Milvus架构与核心原理
文章目录
- Milvus架构与核心原理
- [1 整体认识](#1 整体认识)
- [2 三种部署方式](#2 三种部署方式)
- [3 分清逻辑数据模型和物理处理模型](#3 分清逻辑数据模型和物理处理模型)
-
- [3.1 Database](#3.1 Database)
- [3.2 Collection](#3.2 Collection)
- [3.3 Schema](#3.3 Schema)
- [3.4 Field](#3.4 Field)
- [3.5 Entity](#3.5 Entity)
- [3.6 Partition](#3.6 Partition)
- [3.7 Shard](#3.7 Shard)
- [3.8 Segment](#3.8 Segment)
-
-
- [3.8.1.1 Growing Segment](#3.8.1.1 Growing Segment)
- [3.8.1.2 Sealed Segment](#3.8.1.2 Sealed Segment)
-
- [4 分布式 Milvus 的四层架构](#4 分布式 Milvus 的四层架构)
-
- [4.1 Client SDK](#4.1 Client SDK)
- [4.2 Proxy: 无状态访问层](#4.2 Proxy: 无状态访问层)
- [4.3 Coordinator: 控制平面的"大脑"](#4.3 Coordinator: 控制平面的“大脑”)
- [4.4 Streaming Node: 实时数据负责人](#4.4 Streaming Node: 实时数据负责人)
- [4.5 Query Node: 历史数据查询引擎](#4.5 Query Node: 历史数据查询引擎)
- [4.6 Data Node: 历史数据后台处理节点](#4.6 Data Node: 历史数据后台处理节点)
- [5 三类持久化存储](#5 三类持久化存储)
-
- [5.1 Meta Storage: etcd](#5.1 Meta Storage: etcd)
- [5.2 WAL:Write\-Ahead Log](#5.2 WAL:Write-Ahead Log)
- [5.3 Object Storage](#5.3 Object Storage)
- [6 VChannel,PChannel,Shard](#6 VChannel,PChannel,Shard)
-
- [6.1 VChannel](#6.1 VChannel)
- [6.2 PChannel](#6.2 PChannel)
- [6.3 为什么需要两层 Channel](#6.3 为什么需要两层 Channel)
- [6.4 主键散列与写入路由](#6.4 主键散列与写入路由)
- [7 一次insert内部发生了什么](#7 一次insert内部发生了什么)
-
- [7.1 Insert返回不等于索引已经建立好](#7.1 Insert返回不等于索引已经建立好)
- [7.2 TSO](#7.2 TSO)
- [8 Flush、Index、Load、Handoff](#8 Flush、Index、Load、Handoff)
-
- [8.1 Flush](#8.1 Flush)
- [8.2 Index Building](#8.2 Index Building)
- [8.3 Load](#8.3 Load)
- [8.4 Handoff](#8.4 Handoff)
- [9 一次Search内部发发生了什么](#9 一次Search内部发发生了什么)
-
- [9.1 TopK](#9.1 TopK)
- [9.2 Search 与 Query](#9.2 Search 与 Query)
- [10 标量过滤与BitSet](#10 标量过滤与BitSet)
-
- [10.1 BitSet](#10.1 BitSet)
-
- [10.1.1 BitSet是什么?](#10.1.1 BitSet是什么?)
- [10.1.2 必须先定义1的含义](#10.1.2 必须先定义1的含义)
- [10.1.3 BitSet如何参数属性过滤](#10.1.3 BitSet如何参数属性过滤)
- [10.1.4 BitSet如何参与删除](#10.1.4 BitSet如何参与删除)
- [10.2 案例](#10.2 案例)
-
- [10.2.1 查询时间ts=150](#10.2.1 查询时间ts=150)
- [10.2.2 查询时间ts=250](#10.2.2 查询时间ts=250)
- [10.2.3 查询时间ts=350](#10.2.3 查询时间ts=350)
- [10.3 删除时不会立即释放对象存储空间](#10.3 删除时不会立即释放对象存储空间)
- [11 时间戳与数据可见性](#11 时间戳与数据可见性)
-
- [11.1 Guarantee Timestamp](#11.1 Guarantee Timestamp)
- [11.2 Service Timestamp](#11.2 Service Timestamp)
- [11.3 Graceful Time](#11.3 Graceful Time)
- [12 四种一致性级别](#12 四种一致性级别)
-
- [12.1 Strong](#12.1 Strong)
- [12.2 Bounded Staleness](#12.2 Bounded Staleness)
- [12.3 Session](#12.3 Session)
- [12.4 Eventually](#12.4 Eventually)
- [13 Compaction](#13 Compaction)
1 整体认识
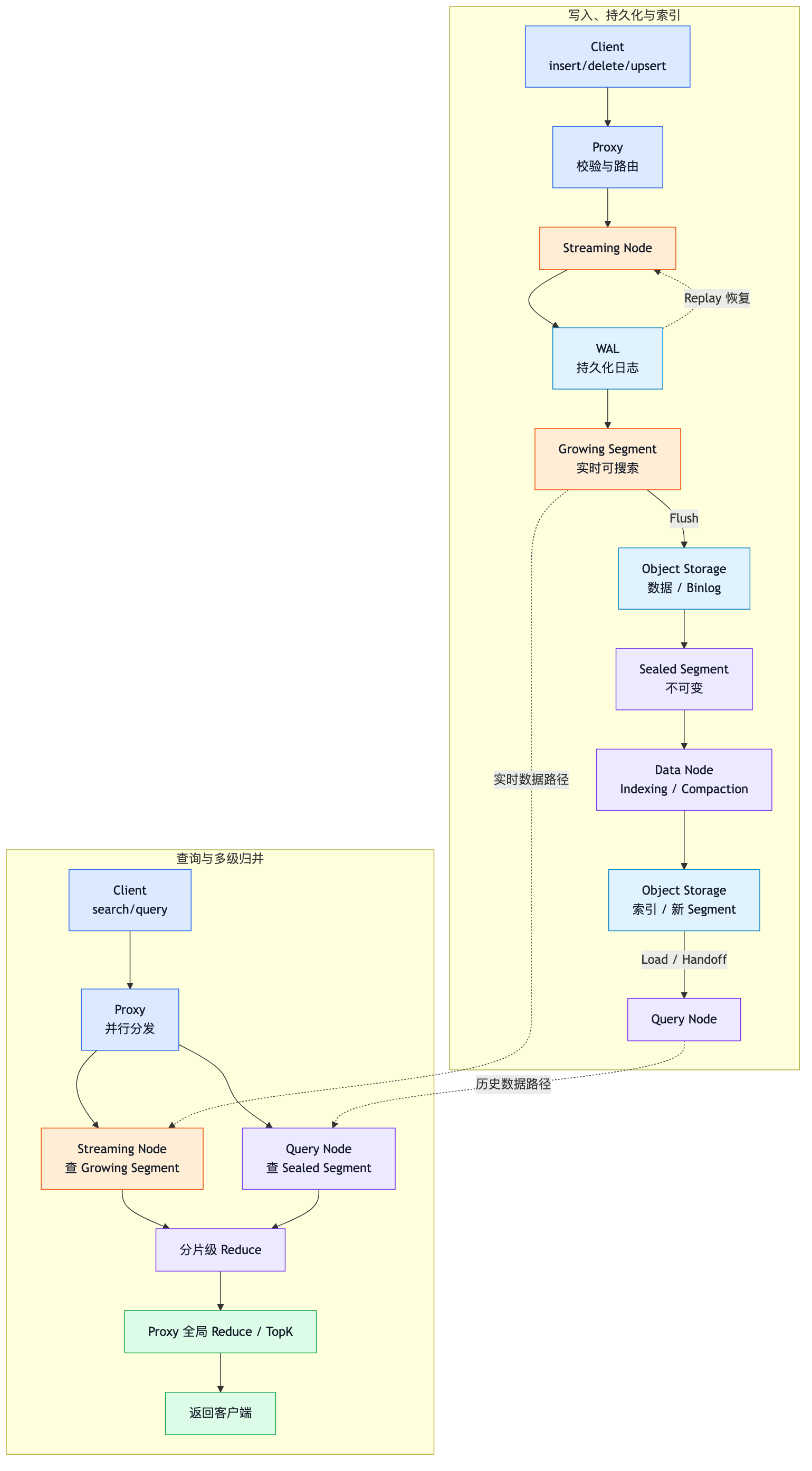
Milvus 不是"把向量写进一个文件,然后从这个文件里搜索"的简单程序。分布式 Milvus 把以下工作拆给不同组件:
-
接收、校验和路由请求;
-
协调集群中的任务和数据分布;
-
处理实时写入及实时数据查询;
-
查询已经持久化的历史数据;
-
构建索引、压缩数据段;
-
持久化元数据、操作日志、原始数据和索引。
数据和索引的持久副本放在共享存储中,计算节点可以按需加载数据。计算节点发生故障时,系统可以重新调度节点并从 WAL、元数据存储和对象存储恢复,而不是把某台计算节点的本地磁盘当作唯一数据来源。
来源:Milvus 架构概述
2 三种部署方式
Milvus官网给出了三种部署方式
| 部署模式 | 形态 | 适用场景 | 官网给出的规模参考 |
|---|---|---|---|
| Milvus Lite | 嵌入 Python 应用,本地文件持久化 | 学习、Notebook、原型、边缘设备 | 数百万向量以内 |
| Milvus Standalone | 所有服务组件打包在单机 Docker 部署中 | 中小规模生产环境 | 可扩展到约 1 亿向量 |
| Milvus Distributed | 组件运行在 Kubernetes 集群中 | 大规模生产、高可用、独立扩缩容 | 约 1 亿到数百亿向量 |
Milvus Lite
MilvusClient("milvus_demo.db")会创建一个嵌入应用进程的本地向量数据库。它适合学习 API,但不能据此认为生产集群也只有一个.db文件。
三种部署共享主要客户端 API,因此从 Lite 迁移到服务端部署时,业务代码通常不需要重写,但底层组件数量、可用功能和一致性能力并不完全相同。
3 分清逻辑数据模型和物理处理模型
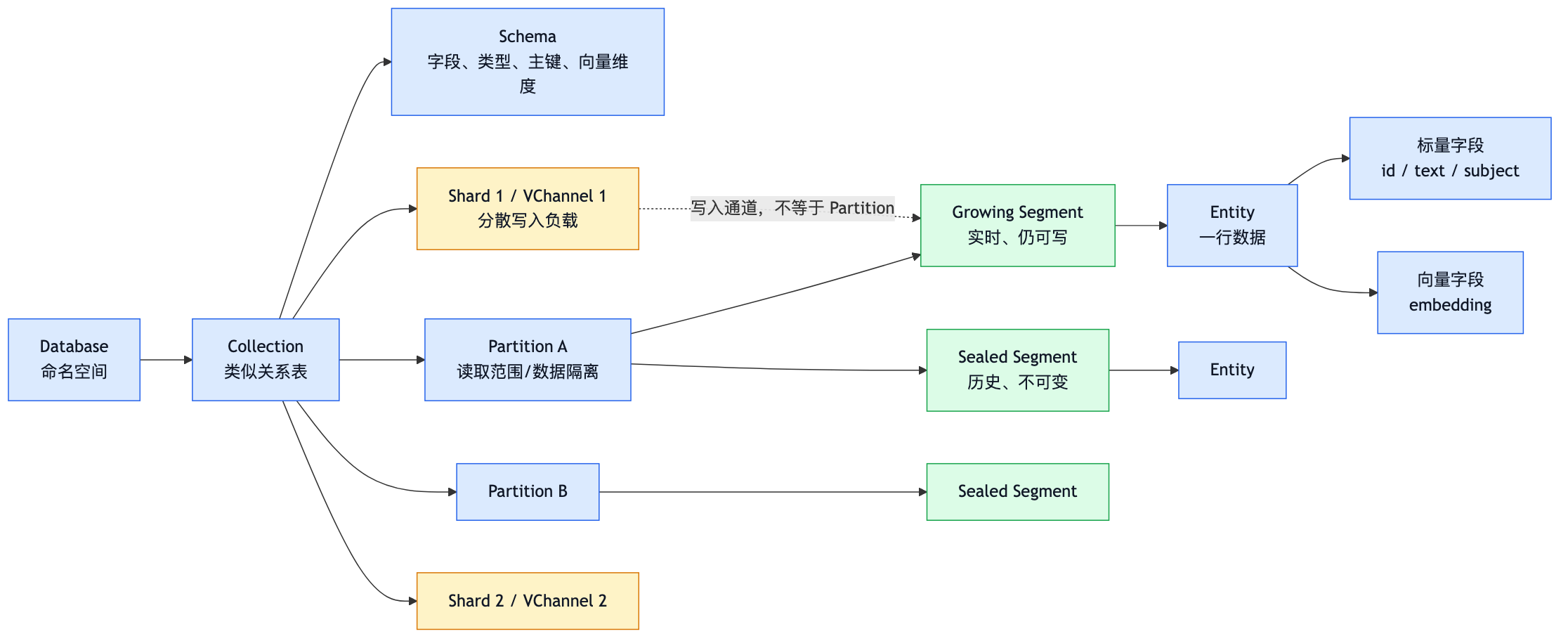
3.1 Database
Database: 命名空间
Database用于组织多个collection,他不是向量数据的直接处理单位
可以类比关系型数据库中的数据库
Python
Database
├── Collection: documents
├── Collection: images
└── Collection: users3.2 Collection
Collection:逻辑数据表
Collection 是存储和管理实体的主要逻辑对象。官网将它类比成关系数据库的表:列是 Field,行是 Entity。
例如一个rag知识库可以设计为:
| id | text | source | category | vector |
|---|---|---|---|---|
| 1 | "Milvus 是向量数据库......" | milvus.md | database | 0.12, ... |
| 2 | "LangChain 是......" | langchain.md | framework | 0.38, ... |
3.3 Schema
Schema: Collection的结构定义
Schema描述Collection中有哪些字段,字段类型,主键,向量维度以及其他字段属性
一个字段可以是:
-
主键字段,例如
id; -
标量字段,例如
text、price、category; -
向量字段,例如
FLOAT_VECTOR、SPARSE_FLOAT_VECTOR; -
动态字段中保存的额外属性。
向量字段通常还需要声明维度,例如dim=768表示每个向量必须包含 768个分量
3.4 Field
Field:Collection 的一列
标量字段保存结构化属性,向量字段保存 Embedding。
标量字段参与:
-
输出结果;
-
标量查询;
-
元数据过滤;
-
分区键;
-
标量索引。
向量字段参与:
-
ANN 相似性搜索;
-
范围搜索;
-
混合搜索;
-
向量索引。
3.5 Entity
Entity: Collection中的一行记录
同一行所有字段的值共同组成一个 Entity,每个 Entity 通过主键识别。
例如
JSON
{
"id": 1,
"vector": [0.12, 0.08, ...],
"text": "Alan Turing...",
"subject": "history",
}3.6 Partition
Partition:Collection 的逻辑子集
Partition 与父 Collection 使用同一个 Schema,但只包含部分实体。指定 Partition 搜索时,可以跳过其他 Partition。
例如按业务隔离:
Python
documents
├── partition: tenant_a
├── partition: tenant_b
└── partition: tenant_cPartition 主要解决:
-
缩小读取范围;
-
按业务或数据生命周期隔离数据;
-
避免搜索无关数据。
3.7 Shard
Shard:Collection 的写入分片
Shard 用于把写入负载分散到多个流处理通道。每个 Shard 对应一个 VChannel。
Shard与Partition不同
| 概念 | 主要目的 |
|---|---|
| Partition | 缩小读取范围、逻辑隔离数据 |
| Shard | 分散写入负载、提高写入并行度 |
不要把 shard_num=4 理解为创建了四个供业务直接选择的 Partition。
3.8 Segment
Segment:Milvus 内部存储和处理数据的基本物理单位
一个 Collection 可以包含多个 Segment。搜索时,Milvus 会在相关 Segment 上执行查询并归并结果。
Segment 分为两种状态。
3.8.1.1 Growing Segment
-
正在接收新数据;
-
尚未全部预存到对象存储;
-
由 Streaming Node 维护;
-
可以参与实时搜索;
-
通常不能像稳定的历史段一样使用完整的持久化索引。
3.8.1.2 Sealed Segment
-
数据已经持久化到对象存储;
-
不再接受新写入,内容不可变;
-
可以由 Data Node 构建正式索引;
-
可由 Query Node 加载并查询。
Flush
Growing Segment 转换为 Sealed Segment 的过程称为 Flush。Flush 影响数据从实时路径进入历史数据路径,但"数据是否能被查询到"还受一致性级别控制,不能简单理解成"不 Flush 就查不到"。
4 分布式 Milvus 的四层架构
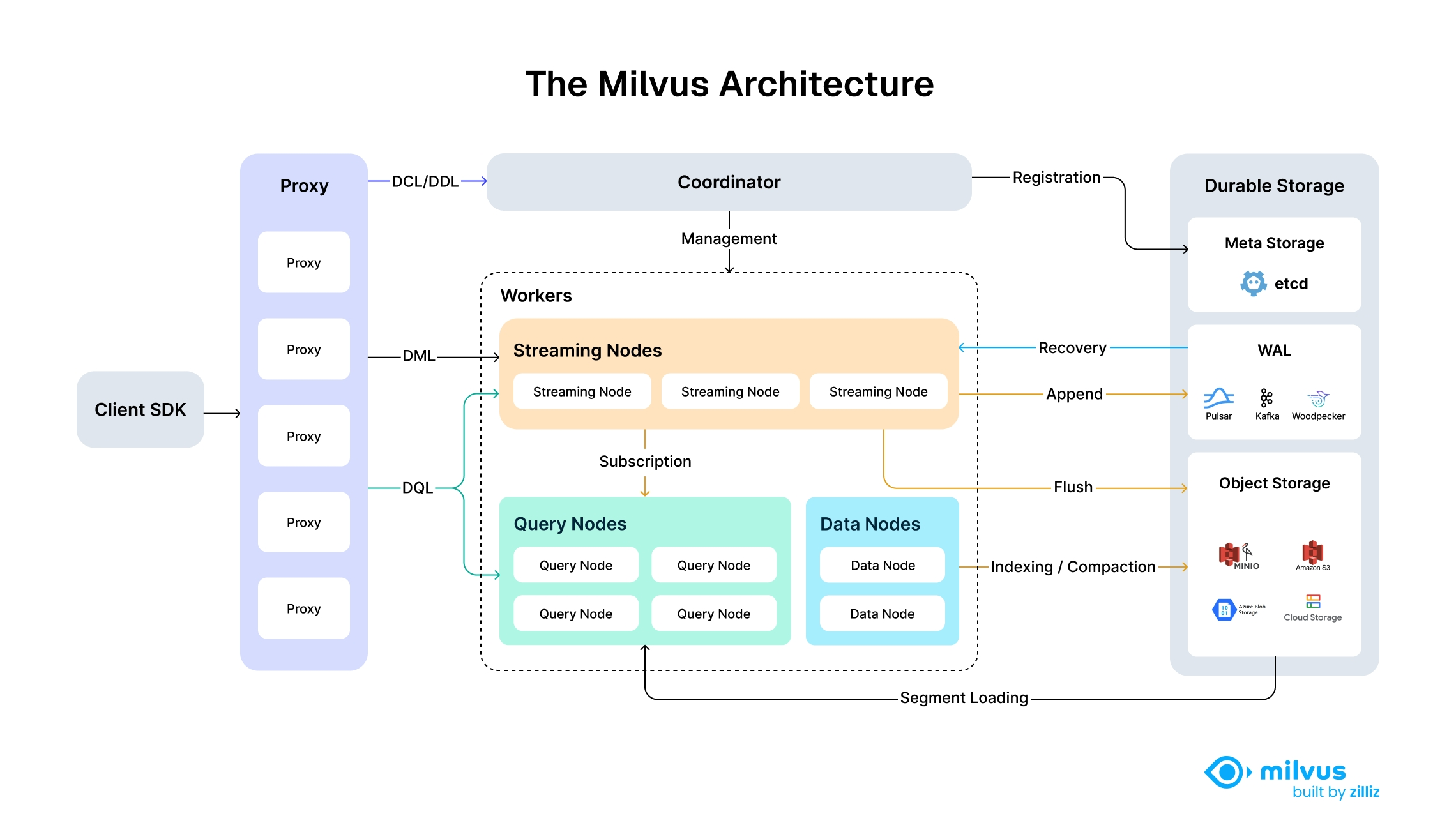
官网把分布式 Milvus 分为:
-
Access Layer:访问层;
-
Coordinator:协调层;
-
Worker Nodes:工作节点;
-
Storage:存储层。
4.1 Client SDK
Client SDK 包括 Python、Java、Go、Node.js、C# 等客户端。
4.2 Proxy: 无状态访问层
Proxy:API 网关、请求校验器、路由器和结果归并器
Proxy 主要负责:
-
接收 SDK 请求;
-
认证和权限检查;
-
校验 Schema、字段类型和向量维度;
-
将请求路由到正确的处理节点;
-
聚合中间查询结果;
-
将最终结果返回客户端。
Proxy 自身不保存向量和索引的权威持久副本,因此可以横向部署多个实例:
Python
┌── Proxy 1
Client ─ LB ─┼── Proxy 2
└── Proxy 3Milvus 使用 MPP(Massively Parallel Processing,大规模并行处理)模式。一个搜索可能在多个 Shard、Segment 和节点上并行执行,再经过多级 Reduce 得到全局结果。
Reduce:结果归并
每个执行节点先返回自己的局部候选结果,上层节点合并、去重或重新排序,最终保留全局 TopK。
4.3 Coordinator: 控制平面的"大脑"
Coordinator:维护集群拓扑、调度任务、管理数据分布和集群级一致性
它负责的任务包括:
-
DDL 和 DCL 管理;
-
Collection、Partition、索引等元数据管理;
-
TSO 与时间刻度管理;
-
WAL 与 Streaming Node 的绑定和服务发现;
-
Query Node 拓扑、负载均衡和查询视图;
-
Segment 拓扑和数据视图;
-
将索引、Compaction 等离线任务分配给 Data Node;
-
节点故障后的重新调度。
Coordinator 不是向量搜索或索引构建的主要执行者。它更像调度中心
Python
Coordinator:将 Segment A 加载到 Query Node 2。
Query Node 2:从对象存储加载 Segment A。
Coordinator:为 Segment B 创建索引。
Data Node:读取 Segment B,构建索引并写回对象存储。官网说明任一时刻集群中有一个活动 Coordinator 负责协调工作。高可用部署中的备用实例不应理解成多个 Coordinator 同时独立修改同一份集群状态。
4.4 Streaming Node: 实时数据负责人
Streaming Node:分片级实时处理节点
它基于 WAL 提供分片级一致性和故障恢复,管理 Growing Segment,并参与实时数据查询。
主要职责:
-
接收
insert、delete、upsert; -
将操作追加到 WAL;
-
为数据包分配 TSO;
-
维护 Growing Segment;
-
搜索本地 Growing Segment;
-
生成分片级查询计划;
-
协调 Query Node 获取 Sealed Segment 的历史结果;
-
Flush Growing Segment;
-
崩溃后重放 WAL。
为什么 Streaming Node 既参与写入又参与查询?
因为刚写入的数据可能还没有:
-
Flush 到对象存储;
-
构建完整的持久化索引;
-
Handoff 到 Query Node。
如果只查 Query Node,就可能漏掉实时数据。因此当前官方架构描述的搜索路径是:
Python
Streaming Node:搜索 Growing Segment
Query Node:搜索 Sealed Segment
↓
合并实时与历史结果4.5 Query Node: 历史数据查询引擎
Query Node:加载并查询 Sealed Segment
Query Node 负责:
-
从对象存储加载 Sealed Segment;
-
加载向量索引和标量索引;
-
执行 Segment 级向量搜索;
-
执行标量过滤;
-
返回局部候选结果。
Query Node 的主要资源是:
-
内存;
-
CPU;
-
可选 GPU;
-
本地缓存;
-
对象存储带宽。
Query Node 的本地数据不是唯一持久副本。节点故障后,系统可以让其他 Query Node 从对象存储重新加载相关 Segment。
4.6 Data Node: 历史数据后台处理节点
Data Node:处理历史数据的离线计算节点
主要职责:
-
构建向量索引;
-
构建标量索引;
-
执行 Compaction;
-
合并或重组 Segment;
-
将处理结果写回对象存储。
Data Node 通常不直接承接在线搜索。这样可以避免索引构建和 Compaction 的 CPU、内存开销干扰查询延迟。
5 三类持久化存储
5.1 Meta Storage: etcd
元数据: 描述数据和集群状态的数据
etcd 主要保存:
-
Collection Schema;
-
Segment 状态;
-
消息消费检查点;
-
服务注册和健康信息;
-
集群拓扑及任务状态。
5.2 WAL:Write-Ahead Log
WAL:先写日志
在提交数据变化前,先将操作写入日志。节点发生故障后,可以重放日志恢复尚未完成的操作。
写入路径不是: insert → 直接修改 Query Node 内存 → 完成
而是
Python
insert
↓
Streaming Node
↓
WAL 持久化
↓
Growing Segment
↓
异步 Flush 到对象存储WAL 中记录的是有顺序的操作,例如:
Python
TSO 1001:Insert PK=1
TSO 1002:Insert PK=2
TSO 1003:Delete PK=1Milvus 架构文档列出的常见 WAL 实现包括 Kafka、Pulsar 和 Woodpecker。Woodpecker 使用面向云对象存储的设计,目的是降低本地磁盘管理成本
5.3 Object Storage
对象存储用于保存大体量持久数据,例如:
-
标量和向量数据;
-
日志快照或 Binlog;
-
Sealed Segment 的数据;
-
向量和标量索引文件;
-
Compaction 产生的新 Segment;
-
部分中间结果。
常见实现包括:
-
MinIO;
-
Amazon S3;
-
Azure Blob Storage。
对象存储延迟通常高于内存,因此正常在线查询路径是:
Python
Object Storage
↓ Load
Query Node 内存或缓存
↓
执行在线搜索6 VChannel,PChannel,Shard
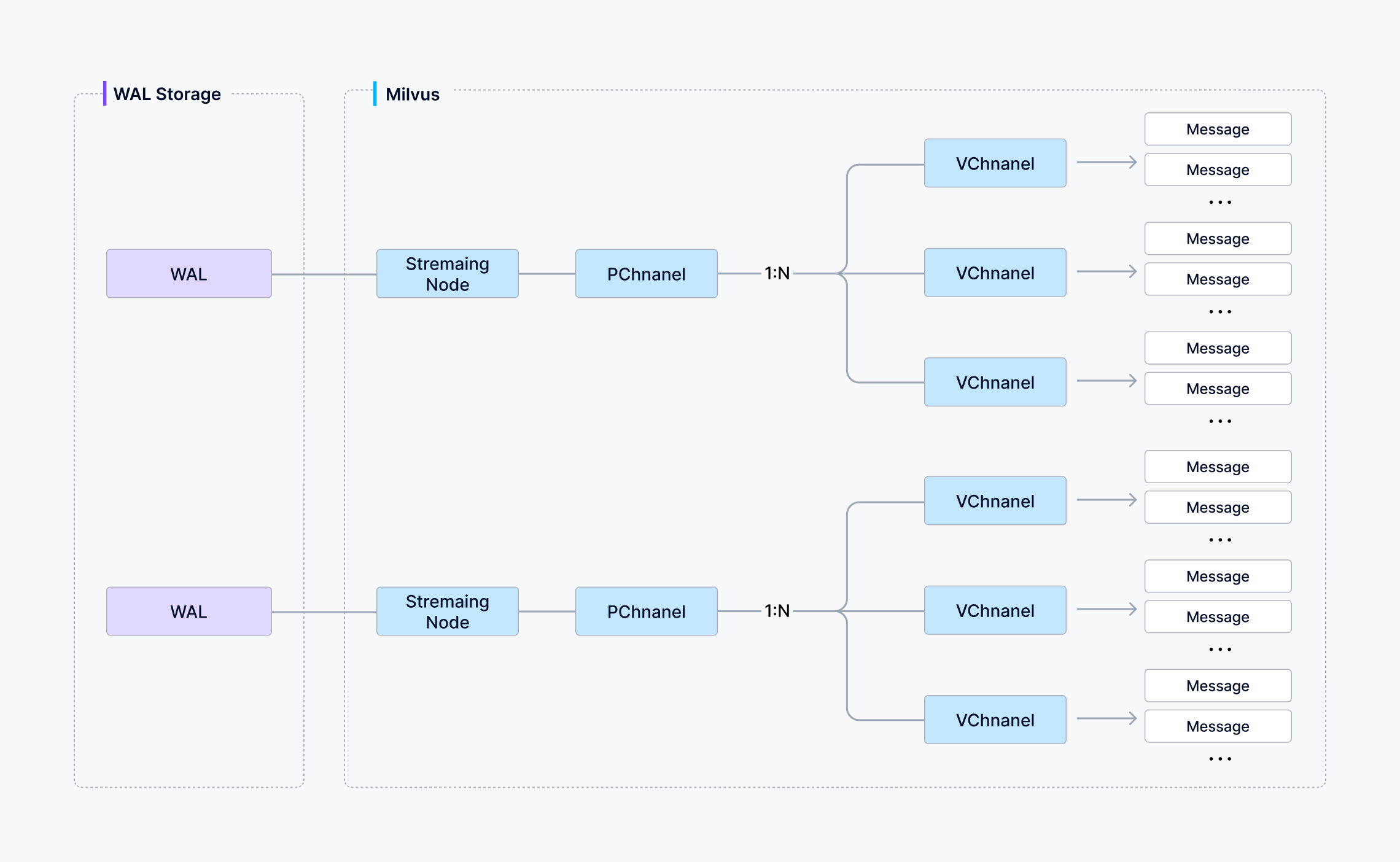
6.1 VChannel
VChannel: 逻辑写入通道
每个Collection的一个Shard对应一个VChannel
它代表一个Collection内的一条逻辑写入流
6.2 PChannel
PChannel:物理 WAL 通道
每个 PChannel 对应一条由底层 WAL 管理的物理日志流,并绑定到一个 Streaming Node。
逻辑关系可以表示为
Python
Collection A / Shard 1 → VChannel A1 ┐
Collection A / Shard 2 → VChannel A2 ├→ PChannel 1 → Streaming Node 1
Collection B / Shard 1 → VChannel B1 ┘6.3 为什么需要两层 Channel
如果业务逻辑直接绑定到底层物理日志,节点扩缩容和故障转移会非常僵硬
VChannel 与 PChannel 分离后:
-
Collection 看到的是稳定的逻辑 Shard;
-
系统可以调整逻辑通道到物理 WAL 的映射;
-
PChannel 可以重新绑定到其他 Streaming Node;
-
故障节点负责的日志可由新节点重放。
6.4 主键散列与写入路由
Milvus 使用基于主键散列的 Shard 路由,将写入分散到不同 Shard,从而利用多个节点并行写入。
这不等于:
-
相同语义的向量一定进入同一 Shard;
-
同一 Partition 只有一个 Shard;
-
查询只需要访问一个 Shard。
如果查询没有可用于裁剪范围的条件,Proxy 可能需要请求所有相关 Shard,再做全局结果归并。
7 一次insert内部发生了什么
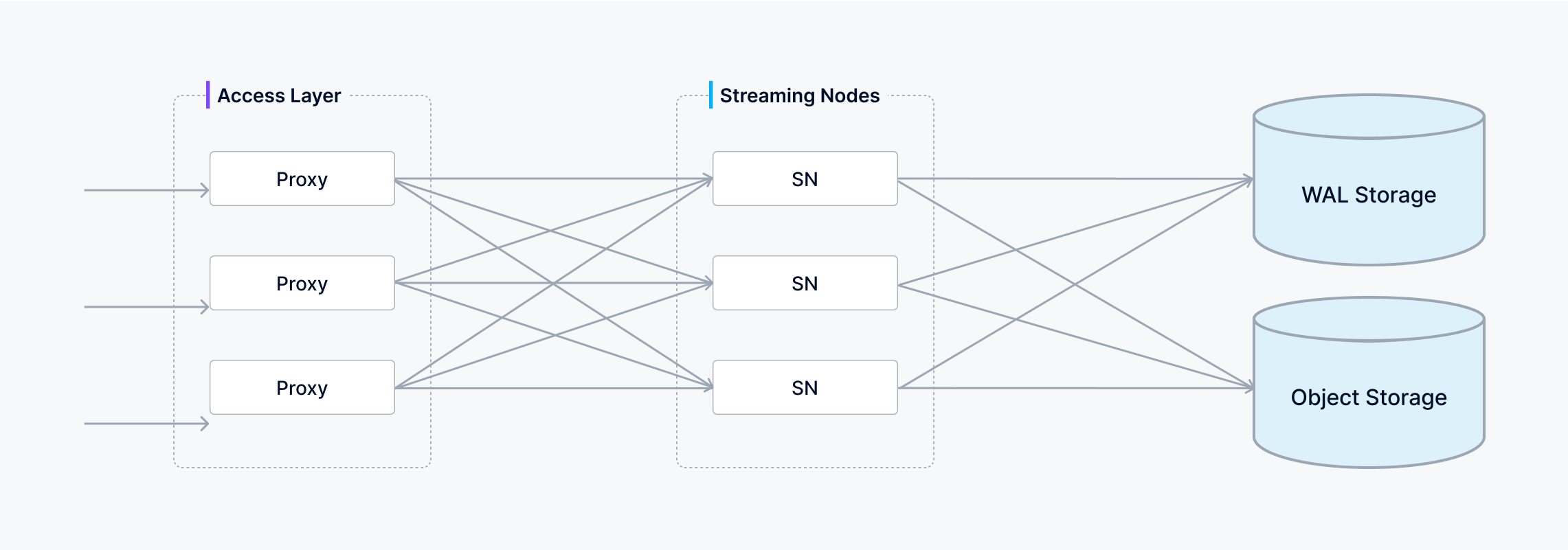
如果执行以下代码:
JSON
client.insert(
collection_name="demo_collection",
data=[
{
"id": 1,
"vector": [0.12, 0.08, ...],
"text": "Milvus architecture",
"subject": "database",
}
],
)内部流程可以理解为:
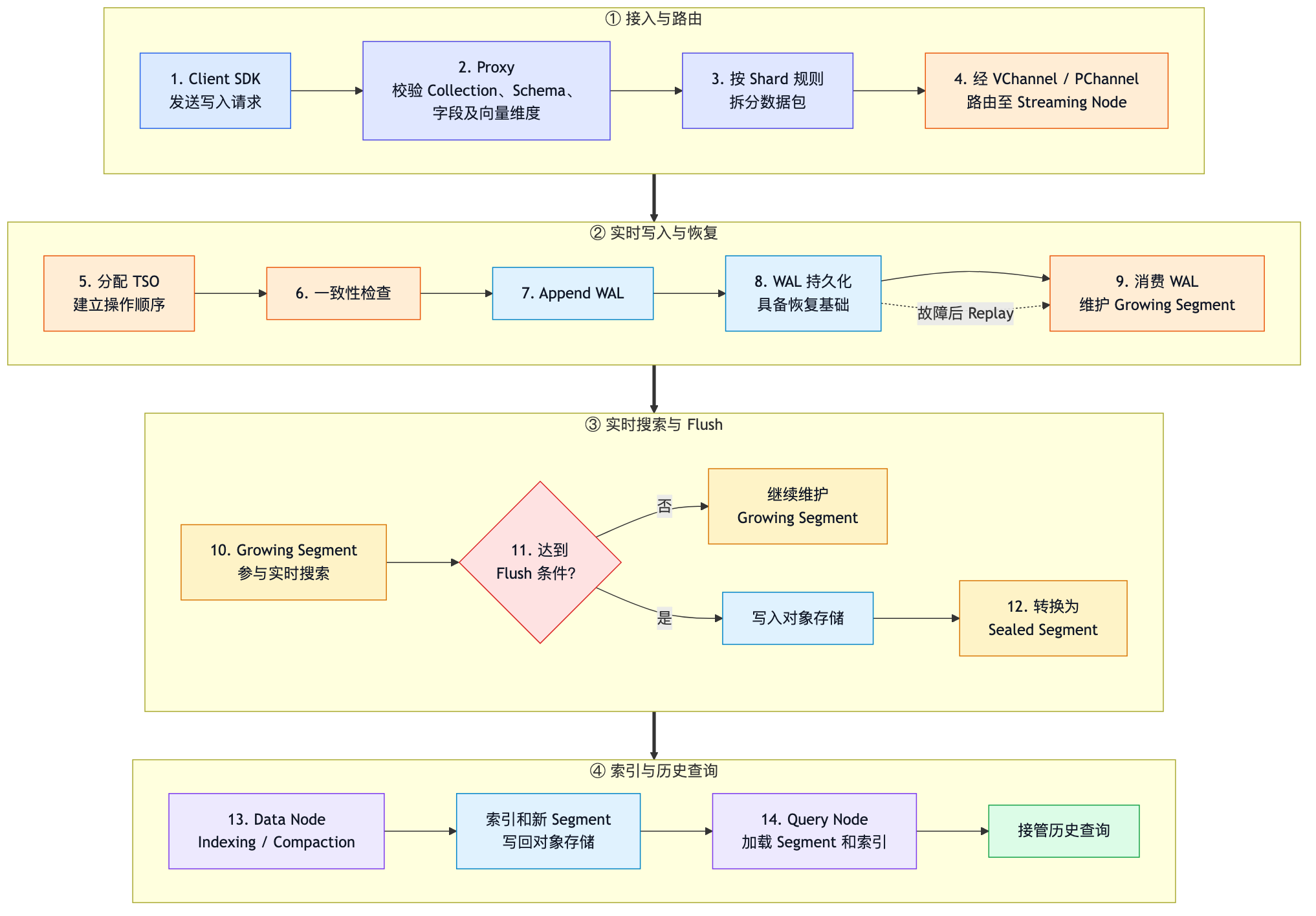
7.1 Insert返回不等于索引已经建立好
insert() 返回时,不应该推断:
-
HNSW、IVF 等索引已经完成;
-
Segment 已经 Flush;
-
数据已经加载进 Query Node。
数据是否立即对搜索可见,主要由一致性级别和服务时间推进情况决定,而不是简单由 Flush 决定。
7.2 TSO
TSO:Timestamp Oracle
TSO 为 DML 操作建立可比较的时间顺序,用于数据可见性、一致性判断和恢复。
同一个 DML 批次中的实体共享同一时间戳。时间戳不是业务字段,而是 Milvus 内部用于排列数据变化顺序的逻辑依据。
8 Flush、Index、Load、Handoff
8.1 Flush
Python
Growing Segment
↓ Flush
对象存储中的持久化数据
↓
Sealed SegmentFlush 解决的是实时数据向历史持久数据转换的问题。
8.2 Index Building
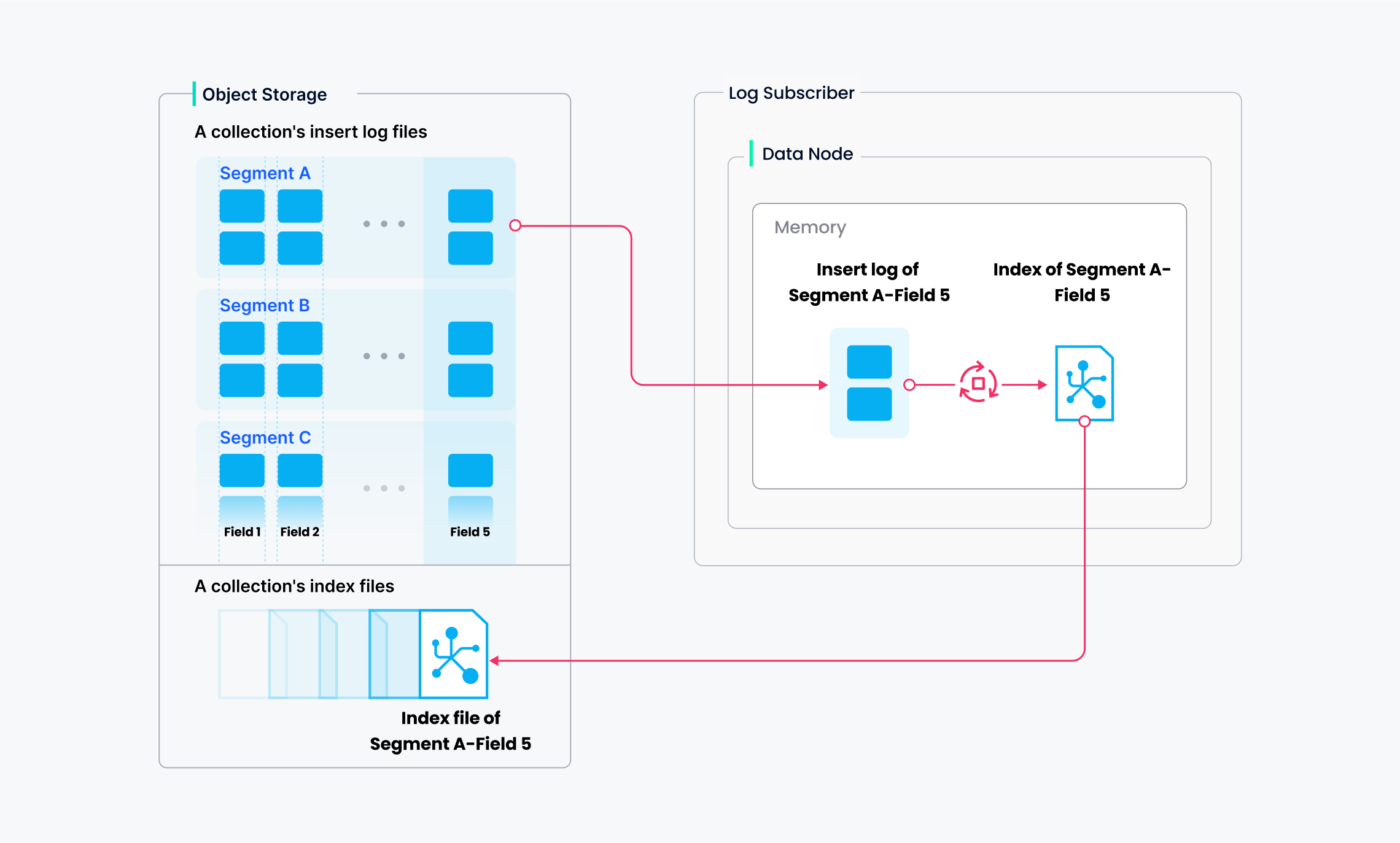
索引构建由Data Node 执行
Python
对象存储中的 Segment 数据
↓
Data Node 下载并反序列化
↓
构建向量或标量索引
↓
序列化索引
↓
写回对象存储向量索引
向量索引是从原始向量衍生出的搜索数据结构,用于减少搜索时需要比较的候选向量数量。
例如:
-
FLAT:近似理解为穷举比较;
-
IVF:先把向量划分到多个聚类桶,再搜索部分桶;
-
HNSW:构建多层近邻图,通过图遍历寻找候选;
-
DISKANN:面向磁盘的大规模 ANN 检索。
索引通常是在 Segment 级别构建,而不是整个 Collection 只生成一个不可分割的大索引。
8.3 Load
Load:把搜索所需的数据和索引加载到 Query Node
Python
Object Storage
↓
Query Node 内存 / 缓存8.4 Handoff
Handoff:把查询责任从实时路径交接给历史数据路径
当 Growing Segment 被 Flush,或者 Data Node 完成 Compaction 后,Coordinator 会协调 Sealed Segment 在 Query Node 上的分配,并释放冗余 Segment。
9 一次Search内部发发生了什么
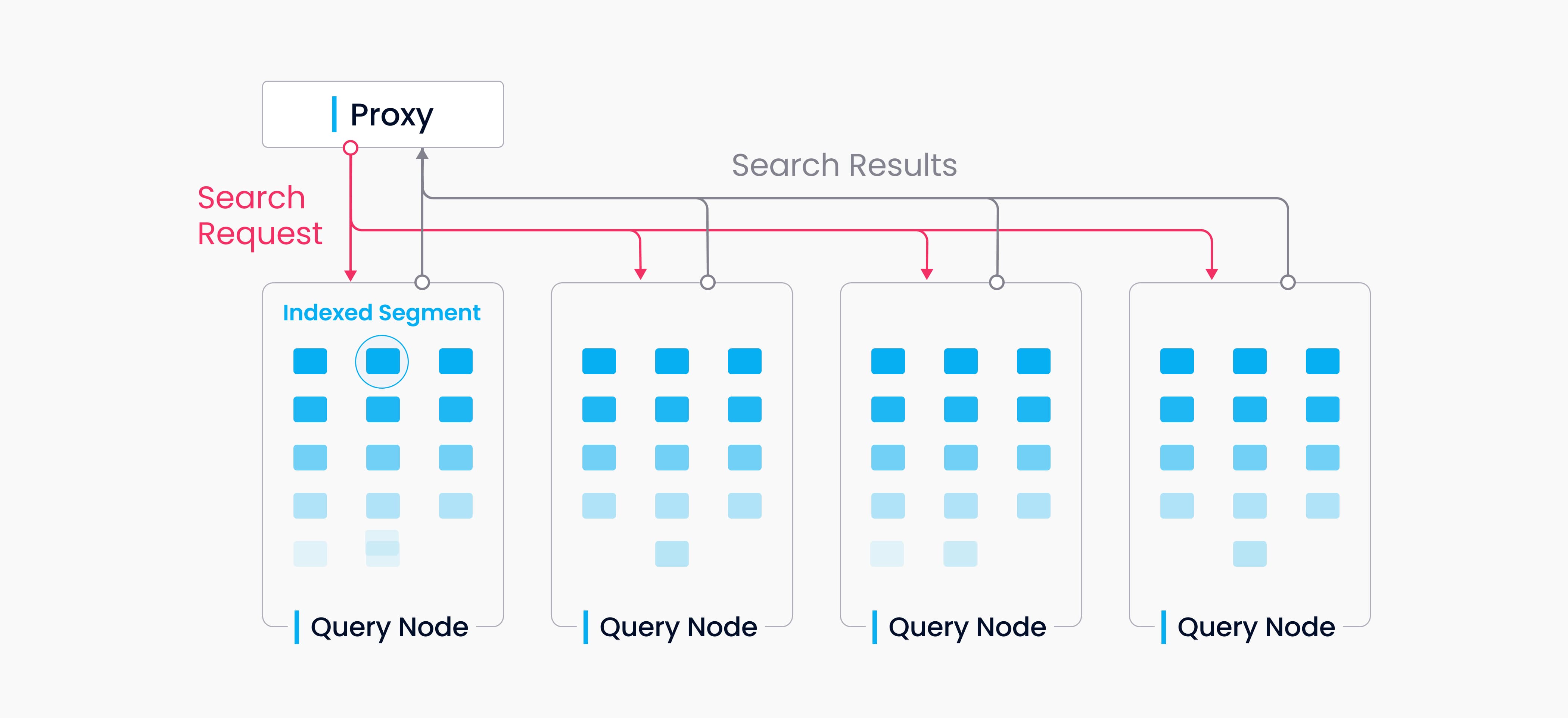
Python
client.search(
collection_name="demo_collection",
data=[query_vector],
filter="subject == 'biology'",
limit=10,
output_fields=["text", "subject"],
)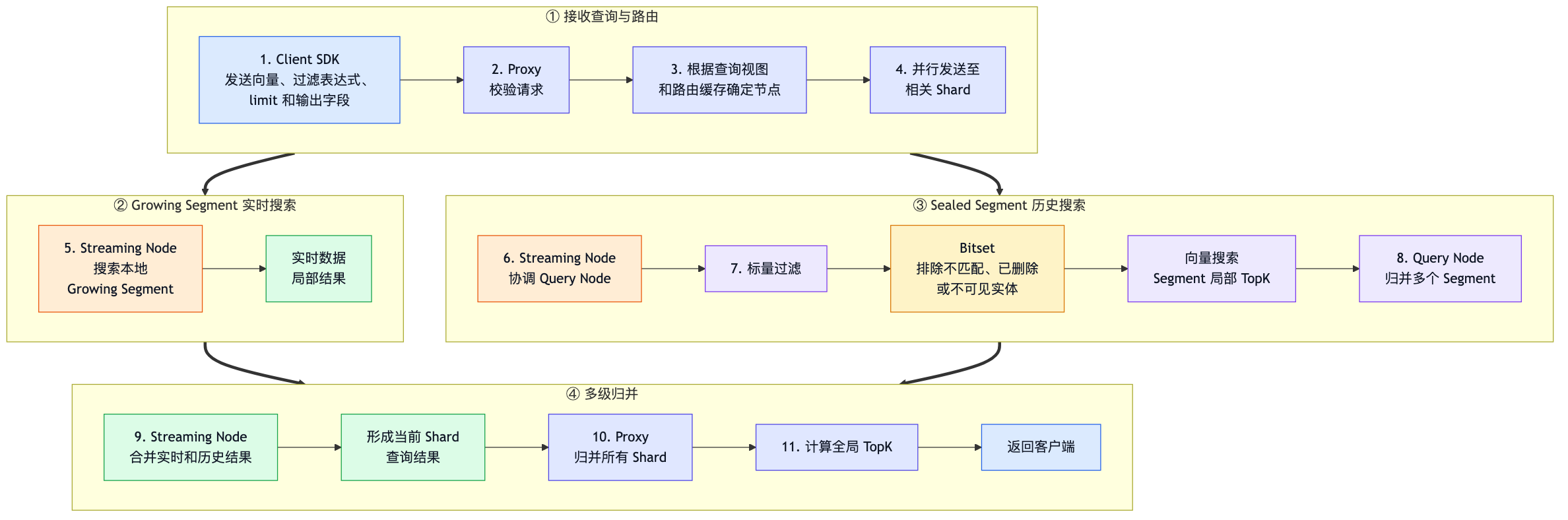
9.1 TopK
TopK:按距离或相似度排序后保留最优的 K 个候选
如果 limit=10,并不表示每个 Segment 只产生一个候选。底层节点可能先产生局部候选,再经过多级 Reduce 得到全局前 10。
9.2 Search 与 Query
| API | 主要用途 |
|---|---|
| search() | 使用查询向量执行相似性搜索,可附加标量过滤 |
| query() | 按主键或过滤表达式检索实体,主要是标量查询 |
10 标量过滤与BitSet
Python
client.search(
collection_name="demo_collection",
data=embedding_fn.encode_queries(
["tell me AI related information"]
),
filter="subject == 'biology'",
limit=2,
output_fields=["text", "subject"],
)Milvus 不应该对所有向量完成距离计算后,才逐条检查 subject。对于大规模数据,这会浪费大量计算。典型过程是:
Python
解析过滤表达式
↓
计算哪些行满足标量条件
↓
形成 Bitset
↓
与删除、时间可见性等掩码组合
↓
向量搜索跳过不可参与计算的行10.1 BitSet
10.1.1 BitSet是什么?
Bitset:由 0 和 1 组成的紧凑数组
每个 bit 可以对应 Segment 中的一行,用来表示这一行是否满足某种条件。
假设 Segment 有 8 行:
Python
行位置: 1 2 3 4 5 6 7 8
Bitset: 1 0 1 0 1 0 1 0Bitset 比为每一行存储完整整数或对象更紧凑,也适合执行按位布尔运算。
10.1.2 必须先定义1的含义
1 没有脱离上下文的永恒语义:
-
在"条件命中 Bitset"中,
1可以表示该行满足过滤条件; -
在"删除 Bitset"中,
1表示该行已删除,应被跳过; -
在最终"排除 Bitset"中,
1表示该行不参与后续搜索。
10.1.3 BitSet如何参数属性过滤
假设过滤条件是PK ∈ {1, 3, 5, 7}
首先的到"命中bitset": match = [1, 0, 1, 0, 1, 0, 1, 0]
如果后续搜索组件使用的是"1 表示跳过"的排除掩码,就需要翻转:
filter_exclude = NOT match = [0, 1, 0, 1, 0, 1, 0, 1]
于是向量搜索就会跳过 2,4,6,8,只计算 1,3,5,7
10.1.4 BitSet如何参与删除
假设实体 7 和 8 已删除,那么delete_exclude = [0, 0, 0, 0, 0, 0, 1, 1]
10.2 案例
假设有下面的时间顺序
-
ts=100:插入 PK 1、2、3、4; -
ts=200:插入 PK 5、6、7、8; -
ts=300:删除 PK 7、8; -
属性条件只匹配 PK 1、3、5、7。
10.2.1 查询时间ts=150
此时只有1,2,3,4, 属性条件在该时间点存在的只有1,3
最终的排除掩码:
[0,1,0,1,1,1,1,1]只有1,3参与搜索
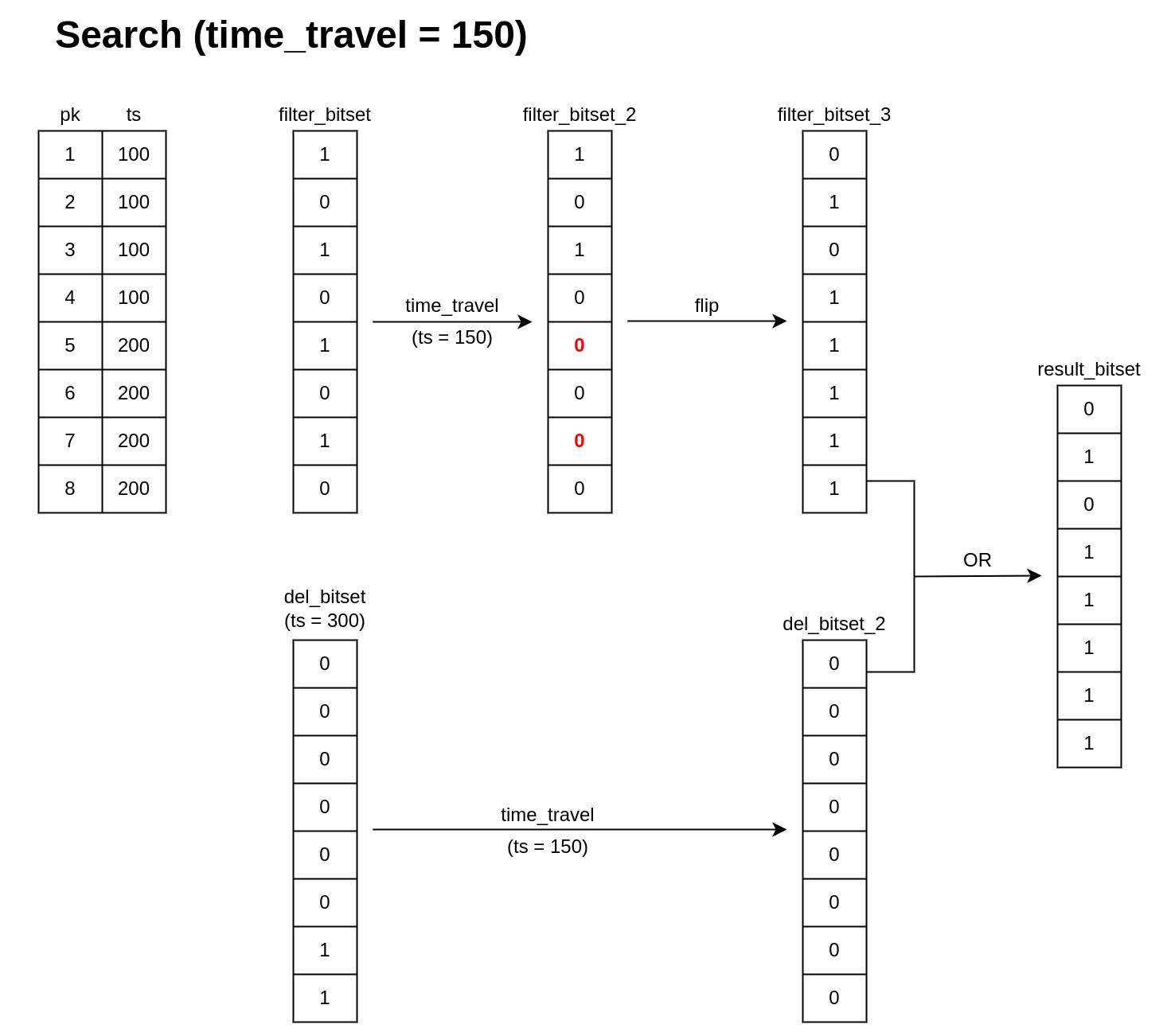
10.2.2 查询时间ts=250
此时有1-8的数据,最终的排除掩码: [0,1,0,1,0,1,0,1]
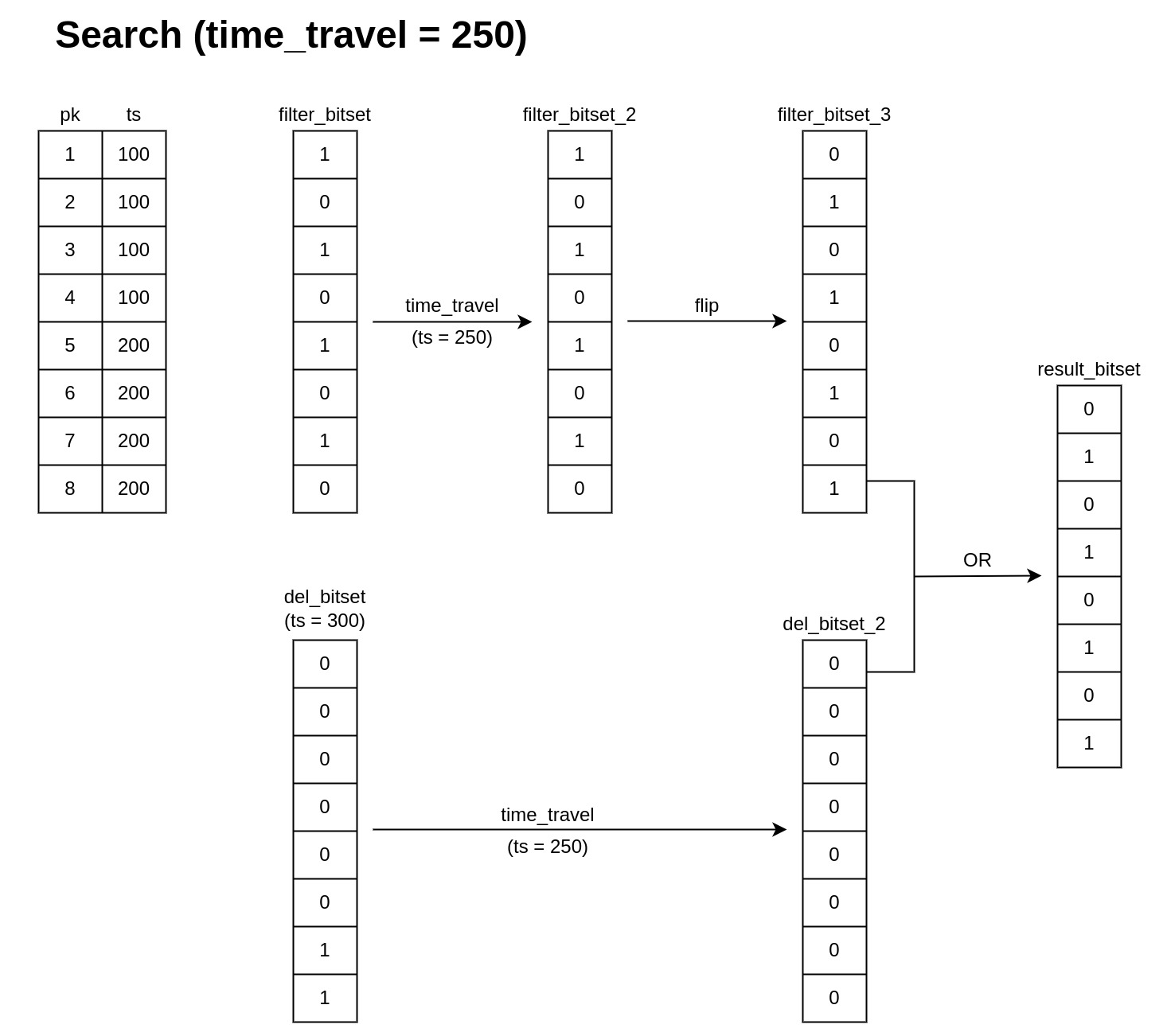
10.2.3 查询时间ts=350
此时1-8都曾被插入,但是7,8被删除
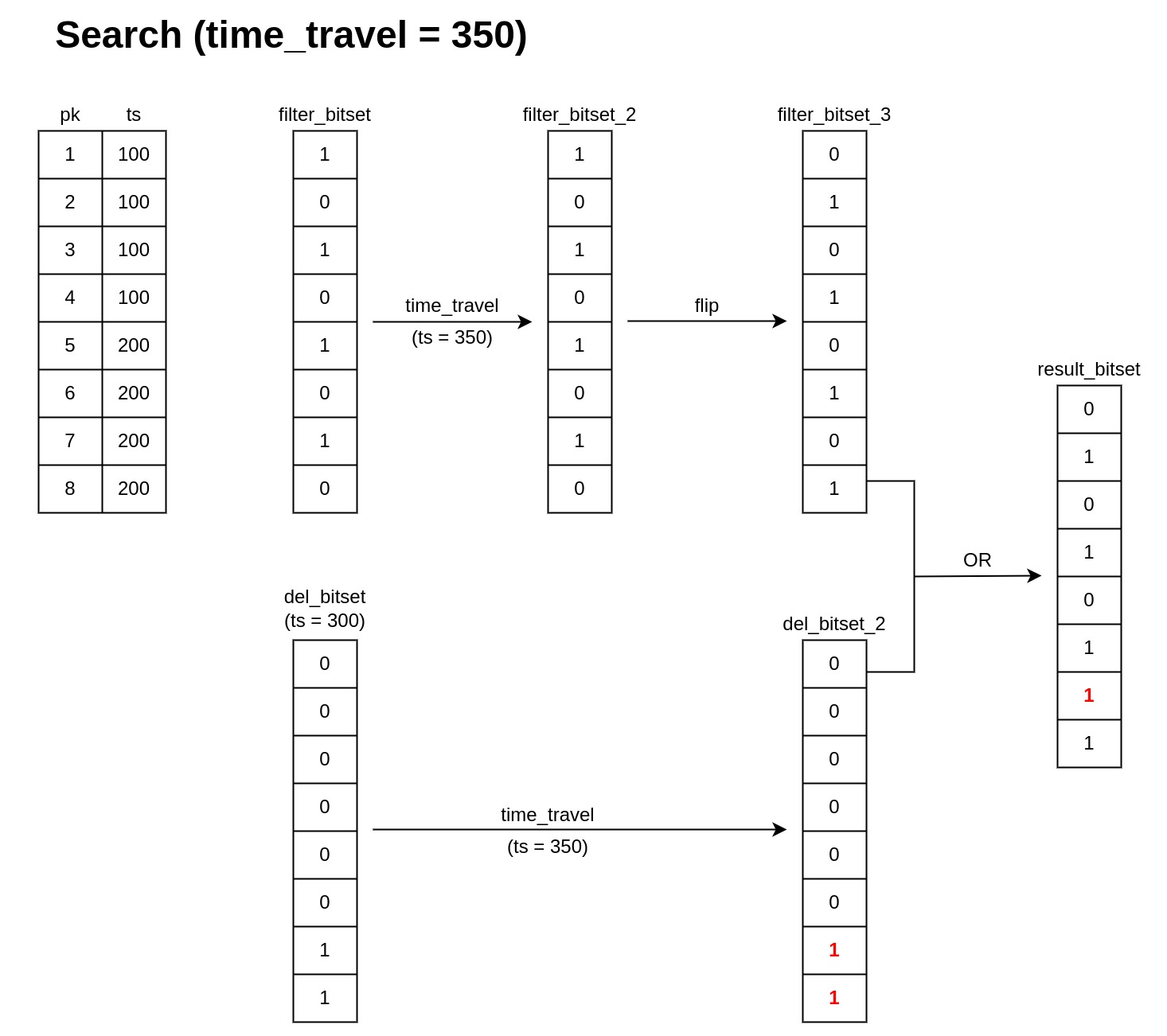
10.3 删除时不会立即释放对象存储空间
删除首先使实体在查询结果中不可见,但底层旧 Segment 占用的空间通常不会立即释放。
过程如下:
-
删除被作为逻辑删除处理;
-
后台 Compaction 合并 Segment,并去掉逻辑删除或过期实体;
-
旧 Segment 被标记为 Dropped;
-
Garbage Collection 最终清理旧 Segment,释放存储空间。
11 时间戳与数据可见性
11.1 Guarantee Timestamp
Guarantee Timestamp
搜索或查询执行前,Milvus 必须保证该时间戳之前的 DML 更新对查询可见。
例如
Python
15:00 插入 A
17:00 插入 B
Guarantee Timestamp = 18:00执行查询时,A 和 B 都应该进入查询所依据的数据视图。
通常用户不需要直接计算内部 TSO,而是通过一致性级别表达需求。
11.2 Service Timestamp
Service Timestamp
表示查询服务已经处理完成并能保证可见的数据时间点。
查询执行时会比较Guarantee Timestamp和Service Timestamp
如果Guarantee Timestamp > Service Timestamp:
说明查询服务尚未追上所需数据,强一致性请求需要等待时间推进。
否则说明数据变化已经可见,可以执行查询
11.3 Graceful Time
Graceful Time
一个允许数据视图落后于最新写入的时间窗口,它是时长而不是时间戳。
有界滞后一致性可以接受一定时间窗口内的数据暂时不可见,以换取更低查询等待时间。
12 四种一致性级别
分布式系统通常需要在一致性、可用性和延迟之间权衡。Milvus 支持四种一致性级别。
12.1 Strong
强一致性:查询必须看到最新数据视图
Milvus 将 GuaranteeTs 对齐到最新系统时间戳。查询节点需要等到能看到要求时间点之前的所有操作。
特点:
-
最新写入可见性最强;
-
可能产生等待;
-
查询延迟通常更高。
12.2 Bounded Staleness
有界滞后:允许数据视图在规定时间窗口内落后
特点:
-
默认一致性级别;
-
在可控的数据新鲜度损失下减少等待;
-
适合推荐、检索等允许极少量新数据暂不可见的场景。
12.3 Session
会话一致性:同一客户端会话至少能读到自己已经完成的写入
客户端使用最近一次写入的时间戳作为 GuaranteeTs,从而实现 Read Your Writes。
12.4 Eventually
最终一致性:查询立即使用当前可用的数据视图
特点:
-
一致性约束最弱;
-
查询等待最少;
-
新写入可能暂时不可见;
-
不再写入后,各副本最终收敛。
13 Compaction
Compaction:将多个 Segment 合并或重组为新的 Segment
持续写入和删除后,系统可能出现:
-
许多小 Segment;
-
删除记录;
-
Segment 碎片;
-
查询需要访问过多 Segment;
-
存储空间中存在已被替代的旧 Segment。
Compaction 可以:
-
合并小 Segment;
-
清理满足回收条件的逻辑删除数据;
-
减少查询扇出;
-
重组数据布局;
-
生成新的 Segment。
示例:
Python
Segment A:1000 行
Segment B: 800 行
Segment C: 500 行
逻辑删除: 300 行
↓ Compaction
新 Segment:约 2000 行有效数据Compaction 不是原地修改旧 Segment:
-
Data Node 读取旧 Segment;
-
生成新 Segment;
-
新 Segment 写回对象存储;
-
Coordinator 调度 Query Node 加载新 Segment;
-
旧 Segment 被标记为 Dropped;
-
GC 后续清理旧数据。