附录 I:双量子比特编织变换
这里我们推导编织一个 Z-cut 量子比特孔洞穿过一个 X-cut 量子比特,如图 21、22 和 23(正文)所示。我们想证明这两种量子比特类型之间的编织等价于逻辑 CNOT,Z-cut 量子比特作为控制,X-cut 量子比特作为目标。当编织一个 X-cut 量子比特穿过一个 Z-cut 时,同样的结果成立,X-cut 量子比特仍然是 CNOT 的目标,Z-cut 作为控制,但编织两个 Z-cut 量子比特或两个 X-cut 量子比特需要其他逻辑电路,如第 XIV D 节所讨论。
如我们在正文中讨论的,结果我们只需要证明编织正确变换十六种可能的两量子比特算符组合中的四种,就能证明编织是 CNOT:X^L⊗I^L\hat{X}_L \otimes \hat{I}_LX^L⊗I^L、I^L⊗X^L\hat{I}_L \otimes \hat{X}_LI^L⊗X^L、Z^L⊗I^L\hat{Z}_L \otimes \hat{I}_LZ^L⊗I^L 和 I^L⊗Z^L\hat{I}_L \otimes \hat{Z}_LI^L⊗Z^L。我们依次考虑每一种,此外还推导 X^L⊗X^L\hat{X}_L \otimes \hat{X}_LX^L⊗X^L 的变换,提供两个顺序编织如何等价于恒等操作的示例。
X^L⊗I^L→X^L⊗X^L\hat{X}_L \otimes \hat{I}_L \to \hat{X}_L \otimes \hat{X}_LX^L⊗I^L→X^L⊗X^L: 我们首先考虑编织对两量子比特算符 X^L⊗I^L=X^L1I^L2\hat{X}L \otimes \hat{I}L = \hat{X}{L1}\hat{I}{L2}X^L⊗I^L=X^L1I^L2 的影响,如图 21 所示。X^L1\hat{X}{L1}X^L1 比特翻转针对第一个 Z-cut 量子比特,I^L2\hat{I}{L2}I^L2 针对第二个 X-cut 量子比特(下标 1 和 2 指示算符作用于哪个逻辑量子比特)。对于编织的第一次移动,我们有
X^L1I^L2→(X^1...X^8X^L1)I^L2=X^L1′I^L2.(I1)\hat{X}{L1}\hat{I}{L2} \to (\hat{X}1\ldots\hat{X}8\hat{X}{L1})\hat{I}{L2} = \hat{X}{L1}'\hat{I}{L2}. \tag{I1}X^L1I^L2→(X^1...X^8X^L1)I^L2=X^L1′I^L2.(I1)
注意我们混合了逻辑和物理量子比特算符,但由于逻辑算符由物理量子比特算符的乘积构造,这在形式上是可接受的。
在第二次移动中,我们有
X^L1′I^L2→(X^9...X^12X^L1′)I^L2=X^L1′′I^L2.(I2)\hat{X}{L1}'\hat{I}{L2} \to (\hat{X}9\ldots\hat{X}{12}\hat{X}{L1}')\hat{I}{L2} = \hat{X}{L1}''\hat{I}{L2}. \tag{I2}X^L1′I^L2→(X^9...X^12X^L1′)I^L2=X^L1′′I^L2.(I2)
如图 21e 所示,两次移动中 X^L1\hat{X}{L1}X^L1 的组合产生了一个算符 X^L1′′\hat{X}{L1}''X^L1′′,它包括原始 X^L1\hat{X}_{L1}X^L1 链以及一个闭合的数据量子比特算符环,该环包围 X-cut 量子比特 2 的上方孔洞,以及若干完全稳定的格。我们可以将其重写为
X^L1′′I^L2=X^loopX^L1′′′I^L2=(X^s1...X^s4X^L2X^s6...X^s9)X^L1′′′→X^L1′′′X^L2.(I3)\hat{X}{L1}''\hat{I}{L2} = \hat{X}{loop}\hat{X}{L1}'''\hat{I}{L2} = (\hat{X}{s1}\ldots\hat{X}{s4}\hat{X}{L2}\hat{X}{s6}\ldots\hat{X}{s9})\hat{X}{L1}''' \to \hat{X}{L1}'''\hat{X}_{L2}. \tag{I3}X^L1′′I^L2=X^loopX^L1′′′I^L2=(X^s1...X^s4X^L2X^s6...X^s9)X^L1′′′→X^L1′′′X^L2.(I3)
为了获得这个结果,我们将来自变换后的 X^L1′\hat{X}{L1}'X^L1′ 的闭合环 X^loop\hat{X}{loop}X^loop 变形穿过每个被包围的 X^\hat{X}X^ 稳定子 X^sj\hat{X}{sj}X^sj,包括一个紧密包裹在 X-cut 量子比特 2 上方孔洞周围的物理 X^\hat{X}X^ 比特翻转环,这正是 X^L2\hat{X}{L2}X^L2 比特翻转。X^\hat{X}X^ 稳定子分解为测量本征值 ±1\pm 1±1,留下逻辑算符的外积 X^L2X^L1′′′=X^L1′′′X^L2\hat{X}{L2}\hat{X}{L1}''' = \hat{X}{L1}'''\hat{X}{L2}X^L2X^L1′′′=X^L1′′′X^L2,如式 (I3) 的最后一行。
根据稳定子结果可能发生许多符号变化。我们再次使用幂次 pXp_XpX 和 pZp_ZpZ 来捕获这些符号变化。第一个逻辑量子比特的编织产生符号变化 (−1)pX1≡(X1e...X8e)(X9e...X12e)=±1(-1)^{p_{X1}} \equiv (X_1^e \ldots X_8^e)(X_9^e \ldots X_{12}^e) = \pm 1(−1)pX1≡(X1e...X8e)(X9e...X12e)=±1,等于两次移动中稳定单数据量子比特测量的乘积。这与空环编织的符号变化相同。
编织还在第二个量子比特上产生符号变化,因为在编织中我们将该量子比特上的恒等算符变换为 X^L2\hat{X}{L2}X^L2 逻辑算符。符号变化与第一个量子比特非常相似,其中我们定义幂次 pX2p{X2}pX2,由 (−1)pX2≡Xs1f...Xs4fXs6f...Xs9f=±1(-1)^{p_{X2}} \equiv X_{s1}^f \ldots X_{s4}^f X_{s6}^f \ldots X_{s9}^f = \pm 1(−1)pX2≡Xs1f...Xs4fXs6f...Xs9f=±1 给出,即将环绕第二个量子比特上方孔洞的环 X^loop\hat{X}{loop}X^loop 变形为作为 X^L2\hat{X}{L2}X^L2 算符的环所涉及的 X^\hat{X}X^ 稳定子的乘积。
为了考虑两个逻辑量子比特的符号变化,我们用两个副产品算符 Z^L1pX1\hat{Z}{L1}^{p{X1}}Z^L1pX1 和 Z^L2pX2\hat{Z}{L2}^{p{X2}}Z^L2pX2 修改后编织波函数 ∣ψ′′⟩|\psi''\rangle∣ψ′′⟩,使得我们最终得到
Z^L1pX1Z^L2pX2∣ψ′′⟩.(I4)\hat{Z}{L1}^{p{X1}} \hat{Z}{L2}^{p{X2}} |\psi''\rangle. \tag{I4}Z^L1pX1Z^L2pX2∣ψ′′⟩.(I4)
这还不是完整的故事,因为我们还需要确定与 Z^L1\hat{Z}{L1}Z^L1 和 Z^L2\hat{Z}{L2}Z^L2 算符的任何编织诱导符号变化相关的副产品算符;见式 (I8) 的完整表达式。
忽略任何副产品算符,编织因此产生变换
X^L⊗I^L→X^L⊗X^L.(I5)\hat{X}_L \otimes \hat{I}_L \to \hat{X}_L \otimes \hat{X}_L. \tag{I5}X^L⊗I^L→X^L⊗X^L.(I5)
X^L⊗X^L→X^L⊗I^L\hat{X}_L \otimes \hat{X}_L \to \hat{X}_L \otimes \hat{I}_LX^L⊗X^L→X^L⊗I^L: 这里我们将编织变换应用于两个逻辑量子比特上两个 X^L\hat{X}_LX^L 算符的外积。因此这是对我们刚刚讨论的编织结果的编织变换,X^L⊗I^L→X^L⊗X^L\hat{X}_L \otimes \hat{I}_L \to \hat{X}_L \otimes \hat{X}_LX^L⊗I^L→X^L⊗X^L。编织不是可逆过程,因为移动期间涉及投影测量,但正如我们将看到的,X^L⊗X^L\hat{X}_L \otimes \hat{X}_LX^L⊗X^L 的编织变换反转了 X^L⊗I^L\hat{X}_L \otimes \hat{I}_LX^L⊗I^L 的编织变换。简单的论证如下:当我们从 X^L⊗X^L\hat{X}_L \otimes \hat{X}_LX^L⊗X^L 开始时,编织过程将 Z-cut 量子比特 1 的 X^L\hat{X}_LX^L 链包裹在代表 X-cut 量子比特 2 的 X^L\hat{X}_LX^L 环周围,就像 X^L⊗I^L\hat{X}_L \otimes \hat{I}_LX^L⊗I^L 一样。我们可以再次将 Z-cut 量子比特 1 变换后的 X^L\hat{X}_LX^L 中的环变形穿过被包围的 X^\hat{X}X^ 稳定子,使其紧密包裹在 X-cut 量子比特 2 周围,给我们 X-cut 量子比特 2 上两个 X^L\hat{X}_LX^L 比特翻转的等价;然而这些相互抵消(X^L2=I^L\hat{X}_L^2 = \hat{I}_LX^L2=I^L),在量子比特 2 上留下 I^L\hat{I}_LI^L 作为结果操作。注意在此过程中,除了波函数上的副产品操作外,Z-cut 量子比特 1 的 X^L\hat{X}_LX^L 算符没有净修改。因此我们发现 X^L⊗X^L→X^L⊗I^L\hat{X}_L \otimes \hat{X}_L \to \hat{X}_L \otimes \hat{I}_LX^L⊗X^L→X^L⊗I^L 在编织变换下。
我们写出详细过程。对于第一次移动,与 X^L1⊗I^L2\hat{X}{L1} \otimes \hat{I}{L2}X^L1⊗I^L2 一样,我们有
X^L1X^L2→(X^1...X^8X^L1)X^L2=X^L1′X^L2.(I6)\hat{X}{L1}\hat{X}{L2} \to (\hat{X}1\ldots\hat{X}8\hat{X}{L1})\hat{X}{L2} = \hat{X}{L1}'\hat{X}{L2}. \tag{I6}X^L1X^L2→(X^1...X^8X^L1)X^L2=X^L1′X^L2.(I6)
在第二次移动中,我们有
X^L1′X^L2→(X^9...X^12X^L1′)X^L2→(X^s1...X^s4X^L2X^s6...X^s9)X^L1′′X^L2→X^L1′′X^L2′′X^L2→X^L1′′I^L2,(I7)\hat{X}{L1}'\hat{X}{L2} \to (\hat{X}9\ldots\hat{X}{12}\hat{X}{L1}')\hat{X}{L2} \to (\hat{X}{s1}\ldots\hat{X}{s4}\hat{X}{L2}\hat{X}{s6}\ldots\hat{X}{s9})\hat{X}{L1}''\hat{X}{L2} \to \hat{X}{L1}''\hat{X}{L2}''\hat{X}{L2} \to \hat{X}{L1}''\hat{I}{L2}, \tag{I7}X^L1′X^L2→(X^9...X^12X^L1′)X^L2→(X^s1...X^s4X^L2X^s6...X^s9)X^L1′′X^L2→X^L1′′X^L2′′X^L2→X^L1′′I^L2,(I7)
其中我们在 X^L2′′\hat{X}{L2}''X^L2′′ 上使用双撇号来区分量子比特 2 上的第二个 X^L2\hat{X}{L2}X^L2 逻辑算符与原始 X^L2\hat{X}{L2}X^L2。然而这些 X^L2\hat{X}{L2}X^L2 算符的乘积是恒等,如该方程的最后一行。
一般来说,执行相同的编织操作两次等价于恒等,除了副产品算符的出现。
I^L⊗X^L→I^L⊗X^L\hat{I}_L \otimes \hat{X}_L \to \hat{I}_L \otimes \hat{X}_LI^L⊗X^L→I^L⊗X^L: 现在考虑涉及 Z-cut 量子比特 1 上的 I^L1\hat{I}{L1}I^L1 和 X-cut 量子比特 2 上的 X^L2\hat{X}{L2}X^L2 的编织;这在图 22a 到 d 中展示。X^L2\hat{X}{L2}X^L2 算符是围绕 X-cut 量子比特上方孔洞的数据量子比特 X^\hat{X}X^ 比特翻转环。编织对恒等 I^L1\hat{I}{L1}I^L1 没有影响,因为恒等不涉及任何操作,因此拖动上方量子比特孔洞围绕闭合环不会从移动量子比特留下可以与 X-cut 量子比特 2 相互作用的算符轨迹,反之亦然。因此编织使这两个算符不变,如图 22d 所示,I^L⊗X^L→I^L⊗X^L\hat{I}_L \otimes \hat{X}_L \to \hat{I}_L \otimes \hat{X}_LI^L⊗X^L→I^L⊗X^L(除了此处未显示的副产品算符)。
I^L⊗Z^L→Z^L⊗Z^L\hat{I}_L \otimes \hat{Z}_L \to \hat{Z}_L \otimes \hat{Z}_LI^L⊗Z^L→Z^L⊗Z^L: 现在考虑涉及 Z-cut 量子比特 1 上的 I^L1\hat{I}{L1}I^L1 和 X-cut 量子比特 2 上的 Z^L2\hat{Z}{L2}Z^L2 的编织;这在图 23a 中展示。这与 X^L⊗I^L\hat{X}L \otimes \hat{I}LX^L⊗I^L 完全类似,只是 Z-cut 和 X-cut 量子比特的角色互换。我们变形 X-cut 量子比特 2 的 Z^L2\hat{Z}{L2}Z^L2 算符,使其具有图 23b 所示的形式。然后量子比特 1 的孔洞穿过 Z^L2\hat{Z}{L2}Z^L2 扩展后留下的路径,直到它返回原始位置,如图 23c 所示。然后我们可以将 Z^L2\hat{Z}{L2}Z^L2 算符乘以图 23d 中虚线框所示的所有稳定子 Z^s1,Z^s2...Z^s7\hat{Z}{s1}, \hat{Z}{s2} \ldots \hat{Z}{s7}Z^s1,Z^s2...Z^s7,其稳定测量结果都是已知的,使用恒等式 Z^L2=Z^L1Z^s1...Z^s7Z^L2′\hat{Z}{L2} = \hat{Z}{L1}\hat{Z}{s1}\ldots\hat{Z}{s7}\hat{Z}{L2}'Z^L2=Z^L1Z^s1...Z^s7Z^L2′,其中 Z^L1\hat{Z}{L1}Z^L1 是围绕下方量子比特 1 孔洞的数据量子比特 Z^\hat{Z}Z^ 算符环,因此对应于该量子比特上的 Z^L\hat{Z}LZ^L,而 Z^L2′\hat{Z}{L2}'Z^L2′ 是原始 Z^L2\hat{Z}{L2}Z^L2 链,如图 23d 所示。因此我们已经在 Z-cut 量子比特 1 上生成了 Z^L1\hat{Z}{L1}Z^L1 相位翻转操作。除了可能的副产品算符外,量子比特 2 上的 Z^L2\hat{Z}_{L2}Z^L2 操作不被编织修改。因此我们看到 I^L⊗Z^L\hat{I}_L \otimes \hat{Z}_LI^L⊗Z^L 变换为 Z^L⊗Z^L\hat{Z}_L \otimes \hat{Z}_LZ^L⊗Z^L。
第二次执行此编织,即现在从 Z^L⊗Z^L\hat{Z}_L \otimes \hat{Z}LZ^L⊗Z^L 开始,将在 Z-cut 量子比特 1 上生成第二个 Z^L1\hat{Z}{L1}Z^L1 操作,因此这将变换回原始算符对,即 (Z^L⋅Z^L)⊗Z^L=I^L⊗Z^L(\hat{Z}_L \cdot \hat{Z}_L) \otimes \hat{Z}_L = \hat{I}_L \otimes \hat{Z}_L(Z^L⋅Z^L)⊗Z^L=I^L⊗Z^L,方式与 X^L⊗X^L→X^L⊗I^L\hat{X}_L \otimes \hat{X}_L \to \hat{X}_L \otimes \hat{I}_LX^L⊗X^L→X^L⊗I^L 完全类似。
Z^L⊗I^L→Z^L⊗I^L\hat{Z}_L \otimes \hat{I}_L \to \hat{Z}_L \otimes \hat{I}_LZ^L⊗I^L→Z^L⊗I^L: 最后,考虑涉及 Z-cut 量子比特 1 上的 Z^L1\hat{Z}{L1}Z^L1 操作和 X-cut 量子比特 2 上的 I^L2\hat{I}{L2}I^L2 的编织变换。这种情况与 I^L⊗X^L\hat{I}_L \otimes \hat{X}LI^L⊗X^L 完全类似:Z^L1\hat{Z}{L1}Z^L1 是围绕 Z-cut 孔洞的数据量子比特 Z^\hat{Z}Z^ 相位翻转环,在编织期间波函数获得副产品算符。然而环不以与 X-cut 量子比特 2 相互作用的方式包围它,因此编织对 X-cut 量子比特 2 不执行任何操作。因此我们看到,除了副产品算符外,Z^L⊗I^L\hat{Z}_L \otimes \hat{I}_LZ^L⊗I^L 变换为 Z^L⊗I^L\hat{Z}_L \otimes \hat{I}_LZ^L⊗I^L。
双量子比特变换的副产品算符
在讨论 X^L⊗I^L→X^L⊗X^L\hat{X}L \otimes \hat{I}L \to \hat{X}L \otimes \hat{X}LX^L⊗I^L→X^L⊗X^L 变换时,我们给出了幂次 pX1p{X1}pX1 和 pX2p{X2}pX2 的表达式,它们确定与最终 X^L1X^L2\hat{X}{L1}\hat{X}{L2}X^L1X^L2 算符相关的符号变化是否必须用相位翻转 Z^L1\hat{Z}{L1}Z^L1 和 Z^L2\hat{Z}{L2}Z^L2 来修正。产生 Z^L1\hat{Z}{L1}Z^L1 或 Z^L2\hat{Z}{L2}Z^L2 算符的编织变换同样必须修正这些算符中的任何不希望的符号变化,如通常由编织变换中涉及的各种稳定子和单数据量子比特测量结果决定:如果由于 Z^L1\hat{Z}{L1}Z^L1 算符的编织变换存在(不存在)符号变化,则幂次 pZ1=1(0)p{Z1} = 1(0)pZ1=1(0),而如果由于 Z^L2\hat{Z}{L2}Z^L2 算符的变换存在(不存在)符号变化,则幂次 pZ2=1(0)p{Z2} = 1(0)pZ2=1(0)。在任一情况下,变换后的状态波函数由副产品算符 X^L1pZ1\hat{X}{L1}^{p{Z1}}X^L1pZ1 和 X^L2pZ2\hat{X}{L2}^{p{Z2}}X^L2pZ2 修改以指示这些符号变化。
结合副产品算符 Z^L1\hat{Z}{L1}Z^L1 和 Z^L2\hat{Z}{L2}Z^L2,编织后的最终波函数 ∣ψ′′⟩|\psi''\rangle∣ψ′′⟩ 由下式给出
(Z^L1)pX1(X^L1)pZ1(Z^L2)pX2(X^L2)pZ2∣ψ′′⟩.(I8)(\hat{Z}{L1})^{p{X1}} (\hat{X}{L1})^{p{Z1}} (\hat{Z}{L2})^{p{X2}} (\hat{X}{L2})^{p{Z2}} |\psi''\rangle. \tag{I8}(Z^L1)pX1(X^L1)pZ1(Z^L2)pX2(X^L2)pZ2∣ψ′′⟩.(I8)
附录 J:逻辑 Hadamard 过程
对单个逻辑量子比特执行逻辑 Hadamard 的过程在图 26、27 和 28 中详细说明。详细序列如下:
-
我们关闭围绕要 Hadamard 变换的逻辑量子比特的两个 Z-cut 孔洞的一圈 X^\hat{X}X^ 稳定子,还将环两侧上的 Z^\hat{Z}Z^ 稳定子从四端减少到三端和两端测量,有效地将目标量子比特隔离在二维阵列的一个独立块中。间隙中未稳定的数据量子比特沿 Z^\hat{Z}Z^ 测量,维持表面码错误跟踪。这在图 27a 中展示。通过将此图与图 26 比较,很明显环边界非常接近环外的逻辑量子比特,似乎这些逻辑量子比特的接近性将阵列距离 ddd 减小到一个小值;然而,护城河内部 Z 边界不允许短不可检测错误链到达环外 Z-cut 逻辑量子比特的内部 X 边界,因此实际上距离 d=7d=7d=7 被保持。如果环外的任何量子比特是 X-cut 量子比特,然而,这些必须距离环 ddd。这同样适用于环内的 Z-cut 量子比特;它也受到环内部 Z 边界的保护。
-
我们通过将其乘以图 27b 中勾勒的所有 Z^sL\hat{Z}_{sL}Z^sL 稳定子来变形 Z^L\hat{Z}_LZ^L 环;这给我们留下从隔离二维块的左边界到右边界的 Z^L\hat{Z}_LZ^L 算符链,如图 27b 中的水平实线所示。
-
我们关闭或减少环内所有 X^\hat{X}X^ 和 Z^\hat{Z}Z^ 稳定子的端数,创建一条"护城河",使护城河吞没两个量子比特孔洞,留下图 27c 中虚线框内的那些;这给我们留下图 27d 所示的较小二维块,消除了两个量子比特孔洞,Z^L\hat{Z}_LZ^L 仍然从左到右穿过,X^L\hat{X}_LX^L 现在从上到下穿过。注意这个二维块现在只是我们先前讨论过的 d=5d=5d=5 阵列量子比特(图 3)的更大(d=7d=7d=7)版本;顶部和底部的两个 X 边界,以及左侧和右侧的 Z 边界,使这成为一个具有两个自由度的逻辑量子比特。护城河两个内部 X 边界之外的数据量子比特在 X^\hat{X}X^ 中测量,以与护城河内部边界上仍然活跃的三端 X^\hat{X}X^ 稳定子保持错误跟踪。
-
我们执行此过程的关键,对块中的所有数据量子比特执行物理 Hadamard。由于这改变了从 Z^\hat{Z}Z^ 到 X^\hat{X}X^ 的本征基反之亦然,我们改变了测量量子比特的身份,从 X^\hat{X}X^ 稳定化变为 Z^\hat{Z}Z^ 稳定化反之亦然,如图 27e 所示。此外,X^L\hat{X}_LX^L 和 Z^L\hat{Z}_LZ^L 逻辑算符交换了它们的身份。这一步以及接下来的两步在表面码的两个周期之间完成(因此 measure-X 和 measure-Z 量子比特在孤立块上不执行任何稳定化)。
-
块中的 X^\hat{X}X^ 和 Z^\hat{Z}Z^ 稳定子现在与更大二维阵列中的错位。为了纠正这一点,我们执行数据量子比特-测量量子比特交换,在每个块数据量子比特与其正上方的测量量子比特之间。
-
我们执行第二次交换,在每个测量量子比特与其左侧的块数据量子比特之间,如图 27f 所示。数据量子比特现在持有块的 Hadamard 变换后的逻辑状态。表面码周期重新启动,测量量子比特继续像物理 Hadamard 之前一样测量 X 和 Z,与更大的二维阵列对齐;两次交换确保二维块中的 Hadamard 变换状态与此稳定化一致。
-
隔离二维块与二维阵列的大多数 X^\hat{X}X^ 和 Z^\hat{Z}Z^ 稳定子被重新打开,将护城河的宽度减小到仅一个数据量子比特宽的环,将块与二维阵列分离,如图 27a 所示。这以在块中创建两个逻辑量子比特孔洞的方式完成,如图 28g 所示,两个量子比特孔洞定位使得 X^L\hat{X}_LX^L 算符链终止于两个量子比特孔洞的内部边界,Z^L\hat{Z}_LZ^L 链乘以一组稳定子使其返回到围绕一个量子比特孔洞的环。
-
Z^L\hat{Z}_LZ^L 链被变形使其紧密包裹在右侧量子比特 Z-cut 孔洞周围,如图 28g 所示。这是通过乘以所有勾勒的 Z^\hat{Z}Z^ 稳定子来完成的。
-
左右量子比特孔洞以通常的方式在块周围移动,如图 28h 中移动变换进行中的部分,以及图 28i 中开放格被重新稳定、关闭移动切口后。孔洞移动必须分成两步以避免减小逻辑量子比特的距离 ddd。我们等待 ddd 个表面码周期以在时间上建立所有稳定子值。
-
两个 Z-cut 孔洞中的每一个被移动一格以返回各自的原始起点,如图 28j 所示。
-
隔离块与二维阵列的稳定子全部被重新打开,将块与阵列重新统一并完成 Hadamard 变换,等待 ddd 个表面码周期以在时间上建立稳定子值。
附录 K:短量子比特
这里我们概述如何创建和注入状态到短 X-cut 量子比特(短 Z-cut 量子比特的过程完全类似,简单地交换 X 和 Z 的角色)。图 31 在正文中。
- 我们从二维阵列的完全稳定部分开始,如图 31(a)。
- 我们关闭两个 X^\hat{X}X^ 稳定子 X^1X^2X^3X^5\hat{X}_1\hat{X}_2\hat{X}_3\hat{X}_5X^1X^2X^3X^5 和 X^5X^7X^8X^9\hat{X}_5\hat{X}_7\hat{X}_8\hat{X}_9X^5X^7X^8X^9,创建一对 X-cut 孔洞。这些孔洞仅被一个数据量子比特------量子比特 5------分隔;这就是"短量子比特"。
在同一表面码周期中,我们测量两个 Z^\hat{Z}Z^ 稳定子 Z^s1=Z^2Z^4Z^5Z^7\hat{Z}_{s1} = \hat{Z}_2\hat{Z}_4\hat{Z}_5\hat{Z}7Z^s1=Z^2Z^4Z^5Z^7 和 Z^s2=Z^3Z^5Z^6Z^7\hat{Z}{s2} = \hat{Z}_3\hat{Z}5\hat{Z}6\hat{Z}7Z^s2=Z^3Z^5Z^6Z^7,同时测量数据量子比特 5 沿 X^\hat{X}X^,得到本征值 X5X_5X5。注意 X^5\hat{X}5X^5 与两个 Z^\hat{Z}Z^ 稳定子 Z^s1\hat{Z}{s1}Z^s1 和 Z^s2\hat{Z}{s2}Z^s2 反对易,因此这三个测量不能导致所有三个稳定子的同时本征态。然而,由乘积 Z^s1Z^s2=Z^2Z^3Z^4Z^6Z^7Z^8\hat{Z}{s1}\hat{Z}{s2} = \hat{Z}2\hat{Z}3\hat{Z}4\hat{Z}6\hat{Z}7\hat{Z}8Z^s1Z^s2=Z^2Z^3Z^4Z^6Z^7Z^8 形成的算符与 Z^s1\hat{Z}{s1}Z^s1、Z^s2\hat{Z}{s2}Z^s2 和 X^5\hat{X}5X^5 对易,因此同时测量将选择是 Z^s1Z^s2\hat{Z}{s1}\hat{Z}{s2}Z^s1Z^s2 和 X^5\hat{X}5X^5 本征态的状态。测量结果 Zs1Zs2Z{s1}Z{s2}Zs1Zs2 将等于前一周表面码周期中 Zs1Z{s1}Zs1 和 Zs2Z{s2}Zs2 的乘积,X5=±1X_5 = \pm 1X5=±1。
-
我们现在创建了一个可以操纵的短量子比特。我们通过应用适当的绕 Z 轴旋转,使用 R^Z(θ)\hat{R}_Z(\theta)R^Z(θ)(见式 (52))将量子比特制备到期望的最终状态 ∣gL⟩+eiθ∣eL⟩|g_L\rangle + e^{i\theta}|e_L\rangle∣gL⟩+eiθ∣eL⟩;具体旋转将取决于逻辑量子比特是初始化在 ∣+L⟩|+_L\rangle∣+L⟩(X5=+1X_5 = +1X5=+1)还是 ∣−L⟩|-_L\rangle∣−L⟩(X5=−1X_5 = -1X5=−1)。如果我们有兴趣注入 ∣YL⟩|Y_L\rangle∣YL⟩ 状态,角度 θ=π/2\theta = \pi/2θ=π/2,而对于 ∣AL⟩|A_L\rangle∣AL⟩ 状态我们将使用 θ=π/4\theta = \pi/4θ=π/4。
-
表面码稳定化序列现在重新启动,两个 X^\hat{X}X^ 稳定子保持空闲。量子比特的两个孔洞现在可以被分离并扩大以更好地防止错误。量子比特中的状态现在可以在蒸馏过程中被纯化,然后用于 S^L\hat{S}_LS^L 或 T^L\hat{T}_LT^L 门。
附录 L:S^L\hat{S}_LS^L 和 T^L\hat{T}_LT^L 蒸馏子电路
在本附录中,我们明确查看 ∣YL⟩|Y_L\rangle∣YL⟩ 和 ∣AL⟩|A_L\rangle∣AL⟩ 蒸馏电路中使用的一些操作,重点关注终端 S^L\hat{S}_LS^L 和 T^L†\hat{T}_L^\daggerT^L† 门,随后是测量 MXM_XMX,即图 32 和图 33 中每个辅助量子比特蒸馏的最后两步。图 29 所示的 S^L\hat{S}_LS^L 门是确定性的,但为了与 ∣AL⟩|A_L\rangle∣AL⟩ 蒸馏的分析提供并行讨论,我们改用图 30 中的电路,将该电路中的 ∣AL⟩|A_L\rangle∣AL⟩ 辅助状态替换为 ∣YL⟩|Y_L\rangle∣YL⟩。使用 ∣YL⟩|Y_L\rangle∣YL⟩,此电路将执行 S^L\hat{S}_LS^L,尽管只有大约一半时间,因为使用这个非确定性电路,另一半时间需要修正输出状态,正如 T^L\hat{T}_LT^L 门一样。
图 35 显示了相应的子电路,以及包含条件测量的等价电路。由于本附录中的所有状态和操作都是逻辑的,为简洁起见我们将去掉下标 LLL。
我们首先考虑图 35a,它实现 S^\hat{S}S^ 门。对于进入 MX′M_X'MX′ 测量的状态,CNOT 后接 MZ′M_Z'MZ′ 测量给出 ∣ψ′⟩=S^∣ψ⟩|\psi'\rangle = \hat{S}|\psi\rangle∣ψ′⟩=S^∣ψ⟩(当 MZ′=+1M_Z' = +1MZ′=+1),以及 ∣ψ′⟩=X^Z^S^∣ψ⟩|\psi'\rangle = \hat{X}\hat{Z}\hat{S}|\psi\rangle∣ψ′⟩=X^Z^S^∣ψ⟩(当 MZ′=−1M_Z' = -1MZ′=−1)。随后 MX′M_X'MX′ 测量的结果则为
MX′=MXS\^∣ψ⟩(当 MZ′=+1),M_X' = M_X\\hat{S}\|\\psi\\rangle \quad (\text{当 } M_Z' = +1),MX′=MXS\^∣ψ⟩(当 MZ′=+1),
和
MX′=MXX\^Z\^S\^∣ψ⟩(当 MZ′=−1)=MXZ\^S\^∣ψ⟩=−MXS\^∣ψ⟩M_X' = M_X\\hat{X}\\hat{Z}\\hat{S}\|\\psi\\rangle \quad (\text{当 } M_Z' = -1) = M_X\\hat{Z}\\hat{S}\|\\psi\\rangle = -M_X\\hat{S}\|\\psi\\rangleMX′=MXX\^Z\^S\^∣ψ⟩(当 MZ′=−1)=MXZ\^S\^∣ψ⟩=−MXS\^∣ψ⟩
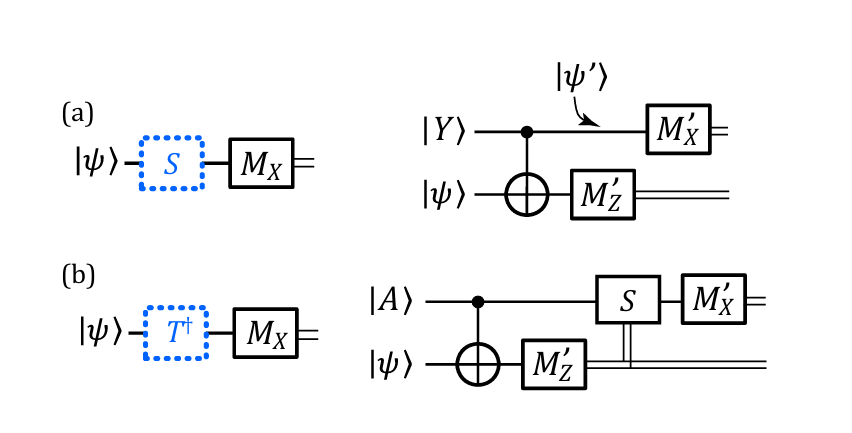
图35.(彩色在线版)(a) 左面板显示 ∣Y^⟩|\hat{Y}\rangle∣Y^⟩ 蒸馏电路的原始部分,涉及 S^\hat{S}S^ 门后接测量 MXM_XMX,而右面板显示扩展的 S^\hat{S}S^ 电路,展示逻辑 CNOT 和测量 MZ′M_Z'MZ′ 和 MX′M_X'MX′。(b) 与 (a) 相同,但针对 ∣A⟩|A\rangle∣A⟩ 蒸馏电路的一部分,涉及 T^†\hat{T}^\daggerT^† 门。如果 MZ′=+1M_Z' = +1MZ′=+1,则对上量子比特应用一个条件 S^\hat{S}S^ 门。
使用 MXX\^∣ψ⟩=MX∣ψ⟩M_X\\hat{X}\|\\psi\\rangle = M_X\|\\psi\\rangleMXX\^∣ψ⟩=MX∣ψ⟩ 和 MXZ\^∣ψ⟩=−MX∣ψ⟩M_X\\hat{Z}\|\\psi\\rangle = -M_X\|\\psi\\rangleMXZ\^∣ψ⟩=−MX∣ψ⟩。
因此当电路未能生成 S^\hat{S}S^ 而生成 X^Z^S^\hat{X}\hat{Z}\hat{S}X^Z^S^ 时,最终测量获得负号。此结果总结在表 VI 的 ∣Y⟩|Y\rangle∣Y⟩ 列中。从这些方程中,很容易看出期望的 MXM_XMX 测量的净结果等于两个子测量的乘积
MXS\^∣ψ⟩=MX′MZ′.(L2)M_X\\hat{S}\|\\psi\\rangle = M_X' M_Z'. \tag{L2}MXS\^∣ψ⟩=MX′MZ′.(L2)
由于蒸馏的目标是减少 ∣Y⟩|Y\rangle∣Y⟩ 中的错误,我们接下来考虑错误对输入 ∣Y⟩|Y\rangle∣Y⟩ 辅助状态的影响,以及这些如何影响输出测量。这些错误可以被建模为对 ∣Y⟩|Y\rangle∣Y⟩ 状态的 X^\hat{X}X^、Y^\hat{Y}Y^ 或 Z^\hat{Z}Z^ 的概率性应用,给出 Z^∣Y⟩=∣Y∗⟩=∣g⟩−i∣e⟩\hat{Z}|Y\rangle = |Y^*\rangle = |g\rangle - i|e\rangleZ^∣Y⟩=∣Y∗⟩=∣g⟩−i∣e⟩,X^∣Y⟩=i∣Y∗⟩\hat{X}|Y\rangle = i|Y^*\rangleX^∣Y⟩=i∣Y∗⟩ 和 Y^∣Y⟩=−i∣Y⟩\hat{Y}|Y\rangle = -i|Y\rangleY^∣Y⟩=−i∣Y⟩,其中 ±i\pm i±i 代表可以去掉的整体相位因子。对于一般输入状态 ∣g⟩+exp(iθ)∣e⟩|g\rangle + \exp(i\theta)|e\rangle∣g⟩+exp(iθ)∣e⟩,∣Y⟩|Y\rangle∣Y⟩(∣Y∗⟩|Y^*\rangle∣Y∗⟩)状态对应于 θ=π/2\theta = \pi/2θ=π/2(θ=−π/2\theta = -\pi/2θ=−π/2)。当我们有错误的输入 ∣Y∗⟩|Y^*\rangle∣Y∗⟩ 状态,即 θ=−π/2\theta = -\pi/2θ=−π/2 时,MZ′=+1M_Z' = +1MZ′=+1 的测量结果将状态 S^†∣ψ⟩=Z^S^∣ψ⟩\hat{S}^\dagger|\psi\rangle = \hat{Z}\hat{S}|\psi\rangleS^†∣ψ⟩=Z^S^∣ψ⟩ 送入测量 MX′M_X'MX′,而 MZ′=−1M_Z' = -1MZ′=−1 将状态 X^S^∣ψ⟩\hat{X}\hat{S}|\psi\rangleX^S^∣ψ⟩ 送入测量。表 VI 列出了两种 MZ′M_Z'MZ′ 结果和所有错误类型的 MX′M_X'MX′ 测量结果,并显示对于 Z^\hat{Z}Z^ 和 X^\hat{X}X^ 错误,测量结果 MXM_XMX 的符号反转,标志着蒸馏过程中的错误。虽然 Y^\hat{Y}Y^ 错误不可检测(整体相位因子无法测量),但蒸馏不受影响,因为此错误对输入状态没有显著变化 Y^∣Y⟩=−i∣Y⟩\hat{Y}|Y\rangle = -i|Y\rangleY^∣Y⟩=−i∣Y⟩。因此所有错误都由 X^\hat{X}X^ 或 Z^\hat{Z}Z^ 操作描述,并被电路成功且直接地检测。
对于图 35b 中的 T^†\hat{T}^\daggerT^† 电路,测量结果 MZ′=+1M_Z' = +1MZ′=+1 表明电路产生了 T^∣ψ⟩\hat{T}|\psi\rangleT^∣ψ⟩,这通过应用 S^\hat{S}S^ 来修正,使用恒等式 S^T^=Z^T^†\hat{S}\hat{T} = \hat{Z}\hat{T}^\daggerS^T^=Z^T^†,期望的结果伴随副产品 Z^L\hat{Z}_LZ^L 算符。对于 MZ′=−1M_Z' = -1MZ′=−1,电路产生 X^T^†∣ψ⟩\hat{X}\hat{T}^\dagger|\psi\rangleX^T^†∣ψ⟩。MX′M_X'MX′ 测量的结果因此为
MX′=MXS\^T\^∣ψ⟩(当 MZ′=+1)=MXZ\^T\^†∣ψ⟩=−MXT\^†∣ψ⟩,M_X' = M_X\\hat{S}\\hat{T}\|\\psi\\rangle \quad (\text{当 } M_Z' = +1) = M_X\\hat{Z}\\hat{T}\^\\dagger\|\\psi\\rangle = -M_X\\hat{T}\^\\dagger\|\\psi\\rangle,MX′=MXS\^T\^∣ψ⟩(当 MZ′=+1)=MXZ\^T\^†∣ψ⟩=−MXT\^†∣ψ⟩,
和
MX′=MXX\^T\^†∣ψ⟩(当 MZ′=−1)=MXT\^†∣ψ⟩.(L3)M_X' = M_X\\hat{X}\\hat{T}\^\\dagger\|\\psi\\rangle \quad (\text{当 } M_Z' = -1) = M_X\\hat{T}\^\\dagger\|\\psi\\rangle. \tag{L3}MX′=MXX\^T\^†∣ψ⟩(当 MZ′=−1)=MXT\^†∣ψ⟩.(L3)
因此我们发现对于 T^†\hat{T}^\daggerT^† 电路
MXT\^†∣ψ⟩=−MX′MZ′.(L4)M_X\\hat{T}\^\\dagger\|\\psi\\rangle = -M_X' M_Z'. \tag{L4}MXT\^†∣ψ⟩=−MX′MZ′.(L4)
对于一般辅助状态 ∣g⟩+eiθ∣e⟩|g\rangle + e^{i\theta}|e\rangle∣g⟩+eiθ∣e⟩,将输入状态 ∣ψ⟩=α∣g⟩+β∣e⟩|\psi\rangle = \alpha|g\rangle + \beta|e\rangle∣ψ⟩=α∣g⟩+β∣e⟩ 送入 T^†\hat{T}^\daggerT^† 电路根据 MZ′M_Z'MZ′ 测量产生两个结果。对于 MZ′=+1M_Z' = +1MZ′=+1,应用 S^\hat{S}S^,结果 α∣g⟩+βei(θ−π/2)∣e⟩\alpha|g\rangle + \beta e^{i(\theta-\pi/2)}|e\rangleα∣g⟩+βei(θ−π/2)∣e⟩ 被送入 MX′M_X'MX′ 测量。对于 MZ′=−1M_Z' = -1MZ′=−1 的结果,条件 S^\hat{S}S^ 不被应用,反而结果 β∣g⟩+αeiθ∣e⟩=eiθX^(α∣g⟩+βe−iθ∣e⟩)\beta|g\rangle + \alpha e^{i\theta}|e\rangle = e^{i\theta}\hat{X}(\alpha|g\rangle + \beta e^{-i\theta}|e\rangle)β∣g⟩+αeiθ∣e⟩=eiθX^(α∣g⟩+βe−iθ∣e⟩) 被送入 MX′M_X'MX′ 测量。在后一种情况下,相位因子和 X^\hat{X}X^ 不影响测量,因此 MX′M_X'MX′ 测量在 α∣g⟩+βe−iθ∣e⟩\alpha|g\rangle + \beta e^{-i\theta}|e\rangleα∣g⟩+βe−iθ∣e⟩ 上执行。对于 θ=π/4\theta = \pi/4θ=π/4 的 ∣A⟩|A\rangle∣A⟩ 辅助,送入测量的两个状态是相同的,如 (L3) 所述。然而 ∣A⟩|A\rangle∣A⟩ 辅助上的错误改变角度。对于 Z^\hat{Z}Z^ 错误,辅助角度变为 θ=−3π/4\theta = -3\pi/4θ=−3π/4,对于 X^\hat{X}X^ 它变为 eiπ/4∣A∗⟩e^{i\pi/4}|A^*\rangleeiπ/4∣A∗⟩,等价于 θ=−π/4\theta = -\pi/4θ=−π/4,对于 Y^\hat{Y}Y^ 角度为 θ=3π/4\theta = 3\pi/4θ=3π/4。
正确 ∣A⟩|A\rangle∣A⟩ 的结果,以及辅助上的 Z^\hat{Z}Z^、X^\hat{X}X^ 和 Y^\hat{Y}Y^ 错误,列在表 VII 中。为了计算其中一些条目,我们使用了恒等式
T^=S^T^†=(1+i2I^+1−i2Z^)T^†=eiπ/4T^†+e−iπ/4Z^T^†.(L5)\hat{T} = \hat{S}\hat{T}^\dagger = \left(\frac{1+i}{\sqrt{2}}\hat{I} + \frac{1-i}{\sqrt{2}}\hat{Z}\right)\hat{T}^\dagger = e^{i\pi/4}\hat{T}^\dagger + e^{-i\pi/4}\hat{Z}\hat{T}^\dagger. \tag{L5}T^=S^T^†=(2 1+iI^+2 1−iZ^)T^†=eiπ/4T^†+e−iπ/4Z^T^†.(L5)
对 T^∣ψ⟩\hat{T}|\psi\rangleT^∣ψ⟩ 的测量 MX′M_X'MX′ 因此大约一半时间与对 T^†∣ψ⟩\hat{T}^\dagger|\psi\rangleT^†∣ψ⟩ 的 MX′M_X'MX′ 产生相同结果(意味着事情成功了),而另一半时间产生 −MX′-M_X'−MX′(意味着我们丢弃结果)。我们从表 VII 中看到,每当 ∣A⟩|A\rangle∣A⟩ 状态中的错误产生不正确的输出时,它由 MX′M_X'MX′ 测量的符号变化来标志,因此该状态将被丢弃。
在计算错误对输入状态 ∣A⟩|A\rangle∣A⟩ 的影响时,(无错误的)逻辑电路模拟显示,具有期望 Reed 码稳定子结果的 T^†\hat{T}^\daggerT^† 电路在零个、一个或两个辅助状态具有 X^\hat{X}X^、Z^\hat{Z}Z^ 或 Y^\hat{Y}Y^ 错误时产生完美输出,但当三个或更多辅助状态具有错误时,输出以错误率 p3p^3p3 缩放的概率被纯化;统计论证表明错误率应为 35p335p^335p3,如上所述。蒸馏电路失败的速率为 1−15p1-15p1−15p。
附录 M:估计分解电路的时间和规模
我们在这里提供关于分解 N=2000N=2000N=2000 位数字为其质因数所需的表面码量子计算机规模和执行时间的更多细节。我们使用文献 35 中描述的一般 Shor 电路,使用文献 37 中描述的加法电路。Shor 算法中最资源密集的部分是模幂电路,这是分解算法的支柱;在此实现中,模幂涉及 40N340N^340N3 个顺序 Toffoli 门,每个 Toffoli 门使用总共七个 T^L\hat{T}_LT^L 非 Clifford 门,先三个并行,然后一个,然后再三个并行。T^L\hat{T}_LT^L 门序列本质上不可压缩,是模幂电路中最资源密集的部分,因为每个 T^L\hat{T}_LT^L 门消耗一个高度蒸馏的 ∣AL⟩|A_L\rangle∣AL⟩ 辅助状态。
来自文献 41 的高度时间优化版 T^L\hat{T}_LT^L 电路表明,每个 T^L\hat{T}_LT^L 门可以在一个测量时间 tMt_MtM 内完成,这是表面码周期时间的一部分,因此每个 Toffoli 门需要 3tM3t_M3tM 的时间来完成。因此模幂电路的总时间为 120N3tM120N^3 t_M120N3tM。以目标测量时间 tM=100t_M = 100tM=100 ns(见第 XVII 节),这意味着分解一个 N=2000N=2000N=2000 位数字需要 26.7 小时。表面码的其余部分必须设计为向该电路提供足够的资源,以允许在此时间内执行。
每个 T^L\hat{T}_LT^L 门消耗一个辅助 ∣AL⟩|A_L\rangle∣AL⟩ 状态,因此模幂电路总共消耗 7×40N3=280N3≈2×10127 \times 40N^3 = 280N^3 \approx 2 \times 10^{12}7×40N3=280N3≈2×1012 个 ∣AL⟩|A_L\rangle∣AL⟩ 状态。这些状态必须以足以跟上模幂电路的速度生成,并且以足够小的逻辑错误率生成,使得模幂电路产生可忽略数量的错误;我们希望最终 ∣AL⟩|A_L\rangle∣AL⟩ 状态的错误率远小于 PA=(280N3)−1≈4×10−13P_A = (280N^3)^{-1} \approx 4 \times 10^{-13}PA=(280N3)−1≈4×10−13,以确保良好的保真度。
以状态注入错误率 pI=0.005p_I = 0.005pI=0.005(意味着短量子比特中注入的 ∣AL⟩|A_L\rangle∣AL⟩ 状态具有 0.5% 的错误率),假设蒸馏电路无错误,第一级蒸馏将产生错误率为 p1=35pI3≈4×10−6p_1 = 35p_I^3 \approx 4 \times 10^{-6}p1=35pI3≈4×10−6 的 ∣AL⟩|A_L\rangle∣AL⟩ 状态;第二级将产生错误率为 p2=35p13≈3×10−15p_2 = 35p_1^3 \approx 3 \times 10^{-15}p2=35p13≈3×10−15 的状态。由于此错误率低于 ∣AL⟩|A_L\rangle∣AL⟩ 状态错误的目标速率 PAP_APA,在此注入错误率下两级蒸馏是足够的。
蒸馏电路当然不是完美无缺的;给定每表面码步物理量子比特错误率 p=10−3p = 10^{-3}p=10−3,我们必须找到产生足够低逻辑错误率的表面码距离 ddd。∣AL⟩|A_L\rangle∣AL⟩ 状态的第二级也是最后一级蒸馏需要 16 个逻辑量子比特(15 个辅助加一个用于贝尔对的逻辑量子比特),并在 8×1.25×d228 \times 1.25 \times d_2^28×1.25×d22 个表面码周期内执行,包括压缩格式中的各种 CNOT 和足够的时间距离 d2d_2d2,因为我们用表面码距离 d2d_2d2 执行此蒸馏。前一级(第一级)蒸馏需要更多逻辑量子比特,使用 15×1615 \times 1615×16 个逻辑量子比特(15 组蒸馏电路,每组 16 个逻辑量子比特),以表面码距离 d1d_1d1 在 10d110d_110d1 个表面码周期内运行。我们想将第一级蒸馏的距离 ddd 减小到低于第二级,因为这减少了所需的表面码占用面积;距离减小将同时增加超过后续级的逻辑错误率,但这些错误将被蒸馏掉。
对于第二级也是最后一级蒸馏,距离 d2d_2d2 的表面码每个表面码周期的错误率 PL2P_{L2}PL2 将产生约 16×2×3×1.25d2×PL2=120d2PL216 \times 2 \times 3 \times 1.25d_2 \times P_{L2} = 120d_2 P_{L2}16×2×3×1.25d2×PL2=120d2PL2 的 ∣AL⟩|A_L\rangle∣AL⟩ 错误率(16 个逻辑量子比特,2 种逻辑量子比特,3 种错误链的乘数,以及 5d2/45d_2/45d2/4 个表面码周期)。我们需要 d2d_2d2 足够大以保持此错误率低于 PAP_APA。以错误率 p=10−3p = 10^{-3}p=10−3,距离 d2=34d_2 = 34d2=34 的码给出 PL2≈3×10−19P_{L2} \approx 3 \times 10^{-19}PL2≈3×10−19,120d2PL≈1×10−15<PA120d_2 P_L \approx 1 \times 10^{-15} < P_A120d2PL≈1×10−15<PA,刚好低于目标错误率。对于第一级蒸馏,距离 d1d_1d1 的表面码的逻辑错误率 PL1P_{L1}PL1 将产生错误率 15×16×2×3×1.25d1×PL1=1800d1PL115 \times 16 \times 2 \times 3 \times 1.25d_1 \times P_{L1} = 1800d_1 P_{L1}15×16×2×3×1.25d1×PL1=1800d1PL1 的状态。此速率可以高于 PAP_APA,因为我们蒸馏输出,所以我们实际上只需要 35(1800d1PL1)3<PA35(1800d_1 P_{L1})^3 < P_A35(1800d1PL1)3<PA。距离 d1=17d_1 = 17d1=17 的码给出 PL1≈1×10−10P_{L1} \approx 1 \times 10^{-10}PL1≈1×10−10,因此 ∣AL⟩|A_L\rangle∣AL⟩ 状态将以约 3×10−63 \times 10^{-6}3×10−6 的错误率输出。随后的蒸馏级将其减小到 1×10−151 \times 10^{-15}1×10−15,再次刚好低于目标速率。
第一级蒸馏在表面码中占据最大的占用面积,因为要生成一个最终纯化的 ∣AL⟩|A_L\rangle∣AL⟩ 状态我们需要 16×15=24016 \times 15 = 24016×15=240 个逻辑量子比特。在距离 d1=17d_1 = 17d1=17 的码中,一个逻辑量子比特占用 2.5×1.25×(2d1)2≈36002.5 \times 1.25 \times (2d_1)^2 \approx 36002.5×1.25×(2d1)2≈3600 个物理量子比特。因此第一级蒸馏将占用 240×3600≈8×105240 \times 3600 \approx 8 \times 10^5240×3600≈8×105 个物理量子比特,蒸馏需要 10d1=17010d_1 = 17010d1=170 个表面码周期。第二级也是最后一级使用 d2=34d_2 = 34d2=34 的码,因此一个逻辑量子比特占用 2.5×1.25×(2d2)2≈145002.5 \times 1.25 \times (2d_2)^2 \approx 145002.5×1.25×(2d2)2≈14500 个物理量子比特。蒸馏然后占用 16×14500≈2.4×10516 \times 14500 \approx 2.4 \times 10^516×14500≈2.4×105 个物理量子比特和约 340 个表面码周期。第一级蒸馏占用的表面码占用面积可以在第二级中重复使用,因此总共约 800,000 个物理量子比特需要生成一个足够纯化的 ∣AL⟩|A_L\rangle∣AL⟩ 状态,这需要约 500 个表面码周期。用于生成这一个状态的表面码占用面积在时空中占据一个体积,包括一个方形金字塔,底部大用于第一级蒸馏,在后续级中减小约三倍。两级的总时空体积为 170×8×105+340×2.4×105∼2.2×108170 \times 8 \times 10^5 + 340 \times 2.4 \times 10^5 \sim 2.2 \times 10^8170×8×105+340×2.4×105∼2.2×108。使用完整占用面积完整持续时间可用的时空体积为 500×8×105∼4×108500 \times 8 \times 10^5 \sim 4 \times 10^8500×8×105∼4×108。因此完整占用面积可以在相同数量的表面码周期内生成约两个 ∣AL⟩|A_L\rangle∣AL⟩ 状态,形成我们所谓的"AA 工厂"。
每个表面码周期涉及单物理量子比特重置和门、物理量子比特 CNOT,以及测量量子比特的读出;如第 XVII 节所讨论,我们相信 200 ns 的周期时间并非不合理,主要受测量时间 tMt_MtM 限制,我们取为 100 ns,但也部分受微波技术以及经典处理速度的限制。因此一个 AA 工厂可以每 500×200500 \times 200500×200 ns ≈100\approx 100≈100 μs 产生两个 ∣AL⟩|A_L\rangle∣AL⟩ 状态,并可以在 26.7 小时的分解时间内生成 2×1092 \times 10^92×109 个状态。280N3≈2.2×1012280N^3 \approx 2.2 \times 10^{12}280N3≈2.2×1012 个所需的 ∣AL⟩|A_L\rangle∣AL⟩ 状态转化为需要约 1200 个 AA 工厂并行工作,因此 1200×8×105≈1091200 \times 8 \times 10^5 \approx 10^91200×8×105≈109 个物理量子比特。Shor 算法的其余部分需要约 2N=40002N = 40002N=4000 个逻辑量子比特,在距离 d2=34d_2 = 34d2=34 的表面码中占用约 4000×14500≈5.6×1074000 \times 14500 \approx 5.6 \times 10^74000×14500≈5.6×107 个额外物理量子比特,为 AA 工厂占用面积增加相当微不足道的 6%,总共约十亿个物理量子比特。
提高表面码的性能可以在某种程度上减少这些数字。消除 ∣AL⟩|A_L\rangle∣AL⟩ 蒸馏的第一级(因此我们只做一轮蒸馏)将需要状态注入错误率 pI≲(PA/35)1/3≈2×10−5p_I \lesssim (P_A/35)^{1/3} \approx 2 \times 10^{-5}pI≲(PA/35)1/3≈2×10−5,这可能无法实现。将物理量子比特错误率提高十倍,到 p=10−4p = 10^{-4}p=10−4,将减小顶层的距离 ddd,允许 d2=16d_2 = 16d2=16 的顶层表面码,PL2≈3×10−19P_{L2} \approx 3 \times 10^{-19}PL2≈3×10−19。具有 240 个逻辑量子比特的第一级蒸馏可以使用 d1=8d_1 = 8d1=8 的码运行,PL1≈3×10−15P_{L1} \approx 3 \times 10^{-15}PL1≈3×10−15,输出错误率 ≈4×10−11\approx 4 \times 10^{-11}≈4×10−11。AA 工厂的总占用面积将为 240×2.5×1.25×(2d1)2≈2×105240 \times 2.5 \times 1.25 \times (2d_1)^2 \approx 2 \times 10^5240×2.5×1.25×(2d1)2≈2×105 个物理量子比特,并且由于码距离的减小,将以两倍速率产生 ∣AL⟩|A_L\rangle∣AL⟩ 状态,因此只需要一半的工厂数量,总共约 1.2 亿个物理量子比特。d2=16d_2 = 16d2=16 表面码中的 2N=40002N = 40002N=4000 个计算量子比特将占用 4000×3200≈12004000 \times 3200 \approx 12004000×3200≈1200 万个量子比特。因此整体表面码可以用约 1.3 亿个物理量子比特实现,尽管总体执行时间没有变化。
参考文献
1 M. A. Nielsen 和 I. L. Chuang, Quantum Computation and Quantum Information (Cambridge University Press, 2000).
2 A. M. Steane, "Quantum computing," Rep. Prog. Phys. 61, 117 (1998), arXiv:quant-ph/9708022。
3 P. W. Shor, "Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer," SIAM J. Comput. 26, 1484 (1997), arXiv:quant-ph/9508027。
4 L. K. Grover, "Quantum mechanics helps in searching for a needle in a haystack," Phys. Rev. Lett. 79, 325 (1997), arXiv:quant-ph/9706033。
5 L. K. Grover, "Quantum computers can search rapidly by using almost any transformation," Phys. Rev. Lett. 80, 4329 (1998), arXiv:quant-ph/9712011。
6 J. Clarke 和 F. K. Wilhelm, "Superconducting quantum bits," Nature 453, 1031 (2008)。
7 M. H. Devoret 和 J. M. Martinis, "Implementing qubits with superconducting integrated circuits," Quantum Inf. Process. 3, 163 (2004)。
8 S. B. Bravyi 和 A. Yu. Kitaev, "Quantum codes on a lattice with boundary," arXiv:quant-ph/9811052。
9 M. Freedman 和 D. Meyer, "Projective plane and planar quantum codes," Foundations of Computational Mathematics 1, 325 (2001), arXiv:quant-ph/9810055。
10 D. Gottesman, "Stabilizer codes and quantum error correction," Ph.D. thesis, California Institute of Technology (1997), arXiv:quant-ph/9705052。
11 A. Yu. Kitaev, "Fault-tolerant quantum computation by anyons," Ann. Phys. 303, 2 (2003), arXiv:quant-ph/9707021。
12 M. H. Freedman, A. Kitaev, M. J. Larsen 和 Z. Wang, "Topological quantum computation," Bull. Amer. Math. Soc. 40, 31 (2003), arXiv:quant-ph/0101025。
13 C. Nayak, S. H. Simon, A. Stern, M. Freedman 和 S. Das Sarma, "Non-Abelian anyons and topological quantum computation," Rev. Mod. Phys. 80, 1083 (2008), arXiv:0707.1889。
14 J. Preskill, "Lecture notes on quantum computation," 可在 http://www.theory.caltech.edu/people/preskill/ph229/ 获取。
15 M. Freedman, D. Meyer 和 F. Luo, "Z2Z_2Z2-systolic freedom and quantum codes," Mathematics of Quantum Computation, 303 (2002), arXiv:quant-ph/1303217。
16 E. Dennis, A. Kitaev, A. Landahl 和 J. Preskill, "Topological quantum memory," J. Math. Phys. 43, 4452 (2002), arXiv:quant-ph/0110143。
17 R. Raussendorf 和 J. Harrington, "Fault-tolerant quantum computation with high threshold in two dimensions," Phys. Rev. Lett. 98, 190504 (2007), arXiv:quant-ph/0610082。
18 R. Raussendorf, J. Harrington 和 K. Goyal, "Topological fault-tolerance in cluster state quantum computation," New J. Phys. 9, 199 (2007), arXiv:quant-ph/0703143。
19 R. Raussendorf, J. Harrington 和 K. Goyal, "A fault-tolerant one-way quantum computer," Ann. Phys. 321, 2242 (2006), arXiv:quant-ph/0510135。
20 A. G. Fowler, A. M. Stephens 和 P. Groszkowski, "High-threshold universal quantum computation on the surface code," Phys. Rev. A 80, 052312 (2009), arXiv:0803.0272。
21 A. G. Fowler 和 K. Goyal, "Topological cluster state quantum computing," Quantum Information & Computation 9, 721 (2009), arXiv:0805.3202。
22 A. G. Fowler, A. C. Whiteside 和 L. C. L. Hollenberg, "Towards practical classical processing for the surface code," Phys. Rev. Lett. 108, 180501 (2012), arXiv:1111.6305。
23 A. G. Fowler, M. Mariantoni, J. M. Martinis 和 A. N. Cleland, "Surface codes: Towards practical large-scale quantum computation," Phys. Rev. A 86, 032324 (2012), arXiv:1208.0928。
24 A. G. Fowler, "Constructing arbitrary steane code single logical qubit fault-tolerant gates," Quantum Information & Computation 11, 867 (2011), arXiv:0411206。
25 S. J. Devitt, A. G. Fowler, A. Stephens, A. D. Greentree, L. C. L. Hollenberg, W. J. Munro 和 K. Nemoto, "Architectural design for a topological cluster state quantum computer," New J. Phys. 11, 083032 (2009), arXiv:0808.1782。
26 A. G. Fowler, "Autotune for quantum control," arXiv:1210.4626。
27 A. G. Fowler 和 L. C. L. Hollenberg, "Scalability of Shor's algorithm with a limited set of rotation gates," Phys. Rev. A 70, 032329 (2004), arXiv:quant-ph/0401086。
28 A. G. Fowler, A. C. Whiteside 和 L. C. L. Hollenberg, "Towards practical classical processing for the surface code: Timing analysis," Phys. Rev. A 86, 042313 (2012), arXiv:1202.5601。
29 H. Bombin 和 M. A. Martin-Delgado, "Topological quantum distillation," Phys. Rev. Lett. 97, 180501 (2006), arXiv:quant-ph/0605138。
30 H. Bombin, "Topological order with a twist: Ising anyons from an abelian model," Phys. Rev. Lett. 105, 030403 (2010), arXiv:1004.1838。
31 A. Kitaev, "Anyons in an exactly solved model and beyond," Ann. Phys. 321, 2 (2006), arXiv:cond-mat/0506438。
32 S. Bravyi 和 R. Raussendorf, "Measurement-based quantum computation with the toric code states," Phys. Rev. A 76, 022304 (2007), arXiv:quant-ph/0610162。
33 A. M. Stephens, "Fault-tolerant thresholds for quantum error correction with the surface code," Phys. Rev. A 89, 022321 (2014), arXiv:1311.5003。
34 A. G. Fowler, "Optimal complexity correction of correlated errors in the surface code," arXiv:1310.0863。
35 V. Vedral, A. Barenco 和 A. Ekert, "Quantum networks for elementary arithmetic operations," Phys. Rev. A 54, 147 (1996), arXiv:quant-ph/9511018。
36 D. Beckman, A. N. Chari, S. Devabhaktuni 和 J. Preskill, "Efficient networks for quantum factoring," Phys. Rev. A 54, 1034 (1996), arXiv:quant-ph/9602016。
37 C. Miquel, J. P. Paz 和 W. H. Zurek, "Quantum computation with phase drift errors," Phys. Rev. Lett. 78, 3971 (1997), arXiv:quant-ph/9704003。
38 I. Garcia-Mata, K. M. Frahm 和 D. L. Shepelyansky, "Shor's factorization algorithm with a limited set of rotation gates," Phys. Rev. A 75, 052311 (2007), arXiv:quant-ph/0702105。
39 M. A. Nielsen 和 I. L. Chuang, Quantum Computation and Quantum Information, 第 5 章 (Cambridge University Press, 2000)。
40 P. O. Boykin, T. Mor, M. Pulver, V. Roychowdhury 和 F. Vatan, "On universal and fault-tolerant quantum computing," arXiv:quant-ph/9906054。
41 R. Van Meter 和 K. M. Itoh, "Fast quantum modular exponentiation," Phys. Rev. A 71, 052320 (2005), arXiv:quant-ph/0408006。
42 A. G. Fowler, D. S. Wang 和 L. C. L. Hollenberg, "Surface code quantum error correction incorporating accurate error propagation," Quantum Information & Computation 11, 8 (2011), arXiv:1004.0255。
43 J. Edmonds, "Paths, trees, and flowers," Canad. J. Math. 17, 449 (1965)。
44 J. Edmonds, "Maximum matching and a polyhedron with 0,1-vertices," J. Res. Nat. Bur. Standards 69B, 125 (1965)。
45--57 其他相关参考文献(见原文)。
58 Y. Makhlin, G. Schön 和 A. Shnirman, "Quantum-state engineering with Josephson-junction devices," Rev. Mod. Phys. 73, 357 (2001)。
59 M. H. Devoret 和 J. M. Martinis, "Implementing qubits with superconducting integrated circuits," Quantum Inf. Process. 3, 163 (2004)。
60 J. Q. You 和 F. Nori, "Superconducting circuits and quantum information," Physics Today 58, 42 (2005)。
61 J. Clarke 和 F. K. Wilhelm, "Superconducting quantum bits," Nature 453, 1031 (2008)。
62 R. J. Schoelkopf 和 S. M. Girvin, "Wiring up quantum systems," Nature 451, 664 (2008)。
63 D. P. DiVincenzo, "The physical implementation of quantum computation," Fortschr. Phys. 48, 771 (2000), arXiv:quant-ph/0002077。
64 H. Paik 等, "Observation of high coherence in Josephson junction qubits measured in a three-dimensional circuit QED architecture," Phys. Rev. Lett. 107, 240501 (2011)。
65 M. Mariantoni 等, "Implementing the quantum von Neumann architecture with superconducting circuits," Science 334, 61 (2011)。
66 R. Raussendorf, D. E. Browne 和 H. J. Briegel, "Measurement-based quantum computation on cluster states," Phys. Rev. A 68, 022312 (2003), arXiv:quant-ph/0301052。