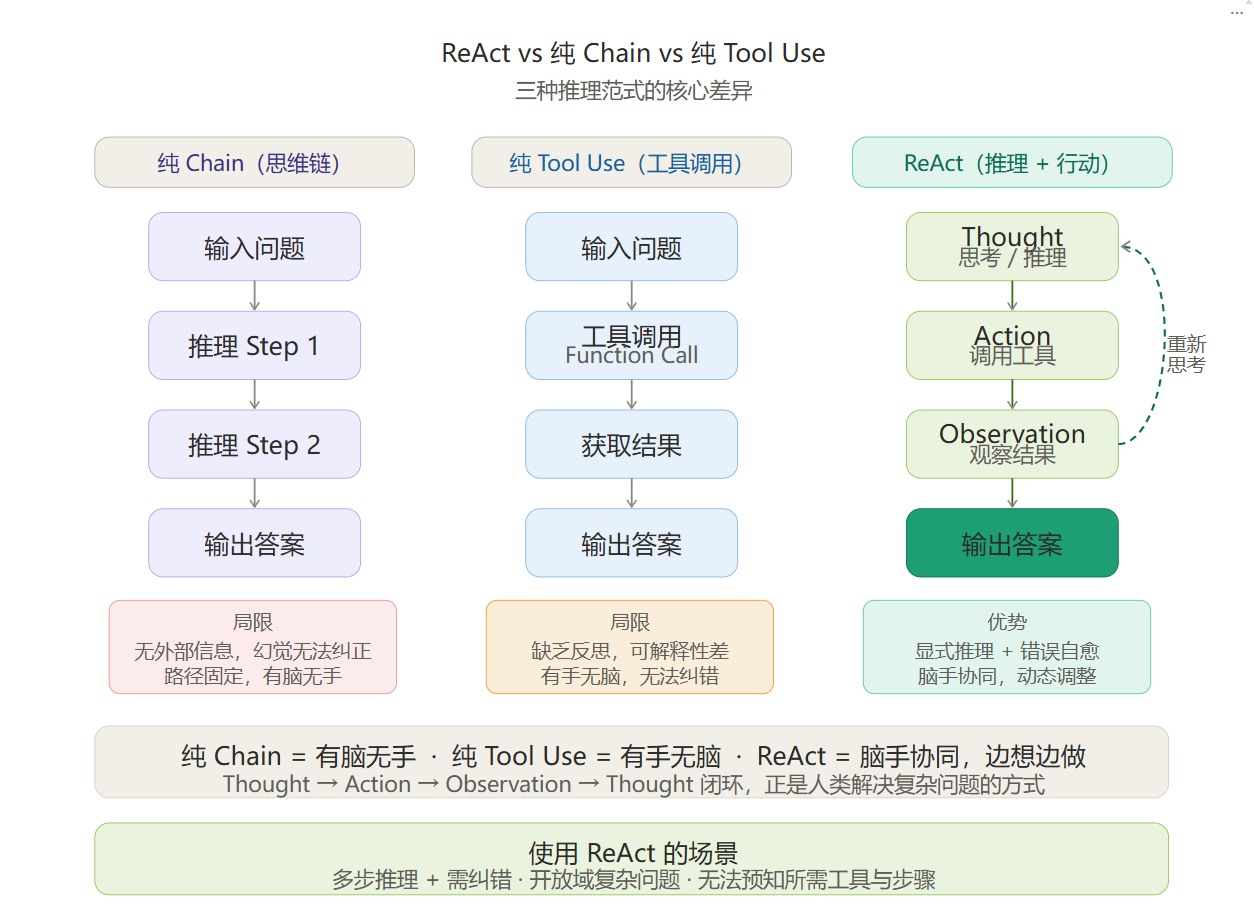
一、三种范式对比
| 维度 | 纯 Chain(思维链) | 纯 Tool Use(工具调用) | ReAct(推理+行动) |
|---|---|---|---|
| 核心流程 | 一次性推理到底 | 调用工具 → 拿结果 → 继续调用 | 思考 → 行动 → 观察 → 再思考 循环 |
| 有无反馈闭环 | ❌ 无 | ⚠️ 隐式(工具结果可直接用,但不显式推理) | ✅ 显式推理 + 观察整合 |
| 可解释性 | 中等(有推理步骤,但静态) | 低(只见工具调用链) | 高(每一步思考都可见) |
| 错误恢复能力 | ❌ 一步错,全盘错 | ⚠️ 工具失败可重试,但缺乏反思 | ✅ 观察失败后可重新推理 |
| 动态调整 | ❌ 路径固定 | ⚠️ 工具链可微调 | ✅ 根据观察结果改变策略 |
二、逐一对比如下
2.1 纯 Chain:线性推理的局限
纯 Chain(Chain of Thought)是一次性规划好推理路径,然后按顺序执行。
输入问题
│
▼
Step 1: 推理 → Step 2: 推理 → Step 3: 推理 → ... → 输出答案问题:
- 不能与外部交互------无法查资料、调 API、读文件
- 幻觉无法纠正------推理中产生错误信息,没有外部信息源来校验
- 路径僵化------如果第三步推理需要第一步的实际结果,纯 Chain 做不到
例子:用户问"今天北京天气怎么样?"
| 纯 Chain | ReAct |
|---|---|
| 直接编一个天气(幻觉) | Thought: 需要查实时天气 → Action: 调用天气 API → Observation: 晴,25°C → Thought: 可以回答了 → Answer |
2.2 纯 Tool Use:有手无脑
纯 Tool Use 是让模型直接调用工具,不要求显式的推理过程。
Function Call → Result → Function Call → Result → ... → Output问题:
- 缺乏反思环节------工具返回了意料之外的结果,模型可能机械地继续而不是调整思路
- 可解释性差------用户/开发者看到的是工具调用历史,而不是"为什么这样调"
- 复杂推理能力弱------多步任务需要"调用哪个工具 → 结果说明什么 → 下一步该做什么"的推理链,纯调用缺乏中间的 reasoning trace
对比示例:用户问"帮我查一下腾讯今天的股价,如果涨幅超过 3% 就发微信通知我"
| 纯 Tool Use | ReAct |
|---|---|
get_stock("0700.HK") → 结果 |
Thought: 先查股价 |
send_wechat(...) → 结果 |
Action : get_stock("0700.HK") |
| (直接发通知,可能不判断涨幅) | Observation: 涨了 4.2% |
| Thought: 涨幅 4.2% > 3%,需要通知 | |
Action : send_wechat("涨幅 4.2%") |
|
| Observation: 发送成功 | |
| Answer: 已通知 |
三、ReAct 的核心优势
3.1 反馈闭环
Thought思考Action行动Observation观察
每一步行动都有观察结果,观察结果驱动下一步的思考。这是一个感知-行动闭环。
3.2 错误自愈
Thought: 我需要查订单 #12345 的状态
Action: query_order(order_id=12345)
Observation: 订单不存在
Thought: 可能 ID 记错了,让我先搜索用户名 "张三" 的订单
Action: search_orders(user_name="张三")
Observation: 找到 3 个订单,[#12346, #12347, #12348]
Thought: 最近的一条是 #12346,查询它
Action: query_order(order_id=12346)
Observation: 状态 = 已发货
Answer: 您最近的订单 #12346 已发货如果第一步出错就停止,这就是纯 Chain/Tool Use 的问题。ReAct 通过 Thought → Observation → 重新 Thought 实现了主动纠错。
3.3 可解释性与调试友好
| 层级 | 能看到什么 |
|---|---|
| 用户视角 | 模型每一步在想什么,为什么调这个工具 |
| 开发者视角 | 推理路径是否合理,Prompt 是否产生了偏差 |
| 安全审计 | 完整的决策链,可追溯每一步逻辑 |
3.4 动态任务分解
ReAct 可以根据当前观察动态决定下一步,而非提前规划死。
复杂问题: "帮我分析这份财报,挑出营收增长最快的三个业务线"
↓
Thought: 先提取财报 → Action: read_file → Observation: 200页PDF
↓
Thought: 太长了,先看目录 → Action: get_toc → Observation: 5个业务线
↓
Thought: 逐个提取营收数据 → Action: extract_revenue → ...
↓
(根据每步结果,动态决定下一个要处理的业务线)四、ReAct 的实现范式
class ReActAgent:
"""最简 ReAct 循环"""
def __init__(self, llm, tools: dict):
self.llm = llm
self.tools = tools # {"search": func, "calc": func, ...}
self.history = []
def run(self, question: str, max_steps: int = 10) -> str:
prompt = self._build_prompt(question)
for _ in range(max_steps):
response = self.llm(prompt)
# 解析 Thought / Action / Observation
parsed = self._parse(response)
if parsed["type"] == "answer":
return parsed["content"]
if parsed["type"] == "action":
# 执行工具
tool = self.tools.get(parsed["action"])
result = tool(parsed["input"])
obs = f"Observation: {result}"
self.history.append(f"{response}\n{obs}")
prompt = self._build_prompt(question, self.history)
def _parse(self, response: str) -> dict:
"""从 LLM 输出中解析 Thought / Action / Final Answer"""
# 匹配 Thought: ... \n Action: tool_name[input]
# 或 Final Answer: ...
...
def _build_prompt(self, question: str, history=None) -> str:
return f"""Answer the following question. You may use these tools:
{tools_desc}
Use this format:
Thought: your reasoning
Action: tool_name[input]
Observation: tool result
... (repeat)
Final Answer: your answer
Question: {question}
History: {history or ''}
"""Prompt 模板决定了 ReAct 的结构:
You have access to the following tools:
- search[query]: 搜索互联网
- calculator[expression]: 数学计算
Use the following format:
Thought: 你当前的推理
Action: 要调用的工具
Action Input: 工具参数
Observation: 工具返回的结果
... (这个 Thought/Action/Observation 循环可重复)
Final Answer: 最终给用户的回答
Question: {user_question}五、ReAct 也有局限
| 局限 | 说明 | 缓解方案 |
|---|---|---|
| Token 消耗高 | 每次 Thought + Action + Observation 都占上下文 | 对历史做摘要压缩 |
| 死循环风险 | 反复进入同一条 Reasoning 路径 | 设置 max_steps 上限 + 重复检测 |
| 推理质量依赖 Prompt 设计 | Prompt 写得不好,模型可能跳步骤或格式错误 | 结构化输出(JSON Mode)+ Few-shot 示例 |
| 延迟高 | 每步都要 LLM 推理 + 工具调用 + 再 LLM 推理 | 允许并行 action(ReWOO 等变体) |
六、决策矩阵:什么时候该用哪种范式
| 场景 | 推荐范式 | 原因 |
|---|---|---|
| 简单问答、无需外部信息 | 纯 Chain / 直接生成 | 不需要工具,ReAct 反而浪费 token |
| 单步工具调用(查一次天气) | 纯 Tool Use / Function Calling | 无需反思循环 |
| 多步推理 + 工具 + 需纠错 | ReAct ✅ | 需要观察 → 重新推理的闭环 |
| 确定性工作流(固定步骤) | 纯 Chain + Tool Use | 路径已定,不需要动态调整 |
| 开放域复杂问题 | ReAct ✅ | 无法预知所需步骤和工具 |
七、总结
纯 Chain = 有脑无手 (只能想,不能做) 纯 Tool Use = 有手无脑 (能做,但不会反思) ReAct = 脑手协同(边想边做,做完了想,想清楚再做)
ReAct 的核心价值在于 Thought → Action → Observation → Thought 的闭环 ,这正是人类解决复杂问题的方式:尝试、观察、调整、再尝试。对于 AI Agent 需要动态决策的场景,这个闭环是不可替代的决策引擎。